
저자: Xingji, Changjun, Youyi, Liutao
컨테이너 작업 메모리 개념 소개 WorkingSet
Kubernetes 시나리오에서 컨테이너 메모리 실시간 사용 통계(Pod Memory)는 WorkingSet 작업 메모리(WSS로 약칭)로 표시됩니다.
WorkingSet의 지표 개념은 컨테이너 시나리오를 위해 cadvisor에 의해 정의됩니다.
작업 메모리 WorkingSet는 노드 제거를 포함한 메모리 리소스를 결정하기 위한 Kubernetes 예약 결정에 대한 지표이기도 합니다.
WorkingSet 계산 공식
공식 정의: K8s 공식 웹사이트 문서 참조
https://kubernetes.io/docs/concepts/scheduling-eviction/node-press-eviction/#eviction-signals
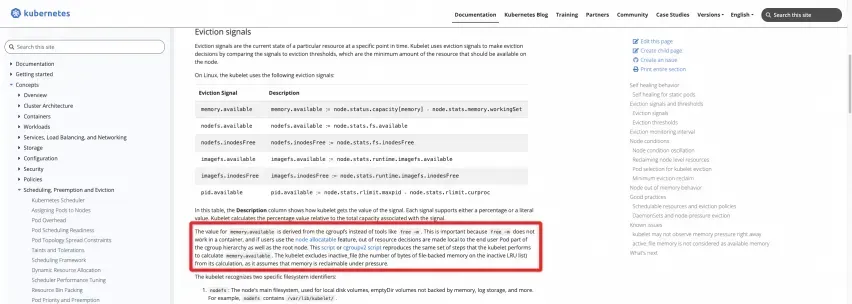
다음 두 스크립트를 노드에서 실행하여 결과를 직접 계산할 수 있습니다.
C그룹V1
https://kubernetes.io/examples/admin/resource/memory-available.sh
#!/bin/bash
#!/usr/bin/env bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to root cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
C그룹V2
https://kubernetes.io/examples/admin/resource/memory-available-cgroupv2.sh
#!/bin/bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to kubepods cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/kubepods.slice/memory.current)
memory_total_inactive_file=$(cat /sys/fs/cgroup/kubepods.slice/memory.stat | grep inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
코드를 보여주세요
보시다시피 노드 WorkingSet의 작업 메모리는 루트 cgroup의 메모리 사용량에서 Inactve(file) 부분의 캐시를 뺀 값입니다. 마찬가지로 Pod에 있는 컨테이너의 WorkingSet 작업 메모리는 컨테이너에 해당하는 cgroup 메모리 사용량에서 Inactve(file) 부분의 캐시를 뺀 값입니다.
실제 Kubernetes 런타임의 kubelet에서 cadvisor가 제공하는 지표 로직 중 이 부분의 실제 코드는 다음과 같습니다.
cadvisor Code [ 1] 에서 WorkingSet 작업 메모리의 정의를 명확하게 볼 수 있습니다.
The amount of working set memory, this includes recently accessed memory,dirty memory, and kernel memory. Working set is <= "usage".
그리고 cadvisor의 WorkingSet [ 2] 계산에 대한 특정 코드 구현은 다음과 같습니다 .
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
컨테이너 메모리 문제에 대한 일반적인 사용자 문제 사례
ACK 팀이 다수의 사용자에게 컨테이너 시나리오에 대한 서비스 지원을 제공하는 과정에서 많은 고객이 비즈니스 애플리케이션을 컨테이너에 배포할 때 컨테이너 메모리 문제에 다소 직면했습니다. 수많은 고객 문제를 경험한 후 ACK 팀과 Alibaba Cloud 운영 체제 팀은 컨테이너 메모리 측면에서 사용자가 직면하는 다음과 같은 일반적인 문제를 요약했습니다.
FAQ 1: 호스트의 메모리 사용량과 노드별 컨테이너의 집계 사용량 사이에는 차이가 있습니다. 호스트는 약 40%이고 컨테이너는 약 90%입니다.
