
Equipe de origem|Plataforma de operação ao vivo da BytedanceNa construção contínua de serviços de agregação de dados entre domínios baseados em ES, descobrimos que muitos recursos do ES são bastante diferentes dos bancos de dados comumente usados, como o MySQL. Este artigo compartilhará os princípios de implementação do ES e sugestões de seleção de negócios em plataformas de transmissão ao vivo. e problemas encontrados na prática e no pensamento.
Introdução ao ES e cenários de aplicação
Elasticsearch é um mecanismo distribuído de armazenamento, recuperação e análise massiva de dados quase em tempo real. O que costumamos chamar de "ELK" refere-se a um sistema de dados composto por Elasticsearch, Logstash/Beats e Kibana que é capaz de coleta, armazenamento, recuperação e visualização. ES desempenha um papel no armazenamento e indexação de dados, recuperação de dados e análise de dados em sistemas de dados semelhantes.
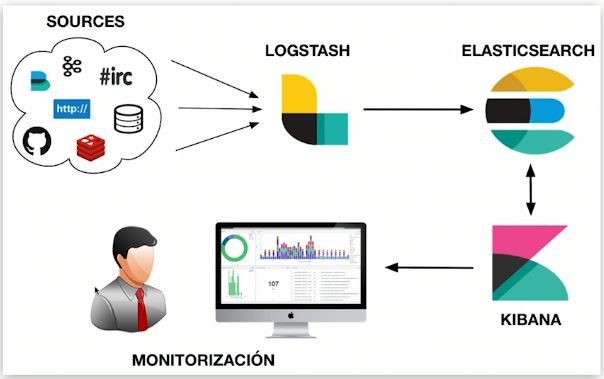
Recursos ES
Cada seleção de tecnologia tem suas próprias características, e as características gerais do ES também são afetadas pela implementação subjacente. A segunda parte deste artigo detalhará as causas básicas das seguintes características.
Prós:
-
Distribuído: por meio de fragmentação, ele pode suportar dados de nível PB e proteger detalhes de fragmentação externos. Os usuários não precisam estar cientes do roteamento de leitura e gravação;
-
Escalável: Fácil de expandir horizontalmente, sem necessidade de dividir manualmente bancos de dados e tabelas como MySQL ou usar componentes de terceiros;
-
Velocidade rápida: cálculo paralelo de cada fragmento, velocidade de recuperação rápida;
-
Recuperação de texto completo: múltiplas otimizações direcionadas, como suporte à recuperação de texto completo em vários idiomas por meio de vários plug-ins de segmentação de palavras e melhoria da precisão por meio de processamento semântico;
-
Funções ricas de análise de dados.
Contras:
-
As transações não são suportadas: o processo de cálculo de cada fragmento é paralelo e independente;
-
Quase em tempo real: há um atraso de vários segundos desde o momento em que os dados são gravados até o momento em que os dados podem ser consultados;
-
A linguagem DSL nativa é relativamente complexa e tem um certo custo de aprendizagem.
Usos comuns
Os recursos afetarão os cenários de aplicação dos componentes Na parte de recuperação e análise de documentos, a plataforma de operação de transmissão ao vivo usa ES para agregar diversas informações de centenas de milhões de âncoras e as utiliza para exibir várias listas na parte de recuperação de log; é usado para detectar erros de pesquisa de log.
Implementação e arquitetura ES
A seguir, entenda como as vantagens do ES mencionadas acima são percebidas e como as deficiências são causadas. Ao falar sobre ES, devemos falar sobre Lucene é uma biblioteca Java de pesquisa de texto completo que usa Lucene como componente subjacente para implementar tudo. funções O seguinte apresenta principalmente os recursos do Lucene. Quais funções e quais novos recursos o ES tem em comparação com o Lucene?
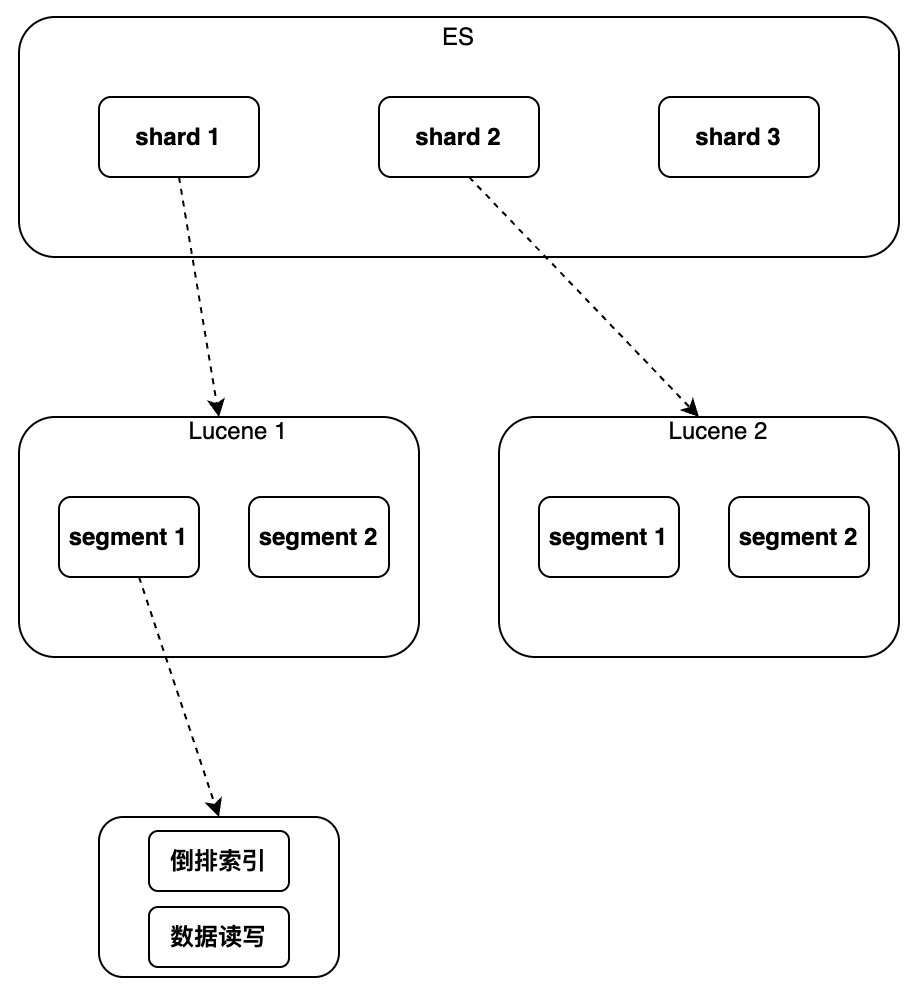
Lucene implementa indexação e recuperação de dados em uma única instância. Ele pode suportar índice invertido e gravação sequencial de dados, mas não suporta modificação e exclusão. Não há conceito de chave primária global. não pode suportar a distribuição operar.
