Construir e manter um mecanismo de busca de bilhões de níveis não é fácil e não existe um método de gerenciamento ideal e definitivo. Este artigo é o resultado de aprendizado contínuo e resumo na prática. Ele apresenta como construir um sistema de pesquisa que pode suportar produtos que variam de dezenas de milhões a centenas de milhões e perceber o aumento do QPS total de consultas de centenas para milhares e escrever. o QPS total O processo de aumento do nível 100 para o nível 10.000. Entre eles, a expansão dos recursos do ES é essencial, mas, além disso, este artigo também se concentrará em alguns problemas de desempenho do ES que não podem ser resolvidos pela expansão. Espero que através deste artigo você possa ter mais dados e referências de uso para cenários de uso de ES. Devido ao espaço limitado, a parte sobre a governação da estabilidade será introduzida no próximo artigo.
Introdução de negócios
O sistema de gerenciamento de investimentos da plataforma atende ao cenário de investimento multientidade das atividades da plataforma de comércio eletrônico Douyin. Ele coletará e selecionará produtos por meio da plataforma de investimento e, em seguida, distribuirá os produtos para vários sistemas C-end. As entidades que atraem investimento também são muito diversas, incluindo salas de transmissão ao vivo, investimento em produtos, investimento em cupões, etc. Entre elas, o investimento em produtos é a nossa maior entidade de investimento.
Estrutura de serviços da plataforma de investimento
Centro de dados
O data center é um serviço de pesquisa baseado em ES que fornece serviços de aquisição e orquestração de dados configuráveis, escaláveis e universais. É um serviço universal que suporta consulta de dados na plataforma de investimento.
Conceitos-chave para entender:
-
Indicadores
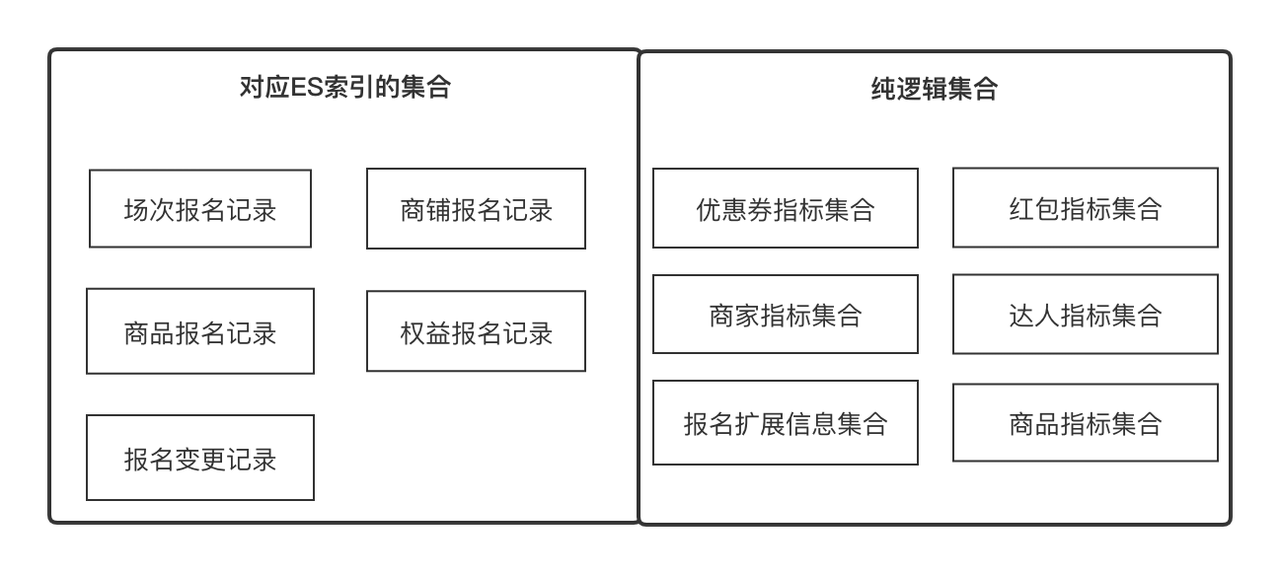
: Indicadores são metadados que usamos para descrever um atributo de uma entidade ou objeto, como nome do produto, pontuação de experiência na loja, nível de especialista, ID do registro de registro. Unidade, como informações de comparação de preços de produtos. Podemos definir todos os campos com semântica clara como indicadores
.
-
Conjunto
: representa um conjunto que pode ser convergido por alguns pontos em comum, como conjunto de atributos de produto e conjunto de atributos de loja, que podem ser obtidos por ID de produto e ID de loja respectivamente. Também pode ser uma coleção de registros de registro de produto, que pode ser obtida por. ID do registro de registro. Em termos comerciais, expressa um conjunto de indicadores relacionados e os indicadores estão em um relacionamento um-para-muitos.
