


▐ 객체지향의 세 가지 주요 특징
-
자바와 C++의 차이점
-
다형성 구현 원리
다형성의 기본 구현은 런타임에 메서드 호출을 메서드 구현과 연결하는 동적 바인딩입니다.
정적 바인딩과 동적 바인딩:
하나는 메서드 오버로딩과 같은 정적 디스패치라고 하는 컴파일 타임에 결정됩니다.
하나는 메소드 재정의(재작성) 및 인터페이스 구현과 같은 동적 디스패치라고 하는 런타임 시 결정됩니다.
다형성 구현
현재 메서드 호출의 스택 프레임(로컬 변수 테이블, 작업 스택, 동적 연결, 반환 주소)이 가상 머신 스택에 저장됩니다. 다형성의 구현 프로세스는 메서드 호출을 동적으로 디스패치하는 프로세스입니다. 하위 클래스가 상위 클래스의 메서드를 재정의하는 경우 다형성 호출에서 동적 바인딩 프로세스는 먼저 실제 유형이 하위 클래스인지 확인합니다. 먼저 하위 클래스 메서드를 검색하세요. 이 프로세스가 메소드 커버리지의 핵심입니다.
정적 및 최종 키워드
-
추상 클래스 및 인터페이스
-
추상 클래스나 인터페이스는 모두 인스턴스화할 수 없습니다. -
추상 클래스와 인터페이스 모두 추상 메서드를 정의할 수 있으며 하위 클래스/구현 클래스는 이러한 추상 메서드를 재정의해야 합니다.
-
추상 클래스에는 생성자가 있고 인터페이스에는 생성자가 없습니다. -
추상 클래스는 일반 메소드를 포함할 수 있으며 인터페이스는 공용 추상(Java 8 이후 사용 가능)을 사용하여 추상 메소드만 수정할 수 있습니다. -
추상 클래스는 한 번만 상속될 수 있고 인터페이스는 여러 번 상속될 수 있습니다. -
추상 클래스는 다양한 유형의 멤버 변수를 정의할 수 있으며 인터페이스는 public static final에 의해 수정된 정적 상수만 될 수 있습니다.
-
일반 및 일반 삭제
-
반사 원리 및 사용 시나리오
1.类名.class(就是一份字节码)2.Class.forName(String className);根据一个类的全限定名来构建Class对象3.每一个对象多有getClass()方法:obj.getClass();返回对象的真实类型사용되는 장면:
공통 프레임워크 개발 - 리플렉션의 가장 중요한 용도는 다양한 공통 프레임워크를 개발하는 것입니다. 많은 프레임워크(예: Spring)가 구성됩니다(예: XML 파일을 통해 JavaBeans, 필터 등을 구성). 프레임워크의 다양성을 보장하려면 다양한 객체나 클래스를 동적으로 로드하고 그에 따라 다양한 메서드를 호출해야 합니다. 런타임 중 구성 파일.
-
동적 프록시 - AOP(Aspect 프로그래밍)에서는 특정 메서드를 가로채는 것이 필요합니다. 일반적으로 동적 프록시 메서드가 선택됩니다. 이때 이를 구현하기 위해서는 반사 기술이 필요하다. JDK: 스프링 기본 동적 프록시는 인터페이스를 구현해야 합니다.
CGLIB: asm 프레임워크를 통해 바이트 스트림을 직렬화하고 구성 가능하며 성능이 낮습니다. 사용자 정의 주석 - 주석 자체는 주석 표시에 따라 주석 해석기를 호출하고 동작을 실행하기 위해 반사 메커니즘을 사용해야 합니다.
자바 예외 시스템
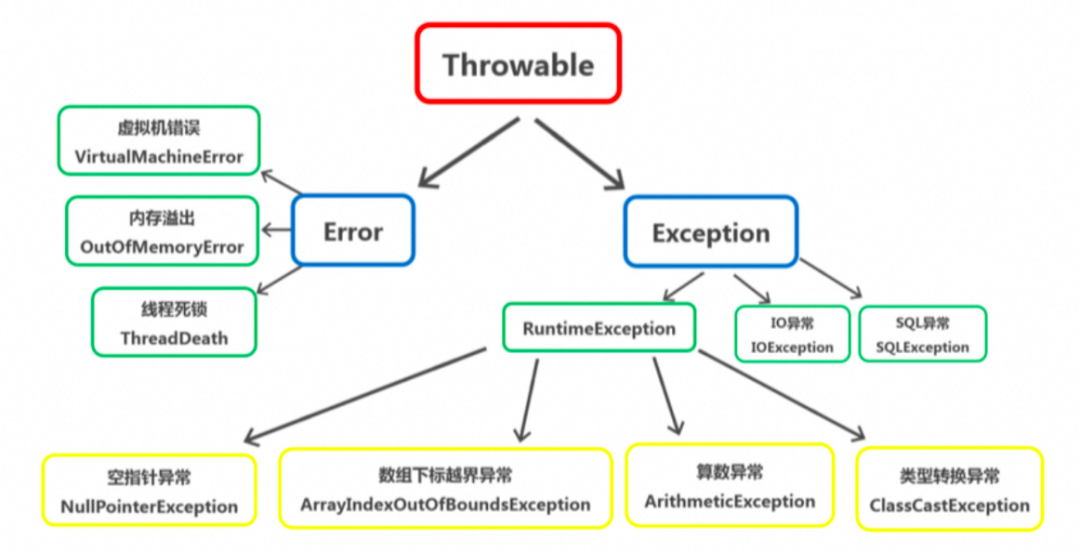
Throwable은 Java 언어의 모든 오류 또는 예외에 대한 슈퍼 클래스입니다. 다음 단계는 오류(Error)와 예외(Exception)로 구분됩니다.
