
바로 지난주에 우리는 GreptimeDB 2024 로드맵을 발표하여 올해 GreptimeDB에 대한 몇 가지 주요 버전 계획을 공개했습니다. 3월 초봄이 도래하면서 모든 것이 회복되는 '징저(Jingzhe)' 시즌에 프로덕션 수준에 적합한 최초의 GreptimeDB 오픈소스 버전도 예정대로 도착했습니다. v0.7은 프로덕션 준비 버전을 향한 중요한 단계이며 커뮤니티의 모든 구성원이 적극적으로 참여하고 귀중한 피드백을 제공하는 것을 환영합니다.
v0.6에서 v0.7까지 Greptime 팀은 상당한 진전을 이루었습니다. 총 184개의 커밋이 병합되었고, 82개의 기능 향상, 35개의 버그 수정, 19개의 코드 리팩토링 및 수많은 파일이 수정되었습니다. 테스트 작업. 이 기간 동안 총 8명의 독립 기여자가 GreptimeDB의 코드 기여에 참여했습니다. GreptimeDB의 코드 기여에 지속적으로 참여 하고 우리와 함께 성장하는 GreptimeDB의 첫 번째 커미터인 Eugene Tolbakov에게 특별히 감사드립니다!
업데이트 하이라이트(스트림 저장 버전) Metric Engine : 관찰 가능한 시나리오를 위해 설계된 새로운 엔진이 권장되며, 클라우드 네이티브 모니터링 시나리오에 적합한 다수의 작은 테이블을 처리할 수 있습니다. Region Migration : 사용 경험을 최적화하고 SQL을 통해 쉽게 실행할 수 있습니다. 영역 마이그레이션, 반전 인덱스 : 사용자 쿼리와 관련된 데이터 세그먼트를 효율적으로 찾고, 데이터 파일을 스캔하는 데 필요한 IO 작업을 크게 줄이고 쿼리 프로세스를 가속화합니다.
v0.7은 GreptimeDB가 오픈소스로 공개된 이후 몇 안 되는 주요 버전 업데이트 중 하나입니다. 이번에는 비디오 계정에서도 라이브로 방송하겠습니다. 기능 세부 사항에 대해 자세히 알아보거나, 데모 데모를 보거나, 핵심 개발팀과 심도 있는 토론을 하고 싶다면 다음 주 목요일(3월 14일) 오후 19시 30분에 라이브 방송에 참여해 주세요.
지역 마이그레이션
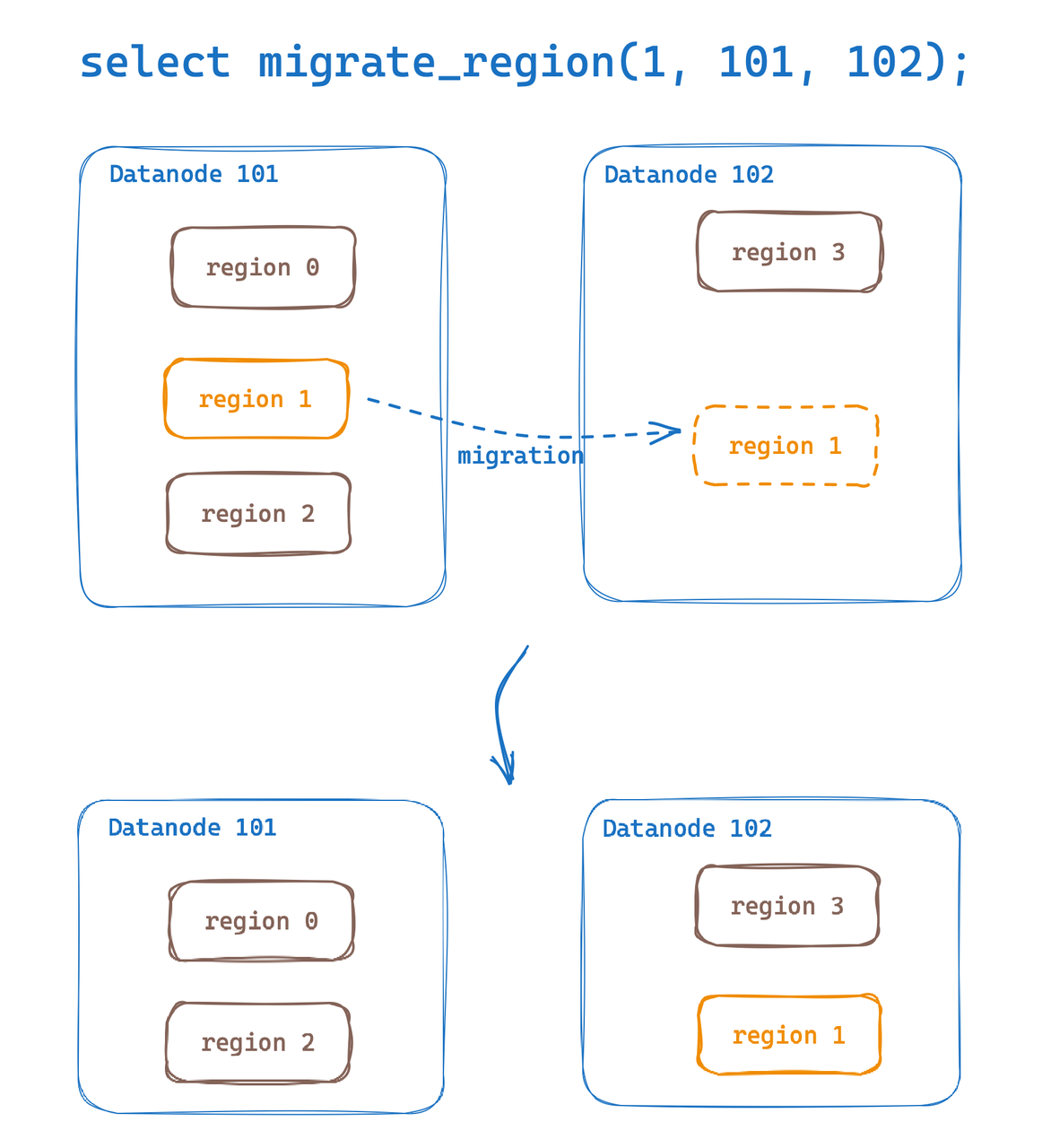
Region Migration은 데이터노드 간 데이터 테이블의 영역을 마이그레이션하는 기능을 제공하며, 이 기능을 통해 핫스팟 데이터 마이그레이션과 로드 밸런싱의 수평 확장을 쉽게 구현할 수 있습니다. GreptimeDB는 v0.6이 출시되었을 때 지역 마이그레이션이 처음 구현되었다고 언급했습니다. 