Para mais intercâmbios técnicos e oportunidades de procura de emprego, preste atenção à conta oficial do WeChat da ByteDance Data Platform e responda [1] para entrar no grupo oficial de intercâmbio
ByteHouse é um data warehouse nativo da nuvem no Volcano Engine, que oferece aos usuários uma experiência de análise extremamente rápida e pode oferecer suporte à análise de dados em tempo real e à análise massiva de dados off-line; recursos elásticos convenientes de expansão e contração, desempenho de análise extremo e recursos avançados de nível empresarial , para ajudar na transformação digital dos clientes.
Este artigo apresentará a evolução da tecnologia de importação em tempo real da ByteHouse baseada em diferentes arquiteturas do ponto de vista da motivação da demanda, implementação da tecnologia e aplicação prática.
Requisitos de importação em tempo real de negócios internos
A motivação para a evolução da tecnologia de importação em tempo real da ByteHouse originou-se das necessidades dos negócios internos da ByteDance.
Dentro do Byte, a ByteHouse usa principalmente o Kafka como a principal fonte de dados para importação em tempo real ( este artigo usa a importação do Kafka como exemplo para expandir a descrição, que não será repetida abaixo ). Para a maioria dos usuários internos, o volume de dados é relativamente grande; portanto, os usuários prestam mais atenção ao desempenho da importação de dados, à estabilidade dos serviços e à escalabilidade dos recursos de importação. Quanto à latência de dados, a maioria dos usuários pode atender às suas necessidades, desde que seja visível em segundos. Com base nesse cenário, a ByteHouse realizou uma otimização personalizada.
Alta disponibilidade sob arquitetura distribuída

Arquitetura distribuída nativa da comunidade
ByteHouse primeiro seguiu a arquitetura distribuída da comunidade Clickhouse, mas a arquitetura distribuída tem alguns defeitos arquitetônicos naturais. Esses pontos problemáticos se manifestam principalmente em três aspectos:
-
Falha de nó: quando o número de máquinas do cluster atinge uma determinada escala, é necessário lidar manualmente com as falhas de nó todas as semanas. Para clusters de cópia única, em alguns casos extremos, a falha do nó pode até levar à perda de dados.
-
Conflitos de leitura e gravação: devido ao acoplamento leitura-gravação da arquitetura distribuída, quando a carga do cluster atingir um determinado nível, ocorrerão conflitos de recursos nas consultas do usuário e nas importações em tempo real - especialmente CPU e IO, as importações serão afetadas e haverá atraso no consumo.
-
Custo de expansão: Como os dados na arquitetura distribuída são basicamente armazenados localmente, os dados não podem ser reembaralhados após a expansão. A máquina recém-expandida quase não tem dados e o disco na máquina antiga pode estar quase cheio, resultando em um cluster desigual load. , levando à expansão não pode ter um efeito efetivo.
Esses são os pontos problemáticos naturais da arquitetura distribuída, mas devido às suas características naturais de simultaneidade e à extrema otimização de desempenho da leitura e gravação de dados do disco local, pode-se dizer que existem vantagens e desvantagens.
Design de importação em tempo real da comunidade
-
Modo de consumo de alto nível: conte com o próprio mecanismo de reequilíbrio do Kafka para balanceamento de carga de consumo.
-
dois níveis de simultaneidade
O design do núcleo de importação em tempo real com base na arquitetura distribuída é, na verdade, simultaneidade de dois níveis:
Um cluster CH geralmente tem vários shards, e cada shard consumirá e importará simultaneamente, que é a simultaneidade de vários processos entre os shards de primeiro nível;
Cada estilhaço também pode usar vários encadeamentos para consumir simultaneamente, de modo a obter uma taxa de transferência de alto desempenho.
-
Gravar em lotes
No que diz respeito a um único thread, o modo de consumo básico é gravar em lotes - consumir uma certa quantidade de dados ou gravá-los de uma vez após um determinado período de tempo. A gravação em lote pode obter melhor otimização de desempenho, melhorar o desempenho da consulta e reduzir a pressão no thread de mesclagem em segundo plano.
necessidades não atendidas
O design e a implementação das comunidades acima ainda não atendem a algumas necessidades avançadas dos usuários:
-
Em primeiro lugar, alguns usuários avançados têm requisitos relativamente rígidos na distribuição de dados. Por exemplo, eles têm chaves específicas para alguns dados específicos e esperam que os dados com a mesma chave sejam colocados no mesmo fragmento (como requisitos de chave exclusivos). Neste caso, o modelo de consumo da comunidade Nível Alto não pode ser satisfeito.
-
Em segundo lugar, o reequilíbrio da forma de consumo de alto nível é incontrolável, o que pode eventualmente levar à distribuição desigual dos dados importados para o cluster Clickhouse entre os vários shards.
-
Obviamente, a alocação de tarefas de consumo é desconhecida e, em alguns cenários de consumo anormal, torna-se muito difícil solucionar problemas; isso é inaceitável para um aplicativo de nível empresarial.
Mecanismo de consumo de arquitetura distribuída autodesenvolvido HaKafka
Para resolver os requisitos acima, a equipe da ByteHouse desenvolveu um motor de consumo baseado na arquitetura distribuída - HaKafka.
Alta disponibilidade (Ha)
O HaKafka herda as vantagens de consumo do mecanismo de tabela Kafka original na comunidade e, em seguida, concentra-se na otimização Ha de alta disponibilidade.
