
저자: vivo 인터넷 빅데이터 팀 - Huang Guihu, Chen Shengzun
HBase는 높은 신뢰성, 확장성, 고성능을 갖춘 오픈 소스 분산형 비관계형 데이터베이스로 빅데이터 처리, 실시간 컴퓨팅, 데이터 저장 및 검색 등 분야에서 널리 사용됩니다. 분산 클러스터에서는 하드웨어 오류가 흔히 발생합니다. 하드웨어 오류는 노드 또는 클러스터 수준 서비스 중단, 메타 테이블 손상, RIT, 지역 홀, 중복 및 기타 문제로 이어질 수 있습니다. 오류를 신속하게 복구하고 비즈니스를 복원하는 방법은 무엇입니까? 특히 중요합니다. 이 문서는 주로 HBase 메타 테이블과 관련된 일반적인 오류 및 해당 솔루션을 설명합니다.
1. 배경
HBase 개발, 운영, 유지보수 관련 업무를 해본 친구들이라면 어느 정도 이런 느낌을 갖고 있을 거라 생각합니다. HBase는 분산형 비관계형 데이터베이스의 선두주자로서 안정적일 뿐만 아니라 고성능일 뿐만 아니라 설치와 확장이 매우 간편합니다. 성숙한 모니터링 시스템은 문제 해결에 매우 비우호적입니다. HBase에 대한 포괄적인 이해가 부족하면 매일 발생하는 오류를 처리하기가 어려울 수 있습니다. 우리는 편집자로서 1.x~2.x 버전을 포함하여 다양한 크기의 20개 이상의 HBase 클러스터를 운영하고 유지 관리해 왔습니다. 메타 테이블 손상 및 정상적인 온라인 접속 실패, 리전 중복, 리전 홀, 권한 상실 등의 온라인 문제를 다루어 왔으며, 다양한 문제로 HBase 소스 코드에서 정답을 모색했습니다. 편집자들이 수많은 실패를 통해 요약한 메타 테이블에 대한 일반적인 솔루션입니다.
2. HBase 메타 메타 정보 테이블
카탈로그 테이블이라고도 하는 HBase 메타 테이블은 HBase 클러스터의 모든 지역과 해당 RegionServer 정보를 저장하는 특수 HBase 테이블입니다. 메타 정보 테이블의 데이터 정확성은 HBase 클러스터의 정상적인 작동에 중요합니다. 따라서 클러스터의 안정적인 운영을 위해서는 메타정보 테이블의 올바른 데이터가 필수 조건입니다. 메타 테이블의 데이터가 일치하지 않으면 RIT(Region In Transition)가 발생하거나 HMaster가 정상적으로 초기화되지 않아 클러스터가 정상적으로 시작되지 않습니다. 이는 HBase 클러스터에서 메타 테이블의 중요성을 보여줍니다. 메타 테이블 구조, 데이터 형식, 이를 구문 분석하는 프로세스를 시작합니다(이 문서에서는 주로 HBase 2.4.8 버전에 초점을 맞추고 HBase 1.x 버전도 삽입합니다).
2.1 메타 테이블 구조
메타 테이블에는 주로 지역 정보와 테이블 상태를 각각 기록하는 info, table, rep_barrier의 세 가지 열 패밀리가 포함됩니다.
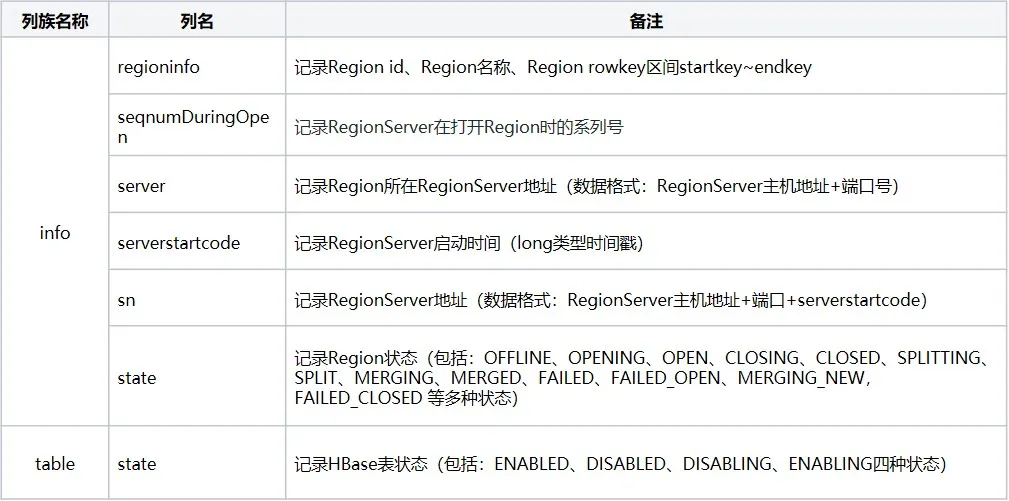
2.2 메타테이블 로딩 과정
위의 메타 테이블 구조를 통해 우리는 테이블에 대해 전반적으로 이해하게 되었으며, HBase 운영 및 유지 관리를 해본 친구들은 모두 이러한 경험을 가지고 있다고 믿습니다. 잘못된 작업입니다. 메타테이블 로딩이 중단되어 후속 프로세스를 계속 실행할 수 없습니다. 메타 테이블 로딩 프로세스에 대해 전반적으로 이해했다면 각 클러스터 시작 시간에 대한 심리적 기대는 어느 정도 있을 것입니다. 다음은 메타 테이블 로딩과 관련된 프로세스입니다.
