Diretório de artigos
Pré-importação
O NoSQL que conhecemos é um banco de dados não relacional. As soluções de integração de 10 tecnologias relacionadas são fornecidas na documentação oficial do springboot. Este artigo abordará várias das soluções de integração de banco de dados NoSQL mais populares no mercado doméstico, a saber:
- Redis
- MongoDB
- ISSO É
Os melhores casos de uso para as tecnologias acima são todos implantados em servidores Linux, mas ainda usamos a plataforma Windows neste artigo.
SpringBoot integra Redis
Introdução e instalação básica do Redis
O Redis é um banco de dados NoSQL na memória com uma estrutura de armazenamento de valor-chave:
- Suporta vários formatos de armazenamento de dados
- Persistência
- Suporte a clusters
Concentre-se no formato de armazenamento de dados, que é o formato de chave-valor, ou seja, a forma de armazenamento de pares de chave-valor. Diferentemente do banco de dados MySQL, o banco de dados MySQL possui tabelas, campos e registros, o Redis não possui essas coisas, ou seja, um nome corresponde a um valor, e os dados são armazenados principalmente na memória para uso. O que é armazenado principalmente na memória? De fato, o Redis tem suas soluções de persistência de dados, ou seja, RDB e AOF, mas o próprio Redis não nasceu para persistência de dados.
O Redis suporta uma variedade de formatos de armazenamento de dados, por exemplo, pode armazenar strings diretamente ou pode armazenar uma coleção de mapas, uma coleção de listas e algumas operações de dados em diferentes formatos serão envolvidas posteriormente
Endereço de download do pacote de instalação da versão do Windows: https://github.com/tporadowski/redis/releases
O pacote de instalação baixado tem duas formas, uma é o arquivo msi para instalação com um clique e a outra é o arquivo zip que pode ser usado após a descompactação.
O que é msi, na verdade, é um pacote de instalação de arquivos, que não apenas instala software, mas também ajuda a associar as funções necessárias para instalação de software e operações de pacotes. Como a sequência de instalação, criação e configuração de caminhos de instalação, configuração de dependências do sistema, configuração de opções de instalação por padrão e propriedades que controlam o processo de instalação. Para simplificar, é um serviço completo e o processo de instalação é uma operação única, que é um programa de instalação de software para usuários iniciantes.
Após a conclusão da instalação, você obterá os seguintes arquivos: Existem dois arquivos correspondentes a dois comandos, que são os comandos principais para iniciar o Redis e precisam ser executados no modo de linha de comando CMD.
iniciar o servidor
redis-server.exe redis.windows.conf
Aqui estamos usando a porta padrão 6379
iniciar o cliente
redis-cli.exe
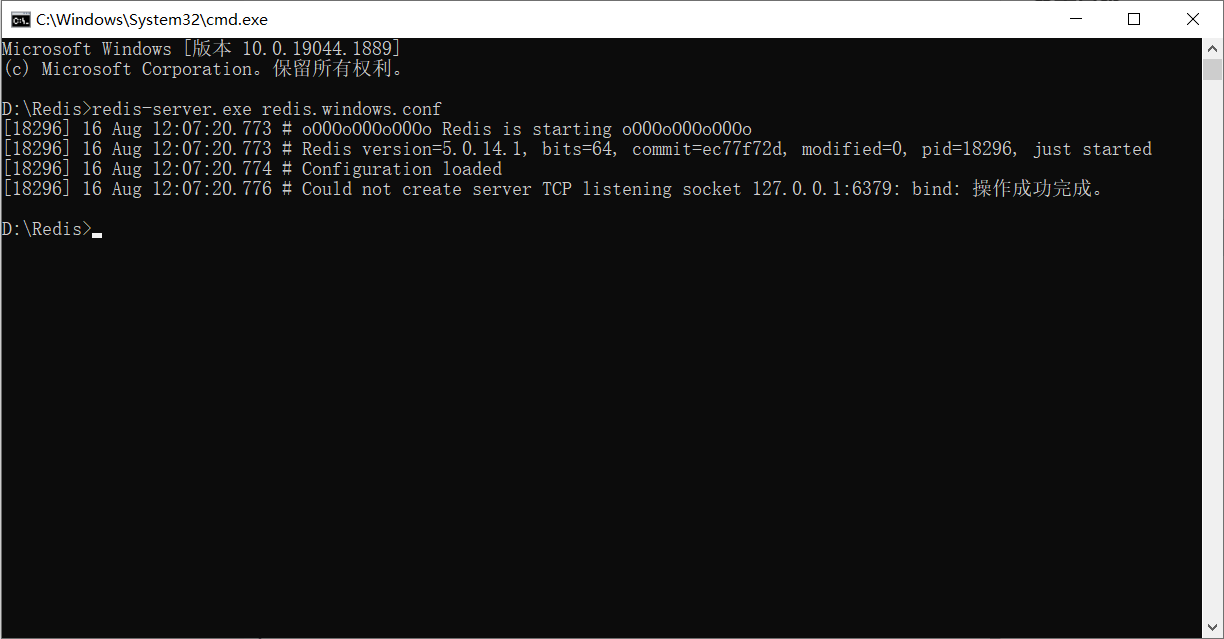
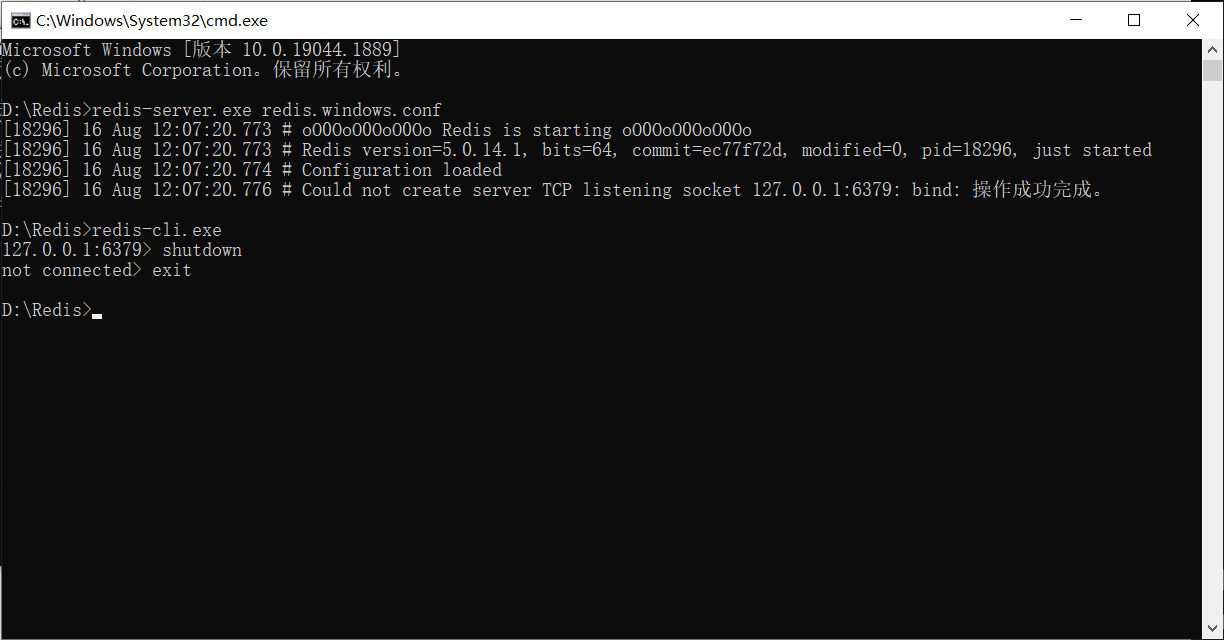
Se a inicialização do servidor redis falhar, você pode iniciar o cliente primeiro, depois executar a operação de desligamento e sair. Neste momento, o servidor redis pode ser executado normalmente.
Vamos demonstrar:
Primeiro inicie o servidor e descubra que a inicialização falhou:
Então continuamos:
vá abrir o servidor novamente, ok:
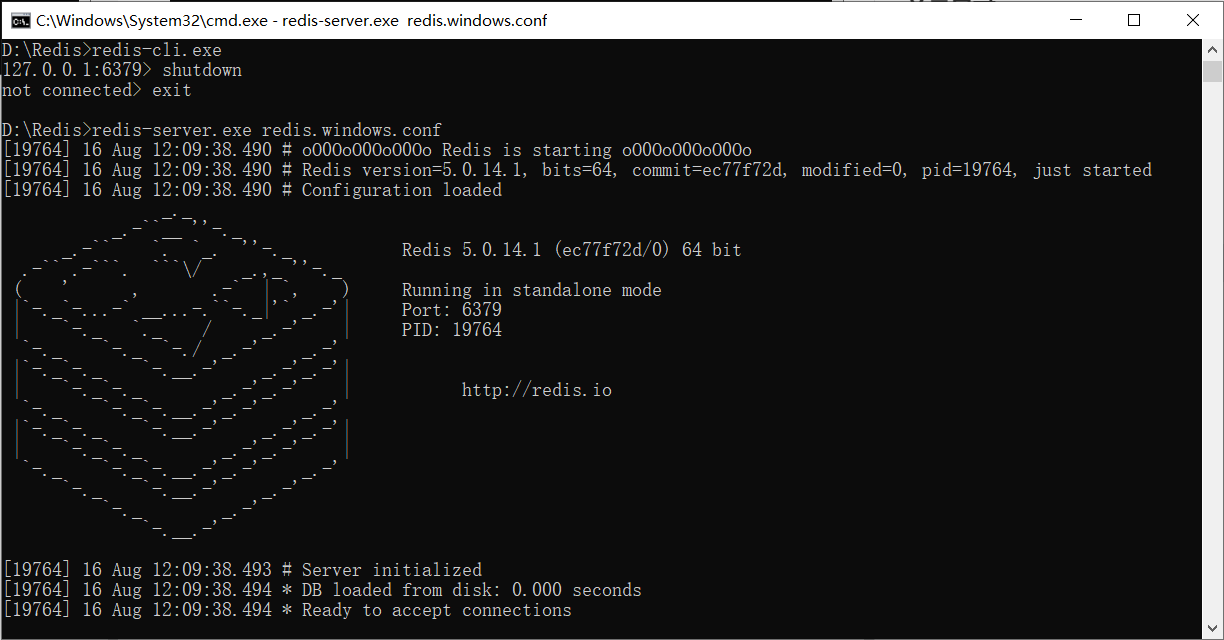
se esta imagem aparecer, significa que o servidor foi aberto com sucesso!
Operação basica
Depois que o servidor é iniciado, você pode usar o cliente para se conectar ao servidor, semelhante a iniciar o banco de dados MySQL e, em seguida, iniciar a linha de comando SQL para operar o banco de dados.