No que diz respeito à arquitetura distribuída, de fato, pode haver várias cópias em cada fragmento, e as tabelas HaKafka podem ser criadas em cada cópia. Mas a ByteHouse só selecionará um Líder através do ZK, deixará o Líder realmente executar o processo de consumo, e os outros nós ficarão no estado Stand by. Quando o nó Líder está indisponível, ZK pode mudar o Líder para o nó Stand by em segundos para continuar o consumo, alcançando assim uma alta disponibilidade.
Modo de baixo nível de consumo
O modo de consumo do HaKafka foi ajustado de Nível Alto para Nível Baixo. O modo de baixo nível pode garantir que as partições de tópico sejam distribuídas para cada shard no cluster de maneira ordenada e uniforme; ao mesmo tempo, multi-threading pode ser usado dentro do shard novamente, permitindo que cada thread consuma diferentes partições. Assim, ele herda totalmente as vantagens da simultaneidade de dois níveis do mecanismo de tabela Kafka da comunidade.
No modo de consumo de baixo nível, desde que os usuários upstream garantam que não haja distorção de dados ao gravar no tópico, os dados importados para o Clickhouse por meio do HaKafka devem ser distribuídos uniformemente entre os estilhaços.
Ao mesmo tempo, para usuários avançados que têm requisitos especiais de distribuição de dados - gravar os dados da mesma chave no mesmo fragmento - desde que o upstream assegure que os dados da mesma chave sejam gravados na mesma partição e, em seguida, importe o ByteHouse pode atender plenamente às necessidades do usuário, e é muito fácil Bem cenários de suporte, como chaves exclusivas.
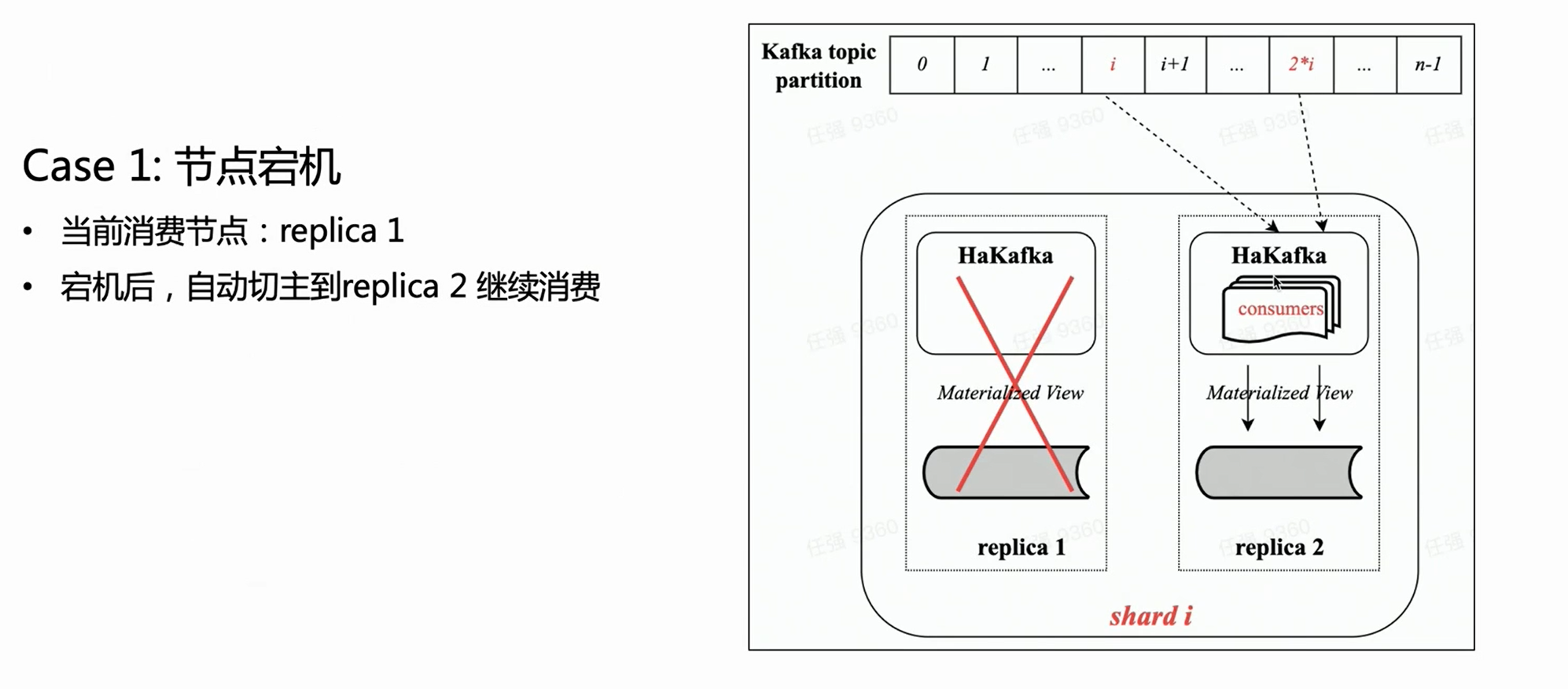
cena um:
Com base na figura acima, supondo que haja um shard com duas cópias, cada cópia terá a mesma tabela HaKafka no estado Pronto. Mas apenas no nó líder que elegeu com sucesso o líder através do ZK, o HaKafka executará o processo de consumo correspondente. Quando o nó líder cair, a réplica Réplica 2 será reeleita automaticamente como novo líder para continuar o consumo, garantindo assim alta disponibilidade.
