Em 17 de janeiro, a coletiva de imprensa do Scholar Puyuan 2.0 (InternLM2) e a cerimônia de lançamento do Scholar Puyuan Large Model Challenge foram realizadas em Xangai. O Laboratório de Inteligência Artificial de Xangai e o SenseTime, juntamente com a Universidade Chinesa de Hong Kong e a Universidade Fudan, lançaram oficialmente a nova geração do grande modelo de linguagem acadêmica Puyu 2.0 (InternLM2) .

Endereço de código aberto
- Github: https://github.com/InternLM/InternLM
- HuggingFace: https://huggingface.co/internlm
- ModelScope: https://modelscope.cn/organization/Shanghai_AI_Laboratory
Segundo relatos, o InternLM2 foi treinado em um corpus de alta qualidade de 2,6 trilhões de tokens. Seguindo as configurações do estudioso de primeira geração Puyu (InternLM), o InternLM2 inclui duas especificações de parâmetros de 7B e 20B, bem como versões base e de diálogo para atender às necessidades de diferentes cenários de aplicação complexos. Aderindo ao conceito de "capacitar a inovação com código aberto de alta qualidade", o Shanghai AI Laboratory continua a fornecer licença comercial gratuita para o InternLM2.
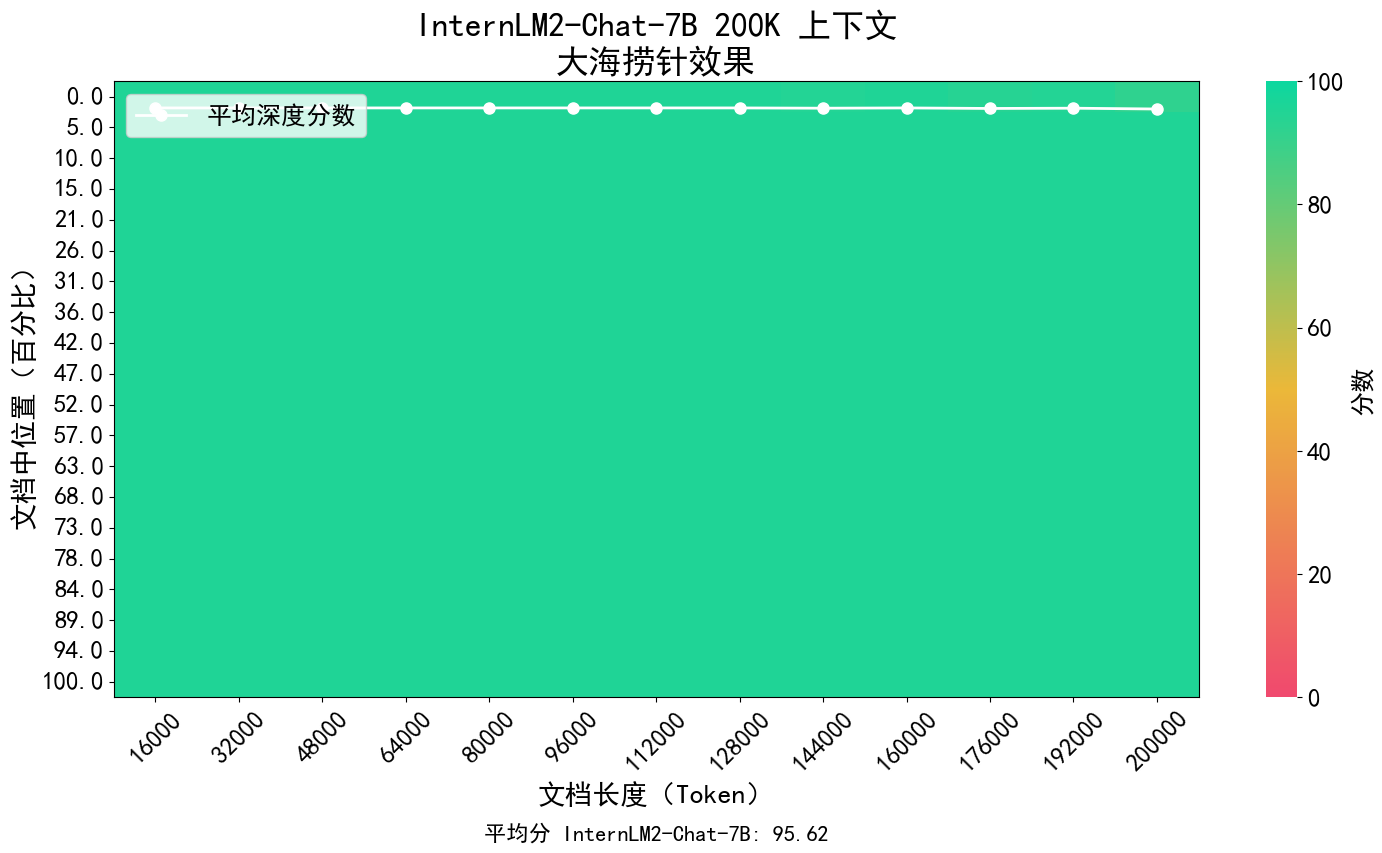
O conceito central do InternLM2 é retornar à essência da modelagem de linguagem e está comprometido em alcançar uma melhoria qualitativa nas capacidades de modelagem de linguagem da base do modelo, melhorando a qualidade do corpus e a densidade da informação e, em seguida, fazendo grandes avanços em matemática, codificação, diálogo, criação, etc. Progressos foram feitos e o desempenho abrangente atingiu o nível de liderança de modelos de código aberto da mesma magnitude. Ele suporta o contexto de 200 mil tokens, recebe e processa conteúdo de entrada de cerca de 300.000 caracteres chineses de uma só vez, extrai informações importantes com precisão e consegue "encontrar a agulha no palheiro" de textos longos.