이번 버전 업데이트는 사용자 경험을 개선하고 최적화합니다.
이제 SQL을 통해 쉽게 지역 마이그레이션을 수행할 수 있습니다.
select migrate_region(
region_id,
from_dn_id,
to_dn_id,
[replay_timeout(s)]);
미터법 엔진
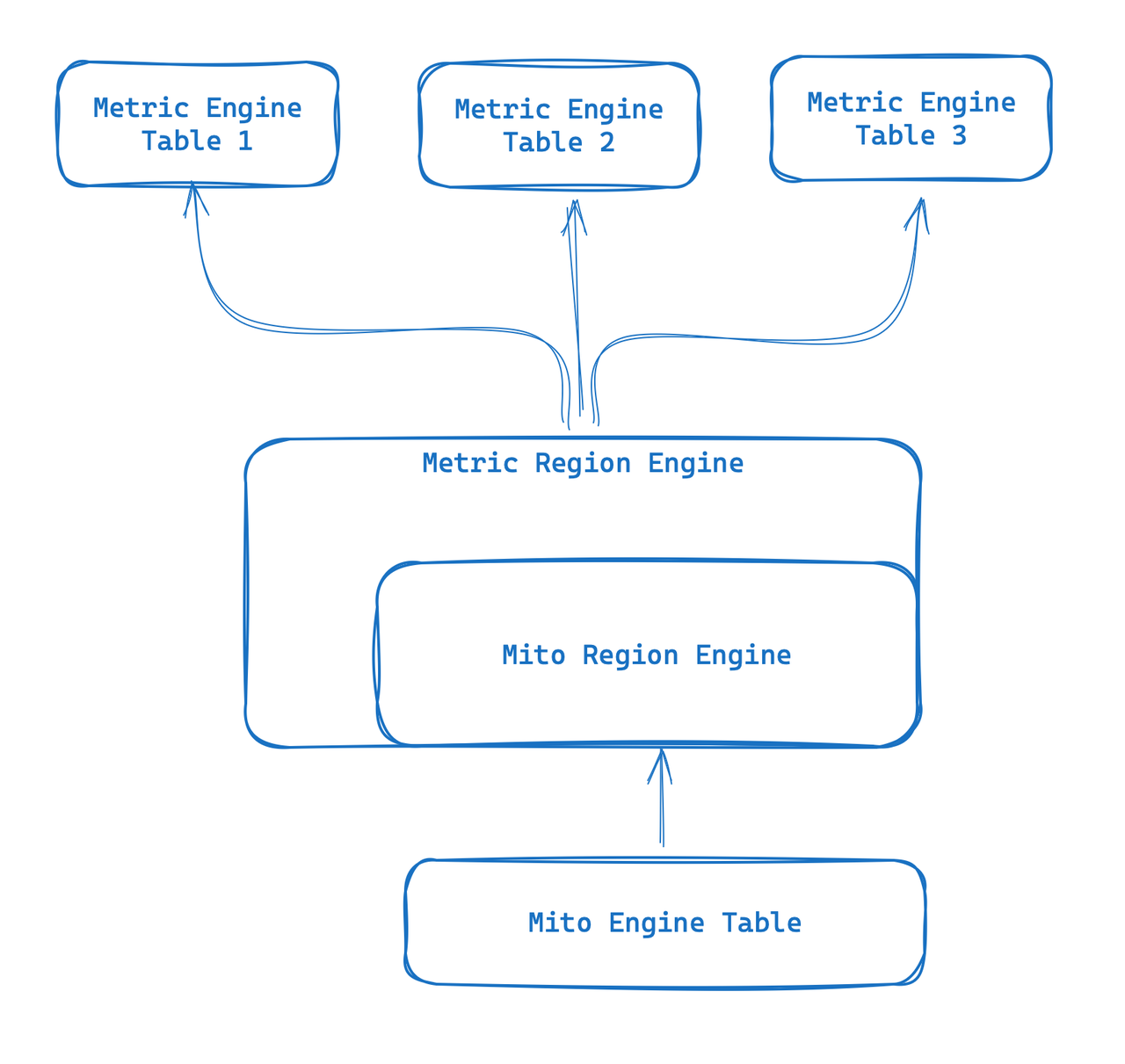
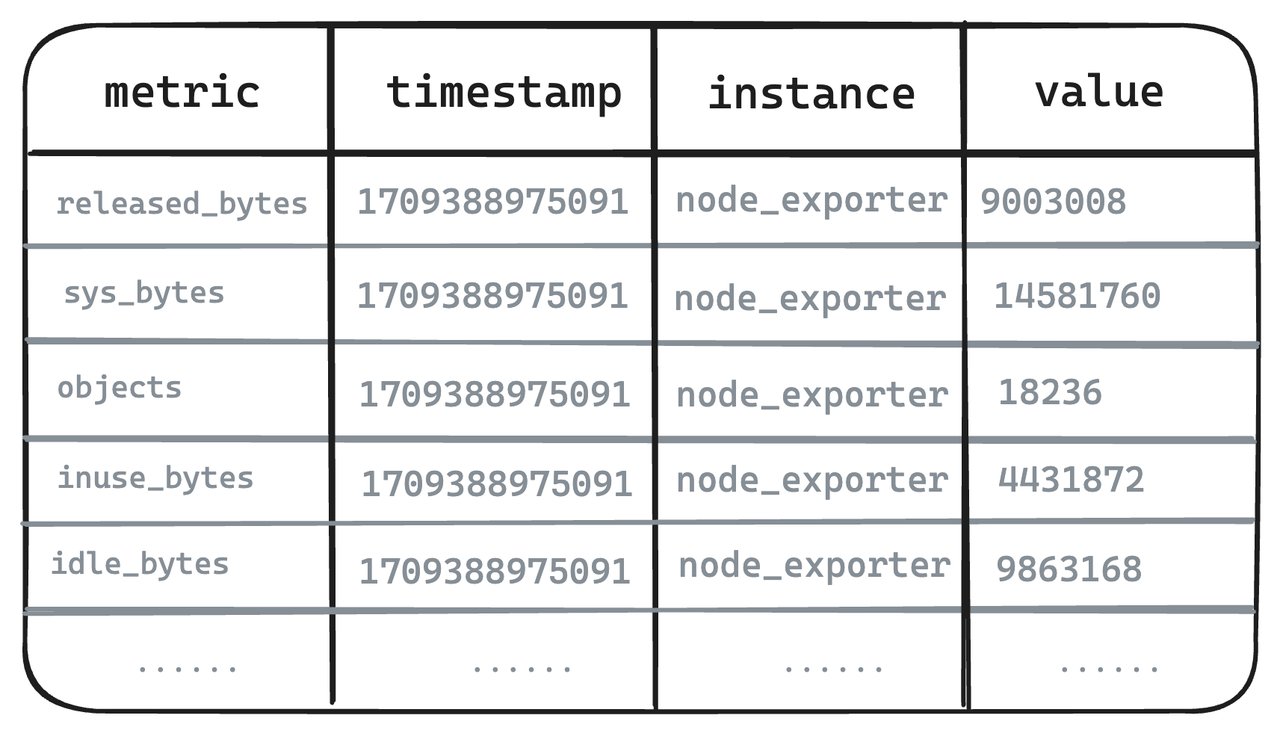
Metric Engine은 관찰 가능한 시나리오를 위해 설계된 새로운 엔진입니다. 주요 목표는 다수의 작은 테이블을 처리할 수 있는 것이며 특히 Prometheus 사용과 같은 클라우드 기반 모니터링 시나리오에 적합합니다. 이 새로운 엔진은 합성 와이드 테이블을 활용하여 지표 데이터를 저장하고 메타데이터를 재사용할 수 있는 기능을 제공합니다. 그 위에 "테이블"이 더 가벼워지고 너무 무거운 기존 Mito 엔진 테이블의 일부 한계를 극복할 수 있습니다.
