
검색 애플리케이션에서는 기존의 키워드 검색이 항상 주요 검색 방법이었습니다. 이는 정확한 일치 쿼리 시나리오에 적합하며 짧은 대기 시간과 우수한 결과 해석성을 제공할 수 있습니다. 그러나 키워드 검색은 문맥 정보를 고려하지 않으며 관련 없는 결과를 생성할 수 있습니다. 최근에는 벡터 검색 기술을 기반으로 한 검색 강화 기술인 시맨틱 검색(Semantic Search)이 점점 인기를 얻고 있으며, 머신 러닝 모델을 사용하여 데이터 객체(텍스트, 이미지, 오디오 및 비디오 등)를 벡터로 변환합니다. 객체 간의 유사성 사용된 모델이 문제 영역과 관련성이 높으면 컨텍스트와 검색 의도를 더 잘 이해할 수 있어 검색 결과의 관련성이 향상됩니다. 문제 영역에서는 효과가 크게 감소합니다.
키워드 검색과 의미 검색은 둘 다 분명한 장점과 단점을 갖고 있는데, 그 장점을 결합하면 검색의 전반적인 관련성을 높일 수 있을까요? 대답은 다음과 같은 두 가지 주요 이유로 인해 간단한 산술 조합으로는 예상한 결과를 얻을 수 없다는 것입니다.
-
첫째, 서로 다른 쿼리 유형의 점수는 동일한 비교 차원에 있지 않으므로 간단한 산술 계산을 직접 수행할 수 없습니다.
-
둘째, 분산 검색 시스템에서 점수는 일반적으로 샤드 수준에 있으며 모든 샤드의 점수는 전역적으로 정규화되어야 합니다.
요약하자면, 이러한 문제를 해결하기 위해서는 이상적인 쿼리 유형을 찾아야 하며, 각 쿼리 절을 개별적으로 실행하고, 샤드 수준에서 쿼리 결과를 수집하고, 최종적으로 모든 쿼리의 점수를 정규화하고 병합하여 최종 결과를 반환할 수 있습니다. 하이브리드 검색 솔루션입니다.
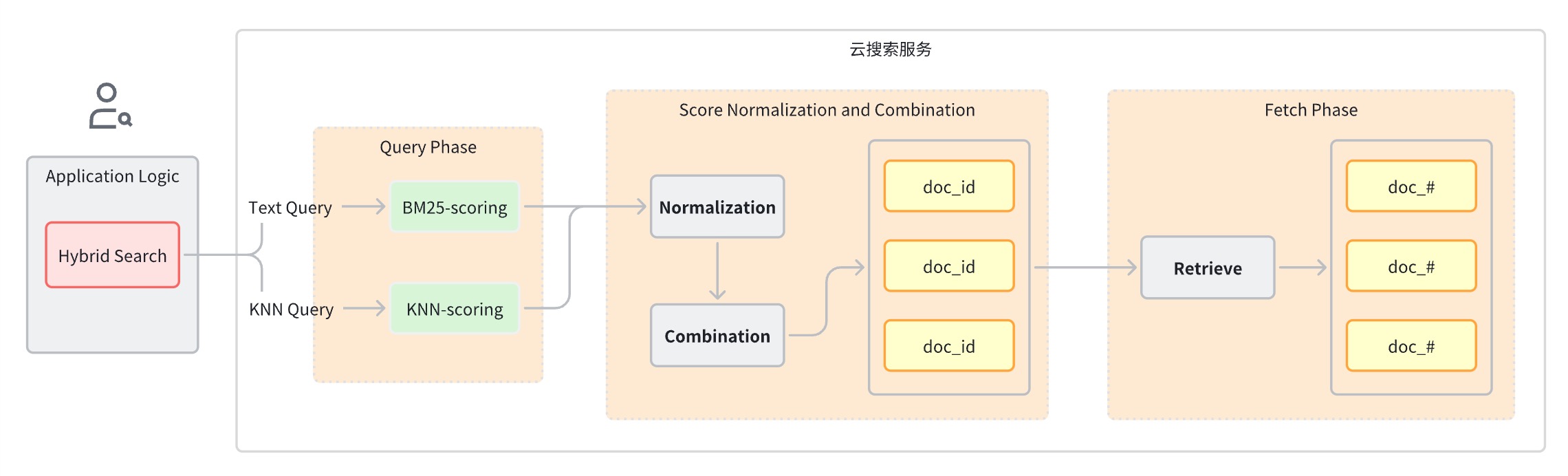
일반적으로 하이브리드 검색어는 다음 단계로 나눌 수 있습니다.