-
Solução
: Solução de aquisição de dados. Abstraímos os dois conceitos de indicadores e coleções para que os dados possam ser obtidos na menor unidade e possam ser continuamente expandidos horizontalmente.
-
Cabeçalho personalizado
: o cabeçalho personalizado refere-se ao título a ser exibido em qualquer lista de dados de linha bidimensional. Possui um relacionamento um para muitos com o indicador;
-
Item de filtro
: O item de filtro refere-se ao item de filtro que precisa ser usado em qualquer lista de dados de linha bidimensional. Pode indicar um relacionamento 1 para 1;
-
Visualização de auditoria
: a visualização de auditoria refere-se a uma página de auditoria que pode ser renderizada dinamicamente a partir de um conjunto de cabeçalhos personalizados e de um conjunto de itens de filtro em um cenário de negócios de auditoria.
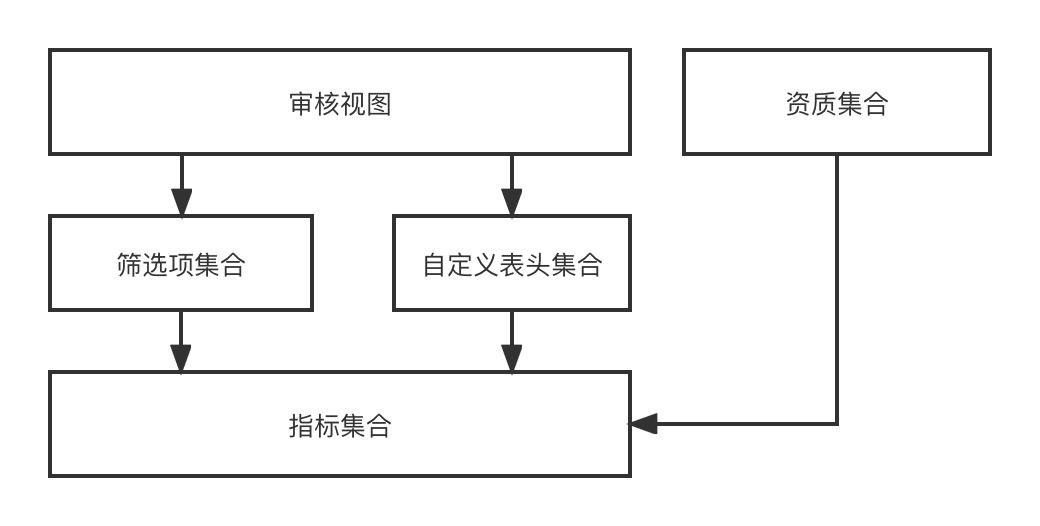
No design funcional, através do indicador-->[Itens de filtro, cabeçalho personalizado]-->Visualização de auditoria-->o processo de finalmente renderizar dinamicamente uma página de auditoria Uma vez que estamos recrutando investimentos com múltiplas entidades e múltiplos cenários, diferentes entidades. têm cenários diferentes. São necessárias diferentes visualizações de auditoria, portanto, esta série de recursos que projetamos pode combinar dinamicamente quaisquer efeitos de visão de auditoria necessários.
