기사 디렉토리
휘발성 1의 시인성을 확보하는 방법
기사, " [] 동시 프로그래밍 - 동시 프로그래밍 가시성, 자성, 주문 문제는 "두 개의 스레드가 같은 공유 변수 투명 문제를 수정 재현합니다. 나는 당신이 문제를 해결하기 위해 모든 노하우, 하나 개의 방법이이 나는 믿는다 : 在声明共享变量时加上volatile关键字。
그것이 무엇입니까의 기본 원리? ? ?
첫째, 휘발성 키워드없이 변수의 스레드 (2)가 공유 된 경우에도 값을 수정하지만, 스레드 (1) (주 메모리에 대한 몇 가지 점에서 동기화되지를) 공유 변수로 사용 되었기 때문에 때 알고 있어야, 따라서 스레드는 (참조도 상기 이해하게 될 수있다. 1) 공유 변수 스레드 2 변형을 감지 할 수 없다.
수정이 개 공유 변수, 후 스레드가 직접 스레드 1 개의 벌금을 통지 할 경우이 시간은 당신이 확실히 할 것입니다. . .
이 작업을 수행하는 휘발성 키워드는 자사의 특정 구현 원리는 다음 그림에 의해 설명 될 수 있습니다 :
注意:이 많은 친구는 그 사실, CPU가 버스를 사용하지 않는 얘기, 그리고 내가 잘 모르겠지만, 버스를 사용하지 않을 경우에도 내 정보와 자신의 이해에 대한 액세스 권한에 따라,이 작품의 기본 원칙은 동일이 시점. . .

사실, 메인 메모리 및 다양한 스레드간에, 여전히 휘발성 키워드가 스레드 간의 가시성을 확보 할 수 있었다 버스가 세 가지 중요한이 있습니다 :
- (1) 메인 메모리에 다시 기록하기 전에, 2를 작업 메모리 공유 변수의 수정 카피를 스레드
总线잠금 동작을 수행 - 각각의 나사에 의해 (2)
总线嗅探机制버스를 모니터링 일단 데이터가 해제되도록,이 스레드의 작업 메모리에서 데이터의 복사에 관한 동작 잠금 및 잠금 변수를 발견하고, 메인 메모리로부터 다시 판독
공유 변수를 모니터링하는 단지 하나 개의 스레드가있을 수 있기 때문에 물론, 단지 충분한 경우 즉시 스레드 (2) 수정 된 변수 주에 동기화되지 한 번에 데이터를 가져옵니다 메인 메모리에, 변경, 이전 두를 충족 공유 변수 수정안 2 스레드와 등가 인 변수 또는 이전 값을 얻을 것이다 공유 메모리, 스레드 1, 스레드 1은 스레드 사이의 가시성을 보장 할 수 있고, 검출되지 않는다. 그래서 중요한 포인트가있다 :
- 다른 스레드를 수정할 것이다 변수 스레드 2 이전에 메인 메모리 (3)에 라이트 백을 차단한다 공유 변수의 메인 메모리로부터 판독하여, 메인 메모리에 변수 라이트 백 후에 스레드 2
会进行unlock와 다른 스레드가 읽을 수 에. - 물론,이 시간이 매우 빠릅니다.
위의 세 가지 점을 바탕으로, 스레드 간의 휘발성 캔 보증 가시성.
그런데, 매력이 아니라 其具体实现是利用汇编语言的Lock前缀指令, 이론적 .
자성 2 휘발성 문제를 보장 할 수없는 이유
참조하여 상기의 예 " -] 동시 프로그래밍 공개 동시 프로그래밍, 자성, 정렬 문제 번째 예에서,"두 스레드 어디 이유.
