
MySQL 연결의 메모리 사용량을 시각화하는 방법을 알아보세요.
저자 : 벤자민 디킨
이 기사와 표지의 출처: https://planetscale.com/blog/, Axon 오픈 소스 커뮤니티에서 번역됨.
이 글은 3,000단어 정도이며 읽는 데 10분 정도 걸릴 것으로 예상됩니다.
소개
모든 소프트웨어의 성능을 고려할 때 시간과 공간 사이에는 일반적인 균형이 있습니다. MySQL 쿼리 성능을 평가하는 과정에서 우리는 종종 쿼리 성능의 주요 지표로 실행 시간(또는 쿼리 대기 시간)에 중점을 둡니다. 궁극적으로 우리는 가능한 한 빨리 쿼리 결과를 얻고 싶기 때문에 이는 사용하기에 좋은 측정항목입니다.
저는 최근 실행 시간과 행 읽기 측면에서 낮은 성능을 측정하는 데 초점을 맞춘 문제가 있는 MySQL 쿼리를 식별하고 분석하는 방법 에 대한 블로그 게시물을 게시했습니다 . 그러나 이 논의에서는 메모리 소비가 거의 무시되었습니다.
자주 필요하지는 않더라도 MySQL에는 쿼리에 사용되는 메모리 양과 해당 메모리의 용도에 대한 통찰력을 제공하는 내장 메커니즘도 있습니다. 이 기능을 자세히 살펴보고 MySQL 연결의 메모리 사용량을 실시간으로 모니터링할 수 있는 방법을 살펴보겠습니다.
메모리 통계
MySQL에는 개별적으로 계측할 수 있는 시스템 구성 요소가 많이 있습니다. 표 performance_schema.setup_instruments에는 각 구성 요소가 나열되어 있으며 그 중 상당수가 다음과 같습니다.
SELECT count(*) FROM performance_schema.setup_instruments;
+----------+
| count(*) |
+----------+
| 1255 |
+----------+
이 표에는 메모리 분석에 사용할 수 있는 다양한 도구가 포함되어 있습니다. 사용 가능한 항목을 보려면 표에서 선택하고 로 필터링해 보세요 memory/.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%';
수백 개의 결과가 표시됩니다. 이들 각각은 서로 다른 메모리 범주를 나타내며 MySQL에서 개별적으로 감지할 수 있습니다. 이러한 범주 중 일부에는 documentation해당 메모리 범주가 무엇을 나타내거나 사용되는지 설명하는 짧은 단락이 포함되어 있습니다 . null이 아닌 값이 있는 메모리 유형만 보려면 다음을 documentation실행하면 됩니다.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%'
AND documentation IS NOT NULL;
이러한 각 메모리 클래스는 여러 가지 세분성으로 샘플링될 수 있습니다. 다양한 수준의 세분성이 여러 테이블에 저장됩니다.
SELECT table_name
FROM information_schema.tables
WHERE table_name LIKE '%memory_summary%'
AND table_schema = 'performance_schema';
+-----------------------------------------+
| TABLE_NAME |
+-----------------------------------------+
| memory_summary_by_account_by_event_name |
| memory_summary_by_host_by_event_name |
| memory_summary_by_thread_by_event_name |
| memory_summary_by_user_by_event_name |
| memory_summary_global_by_event_name |
+-----------------------------------------+
- memory_summary_by_account_by_event_name: 계정별 메모리 이벤트 요약(계정은 사용자와 호스트의 조합)
- memory_summary_by_host_by_event_name: 호스트 세분성에서 메모리 이벤트를 요약합니다.
- memory_summary_by_thread_by_event_name: MySQL 스레드 단위로 메모리 이벤트를 요약합니다.
