As declarações da Oracle precisam ser entendidas ~
oracle知识的总结
1. Principais tipos de dados
1. Tipo de personagem
varchar(10):定长的字符型数据
char(2):定长的字符型数据
varchar2(20):变长的字符串数据
long :变长度的字符串,最大字节数可达2GB
BLOB:二进制数据,最大字节数4G
BFILE:二进制数据外部存储,最大字节数4G
2.Tipo de dados
number(4):不带小数点的数据
number(8,2):数据的总长度是8位,小数点后占两位
3.Tipo de data
date
2. Classificação de instruções SQL
Instruções DML (linguagem de manipulação de dados)
inserir adicionar/atualizar modificar/excluir excluir/mesclar mesclar
Instruções DDL (linguagem de definição de dados)
criar criar/descartar excluir/truncar
Instrução DCL (linguagem de controle de dados)
conceder/revogar
declaração de controle de transação
commit/reversão/ponto de salvamento
3. Operações de tabela
~Criar
--创建数据表
1.在建表的时候,先建立父表,后建立子表;
2.先添加父表数据,后添加子表数据
3.删除数据的时候,先删除子表数据,后删除父表数据
4.删除表的时候,先删除子表,后删除父表
--创建表
create table card(
cid number(4) primary key,
pname varchar2(20)
);
create table perscn(
pid number(4) primary key,
pname varchar2(20),
cid number(4),
--添加外键,给表添加外键,指定哪个表
constraints FK_Per_crad foreign key(cid) references card(cid),
constraint cid_uni unique (cid)
)
--查看表结构,只能在命令行模式下
desc users;
--删除表
drop table "表名";/*没有 if exists字段*/
-
Use subconsultas ao criar tabelas
create table user as select name ,age from user where id=5; --创建表和查询的字段一样 create table user_a("名字","性别","住址") as select * from user; -
Um sinônimo
é um alias para um objeto de banco de dados que simplifica o acesso aos bancos de dados de outros usuários.select name from user_table; --创建user_table表名的别名user,方便使用 create or repalce synonym user for user_table
~Alter modifica a tabela (estrutura da tabela)
alterar tabela nome da tabela adicionar tipo de dados de campo
/*添加单行*/
alter table user add score varchar2(3);
/*添加多行*/
alter table user add (score varchar2(3),disth varchat2(100))
-
Modificar campos
--在改字段没有数据的时候,字段的类型和长度都是可以修改的 alter table user modify tel number(11); --对于缺省值的修改,不会影响已经存在的数据,只会对以后插入的数据产生影响 --不会改变表中的性别,但对新插入的数据的性别会有影响 alter table user modify sex default '女'; --当该字段有数据的时候,字段的类型是不能修改的;字段的长度是可以修改的,增大总是可以的,减少要看数据的实际长度; alter table user modify name varchar2(20); -
Excluir campo
--有无数据都可以删除 alter table user drop column name; -
Modifique o nome da coluna e use to para conectar (não usado com mysql)
--将user中addre列名改为address alter table user rename addre to address; -
Modificar o tipo de coluna (não pode ser modificado quando há dados, o mysql pode)
--将user中的score列类型修改 alter table user modify (score varchar2(3));
~inserirInserir
--一次性插入多条数据,复制表中的数据,把插入结果当作数据插入到表中
insert into user select * from user1;
~atualizar atualização
--使用update语句的时候,在事务没有结束之前,该条数据会被锁住,其他的用户无法修改这条数据
--事务结束之后,该条数据的锁放开,其他的用户可以操作这条数据
update user set ename='xiaoming',eage=3,eaddre='pingyao' where empid=5;
~deleteExcluir
delete from user where sal > 5000;
比较,删除表truncate table
删除表的数据,truncate table 比delete的删除速度快,但是改命令一定要慎重使用
清空users表
truncate table users;--回滚是不可能的
~Mude o nome do objeto
--改变表的名字
rename user to users;
用 ‘||’ 可以把两列或者多列查询结果合并到一起
- 任何类型都支持null
~Adicionar comentários às colunas da tabela
--给表userTable的name字段加注释
comment on column userTable.name is '用户名';
--给表userTable加注释
comment on table userTable is '用户信息表';
Imagem de referência

·4. Remover duplicação numérica distinta
--去除单列重复的数据
select distinct deptno from emp;
--去除多列重复的数据
select distinct job,deptno from emp
·5. Filtragem de cláusulas Where
-
Aspas simples'' devem ser usadas para dados de caracteres e dados de data.
-
Para dados do tipo data, o formato é sensível. O formato dos dados do tipo data é DD-MM-AAAA (dia-mês-ano)
--查询emp表时间为'20-02-1981'的数据
select * from emp where date='20-02-1981'
- Alterar o formato da data na sessão atual
--改变会话session的日期格式为"YYYY-MM-DD HH:MI:SS"
alter session set date = "YYYY-MM-DD HH:MI:SS"
- Use outros operadores de comparação em condições de consulta.
Use and em vez de && e
or em vez de ||
·6. Como consulta difusa
--名字带%号的,相当于转义符;即,‘\’为转移字符,第二个‘%’为普通字符,第一第三个是通配符
select * from emp where ename like '%\%%' escape '\';
·7. Funções de linha única e funções multilinha
- Função de linha única: pegue um registro por vez e use-o como parâmetro da função para obter um único resultado correspondente a este registro.
