


현재 주류 가속 아이디어에는 연산자 최적화, 모델 컴파일, 모델 캐싱, 모델 증류 등이 포함됩니다. 다음에서는 테스트에 사용되는 몇 가지 대표적인 오픈 소스 솔루션을 간략하게 소개합니다.
▐운영자 최적화: FlashAttention2
▐모델 컴파일: oneflow/stable-fast
oneflow는 모델을 정적 그래프로 컴파일하고 이를 oneflow.nn.Graph에 내장된 연산자 융합 및 기타 가속 전략과 결합하여 모델 추론을 가속화합니다. 장점은 기본 SD 모델이 가속을 완료하기 위해 컴파일된 코드 한 줄만 필요하고 가속 효과가 분명하며 생성 효과의 차이가 작으며 다른 가속 솔루션(예: deepcache)과 함께 사용할 수 있다는 것입니다. , 공식 업데이트 빈도가 높습니다. 단점은 나중에 다루겠습니다.
Stable-fast 역시 모델 컴파일을 기반으로 하는 가속 라이브러리이며 일련의 운영자 융합 가속 방법을 결합하지만 성능 최적화는 xformer, triton 및 torch.jit와 같은 도구에 의존합니다.
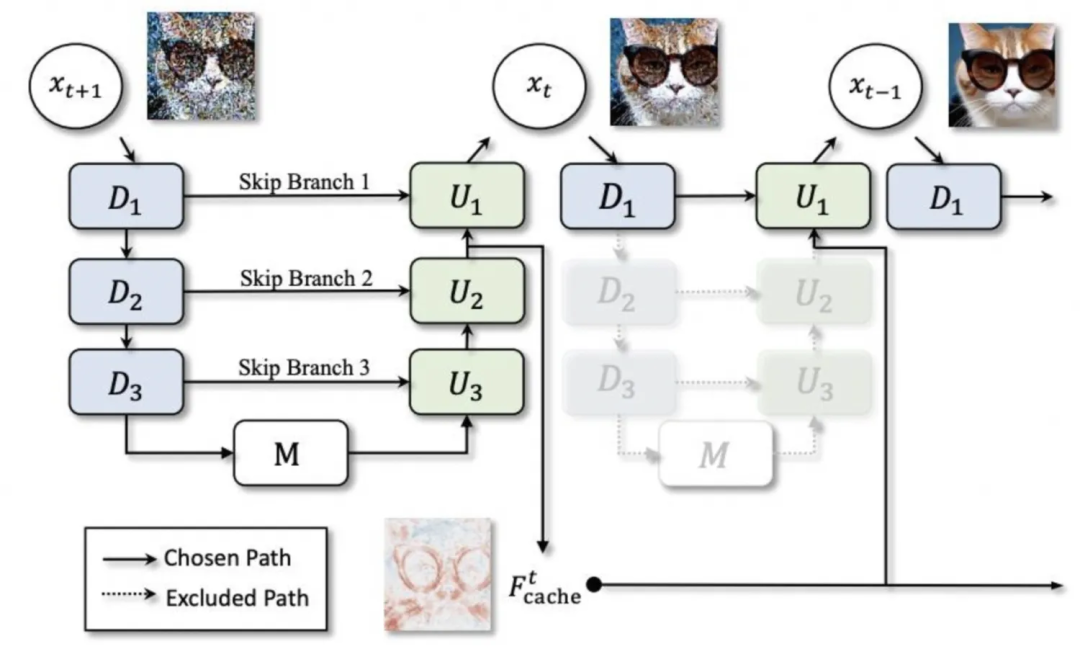
▐모델 캐싱: deepcache
▐모형 증류: lcm-lora
lcm(Latent Consistency Model)과 lora를 결합한 lcm은 전체 sd 모델을 정제하여 몇 단계의 추론을 달성하는 반면, lcm-lora는 lora 부분만 최적화하기 위해 lora 형식을 사용하므로 직접 결합할 수도 있습니다. 정기적으로 lora를 사용합니다.