- memory_summary_by_user_by_event_name: 사용자 단위로 메모리 이벤트 요약
- memory_summary_global_by_event_name: 메모리 통계의 전역 요약
각 쿼리 수준에서는 메모리 사용량을 구체적으로 추적할 수 없습니다. 그러나 이것이 쿼리의 메모리 사용량을 분석할 수 없다는 의미는 아닙니다. 이를 달성하기 위해 관심 있는 쿼리를 실행하는 모든 연결에서 메모리 사용량을 모니터링할 수 있습니다. 따라서 memory_summary_by_thread_by_event_nameMySQL 연결과 스레드 간의 편리한 매핑이 있기 때문에 테이블 사용에 중점을 둘 것입니다 .
연결의 목적 찾기
이 시점에서 명령줄에서 MySQL 서버에 대한 두 개의 별도 연결을 설정해야 합니다. 첫 번째는 메모리 사용량을 모니터링하려는 쿼리를 실행하는 쿼리입니다. 두 번째는 모니터링 목적으로 사용됩니다.
첫 번째 연결에서 다음 쿼리를 실행하여 연결 ID와 스레드 ID를 가져옵니다.
SET @cid = (SELECT CONNECTION_ID());
SET @tid = (SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=@cid);
그런 다음 이러한 값을 가져옵니다. 물론 귀하의 모습은 여기에서 보는 것과 다를 수 있습니다.
SELECT @cid, @tid;
+------+------+
| @cid | @tid |
+------+------+
| 49 | 89 |
+------+------+
다음으로 메모리 사용량을 분석하려는 장기 실행 쿼리를 실행합니다. 이 예에서는 1억 행이 있는 테이블에서 대규모 작업을 수행하려고 합니다. aliasSELECT 열에 인덱스가 없기 때문에 시간이 좀 걸립니다.
SELECT alias FROM chat.message ORDER BY alias DESC LIMIT 100000;
이제 실행하는 동안 다른 콘솔 연결로 전환하고 다음 명령을 실행하여 스레드 ID를 연결의 스레드 ID로 바꿉니다.
SELECT
event_name,
current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = YOUR_THREAD_ID
ORDER BY current_number_of_bytes_used DESC
세부 사항은 쿼리와 데이터에 따라 크게 달라지지만 다음과 유사한 결과가 표시됩니다.
+---------------------------------------+------------------------------+
| event_name | current_number_of_bytes_used |
+---------------------------------------+------------------------------+
| memory/sql/Filesort_buffer::sort_keys | 203488 |
| memory/innodb/memory | 169800 |
| memory/sql/THD::main_mem_root | 46176 |
| memory/innodb/ha_innodb | 35936 |
...
이는 이 쿼리를 실행할 때 각 범주에서 사용되는 메모리 양을 나타냅니다. 다른 쿼리를 실행하는 동안 이 쿼리를 여러 번 실행 하면 SELECT alias...쿼리의 메모리 사용량이 실행 전체에서 일정할 필요가 없기 때문에 다른 결과가 나타날 수 있습니다. 이 쿼리를 실행할 때마다 특정 시점의 샘플을 나타냅니다. 따라서 시간이 지남에 따라 사용량이 어떻게 변하는지 이해하려면 많은 샘플을 채취해야 합니다.
memory/sql/Filesort_buffer::sort_keys이 (가) 테이블에 documentation없습니다 performance_schema.setup_instruments.
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory%sort_keys';
+---------------------------------------+---------------+
| name | documentation |
+---------------------------------------+---------------+
| memory/sql/Filesort_buffer::sort_keys | <null> |
+---------------------------------------+---------------+
그러나 이름은 파일의 데이터를 정렬하는 데 사용되는 메모리임을 나타냅니다. 이 쿼리 비용의 대부분은 데이터를 내림차순으로 표시할 수 있도록 정렬하는 것이므로 이는 의미가 있습니다.
시간 경과에 따른 사용량 수집
다음으로 시간 경과에 따른 메모리 사용량을 샘플링할 수 있어야 합니다. 이 쿼리는 한 번만 실행할 수 있거나 분석 쿼리를 실행하는 동안 적은 횟수만 실행할 수 있으므로 짧은 쿼리에는 그다지 유용하지 않습니다. 이는 오래 실행되는 쿼리(몇 초 또는 몇 분이 걸리는 쿼리)에 더 유용합니다. 그럼에도 불구하고 이러한 쿼리는 대부분의 메모리를 사용할 가능성이 높으므로 분석하려는 쿼리 유형입니다.