Categoria: funções de caracteres, outras funções, funções de conversão, funções de data, funções numéricas, funções trigonométricas
--查询emp表中名字和名字的长度
select name,length(name) from emp;
- Função multilinha: insira vários registros como parâmetros para a função ao mesmo tempo e obtenha um único resultado correspondente a vários registros.
select max(sal) from emp;
①Função de personagem
- Use minúsculo para converter para minúsculas
--查询emp表并将名字是‘smith’的转换成小写
select * from emp where lower(ename)='smith';
- Use maiúscula para converter para maiúsculas
--查询emp表并将名字是‘smith’的转换成大写
select * from emp where ename=upper('smith');
- Converter caixa de camelo usando initcap
--查询emp表并将名字是‘smith’转换成驼峰式写法
select ename,initcap(ename) from emp where initcap(ename)='Smith';
- O caractere de conexão é concat
concat (x, s1, s2, s3...), que é igual a concat, exceto que x é adicionado entre cada string.
--concat 只能连接两个字符,而 “||” 可以连接多个字符。
select concat('aa','bb') from test; --得aabb
- Interceptar string usando substr
--截取字符串 用substr
--截取ename从第一个字符到第二个字符(没有第0个)
select ename,substr(ename,1,2) from emp;
- Use instr para retornar a posição do subscrito
--打印字符出现的位置 instr
--名字中有A的位置(从左下标第1位开始,A在第几位就返回第几位,如果没有A这个字符就会返回的是0)
select ename ,instr(ename,'A') from emp;
- Uso complementar lpad, rpad
--补充字符 lpad,rpad
--把sal字段的内容扩展成8位,左边(lpad)不够用*代替,右边(rpad)不够用#代替
select sal ,lpad(sal,8,'*'),rpad(sal,8,'#') from emp;
- Substituir por substituir
--替换 replace
--将名字中的有A的找到,将其替换成a,没有的话就不动
select ename.replace(ename,'A','a') from emp;
- ASCII(s): Retorna o valor do código ASCII do primeiro caractere da string s
- CHAR_LENGTH(S): Retorna o número de caracteres na string s, a mesma função que CHARACTER_LENGTH(S)
- length(s): Retorna o número de bytes da string s, relacionados ao conjunto de caracteres
- left(str,n): Retorna os n caracteres mais à esquerda da string str
- right(str,n): Retorna os n caracteres mais à direita da string str
- LTRIM(S): Remove espaços no lado esquerdo da string s
- RTRIM(S): Remove espaços no lado direito da string s
- TRIM(S): Remove espaços no início e no final da string s
- TRIM(S1 FROM S): Remove s1 no início e no final da string s
- TRIM (LENDING S1 FROM S): Remova s1 no início de s
- TRIM(TRAILING S1 FROM S): remova s1 no final de s
- REPEAT(STR,N): Retorna o resultado de str repetido n vezes
- ESPAÇO(N): retorna n espaços
- STRCMP(s1,s2): Compare o tamanho dos valores do código ASCII das strings s1 e s2
- LOCATE(substr, str): Retorna a posição onde a string substr aparece pela primeira vez na string str
- FIELD(S,S1,S2,S3…): Retorna a posição da primeira ocorrência da string s na lista de strings
②Função numérica
- Use round para arredondar
--得45.26,45,41
select round(45.2568,2) "小数点后两位",
round(45.2568,0) "个位",
round(45.2568,-1) "十位"
from NUMTable;
- Intercepte o valor sem arredondar, use trunc
select trunc(45.2568,2) "小数点后两位",
trunc(45.2568,0) "个位",
trunc(45.2568,-1) "十位"
from NUMTable;
- Use mod para encontrar o restante
select ename,sal,mod(sal,300)
from emp where empno=7369
查询编号为7369的人的工资除以300的余数
| Resumo da função | uso |
|---|---|
| ABS(x) | Retorna o valor absoluto de x |
| SINAL(x) | Retorna o sinal de x. Números positivos retornam 1, números negativos retornam -1, 0 retorna 0 |
| PI() | Retorna o valor de pi |
| TETO (x), TETO (x) | Retorna o menor inteiro maior ou igual a um valor |
| ANDAR(x) | Retorna o maior inteiro menor ou igual a um valor |
| MENOS (e1, e2, e3…) | Retorna o valor mínimo da lista |
| MAIOR (e1,e2,e3) | Retorna o valor máximo da lista |
| MOD(x,y) | Retorna o resto após dividir x por y |
| Rand() | Retorna um valor aleatório de 0 a 1 |
| Rand (x) | Retorna um valor aleatório de 0 a 1, onde o valor de x é usado como valor inicial. O mesmo valor de x gerará o mesmo número aleatório. |
| rodada (x) | Retorna o valor mais próximo de x após arredondar o valor de x |
| rodada (x, y) | Retorna o valor de x arredondado para o valor de x mais próximo, preservando y dígitos após a vírgula decimal |