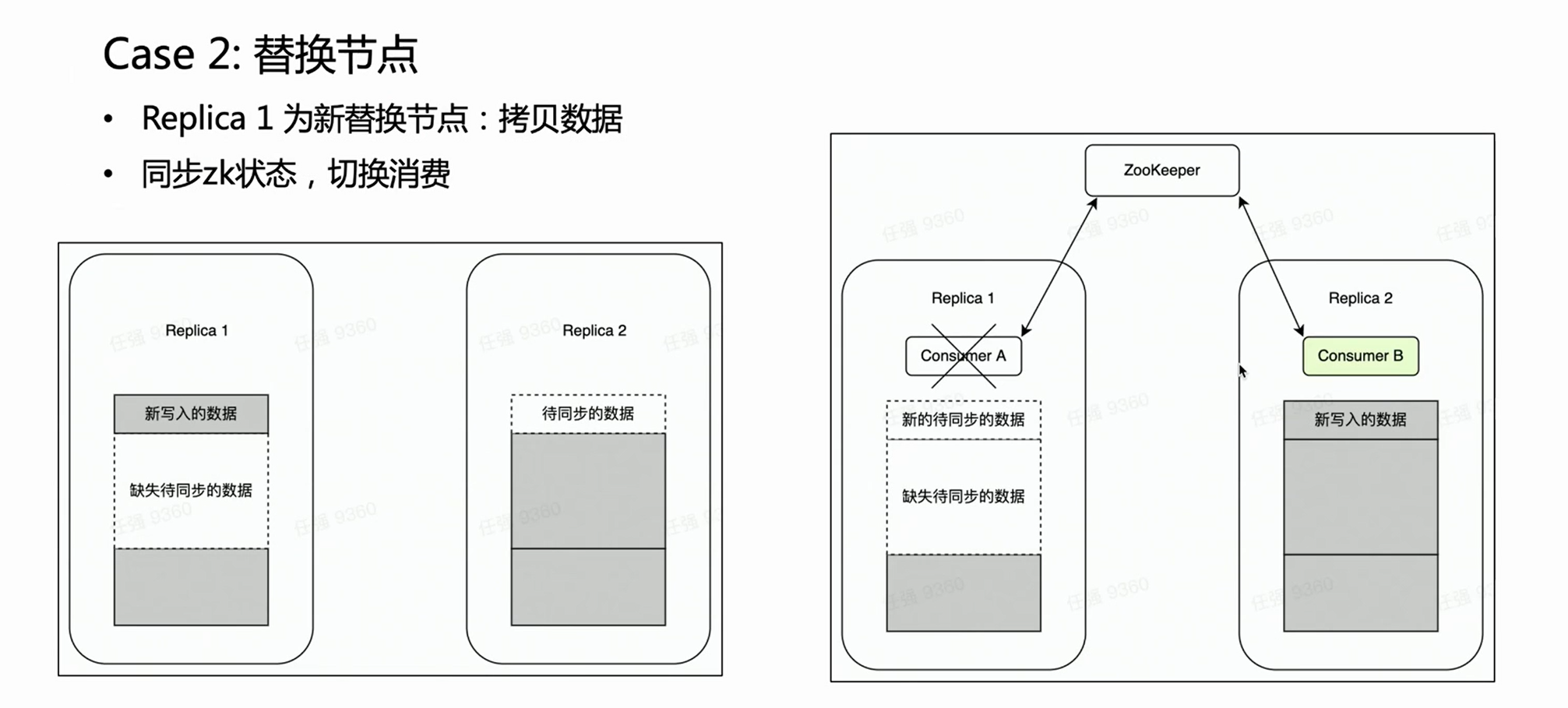
Cena dois:
No caso de falha de um nó, geralmente é necessário realizar o processo de substituição do nó. Existe uma operação muito pesada para substituição de nó distribuído - cópia de dados.
Se for um cluster com várias réplicas, uma cópia falha e a outra fica intacta. Esperamos naturalmente que durante a fase de substituição do nó, o consumo de Kafka seja colocado na réplica intacta Réplica 2, porque os dados antigos nela estão completos. Dessa forma, a Réplica 2 é sempre um conjunto de dados completo e pode fornecer serviços externos normalmente. HaKafka pode garantir isso. Quando HaKafka elege o líder, se for determinado que um determinado nó está em processo de substituição do nó, ele evitará ser selecionado como líder.
