

외부 캐시는 대기 시간을 줄이는 데 탁월하지만 종종 이점보다 더 많은 문제를 야기합니다. 이 문제를 해결하는 방법은 다음과 같습니다.
팀이 외부 데이터베이스 캐시를 교체하는 이유와 방법 에서 Felipe Cardeneti Mendes가 번역했습니다 .
팀에서는 기존 데이터베이스가 필수 SLA(서비스 수준 계약)를 충족할 수 없을 때 외부 캐싱을 고려하는 경우가 많습니다. 이는 확실히 성과 지향적인 결정입니다. 다양한 요인(예: 비효율적인 데이터베이스 내부, 드라이버 사용, 인프라 선택, 트래픽 급증 등)으로 인해 발생하는 차선의 대기 시간을 보상하기 위해 데이터베이스 앞에 외부 캐시를 배치 하는 경우가 많습니다.
캐싱은 큰 번거로움과 데이터베이스 확장 , 데이터베이스 스키마 재설계 또는 심층적인 기술 전환 에 드는 상당한 비용을 발생시키지 않고 배포를 구현할 수 있으므로 빠르고 쉬운 솔루션인 것 같습니다 . 그러나 외부 캐싱은 흔히 말하는 것처럼 간단하지 않습니다. 이는 분산 애플리케이션 아키텍처에서 가장 문제가 되는 구성 요소 중 하나일 수 있습니다.
길고 비용이 많이 드는 계산으로 인해 변환된 데이터에 자주 액세스해야 하고 대기 시간을 줄이기 위해 다른 모든 방법을 시도한 경우와 같이 이는 필요악인 경우도 있습니다. 그러나 대부분의 경우 성능 향상은 그만한 가치가 없습니다. 한 가지 문제를 해결하고 다른 문제를 만듭니다.
외부 캐싱과 관련하여 자주 간과되는 위험과 세 팀이 핵심 데이터베이스와 외부 캐싱을 단일 솔루션으로 교체하여 성능 향상과 비용 절감을 달성한 방법은 다음과 같습니다. 스포일러: 그들은 특수한 내부 캐시를 활용하여 향상된 롱테일 대기 시간을 달성 하는 고성능 데이터베이스인 ScyllaDB를 사용합니다 .
왜 캐시하지 않습니까?
ScyllaDB에서는 기존 데이터베이스 성능 개선 시도의 비용, 번거로움 및 한계를 해결하기 위해 노력하는 수많은 팀과 협력하고 있습니다. 데이터베이스 앞에 외부 캐싱을 배치할 때 팀이 겪는 주요 어려움은 다음과 같습니다.
외부 캐싱으로 인해 대기 시간이 늘어납니다.
별도의 캐시는 도중에 한 번 더 점프하는 것을 의미합니다. 캐싱이 데이터베이스 주변에 있을 때 첫 번째 액세스는 캐시 계층에서 발생합니다. 데이터가 캐시에 없으면 요청이 데이터베이스로 전송됩니다. 이로 인해 캐시되지 않은 데이터에 대한 이미 느린 경로에 대기 시간이 추가됩니다. 전체 데이터 세트가 캐시에 맞으면 추가 대기 시간이 발생하지 않는다고 주장할 수도 있습니다. 그러나 데이터 세트가 상당히 작지 않은 한 모든 데이터를 메모리에 저장하면 비용이 크게 증가하여 대부분의 조직에서 엄청나게 많은 비용이 듭니다.
외부 캐싱은 추가 비용이 발생합니다.
캐싱은 고가의 DRAM을 의미하며, 이는 기가바이트당 비용이 솔리드 스테이트 디스크보다 높다는 것을 의미합니다. (자세한 내용은 P99 CONF에서 Grafana의 Danny Kopping 강연을 참조하세요 .) 캐싱을 위해 완전히 별도의 인프라를 프로비저닝하는 것보다 기존 데이터베이스 메모리를 사용하거나 내부 캐시를 수용할 수 있도록 메모리를 늘리는 것이 더 나은 경우가 많습니다. 크기를 올바르게 조정하면 최신 데이터베이스 캐시는 기존 인메모리 캐싱 솔루션만큼 효율적일 수 있습니다. 데이터베이스는 작업 세트 크기가 너무 커서 메모리에 맞지 않을 때 플래시 스토리지에 대한 I/O 액세스를 최적화하는 데 효과적인 경우가 많으므로 별도의 데이터베이스(외부 캐시 없음)가 선호되고 저렴한 옵션이 됩니다.
