modelo GPT
Modelo GPT: pré-treinamento generativo
A estrutura geral:
Pré-treinamento não supervisionado
Ajuste fino supervisionado para tarefas posteriores
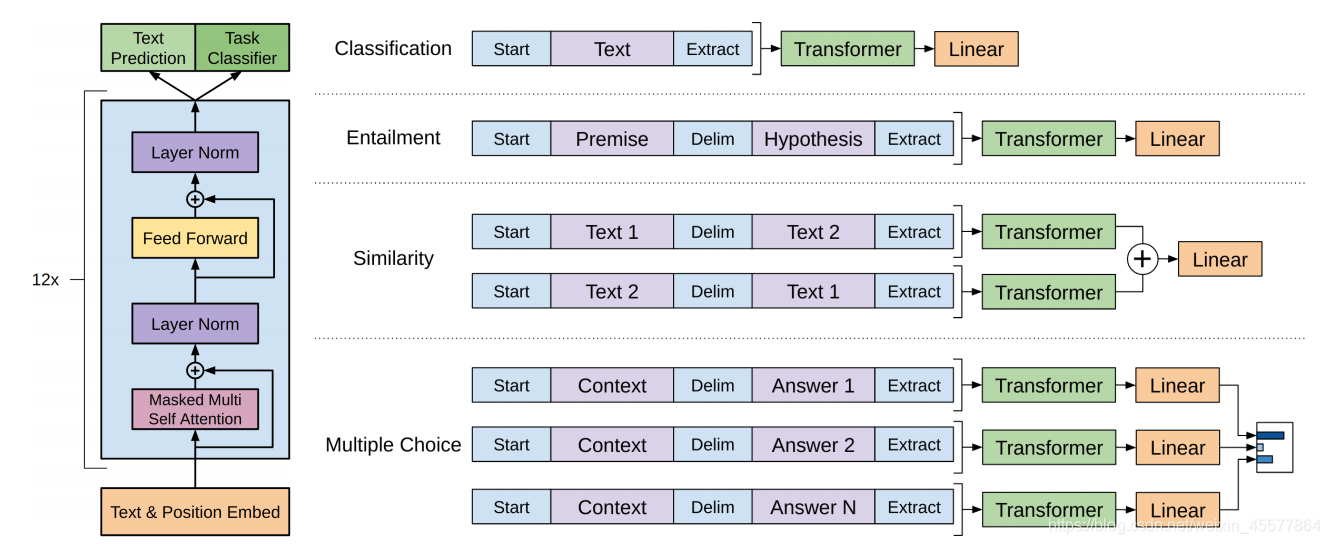
Estrutura do núcleo: a parte do meio é composta principalmente por 12 blocos do Transformer Decoder empilhados
A imagem a seguir reflete de forma mais intuitiva a estrutura geral do modelo:
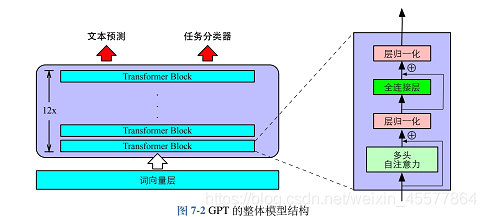
descrição do modelo
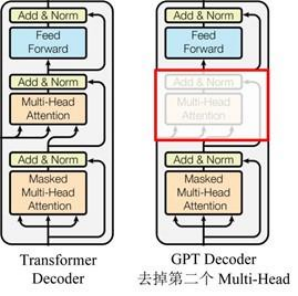
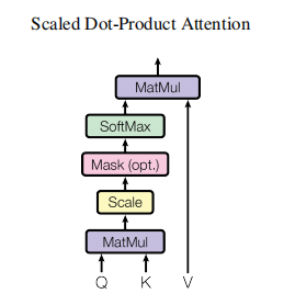
O GPT usa a estrutura do Decoder do Transformer e faz algumas alterações no Transformer Decoder.O Decoder original contém duas estruturas Multi-Head Attention, e o GPT retém apenas Mask Multi-Head Attention, conforme mostrado na figura abaixo .
(Muitos dados dizem que é semelhante à estrutura do decodificador, porque o mecanismo de máscara do decodificador é usado, mas, além disso, na verdade parece mais semelhante ao codificador; portanto, às vezes é implementado ajustando o codificador. Não )
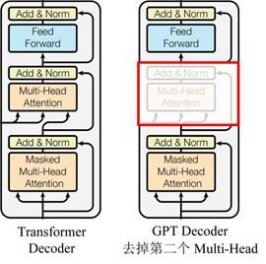
Comparado com a estrutura do transformador original
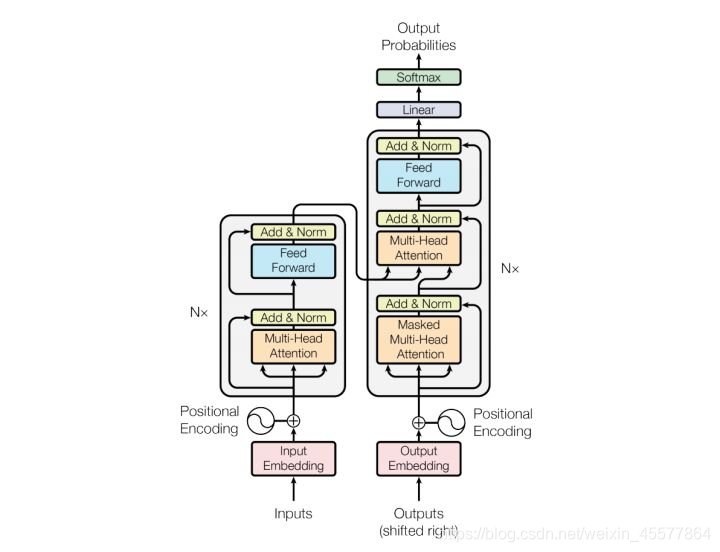
descrição do palco
Fase pré-treino:



O estágio de pré-treinamento é a previsão de texto, ou seja, prever a palavra atual com base nas palavras históricas existentes. As três fórmulas 7-2, 7-3 e 7-4 correspondem ao diagrama de estrutura GPT anterior e a saída P (x) é a saída. A probabilidade de cada palavra ser prevista e, em seguida, use a fórmula 7-1 para calcular a função de máxima verossimilhança e construa uma função de perda com base nisso, ou seja, o modelo de linguagem pode ser otimizado.
Estágio de ajuste fino da tarefa downstream

função de perda
Uma combinação linear de tarefas downstream e perdas de tarefas upstream

processo de cálculo:
- digitar
- Incorporação
- Bloco transformador de várias camadas
- Obter dois resultados de saída
- calcular perda
- retropropagação
- parâmetros de atualização
Um código de exemplo GPT específico:
você pode ver que na função direta do modelo GPT, a operação de incorporação é executada primeiro, depois a operação é executada no bloco do transformador de 12 camadas e, em seguida, o valor do cálculo final é obtido por meio de duas transformações lineares (uma para previsão de texto), uma para o classificador de tarefas), o código é consistente com o diagrama de estrutura do modelo mostrado no início.
Referência: Não se preocupe
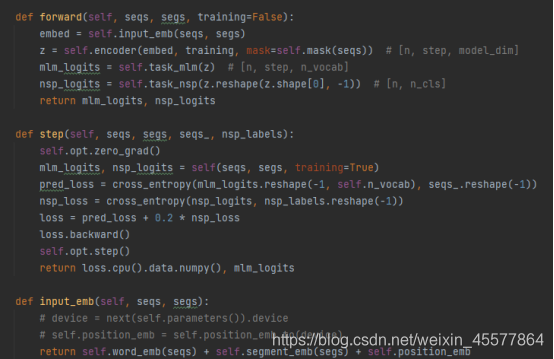
com o código de implementação Python GPT Vamos nos concentrar nas etapas de cálculo 2 e 3
Detalhes do cálculo:
[Camada de incorporação]:
A camada de incorporação para operação de pesquisa de tabela
é uma camada totalmente conectada com um hot como entrada e nós de camada intermediária como dimensões de vetor de palavras. E o parâmetro dessa camada totalmente conectada é uma "tabela de vetores de palavras".

A multiplicação de matriz de um tipo quente é equivalente a uma pesquisa de tabela, portanto, ela usa diretamente a pesquisa de tabela como uma operação em vez de escrevê-la em uma matriz para cálculo, o que reduz bastante a quantidade de cálculo. É enfatizado novamente que a redução na quantidade de computação não se deve ao surgimento de vetores de palavras, mas porque a operação de uma matriz quente é simplificada para uma operação de consulta de tabela.
[Camada do decodificador semelhante ao transformador no GPT]:
Cada camada do decodificador contém duas subcamadas
- sublayer1: camada de atenção multicabeça para máscara
- subcamada2: ffn (rede feedforward) rede feedforward (perceptron multicamada)
sublayer1: camada de atenção de várias cabeças da máscara
输入:q, k, v, máscara
计算注意力:Linear (multiplicação de matrizes)→Atenção escalada de produto escalar→Concat (resultados de atenção múltipla, remodelar)→Linear(multiplicação de matrizes)
残差连接和归一化操作:Operação de dropout → conexão residual → operação de normalização de camada
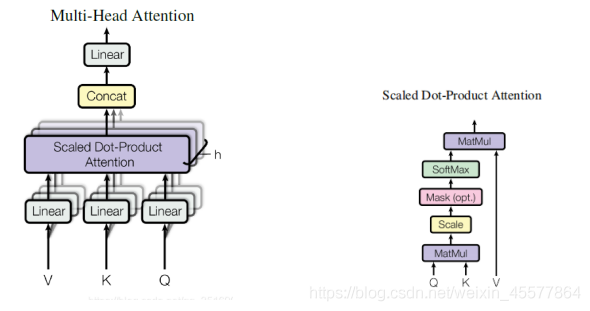
processo de cálculo:
O parágrafo a seguir descreve o processo geral de cálculo da atenção:

Instruções de explosão:
Máscara de atenção multicabeça
1. Multiplicação de matrizes:
Transforme a entrada q, k, v
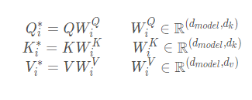
2. Atenção escalado do produto escalar
O principal é realizar o cálculo da atenção e a operação da máscara
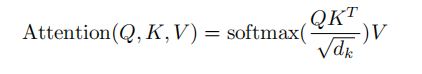
Operação da máscara: masked_fill_(mask, value)
mask operation, preenche o elemento no tensor correspondente ao valor 1 na máscara com valor. A forma da máscara deve corresponder à forma do tensor a ser preenchido. (Aqui, o preenchimento -inf é usado, de modo que o softmax se torne 0, o que equivale a não ver as seguintes palavras)
A operação da máscara no transformador
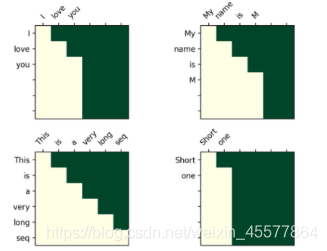
Matriz de visualização após máscara:
O entendimento intuitivo é que cada palavra só pode ver a palavra antes dela (porque o objetivo é prever a palavra futura, se você a vir, não precisa predizê-la)
3. Operação de concatenação:
Combinar os resultados de várias cabeças de atenção realmente transforma a matriz: operações de permuta, remodelação e redução de dimensionalidade. (Conforme mostrado na caixa vermelha na figura abaixo)
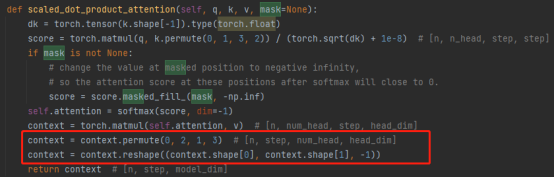
4. Multiplicação de matrizes: uma camada Linear, que transforma linearmente os resultados da atenção
A camada de atenção de várias cabeças de toda a máscara 代码:
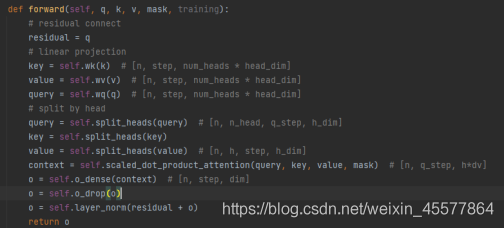
Nota: as seguintes linhas no código acima são para 残差连接和归一化操作
explicar o processo de resultados de atenção:
Conexão residual e operações de normalização:
5. Eliminar camada
6. Adição de matriz
7. Normalização da camada
A normalização em lote é a normalização de um único neurônio entre diferentes dados de treinamento, e a normalização de camada é a normalização de um único dado de treinamento entre todos os neurônios de uma determinada camada.
Normalização de entrada, normalização de lote (BN) e normalização de camada (LN)
代码展示:
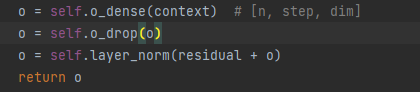
subcamada2: ffn (rede feedforward) rede feedforward
1. Camada linear (multiplicação de matrizes)
2. Ativação da função Relu
3. Camada linear (multiplicação de matrizes)
4. Operação de abandono
5. Normalização de camadas
[Camada linear]:
Os resultados de saída do bloco multicamadas são colocados em duas camadas lineares para transformação, o que é relativamente simples e não será descrito em detalhes.
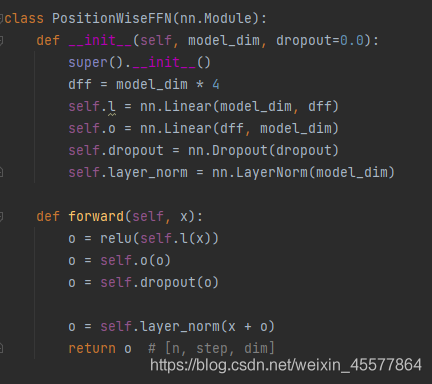
Suplemento: diagrama de fluxo da camada de atenção
Referências
1. Artigo de referência: Radford e outros "Improving Language Undersatnding by Generative Pre-Training"
2. Livro de referência: "Natural Language Processing Based on Pre-training Model Method" Che Wanxiang, Guo Jiang, Cui Yiming
3. A fonte do código neste artigo: Não se preocupe com o código de implementação Python GPT
4. Outros links de referência (partes mencionadas na postagem do blog):
Análise do processo de cálculo de incorporação de palavras
Análise da dimensão da matriz do Transformer e explicação detalhada da máscara