휘발성 수없는 보장 자성 문제도 하에서 가능한 설명 이유는
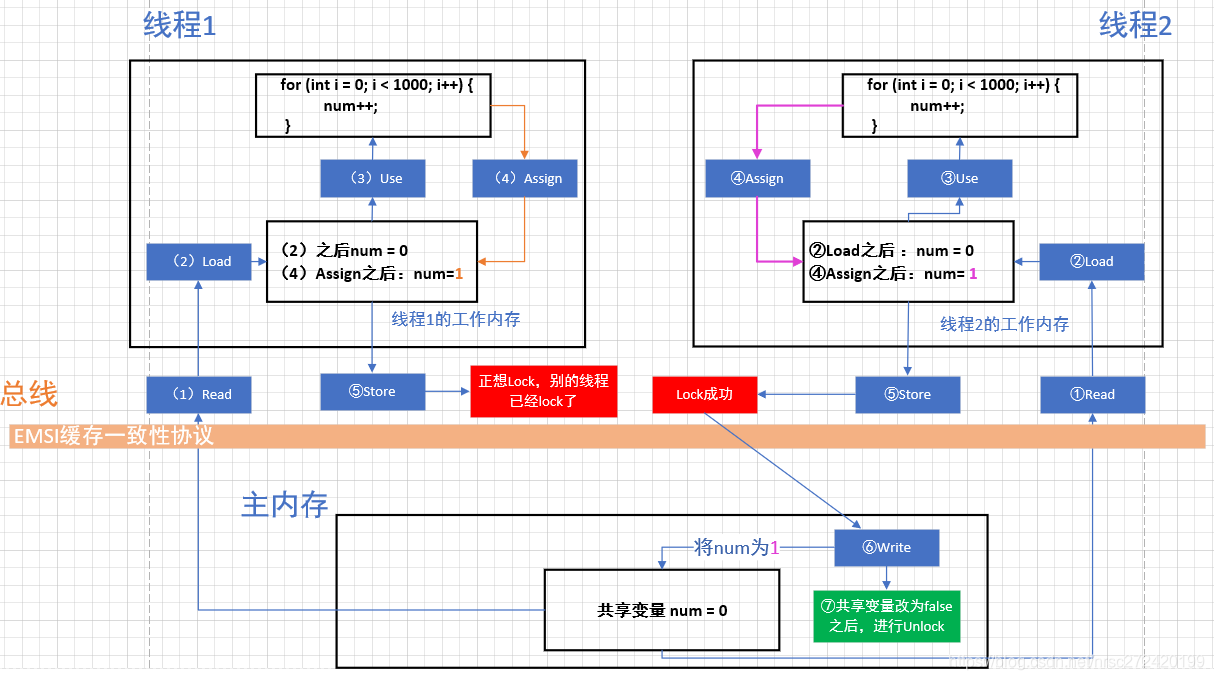
도시 된 바와 같이, 스레드 1, 스레드 2 순환 NUM ++ 동작 스레드 1 행하고 연산 ++ NUM의 사이클이 수행 될 할당을 실행하는 경우 -> 점포 ->와 로크하려고 노력하지만, 갑자기 嗅探쓰레드 (2)는 공유 변수 Num Lock 표시 동작은, 상기 메인 메모리로부터 1 스레드 납입 날짜 값을 당길 것이다있다 再进行新的循环이다 相当于线程1浪费了一次循环. 그래서 심지어 휘발성 캔하지 멀티 스레드 프로그램의 자성을 보장합니다.
주문 캔 보증 3 휘발성 이유
기사, " [] 동시 프로그래밍 - 동시 프로그래밍 가시성, 자성, 주문 문제 "코드가 트리거 재정렬 때문에 여러 스레드 사이에 문제의 질서를 재현하고, 혜택과 재 배열을 설명하기를 입력합니다.
코드의 각 스레드는 아무것도, 어떤 순서 변경을 할 수 있다면 우리는 그들의 소원에 맞춰 코드를 작성하는 프로그래머를 원하는 상상 그 다음 고려해야 할 몇 가지 경우 -> 这将严重增加程序猿的负担!!!-> 때문에 规定某些情况下可以重排序,而有些情况下绝对不能重排序 就成了势在必行的事.
A는 질서의 원칙을 보장 할 수 휘발성 상황을 이해하기 전에 멀티 스레드에서의 모습을 보자 무엇을 한 번에 할 수없는 단일 스레드 경우 재주문.