이는 전적으로 SQL로 구현될 수 있으며 저장 프로시저를 통해 호출될 수 있습니다. 그러나 이 경우 Python에서 별도의 스크립트를 사용하여 모니터링을 제공합니다.
#!/usr/bin/env python3
import time
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY current_number_of_bytes_used DESC LIMIT 4
'''
parser = argparse.ArgumentParser()
parser.add_argument('--thread-id', type=int, required=True)
args = parser.parse_args()
dbc = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
c = dbc.cursor()
ms = 0
while(True):
c.execute(MEM_QUERY, (args.thread_id,))
results = c.fetchall()
print(f'\n## Memory usage at time {ms} ##')
for r in results:
print(f'{r[0][7:]} -> {round(r[1]/1024,2)}Kb')
ms+=250
time.sleep(0.25)
이는 이러한 유형의 모니터링 스크립트에 대한 간단한 첫 번째 시도입니다. 요약하면 이 코드는 다음을 수행합니다.
- 명령줄을 통해 모니터링할 제공된 스레드 ID를 가져옵니다.
- MySQL 데이터베이스에 대한 연결 설정
- 250ms마다 쿼리를 실행하여 가장 많이 사용되는 4개의 메모리 범주를 가져오고 판독값을 인쇄합니다.
이는 분석 요구 사항에 따라 다양한 방식으로 조정될 수 있습니다. 예를 들어 서버에 대한 핑 빈도를 조정하거나 반복당 나열되는 메모리 클래스 수를 변경합니다. 쿼리를 실행하는 동안 이 명령을 실행하면 다음과 같은 결과가 제공됩니다.
...
## Memory usage at time 4250 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4500 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4750 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 5000 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
...
훌륭하지만 몇 가지 약점이 있습니다. 처음 4개의 메모리 사용량 범주를 넘어서는 것을 보는 것은 좋지만 그 숫자를 늘리면 이미 큰 출력 덤프의 크기가 커집니다. 시각화를 통해 좀 더 쉽게 메모리 사용량을 한눈에 파악할 수 있는 방법이 있으면 좋을 것 같습니다. 이는 스크립트가 결과를 CSV 또는 JSON으로 덤프한 다음 시각화 도우미에 로드하도록 하여 수행할 수 있습니다. 더 좋은 점은 데이터가 유입됨에 따라 실시간 결과를 표시할 수 있다는 것입니다. 이를 통해 업데이트된 보기를 제공하고 하나의 도구에서 실시간으로 발생하는 메모리 사용량을 관찰할 수 있습니다.
플롯 메모리 사용량
도구를 더욱 유용하게 만들고 시각화를 제공하기 위해 몇 가지 변경 사항이 적용됩니다.
- 사용자는 명령줄에 연결 ID를 제공하고 스크립트는 기본 스레드를 찾는 역할을 합니다.
- 스크립트가 메모리 데이터를 요청하는 빈도는 명령줄을 통해 구성할 수도 있습니다.
- 이
matplotlib라이브러리는 메모리 사용량의 시각화를 생성하는 데 사용됩니다. 여기에는 가장 높은 메모리 사용량 범주를 보여주는 범례가 있는 스택 플롯이 포함되며 지난 50개의 샘플이 유지됩니다.
이것은 꽤 많은 코드이지만 완전성을 위해 여기에 포함되었습니다.