-
쿼리 단계: 키워드 검색 및 의미 검색에 혼합 쿼리 절을 사용합니다.
-
쿼리 단계 다음에 나오는 점수 정규화 및 병합 단계입니다.
-
각 쿼리 유형은 서로 다른 점수 범위를 제공하므로 이 단계에서는 각 쿼리 절의 점수 결과에 대해 정규화 작업을 수행합니다. 지원되는 정규화 방법은 min_max, l2 및 rrf입니다.
-
정규화된 점수를 결합하기 위해 결합 방법에는 arithmetic_mean, 기하학_평균, harmonic_mean이 포함됩니다.
-
-
문서는 통합된 등급에 따라 다시 정렬되어 사용자에게 반환됩니다.
구현 아이디어
이전 원칙의 도입을 통해 하이브리드 검색 애플리케이션을 구현하려면 최소한 이러한 기본 기술 시설이 필요하다는 것을 알 수 있습니다.
-
전체 텍스트 검색 엔진
-
벡터 검색 엔진
-
벡터 임베딩을 위한 기계 학습 모델
-
텍스트, 오디오, 비디오 및 기타 데이터를 벡터로 변환하는 데이터 파이프라인
-
융합 정렬
Volcano Engine 클라우드 검색은 오픈 소스 Elasticsearch 및 OpenSearch 프로젝트를 기반으로 구축되었으며 출시 첫날부터 완전하고 성숙한 텍스트 검색 및 벡터 검색 기능을 지원하는 동시에 일련의 기능적 반복도 수행했습니다. 하이브리드 검색 시나리오를 위한 진화로 즉시 작동하는 하이브리드 검색 솔루션을 제공합니다. 이 기사에서는 Volcano Engine 클라우드 검색 서비스 솔루션의 도움으로 하이브리드 검색 애플리케이션을 신속하게 개발하는 방법을 소개하기 위해 이미지 검색 애플리케이션을 예로 들어 보겠습니다.

엔드투엔드 프로세스는 다음과 같이 요약됩니다.
-
관련 객체 구성 및 생성
-
수집 파이프라인: 이미지 변환 벡터를 인덱스에 저장하는 모델 자동 호출을 지원합니다.
-
검색 파이프라인: 유사성 계산을 위해 텍스트 쿼리 문을 벡터로 자동 변환 지원
-
k-NN 인덱스: 벡터가 저장된 인덱스
-
-
이미지 데이터 세트 데이터를 OpenSearch 인스턴스에 쓰면 OpenSearch가 자동으로 기계 학습 모델을 호출하여 텍스트를 임베딩 벡터로 변환합니다.
-
클라이언트가 하이브리드 검색 쿼리를 시작하면 OpenSearch는 기계 학습 모델을 호출하여 들어오는 쿼리를 임베딩 벡터로 변환합니다.
-
OpenSearch는 하이브리드 검색 요청 처리를 수행하고 키워드 검색 및 의미 검색 점수를 결합하여 검색 결과를 반환합니다.