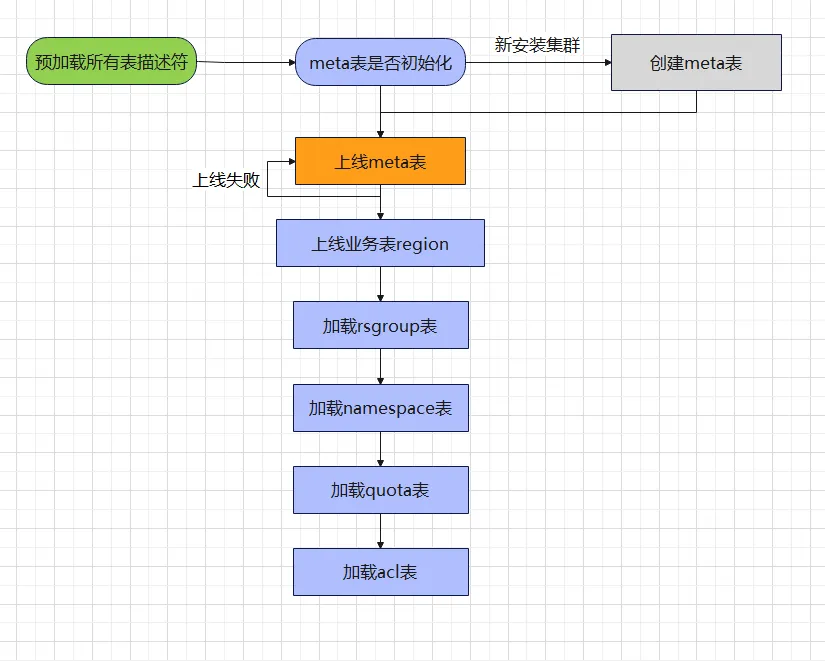
위의 메타 테이블 로딩 흐름도를 통해 일부 클러스터가 느리게 시작되고 일부 클러스터가 시작되지 않는 이유를 쉽게 확인할 수 있습니다. 아래에서는 두 가지 유형의 시나리오를 분석합니다.
- 클러스터가 느리게 시작됩니다.
일반적으로 새 클러스터나 테이블이 적은 클러스터는 더 빨리 시작되는 경향이 있지만 테이블이 많은 클러스터는 훨씬 느리게 시작되는 경향이 있습니다. 일부 클러스터는 때로는 클러스터 시작 시간이 길어서 의심스럽습니다. 클러스터에 문제가 있나요? 왜 그렇게 오랫동안 정상 상태로 들어갈 수 없나요? 전체 로딩 과정에서 시간이 오래 걸리는 곳이 두 군데 있습니다.
모든 테이블 디스크립터 미리 로드 : 전체 HBase 데이터 디렉터리를 스캔하고 .tabledesc 디렉터리 아래의 데이터 파일을 구문 분석하여 테이블 수가 많은 경우(테이블 10,000개 이상) 이 프로세스를 자주 수행해야 합니다. 약 10분 정도 소요됩니다. HMaster 페이지에 "Pre-loading table descriptors"라는 단어가 나타나면 클러스터가 사전 로드 단계에 있다는 의미입니다. 아직 메타 테이블 로딩 단계가 아니기 때문입니다. 도달했다.
온라인 비즈니스 테이블 영역 : 메타 테이블 데이터 크기는 일반적으로 수십 MB에서 수백 MB 사이이며, 클러스터 시작 단계에서 영역 열기 시간이 비교적 빠릅니다. 열기 속도를 높이려면 master.executor.openregion.threads(기본값 5) 값을 적절하게 조정할 수 있습니다.
- 클러스터 시작 실패:
메타 테이블 온라인 오류 : 기본 리소스 그룹의 HRegionServer가 중단되고 다시 시작한 후 시스템의 시작 코드가 변경되면 메타 데이터 샤드가 열린 노드를 찾을 수 없어 클러스터 시작에 실패하게 됩니다.
3. 메타테이블 복구 방법
HBase 클러스터의 상태는 주로 메타 테이블을 통해 유지되기 때문에 메타 테이블이 손상되거나 잘못된 경우 HBase 클러스터를 사용할 수 없게 되어 데이터 손실의 위험이 있습니다. 메타테이블의 데이터 일관성이 매우 중요하다는 것을 알고 있는데, 어떤 상황에서 데이터 불일치가 발생하게 될까요? (HBase 2.4.8 복구 명령의 경우 hbase-operator-tools 도구를 참조하세요.)
-
RegionServer가 다운되거나 비정상인 경우 : RegionServer가 다운되거나 비정상인 경우 메타 테이블에 저장된 Region 및 RegionServer 정보가 부정확하거나 손실될 수 있습니다.
-
데이터 손상 또는 오류 : 메타 테이블의 데이터가 손상되거나 부정확할 경우 HBase 클러스터 사용 불가 및 데이터 손실이 발생할 수 있습니다.
-
불법적인 연산 : 메타테이블에 있는 데이터를 삭제하거나 수정하는 등 불법적인 연산을 메타테이블에 수행할 경우 메타테이블의 오류나 손실이 발생할 수 있습니다.
메타테이블 장애는 일반적인 용어일 뿐이며, 그 유형에 따라 크게 장기 RIT, Region Hole, Region Overlap, 테이블 설명 파일 손실, 메타테이블 hdfs 경로 비어 있음, 메타테이블 데이터 손실 등으로 나눌 수 있습니다. 이러한 유형의 결함을 각각 분석하고 수정하겠습니다.
3.1 RIT
RIT(Region In Transition)는 HBase 클러스터에서 진행 중인 상태 전환을 나타냅니다. 다음 작업을 수행하면 HBase 클러스터의 지역 상태가 변경됩니다. 예를 들어 RegionServer가 다운되고 지역이 분할, 병합되고 있습니다. 기타 작업 지역 상태에는 주로 다음과 같은 12가지 상태와 변환 다이어그램이 포함됩니다.