3.1 단일 스레드로-IF 직렬 재정렬 규칙 금지
경우 직렬로-보인다 중국어로 번역, 주문한다 - 우리가-경우 직렬 단일 스레드 경우 규칙이 있기 때문에, 우리 자신의 단일 스레드 경우의 희망에 따라 실행할 수있는 코드를 작성하는 이유 위에서 아래로 라인으로 그 겉으로는 우리의 코드 실행 라인의 실행, 어떤이 재정렬되고있다.
의미 의미 시리얼로-경우 - 그것입니다 : CPU와 컴파일러 재정렬이 단일 스레드 프로그램 결과의 경우 올바른지 확인해야합니다 아무리.
다음과 같은 데이터 의존 관계는, 재 배열되지.
- 쓰기 후 읽기 :
int a = 1;
int b = a;
- 쓰기 쓰기 후
int a = 1;
int a = 2;
- 읽기, 쓰기
int a = 1;
int b = a;
int a = 2;
编译器和处理器不能对存在数据依赖关系的操作进行重排序- 사실,이 특정 규칙 인 AS-경우 시리얼. 이 때문에 재정렬의 결과를 변경합니다. 이러한 작업은 컴파일러와 프로세서를 다시 정렬 할 수있는 경우, 데이터의 부재는 작업 간의 종속성. 예를 들면 다음과 같습니다 :
int a = 1;
int b = 2;
int c = a + b;
C 및 데이터 의존성 간의 데이터 의존성 B와 C 사이에도 존재한다. 따라서, 명령어 실행의 최종 순서로, C가없는 (A), (B)의 전면에 재 배열한다. 하지만 A와 B 사이의 데이터 의존성 컴파일러 프로세서는 A와 B 사이의 순서를 재 배열을 수행하지 않을 수. 다음은 두 가지 프로그램의 실행 순서이다 :
可以这样:
int a = 1;
int b = 2;
int c = a + b;
也可以重排序成这样:
int b = 2;
int a = 1;
int c = a + b;
위의 예는 의미 컴파일러, 런타임 및 프로세서 우리가 느낄 수있는-경우 직렬을 준수 그들을 보호하기-경우 직렬 단일 스레드 프로그램 규칙에 따라 볼 수 있습니다 : 단일 스레드 프로그램의 외모 절차에 따라 실행 순서를 기록 라인 씩. - "우리는 단일 스레드 프로그램의 상황에 재 스케줄링 문제에 대한 걱정을 할 필요가 없습니다.
그러나 不同处理器之间和不同线程之间的数据依赖性编译器和处理器不会考虑- "이는 재정렬에 의한 절차 적 문제에 멀티 스레드 프로그램 순서 문제가 발생하는 이유입니다.
이상 3.1 스레드가 규칙을 재정렬 금지 발생-전에
3.1.1 발생-이전에 정의 된 규칙과 더 이해
실제로 일어나는-전에 룰 메모리 공개 규칙은 다음과 같이 정의되는 복수의 동작 중 :
이 일어나도 전에 동작하는 복수의 메모리 사이 항 공개 규칙. JMM에서 보이는 다른 동작에 대한 필요에 의해 수행되는 동작의 결과가 존재해야하는 경우 발생-전에 두 동작 간의 관계.
그러나이 발생-전에 함께 두 작업 사이의 관계, 사전 작업이 작동하기 전에 수행되어야한다는 것을 의미하지 않는다! 그것은-전에 일어나는 제 2 동작 전에 표시 및 시퀀싱 이전 작업 후의 동작 하나만 동작 (실행 결과) (첫 번째로 표시되는 두 번째 전에 명령)을 필요로하기 전에
또한 이해 :
위의 정의는, 사실,보기의 다른 지점 매우 모순 된 것 같다, 그것은이다.
- (1) 자바 프로그래머의 관점 서 : 조작자가 일어나도 전에 경우 다른 동작 JMM 보장하는 제 2 동작의 동작 후, 상기 실행 결과를 볼 수 있지만, 하나 개의 동작의 실행 순서 것 제 2 동작의 전방.