오류:
Java 런타임 시스템의 내부 오류 및 리소스 소진 오류를 나타냅니다. 응용 프로그램은 이 클래스의 개체를 발생시키지 않습니다. 이러한 오류가 발생하면 사용자에게 알리는 것 외에 프로그램을 안전하게 종료하도록 노력해야 합니다.
예외: RuntimeException、CheckedException;
프로그래밍 오류는 구문 오류, 논리 오류, 연산 오류의 세 가지 범주로 나눌 수 있습니다.
구문 오류 (컴파일 오류라고도 함)는 컴파일 프로세스 중에 발생하는 오류이며 구문 오류를 찾기 위해 컴파일러에서 검사합니다.
논리적 오류는 프로그램의 실행 결과가 기대한 것과 일치하지 않는 것을 의미하며, 디버깅을 통해 오류의 원인을 찾아낼 수 있습니다.
런타임 오류는 프로그램이 비정상적으로 종료되는 오류로, 런타임 오류는 예외 처리를 통해 처리해야 합니다.
RuntimeException: 런타임 예외. 프로그램은 논리적 관점에서 이러한 예외를 피하도록 노력해야 합니다.
NullPointerException, ClassCastException과 같은;
CheckedException: 검사된 예외입니다. 프로그램은 trycatch를 사용하여 포착하고 처리합니다.
如IOException, SQLException, NotFoundException;
▐ 数据结构
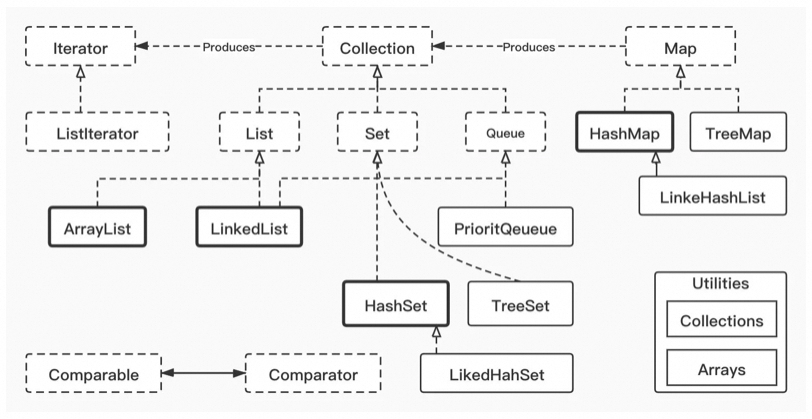
ArrayList和LinkedList
ArrayList:
底层基于数组实现,支持对元素进行快速随机访问,适合随机查找和遍历,不适合插入和删除。(提一句实际上)
默认初始大小为10,当数组容量不够时,会触发扩容机制(扩大到当前的1.5倍),需要将原来数组的数据复制到新的数组中;当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。
LinkedList:
底层基于双向链表实现,适合数据的动态插入和删除;
内部提供了List接口中没有定义的方法,用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。(比如jdk官方推荐使用基于linkedList的Deque进行堆栈操作)
ArrayList与LinkedList区别:
都是线程不安全的,ArrayList适用于查找的场景,LinkedList适用于增加、删除多的场景。
实现线程安全:
可以使用原生的Vector,或者是Collections.synchronizedList(List list)函数返回一个线程安全的ArrayList集合。
建议使用concurrent并发包下的CopyOnWriteArrayList的。
①Vector:底层通过synchronize修饰保证线程安全,效率较差。
②CopyOnWriteArrayList:写时加锁,使用了一种叫写时复制的方法;读操作是可以不用加锁的。
List遍历快速和安全失败
普通for循环遍历List删除指定元素
for(int i=0; i < list.size(); i++){if(list.get(i) == 5)list.remove(i);}
迭代遍历,用list.remove(i)方法删除元素
Iterator<Integer> it = list.iterator();while(it.hasNext()){Integer value = it.next();if(value == 5){list.remove(value);}}
foreach遍历List删除元素
for(Integer i:list){if(i==3) list.remove(i);}
fail—fast:快速失败
当异常产生时,直接抛出异常,程序终止。
fail-fast主要是体现在当我们在遍历集合元素的时候,经常会使用迭代器,但在迭代器遍历元素的过程中,如果集合的结构(modCount)被改变的话,就会抛出异常ConcurrentModificationException,防止继续遍历。这就是所谓的快速失败机制。
fail—safe:安全失败
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。由于在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException。
缺点:基于拷贝内容的优点是避免了ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
详细介绍HashMap
角度:数据结构+扩容情况+put查找的详细过程+哈希函数+容量为什么始终都是2^N,JDK1.7与1.8的区别。
参考:https://www.jianshu.com/p/9fe4cb316c05
数据结构:
HashMap在底层数据结构上采用了数组+链表+红黑树,通过散列映射来存储键值对数据。
扩容情况:
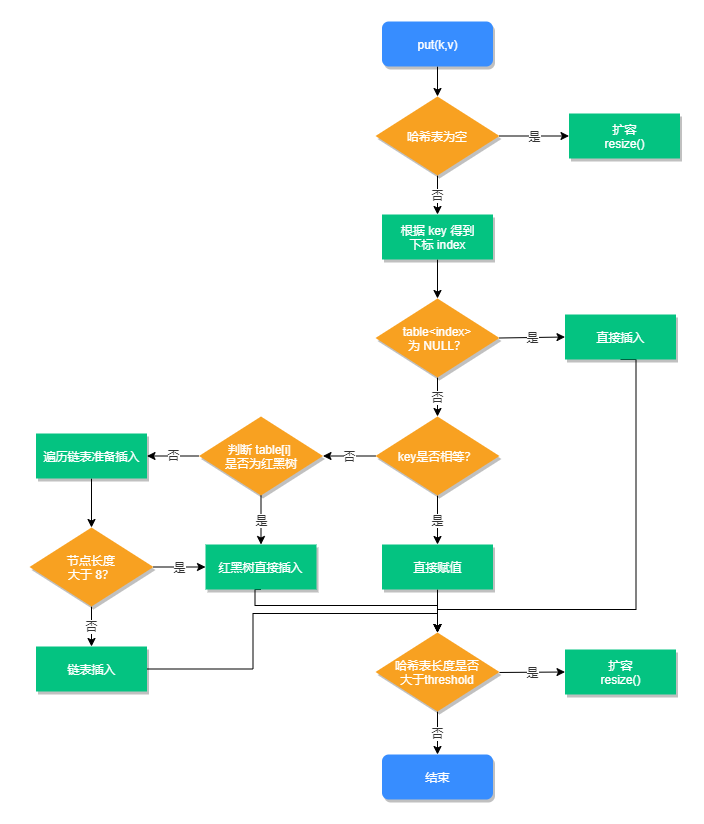
默认的负载因子是0.75,如果数组中已经存储的元素个数大于数组长度的75%,将会引发扩容操作。
【1】创建一个长度为原来数组长度两倍的新数组。