Portanto, o ES adicionou alguns novos recursos em comparação com o Lucene
,
incluindo principalmente o novo campo de chave primária global "_id", que torna possível a modificação/exclusão de dados e o roteamento de fragmentos e o uso de um arquivo separado para marcar o documento excluído para "escrever novo The; A operação de atualização é implementada por "Documento, marcando o documento antigo como excluído" adicionando um novo número de versão ao documento, a simultaneidade é suportada na forma de bloqueio otimista, o processo de realização da distribuição é executado através da execução de várias instâncias do Lucene para rotear leitura e; escrever solicitações e mesclar de acordo com os resultados da consulta de ID da chave primária também foi adicionada, que pode implementar classificação, estatística, etc. Os detalhes específicos de implementação serão apresentados abaixo na ordem de instância única para cluster.
instância única
índice
O objetivo da indexação é acelerar o processo de recuperação. A seleção do índice é um problema inevitável para todos os bancos de dados. O cenário de destino inicial do design ES é a recuperação de texto completo, portanto, ele suporta "índice invertido" e fez muitas otimizações para isso. Além disso, ele também oferece suporte a outros índices, como Block Kd Tree ES, que corresponderá automaticamente ao tipo de índice correspondente de acordo com o tipo de campo e criará índices para os campos que precisam ser indexados.
Índice invertido e Block Kd Tree também são tipos de índice comumente usados para análise. Para strings, existem duas situações comuns: o texto usa segmentação de palavras + índice invertido, enquanto a palavra-chave usa segmentação sem palavras + índice invertido. Para tipos numéricos, como Long/Float, o Block Kd Tree geralmente é usado.
Índice invertido
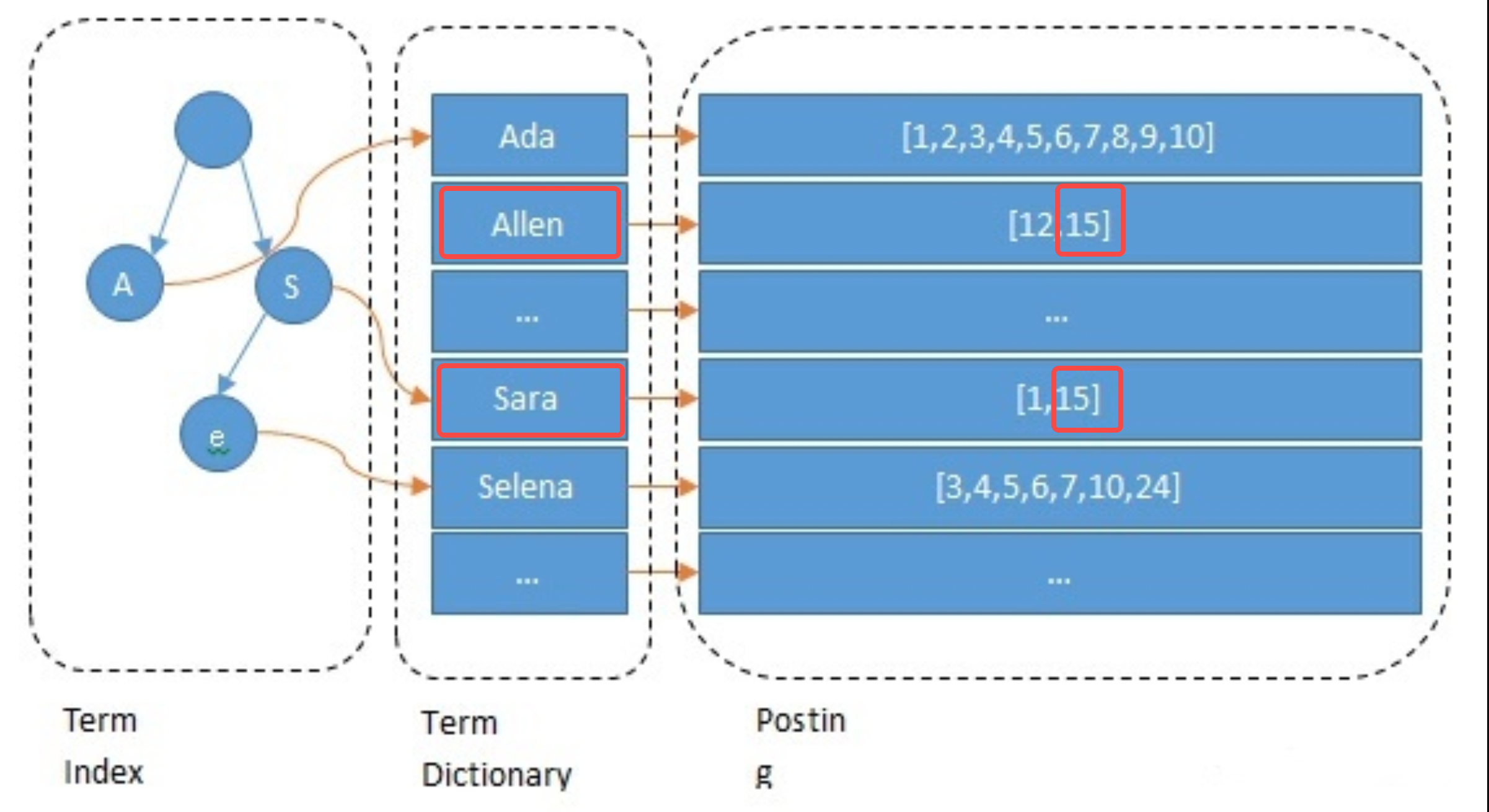
Ao construir o índice, o ES indexará cada campo por padrão. Este processo inclui segmentação de palavras, processamento semântico e construção de tabelas de mapeamento. Primeiramente, o texto será segmentado em palavras. O método de segmentação de palavras está relacionado ao idioma, como o corte por espaços em inglês. Em seguida, palavras sem sentido são excluídas e a normalização semântica é realizada. Finalmente construa a tabela de mapeamento. O exemplo a seguir mostra brevemente o processo de processamento do campo Name da âncora 15: ele é segmentado em allen e sara;
// 主播1 { "id": 1 "name":"ada sara" ... // 其他字段 } // 主播15 { "id": 15 "name":"allen sara" }
Processo de consulta
Tomemos como exemplo a consulta para a âncora chamada "Allen Sara" De acordo com os resultados da segmentação de palavras, duas listas [12, 15] e [1, 15] são encontradas respectivamente (em aplicações reais, a consulta também será baseada em. sinônimos); para mesclar as listas e pontuações, pressione A prioridade é obter os resultados [15, 12, 1] (esta é a etapa de recuperação na pesquisa e também será refinada de acordo com o algoritmo).