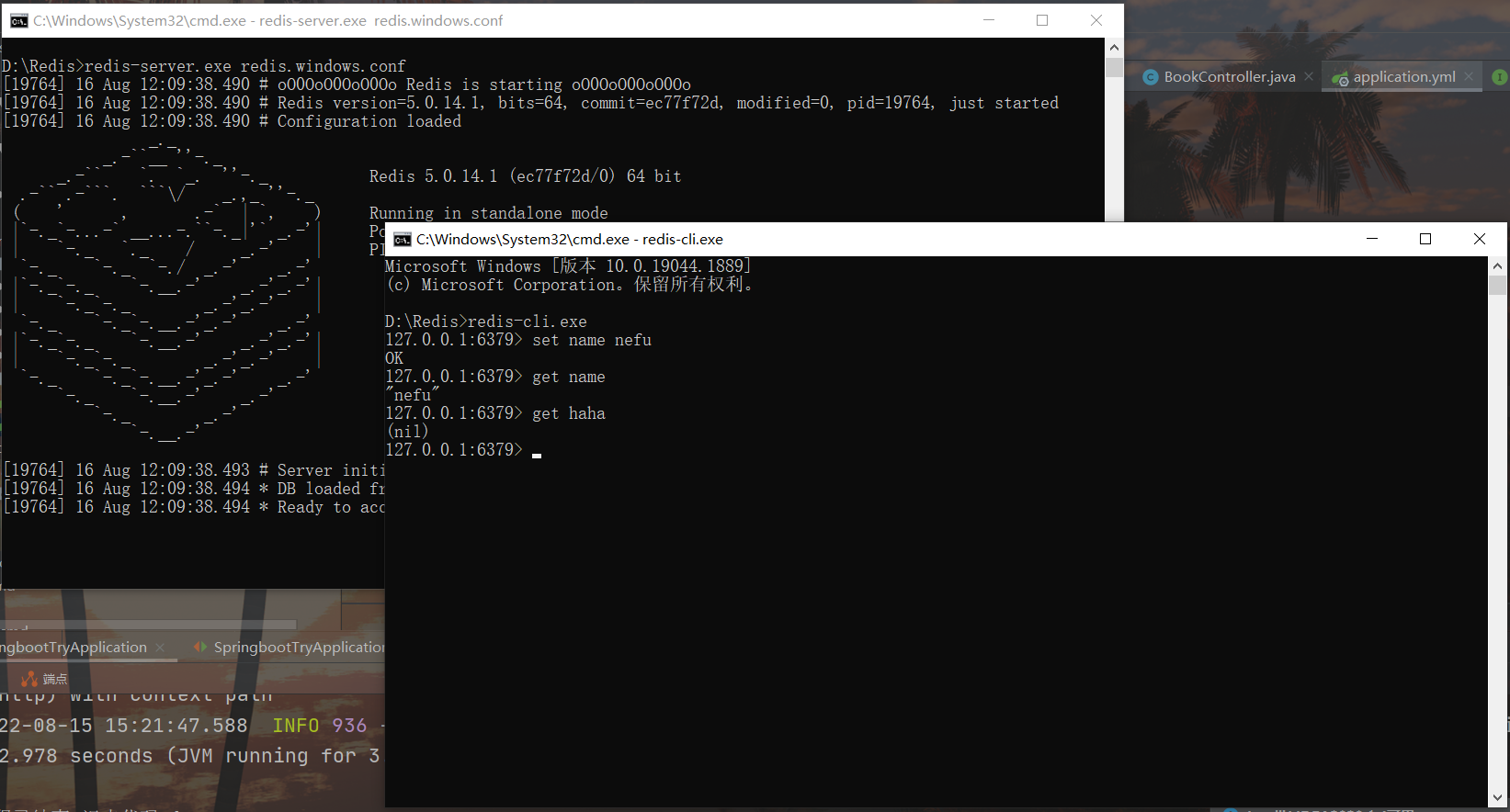
Coloque uma string de dados em redis, primeiro defina um nome para os dados, como nome, idade, etc., e depois use o conjunto de comandos para definir os dados para o servidor redis
set name nefu
set age 12
Retire os dados que foram inseridos do redis e obtenha os dados correspondentes de acordo com o nome. Se não houver dados correspondentes, obterá (nil)
get name
get age
Por exemplo:
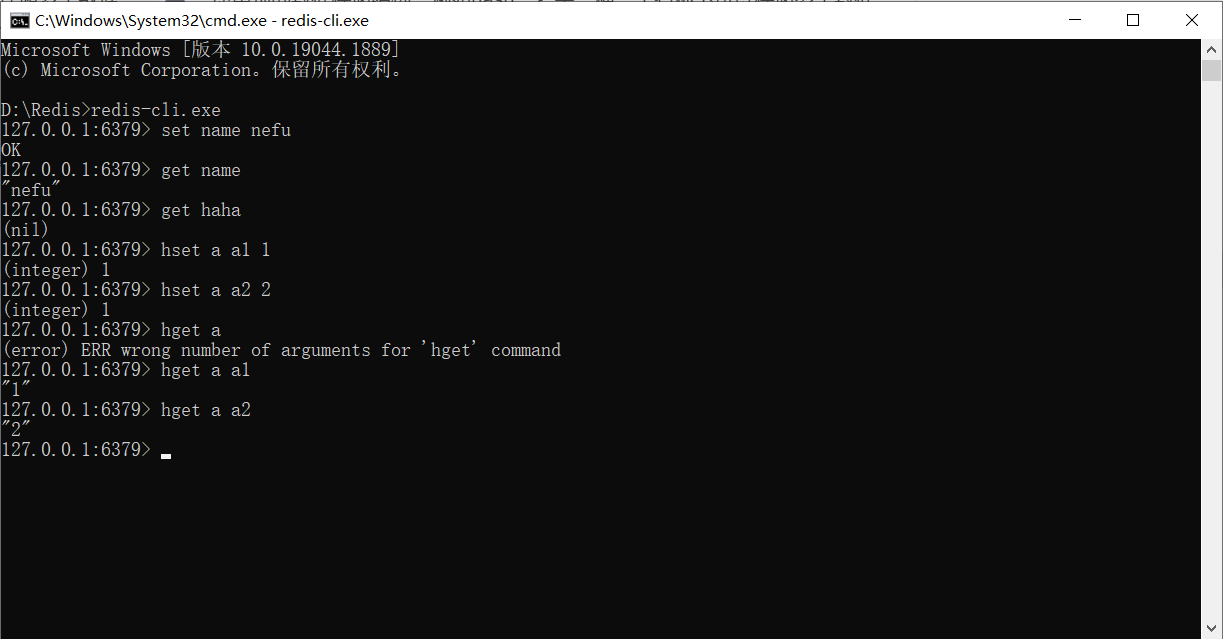
O armazenamento de dados usado acima é um nome correspondente a um valor. Se houver muitos dados a serem mantidos, outras estruturas de armazenamento de dados podem ser usadas. Por exemplo, hash é um modelo de armazenamento que pode armazenar vários dados com um nome e cada dado também pode ter seu próprio nome de armazenamento secundário. O formato de armazenamento de dados na estrutura de hash é o seguinte:
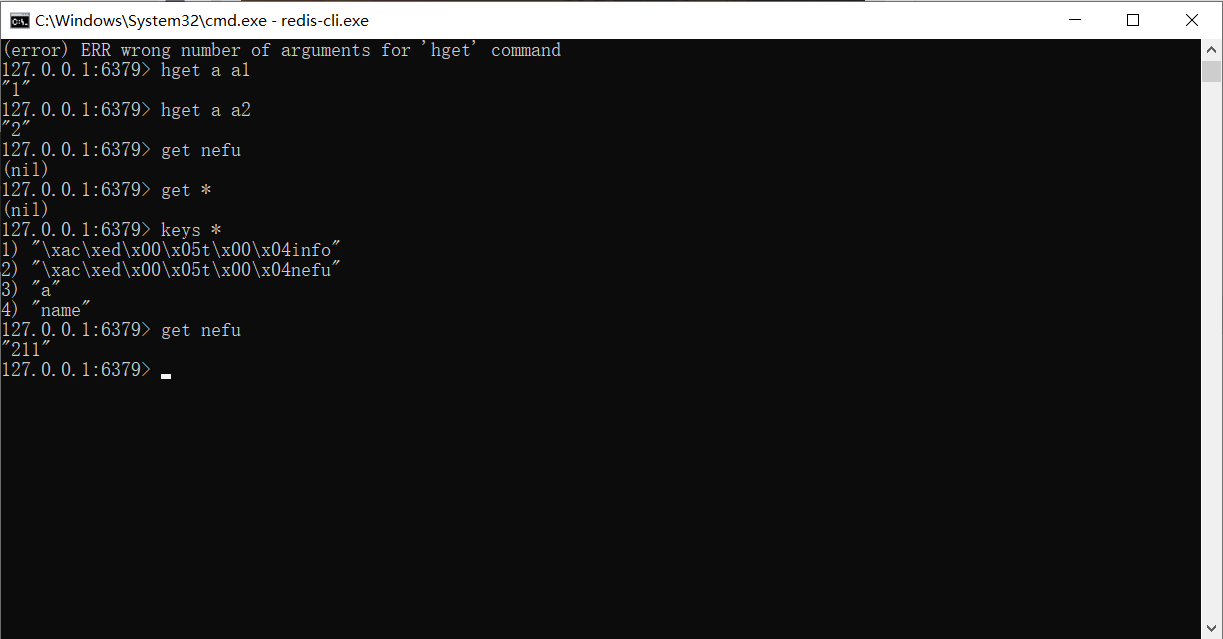
hset a a1 aa1 #对外key名称是a,在名称为a的存储模型中,a1这个key中保存了数据aa1
hset a a2 aa2
O comando para obter os dados na estrutura de hash é o seguinte
hget a a1 #得到aa1
hget a a2 #得到aa2
Observe que você não pode obter um
Por exemplo:
Aqui abordamos apenas algumas operações simples sobre o Redis
Integrar
Antes da integração, vamos resolver a ideia de integração. O Springboot integra qualquer tecnologia para usar a API da tecnologia correspondente no springboot. Se as duas tecnologias não se cruzam, não há conceito de integração. A chamada integração é na verdade o uso da tecnologia springboot para gerenciar outras tecnologias. Vários problemas não podem ser evitados:
-
Primeiramente, as coordenadas da tecnologia correspondente precisam ser importadas primeiro e, após a integração, essas coordenadas sofrem algumas alterações
-
Em segundo lugar, qualquer tecnologia geralmente tem algumas informações de configuração relacionadas. Após a integração, como e onde gravar essas informações é um problema
-
Terceiro, se a operação antes da integração for o modo A, se não trouxer algumas operações convenientes para os desenvolvedores após a integração, a integração não terá sentido. Portanto, a operação após a integração deve ser simplificada e o modo de operação correspondente será naturalmente diferente. diferente
É uma ideia geral pensar na integração de todas as tecnologias do springboot de acordo com as três questões acima. No processo de integração, vamos descobrindo gradativamente a rotina de integração, e a aplicabilidade é muito forte. Após a integração de várias tecnologias, basicamente pode resumir um conjunto de pensamento fixo.
Vamos começar a integrar o redis com o springboot. Os passos da operação são os seguintes:
Etapa 1 : Importe as coordenadas iniciais do springboot para integrar o redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
As coordenadas acima podem ser selecionadas verificando ao criar um módulo e pertencem à categoria NoSQL.