【2】1.7采用Entry的重新hash运算,1.8采用高于运算。
put操作步骤:
-
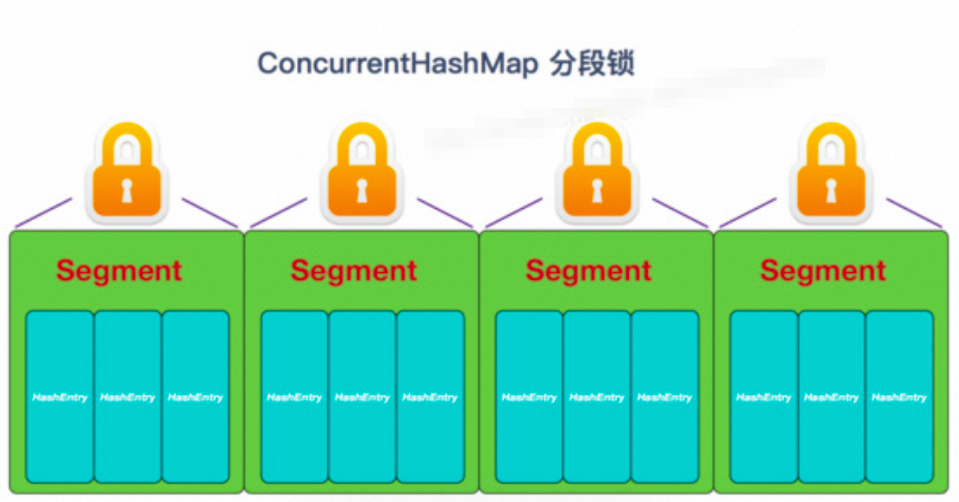
ConcurrentHashMap
序列化和反序列化
序列化的意思就是将对象的状态转化成字节流,以后可以通过这些值再生成相同状态的对象。对象序列化是对象持久化的一种实现方法,它是将对象的属性和方法转化为一种序列化的形式用于存储和传输。反序列化就是根据这些保存的信息重建对象的过程。
-
实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里)Redis的RDB -
利用序列化实现远程通信,即在网络上传送对象的字节序列。Google的protoBuf。
String
StringBuffer对方法加了同步锁,线程安全,效率略低于StringBuilder。
▐ 设计模式与原则
单例模式
-
工厂模式
抽象工厂模式
提供一个接口,用于创建相关或者依赖对象的家族,并由此进行约束。

面试题
▐ 构造方法
构造方法可以被重载,只有当类中没有显性声明任何构造方法时,才会有默认构造方法。
构造方法没有返回值,构造方法的作用是创建新对象。
▐ 初始化块
静态初始化块的优先级最高,会最先执行,在非静态初始化块之前执行。
静态初始化块会在类第一次被加载时最先执行,因此在main方法之前。
▐ This
关键字this代表当前对象的引用。当前对象指的是调用类中的属性或方法的对象。
关键字this不可以在静态方法中使用。静态方法不依赖于类的具体对象的引用。
▐ 重写和重载的区别
重载指在同一个类中定义多个方法,这些方法名称相同,签名不同。
重写指在子类中的方法的名称和签名都和父类相同,使用override注解。
▐ Object类方法
toString默认是个指针,一般需要重写;
equals比较对象是否相同,默认和==功能一致;
hashCode散列码,equals则hashCode相同,所以重写equals必须重写hashCode;
finalize用于垃圾回收之前做的遗嘱,默认空,子类需重写;
clone深拷贝,类需实现cloneable的接口;
getClass反射获取对象元数据,包括类名、方法;
notify、wait用于线程通知和唤醒;
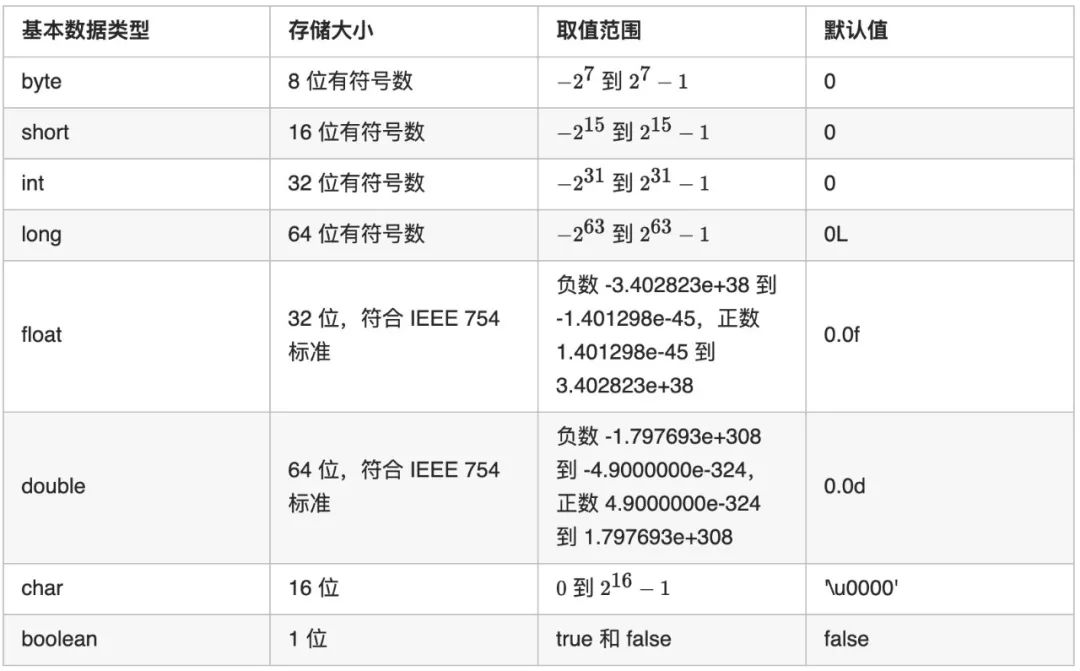
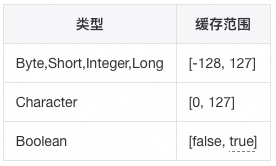
▐ 基本数据类型和包装类
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。