- 에 대한 컴파일러 및 프로세서의 각도에 서 (2) : JMM 허용은 둘 사이의 관계가-일어나기 전에 작업, 자바 플랫폼의 특정 구현이 지정된 순서가 발생-이전에 관련하여 수행 할 수있다 필요로하지 않는다있다. 관계가 수행되면 재정렬 후 결과로서 결과와 일치 전에 일어나도,이 재정렬이 허용된다.
3.1.2 발생-전에 규칙의 세부 사항
3.1.1를 읽은 후, 많은 사람들이 여전히 힘의 무지 같아요. . . 모든 지옥 아. . .
我想了很久觉得还是从禁止重排序的角度去理解比较好理解。
우리가 볼 옆에있는 특정 규칙 전에-발생 및 재정렬의 측면에서 금지되어 어떤 해석의 규칙 :
- (1) 프로그램 순서 규칙 (단일 스레드 규칙) : 각 동작 스레드가 일어나도 전에 스레드 후속 동작.
컴파일러 및 프로세서는 단일 스레드 경우 아래에 존재하는 데이터 의존성을 조작 할 수 있음으로-IF-직렬 규칙에 대해 사실상 다른 말로는 재정렬 않도록
- (2) 모니터 락 규칙 : 잠금을 잠금 해제, 발생-전에 잠금 이후의 잠금.
사실, 그 스레드가 다른 스레드가 잠금을 해제 할 때까지,이 잠금을 잡을 수 기다려야이다 -> 두 작업 사이에 순서가 될 수 없다
- (. 3) 휘발성 변수 규칙 : 휘발성 도메인을 작성, 발생-전에 다음 휘발성이 필드를 읽고.
3.1.2.1 참조
- (4) 전이는 A는 B-전에 일어나는, 및 B가 일어나는 경우 전에-C, A는 - 발생 전에 C.
이 말을 많이하지 않습니다. . .
- (5) () 규칙을 시작 다음 중 어느 발생-전에 조작 ThreadB.start는 () (스레드 B를 시작하는) 경우에 실행되는 스레드 A에 스레드 B, 다음 스레드 ThreadB.start () 동작.
재정렬 될 수 없다> 모두 반전 될 수 없다 - 사실, 즉, 스레드 B 오픈 후에 발생한다 실행될 운영 스레드 B 인
- (6) () 결합 규칙을 다음 스레드 A가 실행 작업 ThreadB.join () 반환이 성공적으로하고있는 다음의 발생-전에 경우 스레드 B 스레드 A에 () 작업에 ThreadB.join에서 성공적으로 반환합니다.
> 두가 내 기사의 또 다른 하나를 볼 수있는, 다시 정렬 할 수 없습니다 - 사실, 그 ThreadB.join ()이 코드 뒤에 작업, 스레드 B를 실행 한 후 발생할 수 있어야합니다 "[동시 프로그래밍] - Thread 클래스 "방법을 결합
- (7) 스레드 인터럽트 규칙 : 스레드 인터럽트 메소드가 호출 될 때 발생-전에 인터럽트 이벤트가 발생하는 인터럽트 스레드 코드를 탐지한다.
> 당신이 내 기사의 또 다른 하나를 볼 수있는 두, 다시 정렬 할 수없는 - 사실 만 스레드의 동작을 인터럽트 실행되는 스레드는 인터럽트 요청 스레드를 인식 할 수있다 "[] 동시 프로그래밍 - 인터럽트를 중단하고 사용 isInterrupted "상세
나는 파란색 글꼴에 따라 관점이 발생-전에 당신이 그것을 확실히 물론, 이해하기 쉬울 것입니다 지배 믿고, 특히 (2), 쓰레기 같은 규칙이 많이있는 것처럼 당신은,,, (6) (5) (4)를 느낄 수 있습니다 몇 가지 규칙이있다 (7). -> 그러나 우리가 인과 관계를 호출하고 컴퓨터가 이해할 수있는 알 ->이 규칙은 우리가 작성하는 코드는 우리의 소원에 따라 수행 될 수 있도록하는 것이었다 정확하게 때문에.
휘발성 + 질서 확신 할 수있는 이유 3.1.2.1 휘발성 변수 규칙은 다음 이해 ★★★
나는 휘발성 변수 규칙 3.1.2에 설명 된 모습, 네 개의 5 또는 6을 볼 수 있다고 생각합니다. . .