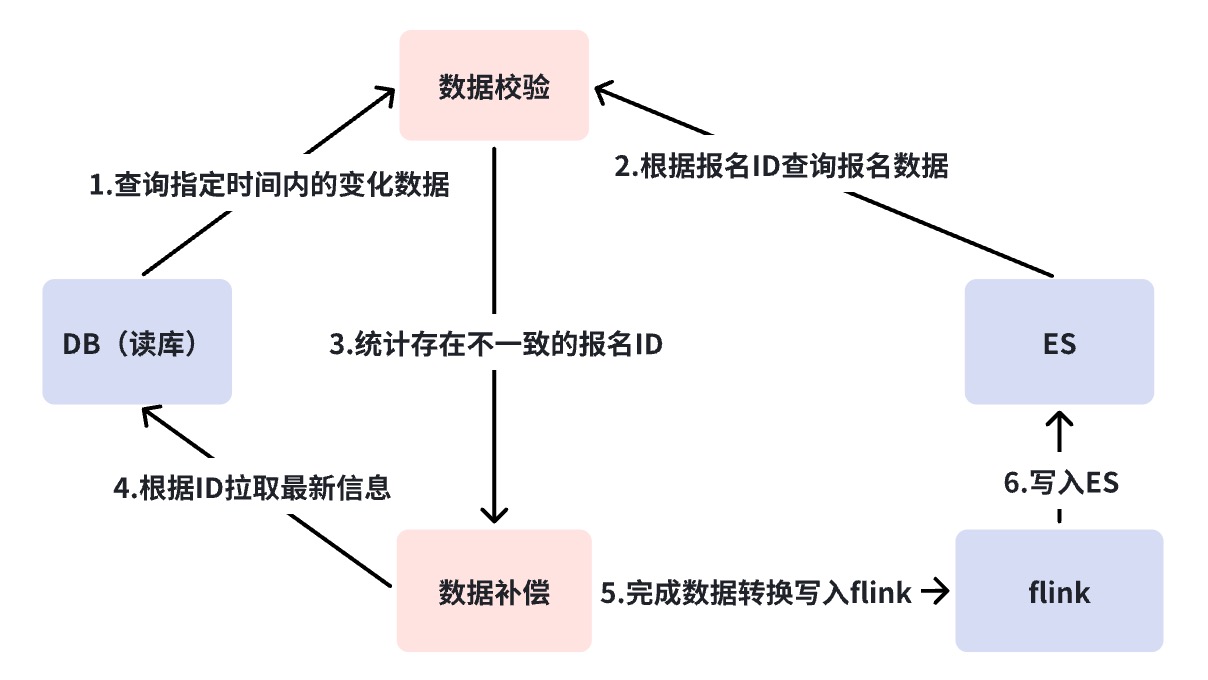
O data center fornece recursos gerais de aquisição de dados para empresas de camada superior, incluindo sincronização e consulta de dados. Existem atualmente duas fontes de dados, a interface RPC externa e o registo de registo ES. O data center integra dois conjuntos de soluções de aquisição de dados, que desconhecem completamente o mundo exterior, ou seja, apenas necessita de obter quais indicadores de dados sob quais. coleção.
O objetivo da construção do ES é apoiar a triagem e as capacidades estatísticas dos registros de registro de investimentos e produzir o conteúdo de dados desejado para os negócios de nível superior.
Construa um cluster ES de 0 a 1
Para construir um sistema de 0 a 1, com base no atendimento das necessidades básicas do negócio, a estabilidade precisa apoiar os dois pontos seguintes;
-
O mecanismo básico de recuperação de desastres significa que quando o desempenho do sistema é afetado devido a alterações nos componentes básicos e no tráfego de leitura e gravação, a empresa pode se ajustar a tempo.
-
A consistência final dos dados significa que o registro de registro DB --> dados da sala multimáquina ES está completo.
Pesquisa do programa
Avaliação da capacidade do cluster ES
A avaliação da capacidade do cluster ES visa garantir que o cluster possa fornecer serviços estáveis por um período de tempo após sua construção. Ele precisa principalmente ser capaz de resolver os seguintes problemas:
-
Quantos fragmentos devem ser definidos para cada índice, quanto incremento de dados subsequente é esperado e estimativas de tráfego de leitura e gravação;
-
Quantas instâncias de dados devem ser configuradas em um único cluster e quais especificações devem ser usadas para uma única instância de dados;
-
Entenda a diferença entre expansão vertical e expansão horizontal, qual é a nossa estratégia de resposta quando o volume de dados aumenta inesperadamente ou o tráfego aumenta inesperadamente e como a recuperação de desastres do cluster ES deve ser projetada.
Principais soluções:
-
Depois que o número de fragmentos do índice ES for definido, ele não poderá ser modificado, por isso é importante determinar o número de fragmentos. Normalmente, o número de fragmentos é um múltiplo inteiro da instância ES para garantir o balanceamento de carga;
-
O tamanho de um único fragmento é relativamente razoável entre 10 e 30G. A indexação excessiva afetará o desempenho da consulta;
-
O aumento no tráfego pode ser resolvido pela expansão da capacidade, e o aumento nos dados pode ser resolvido excluindo dados antigos ou aumentando o número de fragmentos e deve ser implantado com um plano de implantação de recuperação de desastres em várias salas de máquinas, para que uns aos outros; é uma sala de máquinas tolerante a desastres.
Seleção de link de sincronização de dados
Ele resolve principalmente como sincronizar os registros de registro do banco de dados com o ES, como gravar outros indicadores relacionados no ES e como atualizar e garantir a consistência dos dados.
-
DB -> ES precisa ser um fluxo de dados quase em tempo real, e as alterações nos registros de registro e outras informações devem ser pesquisáveis em tempo quase real;
-
Além de seus próprios campos, o registro de registro também precisa complementar seus campos de atributos, como produtos cadastrados, lojas e especialistas. Ele também é gravado no ES e
pode suportar atualizações parciais
, portanto o método de escrita do ES só pode ser o método Upsert. ;
-
As atualizações nos registros de registro individuais devem estar em ordem e não devem entrar em conflito.