#!/usr/bin/env python3
import matplotlib.pyplot as plt
import numpy as np
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY event_name DESC'''
TID_QUERY='''
SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=%s'''
class MemoryProfiler:
def __init__(self):
self.x = []
self.y = []
self.mem_labels = ['XXXXXXXXXXXXXXXXXXXXXXX']
self.ms = 0
self.color_sequence = ['#ffc59b', '#d4c9fe', '#a9dffe', '#a9ecb8',
'#fff1a8', '#fbbfc7', '#fd812d', '#a18bf5',
'#47b7f8', '#40d763', '#f2b600', '#ff7082']
plt.rcParams['axes.xmargin'] = 0
plt.rcParams['axes.ymargin'] = 0
plt.rcParams["font.family"] = "inter"
def update_xy_axis(self, results, frequency):
self.ms += frequency
self.x.append(self.ms)
if (len(self.y) == 0):
self.y = [[] for x in range(len(results))]
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
self.y[i].append(usage)
if (len(self.x) > 50):
self.x.pop(0)
for i in range(len(self.y)):
self.y[i].pop(0)
def update_labels(self, results):
total_mem = sum(map(lambda e: e[1], results))
self.mem_labels.clear()
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
mem_type = results[i][0]
# Remove 'memory/' from beginning of name for brevity
mem_type = mem_type[7:]
# Only show top memory users in legend
if (usage < total_mem / 1024 / 50):
mem_type = '_' + mem_type
self.mem_labels.insert(0, mem_type)
def draw_plot(self, plt):
plt.clf()
plt.stackplot(self.x, self.y, colors = self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.xlabel("milliseconds since monitor began")
plt.ylabel("Kilobytes of memory")
def configure_plot(self, plt):
plt.ion()
fig = plt.figure(figsize=(12,5))
plt.stackplot(self.x, self.y, colors=self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.tight_layout(pad=4)
return fig
def start_visualization(self, database_connection, connection_id, frequency):
c = database_connection.cursor();
fig = self.configure_plot(plt)
while(True):
c.execute(MEM_QUERY, (connection_id,))
results = c.fetchall()
self.update_xy_axis(results, frequency)
self.update_labels(results)
self.draw_plot(plt)
fig.canvas.draw_idle()
fig.canvas.start_event_loop(frequency / 1000)
def get_command_line_args():
'''
Process arguments and return argparse object to caller.
'''
parser = argparse.ArgumentParser(description='Monitor MySQL query memory for a particular connection.')
parser.add_argument('--connection-id', type=int, required=True,
help='The MySQL connection to monitor memory usage of')
parser.add_argument('--frequency', type=float, default=500,
help='The frequency at which to ping for memory usage update in milliseconds')
return parser.parse_args()
def get_thread_for_connection_id(database_connection, cid):
'''
Get a thread ID corresponding to the connection ID
PARAMS
database_connection - Database connection object
cid - The connection ID to find the thread for
'''
c = database_connection.cursor()
c.execute(TID_QUERY, (cid,))
result = c.fetchone()
return int(result[0])
def main():
args = get_command_line_args()
database_connection = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
connection_id = get_thread_for_connection_id(database_connection, args.connection_id)
m = MemoryProfiler()
m.start_visualization(database_connection, connection_id, args.frequency)
connection.close()
if __name__ == "__main__":
main()
이를 통해 MySQL 쿼리 실행에 대한 자세한 모니터링을 수행할 수 있습니다. 이를 사용하려면 먼저 분석하려는 연결의 연결 ID를 가져옵니다.
SELECT CONNECTION_ID();
그런 다음 다음 명령을 실행하면 모니터링 세션이 시작됩니다.
./monitor.py --connection-id YOUR_CONNECTION_ID --frequency 250
데이터베이스에 대해 쿼리를 실행할 때 메모리 사용량의 증가를 관찰하고 어떤 범주가 메모리에 가장 많이 기여하는지 확인할 수 있습니다.