Etapa 2 : Execute a configuração básica
spring:
redis:
host: localhost
port: 6379
Para operar o redis, a informação mais básica é qual servidor redis operar, então o endereço do servidor pertence às informações básicas de configuração e é indispensável. Mas mesmo que você não o configure, ele ainda está disponível agora. Porque os dois conjuntos de informações acima têm configurações padrão, que são exatamente os valores de configuração acima.
Etapa 3 : Use o springboot para integrar a operação da interface do cliente dedicada do redis, aqui está o RedisTemplate
@SpringBootTest
class Springboot16RedisApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
void set() {
//首先决定要操作哪种数据类型
ValueOperations ops = redisTemplate.opsForValue();
ops.set("age",41);
}
@Test
void get() {
ValueOperations ops = redisTemplate.opsForValue();
Object age = ops.get("name");
System.out.println(age);
}
@Test
void hset() {
HashOperations ops = redisTemplate.opsForHash();
ops.put("info","a","csdn");
}
@Test
void hget() {
HashOperations ops = redisTemplate.opsForHash();
Object val = ops.get("info", "a");
System.out.println(val);
}
}
Dois conjuntos de resultados get/set:
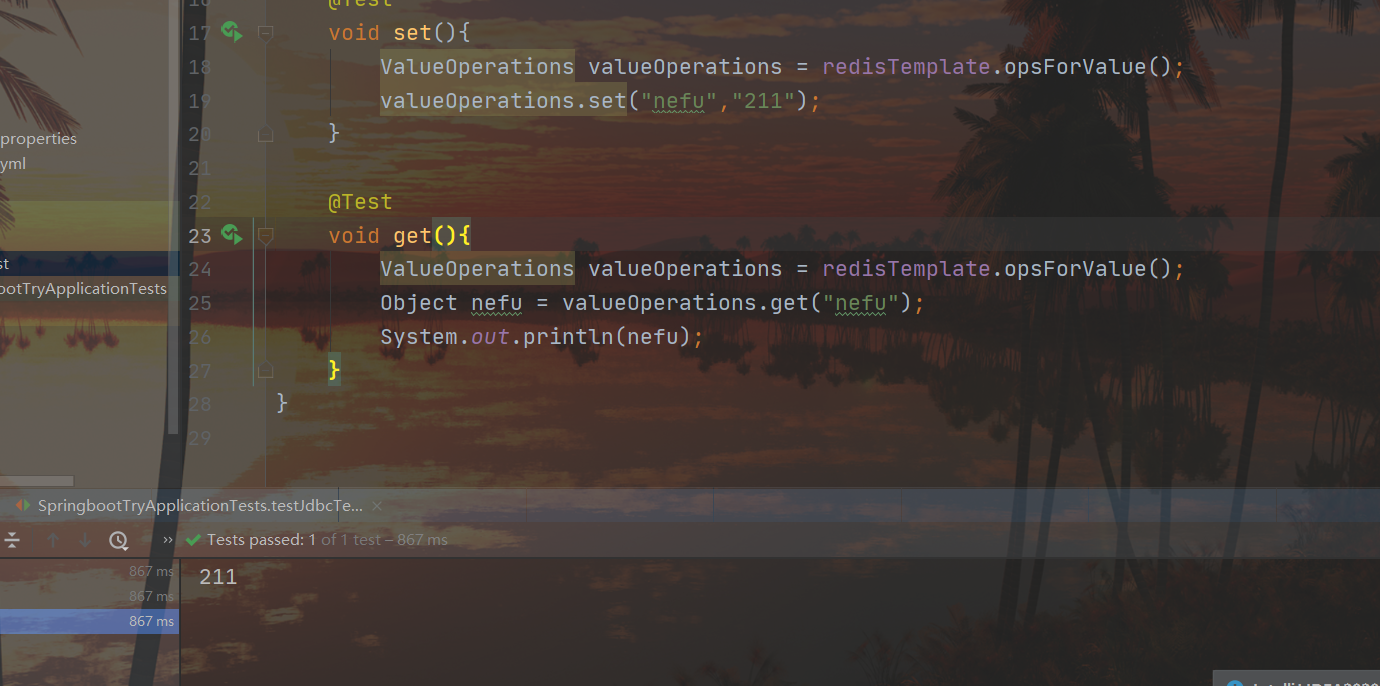
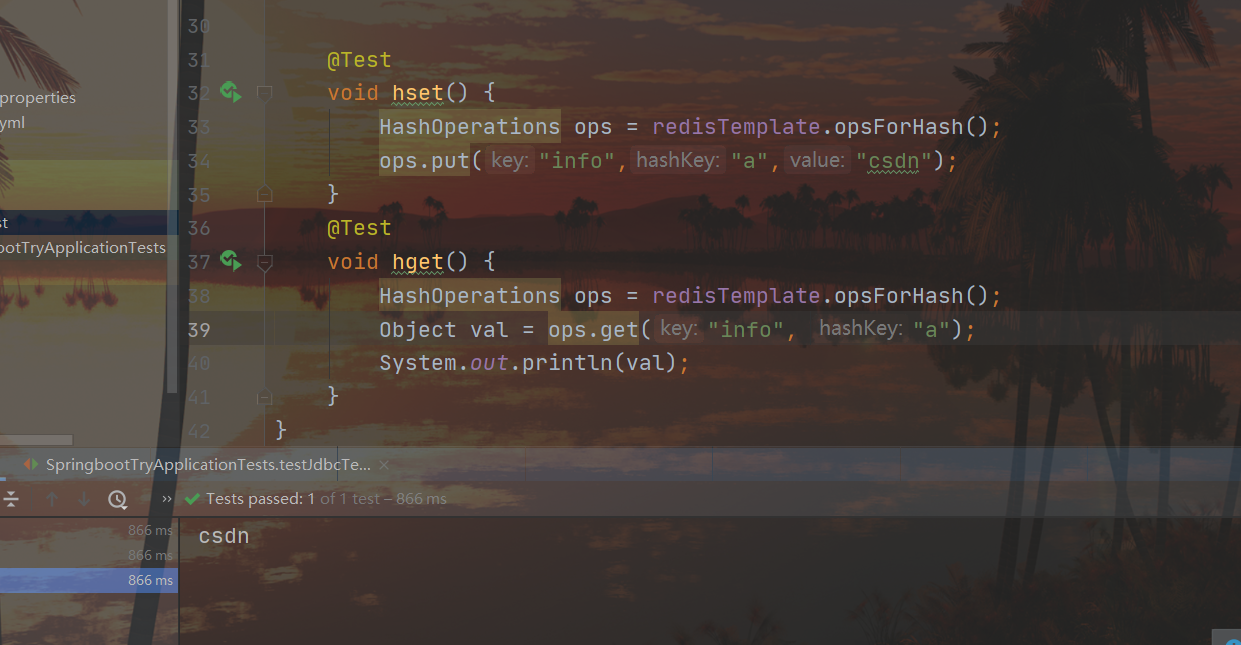
Ao operar o redis, você precisa confirmar que tipo de dados operar e obter a interface de operação de acordo com o tipo de dados. Por exemplo, use opsForValue() para obter a interface de operação de dados do tipo string, use opsForHash() para obter a interface de operação de dados do tipo hash e o resto é chamar a operação api correspondente. Vários tipos de interfaces de manipulação de dados são os seguintes:
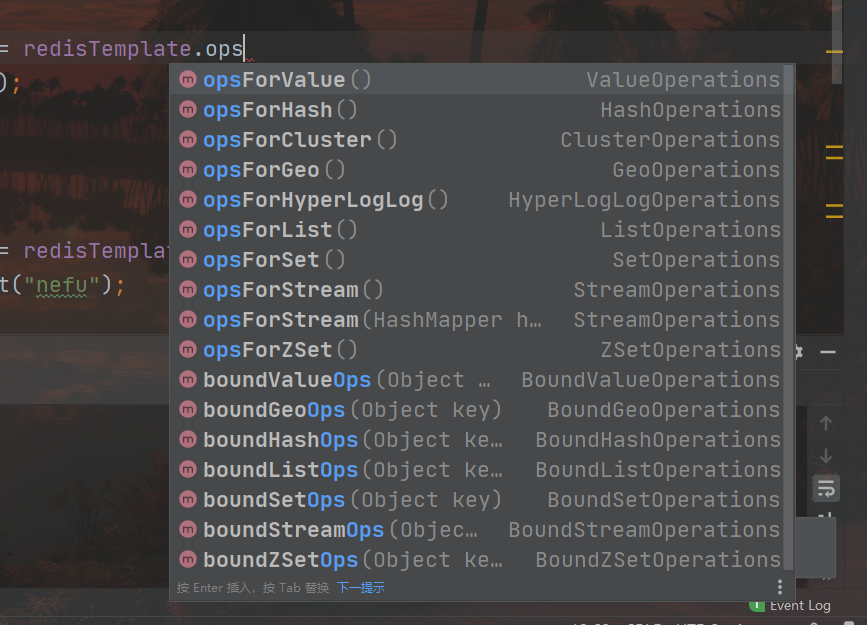
Resumir
- Springboot integra etapas redis
- Importe as coordenadas iniciais do springboot para integrar o redis
- Faça a configuração básica
- Use o springboot para integrar a operação RedisTemplate da interface de cliente dedicada do redis
Há um ponto a ser observado aqui: quando procuramos o par chave-valor que acabamos de adicionar no teste no cliente Redis, não podemos encontrá-lo. Não porque não foi adicionado, mas por causa de um problema de tipo de dados. Podemos usar o comando para visualizar todas as chaves armazenadas neste momento:
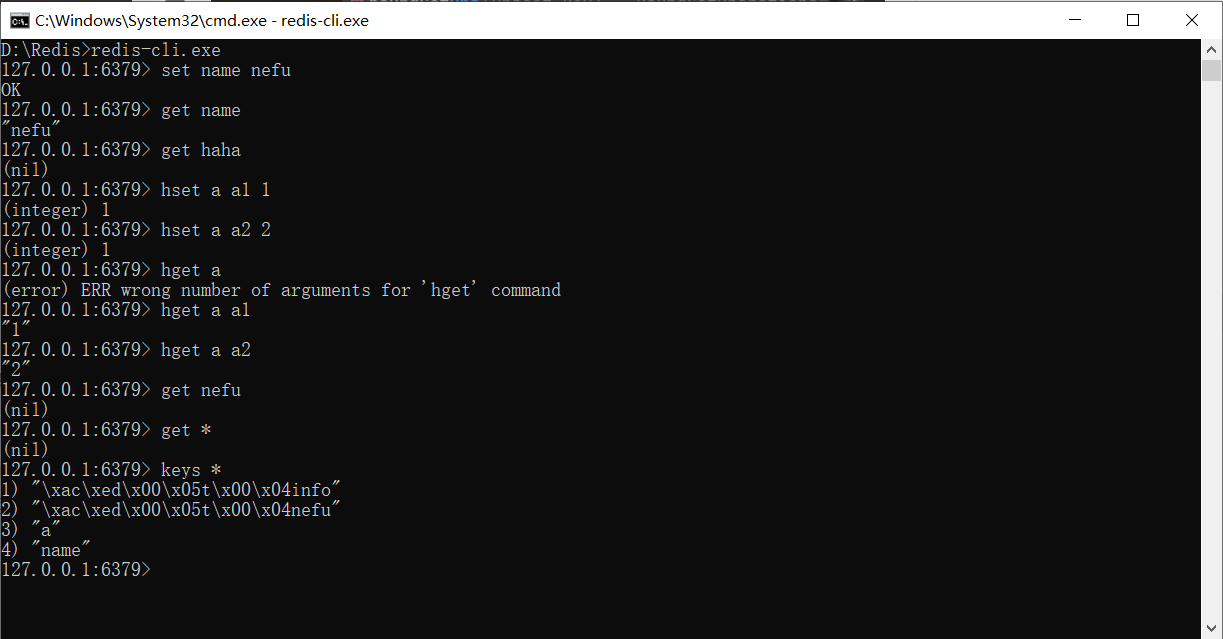
descobrimos que não é que elas não possam ser encontradas, mas porque são armazenadas na forma de objetos e serializadas pelo Redis usando um método especial, então inserimos diretamente caracteres Strings não podem ser encontrados.