| truncar (x,y) | Retorna o número x truncado em y casas decimais |
| quadrado(x) | Retorna a raiz quadrada de x. Quando x é negativo, retorna nulo |
Funções trigonométricas
| função | uso |
|---|---|
| pecado (x) | Retorna o valor do seno de x, onde o parâmetro x é o valor em radianos |
| asin(x) | Retorna o arco seno de x. Se o valor de x não estiver entre -1 e 1, retorna nulo |
| cos(x) | Retorna o valor do cosseno de x, onde o parâmetro x é o valor em radianos |
| acos(x) | Retorna o valor do arco cosseno de x, ou seja, obtém o valor cujo cosseno é x; se o valor de x não estiver entre -1 e 1, retorna nulo |
| então(x) | Retorna o valor da tangente de x, onde o parâmetro x é o valor da tangente |
| tempo (x) | Retorna o arco tangente de x, ou seja, retorna o valor cuja tangente é x |
| atan2(x,y) | Retorna o arco tangente de dois argumentos |
| berço(x) | Retorna o valor cotangente de x, onde x é um valor em radianos |
③Função de data
Para valores de tipo de data, você pode usar os operadores + e -
1.一个日期+- 一个数值(就是+-一个天数),得到一个新的日期
2.两个日期型的数据相减,得到的是两者之间相差的天数
3.两个日期型的数据不能相加,日期型的数据不能进行乘除运算
- Subtraia datas exatas usando Mouths_between
--查询编号,今日,给定日期,相减日期除以365的值;粗糙日期
select empno, sysdate ,birthdate,(sysdate-birthdate)/365 from emp
--查询编号,今日,给定日期,相减日期除以365的值;精确日期,相差多少月
select empno, sysdate ,birthdate,(sysdate-birthdate)/365,mouths_between(sysdate,birthdate) from emp
- 相加精确日期 用add_mouths
select empno ,birthdate "雇佣日期",(birthdate+90) "粗略的转正日期",add_mouths(birthdate,3) "精确的转正日期" from emp;
- Use next_day para a próxima semana
select sysdate "当前日期",next_day(sysday,'星期一') 下周星期一 from emp;
- Use next_day para o último dia
--所在月份的最后一天
select ename , birthdate,last_day(birthdate) from emp;
- rodada dos últimos dias
select sysdate 当时日期,
round(sysdate) 最近0点日期,
round(sysdate,'day') 最近星期日,
round(sysdate,'mouth') 最近月初,
round(sysdate,'q') 最近季初日期,
round(sysdate,'year') 最近年初日期
from numTable;
Obtenha a data há 10 minutos
select sysdate,sysdate-interval '10' minute from dual;
Obtenha a data há uma semana
select sysdate, sysdate - interval '7' day from dual
Obtenha a data há um mês
select sysdate,sysdate-interval '1' month from dual;
Obtenha a data há um ano
select sysdate,sysdate-interval '1' year from dual;
Obtenha o número total de dias do mês
select to_number(to_char(last_day(sysdate),'dd')) from dual;
Obtenha o número total de dias em um determinado mês
select to_number(to_char(last_day(to_date('2018-09','yyyy-mm')),'dd')) from dual;
Consultar todas as datas de um determinado mês
SELECT TO_CHAR(TRUNC(to_date('2018-09','yyyy-MM'), 'MM') + ROWNUM - 1,'yyyy-MM-dd') someday FROM DUAL
CONNECT BY ROWNUM <= TO_NUMBER(TO_CHAR(LAST_DAY(to_date('2018-09','yyyy-MM')), 'dd'));
- Retorna a data atual, incluindo apenas ano, mês e dia
CURDATE(),CURRENT_DATE()
- Retorna a hora atual, incluindo apenas horas, minutos e segundos
CURTIME(),CURRENT_TIME()```
- Retorna a data e hora atuais do sistema
NOW()/SYSDATE()/CURRENT_TIMESTAMP()/LOCALTIME()/LOCALTIMESTAMP()
- Retorna uma data UTC (Tempo Universal Coordenado)
UTC_DATE()
- Retorna a hora UTC (Tempo Universal Coordenado)
UTC_TIME()
- Conversão de hora e carimbo de data/hora
SELECT UNIX_TIMESTAMP(‘2021-10-01 12:12:32’),FROM_UNIXTIME(1635173853) FORM DUAL;
- YEAR() retorna o ano, MONTH() retorna o mês, DAY() retorna o dia, HOUR() retorna a hora, MINUTE() retorna o minuto, SECOND() retorna o segundo
- Retorna o mês, julho
MONTHNAME(DATE)
- Retorna o dia da semana: SEGUNDA-FEIRA
DAYNAME(DATE)
- Retorne o dia da semana: observe que o dia 1 é 0
WEEKDAY(DATE)
- Retorna o trimestre correspondente à data, variando de 1 a 4
QUARTER(date)
- Retorna a semana do ano
WEEK(DATE),WEEKOFYEAR(DATE)
- A data de retorno é o dia do ano
DAYOFYEAR(DATE)
- Retorna o dia do mês em que a data está localizada
DAYOFMONTH(DATE)
- Retorna time1 menos time2. Quando time2 é um número, ele representa segundos e pode ser negativo.