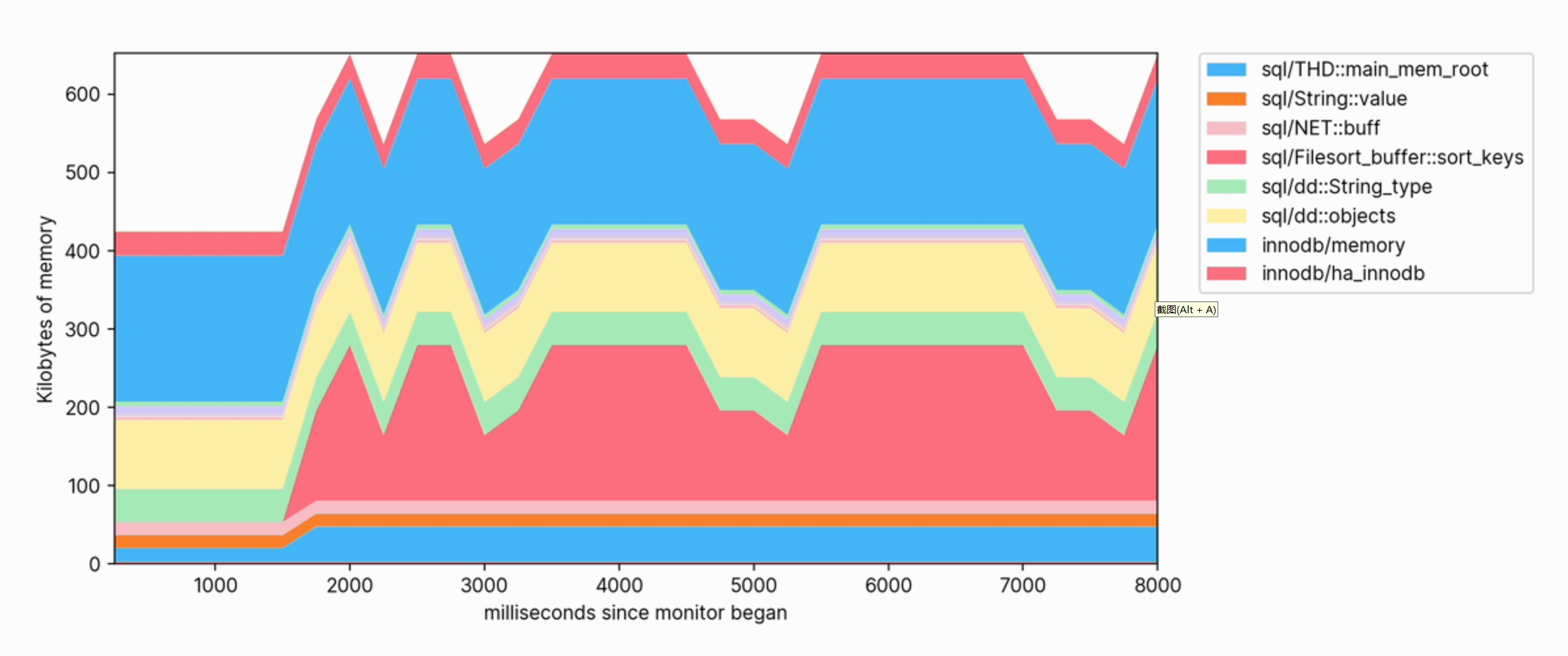
또한 이 시각화를 통해 어떤 작업이 메모리를 소비하는지 명확하게 확인할 수 있습니다. 예를 들어, 다음은 대규모 테이블에 FULLTEXT 인덱스를 생성하는 데 사용되는 메모리 프로필의 일부입니다.