-
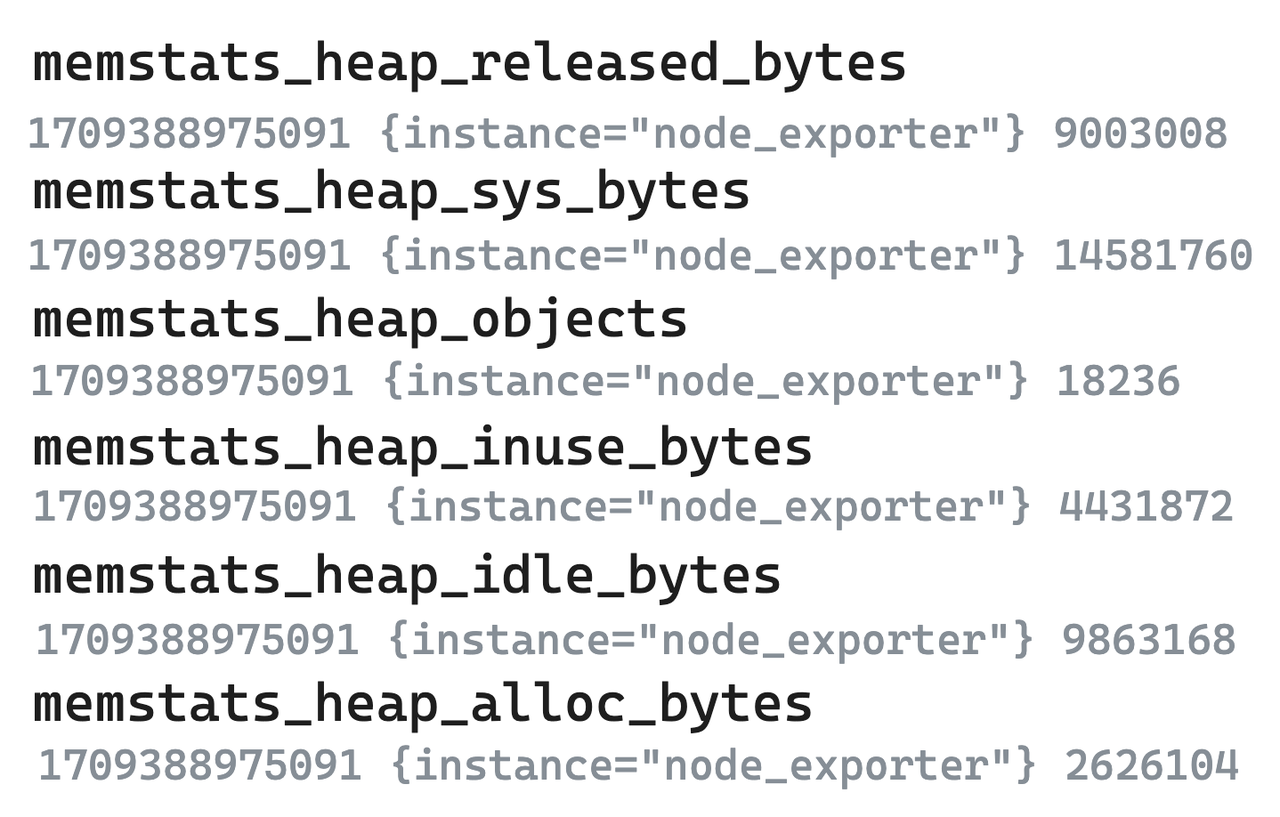
범례 - 원시 측정항목 데이터
- 6개의 노드 내보내기에 대한 다음 지표는 예로 사용됩니다. Prometheus로 대표되는 단일 값 모델 시스템에서는 상관관계가 높은 지표라도 여러 개로 분할하여 별도로 저장해야 합니다.