재정렬 휘발성 변수 규칙에서 어디를 직접 시작합니다.
휘발성 변수는 다음 테이블에서 찾을 수 있습니다 규칙을 재정렬 :
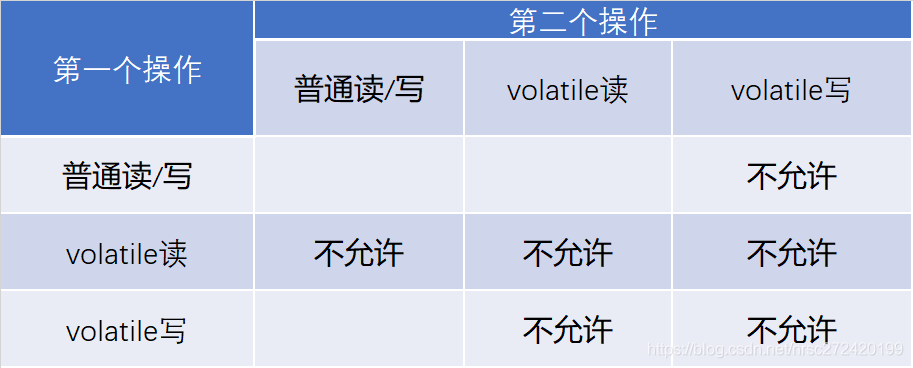
요약 :
- 제 2 동작은 기입 휘발성 시간 (1), 재정렬 될 수없는 제 1 동작이 무엇인지에 관계없이. 이전에 컴파일되지 않습니다 휘발성 쓰기 작업이 쓰기에 주문 후 변동성이 생각하는 것을이 규칙은 보장합니다.
- (2) 상기 제 1 동작은 휘발성 판독 시간 일 때, 제 2 동작이 무엇인지에 상관없이, 재 배열 될 수 없다. 휘발성 읽기 작업은 주문 후 컴파일되지 않습니다이 규칙은 보장하지만 휘발성 전에 읽어 낙담.
- 상기 제 1 기록 동작은 휘발성, 휘발성의 제 2 동작은 (3)의 판독, 리오 더링이다.
사실, 상기 규칙은 다음 표에 의해 표현 될 수있다 :
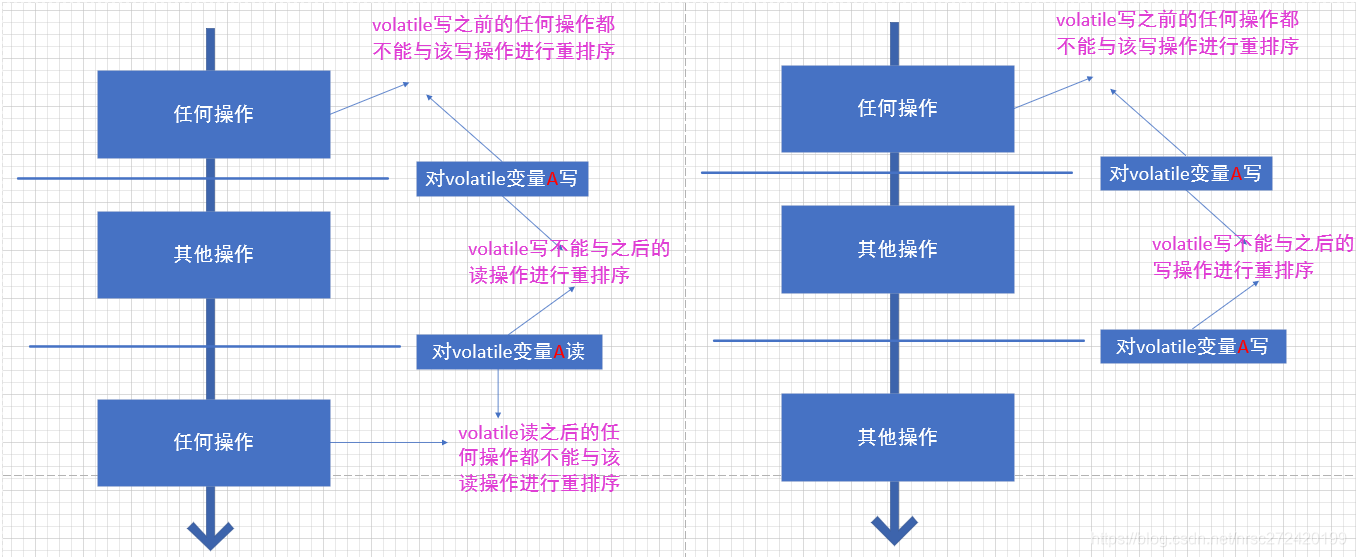
당신은 당신의 앞에 쓸 것을 인식 할 수없이 내 뒤에 당신이이 휘발성 공유 변수 쓰기의 앞에만큼, 읽어 또는 쓰기 -> :이 그림에서, 당신은 또한 결론을 얻을 수 있다고 생각