Pesquisa de configuração básica do índice ES
Entenda os fundamentos e configurações essenciais do ES.
-
{"dynamic": false} evita a expansão automática de mapeamentos es ou a adição de tipos de índice inesperados;
-
index.translog.durability=async, atualizar o translog de forma assíncrona ajudará a melhorar o desempenho de gravação, mas há risco de perda de dados;
-
O intervalo de atualização padrão do ES é 1s, o que significa que os dados podem ser encontrados um segundo após a gravação bem-sucedida.
Solução de sincronização de dados
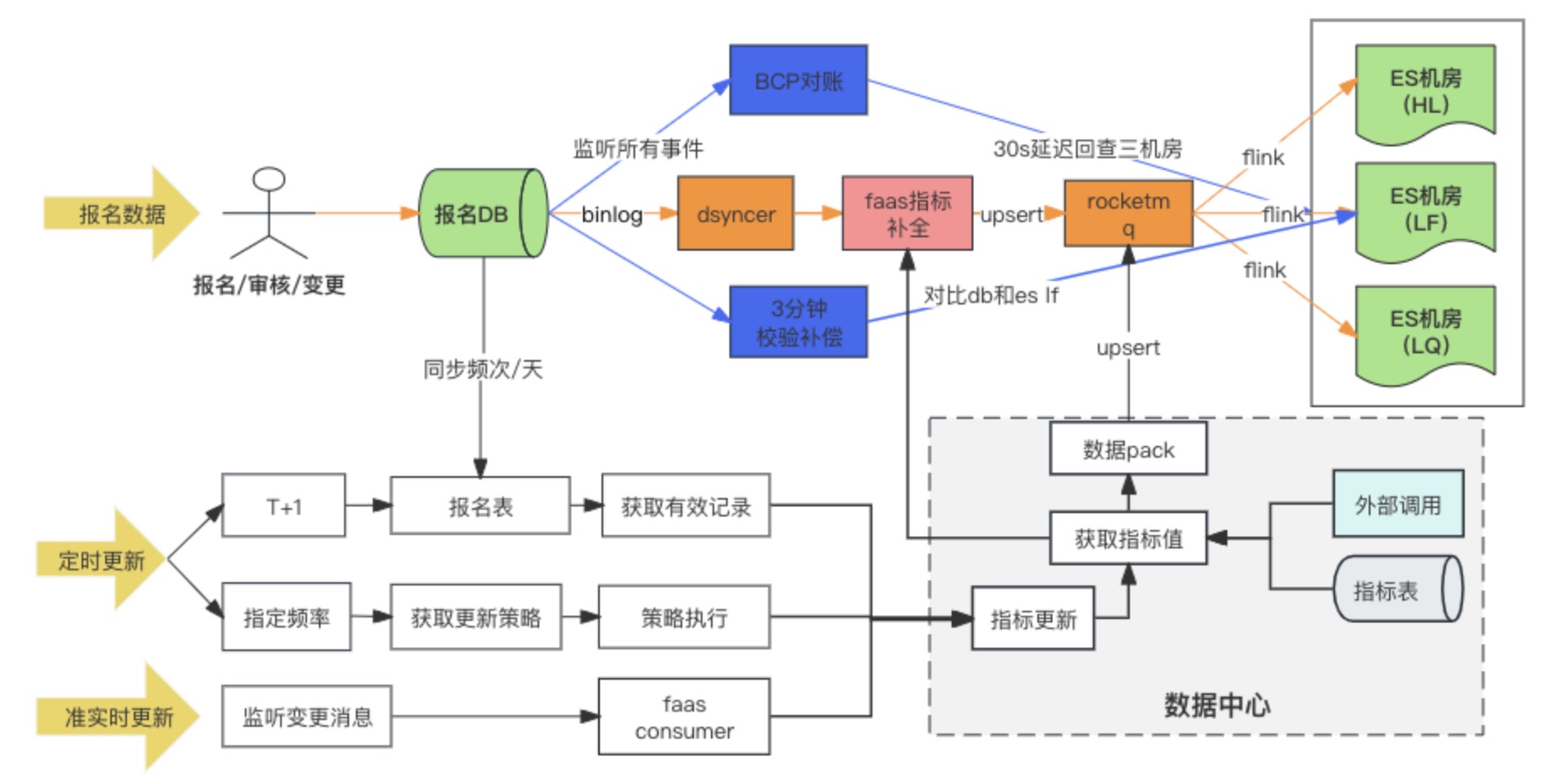
Diagrama de link de sincronização de dados
A solução de sincronização de dados DB -> ES adota, em última análise, o método de gravação síncrona de dados heterogêneos no RocketMQ + Flink para consumo de sala de várias máquinas. Ao mesmo tempo, quando o registro de registro é gravado pela primeira vez, os indicadores estendidos são preenchidos. através do script de conversão personalizado Faas, e as dependências de atualização dos indicadores estendidos são Alterar os dois métodos de escuta de mensagens e tarefas agendadas. Durante a pesquisa, havia na verdade três opções para sala multicomputador DB -> ES. No final, escolhemos a terceira opção. Aqui comparamos as diferenças entre as três opções:
Solução 1: gravar diretamente na sala de múltiplas máquinas ES por meio de sincronização de dados heterogêneos (Dsyncer)
deficiência:
-
A escrita direta está em desvantagem no cumprimento dos requisitos do ES para implantar várias salas de computadores simultaneamente, porque não pode garantir a escrita bem-sucedida em várias salas de computadores ao mesmo tempo. É correto implantar vários dados heterogêneos e gravá-los separadamente? Sim, isto é, a carga de trabalho triplicou para cerca de uma dúzia de índices.