아마도 이는 컨테이너의 Pod가 PageCache와 같은 캐시를 포함하는 WorkingSet으로 간주되기 때문일 것입니다.
호스트의 메모리 값에는 Cache, PageCache, Dirty Memory 등이 포함되지 않지만 작업 메모리에는 이 부분이 포함됩니다.
가장 일반적인 시나리오는 JAVA 애플리케이션의 컨테이너화, JAVA 애플리케이션의 Log4J 및 매우 널리 사용되는 구현인 Logback입니다. 기본 Appender는 NIO를 매우 "간단하게" 사용하기 시작하고 mmap을 사용하여 Dirty Memory를 사용합니다. 이로 인해 메모리 캐시가 증가하여 Pod의 작업 메모리 WorkingSet이 증가합니다.
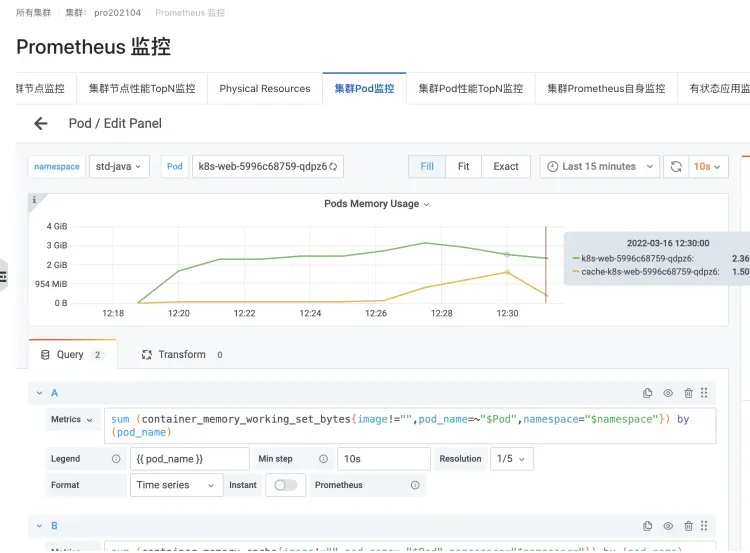
JAVA 애플리케이션 포드의 로그백 로깅 시나리오
캐시 메모리 및 WorkingSet 메모리 증가를 유발하는 인스턴스
FAQ 2: Pod에서 top 명령을 실행할 때 얻은 값은 kubectl top pod에서 보는 작업 메모리 값(WorkingSet)보다 작습니다.
컨테이너 런타임 격리 등의 문제로 인해 Pod에서 top 명령을 실행하면 실제로 컨테이너 격리가 깨지고 호스트의 상위 모니터링 값을 얻습니다.
따라서 보이는 것은 호스트 머신의 메모리 값으로 Cache, PageCache, Dirty Memory 등이 포함되지 않은 반면, 작업 메모리에는 이 부분이 포함되어 있어 FAQ 1과 유사합니다.