외부 캐싱으로 인해 가용성이 감소함
캐싱 고가용성 솔루션은 데이터베이스 자체에 필적할 수 없습니다. 최신 분산 데이터베이스에는 여러 개의 복제본이 있으며 토폴로지 및 속도를 인식하며 데이터 손실 없이 여러 번의 오류를 견딜 수 있습니다.
예를 들어 일반적인 복제 패턴은 3개의 로컬 복제본이며, 이를 통해 데이터베이스의 내부 캐싱 메커니즘을 효과적으로 활용하기 위해 이러한 복제본 간에 읽기 균형을 조정할 수 있는 경우가 많습니다. 복제 인수가 3인 9노드 클러스터를 생각해 보세요. 기본적으로 각 노드는 전체 데이터 세트 크기의 약 1/3을 보유합니다. 요청이 여러 복제본에 걸쳐 균형을 이루므로 데이터를 캐시할 수 있는 공간이 더 많아지고 외부 캐싱이 필요하지 않게 됩니다. 반대로 외부 캐시가 대량의 콜드 요청 직전에 항목을 무효화하는 경우 데이터베이스의 내부 캐시에 해당 데이터가 없기 때문에 일정 기간 동안 가용성에 영향을 미칠 수 있습니다(자세한 내용은 아래 참조).
캐시에는 고가용성 속성이 부족한 경우가 많으며 경험적 방법에 따라 레코드가 쉽게 실패하거나 무효화될 수 있습니다. 부분적인 실패는 일관성 측면에서 더 일반적이며 더 나쁩니다. 캐시가 필연적으로 실패하면 데이터베이스는 완화되지 않은 쿼리의 홍수로 인해 SLA를 위반할 수 있습니다. 게다가 캐시 자체에 고가용성 기능이 있더라도 앞에 있는 영구 데이터베이스를 사용하여 이러한 오류 처리를 조정할 수 없습니다. 결론 : 대기 시간 SLA를 캐시에 의존하는 대신 데이터베이스에 의존합니다.
애플리케이션 복잡성 – 애플리케이션이 더 많은 상황을 처리해야 합니다.
외부 캐싱으로 인해 애플리케이션과 운영이 복잡해졌습니다. 외부 캐시가 있으면 캐시를 데이터베이스와 함께 최신 상태로 유지하는 것은 귀하의 책임입니다. 캐싱 전략(예: 연속 기입, 캐시 우회 등)에 관계없이 캐시가 데이터베이스와 동기화되지 않을 수 있는 극단적인 경우가 있으므로 애플리케이션 개발 중에 이러한 상황을 고려해야 합니다. 캐시를 사용할 수 없거나 콜드 상태가 되었을 때 작동하려면 클라이언트 설정(예: 장애 조치, 재시도 및 시간 초과 정책)이 캐시 및 데이터베이스의 속성과 일치해야 합니다. 일반적으로 이러한 시나리오는 테스트하고 구현하기가 어렵습니다.
외부 캐시로 인해 데이터베이스 캐시가 손상됨
최신 데이터베이스에는 캐시가 내장되어 있으며 이를 관리하기 위한 복잡한 전략이 있습니다. 데이터베이스 앞에 캐시를 배치하면 대부분의 읽기 요청은 외부 캐시에만 도달하며 데이터베이스는 이러한 개체를 메모리에 보관하지 않습니다. 결과적으로 데이터베이스 캐시가 유효하지 않게 됩니다. 요청이 마침내 데이터베이스에 도달하면 해당 캐시는 콜드 상태가 되고 응답은 대부분 디스크에서 나옵니다. 결과적으로 캐시에서 데이터베이스로, 다시 애플리케이션으로의 왕복으로 인해 대기 시간이 늘어날 수 있습니다.
외부 캐싱은 보안 위험을 증가시킬 수 있습니다.
외부 캐싱은 인프라에 완전히 새로운 공격 표면을 추가합니다. 캐시에 있는 데이터에 대한 암호화, 격리 및 액세스 제어는 데이터베이스 계층 자체의 제어와 다를 수 있습니다.