-
A capacidade de gravação em massa direta é relativamente fraca e os picos de gravação serão mais óbvios à medida que o tráfego flutua, o que não é favorável ao desempenho de gravação do ES.
-
A escrita direta não pode garantir a atualização ordenada de um único registro de registro quando o ES possui múltiplas entradas de atualização. Posso aumentar a versão global? Sim, mas muito pesado.
Vantagens:
O caminho de dependência mais curto, baixa latência de gravação e risco mínimo do sistema Não é problema para empresas de pequeno tráfego e empresas com cenários de sincronização simples.
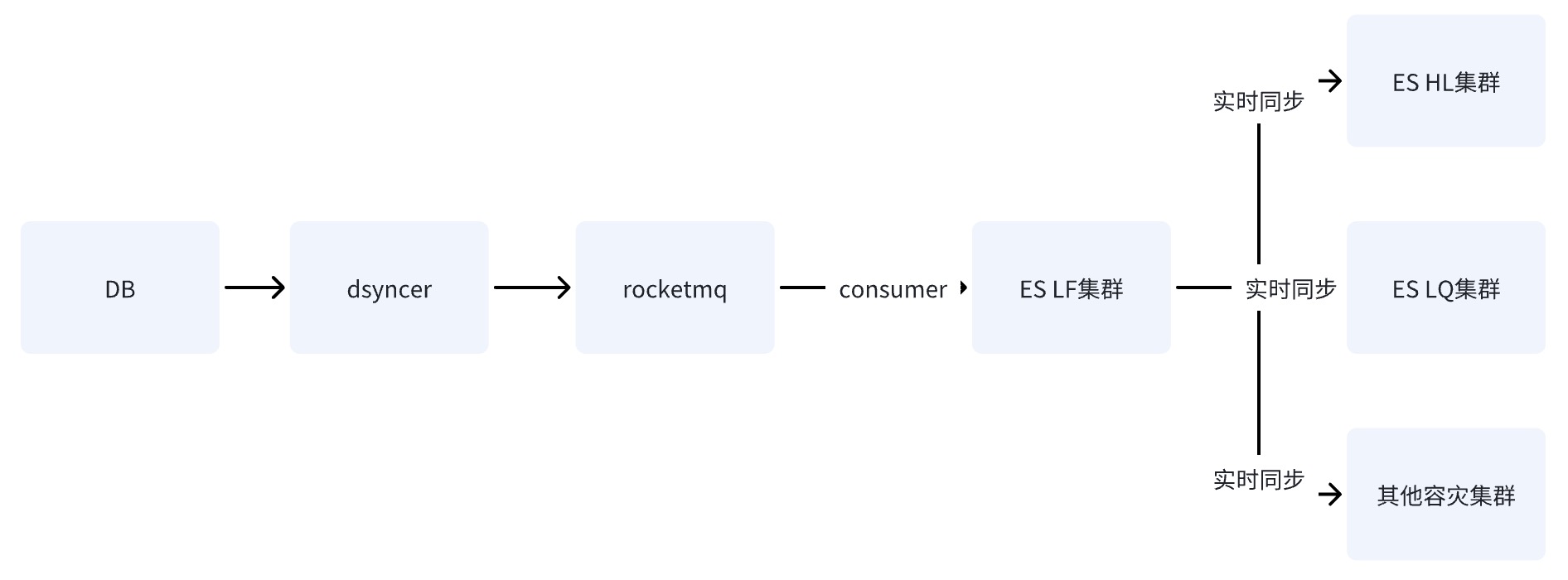
Opção 2: escrever sala de computador único ES por meio do RocketMQ
Depois que o DB grava na sala de computadores única do ES por meio do RocketMQ, os dados são sincronizados com outras salas de computadores por meio do recurso de replicação de dados entre clusters fornecido pelo ES.
