이미 포화 온라인 기사를 위해, 또한 이유는 매우 간단 썼다 - 노트에 대한 이해한다.
머리말
당신이 배울이 문서, MySQL개인적인 이해, 엔진 사용 InnoDb. 먼저 얘기 트랜잭션 개념에서 《高性能MySQL》第三版그의 업무는 다음과 같이 설명 :
거래는 원자 SQL 쿼리의 집합, 또는 직장의 독립형 장치입니다. 데이터베이스 엔진이 성공적으로 데이터베이스 응용 프로그램을 쿼리 모든 진술은 다음 쿼리를 실행 할 수 있습니다. 충돌 또는 다른 이유 집행 이러한 진술의 경우, 모든 문은 실행되지 않습니다.
즉, 트랜잭션은 전체 단위 1, SQL문, 일반적으로 일부 상품처럼 단독으로 실행되는 여러 구성 요소로 구성되지 않지만, 확실히, 개별적으로 부품을 판매하지 않습니다 만 상품을 구매하거나하지 판매.
비즈니스의 이해에 대한 간략한는 또한 거래의 목적이하는 것입니다 알 필요 후 데이터의 정확성과 일관성을 유지하기 가 밖으로 태어난이 목적을 위해 다음 4특성 (당시 세부 사항으로 이동),이 네 가지 특성을 달성하기 위해 및 위해를 포함하여, 많은 특정 구현을 필요로 분리 생산 된 네 개의 격리 수준 , 생산하고 네 개의 격리 수준 세 가지 문제 ( 脏读, 不可重复读와 幻读, 살펴 보겠습니다), 이것은 대략적인 관계 결국이 특별한 무엇을 것입니다.
속성의 1 사가지 (ACID)
트랜잭션의 특성의 말하기, 그것은 입이 와서 확실히 ACID이외에, 그러나, ACID외부 우리가 뭔가 말을해야 할 지점을.
原子性(Atomicity): 것을이 수단 트랜잭션이 중 모든 성공 나눌 수없는 최소 단위, 전체 트랜잭션의 작업으로 처리해야 또는 모든 실행이 수행하지 않습니다 불가분의 같은 원자 (음주 쿼크에 대해 나에게 이야기하지)처럼, 여기 수행은 성공적인 구현을 의미 모든 실행되지 않는 작업을 수행 할 수있는 오류가있을 경우 그것은 우리가 일반적으로 롤백을 볼 것입니다.
一致性(Consistency):이 책에 주어진 의미있는 문제는 항상 일관성있는 상태에서 다른 일관된 상태로 이동합니다 . 나의 이해는, 예를 들어 모든 것을 얻기 위해 돈을 전송, 데이터의 전체 변경되지,라고하는 것입니다, 보존 데이터의 범위에 포함되어 A전송 계정 B``200달러, 다음 만든 A및 B이 데이터 범위의 구성 그는 데이터가 말했다 변경되지 않은(-200+200=0) , 하지만 데이터가 변경되는 방식의 구성은 , 그것은 하나의 일관된 상태에서입니다 -> 다른 일관성있는 상태.
隔离性(Isolation): 일반적으로, 총무에 말을하는 것입니다 볼 수없는 다른 트랜잭션에 대한 트랜잭션의 작업은 독립적이다. 그러나 관련 데이터베이스와이 격리 수준은 이외에 - 격리 수준 외부 (예, 읽기 커밋되지 않은 학생), 다른 하나는, 보이지 않는,이 거래 수준은 거의 사용되지 본 적 그래서 '일반적'입니다.
持久性(Durability): 트랜잭션이 완료되면, 트랜잭션에 의한 데이터 변경을 영구적으로 될 것이며 (다른 트랜잭션이 변경되지 않는 한) 변경되지 않습니다. 그러나 이것은 실제로 전략의 구현과 관련된 책에 언급되어 있지만 멀리 조금 보인다 (예, 나도 몰라!).
이들은의 일이다 특성 네 가지 종류 , 그러나,의 실현은 분리 레벨의 분리가 데이터베이스에 달려있다.
데이터베이스 격리 수준이
에서 MySQL격리 수준이 있습니다 네 가지 종류 다른는 각 해당 트랜잭션 격리 수준은 가능한 문제를 반영 다릅니다.