SUBTIME(time1,time2)
- Retorna o número de dias entre data1-data2
DATEDIFF(date1-date2)
- Retorna o intervalo de tempo entre time1-time2
TIMEDIFF(time,time2)
- Retorna a data n dias após 1º de janeiro de 0000
FROM_DAYS(N)
- Retorna o número de dias a partir de 1º de janeiro de 0000
TO_DAY(date)
- Retorna a data do último dia do mês em que a data está localizada
LAST_DAY (date)
- Combina as horas, minutos e segundos fornecidos em um horário e retorna
MARKTIME(hour,minute,second)
- Retorna hora após hora mais n
PERIOD_ADD(TIME,N)
④Função de conversão
Existem duas formas de conversão: conversão implícita e conversão manual
- Converter valor numérico em caractere ——to_char()
--要查日期,而这个日期是字符串,所以要将日期转化成字符串
select empno,ename from emp where birthdate = '2020-02-03';
--转换
select empno,ename from emp where to_char(birthdate,'YYYY-MM-DD') = '2020-02-03';
--数值转换成字符
select sal, to_char(sal,'$999,999.00'),to_char(sal,'L000,000.00') from emo where id='5'
/*
9:代表一个数字(有数字就显示,没有就不显示)
0:强制显示0
$:放置一个$符
L:放置一个本地货币符
. :(点)显示小数点
,:(逗号)显示千位指示符
*/
- Converter caractere para data ——to_date()
select * from emp where birthdate=to_date('1999-12-25','YYYY-MM-DD');
- Converter caracteres em números ——to_number()
--字符的格式和模板的格式必须要一致,相当于都必须用¥ 或者 $
select to_number('$800,00','$999,99.00') from numTable;
- Converter data em caractere ——to_char()
--日期转字符串
select sysdate,to_char(sysdate,'YYYY-MM-DD HH24:MI:SS AM DAY') from numTable;
⑤Outras funções
- nvl (campo, valor retornado);
Se for nulo, defina-o como 0
#模糊查询在mybatis中
select nvl(x.ZHS,0) zhs from xq x
where
<if test="name!= null and name!= ''">
x.name like concat(#{name},'%')
</if>
select ename,nvl(gongzuo,'还没有找到工作') from user;
- nvl2 (campo, não o valor retornado por nulo, o valor retornado por nulo)
--查询id为5的人如果不是null则返回job,如果式null返回‘没工作’
select nvl2(job,job,'没工作') from user where id=5
-
NULLIF (valor 1, valor 2) ; compara duas expressões, retorna um valor nulo se forem iguais, retorna a primeira expressão se não forem iguais
--举例,第一个相等返回空值,第二个不相等,返回第一个 select ename,eaddre, nullif(length(ename),length(ename)) num1,nullif(length(ename),length(eaddre)) num2 from emp; -
CASE implementa a função if…else if…else
select ename,job,sal,
case job
when '经理' then
0.90 * sal
when '主管' then
0.80 * sal
when '队长' then
0.50 * sal
else '员工'
0.30 * sal
end as '工资捐赠数'
from emp where ename='小明';
例2:
(case QYLX when '地质灾害高易发区' then 1
when '地质灾害中易发区' then 2
when '地质灾害低易发区' then 3
when '地质灾害不易发区' then 4 end ) as NUM
- DECODE implementa a função de if…else if…else
eg1:
select ename,job,sal,
decode(job
'经理',
0.90 * sal,
'主管' ,
0.80 * sal,
'队长',
0.50 * sal,
0.30 * sal) as '工资捐赠数'
from emp where ename='小明';
ex2:
decode(X,A,B,C,D,E)
//这个函数运行的结果是,当X = A,函数返回B;
//当X != A 且 X = C,函数返回D;
//当X != A 且 X != C,函数返回E。
//其中,X、A、B、C、D、E都可以是表达式,这个函数使得某些sql语句简单了许多
- não é nulo não está vazio, é nulo está vazio
Filtrar valores que não estão vazios
select y.name, nvl(y.age,0) age ,nvl(y.score,0) score,y.nf
from user y
where y.name='xiaoming' is not null
and y.nf is not null;
--不在20-30之间
not between 20 and 30
NULL值与空值区别
空值长度为0,不占空间,NULL值得长度为null,占用空间
is null无法判断空值
空值使用"=“或者”<>"来处理(!=)
count()计算时,NULL会忽略,空值会加入计算
注:NULL是占用内存空间的,而空值则不占用内存空间
- Função Extrair()
--截取年份从PZRQ表的字段中
extract(year from rqDate) as NF
--截取月份从PZRQ表的字段中
extract(month from rqDate) as NF
--截取日期从PZRQ表的字段中
extract(day from rqDate) as NF
Usado para interceptar ano, mês, dia, hora, minuto, segundo
⑥Função aninhada
Para aninhar, você deve usar funções aninhadas;
-
função de agrupamento
max( ), min( ), avg( ), sum( ), count( )
avg, sum só pode ser usado para dados numéricos
max, min, count pode ser usado para qualquer tipo de dados
--求名字的最大值A为最小值,Z为最大值
select max(ename) Z,min(ename) A from emp;
contagem tem dois usos
1.count( * ) Consulte o número total de itens de dados
2.count(campo), neste caso os valores vazios são ignorados
select count(*) from emp;
select count(comm) from emp;
- Tendo
por exemplo: Encontrar os departamentos com salário médio superior a 6.000 em cada departamento, e seu salário médio
select id,avg(salary)salary
from username
having avg(salary)>6000
group by id;
--having avg(salary)>6000,也可以发在后面
-
função de grupo
- Após agrupar os dados, use a função de grupo
- Os campos que aparecem na lista de consulta aparecem na função de grupo ou na cláusula group by
- Também só pode aparecer em grupo por
--根据部门分组,查询工资 select max(sal) from emp group by bumenId;--根据部门分组,查询工资和部门 select bumenId,max(sal) from emp group by bumenId;--按照多个字段进行分组;部门和工作分组 select bumenId,job,max(sal) from emp group by bumenId,job order by bumenId--查询部门分组后,并且部门编号不为空的工资最大值 的最大值 select max(max(sal)) from emp where bumenId is not null group by bumenId; - Após agrupar os dados, use a função de grupo
-
Função agregada agrupada
número da linha() sobre a partição por
Agrupamento e agregação: É agrupar primeiro e depois ordenar. Se possível, marque a classificação; se não quiser agrupar, também pode classificar; se não quiser agrupar, também pode reclassificar.