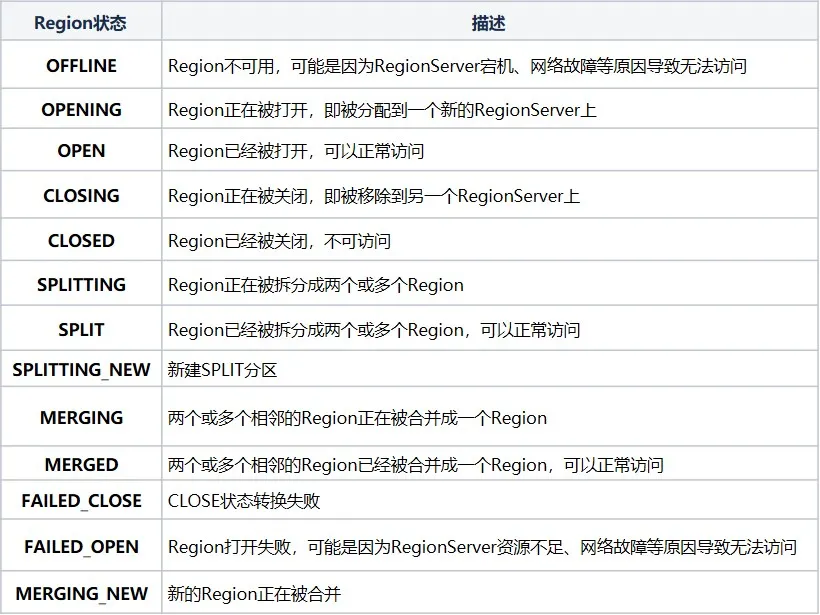
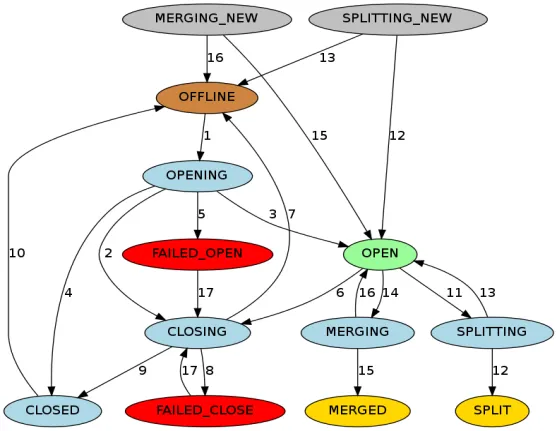
Region 상태를 보다 명확하게 하기 위해 작업 유형에 따라 할당, 할당 취소, 분할, 병합으로 나눌 수 있습니다. RegionServer가 다운되거나 비정상적이거나 작업 중에 데이터가 손상되거나 오류가 발생하는 경우 RIT는 HBase 운영 및 유지 관리 문제에서 RIT가 자주 발생하지만 기본 논리가 명확하면 RIT 문제를 처리하기가 더 쉽습니다. HBase 클러스터에는 수동 개입 없이 정상적으로 복원할 수 있습니다. RIT가 장기간 발생할 때만 개입이 필요합니다. 그렇다면 RIT의 장기 시간은 무엇입니까? 장기 RIT가 발생하는 이유는 무엇입니까?
HBase 1.x 및 HBase 2.x 버전을 사용했다면 HBase 2.x에서는 RIT가 덜 일반적이라는 것을 분명히 느낄 것입니다. 실제로 Region의 작업은 주로 AssignmentManager 클래스를 통해 Region을 전송하는 것입니다. 두 버전의 코드에서 시도 매개변수(할당 재시도 횟수)의 기본값이 두 버전에서 다르다는 것을 발견했습니다. HBase 2.4.8의 재시도 횟수는 최대 정수 정수입니다. .MAX_VALUE(HBase 1.x에서는 기본값이 10임) 이것이 HBase에서 장기 RIT 이유가 2.x에서 상대적으로 드문 이유입니다.
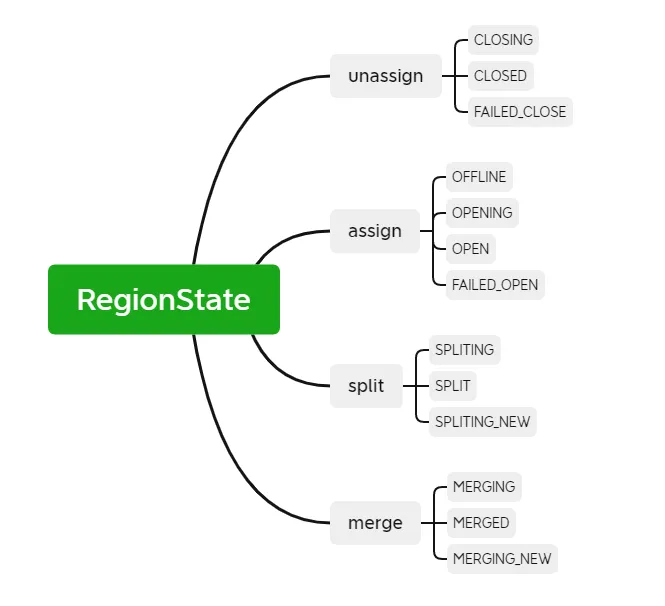
RIT 처리 방법:
-
대규모 테이블을 생성하거나 삭제할 때 RIT가 발생합니다. 이는 주로 리전 수가 많고 클러스터에 대한 높은 압력으로 인해 할당 및 할당 해제 응답 시간이 길어지기 때문에 일반적으로 HBase에는 수동이 필요하지 않습니다. 개입하면 스스로 치유될 수 있습니다.