Otimização de desempenho de importação: tabela de memória
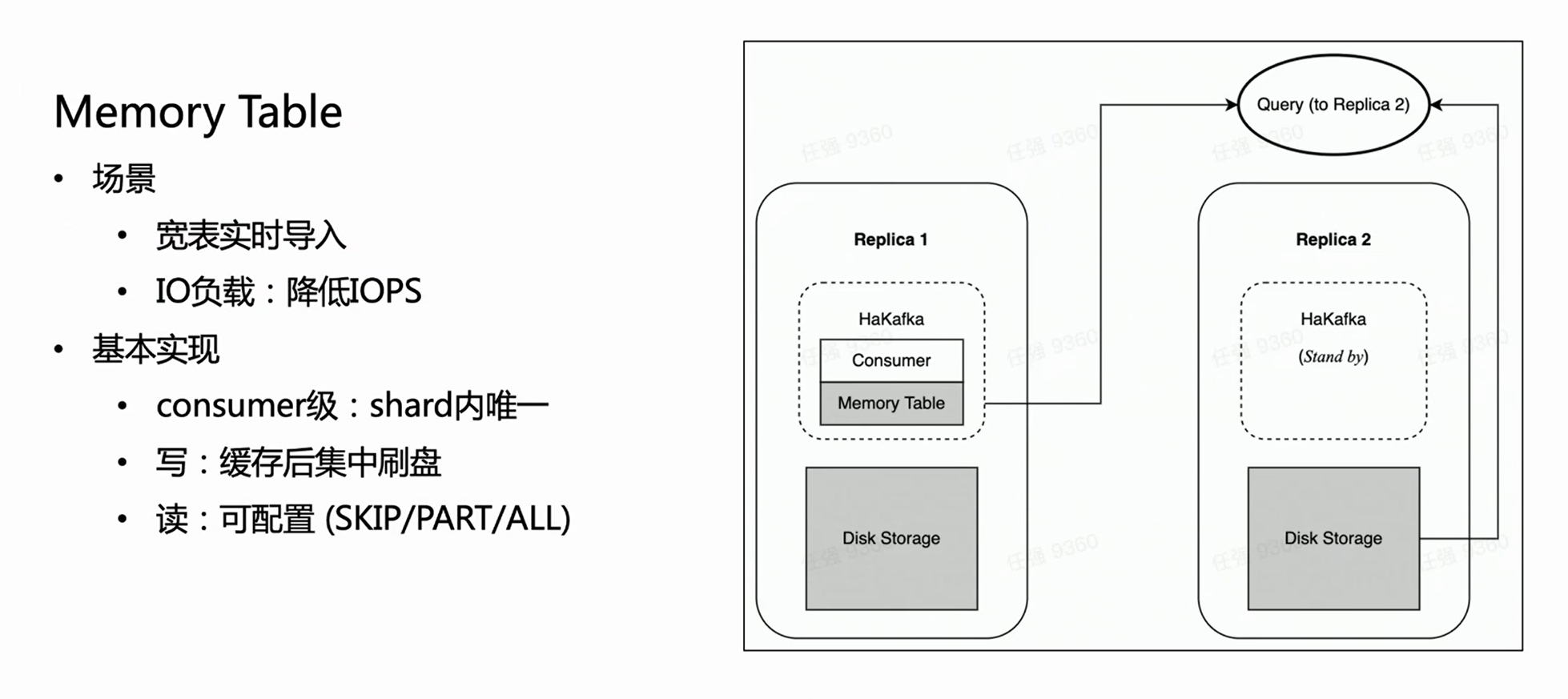
HaKafka também otimiza a tabela de memória.
Considere tal cenário: o negócio tem uma tabela grande e larga, que pode ter centenas de campos ou milhares de Map-Keys. Como cada coluna do ClickHouse corresponderá a um arquivo específico, quanto mais colunas houver, mais arquivos serão gravados a cada importação. Então, dentro do mesmo tempo de consumo, muitos arquivos fragmentados serão gravados com frequência, o que é um fardo pesado para o IO da máquina e, ao mesmo tempo, coloca muita pressão no MERGE; em casos graves, pode até fazer com que o cluster fique indisponível. Para resolver esse cenário, projetamos Memory Table para otimizar o desempenho da importação.
O método da tabela de memória é que cada vez que os dados importados não são flashados diretamente, mas armazenados na memória; quando os dados atingem uma certa quantidade, eles são concentrados no disco para reduzir as operações de E/S. A tabela de memória pode fornecer serviço de consulta externa, e a consulta será roteada para a cópia onde o nó consumidor está localizado para ler os dados na tabela de memória, o que garante que o atraso da importação de dados não seja afetado. Pela experiência interna, o Memory Table não apenas atende a alguns requisitos de importação de tabelas grandes e largas, mas também melhora o desempenho da importação em até 3 vezes.
