
Produzido por CDA Data Analyst
Autor: Mika
Dados: Zhenda
[Guia] Hoje, vou ensiná-lo a usar Python para analisar 170.000 barragens de "The Silent Truth". Passaram-se menos de 2 meses desde que o último drama de consciência doméstica "The Hidden Corner" foi exibido. O "Bald Terrier" e "Mountain Terrier" ainda estão frescos. Em seguida, outro drama doméstico de sucesso veio, e foi "The Silent Truth", que recentemente estourou de boca em boca.

Também do "Teatro da Névoa" de iQIYI para esquetes de suspense, "The Silent Truth" é uma adaptação do romance de Zijin Chen "Long Night is Difficult to See" e diz ao promotor Jiang Yang, que passou muitos anos para descobrir a verdade do caso. história.
No dia da transmissão, "The Silent Truth" marcou 8,8 pontos em Douban. Com a transmissão da série, a reputação da série era imparável e subiu até o fim. Após seis episódios, Douban marcou 9,2 pontos, superando com sucesso sua onda anterior. O canto escondido. Você sabe, essa tendência de dirigir alto e andar alto é muito rara nos dramas domésticos.
Muitos internautas não acreditaram que chorariam no início do show, mas quando viram o final, perceberam que isso é bom demais para chorar. Ver a luz vivificante do protagonista Jiang Yang realmente fez as pessoas chorarem de Lanzhou Ramen ...

Então, por que essa "Verdade Silenciosa" tem uma grande reputação? Por que é o final anual do drama nacional? Hoje vamos usar Python para explicar isso para você.
01, Douban 9,2 pontos! Além da onda frontal "O canto oculto"
O último conhecido como o drama nacional de sucesso anual foi "The Hidden Corner", adaptado do romance de mistério de Zijin Chen - "Bad Child". "The Hidden Corner" foi transmitido com "Little White Boat". "Mountain Terrier" e "Bald Terrier" foram animados durante todo o verão.

Mais de 780.000 pessoas marcaram em Douban, e a pontuação final é de 8,9, o que é um resultado incrível.

Inesperadamente, nos últimos 2 meses, outro drama de suspense "The Silent Corner" se tornou popular por sua reputação contra o céu! Também foi adaptado do romance "Long Night Is Difficult to Know", do autor Zi Jin Chen, e marcou 8,8 pontos quando Douban começou a transmitir. À medida que as pontuações da transmissão estão ficando cada vez mais altas, mais de 200.000 pessoas já avaliaram, com uma pontuação de 9,2, que ultrapassou a onda anterior de "The Hidden Corner".

Análise de pontuação geral de Douban
Após uma análise mais aprofundada das classificações de público, descobrimos que:
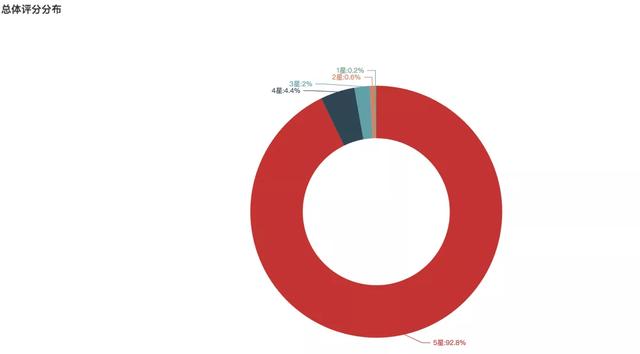
92,8% da audiência deu nota perfeita de cinco estrelas, que atingiu um patamar de referência em dramas nacionais.
Douban Short Commentary Word Cloud
Em seguida, veremos a nuvem de palavras de comentários curtos de Douban.

Podemos ver que o personagem principal "Jiang Yang" discutiu mais nos curtos comentários do público, sua firmeza e perseverança são verdadeiramente impressionantes. As "habilidades de atuação do ator", "o enredo" e o grau de redução ao "original" foram amplamente reconhecidos e elogiados.
02. Quais são as 170.000 telas de bala no drama "The Silent Truth"
Então, do que você está falando quando está fazendo o show? Em seguida, usamos Python para analisar a barragem de vídeo dos primeiros 10 episódios de "The Silent Truth", totalizando 173.226.
Os primeiros dez episódios de tendências de barragem

Como você pode ver na foto, todo mundo gosta de postar barragem ao assistir a um drama. Os primeiros dez episódios: o maior número de barragem é o episódio 9, episódio 3 e episódio 10. O número máximo de barragem em um episódio é 18903. O sexto episódio tem o menor barragem, com 15.561 barragens.
Então, olhamos para a nuvem de palavras dos personagens principais da peça:
Jiangyang Barrage Word Cloud