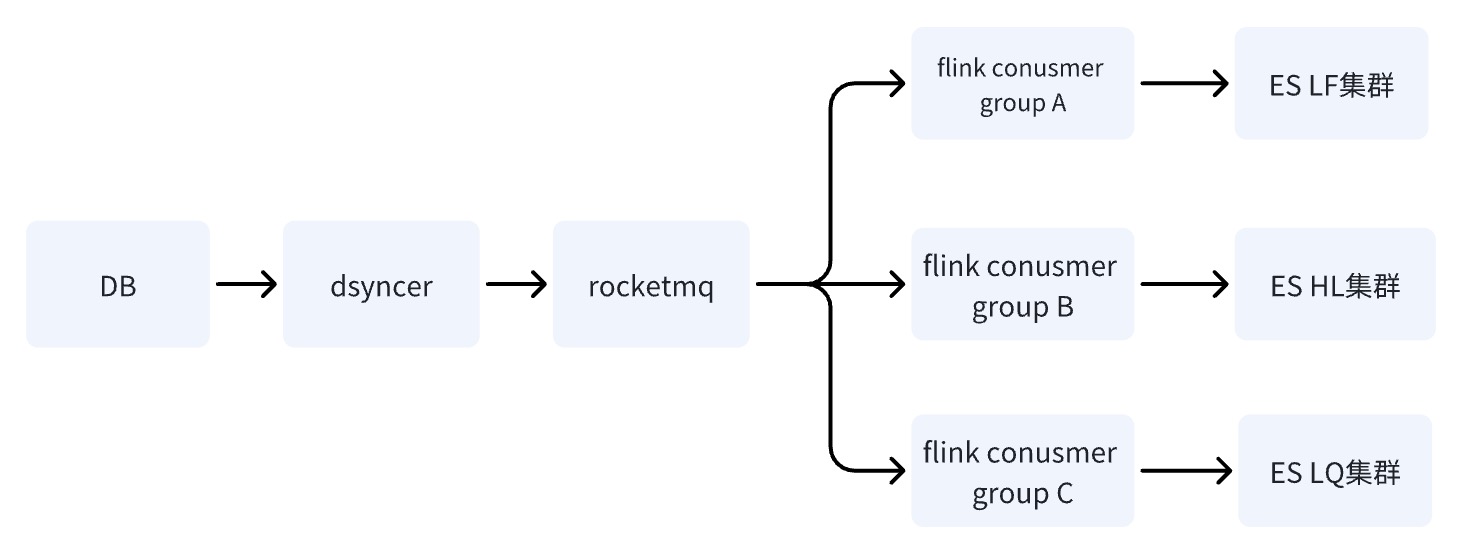
Opção 3: Escreva sala multimáquina ES por meio de RocketMQ + Flink ✅
Quando o banco de dados grava no cluster ES por meio do RocketMQ, várias tarefas independentes do grupo de consumidores são iniciadas. O sistema pode usar o sistema distribuído Flink para gravar dados em várias salas de computadores.
Há apenas uma diferença entre o esquema dois e o esquema três: a maneira de gravar em várias salas de computadores é diferente. O esquema dois é gravar em uma sala de computadores e, em seguida, sincronizar os dados com outras salas de computadores em tempo quase real, enquanto o esquema. três é escrever vários consumidores independentes separadamente.
As desvantagens das opções dois e três são as mesmas: o caminho de dependência é o mais longo e o atraso de gravação é facilmente afetado pela instabilidade dos componentes básicos. No entanto, a desvantagem fatal da opção dois é que existe um
único ponto de risco. o sistema
. Supondo que os dados sejam sincronizados com HL e LQ por meio de LF, o sistema ficará inutilizável depois que LF desligar.
A vantagem da opção três é que os links de gravação de várias salas de computadores são independentes entre si. Em comparação com a opção dois, se algum link apresentar problemas, o RocketMQ pode resolver facilmente o problema de atualização sequencial de chave única; ,
o que também é indesejável pelo motivo da opção um
.
Por que escrever por meio do RocketMQ pode resolver o problema de fora de ordem e conflito?