SD1.5 가속 테스트
▐테스트 환경
▐테스트 결과
-
생성된 이미지를 고정 시드와 비교하면 oneflow 컴파일이 정확도 손실 없이 rt를 40% 이상 줄일 수 있다는 것을 알 수 있습니다. 그러나 새로운 파이프라인을 사용하여 처음으로 이미지를 생성하는 경우 수십 시간이 걸립니다. 준비 시간으로 몇 초의 컴파일 시간이 소요됩니다. -
Deepcache는 이를 기준으로 rt를 추가로 15~25% 줄일 수 있지만 동시에 캐시 간격이 길어질수록 생성 효과의 차이는 점점 더 분명해집니다. -
oneflow는 컨트롤넷을 사용하는 SD1.5 모델에도 효과적입니다. -
stable-fast는 외부 패키지에 크게 의존하며 다양한 버전 문제 및 외부 도구 오류가 발생하기 쉽습니다. oneflow와 마찬가지로 처음 이미지를 생성하는 데 일정량의 컴파일 시간이 걸리고 최종 가속 효과가 약간 떨어집니다. 원플로우.
▐상세 비교 데이터
최적화 |
평균 생성 시간(초) 512*512,50단계 |
가속 효과 |
효과 1 생성 |
효과 2 생성 |
효과 3 생성 |
디퓨저 |
3.3701 |
0 |
|
|
|
디퓨저+bf16 |
3.3669 |
≒0 |
|
|
|
디퓨저+컨트롤넷 |
4.7452 |
|
|||
디퓨저+원플로우 컴파일 |
1.9857 |
41.08% |
|
|
|
디퓨저+원플로우 컴파일+컨트롤넷 |
2.8017 |
|
|||
디퓨저+원플로우 컴파일+딥캐시 |
간격=2:1.4581 |
56.73%(15.65%) |
|
|
|
간격=3:1.3027 |
61.35%(20.27%) |
|
|
||
간격=5:1.1583 |
65.63%(24.55%) |
|
|
||
디퓨저+스패스트 |
2.3799 |
29.38% |















▐테스트 환경
▐테스트 결과
기본 sdxl 모델:
고정된 시드 조건에서 sdxl 모델은 다른 가속 방식을 사용하여 이미지 생성 효과에 더 많은 영향을 미치는 것으로 보입니다.
Oneflow는 rt를 24%만 줄일 수 있지만 생성된 이미지의 정확성은 여전히 보장할 수 있습니다.
Deepcache는 간격이 2일 때(즉, 캐시가 한 번만 사용됨) 간격이 5일 때 rt가 69% 감소합니다. 이미지도 분명합니다.
lcm-lora는 그래프를 생성하는 데 필요한 단계 수를 크게 줄이고 추론 가속을 크게 달성할 수 있습니다. 그러나 사전 훈련된 가중치를 사용하면 안정성이 매우 낮고 단계 수에 매우 민감합니다. 요청한 사진과 일치하는 안정적인 출력 보장
oneflow와 deepcache/lcm-lora를 함께 사용하면 좋습니다.
로라:
로라를 로딩한 후에는 디퓨저의 추론 속도가 크게 감소하며, 감소 정도는 사용된 로라의 종류와 양에 따라 달라집니다.
deepcache는 여전히 작동하고 여전히 정확도 문제가 있지만 낮은 캐시 간격에서는 차이가 크지 않습니다.
lora를 사용하는 경우 oneflow 컴파일은 원본 버전과의 일관성을 유지하도록 시드를 수정할 수 없습니다.
Oneflow 컴파일은 lora를 로드한 후 추론 속도를 최적화합니다. 여러 lora가 로드되면 추론 rt는 lora가 로드되지 않을 때와 거의 동일하며 가속 효과는 매우 중요합니다. 예를 들어 실+수채화 두 로라를 동시에 사용하면 rt가 약 65% 정도 줄어들 수 있습니다.
oneflow에서는 lora 로딩 시간을 소폭 최적화했는데, lora 로딩 후 설정 동작 시간이 늘어났습니다.
▐상세 비교 데이터
최적화 |
로라 |
평균 생성 시간(초) 512*512, 50step |
Lora 로딩 시간(초) |
로라 수정 시간(초) |
효과 1 |
효과 2 |
효과 3 |
디퓨저 |
없음 |
4.5713 |
|
||||
실 |
7.6641 |
13.9235 11.0447 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0263 |
||||||
yarn+watercolor |
10.1402 |
|
|||||
diffusers+bf16 |
无 |
4.6610 |
|
||||
yarn |
7.6367 |
12.6095 11.1033 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0192 |
||||||
yarn+ watercolor |
10.0729 |
||||||
diffusers+deepcache |
无 |
interval=2:2.6402 |
|
||||
yarn |
interval=2:4.6076 |
||||||
watercolor |
interval=2:4.3953 |
||||||
yarn+ watercolor |
interval=2:5.9759 |
|
|||||
无 |
interval=5: 1.4068 |
|
|||||
yarn |
interval=5:2.7706 |
||||||
watercolor |
interval=5:2.8226 |
||||||
yarn+watercolor |
interval=5:3.4852 |
|
|||||
diffusers+oneflow编译 |
无 |
3.4745 |
|
||||
yarn |
3.5109 |
11.7784 10.3166 |
0.5左右 移除lora 0.17 |
||||
watercolor |
3.5483 |
||||||
yarn+watercolor |
3.5559 |
|
|||||
diffusers+oneflow编译+deepcache |
无 |
interval=2:1.8972 |
|
||||
yarn |
interval=2:1.9149 |
||||||
watercolor |
interval=2:1.9474 |
||||||
yarn+watercolor |
interval=2:1.9647 |
|
|||||
无 |
interval=5:0.9817 |
|
|||||
yarn |
interval=5:0.9915 |
||||||
watercolor |
interval=5:1.0108 |
||||||
yarn+watercolor |
interval=5:1.0107 |
|
|||||
diffusers+lcm-lora |
4step:0.6113 |
||||||
diffusers+oneflow编译+lcm-lora |
4step:0.4488 |