未提交读(read uncommited)이 격리 수준에서 작동 다른 문제를 제출하지 않는 거래도 볼 수있는 경우에도 수행. 트랜잭션이 수준에서 나타날 수있는 다른 트랜잭션에 의해 제출 된 더티 데이터 읽을 수 더러운 읽기 . 아래에 도시 된 바와 같이, 수는 실행 순서를 나타낸다.
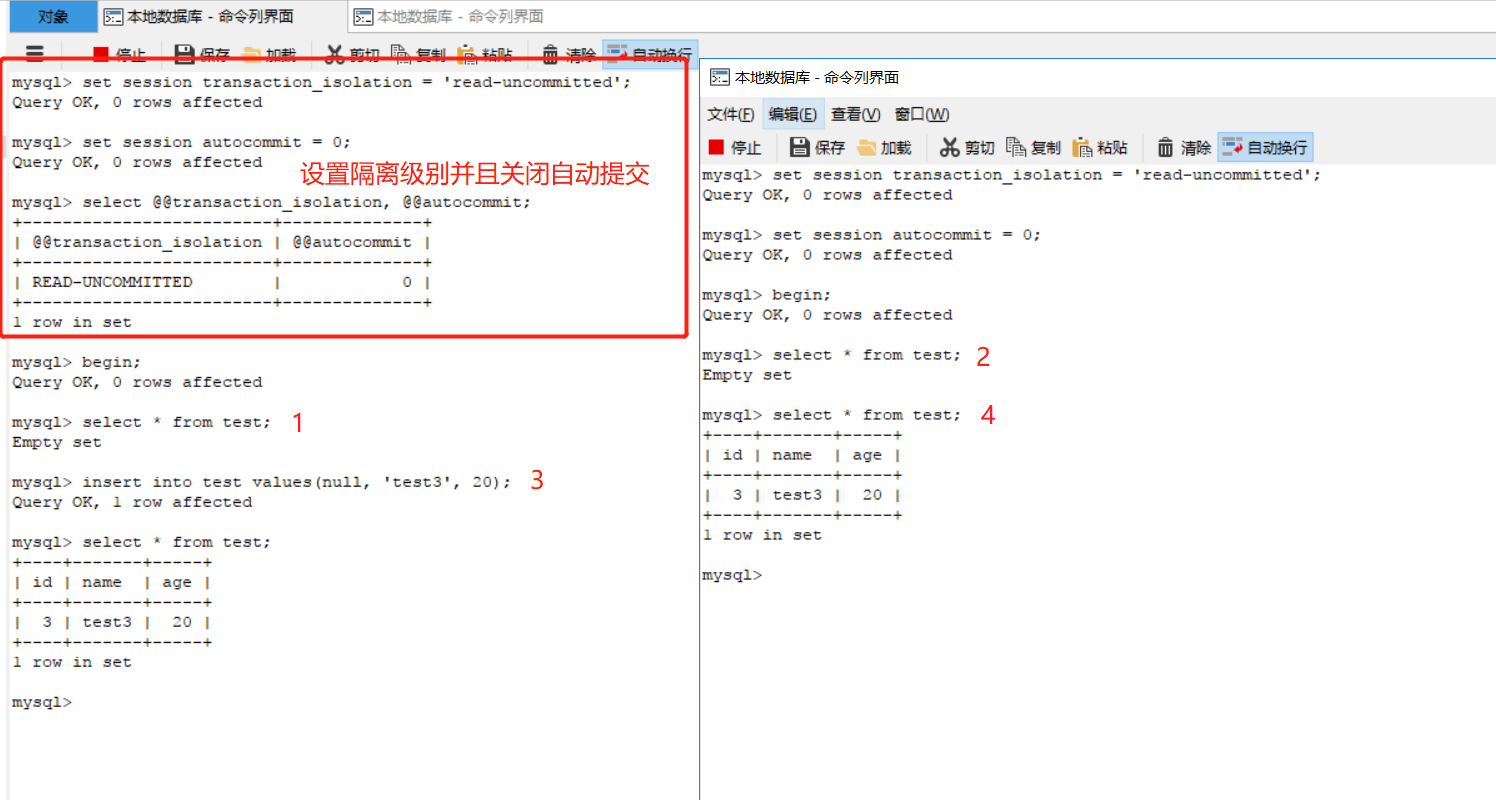
그것은 인터페이스에서 볼 수있는 1받는 트랜잭션 test데이터, 심지어 페이지를 제출하지 이때 삽입 테이블 2도 다른 트랜잭션에 의해 제출 된 데이터를 볼 수 있습니다.