Itens de otimização
Para acelerar a recuperação e reduzir a pressão da memória/disco rígido, o ES realiza as seguintes otimizações no índice invertido, o que também é uma vantagem do ES sobre outros componentes. O que precisa ser observado aqui é que a utilização final do espaço de armazenamento pode ser uma característica comum de todos os bancos de dados. Redis também economiza espaço de memória da mesma maneira: os dados são armazenados no menor número possível de bits, e conjuntos pequenos e grandes são armazenados. armazenados de diferentes maneiras.
-
Índice de termos: Use árvores de prefixo para acelerar o posicionamento de palavras de "Termos" e resolver o problema de velocidade de recuperação lenta causada por muitas palavras;
-
Dicionário de termos: coloque palavras com o mesmo prefixo em um bloco de dados e retenha apenas o sufixo, como [hello, head] -> [lo, ad];
-
Postagem: codificação ordenada + incremental + armazenamento em bloco, como [9, 10, 15, 32, 37] -> [9, 1, 5, 17, 5], cada elemento pode usar armazenamento de 5 bits;
-
Otimização de mesclagem de postagem: use Roaring Bitmap para economizar espaço Ao usar consultas com várias condições, você precisa mesclar várias postagens;
-
Processamento semântico: Conteúdo com semântica semelhante pode ser consultado.
Recursos do índice invertido:
-
Suporte para pesquisa de texto completo: suporte a vários idiomas com diferentes plug-ins de segmentação de palavras, como o plug-in de segmentação de palavras IK para implementar pesquisa de texto completo em chinês;
-
Tamanho pequeno do índice: a árvore de prefixos comprime bastante o espaço e o índice pode ser colocado na memória para acelerar a recuperação;
-
Suporte deficiente para pesquisa de intervalo: limitado pela seleção de árvore de prefixo;
-
Cenários aplicáveis: pesquisa por palavra, pesquisa sem intervalo. Os campos não numéricos do ES usam esse tipo de índice.
Bloqueio de bloco
K d Índice de árvore
O índice Block Kd Tree é muito amigável para pesquisas de intervalo, como valores ES, geo e intervalo, todos usam esse tipo de índice. Na seleção de negócios, os campos numéricos que exigem pesquisa por intervalo devem usar tipos numéricos como Longo. Para índices invertidos, os campos que não exigem pesquisa de texto completo devem usar o tipo Palavra-chave.
Devido ao espaço limitado, este artigo não apresentará muito aqui. Amigos interessados no BKd Tree podem consultar o seguinte conteúdo:
-
https://www.shenyanchao.cn/blog/2018/12/04/lucene-bkd/
-
https://www.elastic.co/cn/blog/lucene-points-6-0
armazenamento de dados
Esta parte explica principalmente como os dados de uma única instância são armazenados na memória e no disco rígido.
Segmento de armazenamento segmentado
Os dados de uma única instância têm até centenas de GB e armazená-los em um arquivo é obviamente inadequado. Assim como Kafka, Pulsar e outros componentes que precisam armazenar dados Append Only, o ES opta por dividir os dados em segmentos para armazenamento.