-
Em primeiro lugar, a escrita ES é controlada pelo bloqueio otimista com base no número da versão. Se o mesmo registro for atualizado simultaneamente ao mesmo tempo, então a versão que obtemos ao mesmo tempo é a mesma, assumindo que seja 1, então todos o farão. atualize a versão para 2 para escrever, ocorrerão conflitos e sempre causarão o problema de atualizações perdidas;
-
Os cenários de negócios gerais exigem um consumo ordenado com base na ordem de chave e partição. O consumo ordenado requer duas condições necessárias: quando as mensagens são armazenadas, elas devem ser consistentes com a ordem em que são enviadas; em que estão armazenados.
Portanto, se o negócio deseja consumir mensagens de forma ordenada, ele precisa garantir que as mensagens enviadas com a mesma Chave sejam enviadas para a mesma Partição, e as mensagens consumidas garantam que as mensagens com a mesma Chave sejam sempre consumidas pelo mesmo Consumidor. Mas, na verdade, as duas condições necessárias mencionadas acima são ideais. Em alguns casos, não podem ser totalmente garantidas, como o Reequilíbrio do Consumidor. Por exemplo, a escrita de uma determinada instância do Corretor continua falhando.
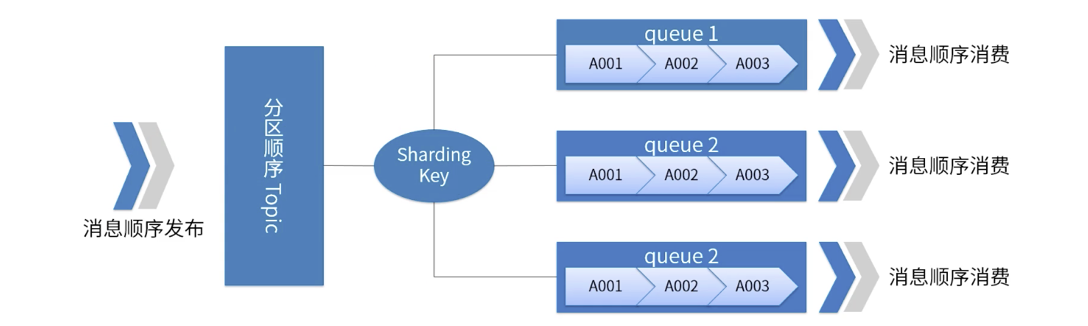
Uma imagem ilustra a ordem de partição do RocketMQ
-
Para um tópico específico, todas as mensagens são divididas em múltiplas (fila) de acordo com a chave de fragmentação.
-
As mensagens na mesma fila são publicadas e consumidas em ordem FIFO estrita.
-
Sharding Key é um campo-chave usado para distinguir diferentes partições em mensagens sequenciais. É um conceito completamente diferente da chave das mensagens comuns.
-
Cenários aplicáveis: Requisitos de alto desempenho Determine para qual fila a mensagem é enviada com base na chave de fragmentação da mensagem Geralmente, o particionamento ordenado pode atender aos nossos requisitos de negócios e ter alto desempenho.
O que precisa ser observado aqui é
que
o RocketMQ pode ter ajudado o negócio a resolver 99% dos problemas de fora de ordem, mas não é 100%. Em casos extremos, as mensagens ainda podem ter problemas de consumo fora de ordem, como. como o fenômeno ABA, como quando o Partiton falha, a mensagem é enviada repetidamente para outras filas de partição, etc., portanto, a reconciliação de consistência é essencial.
Mecanismo de reconciliação multicamadas
O mecanismo de reconciliação resolve o problema de consistência de dados de DB->ES Como mencionado anteriormente, DB -> ES é um fluxo de dados quase em tempo real e o link de dependência é relativamente longo. estratégias de reconciliação e compensação para garantir eventual consistência dos dados.
Aqui fizemos uma reconciliação em três camadas. Usamos a plataforma de reconciliação para obter reconciliação em nível minucioso e reconciliação offline. As razões para a necessidade de reconciliação em várias camadas serão explicadas uma por uma abaixo.
Diagrama de análise de falha do link ES de sincronização de banco de dados
Reconciliação de segundo nível da Business Verification Platform ( BCP )
Referindo-se à figura acima, você descobrirá que a sincronização DB -> ES depende de muitos componentes dependentes. Nesse caso, precisamos de uma
reconciliação de uma perspectiva global
para descobrir problemas de link de sincronização, ou seja, reconciliação em tempo real do BCP.