-
클러스터 버전이 1.x인 경우 hbase.location.maximum.attempts 값을 적절하게 조정하여 재시도 횟수를 늘릴 수 있습니다. 예를 들어 FAILED_OPEN 및 FAILED_CLOSE는 일반적으로 자체 복구되거나 할당 명령을 수동으로 실행하여 각 항목을 할당할 수 있습니다. 지역 온라인(지역이 많은 경우 HMaster 수리로 전환)
-
Region 할당이 실패하고 RegionServer가 없는 경우 수동 할당을 복원할 수 없습니다. 예를 들어 Region은 bogus.example.com에 할당되고 노드 1과 1은 HMaster를 전환해야만 복원할 수 있습니다.
생각해 볼 질문:
수동 개입 후에도 리전이 정상적으로 온라인 상태가 되지 않는 이유는 무엇이며, HMaster를 전환하면 복원할 수 있습니까? (HMaster 시작 프로세스 TransitRegionStateProcedure, HMaster 클래스 소스 코드 참조)
3.2 지역 홀
HBase 테이블을 생성할 때 Region 규칙을 주의 깊게 분석하면 Region 시작 키와 끝 키가 왼쪽에서 닫히고 오른쪽에서 열리는 연속 간격에 속한다는 사실에 놀랄 것입니다. 갑자기 하나가 발생하면 어떤 문제가 발생합니까? 아래에 표시된 것처럼 이러한 간격이 누락되었습니까?
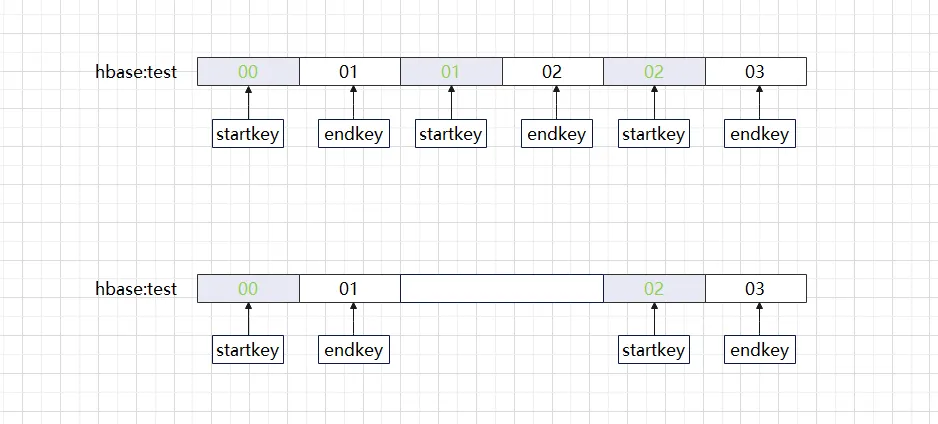
위의 상황은 우리가 흔히 지역에 구멍이라고 부르는 상황입니다. HBase hbck 도구를 사용하여 확인하면 오류 메시지 ERROR: 01과 02 사이에 구멍이 있습니다. 구멍을 막기 위한 hdfs의 새로운 .regioninfo 및 지역 디렉토리 HBase 클러스터에 구멍이 나타나면 종종 스스로 치료할 수 없으며 정상으로 돌아가려면 수동 개입이 필요합니다. 빈칸에 Region만 채우면 충분할까요? 일반적인 접근 방식은 먼저 빈 리전을 다시 추가하고 메타 테이블 정보가 올바른지 확인한 후 마지막으로 해당 리전과 온라인 상태로 전환하는 것입니다. 이 일련의 작업을 수동으로 수행하면 오류가 발생하기 쉬울 뿐만 아니라 시간도 걸립니다. 오랜 시간이 걸렸습니다. HBase 복구 방법은 실제로 버전마다 처리 방법이 약간 다르지만 처리 과정은 동일합니다.
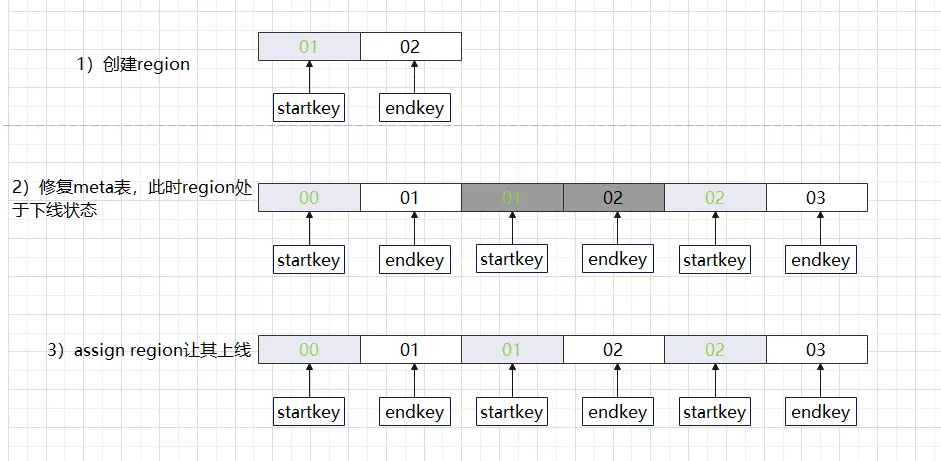
영역 홀 처리 방법:
(1) HBase 1.x 복구 방법
-
HBase hbck –fixHdfsHoles : hdfs에 빈 영역 파일 경로 생성
-
HBase hbck -fixMeta : Region이 위치한 메타 테이블 데이터를 복구합니다.
-
HBase hbck –fixAssignments : 온라인 복구 후 지역
-
또는 HBase hbck –repairHoles는 (fixHdfsHoles, fixMeta, fixAssignments)의 조합과 동일합니다.