-
Segmento: Cada segmento possui seu próprio arquivo de índice e os resultados são mesclados após consultas paralelas;
-
Tempo de geração do segmento: geração programada ou baseada no tamanho do arquivo, a duração é configurável, geralmente alguns segundos;
-
Mesclagem de segmentos: como os segmentos são gerados regularmente e geralmente são relativamente pequenos, eles precisam ser mesclados em segmentos grandes.
Latência e risco de perda de dados
-
Atraso na recuperação: a recuperação condicional depende do índice, e o índice só está disponível quando o segmento é gerado, portanto, geralmente há um atraso de vários segundos entre a gravação e a recuperação;
-
Risco de perda de dados: os segmentos recém-gerados levarão dezenas de minutos para serem liberados por padrão e há risco de perda de dados;
-
Reduza o risco de perda de dados: o Translog também é usado para registrar eventos de gravação. Por padrão, o disco é descarregado a cada 5 segundos, mas ainda há o risco de perder vários segundos de dados.
Como implementar Excluir/Atualizar
-
Excluir: Cada segmento corresponde a um arquivo del, registrando o ID excluído, e os resultados da pesquisa precisam ser filtrados;
-
Atualizar: Escreva novos documentos e exclua documentos antigos.
conjunto
Os bancos de dados de máquina única apresentam problemas como capacidade e rendimento limitados e recursos fracos de recuperação de desastres. Esses problemas geralmente são resolvidos por meio de fragmentação e redundância de dados. Vejamos primeiro como o ES fragmenta e faz backup de dados e, em seguida, como resolver as três questões a seguir: Como as solicitações de leitura e gravação são roteadas para cada fragmento? Como mesclar os resultados da pesquisa de cada fragmento? Como escolher o master entre instâncias ativas e standby?
Fragmento Distribuído
O número de fragmentos para cada índice pode ser configurado de forma independente. A figura a seguir toma um índice com três fragmentos como exemplo. A capacidade geral de armazenamento é aumentada por meio da expansão horizontal e a velocidade de recuperação é melhorada por meio da computação paralela de cada fragmento.
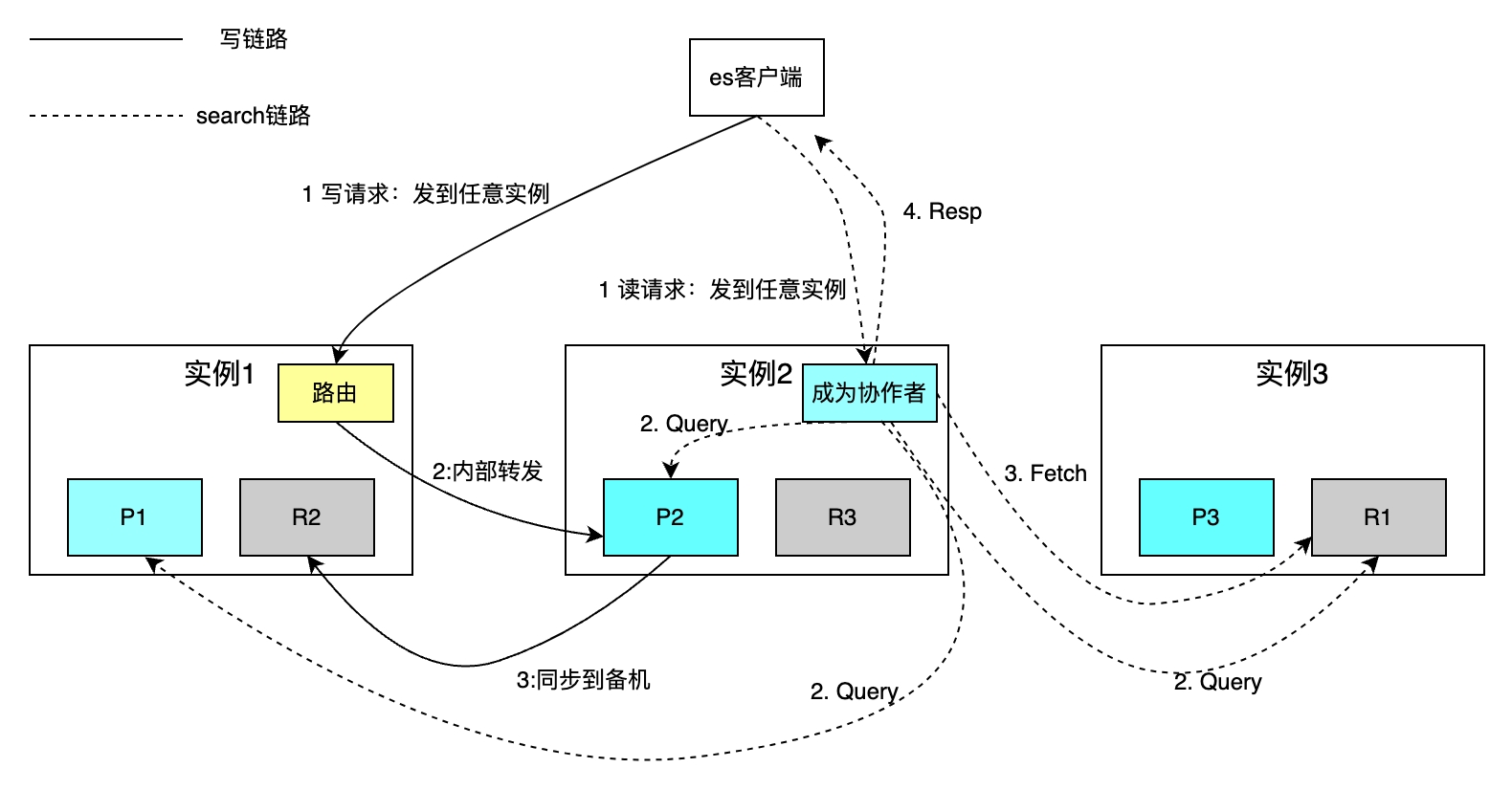
A política de roteamento lê e grava um único documento com base na chave primária. O roteamento de hash usa o ID como chave primária por padrão. Para operações de gravação, se a parte comercial não especificar o ID da chave primária, o ES usa o algoritmo Guid para gerá-lo automaticamente. Devido às restrições da política de roteamento, o aumento ou diminuição do número de fragmentos requer a migração de todos os dados. As solicitações de pesquisa baseadas na recuperação condicional são implementadas por meio de duas etapas: as fases de consulta da Fase de Coordenação e de Consulta do colaborador e a fase de aquisição da Fase de Busca. O colaborador envia uma solicitação de leitura para qualquer instância, e a instância envia a solicitação para cada fragmento em paralelo. Cada fragmento executa SQL local e retorna 2.000 + 100 dados ao colaborador, cada dado incluindo id e uid. O colaborador classifica todos os dados fragmentados, obtém os IDs de 100 documentos, depois obtém os dados por ID e os devolve ao cliente.
