1. Resumo
O reconhecimento refinado de imagens de pássaros é dedicado a obter uma classificação precisa de imagens de pássaros e é um trabalho básico no rastreamento visual de robôs. Dada a importância da monitorização e conservação das aves ameaçadas na protecção das aves ameaçadas, são necessários métodos automatizados para facilitar a monitorização das aves. Neste trabalho, propomos um novo método de monitoramento de aves baseado no rastreamento visual de robôs, que adota um modelo com reconhecimento de afinidade chamado TBNet, que combina as arquiteturas CNN e Transformer com o módulo Novel feature selection (FS). Especificamente, a CNN é usada para extrair informações de superfície. Use Transformers para desenvolver afinidades semânticas abstratas. O módulo FS é introduzido para revelar recursos de identificação .
Experimentos abrangentes mostram que o algoritmo pode atingir desempenho de última geração tanto no conjunto de dados cub-200-201 (91,0%) quanto no conjunto de dados nabbirds (90,9%).
2. Pergunta
O reconhecimento refinado de imagens de pássaros é uma tarefa básica para rastreamento visual de robôs e processamento de imagens [1-3]. O rastreamento autônomo de aves por robôs, sem interferência humana, é crucial para a conservação de aves ameaçadas. Atualmente, algumas aves ameaçadas de extinção estão à beira da extinção devido à ameaça de degradação ambiental. Portanto, o monitoramento e a proteção de aves ameaçadas são de grande importância para a conservação das aves. Dado que quase metade das populações de aves do mundo estão em declínio, e 13% delas estão "numa situação muito grave" [4], a protecção das aves ameaçadas tem atraído cada vez mais atenção. A fim de reforçar a protecção das aves, a monitorização da população de aves tornou-se um centro de investigação. No entanto, esta tem sido uma tarefa desafiadora devido às condições extremas de campo, como altas temperaturas nos trópicos e alta umidade nas florestas tropicais. Tradicionalmente, os investigadores de aves observam e registam manualmente informações sobre aves ameaçadas nos seus habitats, o que é uma tarefa demorada e trabalhosa. Nos últimos anos, com o desenvolvimento da inteligência artificial, muitos métodos de aprendizagem profunda foram propostos para classificação refinada de imagens de aves (FBIC). Portanto, as tarefas posteriores, como o monitoramento de aves, falham.
Através da observação cuidadosa da aparência das aves, descobrimos a afinidade entre várias partes das aves, o que é útil para a pesquisa do FBIC. Conforme mostrado na Figura 1, a combinação da cabeça e do bico de um pássaro ou o padrão de cores na cabeça, asas e cauda de um pássaro. Essas relações de afinidade podem ser usadas como características discriminantes do FBIC.