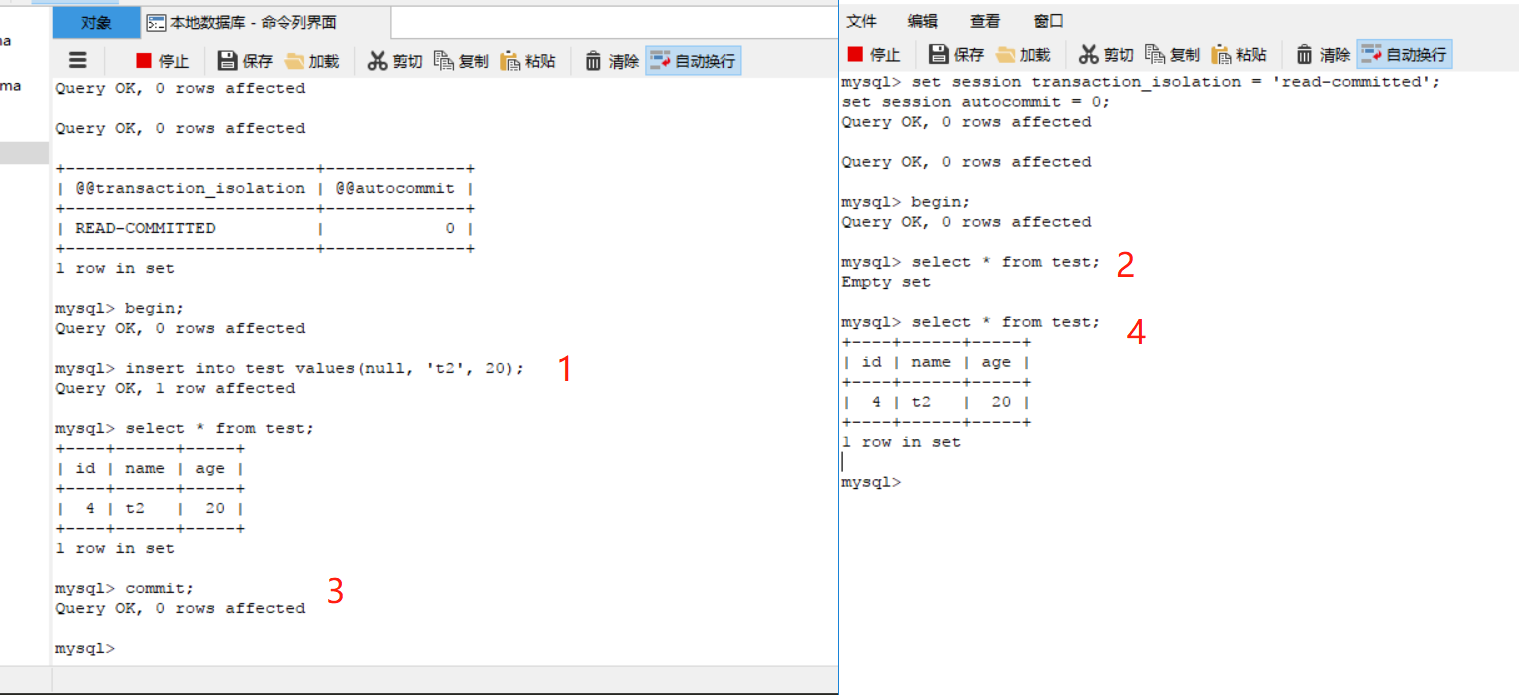
提交读(read commited): 트랜잭션이 커밋되면, 다른 트랜잭션이 수정 된 트랜잭션을 볼 수 있습니다 . 동일한 쿼리를 나타날 수 있습니다이 격리 수준은 같은 트랜잭션을 실행하지만입니다, 다른 데이터를 읽어 비 반복 읽기 ( nonrepeatable read), 다른 커밋되지 않은 읽기는 비 반복 읽기를 발생할 수 있습니다. 예는 다음이다
可重复读(repeatable read):这是MySQL的默认隔离级别,在事务开始的时候会保存此刻的一个快照(这里啰嗦一下,实际上是开启事务后执行第一条语句的时候准备的快照,准备快照的方法则是记录当前事务的版本号,没有进行数据的复制,不明