Jiang Yang, interpretado por Bai Yu, era originalmente jovem e promissor, mas para buscar a verdade e persistir na justiça, ele deu sua vida. Coisas como "justiça", "excelente", "habilidades de atuação" e assim por diante aparecem com frequência na nuvem de palavras.
Li Jing Barrage Word Cloud

Em relação a Li Jing, interpretado por Tan Zhuo, muitas pessoas pensariam em seu papel como Concubina Gao em "A História do Palácio de Yanxi" no drama. Seja de "Gao Guifei" a Liu Sihui em "Não sou o Deus da Medicina", ou desta vez, Li Jing, as habilidades de atuação de Tan Zhuo são óbvias para todos.
Yanliang Barrage Word Cloud

Desde o início do anúncio oficial do ator Liao Fan, muitos telespectadores disseram que deveriam assistir "The Silent Truth" para Liao Fan. Como esperado, assim que o episódio foi transmitido, os fãs o elogiaram como um "produto isento".
Nuvem de palavras da barragem de Zhang Chao

O professor Ning Li, que interpreta Zhang Chao, é um velho amigo do Fog Theatre. O "Irmão Toyota" social que ele interpretou em "Prova de Inocência" não é muito implacável. "Fumar reverso" é muito popular. De "Crimes Indocumentados" a "O Canto Escondido" e depois a "A Verdade Silenciosa", Yan Liang mudou três pessoas. É realmente Yan Liang fluindo e Li Fengtian .
03. Ensine como analisar barragem com Python
Usamos Python para obter e analisar os dados de barragem dos primeiros dez episódios de "The Silent Truth" de iQIYI. Todo o processo de análise de dados é dividido nas seguintes três partes:
- Aquisição de dados de barragem
- Leitura de dados e processamento simples
- Análise de visualização de dados
1. Aquisição de dados
O programa de aquisição de dados de barragem de iQiyi foi explicado no artigo anterior.
2. Leitura e pré-processamento de dados
Primeiro, importe os pacotes necessários, onde pandas é usado para leitura e processamento de dados, os é usado para operações de arquivo, jieba é usado para segmentação de palavras em chinês e pyecharts e stylecolud são usados para visualização de dados.
# 导入 库 import os import jieba import pandas as pd from pyecharts.charts import Bar, Pie, Line, WordCloud, Page from pyecharts importar opções como opts from pyecharts.globals import SymbolType, WarningType WarningType.ShowWarning = Falso importar stylecloud from IPython.display importar imagem
Armazene os dados rastreados na pasta de dados, use a operação os para obter a lista de arquivos csv que precisam ser lidos e leia os arquivos em um loop.
# 读 入 数据
data_list = os.listdir ('../ data /')
df_all = pd.DataFrame ()
para i em data_list:
if i.endswith ('csv'):
df_one = pd.read_csv (f '.. / data / {i} ', engine =' python ', encoding =' utf-8 ', index_col = 0)
df_all = df_all.append (df_one, ignore_index = False)
print (df_all.shape)
(173226, 6)
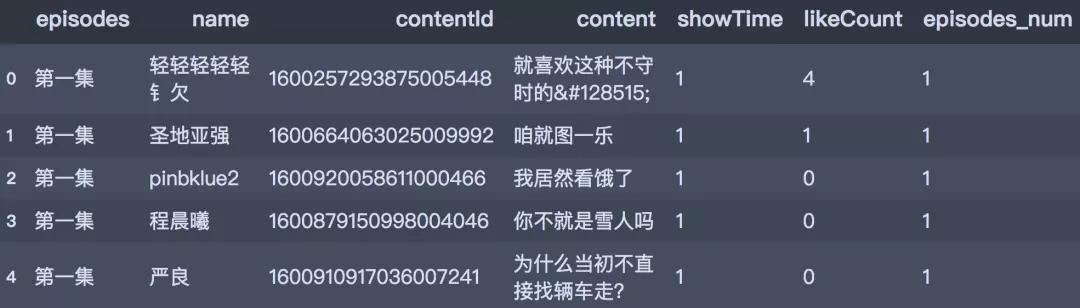
Há um total de 173226 barragens, por favor, visualize os dados:
df_all ['name'] = df_all.name.str.strip () df_all.head ()