2.1 Descoberta
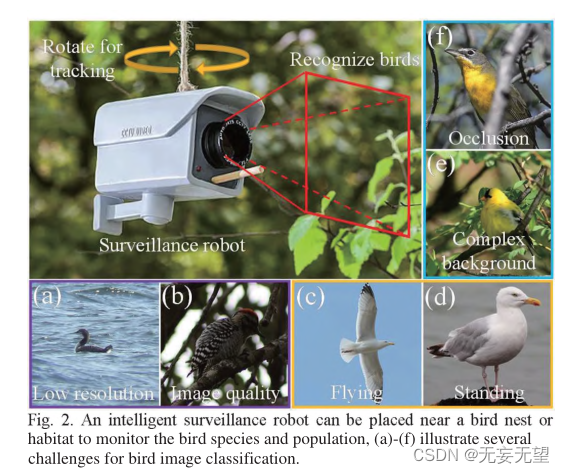
Contudo, a identificação de aves na natureza também enfrenta alguns desafios. Primeiro, a qualidade da imagem irá variar devido ao ambiente extremamente selvagem. Por exemplo, imagens tiradas à distância podem resultar em baixa resolução (Figura 2(a)) ou imagens tiradas sob baixa iluminação (Figura 2(a)). 2(b)), em segundo lugar, existem poses arbitrárias de pássaros. Por exemplo, como pode ser visto na Figura 2 (e) e na Figura 2 (d), a primeira imagem mostra uma gaivota voadora, enquanto a segunda imagem mostra uma gaivota em pé. Em cada imagem, os pássaros parecem ter uma aparência diferente, outra fonte de dificuldade para o FBIC. Terceiro, devido à ocultação e complexidade dos cenários selvagens, as aves podem estar entre galhos e folhas (Figura 2 (e)), ou podem ser observadas por galhos (Figura 2 (f)), o que faz com que a classificação das imagens de aves traga dificuldades .
2.2 Desenvolvimento
Uma vez que é de grande importância identificar as afinidades semânticas dependentes de longo prazo entre imagens de pássaros, o Transformer é uma linguagem que é inerentemente boa para explorar detalhes microscópicos de granulação fina e relações semânticas microscópicas dependentes de longo prazo em imagens. Transformer[5] foi originalmente usado para processamento de linguagem natural. Depois foi inspirado no campo da visão computacional. Carion et al. [6] propuseram um método de detecção de alvo ponta a ponta baseado no Transformer. Em [7], Dosovitskiy et al. propuseram o Vision Transformer (ViT), que foi aplicado pela primeira vez e provou que o Transformer puro é um método que pode competir com a CNN e a estrutura que ocupa o seu lugar. Portanto, a estrutura ViT é usada como espinha dorsal do nosso modelo para explorar as afinidades das tarefas FBIC.
2.3 Inovação
Neste trabalho, propomos um método que pode ser usado para robôs inteligentes de monitoramento de aves (Fig. 2), que podem ser instalados próximos a comedouros, ninhos de pássaros ou habitats de pássaros. O robô pode girar vertical e horizontalmente para fornecer um campo de visão mais amplo para detectar pássaros. O robô grava imagens em intervalos regulares, aumentando a frequência quando um pássaro é detectado na imagem. Um grande robô é equipado com uma bateria de grande capacidade que permite o monitoramento de longo prazo.Nosso chip de programa modelo TBNet também está instalado dentro do robô, que pode classificar as aves em tempo real.
Durante o período de monitoramento, a frequência de ocorrência das aves do estudo será calculada e registrada. As informações coletadas podem então ser usadas por pesquisadores de aves para estimar e conservar as populações de aves. O modelo TBNet classifica imagens de aves identificando relações de afinidade em imagens de aves, facilitando assim a estimativa da população de aves a jusante. Em resumo, as principais contribuições deste trabalho são as seguintes:
1) É proposto um novo método de rastreamento visual de robôs para proteção de aves. O robô de monitoramento inteligente pode girar em diferentes direções e registrar o número de pássaros.
2) Foi estabelecido um modelo TBNet eficaz. Até onde sabemos, esta afinidade foi revelada pela primeira vez em imagens de aves. Portanto, o ViT é usado para explorar essas afinidades semânticas abstratas. CNN é usado para extrair informações de superfície e o módulo FS é introduzido para revelar características discriminativas. Para geração de mapas de características do modelo TBNet, é proposta uma estratégia de extração de características (estratégia CPG).
3) Realizar experimentos em dois conjuntos de dados de aves, CUB-200-2011 e NABirds. O TBNet proposto alcança melhor desempenho em comparação com vários métodos de última geração existentes, validando assim a sua eficácia.
3.Rede
3.1 Estrutura geral
O pipeline do modelo TBNet é mostrado na Figura 3. O método inclui três partes: backbone de extração de recursos, módulo FS e cabeçalho de classificação . A primeira parte é o backbone de extração de recursos, que é usado para extrair informações refinadas e em várias escalas de imagens de pássaros. De modo geral, vários backbones atuais [1-3,7] podem ser considerados candidatos. Como a CNN tem uma forte capacidade de extrair informações de superfície e o Transformer é excelente na mineração de relacionamentos de afinidade semântica abstrata, este estudo usa a combinação de CNN e ViT como espinha dorsal . O backbone foi modificado posteriormente para melhorar o desempenho. Para mitigar o overfitting, a rede desenvolvida possui uma camada de dropout na cabeça de classificação do backbone. A segunda parte é o módulo FS, que extrai as características discriminativas de aves específicas. A terceira parte é o cabeçalho de classificação, no qual o mapa de características é finalmente utilizado para a classificação final.
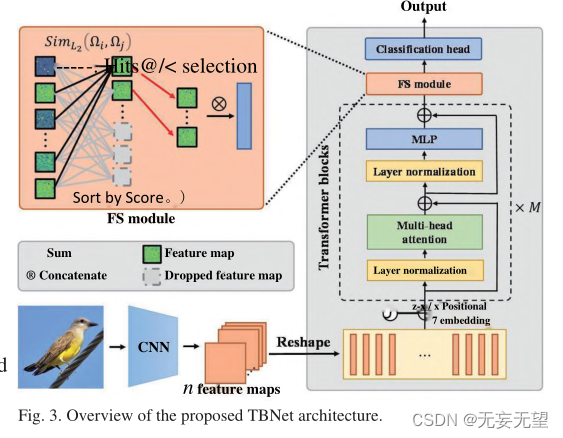
1. Use a rede CNN para extrair características preliminares da imagem e, em seguida, compacte-a em um patch e insira-a na rede vit, que pode reter mais informações globais da imagem, mas ao mesmo tempo algumas informações de baixo nível informações detalhadas são ignoradas devido à convolução camada por camada.
2. O módulo FS equivale ao aprimoramento de imagem, pois aumenta o peso de áreas significativas removendo áreas com pequenas contribuições no bloco transformador.
3.2 Geração de mapa de recursos
As imagens das aves são processadas através do backbone de extração de características e mapas de características são gerados. Este processo pode ser resumido em três etapas: processamento de CNN, incorporação de posição e passagem do bloco Transformer (estratégia CPG). Após a conclusão do processo, a imagem de entrada original é convertida em um mapa de características para classificação.
Etapa I: Processamento da CNN. Nesta etapa, a imagem de entrada original é inicialmente processada através da CNN para gerar n mapas de características. Então, cada mapa de características t é planarizado em um vetor unidimensional. A seguir, aplique a projeção linear para projetar pt em p[. Este processo é expresso da seguinte forma:

Na fórmula, pt é o i-ésimo patch, E é a projeção linear e i é o vetor visual projetado ddimensional.
Etapa II: Incorporação de posição. Como a camada Transformer é invariante ao arranjo da sequência de patches de entrada, são necessários embeddings de posição para codificar as posições espaciais e os relacionamentos dos patches. Especificamente, esses patches são adicionados por meio de incorporação posicional em vetores de patch. A fórmula de incorporação é a seguinte:

Na fórmula, representa uma matriz composta por vetores de patches, n representa o número de patches e
representa a incorporação de posição. O tipo de incorporação de posição pode ser escolhido entre várias opções, nomeadamente incorporação 2D sinusoidal, aprendível e de posição relativa.
Etapa III: Passe pelo bloco Transformer. O patch de incorporação posicional é então passado pelos blocos M Transformer. Cada bloco Transformer é calculado da seguinte forma:

onde l e
são os vetores de patch de saída do módulo MSA e do módulo MLP do bloco transformador 1, respectivamente. LN(-) indica normalização da camada. MLP representa múltiplas camadas totalmente conectadas. MSA significa que os touros se observam. Esses blocos transformadores podem ser divididos em N níveis.
3.3 Módulo FS
O patch original pode introduzir recursos prejudiciais que prejudicam a classificação. A Figura 4 mostra a lista de mapeamentos de atributos no bloco Transformer. A etapa final classifica os mapas de recursos com base em suas pontuações de discriminação. Conforme mostrado na Figura 4, em níveis inferiores, como estágio 1 e estágio 2, os recursos do Hits@k quase não têm semelhança entre si, enquanto os recursos com pontuações piores são quase idênticos entre si. Em camadas superiores, como o estágio N, os recursos Hits@k são mais semelhantes e altamente ativados, enquanto os recursos com pontuações piores parecem ser ruidosos. Em geral, em cada fase, as características salientes das pontuações altas são mais importantes do que as características salientes das pontuações baixas . Portanto, propomos o módulo FS para utilizar ainda mais as informações fornecidas por esses recursos exclusivos e mitigar efetivamente os efeitos prejudiciais dos recursos destrutivos.
Suponha que no estágio i a saída sejam n vetores de patch de ID, denotados como Qj, ou seja, [1,2,3,…,]. Primeiro, o módulo FS calcula a similaridade entre n vetores. Selecione similaridade entre similaridade de cosseno ou o inverso da distância L2. A similaridade do cosseno é definida como segue
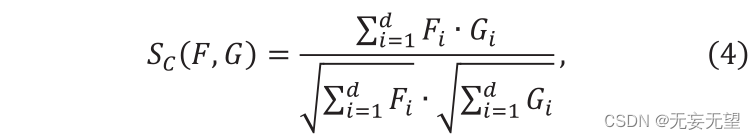
Onde F ” e G ” são dois vetores, Sc (F,G) ∈[0,1]. O valor de Sc representa a semelhança entre F e g, e sua distância L2 é construída da seguinte forma:
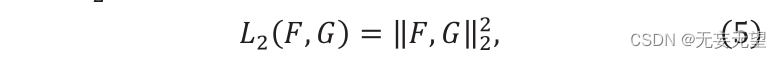
Onde "F" e "G" representam dois vetores de recursos. A fórmula de cálculo de similaridade é a seguinte:
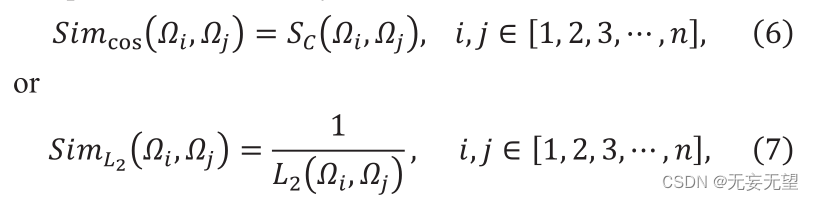
Entre eles, e
representam os i-ésimo e j-ésimo vetores de patch, respectivamente. Sc representa similaridade de cosseno,
que representa
distância. Calculando a similaridade, a matriz de similaridade pode ser obtida. A matriz de similaridade contendo as semelhanças entre todos os patches pode ser expressa como:

Em segundo lugar, cada vetor patch obtém uma pontuação discriminante adicionando sua similaridade a outros vetores patch e realizando uma operação de ida e volta. A fórmula operacional é a seguinte:
 Finalmente, o vetor de patch Hits@k (k) com a pontuação mais alta é selecionado e inserido na próxima camada. Os vetores de patch restantes são descartados porque são menos discriminativos.
Finalmente, o vetor de patch Hits@k (k) com a pontuação mais alta é selecionado e inserido na próxima camada. Os vetores de patch restantes são descartados porque são menos discriminativos.

4. Experimente
4.1 Configuração experimental
4.1.1 Conjunto de dados
CUB-200-2011,NABirds
4.1.2 Detalhes experimentais
O modelo proposto é implementado da seguinte maneira. Primeiro, redimensione a resolução da imagem de entrada para 448 a 448 para uma comparação justa. Para melhorar a eficiência, o tamanho do lote é definido como 8. O otimizador AdamW é usado e a atenuação de peso é 0,05. A taxa de aprendizagem é inicializada em 0,0001. Todos os experimentos foram realizados em uma GPU Nvidia TITAN usando a caixa de ferramentas PyTorch.
4.2 Teste comparativo


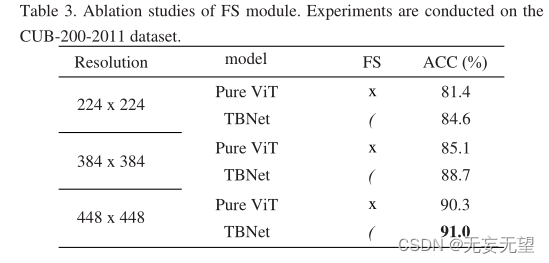
4.3 Experimento de ablação
4.4 Visualização

5. Conclusão
Neste trabalho, propomos um novo método de rastreamento visual para robôs de proteção de aves. O robô de monitoramento inteligente pode girar em diferentes direções e registrar o número de pássaros. Nesta base, é estabelecido um modelo TBNet eficaz. Até onde sabemos, afinidades em imagens de pássaros foram reveladas pela primeira vez. CNNs são usadas para extrair informações superficiais. Use ViT para explorar relacionamentos abstratos de afinidade semântica. O módulo FS é introduzido para revelar recursos de identificação. Para geração de mapas de características do modelo TBNet, é proposta uma estratégia de extração de características (estratégia CPG). Testamos o TBNet em dois conjuntos de dados FBIC. Resultados experimentais mostram que este método pode identificar relações de afinidade e características discriminativas em imagens de aves. Com os resultados promissores alcançados pela TBNet, é razoável acreditar que o rastreamento visual de aves por robôs tem um grande potencial.