白事务版本号或隐藏字段的可以看看MySQL的MVCC),然后接下来这个事务的所有数据读取都是从这个快照读,所以不会出现不可重复读的情况,但是还是有可能出现幻读。意思就是读取的是快照表数据不会变化,但是进行写操作如更新的时候更新的数量可能会跟预期的不同。如图
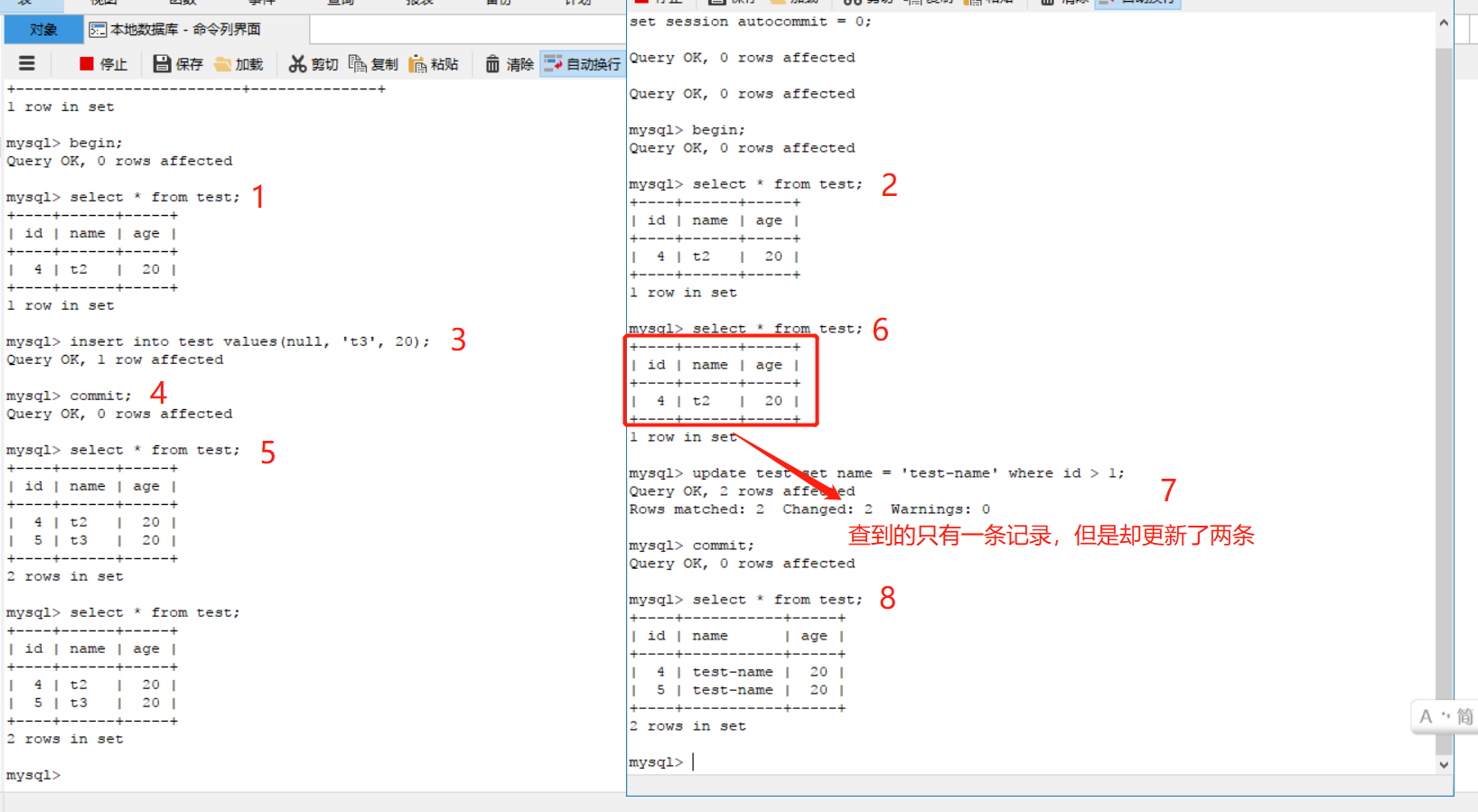
可以看到,在界面1插入一条记录并且提交之后,界面2还是没有读到这个提交的数据,因为他是从事务开始时的快照表读取的所以自然是读不到的,但是在进行更新操作的时候则是更新了意料之外的记录,这就是一种幻读的现象。
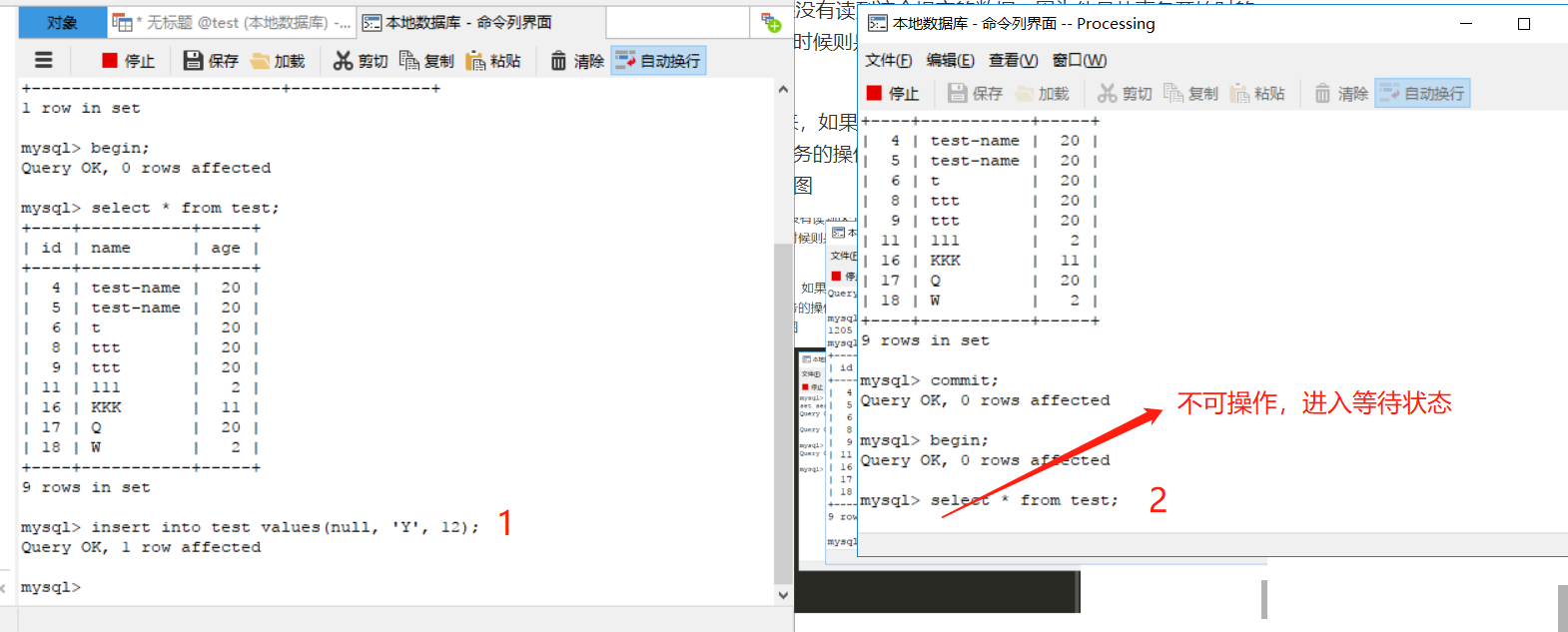