AI试衣业务场景使用了算法在diffusers框架基础上改造的专用pipeline,功能为根据待替换服饰图对原模特图进行换衣,基础模型为SD2.1。
根据调研的结果,deepcache与oneflow是优先考虑的加速方案,同时,由于pytorch版本较低,也可以尝试使用较新版本的pytorch进行加速。
▐ 测试环境
A10 + cu118 + py310 + torch2.0.1 + diffusers0.21.4
图生图(示意图,仅供参考):
待替换服饰 |
原模特图 |
|
|


▐ 测试结果
pytorch2.2版本集成了FlashAttention2,更新版本后,推理加速效果明显
deepcache仍然有效,为了尽量不损失精度,可设置interval为2或3
对于被“魔改”的pipeline和子模型,oneflow的图转换功能无法处理部分操作,如使用闭包函数替换forward、使用布尔索引等,而且很多错误原因较难通过报错信息来定位。在进行详细的排查之后,我们尝试了改造原模型代码,对其中不被支持的操作进行替换,虽然成功地在没有影响常规生成效果的前提下完成了改造,通过了oneflow编译,但编译后的生成效果很差,可以看出oneflow对pytorch的支持仍然不够完善
最终采取pytorch2.2.1+deepcache的结合作为加速方案,能够实现rt降低40%~50%、生成效果基本一致且不需要过多改动原服务代码
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 576*768,25step |
生成效果 |
diffusers |
22.7289 |
|
diffusers+torch2.2.1 |
15.5341 |
|
diffusers+torch2.2.1+deepcache |
11.7734 |
|
diffusers+oneflow编译 |
17.5857 |
|
diffusers+deepcache |
interval=2:18.0031 |
|
interval=3:16.5286 |
|
|
interval=5:15.0359 |
|








目前市面上有很多非常好用的开源模型加速工具,pytorch官方也不断将各种广泛采纳的优化技术整合到最新的版本中。
我们在初期的调研与测试环节尝试了很多加速方案,在排除了部分优化效果不明显、限制较大或效果不稳定的加速方法之后,初步认为deepcache和oneflow是多数情况下的较优解。
但在解决实际线上服务的加速问题时,oneflow表现不太令人满意,虽然oneflow团队针对SD系列模型开发了专用的加速工具包onediff,且一直保持高更新频率,但当前版本的onediff仍存在不小的限制。
如果使用的SD pipeline没有对unet的各种子模块进行复杂修改,oneflow仍然值得尝试;否则,确保pytorch版本为最新的稳定版本以及适度使用deepcache可能是更省心且有效的选择。

相关资料
FlashAttention:
https://github.com/Dao-AILab/flash-attention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
oneflow
https://github.com/Oneflow-Inc/oneflow
https://github.com/siliconflow/onediff
stable-fast
https://github.com/chengzeyi/stable-fast
deepcache
https://github.com/horseee/DeepCache
lcm-lora
https://latent-consistency-models.github.io/
pytorch 2.2
https://pytorch.org/blog/pytorch2-2/

我们是淘天集团内容技术AI工程团队,通过搭建完善的算法工程化一站式平台,辅助上千个淘宝图文、视频、直播等泛内容领域算法的工程落地、部署和优化,承接每日上亿级别的数字内容数据,支撑并推动AI技术在淘宝内容社交生态中的广泛应用。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。