FAQ 3: 포드 메모리 블랙홀 문제
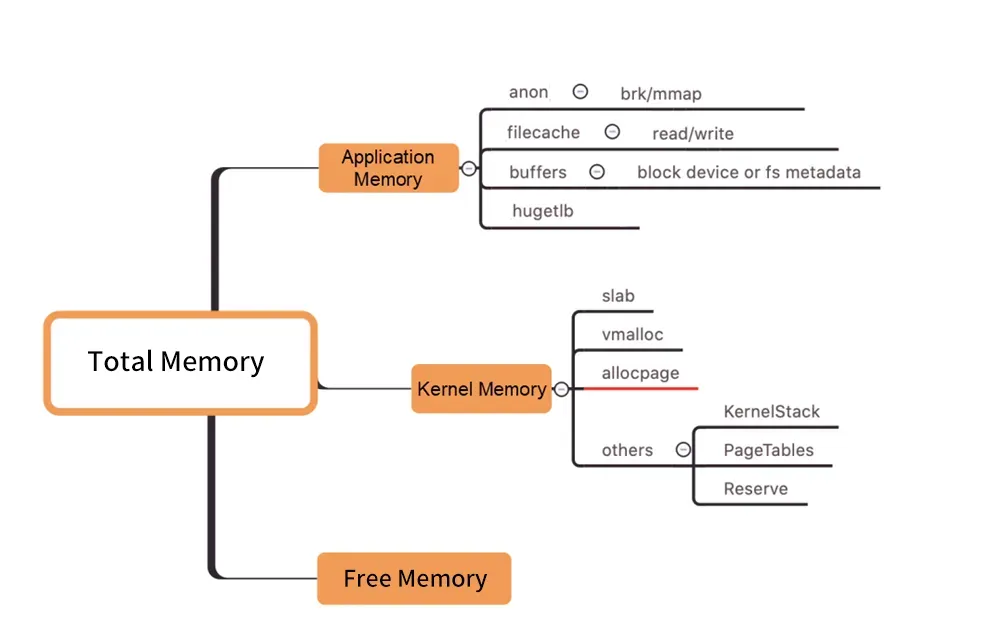
图/커널 수준 메모리 배포
위 그림과 같이 Pod WorkingSet 작업 메모리에는 Inactive(anno)가 포함되어 있지 않으며 사용자가 사용하는 Pod 메모리의 다른 구성 요소가 기대에 미치지 못하여 결국 WorkingSet 워크로드가 증가하여 결국 Node로 이어질 수 있습니다. 퇴거.
수많은 기억 구성요소 중에서 작업기억이 증가하는 실제 원인을 찾는 방법은 블랙홀만큼이나 눈에 띄지 않습니다. ("메모리 블랙홀"은 이 문제를 가리킨다.)
WorkingSet 높은 문제를 해결하는 방법
일반적으로 메모리 재활용 지연은 높은 작업 세트 메모리 사용량을 동반합니다. 그렇다면 이러한 유형의 문제를 해결하는 방법은 무엇입니까?
직접 확장
용량 계획(직접 확장)은 높은 리소스 문제에 대한 일반적인 솔루션입니다.
"메모리 블랙홀" - 딥 메모리 비용(예: PageCache)으로 인해 발생하는 경우 대처 방법
그러나 메모리 문제를 진단하려면 먼저 분석하고, 통찰력을 얻고, 분석해야 하며, 인간의 관점에서 어떤 메모리 조각이 누구(어떤 프로세스 또는 파일과 같은 특정 리소스)에 의해 보유되고 있는지 명확하게 확인해야 합니다. 그런 다음 타겟 수렴 최적화를 수행하여 최종적으로 문제를 해결합니다.
1단계: 메모리 확인
첫째, 운영 체제 커널 수준 컨테이너 모니터링 메모리 표시기를 분석하는 방법은 무엇입니까? ACK 팀은 운영 체제 팀과 협력하여 현재 Alibaba Cloud의 고유한 SysOM 컨테이너 에서 Pod 메모리 모니터를 확인함으로써 운영 체제의 커널 계층에서 컨테이너 모니터링의 SysOM(시스템 관찰자 모니터링) 제품 기능을 출시했습니다. 시스템 모니터링-Pod 차원에서는 아래와 같이 Pod의 자세한 메모리 사용량 분포에 대한 통찰력을 얻을 수 있습니다.