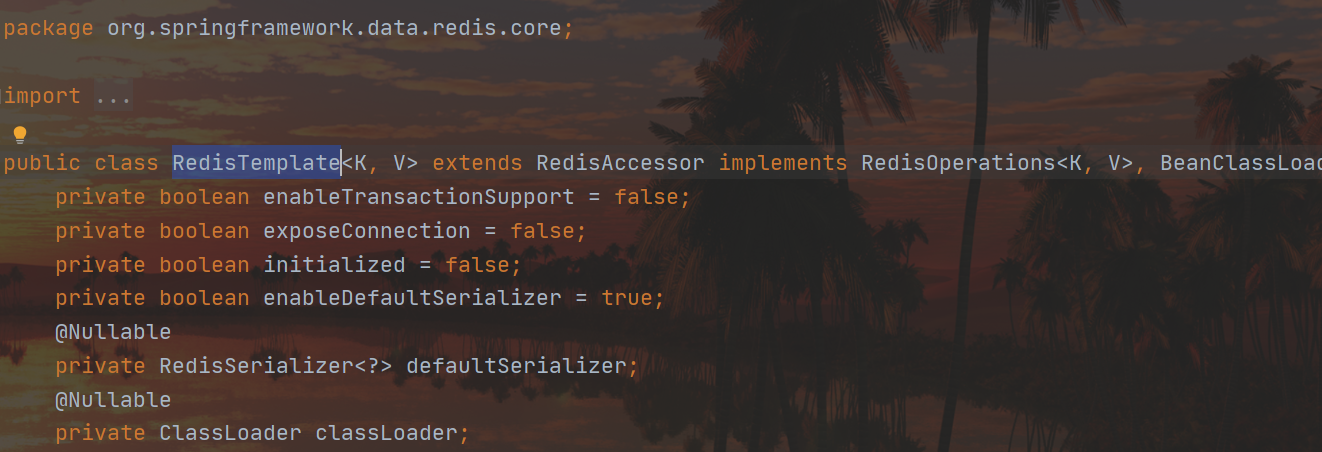
Também podemos vê-lo em RedisTemplate:
genéricos são usados aqui, e quando não escrevemos nada, é tratado como um objeto Object
Para evitar isso podemos usar StringRedisTemplate:
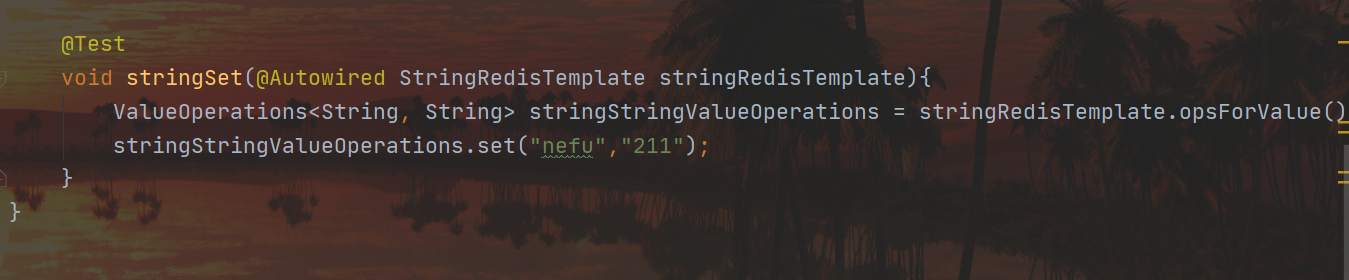
Então podemos encontrar:
SpringBoot integra MongoDB
Introdução e instalação básica do MongoDB
O uso da tecnologia Redis pode melhorar efetivamente a velocidade de acesso aos dados, mas devido ao formato de dados único do Redis, ele não pode operar dados estruturados.Ao operar dados do tipo objeto, o Redis é esticado . No caso de garantir a velocidade de acesso, se você deseja operar dados estruturados, parece que o Redis não atende aos requisitos, neste momento, uma nova estrutura de armazenamento de dados precisa ser usada para resolver esse problema.
MongoDB é um banco de dados de documentos de código aberto, de alto desempenho e sem esquema, que é um dos produtos de banco de dados NoSQL.é um banco de dados não relacional que é mais parecido com um banco de dados relacional.
Das poucas palavras na descrição acima, as mais desconhecidas para nós não têm padrão. O que é sem modelo? Simplificando, como um banco de dados, não há estrutura fixa de armazenamento de dados. A primeira parte dos dados pode ter 3 campos de A, B e C, a segunda parte dos dados pode ter 3 campos de D, E e F, e o terceiro dado pode ter 3 campos, os dados podem ser campos A, C, E3, ou seja, a estrutura dos dados não é fixa, o que não é esquema . Algumas pessoas vão dizer para que serve isso? Flexível, altere a qualquer momento, sem restrições. Com base nas características acima, o lado do aplicativo do MongoDB também passará por algumas mudanças. A seguir, listamos alguns cenários em que o MongoDB pode ser usado como armazenamento de dados, mas não é necessário usar o MongoDB:
-
Dados do usuário Taobao
- Local de armazenamento: banco de dados
- Características: Armazenamento permanente, frequência de modificação extremamente baixa
-
Dados de equipamento de jogo, dados de suporte de jogo
- Local de armazenamento: banco de dados, Mongodb
- Características: combinação de armazenamento permanente e armazenamento temporário, alta frequência de modificação
-
Dados de transmissão ao vivo, dados de recompensa, dados de fãs
- Local de armazenamento: banco de dados, Mongodb
- Características: Combinação de armazenamento permanente e armazenamento temporário, a frequência de modificação é extremamente alta
-
Dados de IoT
- Local de armazenamento: Mongodb
- Características: Armazenamento temporário, frequência de modificação rápida

Após um breve entendimento do MongoDB, vamos falar sobre sua instalação.
Endereço de download do pacote de instalação da versão do Windows: https://www.mongodb.com/try/download
O pacote de instalação baixado também tem dois formulários, um é o arquivo msi para instalação com um clique e o outro é o arquivo zip que pode ser usado após a descompactação.
Após a descompactação, você obterá os seguintes arquivos, onde o diretório bin contém todos os comandos executáveis do mongodb

O mongodb precisa especificar um diretório de armazenamento de dados em tempo de execução, então crie um diretório de armazenamento de dados, geralmente colocado no diretório de instalação, onde o diretório de dados é criado para armazenar os dados (também criamos uma pasta db na pasta de dados. para armazenar dados), como segue

Se a seguinte mensagem de aviso aparecer durante o processo de instalação, ela informa que seu sistema operacional atual está faltando alguns arquivos do sistema, então não se preocupe com isso.

A solução pode ser resolvida de acordo com a seguinte solução: Procure no navegador o arquivo correspondente ao nome ausente, baixe-o, copie o arquivo baixado para o diretório system32 do diretório de instalação do Windows e execute o comando regsvr32 na linha de comando para registrar o arquivo. Dependendo do nome do arquivo baixado, altere o nome correspondente antes de executar o comando.
regsvr32 vcruntime140_1.dll
iniciar o servidor
mongod --dbpath=..\data\db
Ao iniciar o servidor, você precisa especificar o local de armazenamento de dados, que pode ser definido através do parâmetro –dbpath.Você pode definir o caminho de armazenamento de dados de acordo com suas necessidades.Porta de serviço padrão 27017.
Então, quando entrarmos na pasta db em data, encontraremos algo mais:
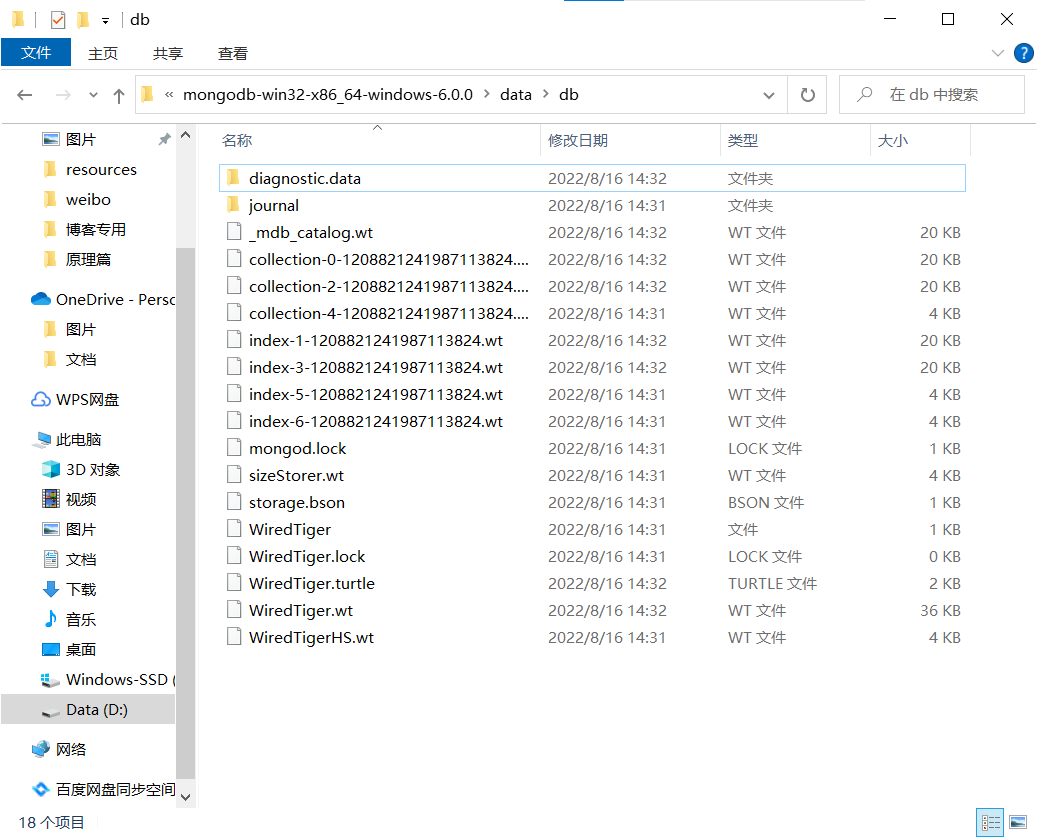
esses arquivos são gerados apenas uma vez para inicialização e não serão gerados novamente quando o servidor for iniciado posteriormente.