A desvantagem é que o método de recuperação acima protege o conceito de fragmentação do cliente, o que facilita muito as operações de leitura e gravação. No entanto, cada instância também precisa ser aberta. um espaço de tamanho from+limit Quando ocorre uma virada profunda de página, é necessária uma grande quantidade de espaço para classificar documentos fragmentados* (from+limit).
Em resposta aos problemas acima, na prática, adicionamos parâmetros como uid>2200 que mudam a cada solicitação aos itens condicionais de Search After, o que pode reduzir o número de ordenações de from+limit para Limit para outra forma de Scroll; Pesquisar depois, manter os itens de condição de cada solicitação internamente no ES e oferecer suporte à simultaneidade.
Renda de sincronização mestre-escravo
Os benefícios incluem principalmente alta disponibilidade por meio de redundância de dados e maior rendimento do sistema. O método de sincronização de dados inclui sincronização mestre-escravo dentro do cluster, que geralmente é implantado em diferentes salas de computadores na mesma região para acelerar as operações de gravação. A consistência pode ser selecionada. Além disso, existe a sincronização entre clusters (CCR), que é usada para recuperação de desastres em vários clusters e acesso próximo em diferentes regiões. Adota um método assíncrono e o nível do índice pode ser replicação de dados unidirecional ou bidirecional. .
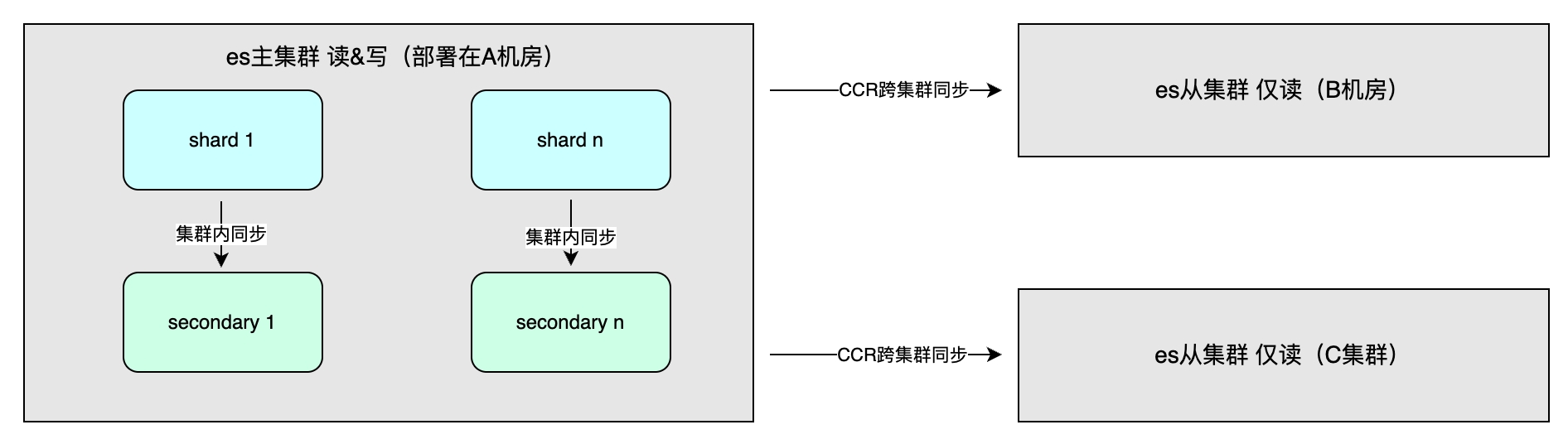
Cena aplicável
Os detalhes de implementação do ES determinam as suas características gerais, o que por sua vez afeta os cenários aplicáveis. Os cenários aplicáveis incluem: grande volume de dados, abaixo do nível PB; necessidade de indexação e classificação flexível de vários campos (Kibana); Porém, não é recomendado usar o ES como único armazenamento para dados importantes, pois há um atraso de vários segundos e o risco de perda de dados e, ao contrário do MySQL, a alta disponibilidade é cuidadosamente otimizada em cada detalhe.
