목차
1. 하이퍼로그로그
먼저 우리는 두 가지 개념을 이해합니다.
UV: 전체 이름은 Unique Visitor(순 방문자라고도 함)이며 인터넷을 통해 이 웹페이지에 액세스하고 탐색하는 자연인을 의미합니다.
동일한 사용자가 하루에 여러 번 웹사이트를 방문하는 경우 한 번만 기록됩니다.
PV: 전체 이름은 페이지 뷰(Page View)이며, 사용자가 웹사이트의 페이지를 방문할 때마다 하나의 PV가 기록되고 사용자는 페이지를 여러 번 엽니다.
표면에는 여러 개의 PV가 기록됩니다.
웹사이트 트래픽을 측정하는 데 자주 사용됩니다.
일반적으로 UV는 PV보다 훨씬 크기 때문에 동일한 웹사이트의 방문수를 측정할 때는 여러 가지 요소를 고려해야 합니다.
그래서 우리는 이 두 값을 참고값으로만 사용합니다.
사용자가 집계되었는지 여부를 확인하려면 집계된 사용자 정보를 저장해야 하기 때문에 서버 측에서 UV 통계를 수행하는 것이 더 번거롭습니다.
하지만 방문하는 모든 사용자를 Redis에 저장한다면 데이터의 양이 엄청날텐데 어떻게 처리해야 할까요?
HLL(Hyperloglog)은 Loglog 알고리즘에서 파생된 확률적 알고리즘으로, 모든 세트를 저장할 필요 없이 매우 큰 세트의 카디널리티를 결정하는 데 사용됩니다.
값.
관련 알고리즘 원리를 참고하실 수 있습니다: https://juejin.cn/post/6844903785744056333#heading-0
Redis의 HLL은 문자열 구조를 기반으로 구현됩니다. 단일 HLL의 메모리는 항상 16kb 미만이며 메모리 사용량은 놀라울 정도로 낮습니다.
트레이드오프로서 측정값은 확률적이며 오류는 0.81% 미만입니다.
그러나 UV 통계의 경우 이는 완전히 무시할 수 있습니다.

2. 수백만 개의 데이터 통계 테스트
테스트 아이디어: 단위 테스트를 통해 HyperLogLog에 100만 개의 데이터를 직접 추가하여 메모리 사용량과 통계 효과가 어떤지 확인합니다.
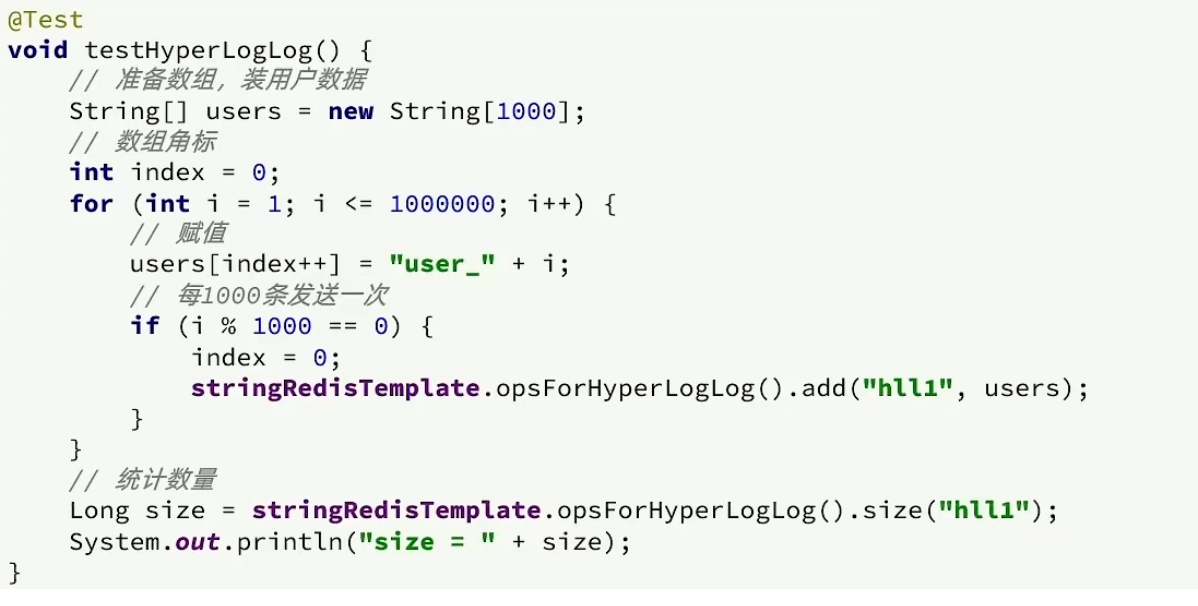
테스트 후: 오류는 허용 범위 내에 있으며 메모리 사용량은 최소화됩니다.