其实从这个角度也可以解释为什么volatile可以保证线程的可见性★★★
여기에 순수 이론은 주문 캔 보증에 대한 휘발성 이유를 분석합니다 :
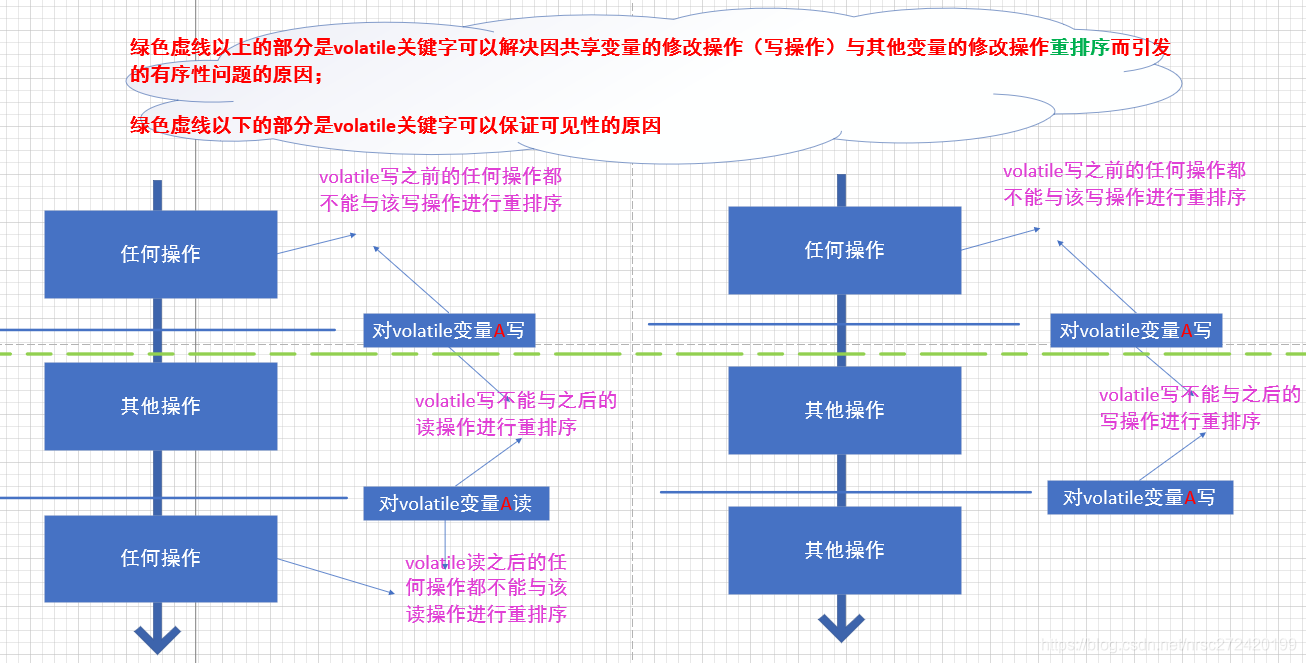
첫째로, 다른 변수를 수정 (또는 기록)하고 있기 관점 위의 두 실시 예에서, 그 이유는 규칙적인 문제가 될 것이다 目标共享变量수정하는 재 배열이 발생하고, 타겟 후 휘발성 키워드와 함께 공유 변수 다른 변수는 될 수 없다, 수정 加上volatile关键字的目标共享变量때문에 표시되지 않습니다 재정렬 수정由于重排序导致的我们写的代码和实际运行生成的结果不一致的问题了。
사실, 당신은 내가 여기에 후 위 그림을 그린 주석의 다음과 같은 분석을 수행 할 수 있습니다 ★★★
기본 원칙 3.1.2.2 휘발성 실현 재정렬 (또는 이론) 금지 - 메모리 장벽을
휘발성 변수 들어 발생이 자바 바이트 코드는 명령 시퀀스에 삽입한다 컴파일러 内存屏障프로세서 재정렬 문제의 특정 유형을 억제한다.