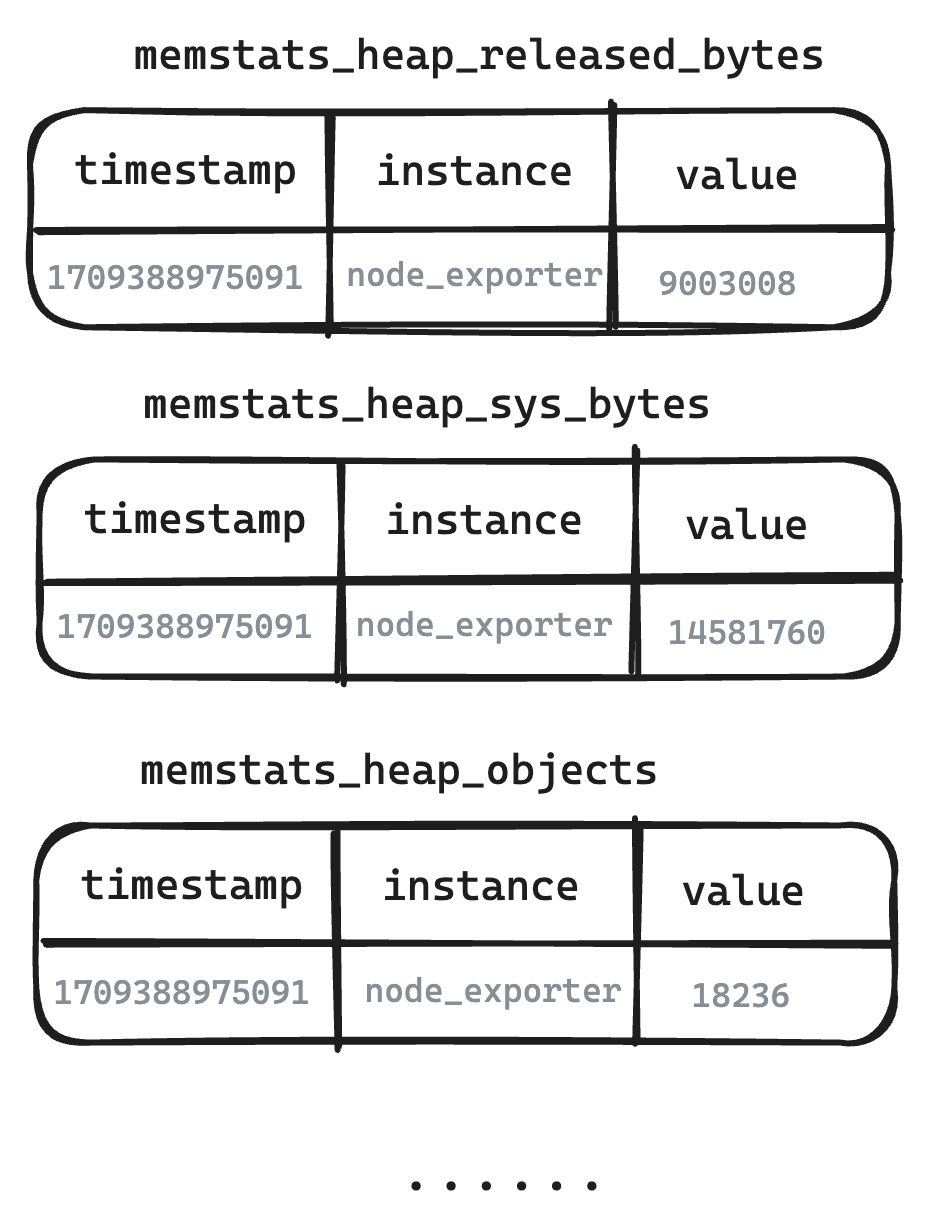
-
범례 - 사용자 관점의 논리 테이블
- Metric Engine은 Metrics의 구조를 실제로 복원하며, 사용자가 보는 것은 작성된 Metrics 구조입니다.
-
범례 - 관점을 저장하는 물리적 테이블
- 스토리지 계층에서 Metric Engine은 매핑을 수행하고 물리적 테이블을 사용하여 관련 데이터를 저장하므로 스토리지 비용을 줄이고 대규모 Metrics 스토리지를 지원할 수 있습니다.
-
범례 - 다음 R&D 계획: 분야 자동 그룹화
- 실제 시나리오에서 생성된 대부분의 지표는 관련성이 있습니다. GreptimeDB는 관련 지표를 자동으로 도출하고 이를 병합할 수 있으므로 지표 전반에 걸쳐 타임라인 수를 줄일 뿐만 아니라 관련 쿼리에도 친숙합니다.