Em seguida, iniciamos o cliente novamente:
iniciar o cliente
mongo --host=127.0.0.1 --port=27017
Como nossas configurações são todas padrão, ao executar,
mongotambém é possível
A seguinte interface aparece para indicar sucesso:
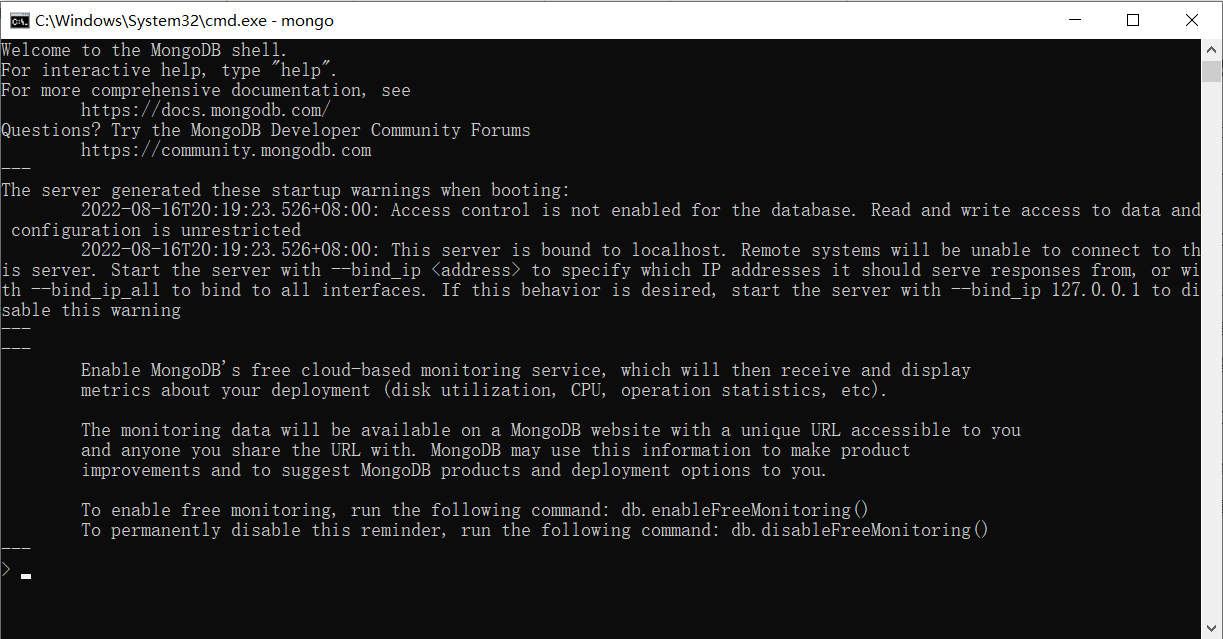
Cuidado para não desligar o servidor, as duas janelas cmd devem existir ao mesmo tempo
Operação basica
Embora o MongoDB seja um banco de dados, suas operações não são executadas usando instruções SQL, então você pode não estar familiarizado com o método de operação. Felizmente, existem alguns softwares cliente de banco de dados semelhantes ao Navicat, que podem operar facilmente o MongoDB. Instale um cliente e, em seguida, operar o MongoDB.
Existem muitos softwares do mesmo tipo. O software a ser instalado desta vez é o Robo3t. O Robot3t é um software verde, que pode ser descompactado sem instalação. Após a descompactação, entre no diretório de instalação e clique duas vezes em robot3t.exe para usá-lo.
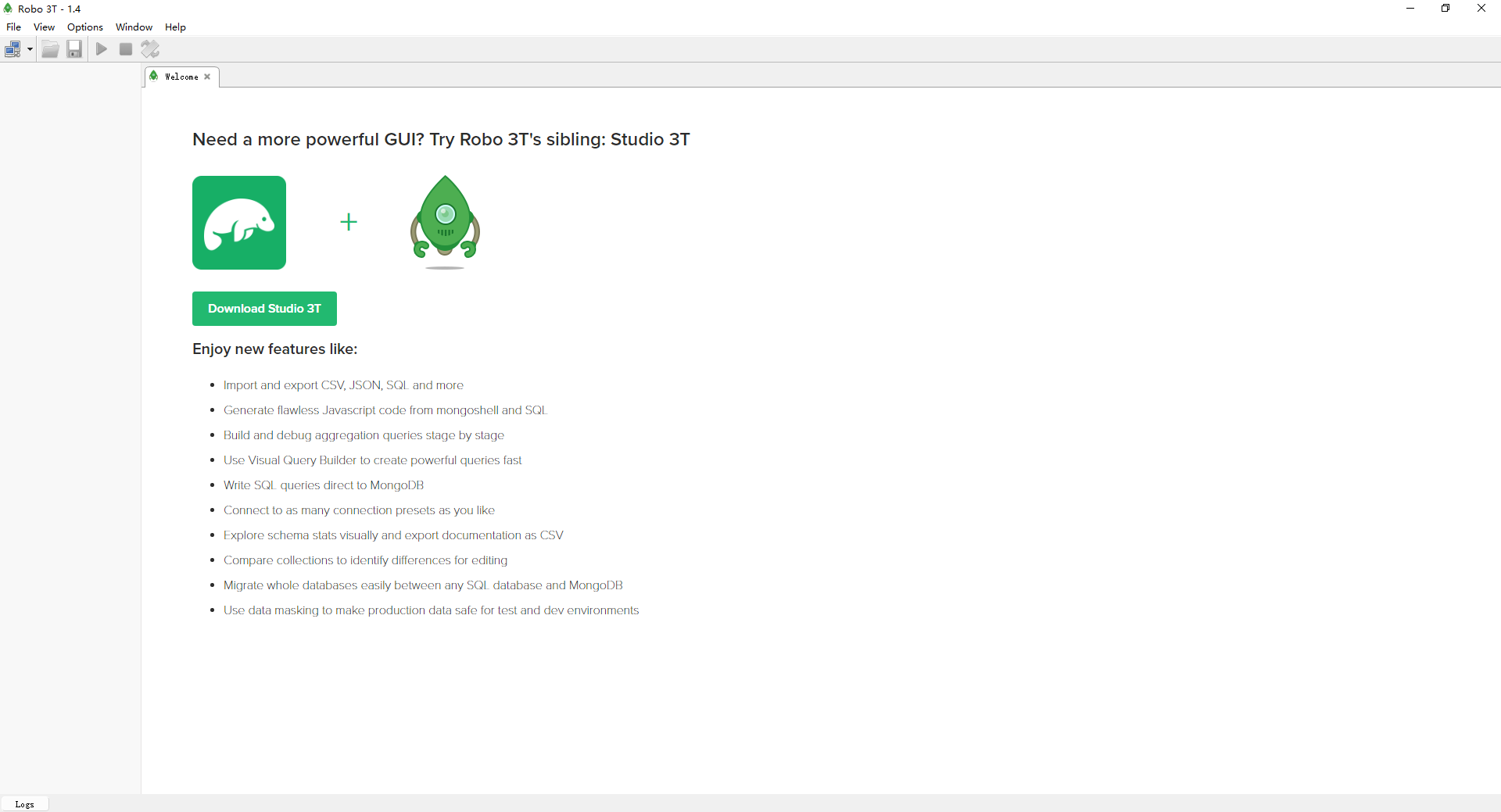
Para abrir o software, você deve primeiro se conectar ao servidor MongoDB, selecionar o menu [Arquivo] e selecionar [Conectar…]

Depois de entrar na interface de gerenciamento de conexão, selecione o link [Criar] no canto superior esquerdo para criar uma nova configuração de conexão

Se você inserir o valor de configuração, poderá conectar (a porta 27017 da máquina local pode ser conectada sem modificação por padrão)

Depois que a conexão for bem-sucedida, insira comandos na área de entrada de comandos para operar o MongoDB.
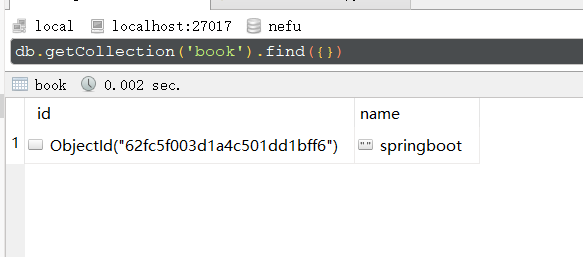
Criar um banco de dados: clique com o botão direito do mouse para criar no menu à esquerda e digite o nome do banco de dados.
Criar uma coleção: Use o botão direito em Coleções para criar, digite o nome da coleção, a coleção é equivalente ao papel da tabela no banco de dados
新增文档: (documento é um tipo de dado em formato json, mas na verdade não é um dado json)
db.集合名称.insert/save/insertOne(文档)
Por exemplo:
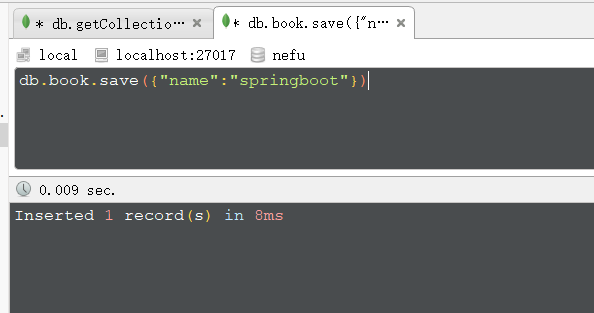
Resultado:
删除文档:
db.集合名称.remove(条件)
修改文档:
db.集合名称.update(条件,{操作种类:{文档}})
查询文档:
基础查询
查询全部: db.集合.find();
查第一条: db.集合.findOne()
查询指定数量文档: db.集合.find().limit(10) //查10条文档
跳过指定数量文档: db.集合.find().skip(20) //跳过20条文档
统计: db.集合.count()
排序: db.集合.sort({age:1}) //按age升序排序
投影: db.集合名称.find(条件,{name:1,age:1}) //仅保留name与age域
条件查询
基本格式: db.集合.find({条件})
模糊查询: db.集合.find({域名:/正则表达式/}) //等同SQL中的like,比like强大,可以执行正则所有规则
条件比较运算: db.集合.find({域名:{$gt:值}}) //等同SQL中的数值比较操作,例如:name>18
包含查询: db.集合.find({域名:{$in:[值1,值2]}}) //等同于SQL中的in
条件连接查询: db.集合.find({$and:[{条件1},{条件2}]}) //等同于SQL中的and、or
Apenas algumas operações básicas do MongoDB estão envolvidas aqui
Integrar
Como integrar o MongDB usando springboot? Na verdade, porque springboot usa tantos desenvolvedores é porque suas rotinas são quase exatamente as mesmas. Importe coordenadas, faça a configuração e use a interface da API para operar. O mesmo vale para a integração do Redis e o mesmo vale para a integração do MongoDB.