메모리 장벽은 다음과 같은 네 가지 유형이 있습니다

: 예는 그림이 이해하는 그릴의 끝에서 게이샤 메모리 장벽, LoadLoad 메모리 장벽 여기에
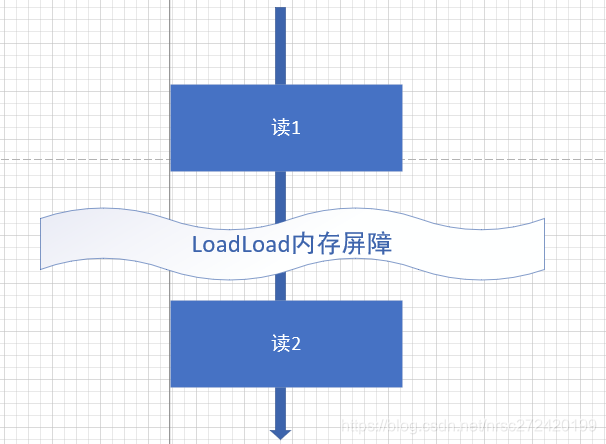
당신이 LoadLoad 메모리 장벽을 추가 한 경우, 다음 (21) 읽기 1 ~ 2를 읽고 읽고 읽을 수 없습니다 당시 분류 재 - "이것은 소위 메모리 장벽이다.
휘발성 키워드를 들어, 다음 작업은 사양 (겉으로는 모든 데이터가 말하는)에 따라 될 것입니다 :
각 쓰기 휘발성하기 전에 StoreStore, 쓰기를 삽입 한 후하는 StoreLoad를 삽입
각 휘발성 읽기, 삽입 및 LoadStore LoadLoad 후
其实这里我有一个疑问: 전면 3.1.2.1 말한다 지금 :
두 번째 작업이 글을 쓰는 휘발성 시간 때에 상관없이 다시 정렬 할 수없는 첫 번째 작업 것입니다. 이전에 컴파일되지 않습니다 휘발성 쓰기 작업이 쓰기에 주문 후 변동성이 생각하는 것을이 규칙은 보장합니다.
StoreStore 휘발성 쓰기 전에 삽입 된,뿐만 아니라이는 이전의 쓰기와 휘발성 기록 할 수 없습니다 재정렬 보장하는 것입니다? ? ? 보장은 할 수 없습니다 재주문이 휘발성 앞에 읽기 및 쓰기 수없는 이유는 무엇입니까? ? ? -> 페인트로 다음과

환영 귀하의 의견을 기대하고! ! !
顺便多说一句: 우리는 일반적으로 프로세서 일반적으로 X86을 사용, 그것은 순전히 명령 만 StoreLoad 사실이다.
3.1.2.3 휘발성 특정 구현 - 잠금 접두사 지침
특정 개방 클래스의 다음 비디오 내용 :
접두사 다음 unsafe.cpp 오픈 JDK 소스 코드의 분석을 통해, 당신은 "잠금"이 수정 된 휘발성 키워드 변수를 찾을 수 있습니다.