--按salary排序,rank给排个名
SELECT *, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee
·8. Administrador de ataque de injeção SQL' ou 'x'='x
- A ordem das operações não é, e, ou
状况:select * from users where name='admin' or 'x'='x' and password = 'xxxxxxx';
--上面情况会被攻击,以下解决
解决:select * from users where name='admin' or ('x'='x' and password = 'xxxxxxx');
·九、GROUP BY、ordenar por
Para agrupamento, também deve ser adicionado o campo de consulta ao qual o campo está agrupado;
Classificação, classificação + campo + método de classificação, ordem crescente ascendente, ordem decrescente decrescente
select t.nf ,sum(score) score
from user t
WHERE t.name='语文'
and t.NF is not null GROUP BY t.NF
order by t.nf asc
·10. Índice
índice de chave primária
primary key
Não pode ser um índice vazio
not null unique
Índice padrão
default '默认的值';/*!注意要用单引号*/
Crie um índice de duas maneiras
- 1. Criação automática: a Oracle criará automaticamente índices para chaves primárias e chaves exclusivas.
Os índices criados automaticamente não podem ser excluídos manualmente, mas ao excluir restrições de chave primária e restrições exclusivas, os índices correspondentes serão excluídos automaticamente.
--添加名字为ename_uni的唯一索引
alter table emp
add constraints ename_uni unique (ename);
--删除名字为ename_uni的索引
alter table emp
drop constraints ename_uni;
- 2. Você pode criar restrições manualmente, quais campos da tabela devem ser indexados,
----- Ao consultar, os campos que são frequentemente usados como acréscimos de consulta devem ser indexados
Criar índice
-- 给表emp的字段ename创建名为ename_index的索引
create index ename_index on emp(ename);
Excluir índice
--删除名为indexName的索引
drop index indexName;
Ver índice
select index_name, table_name, column_name from user_ind_columns where table_name='tableName' ;
Para consultar se o índice é eficaz: adicione explicação antes dele
explain select s.* from stu s where name = '小强';
·11. Ver
Ver introdução
- Uma visualização é uma tabela virtual
- As visualizações são construídas em tabelas existentes.Essas tabelas nas quais as visualizações são construídas são chamadas de tabelas base.
- As visualizações podem ser entendidas como instruções de seleção armazenadas
- As visualizações são outra maneira de fornecer dados da tabela base ao usuário
Criar visualização
create view Hr_view as select empno,ename,job,mgr,deptno from emp;
--创建物化视图
create materialized view Hr_view
refresh force on demand
as select empno,ename,job,mgr,deptno from emp
--可以加只读
with read only;
visualizar redefinição
--创建视图,如果没视图则创建,如果有则重置
create or replace view Hr_view as select empno,ename,job,mgr,deptno from emp;
--起别名
create or replace view Hr_view (员工编号,员工姓名,薪水,佣金) as select empno,ename,sal,comn from emp;
Excluir visualização
--删除视图,不会影响原来的数据
drop view users;
inserir visualização
Uma visão é uma tabela (virtual), podemos inserir dados na tabela ou na visão.
--将工资大于2000的做一个视图表
create or replace view Emp_num as select * from emp where sal>2000;
--对视图插入数据,数据会被插入到源表中
insert into Emp_num values (8000,'刘','软件工程师',005);
--创建只读的视图,不能执行DML操作
create or replace view Emp_num as select * from emp where sal>2000 with read only;
visualização embutida
É a subconsulta que aparece depois de, que é uma view, mas a view não tem nome e não será salva no banco de dados.
--查询工资最大的三个员工;rownum是适用于<=的情况,是按照插入的顺序给记录排号
select rownum,E.* from (select * from emp order by sal desc) E where rownum <=3
--如何才可以拿到第二个数据
select * from (select rownum no, id,name,sal,job from emp) where no=2
--可以使用rowid来获取数据的修改权限
select rowid ,e.* from emp e;
Obtenha dados da tabela e faça view sql
--查询user_after表中将nd转换为字符作为nd,bhnum截取六位作为bhnum,计算(当dlh为‘NC’的时候为DHJ,否则为0,作为NC),
--依次;并对nd,bhnum,dwmc分组;nd,xzqdm排序
select
distinct to_char(nd) nd,
to_char(substr(bhnum,0,6)) as bhnum,
dwmc as xzqmc,
sum(case when dlh ='NC' THEN DHJ else 0 END ) AS NC,
sum(case when dlh ='NM' THEN DHJ else 0 END ) AS NM,
sum(case when dlh ='N+' THEN DHJ else 0 END ) AS NZJ,
sum(case when dlh ='N-' THEN DHJ else 0 END ) AS NJS
from user_after
group by to_char(nd),
to_char(substr(bhnum,0,6)),
dwmc
order by nd,xzqdm;
·12. Consulta multi-tabela
· Consulta não equivalente
Não há relacionamento pai-filho entre as duas tabelas. Use != para vincular as duas tabelas.