Prática de sistema de agregação de dados entre domínios para plataforma de operação de transmissão ao vivo
Cenários de aplicação
Na plataforma de operação de guildas e âncoras de transmissão ao vivo, existem diversos cenários para visualização e análise de dados, como listas de âncoras, âncoras e tarefas de guilda, etc. Esse tipo de dados geralmente possui as seguintes características: grande volume de dados, muitos campos e de muitas fontes. Por exemplo, o número de campos de índice para âncoras é próximo de 200, as fontes de dados chegam a 10+ (como plataformas de dados, plataformas de segurança, carteiras, etc.) e operações como recuperação e classificação. por vários campos são suportados.
Quando os usuários visualizam os dados, leva muito tempo para obter dados de cada parte da empresa em tempo real e é difícil realizar consultas e classificações condicionais com base em vários campos, portanto, os dados precisam ser agregados antecipadamente em um único banco de dados . É difícil para bancos de dados como MySQL e Redis atender às características acima, e o ES pode apoiá-los melhor. Portanto, construímos um sistema de serviço de agregação de dados entre domínios baseado em ES: consumindo alterações nas fontes de dados upstream e gravando-as no. ES grande índice para atender às necessidades de consulta. Tomemos o "Índice Âncora" como exemplo para ilustrar o modo de agregação de dados:
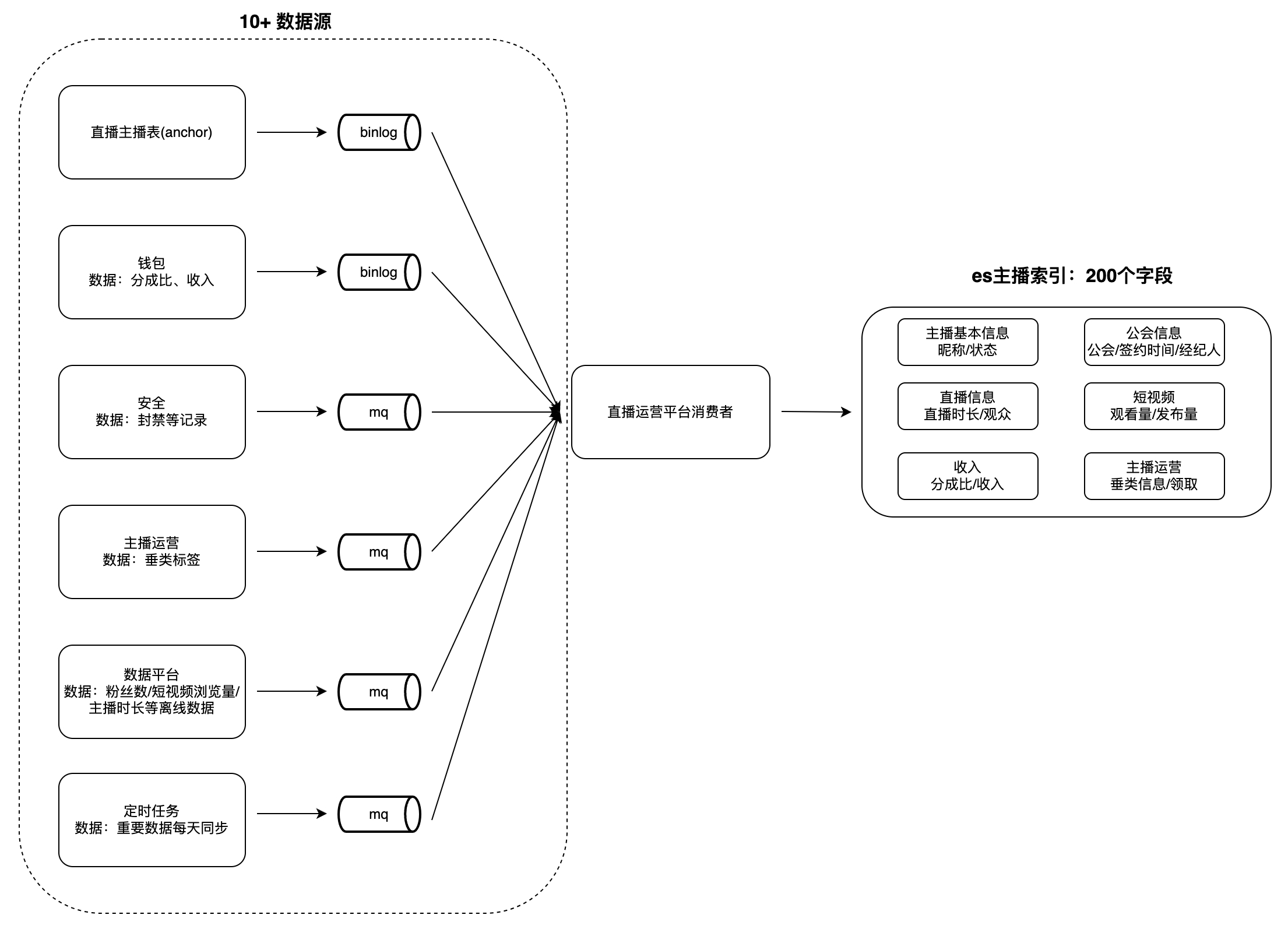
desafio
A primeira versão da implementação usava um único PSM como consumidor para ler os dados upstream e gravá-los no ES. Como as gravações não eram isoladas, havia muitos problemas. Primeiro, todas as partes de acesso gravam a lógica de consumo de dados no mesmo PSM, resultando em alto acoplamento da lógica de processamento de dados e dificuldade de manutenção. Em segundo lugar, existe o risco de várias partes comerciais escreverem para o mesmo campo, o que pode causar exceções comerciais. Além disso, o modo de gravação de dados ES com cobertura total resulta em velocidade lenta de processamento de dados e baixa velocidade de consumo de MQ. Ao mesmo tempo, ainda existem problemas como competição de recursos e consultas lentas que não podem ser associadas a upstreams específicos. Com aproximadamente 5 novos campos adicionados a cada dois meses e os dados continuando a crescer, se estas questões não forem abordadas, haverá desafios maiores no futuro.