Nova arquitetura nativa da nuvem
Tendo em vista as falhas naturais da arquitetura distribuída descritas acima, a equipe da ByteHouse vem trabalhando na atualização da arquitetura. Escolhemos a arquitetura nativa da nuvem que é o mainstream do negócio. A nova arquitetura começará a atender os negócios internos da Byte no início de 2021 e abrirá o código (ByConity ) no início de 2023.
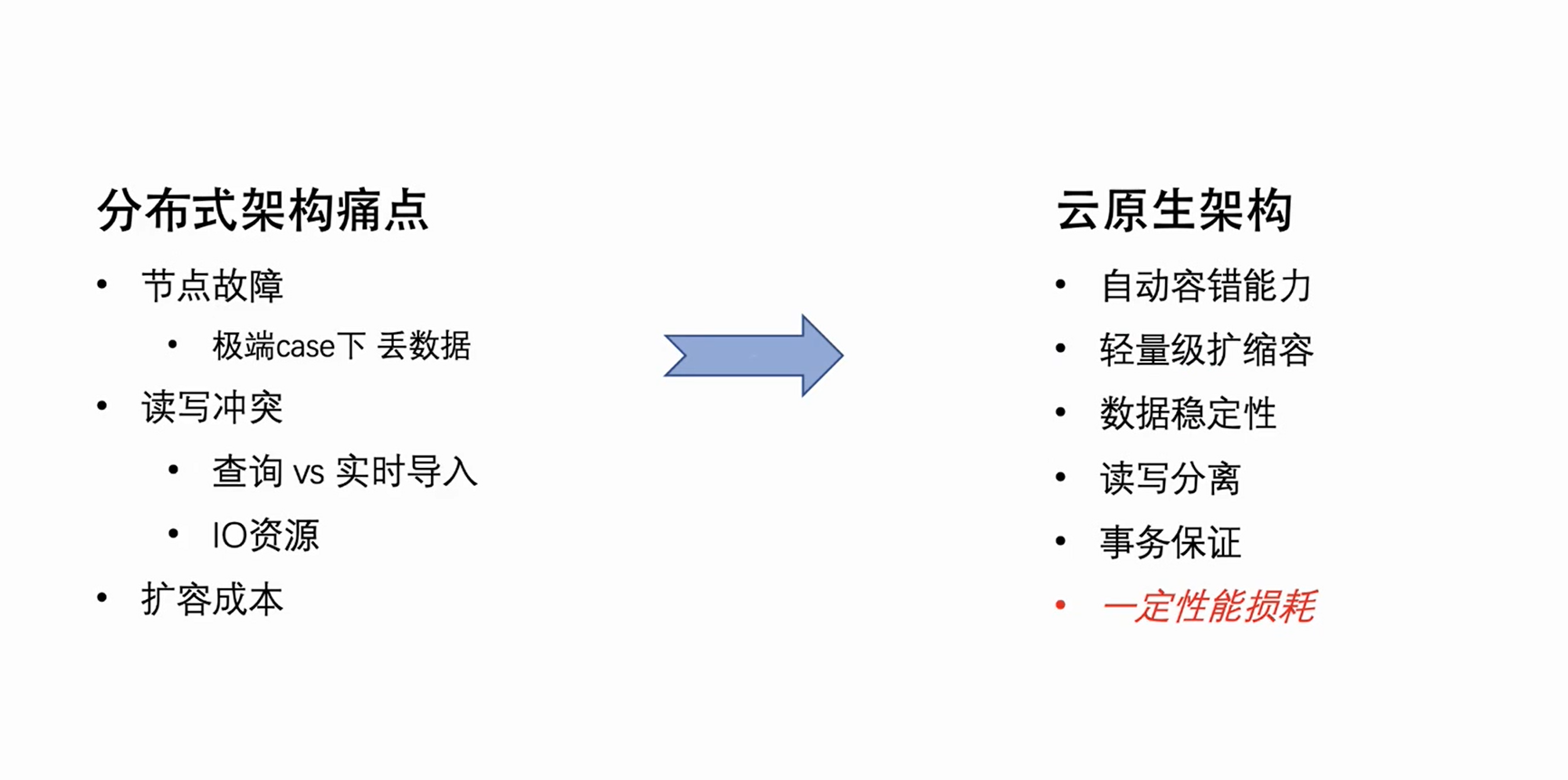
A própria arquitetura nativa da nuvem possui tolerância automática natural a falhas e recursos de dimensionamento leve. Ao mesmo tempo, como seus dados são armazenados na nuvem, ele não apenas realiza a separação de armazenamento e computação, mas também melhora a segurança e a estabilidade dos dados. É claro que a arquitetura nativa da nuvem tem suas deficiências. Mudar a leitura e gravação local original para leitura e gravação remota inevitavelmente trará uma certa perda no desempenho de leitura e gravação. No entanto, trocar uma certa perda de desempenho pela racionalidade da arquitetura e reduzir o custo de operação e manutenção realmente superam as desvantagens.
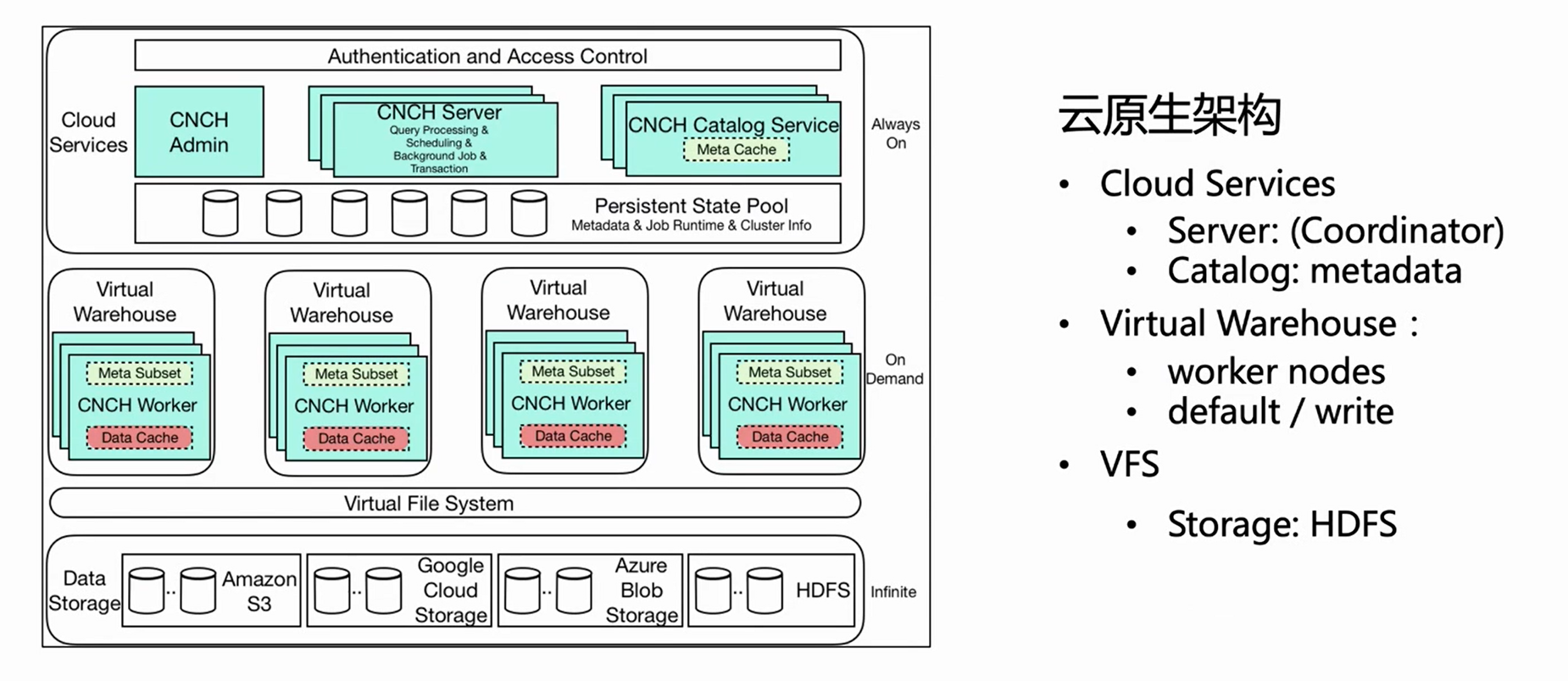
A imagem acima é o diagrama de arquitetura da arquitetura nativa da nuvem ByteHouse. Este artigo apresenta vários componentes relacionados importantes para importação em tempo real.