-
스토리지 비용 최적화
비용 테스트는 AWS S3 스토리지 백엔드를 기준으로 진행되었으며, 각 데이터는 약 30분 동안 작성되었으며, 총 쓰기량은 약 30w row/s였습니다. 프로세스에서 각 작업이 발생하는 횟수를 계산하고 AWS 견적을 기반으로 비용을 추정합니다. 테스트 중에 인덱스 기능이 활성화되었습니다.
견적은 https://aws.amazon.com/s3/pricing/ 에서 표준 수준을 참조하십시오.
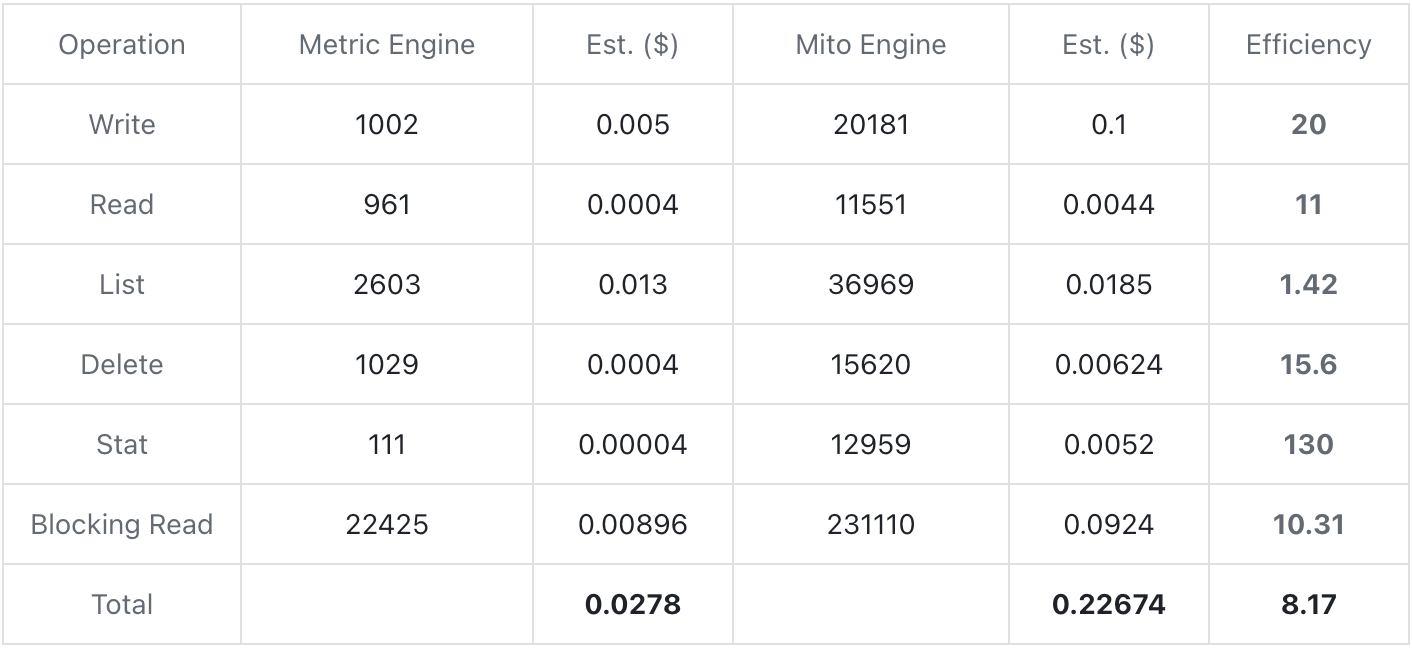
위의 테스트 테이블에서 볼 수 있듯이 Metric Engine은 물리적 테이블 수를 줄여 스토리지 비용을 크게 줄일 수 있으며, 각 단계의 작업 수를 10배 이상 줄여서 변환된 종합 비용을 줄일 수 있습니다. Mito 엔진과 비교하여 시간.