(2) HBase 2.4.8 복구 방법(나중에 hbase-operator-tools 도구 참조)
HBase 2.4.8은 Region 디렉터리 작업을 추가하기 위한 관련 명령을 제공하지 않기 때문에 실제로 HBase 2.4.8의 많은 도구 클래스는 hbase-server-2.4의 HBaseTestingUtility 클래스와 지역 생성을 위한 메서드를 제공합니다. 8개 테스트 패키지는 이를 제공합니다. 지역 관련 입구를 운영하기 위해 아래의 솔루션은 주로 이 방법을 기반으로 한 복구에 중점을 둡니다.
-
extraRegionsInMeta -fix : 먼저 메타 테이블의 hdfs 디렉터리에 존재하지 않는 레코드를 삭제합니다.
-
HBaseTestingUtility.createLocalHRegion : 지역 연속성을 보장하기 위해 hdfs 파일 경로를 생성합니다.
-
addFsRegionsMissingInMeta : 메타 테이블에 새로운 Region 정보를 추가합니다. (추가 성공 후 Region ID가 반환됩니다.)
-
할당 : 마지막으로 새로 추가된 지역을 온라인에 추가합니다.
3.3 지역 중복
지역에 구멍이 있으므로 동일한 시작 키와 끝 키가 여러 개 있습니까? 대답은 '예'입니다. 여러 지역의 시작 키와 끝 키가 동일한 지역인 경우 이 상황을 겹치는 지역이라고 합니다. 영역 중첩은 HBase에서 시뮬레이션하기 어렵고 처리하기도 어려운 문제입니다. hbck 확인을 하면 이런 종류의 로그가 나타납니다. 오류: 여러 지역의 시작 키가 동일합니다: 02

또 다른 유형의 중첩 영역은 하나 또는 두 개의 인접한 샤드의 rowkey 범위와 교차합니다. 이러한 유형의 문제를 집합적으로 중첩 문제라고 합니다. 이 보다 어려운 시나리오에서는 자체 개발 도구를 사용하여 중첩 문제의 재발을 시뮬레이션합니다. 한 번의 클릭으로 겹침(접기) 및 구멍(구멍) 문제.
중복 문제 시뮬레이션 기능
Regionoverlap의 문제는 실제로 두 개의 다른 Region이 겹치는 것입니다. 예를 들어 Region01의 시작 키와 끝 키는 (01,03)이고 다른 Region02의 범위는 (01,02)입니다. 두 지역이 교차하는 경우(01,02), hbck 감지는 중첩 문제를 보고합니다.
생산 환경에서는 영역이 분할되고 동시에 기계가 끊기는 경우에만 겹침 문제가 발생합니다. 조건이 상대적으로 가혹하고 문제를 재현하기가 어렵기 때문에 후속 문제를 재현하는 것이 중요합니다. 수리 및 결함 훈련. 중복 문제 재생산 원리:
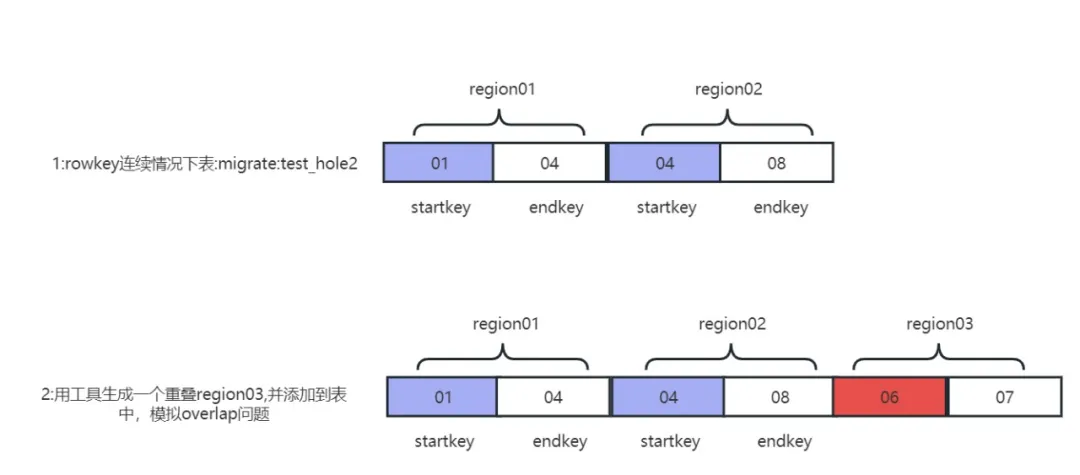
중복 문제 재발
1) rowkey 범위가 겹치는 지역 샤드를 생성합니다.
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=createRegion -DRegion.startkey=06 -DRegion.endkey=07 hbase-meta-tool-0.0.1.jar
2) 겹침 문제 영역을 테이블 디렉터리로 이동합니다.
sudo -uhdfs hdfs dfs -mv /tmp/.tmp/data/migrate/test_hole2/c8662e08f6ae705237e390029161f58f /hbase/data/migrate/test_hole2
3) 일반 테이블 migration:test_hole2의 메타 테이블 정보를 삭제합니다.
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
4) 중복 문제 테이블 메타데이터 정보를 재구성합니다.
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
5) 클러스터를 다시 시작한 후 hbck는 지역이 c8662e08f6ae705237e390029161f58f와 겹쳤다고 보고했고, 겹침 문제가 성공적으로 재현되었습니다.

방법 1: 한 번의 클릭으로 겹치는 부분과 구멍을 복구합니다.