--查询两张表,emp表的id,名字,工资,saldengji表的等级,低值,高值;emp表某人的工资在saldengji表中的工资等级和范围
select e.empId,e.ename,e.esal,s.grade,s.losal,s.hisal
from emp e,saldengji s where e.esal between s.losal and s.hisal;
· Autoconsulta (autoadesão)
Através de aliases, uma tabela é virtualizada em duas tabelas e, em seguida, consultas equivalentes são realizadas nas duas tabelas.
select e.empId,e.name,m.bumenId,m.ename
from emp e,emp m where e.empId = m.bumenId
· Junção externa
Com base na consulta equivalente, podem ser consultados dados que não atendam às condições equivalentes;
**左外连接**:可以把右边不满足等值条件的数据查询出来 left join
**右外连接**:可以把左边表不满足等值条件的数据查出来 right join
Sintaxe SQL92 para implementar junções externas, use + - MySQL não suporta sintaxe SQL92 para junções externas
- junção externa esquerda
//第一种方式
select t.tbbh,w.xmwz
from tdgy t,wpxg w
where t.objectid = w.objectid(+);
//第二种方式
select t.tbbh,w.xmwz
from tdgy t
left join wpxg w on t.objectid = w.objectid
- junção externa direita
//第一种方式
select t.tbbh,w.xmwz
from tdgy t,wpxg w
where t.objectid(+) = w.objectid;
//第二种方式
select t.tbbh,w.xmwz
from tdgy t
right join wpxg w on t.objectid = w.objectid
conexão externa completa
select t.tbbh,w.xmwz
from tdgy t
full outer join wpxg w on t.objectid = w.objectid
· Conexão cruzada
Novo padrão: É equivalente à antiga consulta de equivalência padrão sem fornecer as condições de equivalência pelas quais se esforçar, o que produzirá um efeito cartesiano.
select e.*,d.* from emp e cross join dept d;
· junção natural junção natural
-
No relacionamento de tabela pai-filho, combine automaticamente campos com exatamente os mesmos nomes de coluna nas duas tabelas (chamadas colunas de referência) e execute consultas equivalentes nesses campos com os mesmos nomes.
-
Os prefixos não podem ser usados em colunas de referência
-
Desvantagens da junção natural: 1. Todas as colunas de referência serão consideradas condições equivalentes; 2. Se os tipos de colunas de referência forem diferentes, a consulta reportará um erro;
-
Quando não houver colunas de referência nas duas tabelas, a consulta natural produzirá um produto cartesiano
select u.name,u.age,r.addre from user1 u natural join user2 r;
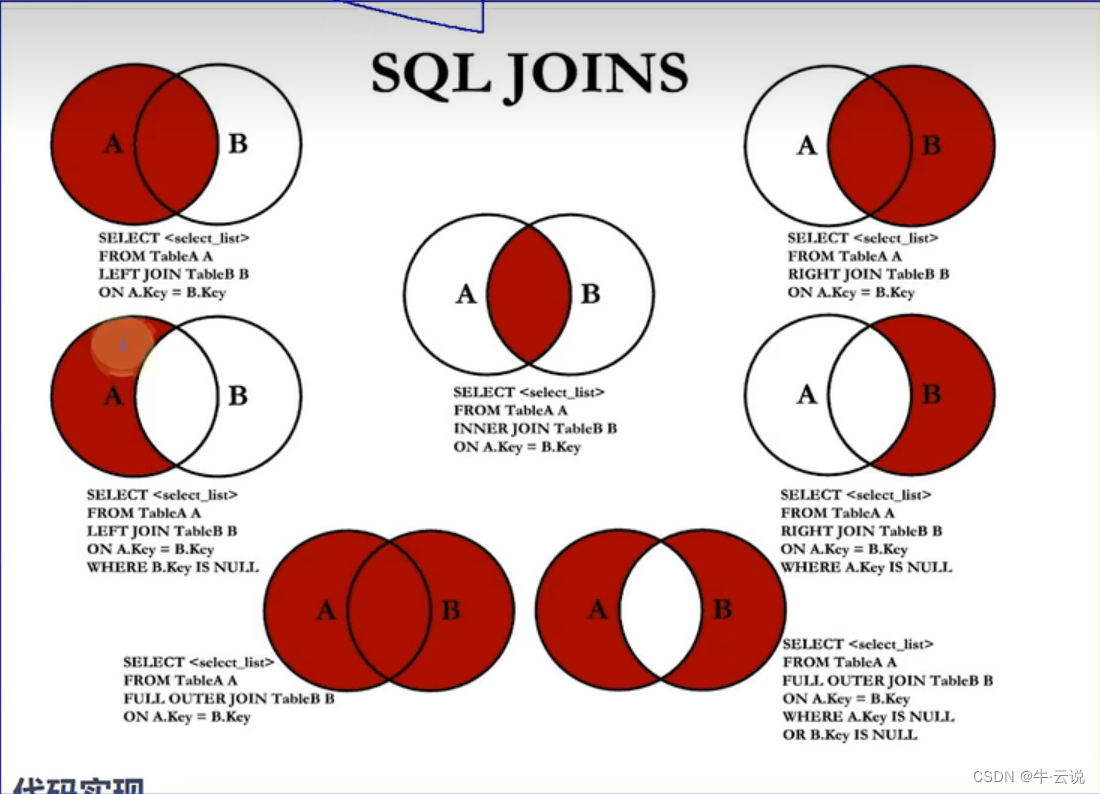
· junte-se…usando
对自然连接的改造
在自然连接的基础上,加以连接,使用指定的参照列来作为等值条件;
--using(指定的参照列)