A análise dos problemas acima pode ser dividida em três categorias: a lógica de processamento de cada fonte de dados é altamente acoplada e o todo é facilmente afetado por uma única parte do negócio; a velocidade de processamento de dados é lenta, intensificando a concorrência de recursos; e recursos de governança de gravação: isolamento de gravação, estatísticas de consulta lenta.
solução
A figura abaixo apresenta a estrutura geral após a governação. Com base nisso, analisaremos os problemas e considerações encontrados no processo de governação, um por um.
Este conteúdo não pode ser exibido fora dos documentos Feishu no momento.
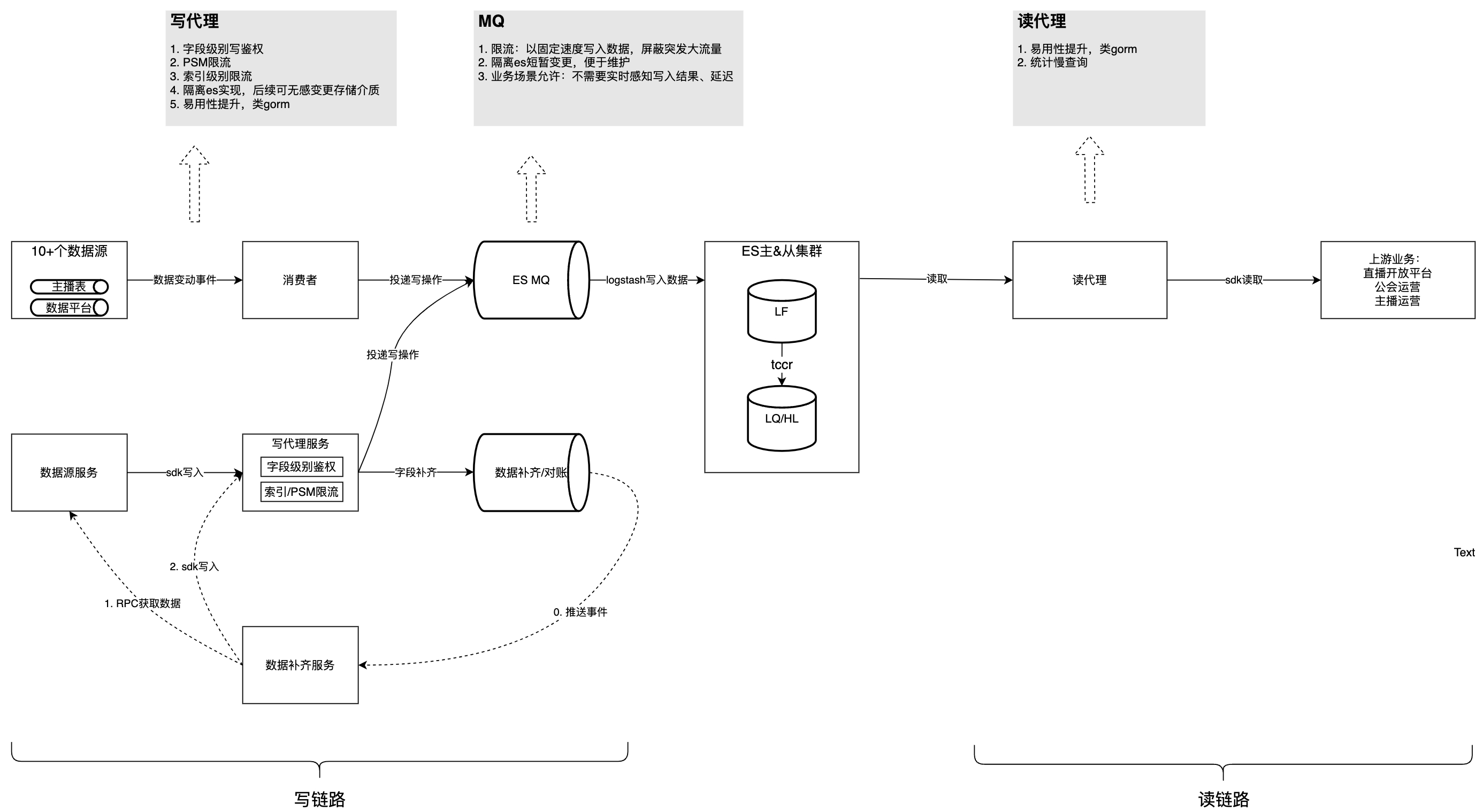
Problema 1: A lógica de consumo de cada fonte de dados é fortemente acoplada, difícil de manter, afeta uma à outra e consome recursos.
A manifestação específica deste problema é que mais de 10 lógicas de consumo de dados MQ são implementadas no mesmo PSM. A lógica de processamento de dados compartilhada e pequenas alterações podem afetar outros processamentos do MQ, tornando a manutenção inconveniente para o serviço monitorar vários eventos do MQ. A competição de recursos e a distribuição desigual de partições de um único evento MQ levam à utilização desigual de recursos em uma única máquina, o que não pode ser resolvido pela expansão horizontal da máquina. Portanto, a instabilidade do código de um único MQ afetará o consumo de todos os Tópicos MQ. A distribuição desigual de Partições de Tópicos MQ individuais fará com que a CPU de instâncias de consumo individuais dispare, afetando assim o consumo de outros Tópicos.