외부 캐싱은 데이터베이스 지식과 데이터베이스 리소스를 무시합니다.
데이터베이스는 복잡하며 시스템의 특수 I/O 워크로드를 위해 구축되었습니다. 많은 쿼리가 동일한 데이터에 액세스하며 특정 양의 작업 세트 크기를 메모리에 캐시하여 디스크 액세스를 절약할 수 있습니다. 좋은 데이터베이스에는 캐시해야 하는 개체, 인덱스 및 액세스를 결정하는 복잡한 논리가 있어야 합니다. 또한 데이터베이스에는 새 데이터가 기존(이전) 캐시 개체를 대체해야 하는 시기를 결정하는 제거 정책이 있어야 합니다.
스캔 방지 캐싱이 한 예입니다. 대규모 범위 또는 전체 테이블 스캔과 같은 대규모 데이터 세트를 스캔할 때 디스크에서 많은 수의 개체를 읽습니다. 데이터베이스는 이것이 일반 쿼리가 아닌 스캔임을 인식하고 해당 개체를 내부 캐시에 보관하도록 선택할 수 있습니다. 그러나 읽기 정책을 따르는 외부 캐싱은 결과 집합을 다른 결과 집합처럼 처리하고 결과를 캐시하려고 시도합니다. 데이터베이스는 들어오는 요청 속도에 따라 캐시된 콘텐츠를 디스크와 자동으로 동기화하므로 사용자와 개발자는 최근에 작성된 데이터 조회의 성능과 일관성을 보장하기 위해 아무것도 할 필요가 없습니다. 따라서 어떤 이유로든 데이터베이스가 충분히 빠르게 응답하지 않는 경우 이는 다음을 의미합니다.
- 캐시 구성 오류입니다.
- 캐시용 RAM이 부족합니다.
- 작업 세트 크기 및 요청 패턴이 캐싱에 적합하지 않습니다.
- 데이터베이스 캐시 구현이 좋지 않습니다.
더 나은 옵션: 데이터베이스가 처리하도록 두십시오.
외부 데이터베이스 캐싱의 위험 없이 SLA를 충족하는 방법은 무엇입니까? 많은 팀은 더 빠른 데이터베이스(예: ScyllaDB)로 마이그레이션하고 전용 내부 캐시를 사용함으로써 덜 번거롭고 더 저렴한 비용으로 대기 시간 SLA를 충족할 수 있다는 것을 알고 있습니다. 물론 결과는 워크로드 특성과 기술 요구 사항에 따라 달라질 수 있습니다. 하지만 무엇이 가능한지, 이들 팀이 무엇을 달성할 수 있는지 생각해 보세요.
SecurityScorecard는 연간 100만 달러 절감으로 대기 시간을 90% 단축했습니다.
SecurityScorecard는 수천 개의 조직이 사이버 보안에 대해 이해하고, 완화하고, 소통하는 방식을 변화시켜 세상을 더욱 안전한 곳으로 만드는 것을 목표로 합니다. 평가 플랫폼은 조직의 전반적인 사이버 보안 및 사이버 위험 노출에 대한 객관적이고 데이터 중심적이며 정량화 가능한 척도입니다.
팀의 이전 데이터 아키텍처는 한동안 잘 작동했지만 성장을 따라잡을 수 없었습니다. 해당 플랫폼 API는 Redis(1,200만 개의 스코어카드를 더 빠르게 조회하기 위해), Aurora(노드 전체에 40억 개의 측정 통계를 저장하기 위해) 또는 Hadoop 분산 파일 시스템 Presto 클러스터(기록 결과에 대한 복잡한 SQL 쿼리를 위해)의 세 가지 데이터 저장소 중 하나를 쿼리합니다. ).
데이터와 요청이 증가함에 따라 문제가 발생합니다. Aurora 및 Presto는 높은 처리량에서 지연 시간이 급증하는 것을 경험합니다. Redis의 가능한 가장 큰 인스턴스는 여전히 충분하지 않았으며 Redis Cluster의 복잡성을 사용하고 싶지 않았습니다.