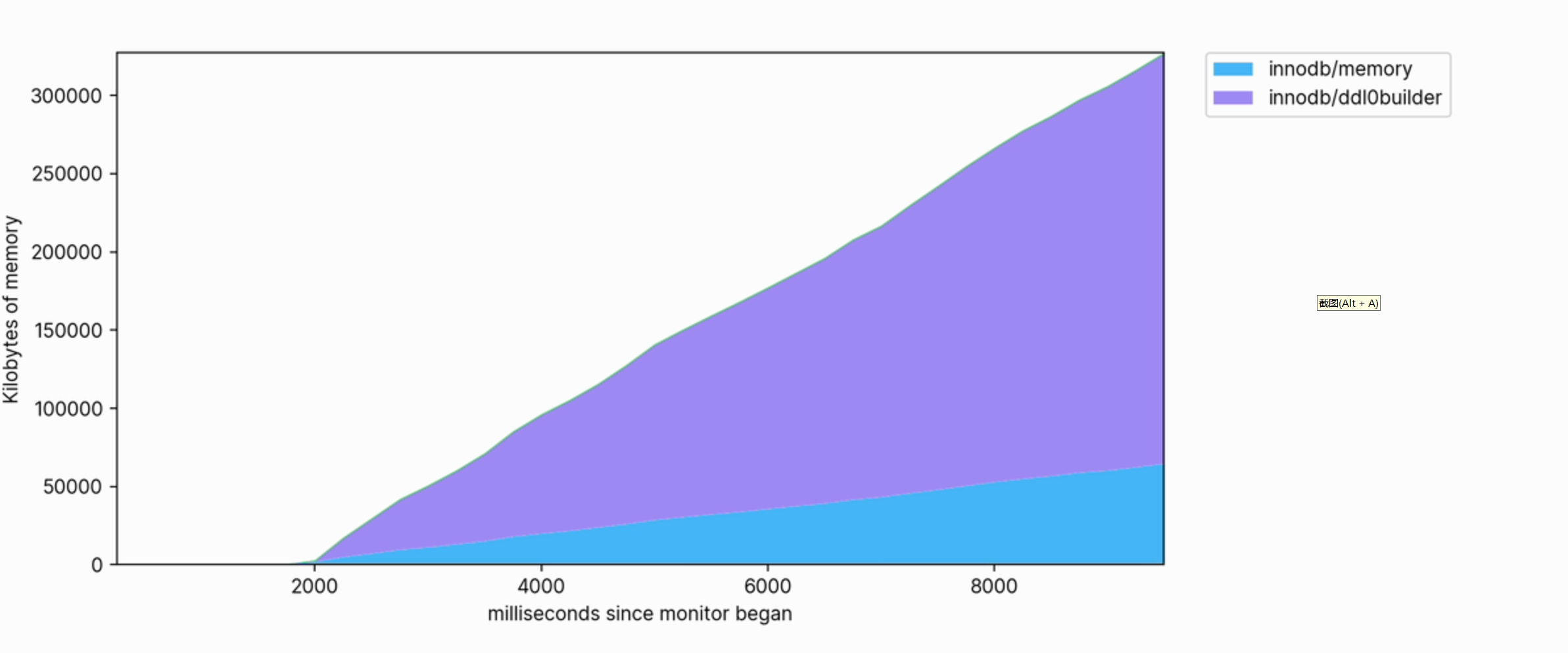
메모리 사용량이 많고 실행 시 수백 메가바이트를 사용하도록 계속 증가합니다.
결론적으로
자주 필요하지는 않더라도 자세한 메모리 사용량 정보를 얻는 기능은 상세한 쿼리 최적화가 필요할 때 매우 유용할 수 있습니다. 이를 통해 MySQL이 시스템에 메모리 압박을 가하는 시기와 이유, 또는 데이터베이스 서버에 메모리 업그레이드가 필요한지 여부를 밝힐 수 있습니다. MySQL은 쿼리 및 워크로드에 대한 분석 도구를 개발할 수 있는 다양한 기본 요소를 제공합니다.
더 많은 기술 기사를 보려면 https://opensource.actionsky.com/을 방문하세요.
SQLE 소개
SQLE는 개발부터 프로덕션 환경까지 SQL 감사 및 관리를 포괄하는 포괄적인 SQL 품질 관리 플랫폼입니다. 주류 오픈소스, 상용 및 국내 데이터베이스를 지원하고 개발, 운영 및 유지 관리를 위한 프로세스 자동화 기능을 제공하고 온라인 효율성을 향상시키며 데이터 품질을 향상시킵니다.