반전 인덱스
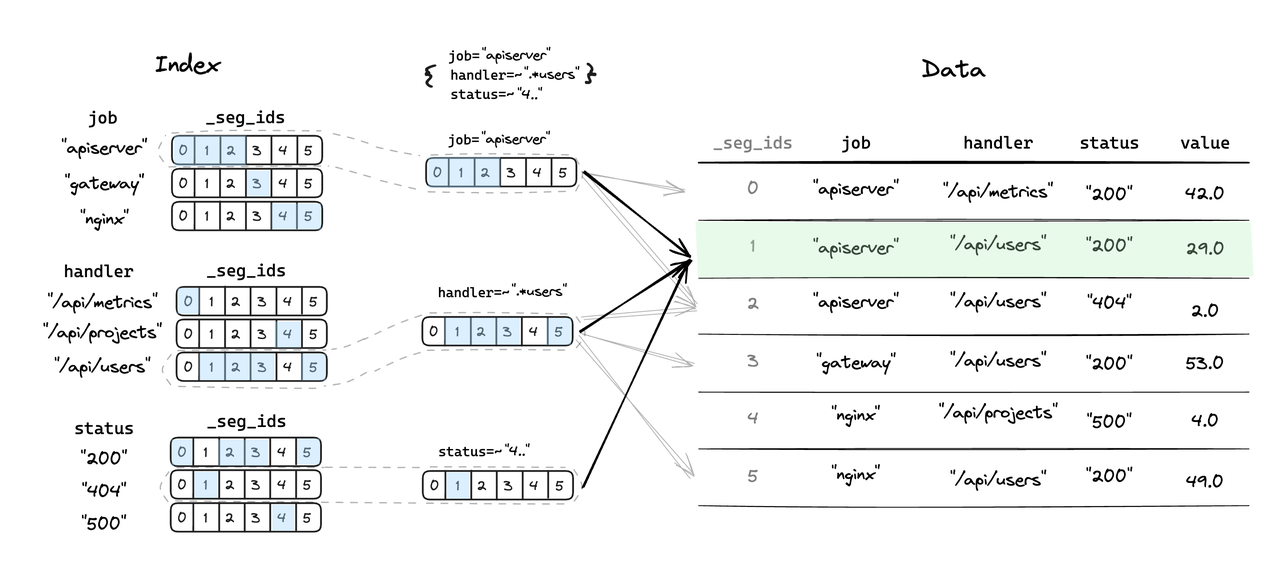
새로 도입된 인덱스 모듈인 Inverted Index는 사용자 쿼리와 관련된 데이터 세그먼트를 효율적으로 찾고, 데이터 파일을 스캔하는 데 필요한 IO 작업을 크게 줄이고 쿼리 프로세스를 가속화하도록 설계되었습니다. TSBS 테스트 시나리오에서는 장면 성능이 평균 50% 향상되었으며 일부 시나리오에서는 성능이 거의 200% 향상되었습니다. 역지수의 핵심 장점은 다음과 같습니다.
- 기본 제공: 시스템이 자동으로 적절한 색인을 생성하며 사용자는 추가 색인을 지정할 필요가 없습니다.
- 실용적인 기능: 다중 열 값의 동일성, 범위 및 정기적인 일치를 지원하여 대부분의 시나리오에서 데이터를 빠르게 찾고 필터링할 수 있습니다.
- 유연한 적응: 내부 매개변수를 자동으로 조정하여 건설 비용과 쿼리 효율성의 균형을 맞추고 다양한 시나리오의 인덱싱 요구 사항에 효과적으로 대응합니다.
- 범례 - Inverted Index 및 데이터 포지셔닝 프로세스의 논리적 표현
- 사용자는 여러 열에 필터링 조건을 지정하고 Inverted Index의 빠른 위치 지정을 통해 일치하지 않는 데이터 세그먼트의 대부분을 제거할 수 있으므로 스캔할 데이터 세그먼트 수가 줄어들고 쿼리 가속화가 달성됩니다.
기타 업데이트
1. 데이터베이스 관리 기능이 대폭 강화되었습니다.
우리는 SCHEMATA 및 PARTITIONS와 같은 새로운 정보를 추가하여 information_schema 테이블을 대폭 보완했습니다. 또한 새 버전에는 DB 관리 작업을 구현하기 위한 많은 새로운 SQL 기능이 도입되었습니다. 예를 들어 이제 SQL을 통해 Region Flush를 트리거하고, Region 마이그레이션을 수행하고, 프로시저의 실행 상태를 쿼리할 수 있습니다.
2. 성능 개선
v0.7 버전에서는 데이터 스캔 속도를 향상시키고 메모리 사용량을 줄이기 위해 Memtable을 재구성했습니다. 동시에 우리는 객체 스토리지의 읽기 및 쓰기 성능을 많이 개선하고 최적화했습니다.
업그레이드 가이드
새 버전의 일부 주요 변경 사항으로 인해 이 v0.7 릴리스에서는 업그레이드를 위해 다운타임이 필요합니다. 일반적인 업그레이드 프로세스는 다음과 같습니다.