빠른 비즈니스 성장에 필요한 새로운 규모의 대기 시간을 줄이기 위해 팀은 ScyllaDB Cloud로 전환하고 대기 시간에 덜 민감한 요청을 Presto 및 S3 스토리지로 라우팅하는 새로운 채점 API를 개발했습니다. 다음은 이 아키텍처를 시각화한 것이며 매우 간단합니다.
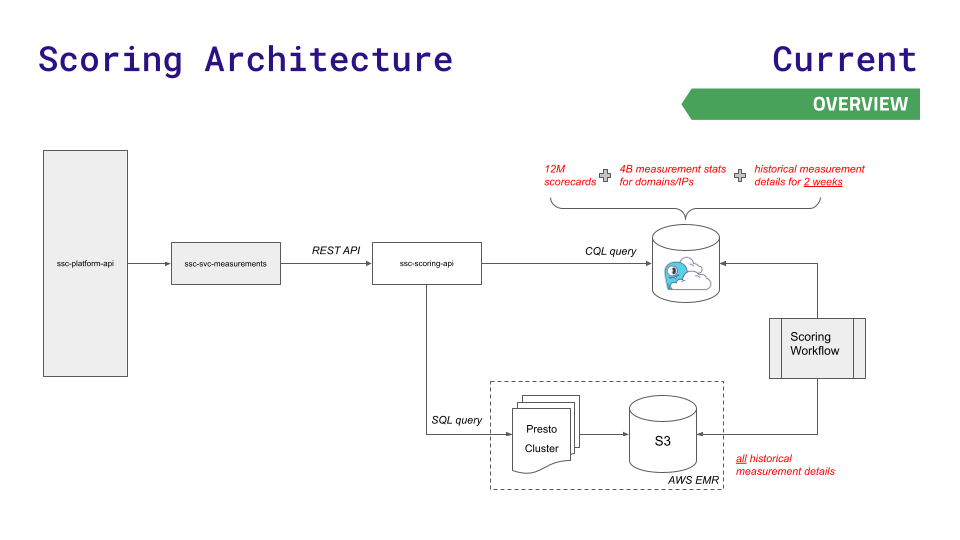
이 움직임의 결과는 다음과 같습니다.
- 대부분의 서비스 엔드포인트에서 대기 시간이 90% 단축됨
- Presto/Aurora 성능 관련 생산 사고 80% 감소
- 연간 인프라 비용 100만 달러 절감
- 데이터 파이프라인 처리 속도가 30% 증가했습니다.
- 고객 경험을 획기적으로 개선
[SecurityScorecard 사용 사례에 대해 자세히 알아보기]
IMVU는 Redis 비용을 100배로 줄였습니다.
IMVU는 데스크톱, 태블릿, 모바일 장치에서 3D 아바타를 사용하여 전 세계 사람들이 상호 작용할 수 있는 인기 있는 소셜 커뮤니티입니다. 증가하는 규모 요구 사항을 충족하기 위해 IMVU는 이전 데이터베이스 아키텍처(MySQL 및 Redis 앞의 Memcached)보다 더 높은 성능의 솔루션이 필요하다고 결정했습니다. 팀은 구성하기 쉽고, 확장하기 쉽고, (성공한 경우) 확장하기 쉬운 것을 찾았습니다.
IMVU의 수석 소프트웨어 엔지니어인 Ken Rudy는 "Redis는 프로토타입 기능에는 훌륭했지만 실제로 출시한 후에는 비용을 정당화하기 어려워졌습니다."라고 말했습니다. "ScyllaDB는 필요한 데이터를 메모리에 보관하고 그 밖의 모든 것을 디스크에 보관하도록 최적화되어 있습니다. ScyllaDB를 사용하면 Redis가 처리할 수 있는 규모의 수백 배에 걸쳐 동일한 응답성을 유지할 수 있습니다."
Comcast는 연간 250만 달러를 절약하여 롱테일 대기 시간을 95% 줄입니다.
Comcast는 세 가지 주요 사업을 운영하는 글로벌 미디어 및 기술 회사입니다. Comcast Cable은 미국 NBCUniversal 및 Sky의 가정용 고객에게 비디오, 초고속 인터넷 및 전화 통화를 제공하는 최대 공급업체 중 하나입니다. Comcast의 Xfinity 서비스는 매일 20억 개가 넘는 API 호출(읽기/쓰기)과 2억 개가 넘는 새로운 개체를 통해 1,500만 가구에 서비스를 제공하고 있습니다. 7년 만에 이 프로그램은 30,000개의 장치 지원에서 3,100만 개 이상의 장치 지원으로 확대되었습니다.