Lock前缀指令并不是一种内存屏障,但是它能完成类似内存屏障的功能. 잠금 캐시 및 CPU 버스를 잠글 것이다 될 수
는 CPU 인스트럭션 레벨 잠금 것으로 이해되어야한다. ->也就是说真正实现内存屏障功能的其实是Lock指令!!!
한편, 상기 데이터 처리 명령어는 현재 캐시 라인은 시스템 메모리에 직접 기록한다 설정하고, 라이트 - 백 캐시 메모리 처리 어드레스의 데이터를 초래할 수있는 다른 CPU에서 유효하지 않다.
특정 구현에서는 버스와 캐시를 고정하고, 후면 잠금을 새로 메인 메모리에 캐시 다시 더러운의 모든 데이터를 발표 할 예정이다 마지막으로 다음 명령을 실행하는 것입니다. 다른 CPU 읽고 잠금이 해제 될 때까지 쓰기 요청이 차단 될 때 잠금 버스에 잠겨.
사실, 같은 위의 두 단락의 내용이 문서 첫 번째 분석 부와 나는.
顺便多说一句:오늘은 열려있는 다른 클래스를 보았다, 그는 휘발성 구현이 잠금 접두사 지침 인 승리 시스템 말했다
다음과 같은 세 가지 시스템 레벨의 명령에 의해 수행되는 기본 리눅스 시스템을 달성하기 위해 :

구체적으로 어떻게 환영 여러분의 의견을 기대합니다! ! !
3.2 위의 예는 다음 바인딩 채팅 휘발성 질서를 보장하는 방법입니다
상기 실시 예 1 :
@Outcome(id = {"0, 1", "1, 0", "1, 1"}, expect = ACCEPTABLE, desc = "ok")
@Outcome(id = "0, 0", expect = ACCEPTABLE_INTERESTING, desc = "danger")
@State
public class OrderProblem2 {
int x, y;
/****
* 线程1 执行的代码
* @param r
*/
@Actor
public void actor1(II_Result r) {
x = 1;
r.r2 = y;
}
/****
* 线程2 执行的代码
* @param r
*/
@Actor
public void actor2(II_Result r) {
y = 1;
r.r1 = x;
}
}
전체 제로 이유 r.r1 및 r.r2 때문에, 실 1 및 2 스레드는 재정렬되어있을 수 있으므로, 다음 단, 스레드 1 2 스레드 후, r.r2 = Y로 수행되고 실행될 r.r1 = X, 그 값은 따라서 0이며, X 및 Y는, 할당되지 않았기 때문에 이번에 r.r1 및 r.r2 모두 제로 상황이 있었다.
그리고 가정하자 r.r1 및 r.r2이 때문에 다음, 휘발성 수정 r.r1 = x;하고 r.r2 = y;다음 전면 쓰기 작업입니다 x =1;및 y=1;작업이 재 배열로 수행 할 수없는, 그것은 r.r1 및 r.r2을 보장하지 않습니다 따라서이 경우는 해결할> - 가능성은 0이다由于重排序导致的我们写的代码和实际运行生成的结果不一致的问题。
(2) 위의 예제, 다음의 코드는, 그것의 자신의 분석에 관심이 있습니다.
@Outcome(id = {"1", "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@Outcome(id = "0", expect = Expect.ACCEPTABLE_INTERESTING, desc = "danger")
@State
public class OrderProblem1 {
int num = 0;
boolean ready = false;
/***
* 线程1 执行的代码
* @param r
*/
@Actor
public void actor1(I_Result r) {
if (ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
/***
* 线程2 执行的代码
* @param r
*/
@Actor
public void actor2(I_Result r) {
num = 2;
ready = true;
}
}
4 포스트 스크립트
이 기사를 작성할 때, 비디오 공개 수업을 많이보고 많은 정보를 읽어보십시오. . . 그러나 홀로 저를 설득 할 수있는 정보 또는 오픈 클래스 비디오의 어떤 사본의 부재, 정보 및 포괄적 인 비디오보기이 문서 때문에 많은 물론, 자신의 이해를 많이 포함되어 있습니다.
그것이 잘못이있는 곳이 발견되면 친애하는 독자, 당신은 매우 외침 지적 줘 오신 것을 환영합니다! ! !