Primeiro, importe as coordenadas iniciais integradas da tecnologia correspondente
Em segundo lugar, configure as informações necessárias
Terceiro, use a API fornecida para operar
Vamos começar a integrar o MongoDB com o springboot. Os passos são os seguintes:
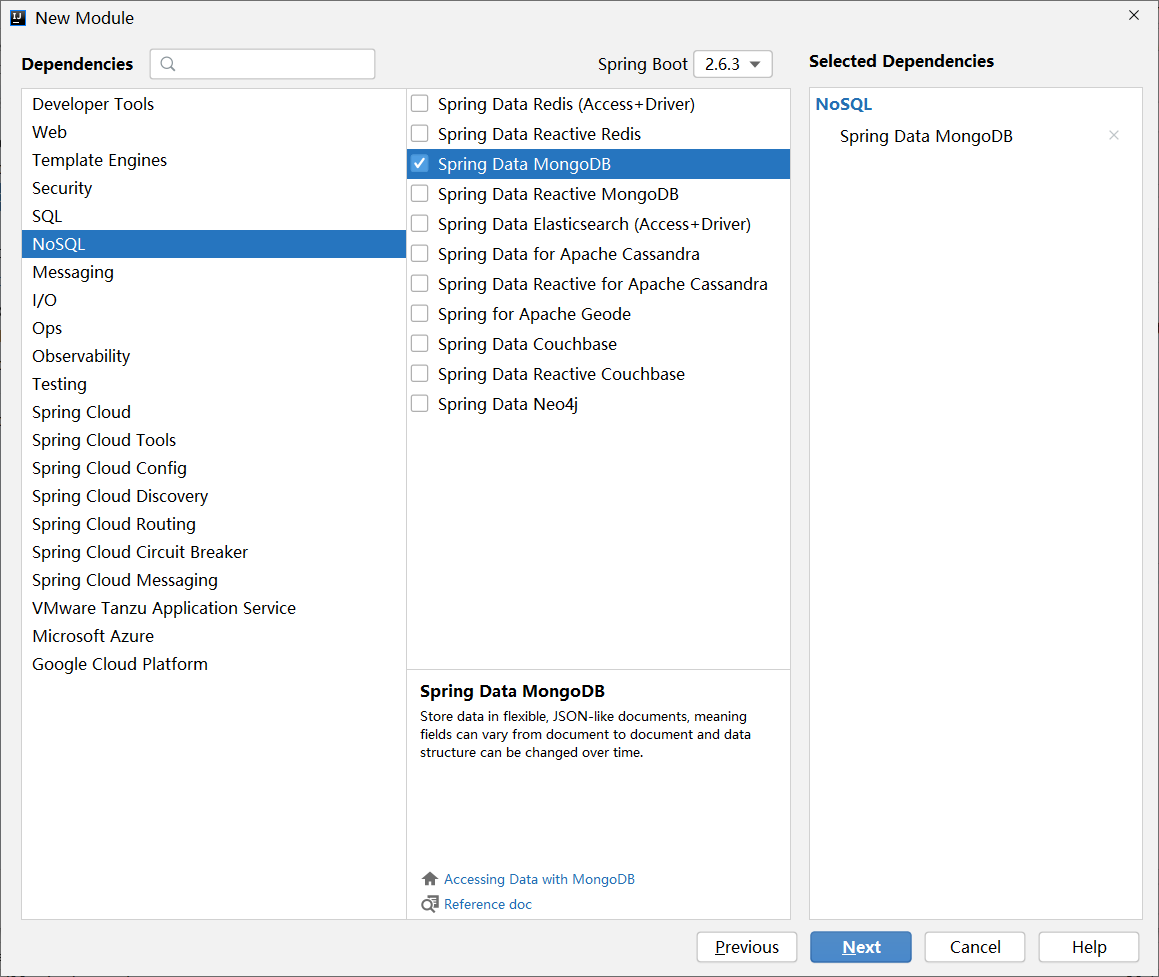
Etapa 1 : Importar springboot para integrar as coordenadas iniciais do MongoDB
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
As coordenadas acima também podem ser selecionadas verificando ao criar um módulo, que também pertence à categoria NoSQL.
Etapa 2 : Execute a configuração básica
spring:
data:
mongodb:
uri: mongodb://localhost/nefu #我们对nefu集合进行操作
A configuração necessária para operar o MongoDB é a mesma para operar o redis, a informação mais básica é qual servidor operar, a diferença é que o endereço IP do servidor conectado e a porta são diferentes, e o formato de escrita é diferente.
Etapa 3 : Use o springboot para integrar a interface de cliente dedicada do MongoDB MongoTemplate para operação
@SpringBootTest
class Springboot17MongodbApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
void contextLoads() {
Book book = new Book();
book.setId(2);
book.setName("springboot2");
book.setType("springboot2");
book.setDescription("springboot2");
mongoTemplate.save(book);
}
@Test
void find(){
List<Book> all = mongoTemplate.findAll(Book.class);
System.out.println(all);
}
}
Após executar a operação de salvamento, podemos visualizar os novos dados no banco de dados:
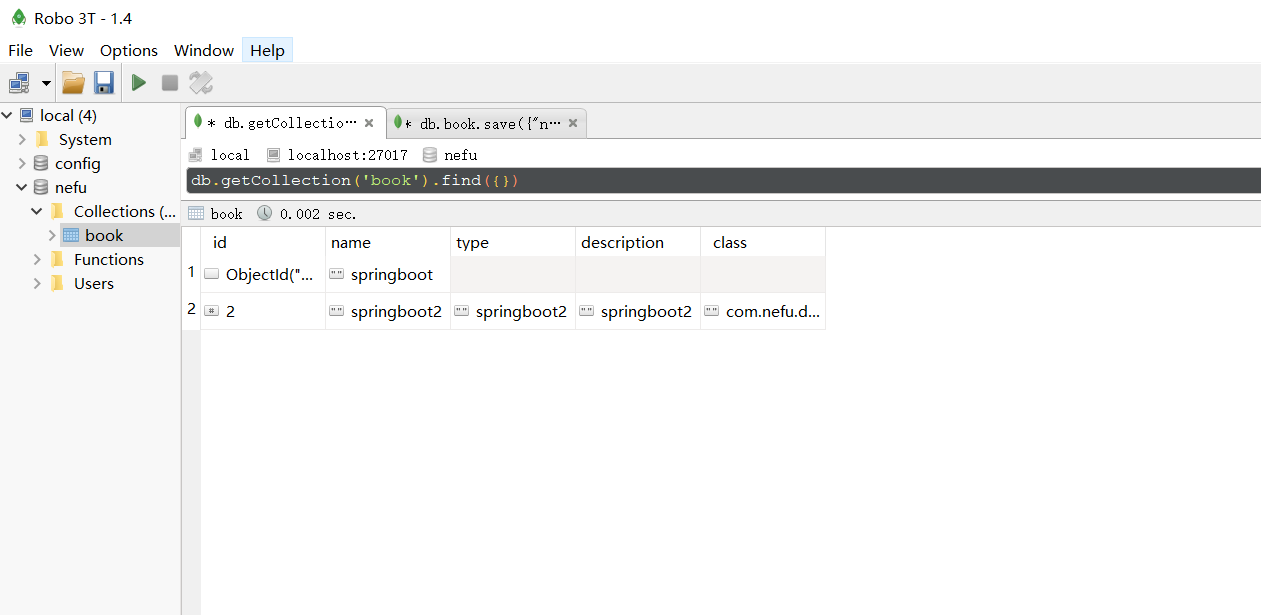
O trabalho de integração é feito aqui e parece familiar e desconhecido. Eu estou familiarizado com essa rotina, três eixos, apenas esses três truques, orientando as coordenadas para configurar as operações da API. O que não conheço é essa tecnologia, e a API específica da operação pode não ser familiar. Falaremos sobre springboot integrando o MongoDB aqui.
Resumir
- Springboot integra etapas do MongoDB
- Importar springboot para integrar as coordenadas iniciais do MongoDB
- Faça a configuração básica
- Use springboot para integrar as operações MongoTemplate da interface de cliente dedicada do MongoDB
SpringBoot integra ES
Introdução e instalação básica do ES
A solução NoSQL concluiu a integração das duas tecnologias. O Redis pode usar a memória para carregar dados e obter acesso rápido aos dados. O MongoDB pode armazenar dados semelhantes a objetos na memória e obter acesso rápido aos dados. No desenvolvimento de nível empresarial, a velocidade do The perseguição nunca acaba. O conteúdo a ser discutido a seguir também é uma solução NoSQL, mas seu papel não é acelerar diretamente a leitura e escrita dos dados, mas sim acelerar a consulta dos dados, o que é chamado de tecnologia ES .
ES (Elasticsearch) é um mecanismo de pesquisa de texto completo distribuído com foco na pesquisa de texto completo.
Então, o que é pesquisa de texto completo? Por exemplo, se um usuário quiser comprar um livro e pesquisar com Java como palavra-chave, seja no título do livro, na introdução do livro, ou mesmo no nome do autor do livro, desde que ele contém java, ele será retornado ao usuário como resultado da consulta. O processo acima é usado. Tecnologia de pesquisa de texto completo. As condições de pesquisa não são mais usadas apenas para comparar um determinado campo, mas para usar as condições de pesquisa em um dado para comparar mais campos , desde que correspondam, eles serão incluídos nos resultados da consulta, que é o objetivo da pesquisa completa -pesquisa de texto. A tecnologia ES é uma tecnologia que pode alcançar os efeitos acima.
Para obter o efeito da pesquisa de texto completo, é impossível usar a operação like no banco de dados para comparação, o que é muito ineficiente. A ES projetou uma nova ideia para realizar a pesquisa de texto completo. O processo de operação específico é o seguinte:
-
Verifique e pontue todas as informações de texto dos dados do campo a ser consultado e divida-o em várias palavras
- Por exemplo, "Spring Actual 5th Edition" será dividido em três palavras, a saber, "Spring", "Actual Combat" e "5th Edition". Esse processo é chamado pela terminologia profissional
分词. Diferentes estratégias de segmentação de palavras têm diferentes efeitos de separação.Diferentes estratégias de segmentação de palavras são chamadas de tokenizers.