可串行化(serializable):意思就是事务要一个一个来,如果在一个事务中进行读操作,那么其他事务在该事务完成前只能进行读操作;如果进行写操作,那么其他事务的操作都进入等待(直到当前事务提交)。这种级别就可以防范目前出现的脏读、不可重复读、幻读等现象。如图
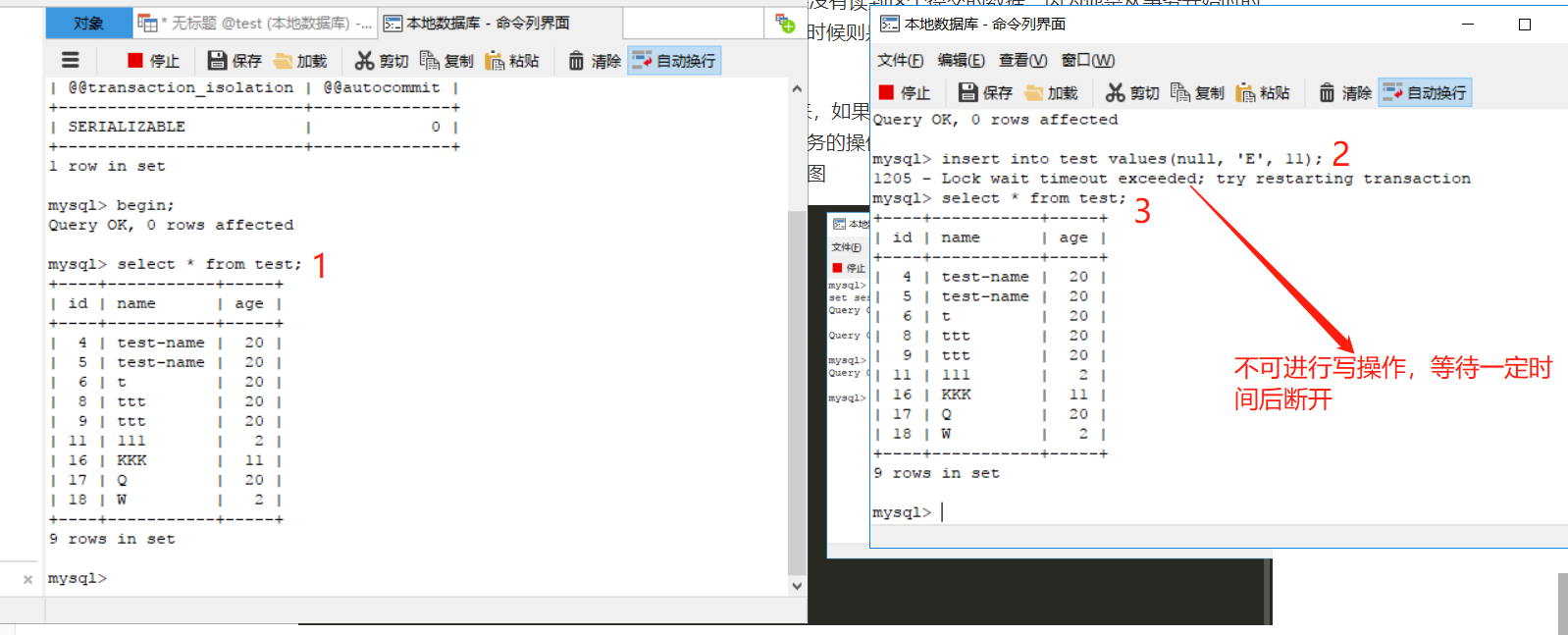
上图演示的是事务读时,其他事务不可写,下图是写时不可操作。
3 三个问题—脏读、不可重复读、幻读。
这是采取事务的不同隔离级别可能产生的几个问题,在上面隔离级别已经提及到了,但是为了避免混淆还是单独拿出来。
脏读: 더티 데이터를 아직 거래에서 일어났다 제출되지 않은 다른 문제를 읽고 참조 읽기 커밋되지 않은 수준.不可重复读: 트랜잭션에서 다른 결과가 나타날 수 있습니다 동일한 쿼리에서 일어났다 읽기 커밋, 헌신 수준의 읽기 . (개인적으로 나는 혼동 반복 될 수없는 전화라는 것을 구체적으로 이해 할 필요를 느끼지 않는다)幻读: 때 같은 데이터 전에 밖으로 쿼리에 대한 변경 서로 다른 기대의 수, 다수의 변형과 트랜잭션의 쓰기 작업.
일부는 장황한 不可重复读과 幻读구별은 :으로 이해 될 수 不可重复读是의 단편 기록 필드 값 의 변화가, 예를 들면, id하기 1기록 name두 값이 다른, 그러나 幻读그것이 양이 다른 , 예를 들어, I는 총 검사 할 때 2기록을 그러나 수정 작업은 업데이트 때 3기사를.
참조 : "고성능 MySQL은" http://www.zsythink.net/archives/1233/
아마도 내가 단순히 인식 할 수 있도록합니다.