Estratégia de otimização:
-
Melhorar a velocidade de consumo de um único evento: atualização parcial do ES revisar a configuração limite atual de todos os Tópicos;
-
Crie mais métodos de gravação de dados e distribua a gravação de campos não essenciais para vários setores de negócios. Por exemplo, ele fornece SDK de escrita e apresenta o Dsyncer.
Problema 2: o consumo de dados
do MQ
é lento e as atualizações dos dados de negócios estão atrasadas
O processamento de uma única mensagem MQ é demorado Tomando como exemplo o modo de gravação de dados ES de cobertura total, a atualização de um campo requer a gravação dos campos restantes que não precisam ser atualizados juntos, porque quase 200 dados de campo precisam ser obtidos. em tempo real por meio de RPC No geral, leva muito tempo e a velocidade de consumo do MQ é lenta; alguns tópicos do MQ consomem 1 trabalhador em uma única instância. O principal impacto é que o atraso na atualização dos dados é alto e demora um pouco para que as informações do usuário sejam exibidas nas plataformas downstream após as alterações. E cada atualização requer a obtenção de quase 200 campos de diversas partes de negócios. Anormalidades em uma única fonte de dados farão com que todo o consumo de eventos do MQ falhe e seja repetido.
Estratégia de otimização:
-
Altere o modo de gravação de dados do cluster ES de cobertura total para atualização parcial: um único campo pode ser atualizado sob demanda, e o Consumidor não precisa mais obter quase 200 campos de várias partes comerciais, o que não apenas reduz o tempo de processamento de dados, mas também também reduz a dificuldade de manutenção do código;
-
Configure todos os Tópicos do MQ para terem vários Trabalhadores, e aqueles que exigem consumo sequencial são configurados para serem roteados para o mesmo Trabalhador com base no ID da chave primária.
Problema 3: A escrita não é isolada/autenticada/limitada
A escrita de campo carece de isolamento e autenticação, e há o risco de que várias partes comerciais possam escrever no mesmo campo, o que pode causar anomalias nos negócios. A principal razão é que as partes que escrevem compartilham recursos. Se uma parte escrever muito rapidamente, ela ocupará os recursos de outras partes, fazendo com que o atraso na escrita aumente. Portanto, é necessário controlar rigorosamente as principais atualizações de campo do armazenamento ES para evitar o desencadeamento de uma grande quantidade de feedback dos usuários.
Estratégia de otimização:
-
Adicionada autenticação de gravação em nível de campo, permitindo que apenas PSMs autorizados gravem determinados dados de campo;
-
Para realizar estratégias de limitação de tráfego nas duas dimensões de PSM e índice, são utilizados componentes configuráveis dinamicamente na plataforma geral de gerenciamento de tráfego.
Problema 4: Falta de estatísticas de consulta lenta e métodos de otimização
Assim como o MySQL e outros bancos de dados, o SQL fora do padrão levará a verificações desnecessárias e grandes atrasos nas consultas. O ES oferece a capacidade de consultar SQL demorado, mas não pode correlacionar PSM upstream, Logid e outras informações, dificultando a solução de problemas.
Estratégia de otimização: O agente de leitura registra SQL, PSM upstream, Logid e outras mensagens que ultrapassam o limite na forma de uma camada intermediária para o ES e relata condições de consulta lenta todos os dias.
Pergunta 5: Facilidade de uso
Estratégia de otimização:
-
Habilite o plug-in ES SQL no cluster ES Como a sintaxe ES SQL é um pouco diferente do MySQL SQL, suporte adicional é fornecido por meio do serviço de agente de leitura: o lado do usuário usa a sintaxe MySQL e o agente de leitura usa expressões regulares para reescrever. SQL para padrões ES SQL; injetar ScrollID em ES SQL, o lado do usuário não precisa se preocupar em como expressar a consulta Scroll em SQL;
-
Ajude os usuários a desserializar dados de consulta em estruturas.
// es dsl查询样例 GET twitter/_search { "size": 10, "query": { "match" : { "title" : "Elasticsearch" } }, "sort": [ {"date": "asc"} ] } // 使用读sdk的等价sql select * from twitter where title="Elasticsearch" order by date asc limit 10
Resultados de governança
Através da governação acima, a acumulação de links de escrita foi completamente eliminada e a capacidade de consumo aumentou 150%, o que se reflecte especificamente no aumento do QPS do negócio de 4k para 10k, sem atingir o limite superior de desempenho do sistema. O QPS de leitura de pico é 1.500 e o SLA é estável em 99,99% no longo prazo. Atualmente, várias partes comerciais estão usando o SDK e as partes comerciais relataram que o tempo de acesso foi reduzido dos 2 dias originais para 0,5 dias.
Planejamento de acompanhamento
O planejamento de acompanhamento inclui principalmente a expansão dos recursos de reconciliação do MVP de cenários individuais para todos os cenários;
Com base na experiência interna de melhores práticas em larga escala da ByteDance, o Volcano Engine fornece
produtos
ES
externamente consistentes - produtos em nuvem de nível empresarial de serviço de pesquisa em nuvem. O serviço de pesquisa em nuvem é compatível com Elasticsearch, Kibana e outros softwares e plug-ins de código aberto comumente usados. Ele fornece recuperação de múltiplas condições, estatísticas e relatórios de texto estruturado e não estruturado. operação e manutenção simplificadas e criação rápida de análise de log, recuperação e análise de informações e outros recursos de negócios.
{{o.nome}}
{{m.nome}}