실제 전투를 계획하세요
환경 준비
-
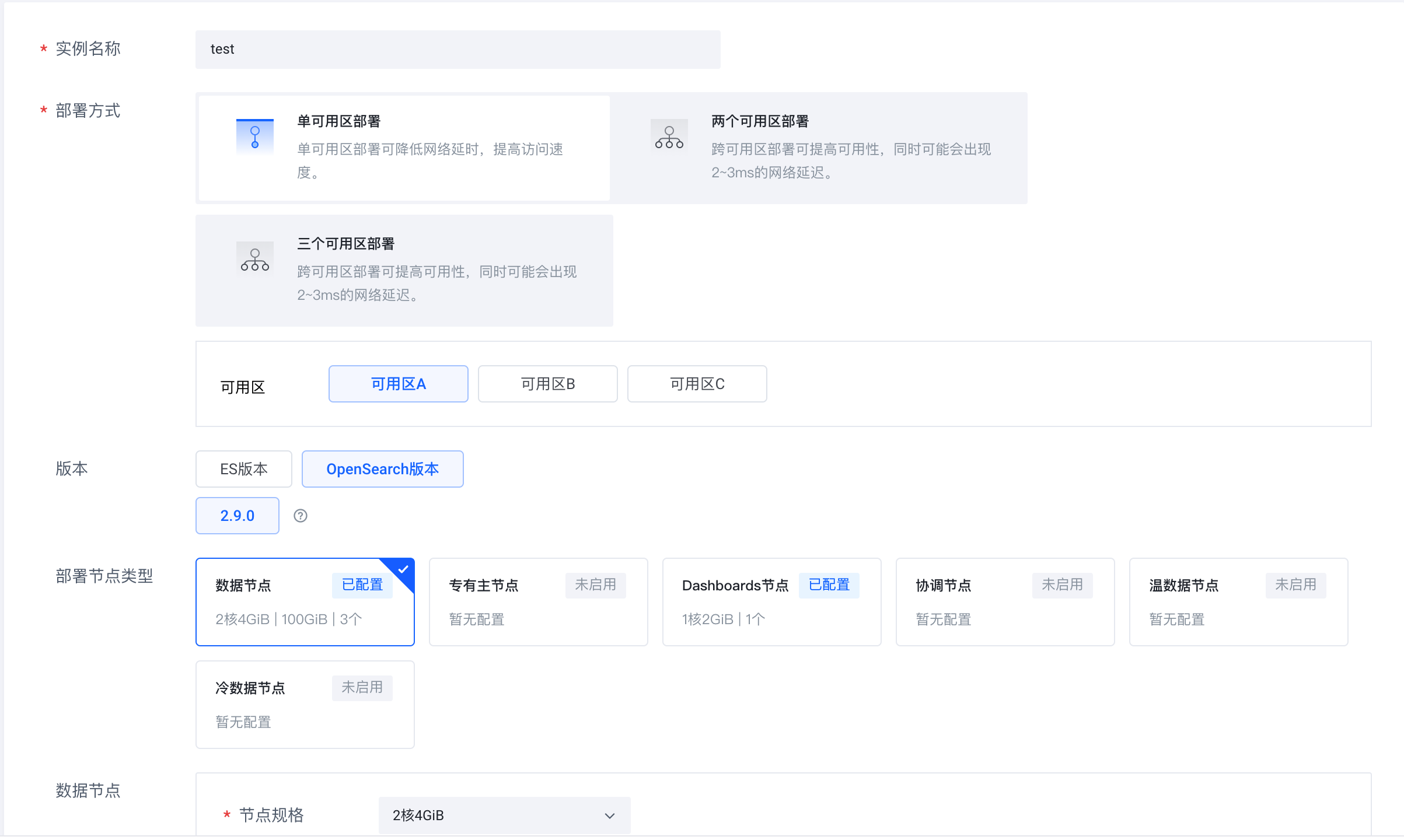
Volcano Engine 클라우드 검색 서비스(https://console.volcengine.com/es)에 로그인하고 인스턴스 클러스터를 생성한 후 버전으로 OpenSearch 2.9.0을 선택합니다.