-
Serviço na nuvem
Em primeiro lugar, a arquitetura geral é dividida em três camadas: A primeira camada é Cloud Service, que inclui principalmente dois componentes, Server e Catlog. Essa camada é a entrada do serviço e todas as solicitações do usuário, incluindo importações de consultas, entram no servidor. O servidor apenas pré-processa a requisição, mas não a executa; após o Catlog consultar a metainformação, ele envia a requisição pré-processada e a metainformação para o Virtual Warehouse para execução.
-
Armazém Virtual
Virtual Warehouse é a camada de execução. Diferentes empresas podem ter armazéns virtuais independentes para obter o isolamento de recursos. Agora, o Virtual Warehouse é dividido principalmente em duas categorias, uma é Default e a outra é Write. Default é usado principalmente para consulta e Write é usado para importação para realizar a separação de leitura e gravação.
-
VFS
A camada inferior é VFS (armazenamento de dados), que oferece suporte a componentes de armazenamento em nuvem, como HDFS, S3 e aws.
Design de importação em tempo real com base na arquitetura nativa da nuvem
Na arquitetura nativa da nuvem, o servidor não realiza uma execução específica de importação, mas apenas gerencia tarefas. Assim, do lado do servidor, cada mesa de consumo terá um Manager para gerenciar todas as tarefas de execução de consumo e agendá-las para serem executadas no Virtual Warehouse.
Por herdar o modo de consumo de baixo nível do HaKafka, o gerente distribuirá uniformemente as partições de tópico para cada tarefa de acordo com o número configurado de tarefas de consumo; o número de tarefas de consumo é configurável e o limite superior é o número de partições de tópico.
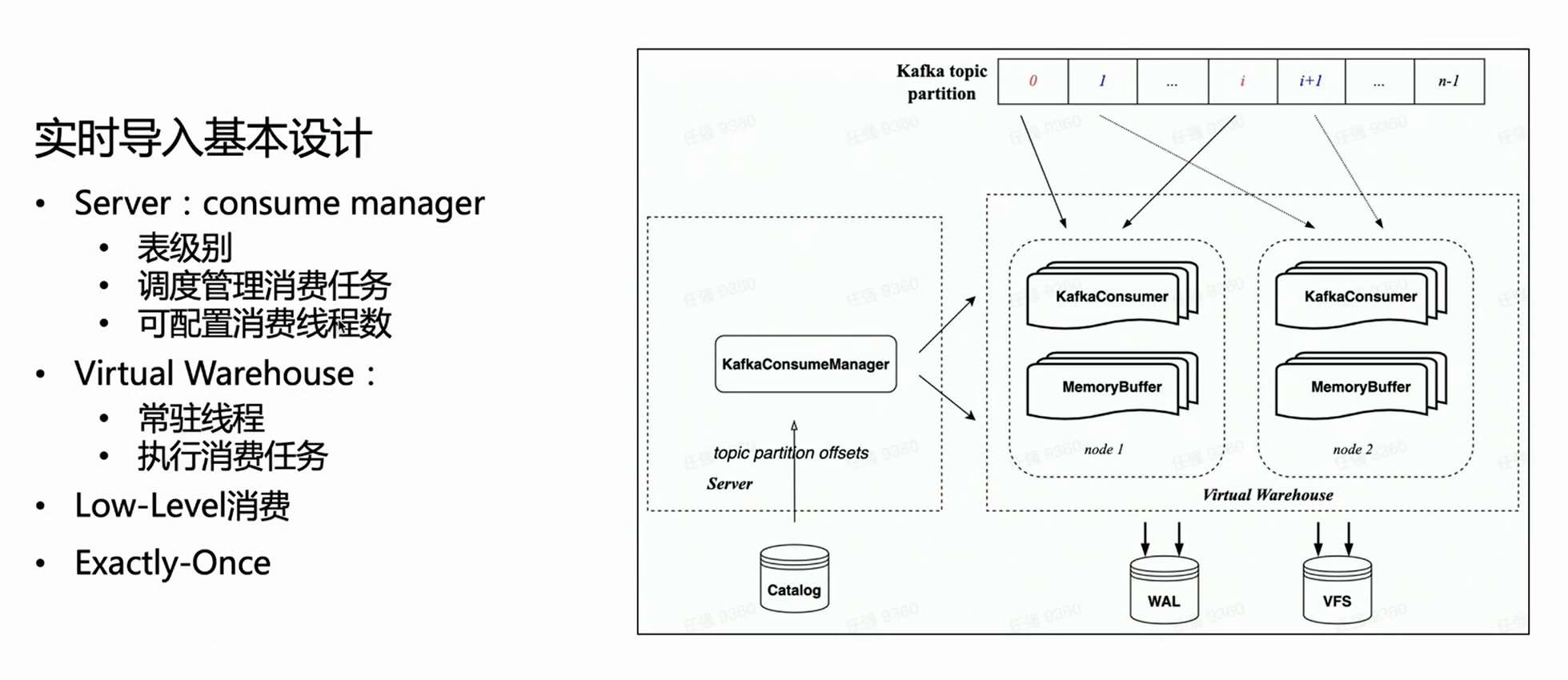
Com base na figura acima, você pode ver que o Gerenciador à esquerda obtém o Offset correspondente do catálogo e aloca a Partição de consumo correspondente de acordo com o número especificado de tarefas de consumo e as agenda para diferentes nós do Armazém Virtual para execução.