3. Visualização de dados
—— Número de barragens de diversidade
Explicação do código:
repl_list = {
'O primeiro episódio': 1,
'O segundo episódio': 2,
'O terceiro episódio': 3,
'O quarto episódio': 4,
'O quinto episódio': 5,
'O sexto episódio': 6 ,
'Episódio Sete': 7,
'Episódio Oito': 8,
'Episódio Nove': 9 , 'Episódio
Dez': 10
}
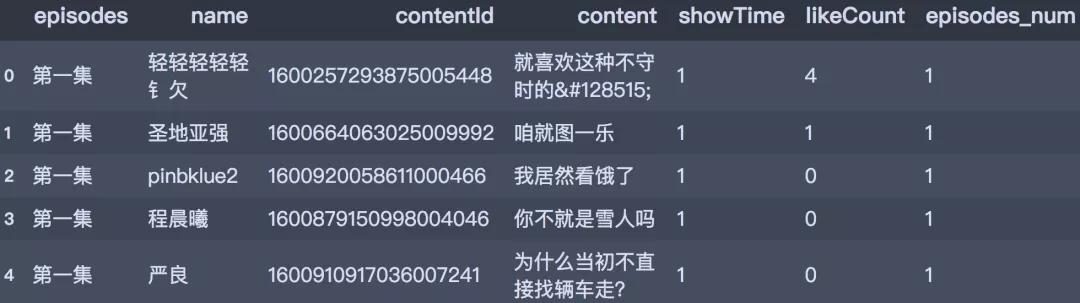
df_all ['episodes_num'] = df_all ['episódios']. Map (repl_list )
df_all.head ()
# Gerar dados
danmu_num = df_all.episodes_num.value_counts ()
danmu_num = danmu_num.sort_index ()
x_data = ['第' + str (i) + '集' para i em danmu_num.index]
y_data = danmu_num.values.tolist ()
# Gráfico de
barras bar1 = Bar (init_opts = opts.InitOpts (largura = '1350px', altura = '750px'))
bar1.add_xaxis (xaxis_data = x_data)
bar1.add_yaxis ('', y_axis = y_data)
bar1.set_global_opts ( title_opts = opts.TitleOpts (title = 'Gráfico de tendência de número de barragem dos primeiros dez episódios'),
visualmap_opts = opts.VisualMapOpts (max_ = 20000, is_show = False)
)
bar1.render ()
x_data = ['第' + str (i) + '集' para i em danmu_num.index]
y_data = danmu_num.values.tolist ()
# Gráfico de
barras bar1 = Barra (init_opts = opts.InitOpts (largura = '1350px' , height = '750px'))
bar1.add_xaxis (xaxis_data = x_data)
bar1.add_yaxis ('', y_axis = y_data)
bar1.set_global_opts (title_opts = opts.TitleOpts (title = 'Gráfico Barrage dos primeiros dez episódios' ),
visualmap_opts = opts.VisualMapOpts (max_ = 20000, is_show = False)
)
bar1.render ('../ html / Iqiyi Barrage Trend Chart.html')
Papel de barragem - mapa de nuvem de palavras de Jiangyang
# Defina a função de segmentação de palavras def get_cut_words (content_series): # leia a lista de palavras de parada stop_words = [] com open (r "stop_words.txt", 'r', encoding = 'utf-8') como f: lines = f. readlines () para linhas em linhas: stop_words.append (line.strip ()) # Adicionar palavras-chave my_words = ['Liao Fan', 'Yan Liang', 'Baiyu', 'Jiangyang', 'Tan Zhuo', 'Li Jing', 'Ning Li', 'Zhang Chao', 'Huang Yao', 'Zhang Xiaoqian', ' Aoli Ge ' ] para i em minhas_palavras: jieba.add_word (i) # Palavras- chave personalizadas my_stop_words = [ 'Realmente', 'este', 'este é', 'um tipo', 'tipo', 'ahhhhh', 'hahaha', ' Hahahaha ', 'Eu quero'] stop_words.extend (my_stop_words) # particípio word_num = jieba.lcut (content_series.str.cat (sep = '。'), cut_all = False) # 条件 筛选 word_num_selected = [i para i em word_num se eu não estiver em stop_words e len (i)> = 2] return word_num_selected
# Obtenha o resultado da segmentação de palavras text1 = get_cut_words (content_series = df_all [df_all.name == '江 阳'] ['content']) # Desenhe uma imagem de nuvem de palavras stylecloud.gen_stylecloud (text = ''. Join (text1), max_words = 1000, collocations = False, font_path = r'C: \ Windows \ Fonts \ msyh.ttc ', icon_name =' fas fa-heart ', size = 653, output_name =' Arraste o papel da tela-Jiangyang word cloud map.png ')