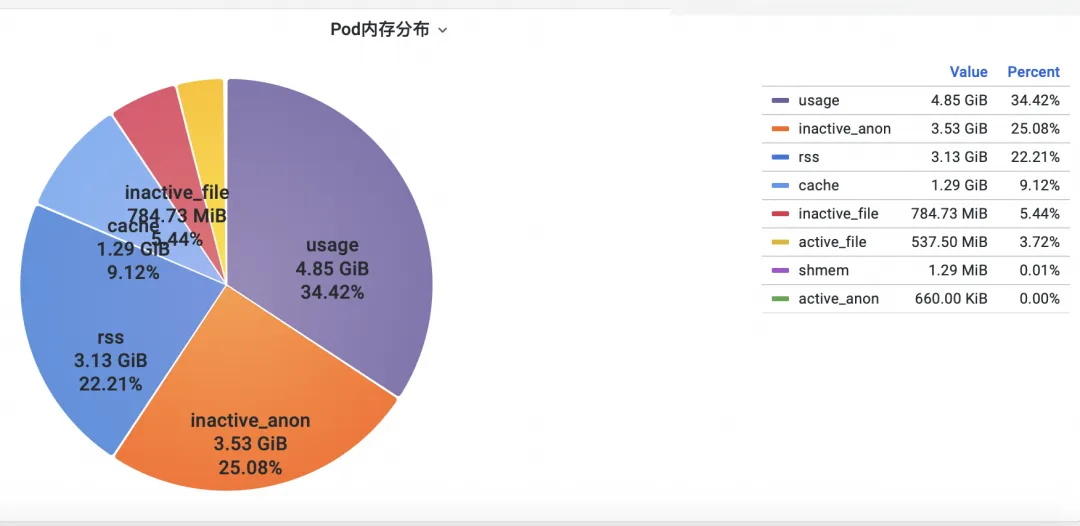
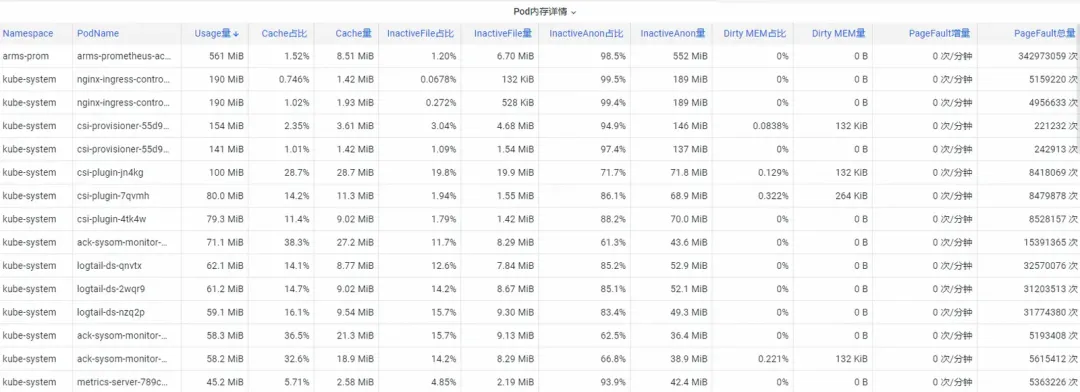
SysOM 컨테이너 시스템 모니터링은 각 Pod의 자세한 메모리 구성을 세부적인 수준으로 볼 수 있습니다. Pod Cache(캐시 메모리), InactiveFile(비활성 파일 메모리 사용량), InactiveAnon(비활성 익명 메모리 사용량), Dirty Memory(시스템 더티 메모리 사용량)와 같은 다양한 메모리 구성 요소의 모니터링 및 표시를 통해 일반적인 Pod 메모리 블랙홀 문제는 다음과 같습니다. 발견되었습니다.
Pod 파일 캐시의 경우 Pod의 현재 열려 있는 파일과 닫힌 파일의 PageCache 사용량을 동시에 모니터링할 수 있습니다. (해당 파일을 삭제하면 해당 캐시 메모리가 해제될 수 있습니다.)
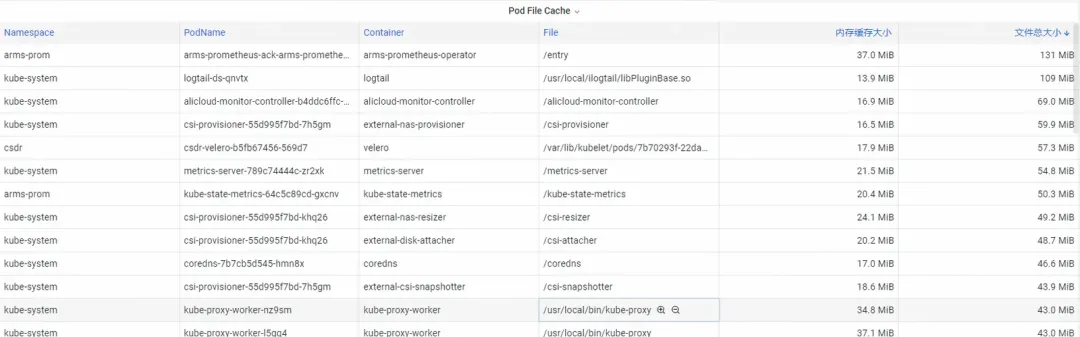
2단계: 메모리 최적화
사용자가 명확하게 보더라도 쉽게 수렴할 수 없는 뿌리 깊은 메모리 소비가 많이 있습니다. 예를 들어 운영 체제에서 균일하게 회수되는 PageCache 및 기타 메모리는 사용자가 플러시( )를 Log4J의 Appender에 추가하여 주기적으로 sync()를 호출합니다.