Novo Processo de Execução de Consumo
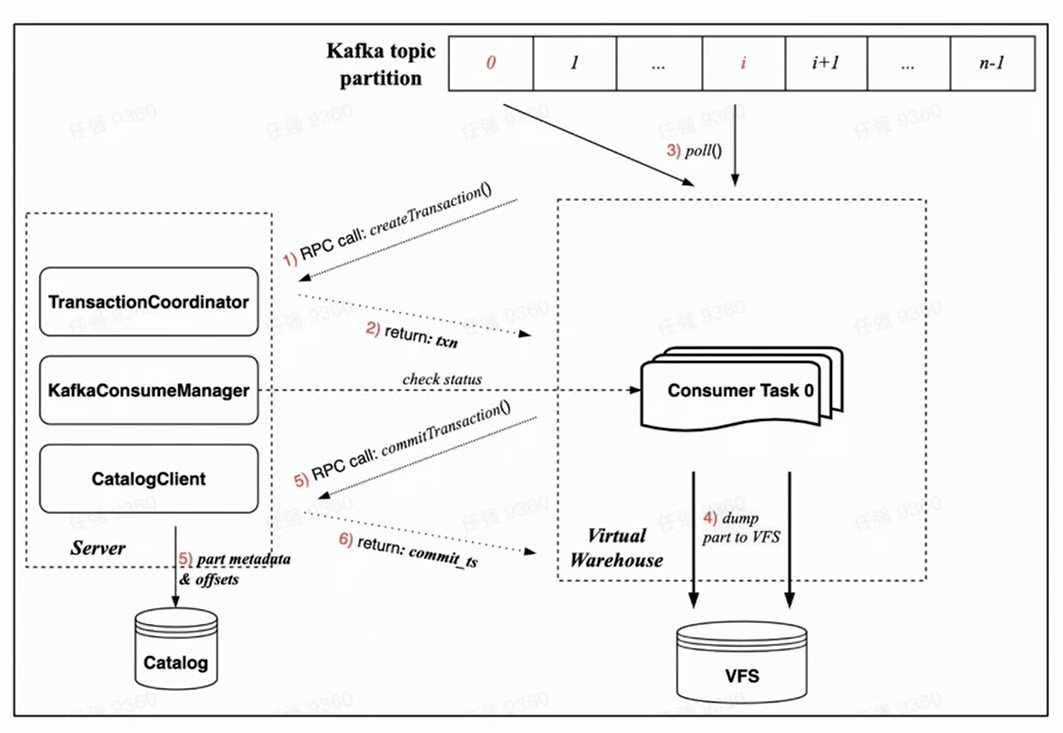
Como a nova arquitetura nativa da nuvem é garantida por Transação, espera-se que todas as operações sejam concluídas em uma transação, o que é mais racional.
Contando com a implementação do Transaction sob a nova arquitetura nativa da nuvem, o processo de consumo de cada tarefa de consumo inclui principalmente as seguintes etapas:
-
Antes do início do consumo, a tarefa do lado Worker primeiro solicitará ao lado Server a criação de uma transação por meio de uma solicitação RPC;
-
Execute rdkafka::poll() para consumir uma certa quantidade de tempo (8s por padrão) ou um bloco de tamanho suficiente;
-
Converter o bloco para Parte e despejar para VFS ( os dados não estão visíveis neste momento );
-
Iniciar uma solicitação de confirmação de transação para o servidor por meio de solicitação RPC
(Os dados de confirmação na transação incluem: despejar os metadados da peça concluída e o deslocamento Kafka correspondente)
-
A transação foi confirmada com sucesso ( os dados estão visíveis )
garantia de tolerância a falhas
A partir do processo de consumo acima, podemos ver que a garantia de consumo tolerante a falhas sob a nova arquitetura nativa da nuvem é baseada principalmente na pulsação bidirecional de Gerenciador e Tarefa e na estratégia de falha rápida:
-
O próprio Gerenciador fará uma sondagem regular, e verificará se a Tarefa agendada está sendo executada normalmente via RPC;
-
Ao mesmo tempo, cada Tarefa usará a solicitação RPC da transação para verificar sua validade durante o consumo. Uma vez que a verificação falha, ela pode ser automaticamente eliminada;
-
Uma vez que o gerenciador falha em detectar a atividade, ele iniciará imediatamente uma nova tarefa de consumo para obter a garantia de tolerância a falhas de segundo nível.
Gastar poder
Quanto à capacidade de consumo, refere-se acima que é escalável, podendo o número de tarefas de consumo ser configurado pelo utilizador, até ao número de Partições do Tópico. Se a carga do nó no Virtual Warehouse for alta, o nó também pode ser expandido levemente.
Obviamente, a tarefa de agendamento do Manager implementa a garantia básica de balanceamento de carga - use o Resource Manager para gerenciar e agendar tarefas.
Aprimoramento semântico: exatamente - uma vez
Por fim, a semântica de consumo sob a nova arquitetura nativa da nuvem também foi aprimorada — de At-Least-Once da arquitetura de livro distribuído para Exactly-Once.
Como a arquitetura distribuída não possui transações, ela só pode atingir At-Least-Once, o que significa que nenhum dado será perdido em nenhuma circunstância, mas em alguns casos extremos pode ocorrer consumo repetido. Na arquitetura nativa da nuvem, graças à implementação de Transaction, cada consumo pode fazer Part e Offset atomicamente comprometidos por meio de transações, de modo a obter o aprimoramento semântico do Exactly-Once.