접기 수가 64개를 초과하지 않는 경우에 적합하며 자체 개발 도구인 hbase-meta-tool을 사용하여 인접 영역의 범위를 rowkey 교차점과 병합하고 구멍이 있거나 범위가 누락된 경우 새 영역을 생성할 수 있습니다. 문제는 수리될 수 있습니다. 문제 수리의 원리는 그림과 같습니다.
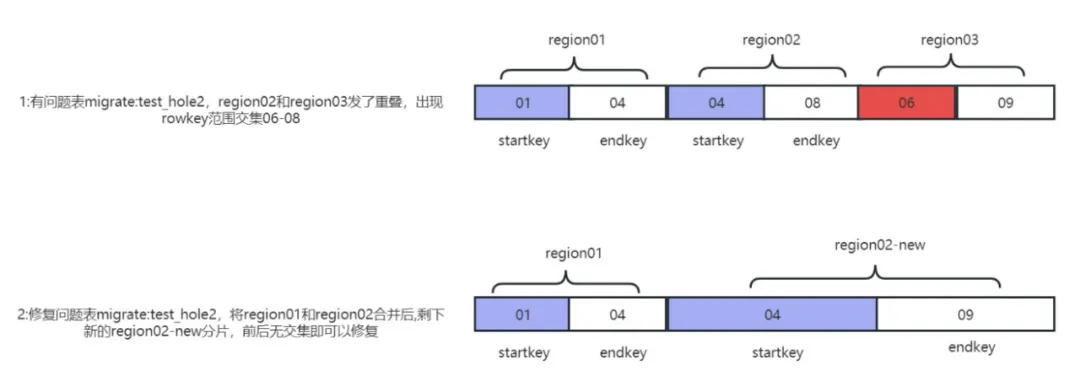
1) 클러스터 겹침 및 구멍 문제 수정:
java -jar -Dfix.operator= fixOverlapAndHole hbase-meta-tool-0.0.1.jar
방법 2: 대규모 접이식 수리
수천, 수만 건 이상의 대규모 폴딩에 적합하며 서버 측 이상 수리를 위해 다음과 같은 수리 방법을 사용하십시오.
1) 한 번의 클릭으로 접기 문제가 있는 테이블의 메타데이터를 지웁니다.
java -jar -Drepair.tableName=migrate:test1 -Dzookeeper.address=zkAddress -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) 원본 테이블 데이터를 백업합니다.
hdfs dfs -mv /hbase/data/migrate/test/ /back
3) 원본 테이블을 삭제하고 각 지역 샤드에 대한 백업 데이터를 가져옵니다.
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /back/test/region01-regionN migrate:test1
3.4 메타테이블 데이터 복구
HBase 온라인 클러스터에서는 다음과 같은 어려운 문제가 발생할 수 있습니다.
-
코프로세서 테이블이 잘못 구성되어 있고, 코프로세서 경로를 찾을 수 없으며, 지역을 로드하는 동안 jar를 찾을 수 없어 클러스터가 반복적으로 중단되고 drop 명령으로 이를 삭제할 수 없습니다.
-
HBase 메타 테이블의 요소 개수가 잘못되었거나, 시작 코드가 잘못되었거나, 온라인 프로세스 중에 서버의 테이블을 찾을 수 없으며, 테이블이 온라인 상태가 되지 않습니다.
클러스터의 다른 테이블 서비스에 영향을 주지 않고 서비스를 중단하지 않고 문제 테이블을 독립적으로 복구해야 합니다.
문제 테이블의 메타데이터 복구
1) migration:test1 테이블에 문제가 있다고 가정하면 한 번의 클릭으로 문제 테이블 메타데이터를 삭제할 수 있습니다.
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) 한 번의 클릭으로 hdfs 테이블의 .regioninfo 폴더 내용을 읽고 올바른 메타데이터를 재구성합니다.
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
3.5 메타 깨짐
위 5가지 상황은 모두 메타테이블이 정상적으로 온라인 상태라는 전제 하에 복구됩니다. 메타테이블 데이터가 손상되어 온라인 상태가 되지 않는 경우 어떻게 복구해야 할까요? 일반적으로 우리는 메타 테이블을 재구축한 다음 지역 정보를 메타 테이블에 쓰는 것을 생각합니다. 클러스터가 오프라인인 경우 일반적으로 HBase 셸 또는 HBase API가 테이블을 빌드하기 위해 create를 실행할 수 없습니다.
메타 테이블 초기화 클래스 InitMetaProcedure를 분석한 결과 메타 테이블 생성 프로세스가 대략 두 단계로 나누어져 있음을 확인했습니다.
1) 지역 디렉터리와 .tabledesc 파일을 만듭니다.
2) 지역을 할당하고 온라인 상태로 전환합니다.