- Por exemplo, "Spring Actual 5th Edition" será dividido em três palavras, a saber, "Spring", "Actual Combat" e "5th Edition". Esse processo é chamado pela terminologia profissional
-
Armazenar o resultado da segmentação de palavras, correspondente ao id de cada dado

-
Por exemplo, o valor do nome do item nos dados com id 1 é "Spring Actual 5th Edition", então após o término da segmentação da palavra, aparecerá que "Spring" corresponde ao id 1, "combate real" corresponde a id 1, "Versão 5" "ID correspondente é 1
-
Por exemplo, o valor do item de nome nos dados com id 3 é "Modo de design Spring5", então após o final da segmentação de palavras, "Spring" corresponde ao id 3 e "modo de design" corresponde ao id 3
-
Neste ponto, aparecerão os seguintes resultados correspondentes: De acordo com o formulário acima, todos osDocumentaçãoFaça segmentação de palavras. Cabe ressaltar que o processo de segmentação de palavras não é realizado apenas em um campo, mas em cada campo participante da consulta, e os resultados finais são resumidos em uma tabela
Esse tipo de dado pode ser chamado de documento:
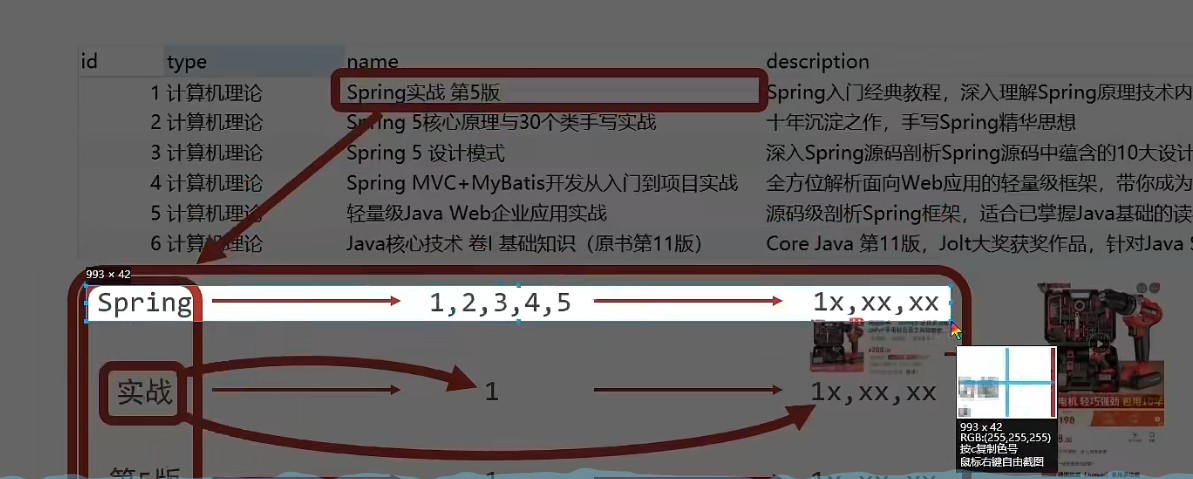
palavra-chave do resultado da segmentação de palavras ID correspondente Primavera 1, 2, 3, 4, 5 combate real 1 5ª edição 1 -
-
Ao consultar, se você inserir "combate real" como a condição de consulta, poderá comparar os dados da tabela acima para obter o valor de id de 1 e, em seguida, obter os dados de resultado da consulta de acordo com o valor de id.

No processo acima, o conteúdo de cada palavra-chave no resultado da segmentação de palavras é diferente e sua função é um pouco semelhante ao índice no banco de dados, que é usado para acelerar a consulta de dados. No entanto, o índice no banco de dados é adicionar um índice a um determinado campo, e a palavra-chave do resultado da segmentação de palavras aqui não é um valor de campo completo, mas apenas uma parte do conteúdo de um campo. E o índice é usado para encontrar todos os dados de acordo com o conteúdo do índice. O resultado da segmentação de palavras na pesquisa de texto completo resulta não nos dados inteiros, mas no id dos dados. Se você deseja obter os dados específicos, você precisa consultar novamente, então aqui Um novo nome é dado a esse tipo de palavra-chave de resultado de segmentação de palavras, que é chamada de índice invertido .
Em seguida, vamos falar sobre a instalação: O
endereço de download do pacote de instalação da versão do Windows : https://www.elastic.co/cn/downloads/elasticsearch
O pacote de instalação baixado é um arquivo zip que pode ser usado após a descompactação. Após a descompactação, os seguintes arquivos serão obtidos

- diretório bin: contém todos os comandos executáveis
- diretório config: contém os arquivos de configuração usados pelo servidor ES
- Diretório jdk: Este diretório contém um kit de ferramentas jdk completo, versão 17. Quando o ES for atualizado, use a versão mais recente do jdk para garantir que não haja nenhum problema de suporte de versão insuficiente
- Diretório lib: contém os arquivos jar dependentes que o ES executa
- diretório logs: contém todos os arquivos de log gerados após a execução do ES
- diretório de módulos: contém todos os módulos funcionais do software ES, e também é um pacote jar um por um. Diferente do diretório jar, o diretório jar é o pacote jar do qual o ES depende durante o tempo de execução, e os módulos são o pacote jar funcional do próprio software ES.
- diretório de plugins: Contém plugins instalados pelo software ES, vazio por padrão
iniciar o servidor
elasticsearch.bat
Clique duas vezes no arquivo elasticsearch.bat para iniciar o servidor ES e a porta de serviço padrão é 9200. Acesse http://localhost:9200 por meio de um navegador e veja as seguintes informações, pois o servidor ES inicia normalmente
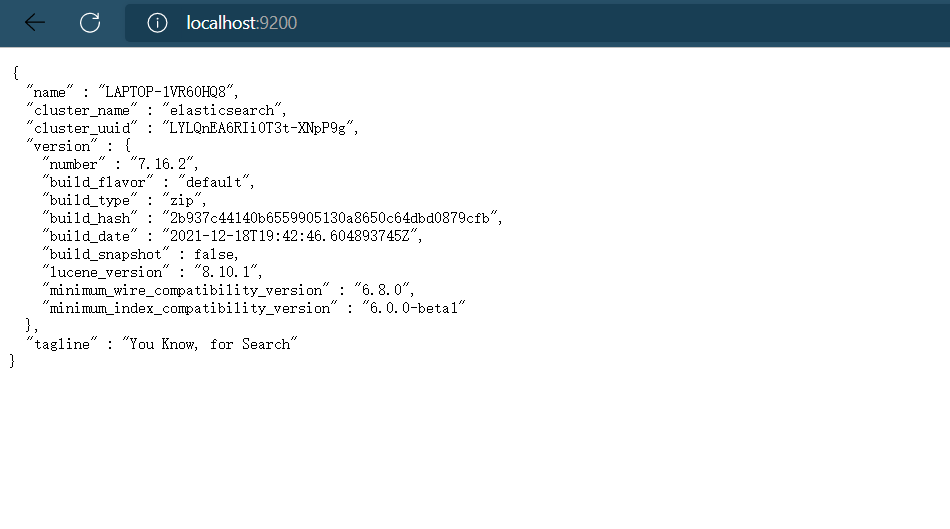
Durante o processo de execução, há dois números de porta que precisam ser lembrados:
Porta 9300: a porta de comunicação do componente elasticsearch clusterware, que é simplesmente a porta para comunicação interna do elasticsearch.
Porta 9200: A porta de acesso do navegador.
Às vezes, a operação relatará o seguinte erro:
GeoIP reported error, GeoIP processor | Elasticsearch Guide [7.14] | Elastic
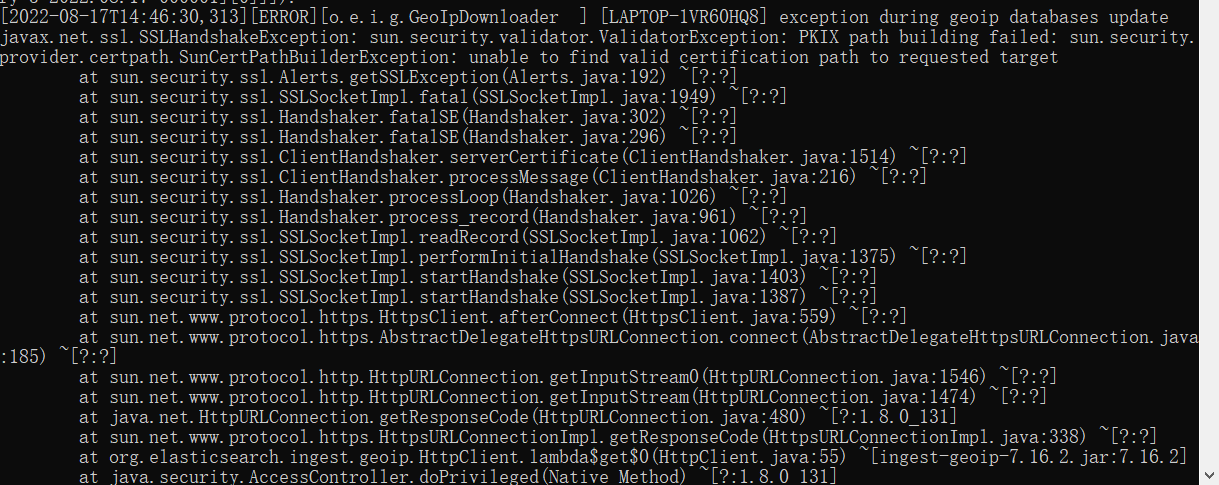
A mensagem de erro é principalmente
javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: falha na construção do caminho PKIX: sun.security.provider.certpath.SunCertPathBuilderException: não foi possível encontrar um caminho de certificação válido para o destino solicitado
A solução é a seguinte, que é adicionar o certificado de segurança ssh ao diretório de segurança do jre baixado. No entanto, isso não afeta a operação, portanto, não pode ser resolvido.
Resolvendo PKIX: A Solução
Alguns usuários podem clicar no arquivo elasticsearch.bat e a janela pop-up cmd fechará automaticamente após exibir algumas linhas de texto. Neste caso, abra-o algumas vezes até que ele seja executado normalmente.
Operação basica
Os dados que queremos consultar são armazenados no ES, mas o formato é diferente do formato dos dados armazenados no banco de dados. No ES, precisamos primeiro criar um índice invertido, que é semelhante em função a uma tabela de banco de dados, e então adicionar dados ao índice invertido.Os dados adicionados são chamados de documento. Portanto, para realizar operações de ES, você deve primeiro criar um índice e, em seguida, adicionar documentos, para que as operações de consulta subsequentes possam ser executadas.
A operação do ES pode ser feita através de requisições no estilo Rest, ou seja, o envio de uma requisição pode realizar uma operação. Por exemplo, a criação de um índice e a exclusão de um índice podem ser realizadas na forma de envio de uma solicitação.
-
Crie um índice, livros é o nome do índice, o mesmo abaixo
PUT请求 http://localhost:9200/booksApós enviar a solicitação, você verá as seguintes informações de que o índice foi criado com sucesso
{ "acknowledged": true, "shards_acknowledged": true, "index": "books" }A criação repetida de um índice existente resultará em uma mensagem de erro, o motivo do erro é descrito no atributo reason
{ "error": { "root_cause": [ { "type": "resource_already_exists_exception", "reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", "index_uuid": "VgC_XMVAQmedaiBNSgO2-w", "index": "books" } ], "type": "resource_already_exists_exception", "reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", # books索引已经存在 "index_uuid": "VgC_XMVAQmedaiBNSgO2-w", "index": "book" }, "status": 400 } -
índice de consulta
GET请求 http://localhost:9200/booksConsulte o índice para obter informações relacionadas ao índice, da seguinte maneira
{ "book": { "aliases": { }, "mappings": { }, "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "provided_name": "books", "creation_date": "1645768584849", "number_of_replicas": "1", "uuid": "VgC_XMVAQmedaiBNSgO2-w", "version": { "created": "7160299" } } } } }Se um índice inexistente for consultado, uma mensagem de erro será retornada. Por exemplo, as informações após consultar um índice chamado livro são as seguintes
{ "error": { "root_cause": [ { "type": "index_not_found_exception", "reason": "no such index [book]", "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" } ], "type": "index_not_found_exception", "reason": "no such index [book]", # 没有book索引 "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" }, "status": 404 } -
índice de queda
DELETE请求 http://localhost:9200/booksDepois de excluir tudo, dê o resultado de exclusão
{ "acknowledged": true }Se a duplicata for excluída, uma mensagem de erro será fornecida e o motivo específico do erro também será descrito no atributo reason.