https://stackoverflow.com/questions/11829922/logback-file-appender-doesnt-flush-immediately
이것은 매우 비현실적입니다.
ACK 컨테이너 서비스 팀은 Koordinator QoS 세분화된 스케줄링 기능을 출시했습니다 .
운영 체제의 메모리 매개변수를 제어하기 위해 Kubernetes에 구현되었습니다.
클러스터에서 차별화된 SLO 공동 배치가 활성화되면 시스템은 지연 시간에 민감한 LS(Latency-Sensitive) 포드의 메모리 QoS에 우선 순위를 부여하고 전체 시스템에서 메모리 재활용을 트리거하는 LS 포드의 타이밍을 지연시킵니다.
아래 그림에서 memory.limit_in_bytes는 메모리 사용량 상한을 나타내고, memory.high는 메모리 현재 제한 임계값을 나타내고, memory.wmark_high는 메모리 백그라운드 재활용 임계값을 나타내고, memory.min은 메모리 사용량 잠금 임계값을 나타냅니다.
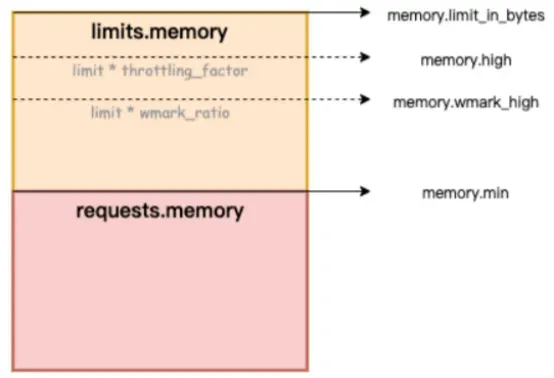
Figure/ack-koordinator는 컨테이너에 대한 메모리 QoS(서비스 품질) 보장 기능을 제공합니다.
메모리 블랙홀 문제를 해결하는 방법은? Alibaba Cloud Container Service는 개선된 스케줄링 기능을 사용하고 Koordinator 오픈 소스 프로젝트를 사용하여 컨테이너에 대한 메모리 서비스 품질 QoS(서비스 품질) 보장 기능을 제공하여 메모리 공정성을 향상시킵니다. 메모리 자원의 공정성을 보장한다는 전제 하에 런타임 시 애플리케이션의 메모리 성능. 이 문서에서는 컨테이너 메모리 QoS 기능을 소개합니다. 자세한 지침은 컨테이너 메모리 QoS [ 3] 를 참조하세요 .
컨테이너는 메모리를 사용할 때 주로 다음과 같은 두 가지 제약 조건을 갖습니다.
1) 자체 메모리 제한: 컨테이너 자체 메모리(PageCache 포함)가 컨테이너의 상한에 도달하면 컨테이너 차원 메모리 재활용이 시작됩니다. 이 프로세스는 컨테이너 내 애플리케이션의 메모리 적용 및 릴리스 성능에 영향을 미칩니다. 메모리 요청을 충족할 수 없으면 컨테이너 OOM이 트리거됩니다.