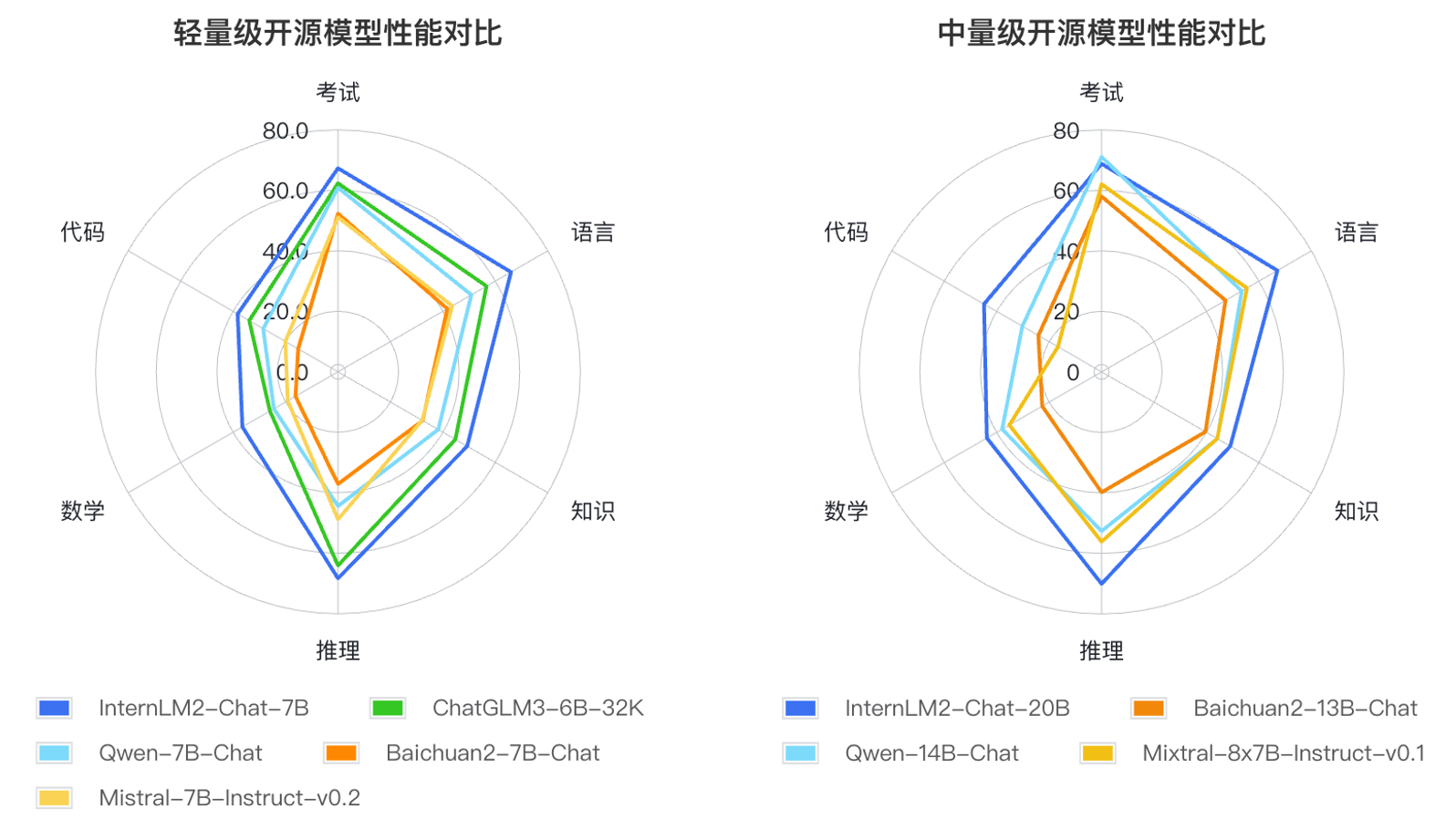
Além disso, o InternLM2 fez progressos abrangentes em várias capacidades.Em comparação com o InternLM de primeira geração, as suas capacidades de raciocínio, matemática, codificação, etc., foram significativamente melhoradas e as suas capacidades abrangentes estão à frente do mesmo nível de modelos de código aberto.
Com base nos métodos de aplicação de grandes modelos de linguagem e nas principais áreas de preocupação do usuário, os pesquisadores definiram seis dimensões de competência, como linguagem, conhecimento, raciocínio, matemática, código e exame, e testaram o desempenho de vários modelos da mesma magnitude em 55 conjuntos de avaliação mainstream. O desempenho foi avaliado de forma abrangente. Os resultados da avaliação mostram que as versões leve (7B) e média (20B) do InternLM2 apresentam bom desempenho entre modelos do mesmo tamanho.