select u.name,u.id,addre,r.name from user u natural join user1 r using(addre) where u.id=5;
· Mesclar consulta de tabela
União: união e união todos
**union,去除重复**
eg:
select adName,id,age,sorce,addre from aSchool
union
select adName,id,age,sorce,addre from bSchool;
若两张表有重复会去除一个
**union all,不去重复(推荐)**
eg:
select adName,id,age,sorce,addre from aSchool
union all
select adName,id,age,sorce,addre from bSchool;
若两张表有重复不会去除
字段名字必须一致

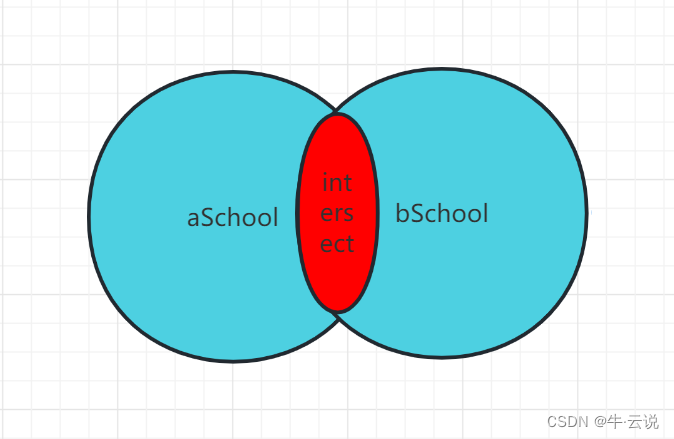
intersecção:intersecção
--取出两张表共同的内容
select adName,id,age,sorce,addre from aSchool
intersect
select adName,id,age,sorce,addre from bSchool;
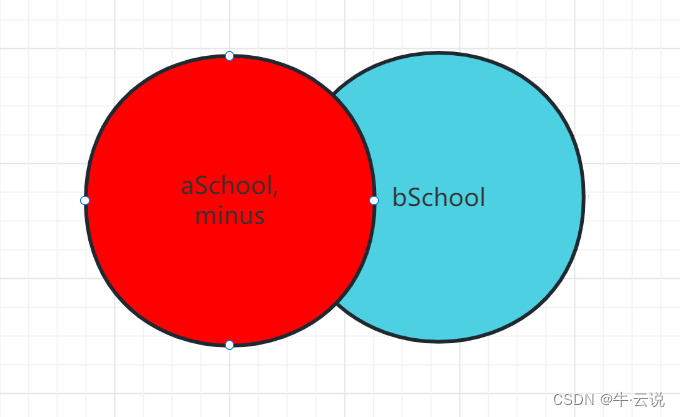
Conjunto de diferenças: menos
--取出aSchool的内容以及和bSchool中相同的内容,反之
select adName,id,age,sorce,addre from aSchool
minus
select adName,id,age,sorce,addre from bSchool;
· Subconsulta
-
A subconsulta não tem resultados e a consulta principal não reportará um erro, apenas não tem resultados de consulta.
-
Subconsulta de coluna única com várias linhas, use operadores de comparação de várias linhas, IN, ANY, ALL
1》Use o operador IN
--查询表中工资大于3000的数据 select job, fromm, emp, where sal>3000; --使用 in;查询emp表工资大于3000工资的数据(当查询另一张表中的员工工资,存在和本张表工资大于3000的工资一样的员工的数据时比较方便) select e.empId,e.ename,e.job,e.sal from emp e where e.job in (select job fromm emp where sal>3000);2》Use o operador ALL
--查询表中大于id为5的部门的工资数据,如果是<号:则小于满足子查询条件的所有数据的最小值,如果是>号:则大于满足子查询条件的所有数据的最大值 select e.* from emp e where e.sal > ALL(select sal from emp where empId=5);3》Use QUALQUER operador
--查询工资数据大于某个部门编号为20的工资;如果是<号,则小于满足子查询条件的所有数据的最大值;如果是>号,则大于满足子查询条件的所有数据的最小值 select e.* from emp e where e.sal < any(select sal from emp where empid=20);4》 Subconsulta de múltiplas linhas e múltiplas colunas
Você pode usar o operador de comparação
--查询部门编号为5和8的addre,job的数据
select ename,job from emp where empid = 5 or ompid = 8;
--成对的比较
--注:查询表中的数据addre,job和部门编号为5和8的addre,job一样的数据,不包括自己
select empid,ename,addre,job from emp
where (addre,job) in (select ename,job from emp where empid = 5 or ompid = 8) and empid != 5 and empid != 8;
--非成对的比较,把多行多列的子查询拆分成两个多行单列的子查询,分别使用in运算符
select empid,ename,addre,job from emp
where addre in (select addre from emp where empid = 5 or ompid = 8)
and job in(select job from emp where empid = 5 or ompid = 8)
and empid != 5 and empid != 8;
bloquear tabela, desbloquear
Bloqueie o relógio!