{ "error": { "root_cause": [ { "type": "index_not_found_exception", "reason": "no such index [books]", "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" } ], "type": "index_not_found_exception", "reason": "no such index [books]", # 没有books索引 "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" }, "status": 404 } -
Crie um índice e especifique um tokenizer
O índice criado anteriormente não especifica um tokenizer. Você pode adicionar parâmetros de solicitação para definir o tokenizer ao criar o índice. Atualmente, o tokenizer mais popular na China é o tokenizer IK. Antes de usá-lo, baixe o tokenizer correspondente e depois use-o.
Endereço de download do tokenizer IK: https://github.com/medcl/elasticsearch-analysis-ik/releasesApós baixar o tokenizer, extraia-o para o diretório de plugins do diretório de instalação do ES. Após instalar o tokenizer, você precisa reiniciar o servidor ES. Crie um formato de índice usando o tokenizer IK:
PUT请求 http://localhost:9200/books 请求参数如下(注意是json格式的参数) { "mappings":{ #定义mappings属性,替换创建索引时对应的mappings属性 "properties":{ #定义索引中包含的属性设置 "id":{ #设置索引中包含id属性 "type":"keyword" #当前属性可以被直接搜索 }, "name":{ #设置索引中包含name属性 "type":"text", #当前属性是文本信息,参与分词 "analyzer":"ik_max_word", #使用IK分词器进行分词 "copy_to":"all" #分词结果拷贝到all属性中 }, "type":{ "type":"keyword" }, "description":{ "type":"text", "analyzer":"ik_max_word", "copy_to":"all" }, "all":{ #定义属性,用来描述多个字段的分词结果集合,当前属性可以参与查询 "type":"text", "analyzer":"ik_max_word" } } } }Após a conclusão da criação, o resultado retornado é o mesmo que o resultado da criação de um índice sem usar o tokenizer. Neste momento, você pode observar visualizando as informações do índice que os mapeamentos de parâmetro de solicitação adicionados inseriram o atributo index.
{ "books": { "aliases": { }, "mappings": { #mappings属性已经被替换 "properties": { "all": { "type": "text", "analyzer": "ik_max_word" }, "description": { "type": "text", "copy_to": [ "all" ], "analyzer": "ik_max_word" }, "id": { "type": "keyword" }, "name": { "type": "text", "copy_to": [ "all" ], "analyzer": "ik_max_word" }, "type": { "type": "keyword" } } }, "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "provided_name": "books", "creation_date": "1645769809521", "number_of_replicas": "1", "uuid": "DohYKvr_SZO4KRGmbZYmTQ", "version": { "created": "7160299" } } } } }
No momento, temos um índice, mas não há dados no índice, então precisamos adicionar os dados primeiro. Os dados são chamados de documento no ES, e a operação do documento é realizada abaixo.
-
Existem três maneiras de adicionar documentos
POST请求 http://localhost:9200/books/_doc #使用系统生成id POST请求 http://localhost:9200/books/_create/1 #使用指定id POST请求 http://localhost:9200/books/_doc/1 #使用指定id,不存在创建,存在更新(版本递增) 文档通过请求参数传递,数据格式json { "name":"springboot", "type":"springboot", "description":"springboot" } -
documento de consulta
GET请求 http://localhost:9200/books/_doc/1 #查询单个文档 GET请求 http://localhost:9200/books/_search #查询全部文档 -
Consulta condicional
GET请求 http://localhost:9200/books/_search?q=name:springboot # q=查询属性名:查询属性值 -
excluir documento
DELETE请求 http://localhost:9200/books/_doc/1 -
Modificar o documento (atualização completa)
PUT请求 http://localhost:9200/books/_doc/1 文档通过请求参数传递,数据格式json { "name":"springboot", "type":"springboot", "description":"springboot" } -
Documentação revisada (parcialmente atualizada)
POST请求 http://localhost:9200/books/_update/1 文档通过请求参数传递,数据格式json { "doc":{ #部分更新并不是对原始文档进行更新,而是对原始文档对象中的doc属性中的指定属性更新 "name":"springboot" #仅更新提供的属性值,未提供的属性值不参与更新操作 } }
Integrar
Como integrar o ES usando springboot? As regras antigas, importam as coordenadas, fazem a configuração e usam a interface da API para operar. A integração do Redis é a mesma, a integração do MongoDB é a mesma e a integração do ES ainda é a mesma. Não é novo, mas não é que não seja novo. Esse é o poder do springboot. Tudo é feito nas mesmas regras, o que é muito amigável para os desenvolvedores.
Vamos começar a integrar o ES com o springboot. Os passos são os seguintes:
Etapa 1 : Importar as coordenadas iniciais do springboot para integrar o ES
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
Etapa 2 : Execute a configuração básica
spring:
elasticsearch:
rest:
uris: http://localhost:9200
Configure o endereço do servidor ES, porta 9200
Etapa 3 : Use o springboot para integrar a interface de cliente dedicada do ES ElasticsearchRestTemplate para operar
@SpringBootTest
class Springboot18EsApplicationTests {
@Autowired
private ElasticsearchRestTemplate template;
}
O formulário de operação acima é o método de operação inicial do ES. O cliente utilizado é chamado de Low Level Client. O desempenho deste método de operação do cliente é um pouco insuficiente, então o ES desenvolveu um novo método de operação do cliente chamado High Level Client. . O cliente de alto nível é atualizado de forma síncrona com a versão ES, mas o springboot usou um cliente de baixo nível ao integrar o ES primeiro, portanto, o desenvolvimento corporativo precisa ser substituído por um modo de cliente de alto nível.
O seguinte usa o método de cliente de alto nível para integrar o ES com o springboot. As etapas da operação são as seguintes:
Passo 1 : Importar springboot para integrar as coordenadas do cliente de alto nível ES Não existe atualmente nenhum iniciador correspondente para este formulário.
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
Etapa 2 : Defina o servidor ES conectado programaticamente e obtenha o objeto cliente
@SpringBootTest
class Springboot18EsApplicationTests {
private RestHighLevelClient client;
@Test
void testCreateClient() throws IOException {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
client.close();
}
}
Configure o endereço do servidor ES e a porta 9200. Lembre-se que o cliente precisa ser fechado manualmente após o uso. Como o cliente atual é mantido manualmente, os objetos não podem ser carregados por meio da fiação automática.
Etapa 3 : Use o objeto cliente para operar o ES, como criar um índice
@SpringBootTest
class Springboot18EsApplicationTests {
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
CreateIndexRequest request = new CreateIndexRequest("books");
client.indices().create(request, RequestOptions.DEFAULT);
client.close();
}
}
Operações de cliente de alto nível completam todas as operações enviando solicitações. ES define vários objetos de solicitação para várias operações. No exemplo acima, o objeto que cria o índice é CreateIndexRequest, e outras operações também terão seu próprio objeto Request dedicado.
Na operação atual, descobrimos que não importa que tipo de operação ES seja realizada, o primeiro passo é sempre obter o objeto RestHighLevelClient, e o último passo é sempre fechar a conexão do objeto. No teste, os recursos da classe de teste podem ser usados para ajudar os desenvolvedores a concluir as operações acima de uma só vez, mas eles também precisam se gerenciar ao escrever negócios. Converta o formato de código acima para usar o método de inicialização e o método destroy da classe de teste para manter o objeto cliente.
@SpringBootTest
class Springboot18EsApplicationTests {
@BeforeEach //在测试类中每个操作运行前运行的方法
void setUp() {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
}
@AfterEach //在测试类中每个操作运行后运行的方法
void tearDown() throws IOException {
client.close();
}
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("books");
client.indices().create(request, RequestOptions.DEFAULT);
}
}
Agora a escrita é muito simplificada e mais razoável. Em seguida, use o modo acima para executar todas as operações ES uma vez e teste os resultados
Criar índice (tokenizer IK) :
@Test
void testCreateIndexByIK() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("books");
String json = "{\n" +
" \"mappings\":{\n" +
" \"properties\":{\n" +
" \"id\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\",\n" +
" \"copy_to\":\"all\"\n" +
" },\n" +
" \"type\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\",\n" +
" \"copy_to\":\"all\"\n" +
" },\n" +
" \"all\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
//设置请求中的参数
request.source(json, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
O tokenizer IK é definido na forma de parâmetros de solicitação, e os parâmetros de solicitação são definidos usando o método de origem no objeto de solicitação. Quanto aos parâmetros, depende do seu tipo de operação. Quando os parâmetros são necessários na solicitação, os parâmetros podem ser definidos no formulário atual.
Adicione a documentação :
@Test
//添加文档
void testCreateDoc() throws IOException {
Book book = bookDao.selectById(1);
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json,XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
}
O objeto de solicitação usado para adicionar documentos é IndexRequest, que é diferente do objeto de solicitação usado para criar um índice.
Adicione documentos em massa :
@Test
//批量添加文档
void testCreateDocAll() throws IOException {
List<Book> bookList = bookDao.selectList(null);
BulkRequest bulk = new BulkRequest();
for (Book book : bookList) {
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json,XContentType.JSON);
bulk.add(request);
}
client.bulk(bulk,RequestOptions.DEFAULT);
}
Ao fazer batches, primeiro crie um objeto BulkRequest, que pode ser entendido como um container para armazenar objetos request. Depois que todas as solicitações forem inicializadas, adicione-as ao objeto BulkRequest e, em seguida, use o método bulk do objeto BulkRequest. Uma vez que a execução sexual está completo.
Consultar documentos por id :
@Test
//按id查询
void testGet() throws IOException {
GetRequest request = new GetRequest("books","1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsString();
System.out.println(json);
}
O objeto de solicitação usado para consultar documentos por id é GetRequest.
Consultar documentos por critérios :
@Test
//按条件查询
void testSearch() throws IOException {
SearchRequest request = new SearchRequest("books");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.termQuery("all","spring"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
String source = hit.getSourceAsString();
//System.out.println(source);
Book book = JSON.parseObject(source, Book.class);
System.out.println(book);
}
}
O objeto de solicitação usado para consultar documentos por condição é SearchRequest. Ao consultar, o método termQuery do objeto SearchRequest é chamado e o nome do atributo de consulta precisa ser fornecido. O campo de mesclagem é suportado aqui, ou seja, o atributo all adicionado quando o atributo index foi definido anteriormente.
A operação de springboot integrando ES é finalizada aqui. A diferença entre springboot integrando redis e mongodb no estágio anterior ainda é bastante grande. O principal motivo é que não usamos springboot para integrar objetos cliente ES. Quanto à operação, porque existem muitos tipos de operações ES, a operação parece ser um pouco complicada.
Resumir
- springboot integra etapas ES
- Importar springboot para integrar as coordenadas do cliente de alto nível do ES
- Gerenciamento manual de objetos do cliente, incluindo operações de inicialização e desligamento
- Use o cliente de alto nível para selecionar diferentes objetos de solicitação para concluir as operações correspondentes de acordo com diferentes tipos de operações