-
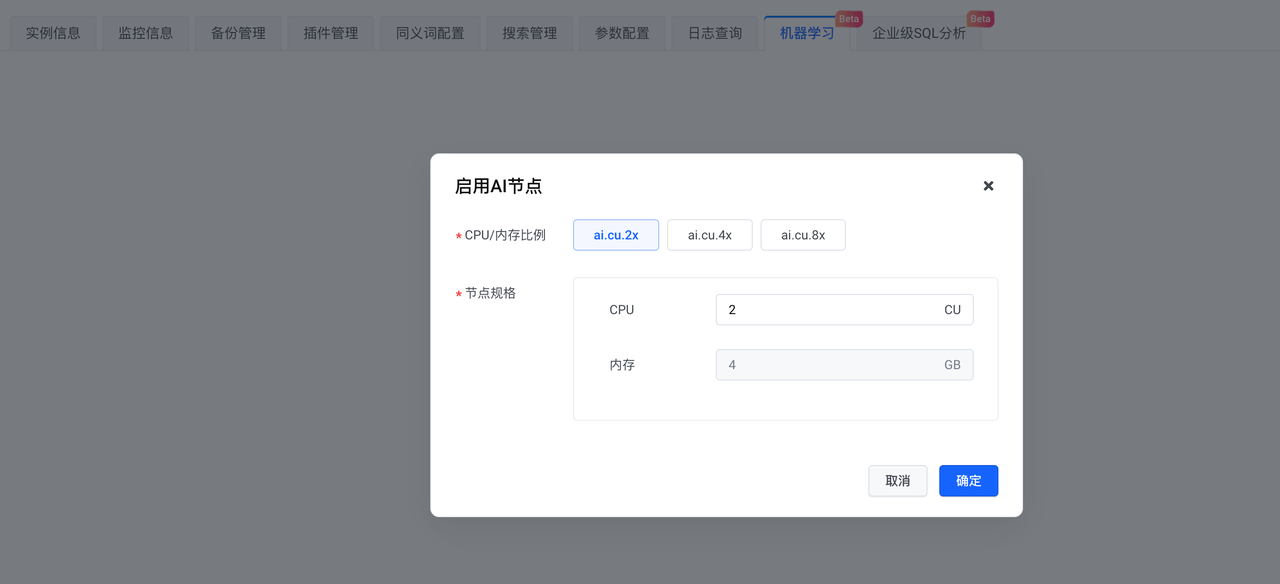
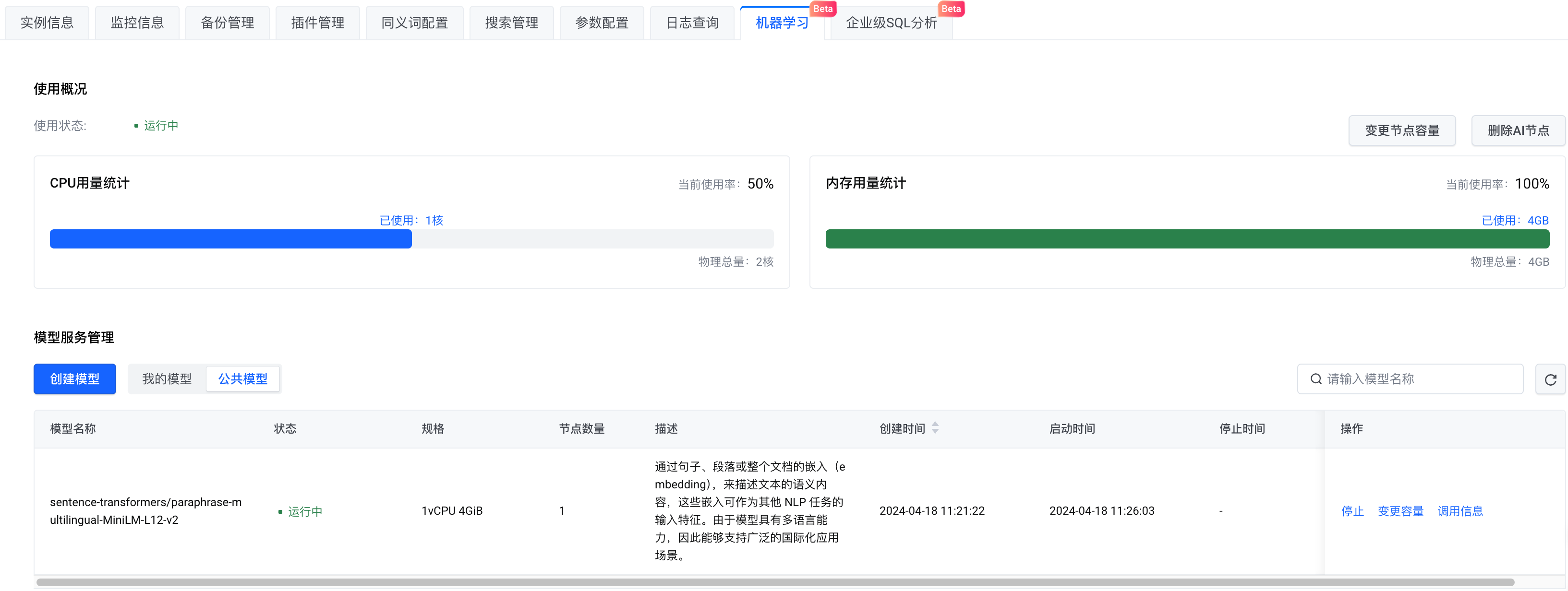
인스턴스가 생성된 후 AI 노드를 활성화합니다.