InitMetaProcedure 핵심 소스 코드:
InitMeta프로시저
protected Flow executeFromState(MasterProcedureEnv env, InitMetaState state) throws ProcedureSuspendedException, ProcedureYieldException, InterruptedException {
try {
switch (state) {
case INIT_META_WRITE_FS_LAYOUT:
Configuration conf = env.getMasterConfiguration();
Path rootDir = CommonFSUtils.getRootDir(conf);
TableDescriptor td = writeFsLayout(rootDir, conf);
env.getMasterServices().getTableDescriptors().update(td, true);
setNextState(InitMetaState.INIT_META_ASSIGN_META);
return Flow.HAS_MORE_STATE;
case INIT_META_ASSIGN_META:
addChildProcedure(env.getAssignmentManager().createAssignProcedures(Arrays.asList(RegionInfoBuilder.FIRST_META_RegionINFO)));
return Flow.NO_MORE_STATE;
default:
throw new UnsupportedOperationException("unhandled state=" + state);
}
} catch (IOException e) {
}
private static TableDescriptor writeFsLayout(Path rootDir, Configuration conf) throws IOException {
LOG.info("BOOTSTRAP: creating hbase:meta region");
FileSystem fs = rootDir.getFileSystem(conf);
Path tableDir = CommonFSUtils.getTableDir(rootDir, TableName.META_TABLE_NAME);
if (fs.exists(tableDir) && !fs.delete(tableDir, true)) {
LOG.warn("Can not delete partial created meta table, continue...");
}
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(conf, fs, rootDir);
HRegion.createHRegion(RegionInfoBuilder.FIRST_META_RegionINFO, rootDir, conf, metaDescriptor, null).close();
return metaDescriptor;
}
InitMetaProcedure 코드 로직을 참조하여 테이블을 생성하고 온라인 상태로 전환하는 해당 도구를 작성할 수 있습니다. 메타 테이블이 온라인 상태가 된 후에는 각 테이블의 지역 정보를 메타에 쓰고 모든 지역을 온라인 상태로 할당하여 정상 상태로 복원하면 됩니다. 클러스터의 상태. 위의 과정을 통해 메타 테이블 복구 과정이 그리 복잡하지 않다는 것을 알 수 있었습니다. 그러나 프로덕션 환경에 테이블 수가 많거나 개별 대형 테이블에 수천 개의 영역이 있는 경우에는 수동으로 추가하는 데 시간이 많이 걸립니다. 지금까지 비교적 간단했던 솔루션(HBase 1.x hbck 도구, HBase 2.x hbase-operator-tools) 프로세스를 아래에서 소개하겠습니다. 오프라인 복구 프로세스를 살펴보겠습니다.
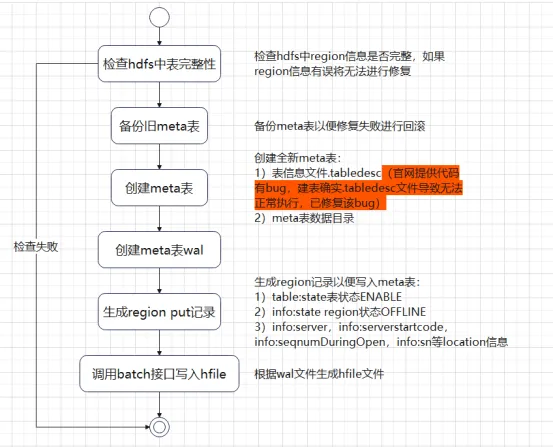
HBase 1.x 수정
-
HBase 클러스터 중지
-
sudo -u hbase hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair -fix
-
복구를 완료하려면 클러스터를 다시 시작하세요.
HBase 2.4.8 복구 방법(hbase-operator-tools 도구)
1) hdfs 경로를 기반으로 메타 테이블 자동 생성
-
HBase 클러스터 중지
-
sudo -u hbase hbase org.apache.hbase.hbck1.OfflineMetaRepair -fix
-
복구를 완료하려면 클러스터를 다시 시작하세요.
2) 싱글 테이블 수리 방법
-
사육사에서 HBase 루트 디렉터리 삭제
-
HMaster 및 RegionServer가 있는 hdfs WALs 디렉터리를 삭제합니다.
-
클러스터를 다시 시작하면 메타에 데이터가 없어 클러스터가 정상 상태로 들어갈 수 없습니다.
-
add Region 명령을 실행하여 hbase:namespace, hbase:quota, hbase:rsgroup 및 hbase:acl 4자 테이블을 클러스터에 추가합니다. 추가가 완료되면 로그에 Regions(지역)와 할당 및 이러한 테이블이 인쇄됩니다. . 다음 할당 작업을 위해 이러한 지역을 기록해야 합니다.
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-tools.jar addFsRegionsMissingInMeta hbase:namespace hbase:quota hbase:rsgroup hbase:acl
- 이전 단계에서 온라인으로 인쇄 영역을 추가하세요.
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-hbck2.jar assigns regionid
- 비즈니스 테이블이 온라인 상태입니다(비즈니스 테이블을 점진적으로 온라인으로 전환하려면 4-5단계만 반복하면 됩니다).
지침
(비즈니스 테이블에 많은 영역이 있고 다섯 번째 영역이 할당되지 않은 경우 모든 영역이 성공적으로 온라인 상태가 될 수 없습니다. 정상적으로 온라인 상태가 되려면 성능을 비활성화했다가 활성화해야 합니다.)
참고: hbase-operator-tools OfflineMetaRepair 도구에는 수정해야 할 다음과 같은 버그가 있습니다.
1. HBaseFsck createNewMeta 메소드로 생성된 메타 테이블에 .tabledesc 파일이 없습니다.
수정하기 전에:
TableDescriptor td = new FSTableDescriptors(getConf()).get(TableName.META_TABLE_NAME);
수정 후:
FileSystem fs = rootdir.getFileSystem(conf);
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(getConf(), fs, rootdir);
2. HBaseFsck generatePuts의 기본 리전 상태는 HMaster가 다시 시작될 때 OFFLINE 상태에서만 온라인 상태가 되므로 CLOSED입니다(CLOSED인 경우 수동으로 하나씩 온라인으로 전환하는 작업량이 매우 큽니다).
수정하기 전에:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.CLOSED);
수정 후:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.OFFLINE);
결점
1) 오프라인 복구를 수행하려면 클러스터 서비스를 중지해야 합니다. 중지 시간은 복구 시간(약 10~15분)에 따라 다릅니다.
2) 영역 중복, 홀 등의 문제가 있는 경우 OfflineMetaRepair 오프라인 복구 명령을 실행하기 전에 수동으로 처리해야 합니다.