select * from user for update;
--锁表(其它事务不能读、更新、删除)
BEGIN TRAN
SELECT * FROM <表名> WITH(TABLOCKX);
WAITFOR delay '00:00:20'
COMMIT TRAN
--锁表(其它事务只能读,不能更新、删除)
BEGIN TRAN
SELECT * FROM <表名> WITH(HOLDLOCK);
WAITFOR delay '00:00:20'
COMMIT TRAN
--锁部分行
BEGIN TRAN
SELECT * FROM <表名> WITH(XLOCK) WHERE ID IN ('81A2EDF9-D1FD-4037-A17B-1369FD3B169B');
WAITFOR delay '00:01:20'
COMMIT TRAN
--查看被锁表
select request_session_id 锁表进程,OBJECT_NAME(resource_associated_entity_id) 被锁表名
from sys.dm_tran_locks where resource_type='OBJECT';
--解锁
declare @spid int
Set @spid = 55 --锁表进程
declare @sql varchar(1000)
set @sql='kill '+cast(@spid as varchar)
exec(@sql)
· 13. Restrições
· Restrição única única
Certifique-se de que os dados neste campo não possam ser repetidos ou a combinação de campos não possa ser repetida, mas pode ser nula
--创建表的时候使用
firstName varchar2(10),
LastName varchar2(10),
//取一个名字叫name_uni的唯一约束
constraints name_uni unique (firstName,LastName)
·Restrições de chave primária chave primária
Não nulo e único. Só pode haver uma restrição de chave primária em uma tabela (apenas uma pode ser escrita); mas pode ser aplicada a vários campos ao mesmo tempo, também chamada de chave primária conjunta.
--创建表
sid number(4),
sname varchar2(20),
constraints T_STU primary key (sid)--给sid加主键约束
- Adicionar restrições de chave primária
alter table myUser add constraint myUser_key primary key (userId); --alter table 表 add constraint 主键名 主键类型(主键字段)
#### ·外键约束
外键约束可以重复,可以为null;
- 添加外键约束
```sql
alter table cTable add foreign key(cUserId) references zTable(userId)
--alter table 从表 add foreign key(外键字段) references 主表(主键字段)
- Excluir restrições de chave estrangeira
alter table myUser drop foreign key cUserId
--alter table 表名 drop foreign key 外键名
seqüência
- Dados de chave primária usados para manter o banco de dados
- Forneça valores exclusivos automaticamente
- Objetos compartilhados
- Carregar valores de sequência na memória pode melhorar a eficiência do acesso
Criar sequência
--创建序列,名字为seq_stu
create sequence seq_stu
INCREMENT BY: --指定序列号之间的间隔,该值可为正的或负的整数,但不可为0。序列为升序。忽略该子句时,缺省值为1。
START WITH:--指定生成的第一个序列号。在升序时,序列可从比最小值大的值开始,缺省值为序列的最小值。对于降序,序列可由比最大值小的值开始,缺省值为序列的最大值。
MAXVALUE:--指定序列可生成的最大值。
NOMAXVALUE:--为升序指定最大值为1027,为降序指定最大值为-1。
MINVALUE:--指定序列的最小值。
NOMINVALUE:--为升序指定最小值为1。为降序指定最小值为-1026。
cycle --需要循环
nocache --不需要缓存登录
-- 创建序列 Student_stuId_Seq --
create sequence Student_stuId_Seq
increment by 1
start with 1
minvalue 1
maxvalue 999999999;
Modificar sequência
-- 更改序列 Student_stuId_Seq--
alter sequence Student_stuId_Seq
increment by 2
minvalue 1
maxvalue 999999999;
Consultar usando sequência
--查询序列下一个值
select Student_stuId_Seq.Nextval 自增序列ID from dual;
--查询序列当前值
select Student_stuId_Seq.currval from dual;
Adicione uma nova sequência de uso
--给表student新增数据,seq_stu.nextval可以自动添加id值
insert into Student(stuId,Stuname) values(Student_stuId_Seq.Nextval,'张三');
insert into Student(stuId,Stuname) values(Student_stuId_Seq.Nextval,'李四');
excluir sequência
drop sequence Student_stuId_Seq;
outro
sql determina se a tabela existe
1. A primeira maneira
select count(*) as count from user_tables where table_name =upper('tableName');
Resultados da consulta
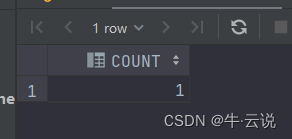
2. A segunda maneira
SELECT COUNT(*) as count FROM ALL_TABLES WHERE OWNER = UPPER('用户名') AND TABLE_NAME = UPPER('表名')
resultado da pesquisa
Crie espaço de tabela (esquema) em plsql
-- 创建表空间
create tablespace TS_RAW_XZ
logging
datafile 'D:\oradata\6400NXdata\TS_RAW_XZ.dbf' --保存的文件
size 16384m --大小
autoextend on
next 32m maxsize unlimited
extent management local;
-- Create the user
--创建用户
create user US_RAW_XZ
identified by "US_RAW_XZ"
default tablespace TS_RAW_XZ
temporary tablespace TEMP
profile DEFAULT
quota unlimited on TS_RAW_XZ;
-- Grant/Revoke role privileges
grant connect to US_RAW_XZ with admin option;
grant dba to US_RAW_XZ with admin option;
grant resource to US_RAW_XZ with admin option;
-- Grant/Revoke system privileges
grant unlimited tablespace to US_RAW_XZ with admin option;
Espero que ajude você