-
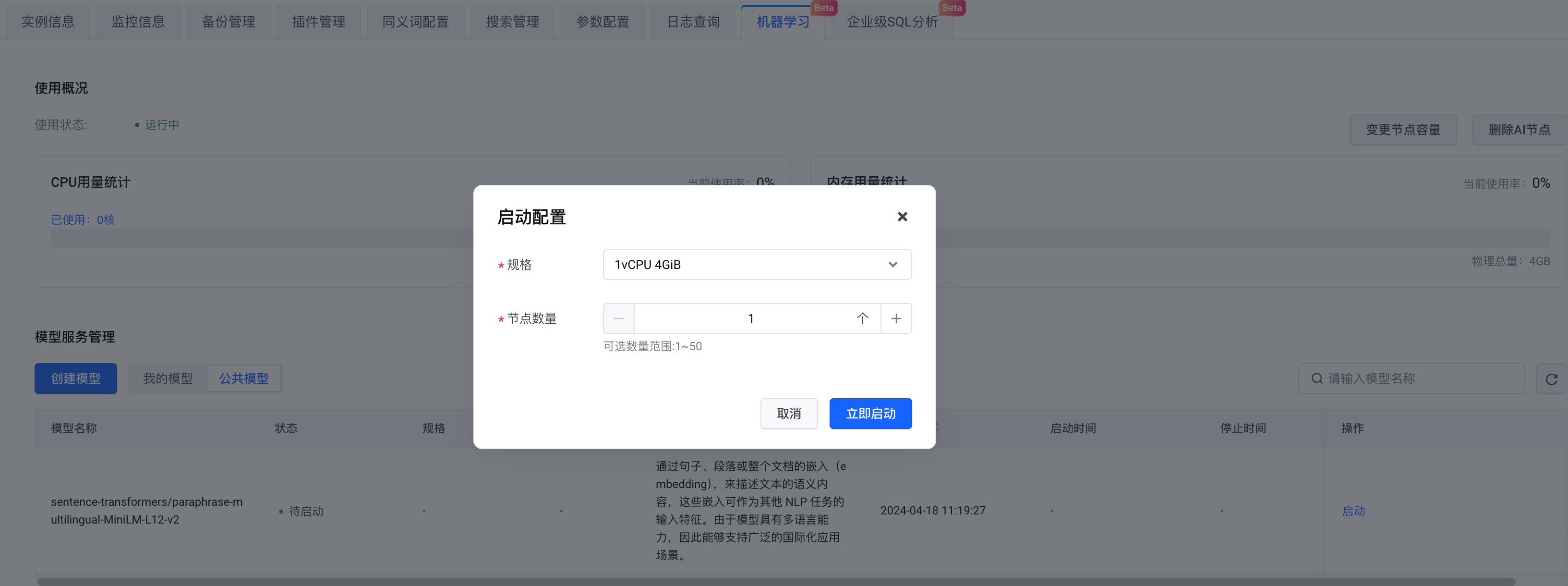
모델 선택 측면에서는 자체 모델을 만들거나 공개 모델을 선택할 수 있습니다. 여기에서는 공개 모델을 선택합니다 . 구성을 완료한 후 지금 시작을 클릭합니다 .
이제 하이브리드 검색이 사용하는 OpenSearch 인스턴스와 기계 학습 서비스가 준비되었습니다.
데이터 세트 준비
Amazon Berkeley Objects Dataset(https://registry.opendata.aws/amazon-berkeley-objects/)를 데이터 세트로 사용합니다. 데이터 세트는 로컬로 다운로드할 필요가 없으며 코드 로직을 통해 OpenSearch에 직접 업로드됩니다. 자세한 내용은 아래 코드 내용을 참조하세요.