4. hbase-operator-tools 도구
hbase-operator-tools는 HBase 관리자가 HBase 클러스터를 관리하고 유지하는 데 도움을 주는 HBase의 도구 세트입니다. hbase-operator-tools는 백업 및 복구 도구, 지역 관리 도구, 데이터 압축 및 이동 도구 등을 포함한 일련의 도구를 제공하여 관리자가 HBase 클러스터를 더 잘 관리하고 클러스터의 안정성과 신뢰성을 향상시키는 데 도움이 됩니다. 소스 코드를 사용하려면 먼저 컴파일해야 합니다. 소스 코드는 git 주소입니다 . 일반적인 명령은 다음과 같습니다.
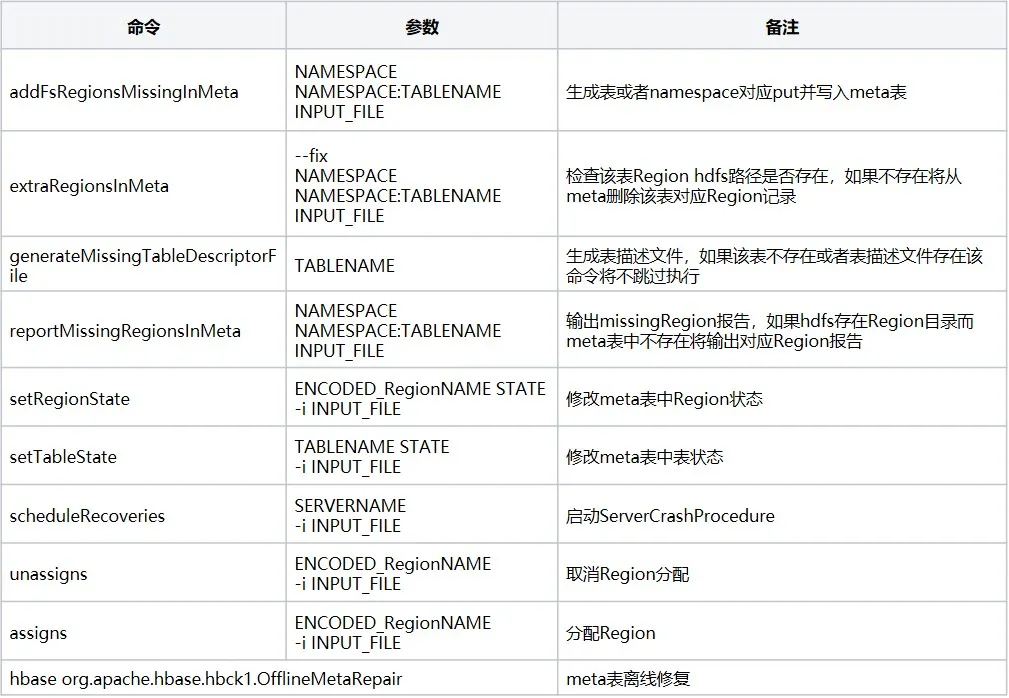
5. 요약
HBase 메타 테이블의 데이터 정확성은 HBase 클러스터의 정상적인 작동에 매우 중요합니다. 메타 테이블 데이터가 올바른지 확인하는 방법과 데이터가 손상된 경우 이를 신속하게 복구하는 방법은 매우 중요합니다. 메타를 포괄적으로 이해하면 클러스터가 실패할 때마다 손실을 입게 됩니다. 이 기사에서는 주로 메타 테이블 구조 로딩 프로세스, 일반적인 문제 및 관련 복구 방법에 대한 분석에 중점을 두고 있습니다. 위의 복구 방법은 대략 다음 두 가지 범주로 나눌 수 있습니다.
-
온라인 복구 : 데이터 무결성을 보장하기 위해 hbck 및 자체 개발 툴을 통해 메타테이블을 정상적으로 복구할 수 있습니다.
-
오프라인 복구 : 메타테이블이 정상적으로 온라인 상태가 될 수 없습니다. HDFS의 Region 정보를 기반으로 메타테이블을 재구성하여 HBase 서비스를 복원합니다.
클러스터 규모가 상대적으로 크고 오프라인 복구 시간이 상대적으로 긴 경우 클러스터는 장기간 서비스를 중지해야 합니다. 대부분의 경우 비즈니스에서는 실제 상황에 따라 이를 수행할 수 없습니다. 메타 테이블 파일이 손상되어 정상적으로 온라인 상태가 될 수 없는 경우를 제외하고 정기적으로 클러스터에서 hbck 검사를 수행하는 것이 좋습니다. 메타 정보 불일치가 발생하면 문제 확산을 피하기 위해 가능한 한 빨리 복구하십시오. 메타 정보가 엉망이 되어 클러스터가 다시 시작되고 엉망인 리전이 할당되지 않으면 다른 리전이 정상적으로 온라인 상태가 될 수 없습니다.) 정기 검사 결과 비즈니스 테이블에 메타 정보가 엉망인 것으로 확인되면 메타 테이블은 테이블 정보를 삭제하고 hdfs 경로 정보를 기반으로 메타 테이블에 지역을 다시 추가합니다. addFsRegions-MissingInMeta 명령은 hdfs 경로를 기반으로 메타 테이블에 지역을 올바르게 추가할 수 있습니다.
참고 기사:
고등학생들이 성인식으로 자신만의 오픈소스 프로그래밍 언어를 만든다 - 네티즌들의 날카로운 논평: 애플은 방어에 의존해 만연한 사기로 인해 국내 서비스가 중단됐다 . 앞으로는 윈도 플랫폼 타오바오(taobao.com)에서 독립 게임을 제작할 계획이다. 웹 버전 최적화 작업을 다시 시작해 프로그래머들의 종착지, 비주얼 스튜디오 코드 1.89에서 가장 많이 쓰이는 자바 LTS 버전인 자바 17이 출시되고, 윈도 10에는 시장 점유율 70%, Windows 11은 계속해서 하락 중