Buffer de memória
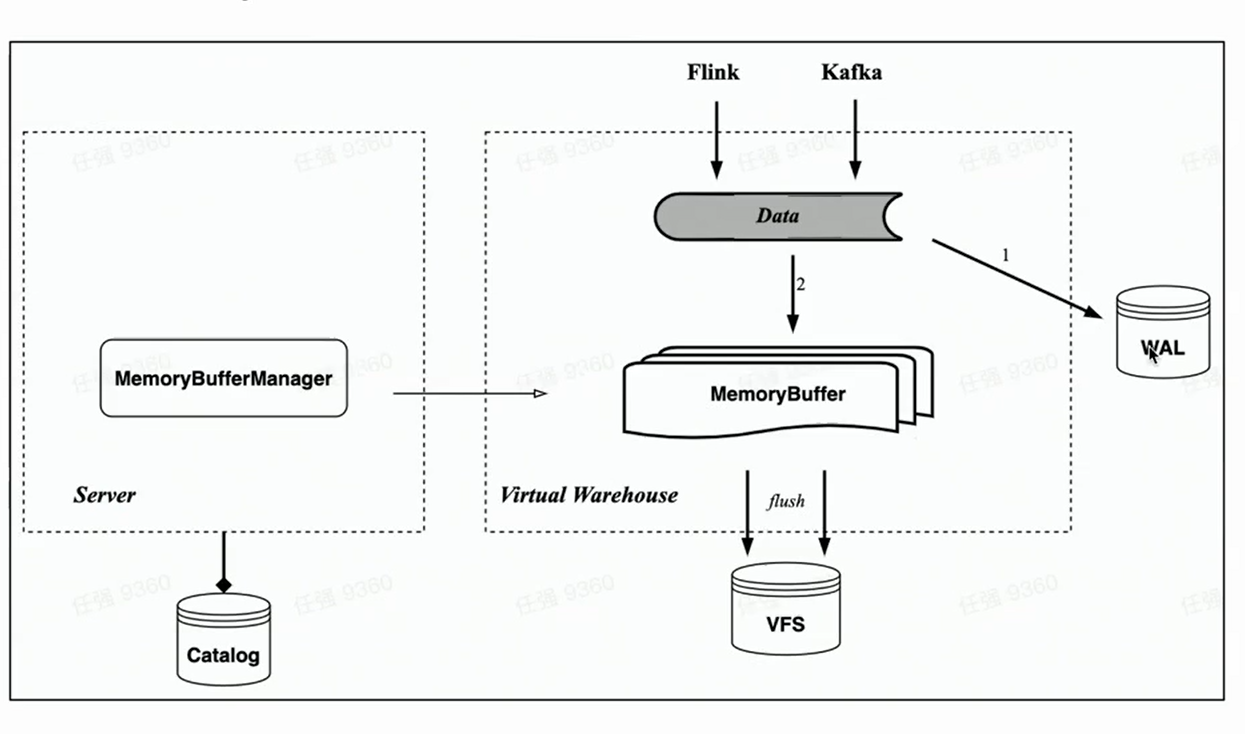
Correspondendo à tabela de memória do HaKafka, a arquitetura nativa da nuvem também implementa a importação do cache de memória Memory Buffer.
Ao contrário da Memory Table, o Memory Buffer não está mais vinculado às tarefas de consumo do Kafka, mas é implementado como uma camada de cache para tabelas de armazenamento. Desta forma, Memory Buffer é mais versátil, podendo ser usado não só para importação Kafka, mas também para importação de pequenos lotes como Flink.
Ao mesmo tempo, introduzimos um novo componente WAL. Quando os dados são importados, primeiro escreva WAL, desde que a gravação seja bem-sucedida, pode-se considerar que a importação de dados foi bem-sucedida - quando o serviço é iniciado, você pode primeiro restaurar os dados que não foram atualizados do WAL; então escreva o buffer de memória e os dados ficarão visíveis após a gravação bem-sucedida - porque o buffer de memória pode ser consultado pelos usuários. Os dados do Memory Buffer também são periodicamente liberados e podem ser apagados do WAL após a liberação.
Aplicação de negócios e pensamento futuro
Por fim, apresenta brevemente o status atual da importação em tempo real em Byte e a possível direção de otimização da tecnologia de importação em tempo real da próxima geração.
A tecnologia de importação em tempo real da ByteHouse é baseada em Kafka, a taxa de transferência diária de dados está no nível PB e o valor da experiência de thread único importado ou taxa de transferência de consumidor único é de 10-20MiB/s. (O valor empírico é enfatizado aqui, porque esse valor não é um valor fixo, nem é um valor de pico; a taxa de transferência de consumo depende muito da complexidade da tabela do usuário, à medida que o número de colunas da tabela aumenta, o desempenho da importação pode ser significativamente reduzido, uma fórmula de cálculo precisa não pode ser usada. Portanto, o valor da experiência aqui é mais o valor da experiência de desempenho de importação da maioria das tabelas dentro do byte.)
Além do Kafka, o Byte realmente suporta a importação em tempo real de algumas outras fontes de dados, incluindo RocketMQ, Pulsar, MySQL (MaterializedMySQL), escrita direta do Flink, etc.
Pensamentos simples sobre a próxima geração de tecnologia de importação em tempo real:
-
Uma tecnologia de importação em tempo real mais geral permite que os usuários suportem mais fontes de dados de importação.
-
A visibilidade dos dados é uma compensação entre latência e desempenho.
Clique para pular para o data warehouse nativo da nuvem ByteHouse para saber mais