Cassandra의 롱테일 대기 시간은 빠르게 성장하는 회사 규모에서 용납할 수 없는 것으로 나타났습니다. Cassandra의 대기 시간 문제를 사용자로부터 숨기기 위해 팀은 데이터베이스 앞에 60개의 캐시 서버를 배치했습니다. 이 캐싱 계층을 데이터베이스와 일관되게 유지하면 관리자에게 많은 골칫거리가 됩니다. 캐시와 관련 인프라는 데이터 센터 간에 복제되어야 하기 때문에 Comcast는 캐시를 활성 상태로 유지해야 합니다. 쓰기량을 확인한 후 데이터 센터 간에 데이터를 복사하는 캐시 워머를 구현했습니다.
Comcast는 이 접근 방식의 오버헤드로 인해 어려움을 겪은 후 신속하게 ScyllaDB로 전환했습니다. ScyllaDB는 내부 캐싱 메커니즘을 통해 지연 시간 급증을 최소화하도록 설계되어 Comcast가 외부 캐싱 계층을 제거하고 데이터 서비스가 데이터 저장소에 직접 연결되는 간단한 프레임워크를 제공할 수 있습니다. Comcast는 962개의 Cassandra 노드를 단 78개의 ScyllaDB 노드로 교체할 수 있었습니다. 60개의 캐시 서버를 완전히 제거하면서 전반적인 가용성과 성능을 향상시켰습니다. 결과: P99, P999 및 P9999는 대기 시간을 95% 줄였으며 60%의 운영 비용으로 두 배 더 많은 요청을 처리할 수 있었습니다. 이를 통해 궁극적으로 인프라 비용과 인건비 측면에서 연간 250만 달러를 절약했습니다.
결론
외부 캐시는 대기 시간을 줄이기 위한 훌륭한 동반자이지만(예: 지속성 수준이 필요하지 않은 정적 콘텐츠 및 개인화된 데이터 제공) 데이터베이스 앞에 배치할 때 이점보다 더 많은 문제를 일으키는 경우가 많습니다.
가장 큰 단점으로는 비용 증가, 애플리케이션 복잡성 증가, 데이터베이스 왕복 추가, 보안 표면 추가 등이 있습니다. 기존 캐싱 전략을 재고하고 규모에 맞게 예측 가능한 낮은 대기 시간을 제공하는 최신 데이터베이스로 전환함으로써 팀은 인프라를 단순화하고 비용을 최소화할 수 있습니다. 동시에 외부 캐싱에 따른 추가적인 번거로움과 복잡성 없이 SLA를 충족할 수 있습니다.
알려지지 않은 오픈 소스 프로젝트가 얼마나 많은 수익을 가져올 수 있습니까? Microsoft의 중국 AI 팀은 수백 명의 사람들을 모아 미국으로갔습니다. Huawei는 Yu Chengdong의 직업 변경이 15년 동안 "FFmpeg Pillar of Shame"에 못 박혔다 고 공식 발표했습니다. 이전에는 그랬지만 오늘은 우리에게 감사해야 합니다.— Tencent QQ Video가 과거의 굴욕을 복수한다고요? Huazhong University of Science and Technology의 오픈 소스 미러 사이트가 외부 액세스 보고를 위해 공식적으로 공개되었습니다 . Django는 여전히 74%의 개발자가 선택한 제품입니다. Zed 편집자는 유명한 오픈 소스 회사의 전직 직원이었습니다 . 소식을 전했습니다: 기술 리더는 부하 직원의 도전을 받은 후 격노하고 무례하게 행동하여 해고되었으며 임신했습니다. 여직원 Alibaba Cloud가 공식적으로 Tongyi Qianwen 2.5를 출시했습니다. Microsoft는 Rust Foundation에 100만 달러를 기부했습니다.이 기사는 Yunyunzhongsheng ( https://yylives.cc/ ) 에 처음 게재되었습니다 . 누구나 방문하실 수 있습니다.