단계
Python 종속성 설치
pip install -U elasticsearch7==7.10.1
pip install -U pandas
pip install -U jupyter
pip install -U requests
pip install -U s3fs
pip install -U alive_progress
pip install -U pillow
pip install -U ipython오픈서치에 연결
# Prepare opensearch info
from elasticsearch7 import Elasticsearch as CloudSearch
from ssl import create_default_context
# opensearch info
opensearch_domain = '{{ OPENSEARCH_DOMAIN }}'
opensearch_port = '9200'
opensearch_user = 'admin'
opensearch_pwd = '{{ OPENSEARCH_PWD }}'
# remote config for model server
model_remote_config = {
"method": "POST",
"url": "{{ REMOTE_MODEL_URL }}",
"params": {},
"headers": {
"Content-Type": "application/json"
},
"advance_request_body": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
}
}
# dimension for knn vector
knn_dimension = 384
# load cer and create ssl context
ssl_context = create_default_context(cafile='./ca.cer')
# create CloudSearch client
cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],
ssl_context=ssl_context,
scheme="https",
http_auth=(opensearch_user, opensearch_pwd)
)
# index name
index_name = 'index-test'
# pipeline id
pipeline_id = 'remote_text_embedding_test'
# search pipeline id
search_pipeline_id = 'rrf_search_pipeline_test'-
OpenSearch 링크 주소와 사용자 이름, 비밀번호 정보를 입력하세요. model_remote_config 는 원격 머신러닝 모델 연결 구성으로, 모델 호출 정보 에서 확인할 수 있습니다. 호출 정보 의 모든 remote_config 구성을 model_remote_config 에 복사합니다 .
-
인스턴스 정보- > 서비스 액세스 섹션 에서 인증서를 현재 디렉터리에 다운로드합니다.
-
인덱스 이름, 파이프라인 ID 및 검색 파이프라인 ID가 지정됩니다.
수집 파이프라인 생성
수집 파이프라인을 생성하고, 사용할 기계 학습 모델을 지정하고, 지정된 필드를 벡터로 변환하고 다시 포함시킵니다. 다음과 같이
캡션
필드를 벡터로 변환하고
caption_embedding
에 저장합니다 .
# Create ingest pipeline
pipeline_body = {
"description": "text embedding pipeline for remote inference",
"processors": [{
"remote_text_embedding": {
"remote_config": model_remote_config,
"field_map": {
"caption": "caption_embedding"
}
}
}]
}
# create request
resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)
print(resp)검색 파이프라인 생성
원격 모델 쿼리 및 구성에 필요한 파이프라인을 생성합니다.
지원되는 정규화 방법 및 가중 합계 방법:
-
정규화 방법:
min_max,l2,rrf -
가중합산 방법:
arithmetic_mean,geometric_mean,harmonic_mean
여기서는 rrf 정규화 방법이 선택됩니다.
# Create search pipeline
import requests
search_pipeline_body = {
"description": "post processor for hybrid search",
"request_processors": [{
"remote_embedding": {
"remote_config": model_remote_config
}
}],
"phase_results_processors": [ # normalization and combination
{
"normalization-processor": {
"normalization": {
"technique": "rrf", # the normalization technique in the processor is set to rrf
"parameters": {
"rank_constant": 60 # param
}
},
"combination": {
"technique": "arithmetic_mean", # the combination technique is set to arithmetic mean
"parameters": {
"weights": [
0.4,
0.6
]
}
}
}
}
]
}
headers = {
'Content-Type': 'application/json',
}
# create request
resp = requests.put(
url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,
auth=(opensearch_user, opensearch_pwd),
json=search_pipeline_body,
headers=headers,
verify='./ca.cer')
print(resp.text)k-NN 인덱스 생성
-
index.default_pipeline 필드 에 미리 생성된 수집 파이프라인을 구성합니다 .
-
동시에 속성을 구성하고 caption_embedding을 knn_Vector로 설정합니다. 여기서는 hnsw를 faiss로 사용합니다.