- 새 v0.7 클러스터 만들기
- 기존 클러스터 교통 입구 폐쇄(쓰기 중지)
- GreptimeDB CLI 업그레이드 도구를 통해 테이블 구조 및 데이터 내보내기
- GreptimeDB CLI 업그레이드 도구를 통해 새 클러스터로 데이터 가져오기
- 인그레스 트래픽이 새 클러스터로 전환됩니다.
자세한 업그레이드 가이드는 다음을 참조하세요.
미래 전망
다음 주요 이정표는 v0.8이 출시되는 4월입니다. 이 버전에서는 GreptimeDB 데이터 스트림에서 지속적인 집계 작업을 수행하도록 특별히 설계된 최적화된 스트림 컴퓨팅 솔루션인 GreptimeFlow를 소개합니다. 유연성에 대한 필요성을 고려하여 GreptimeFlow는 GreptimeDB 컴퓨팅 계층에 통합되어 함께 배포되거나 독립적인 서비스로 배포될 수 있습니다.
기능 수준의 지속적인 업그레이드 외에도 v0.7의 성능이 이전에 비해 크게 향상되었지만 관찰 가능한 시나리오에서 일부 주류 솔루션 사이에는 여전히 약간의 차이가 있습니다. 이는 또한 우리의 다음 주요 최적화 방향이 될 것입니다.
연중 버전 업데이트 계획을 포괄적으로 이해하려면 GreptimeDB 로드맵 2024를 읽어보세요. 또한 코드 기여나 피드백, 기능 및 성능에 대한 토론에 참여하여 GreptimeDB의 지속적인 성장과 개선을 함께 지켜보시기 바랍니다.
Greptime 소개:
Greptime Greptime Technology는 스마트 자동차, 사물 인터넷, 가시성 등 대량의 시계열 데이터를 생성하는 분야에 효율적인 실시간 데이터 저장 및 분석 서비스를 제공하여 고객이 데이터의 깊은 가치를 채굴할 수 있도록 지원하는 데 전념하고 있습니다. 현재 3가지 주요 제품이 있습니다.
-
GreptimeDB는 Rust 언어로 작성된 시계열 데이터베이스로, 분산형, 오픈 소스, 클라우드 기반이며 호환성이 뛰어납니다. 이는 기업이 시계열 데이터를 실시간으로 읽고, 쓰고, 처리하고 분석하는 데 도움이 되며, 장기적인 저장 비용도 절감됩니다.
-
GreptimeCloud는 관찰 가능성, 사물 인터넷 및 기타 분야와 고도로 통합될 수 있는 완전 관리형 DBaaS 서비스를 사용자에게 제공할 수 있습니다.
-
GreptimeAI는 LLM 애플리케이션에 맞춰진 관찰 솔루션입니다.
-
차량-클라우드 통합 솔루션은 자동차 회사의 실제 비즈니스 시나리오에 깊이 파고들어 회사의 차량 데이터가 기하급수적으로 증가한 후 실제 비즈니스 문제점을 해결하는 시계열 데이터베이스 솔루션입니다.
GreptimeCloud 및 GreptimeAI는 공식적으로 테스트되었습니다. 최신 개발 소식을 보려면 공식 계정이나 공식 웹사이트를 팔로우하세요! GreptimDB의 엔터프라이즈 버전에 관심이 있으시면 어시스턴트에게 문의하실 수 있습니다(어시스턴트를 추가하려면 WeChat에서 greptime을 검색하세요).
공식 홈페이지: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
트위터: https://twitter.com/Greptime
슬랙: https://www.greptime.com/slack
링크드인: https://www.linkedin.com/company/greptime
1990년대에 태어난 프로그래머가 비디오 포팅 소프트웨어를 개발하여 1년도 안 되어 700만 개 이상의 수익을 올렸습니다. 결말은 매우 처참했습니다! 고등학생들이 성인식으로 자신만의 오픈소스 프로그래밍 언어 만든다 - 네티즌 날카로운 지적: 만연한 사기로 러스트데스크 의존, 가사 서비스 타오바오(taobao.com)가 가사 서비스를 중단하고 웹 버전 최적화 작업 재개 자바 17은 가장 일반적으로 사용되는 Java LTS 버전입니다. Windows 10 시장 점유율 70%에 도달, Windows 11은 계속해서 Open Source Daily를 지원합니다. Google은 Docker가 지원하는 오픈 소스 Rabbit R1을 지원합니다. Electric, 개방형 플랫폼 종료 Apple, M4 칩 출시 Google, Android 범용 커널(ACK) 삭제 RISC-V 아키텍처 지원 Yunfeng은 Alibaba에서 사임하고 향후 Windows 플랫폼용 독립 게임을 제작할 계획