2) 노드 메모리 제한: 컨테이너 메모리가 초과되어(Memory Limit>Request) 전체 머신의 메모리가 부족할 경우 노드 차원에서 전역 메모리 재활용이 발생하며, 이 프로세스는 성능에 큰 영향을 미치며 극단적인 경우입니다. , 심지어 전체 기계가 비정상이 되는 원인이 되기도 합니다. 재활용이 충분하지 않은 경우 해당 컨테이너는 OOM Kill 대상으로 선택됩니다.
위의 일반적인 컨테이너 메모리 문제를 해결하기 위해 ack-koordinator는 다음과 같은 향상된 기능을 제공합니다.
1) 컨테이너 메모리 백그라운드 재활용 수위: Pod 메모리 사용량이 제한 한도에 가까워지면 메모리의 일부가 백그라운드에서 비동기식으로 재활용되어 직접적인 메모리 재활용으로 인한 성능 영향을 완화합니다.
2) 컨테이너 메모리 잠금 재활용/수위 제한: Pod 간에 보다 공평한 메모리 재활용을 구현합니다. 전체 머신의 메모리 리소스가 부족한 경우 메모리 과다 사용(메모리 사용량>요청)이 있는 Pod의 메모리를 재활용하는 데 우선순위가 부여됩니다. 전반적인 오류를 일으키는 포드입니다. 머신 메모리 리소스의 품질이 저하되었습니다.
3) 전체 메모리 재활용에 대한 차별화된 보장: BestEffort 메모리 과잉 판매 시나리오에서는 보장/버스트 가능 포드의 메모리 실행 품질을 보장하는 데 우선순위가 부여됩니다.
ACK 컨테이너 메모리 QoS로 활성화되는 커널 기능에 대한 자세한 내용은 Alibaba Cloud Linux의 커널 기능 및 인터페이스 개요 [ 4] 를 참조하세요 .
관찰의 첫 번째 단계를 통해 컨테이너 메모리 블랙홀 문제가 발견된 후, ACK 미세 스케줄링 기능은 메모리에 민감한 Pod의 대상 선택과 결합되어 컨테이너 메모리 QoS 기능이 폐쇄 루프 복구를 완료하도록 활성화할 수 있습니다.
참조 문서:
[1] ACK SysOM 기능 설명 문서
[2] 모범 사례 문서
[3] 중국 용 도마뱀 공동체
https://mp.weixin.qq.com/s/b5QNHmD_U0DcmUGwVm8Apw
[4] 국제국 영어
https://www.alibabacloud.com/blog/sysom-container-monitoring-from-the-kernels-perspective_600792
관련된 링크들:
[1] 캐드바이저 코드
[2] Cadvisor에 의한 WorkingSet 계산의 특정 코드 구현
[3] 컨테이너 메모리 QoS
https://help.aliyun.com/zh/ack/ack-managed-and-ack-dedicated/user-guide/memory-qos-for-containers
[4] Alibaba Cloud Linux의 커널 기능 및 인터페이스 개요
https://help.aliyun.com/zh/ecs/user-guide/overview-23
Microsoft의 중국 AI 팀은 수백 명의 사람들을 모아 미국으로갔습니다. 알려지지 않은 오픈 소스 프로젝트는 얼마나 많은 수익을 가져올 수 있습니까? Huawei는 공식적으로 Yu Chengdong의 위치가 화중 과학 기술 대학의 오픈 소스 미러 스테이션 으로 조정되었다고 발표했습니다. 사기꾼들이 TeamViewer를 사용해 외부 네트워크 접속을 공식적으로 개시했습니다 ! 원격 데스크톱 공급업체는 무엇을 해야 합니까? 최초의 프런트 엔드 시각화 라이브러리이자 Baidu의 유명한 오픈 소스 프로젝트 ECharts의 창립자 - "바다에 나간" 유명한 오픈 소스 회사의 전직 직원이 소식을 전했습니다. 리더는 격노하고 무례하게 행동하여 임신한 여성 직원을 해고했습니다. OpenAI는 AI가 포르노 콘텐츠를 생성하도록 허용하는 것을 고려했습니다. Microsoft는 Rust Foundation에 100만 달러를 기부했다고 보고했습니다. 여기서 time.sleep(6)의 역할은 무엇입니까? ?