# Create k-NN index
# create index and set settings, mappings, and properties as needed.
index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 1,
"number_of_replicas": 0,
"default_pipeline": pipeline_id # ingest pipeline
},
"mappings": {
"properties": {
"image_url": {
"type": "text"
},
"caption_embedding": {
"type": "knn_vector",
"dimension": knn_dimension,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"caption": {
"type": "text"
}
}
}
}
# create index
resp = cloud_search_cli.indices.create(index=index_name, body=index_body)
print(resp)데이터세트 로드
데이터 세트를 메모리로 읽고 사용해야 하는 일부 데이터를 필터링합니다.
# Prepare dataset
import pandas as pd
import string
appended_data = []
for character in string.digits[0:] + string.ascii_lowercase:
if character == '1':
break
try:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",
lines=True)
except FileNotFoundError:
continue
appended_data.append(meta)
appended_data_frame = pd.concat(appended_data)
appended_data_frame.shape
meta = appended_data_frame
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()데이터 세트 업로드
데이터 세트를 Opensearch에 업로드하고 각 데이터에 대한 image_url 및 캡션을 전달합니다.
caption_embedding
을 전달할 필요가 없으며 원격 기계 학습 모델을 통해 자동으로 생성됩니다.
# Upload dataset
import json
from alive_progress import alive_bar
cnt = 0
batch = 0
action = json.dumps({"index": {"_index": index_name}})
body_ = ''
with alive_bar(len(dataset), force_tty=True) as bar:
for index, row in (dataset.iterrows()):
if row['path'] == '87/874f86c4.jpg':
continue
payload = {}
payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']
payload['caption'] = row['item_name_in_en_us']
body_ = body_ + action + "\n" + json.dumps(payload) + "\n"
cnt = cnt + 1
if cnt == 100:
resp = cloud_search_cli.bulk(
request_timeout=1000,
index=index_name,
body=body_)
cnt = 0
batch = batch + 1
body_ = ''
bar()
print("Total Bulk batches completed: " + str(batch))하이브리드 검색어
신발 쿼리를
예로 들어 보겠습니다 . 쿼리에는 두 개의 쿼리 절이 포함되어 있습니다. 하나는
match
쿼리이고 다른 하나는
remote_neural
쿼리입니다. 쿼리할 때 이전에 생성된 검색 파이프라인을 쿼리 매개변수로 지정합니다. 검색 파이프라인은 들어오는 텍스트를 벡터로 변환하고 후속 쿼리를 위해
caption_embedding 필드에 저장합니다.
# Search with search pipeline
from urllib import request
from PIL import Image
import IPython.display as display
def search(text, size):
resp = cloud_search_cli.search(
index=index_name,
body={
"_source": ["image_url", "caption"],
"query": {
"hybrid": {
"queries": [
{
"match": {
"caption": {
"query": text
}
}
},
{
"remote_neural": {
"caption_embedding": {
"query_text": text,
"k": size
}
}
}
]
}
}
},
params={"search_pipeline": search_pipeline_id},
)
return resp
k = 10
ret = search('shoes', k)
for item in ret['hits']['hits']:
display.display(Image.open(request.urlopen(item['_source']['image_url'])))
print(item['_source']['caption'])하이브리드 검색 디스플레이

위는 Volcano Engine 클라우드 검색 서비스 솔루션의 도움으로 하이브리드 검색 애플리케이션을 신속하게 개발하는 방법에 대한 실제 프로세스를 소개하기 위해 이미지 검색 애플리케이션을 예로 들어 Volcano Engine 콘솔에 로그인하여 작동하는 것을 환영합니다!
Volcano Engine 클라우드 검색 서비스는 Elasticsearch, Kibana 및 기타 소프트웨어와 일반적으로 사용되는 오픈 소스 플러그인과 호환되며 다중 조건 검색, 통계 및 구조화된 텍스트와 구조화되지 않은 텍스트에 대한 보고서를 제공하며 원클릭 배포, 탄력성을 달성할 수 있습니다. 확장, 단순화된 운영 및 유지 관리, 신속한 로그 구축, 분석, 정보 검색 분석 및 기타 비즈니스 기능을 제공합니다.
{{o.이름}}
{{이름}}