A reconciliação BCP é uma reconciliação de fluxo único que monitora o Binlog e verifica diretamente a reconciliação da sala de várias máquinas ES. Ela depende apenas do fluxo Binlog. Atrasos ou bloqueios na sincronização de dados nos links intermediários podem ser descobertos rapidamente por meio de reconciliação BCP. descobrirá que se o Binlog for cortado e a reconciliação do BCP não puder ser corrigida, como resolver esta situação será discutido mais tarde, mas pelo menos pode-se ver que, exceto para DB-> DBus, a reconciliação do BCP é suficiente para encontrar a maior parte do atraso de sincronização. problemas. Por que fluxo único em vez de fluxos múltiplos?
-
Evite problemas de atraso incontroláveis causados por longos links de fluxo de dados para reconciliação multistream, resultando em baixa precisão de verificação.
-
O custo de manutenção da reconciliação BCP será bastante reduzido, porque se for usado multi-stream, precisamos manter múltiplas reconciliações BCP para reconciliação de sala de vários computadores, que depende de componentes mais básicos para manutenção.
A escrita do banco de dados de reconciliação BCP sempre aciona solicitações Get ES, que consomem certos recursos de consulta no ES, mas as solicitações Get são métodos de consulta com desempenho muito bom. Por exemplo, não temos problemas para escrever dentro de 1000 QPS.
A solicitação Get precisa estar atenta a um parâmetro Realtime, que precisa ser definido como False no momento da solicitação, caso contrário acionará uma operação Refresh toda vez que for solicitada, o que terá impacto no desempenho de escrita do sistema.
mgetReq := EsClient.MultiGet().
Tempo real (falso)
Reconciliação em nível de minuto
Conforme mencionado na seção anterior, o caminho que não pode ser percorrido pela reconciliação do Business Verification Platform (BCP) é DB->DBus, que é a situação em que o Binlog é cortado. Normalmente a interrupção do Binlog pode ter significado um acidente mais grave, mas o que temos que fazer é fazer todo o possível.
A reconciliação em nível de minuto consulta diretamente o DB e o ES para reconciliação, sem depender de nenhum componente. Quando ocorrem inconsistências, a compensação automática é executada. Por um lado, a reconciliação ao nível do minuto compensa as deficiências da reconciliação do BCP, e o segundo ponto é adicionar um mecanismo de compensação. A razão pela qual o BCP não compensa é porque o BCP serve principalmente para descobrir problemas, por isso precisa permanecer leve e rápido. Além disso, ainda depende de componentes básicos como RocketMQ e DBus. Esse tipo de compensação ainda não pode cobrir todos os cenários anormais.
Por padrão, consideraremos que a função do componente está intacta para reconciliação a cada três minutos, mas um pequeno atraso em um nó causa compensação. Se os alarmes de compensação ocorrerem com frequência, precisamos analisar melhor qual é o problema com o link. Neste momento, em nosso cenário, dividirei o link em dois e confirmarei se há um problema com o link anterior do RocketMQ ou um problema com o RocketMQ e links de consumo subsequentes. Através do diagrama de análise de falhas, se houver um problema com o link antes do RocketMQ, como interrupção do Binlog, suspensão de componentes da plataforma de sincronização de dados heterogêneos, etc., os dados de compensação serão gravados diretamente no RocketMQ e consumidos em várias salas de computadores. Ao mesmo tempo, o tráfego de leitura não precisa ser interrompido e pode garantir a consistência dos dados em várias salas de computadores. Mas se o RocketMQ desligar, ele gravará diretamente no ES. Como neste momento não podemos garantir que várias salas de computadores possam ser gravadas com sucesso ao mesmo tempo, nossa decisão é gravar apenas em uma única sala de computadores e transferir todo o tráfego para. a única sala de informática.
O desligamento do RocketMQ é um sinal muito ruim e a situação aqui é mais complicada. Por causa da escrita direta no ES, se o tráfego de gravação for alto, o sistema perde a proteção limitadora de corrente neste momento, e o ES pode não ser capaz de suportá-la, uma única sala de computadores pode não ser capaz de suportar todo o tráfego de leitura no momento; ao mesmo tempo; se ocorrerem conflitos de gravação com frequência, a porta de gravação comercial precisará ser rebaixada. Portanto, se o RocketMQ desligar, pode-se entender que o sistema central do link de gravação está paralisado.
Esta é a última coisa que você deseja ver, então o SLA do RocketMQ é a linha de base do negócio.
Reconciliação off-line T+1
A reconciliação offline serve para sincronizar os dados do DB e ES com o Hive diariamente. Os dados incrementais verificam a consistência final. A reconciliação offline é o resultado final para a consistência dos dados do link de sincronização. os dados devem ser T no máximo +1 compensação bem-sucedida.
Resumir
Acima, concluímos a primeira fase de construção, implantação de recuperação de desastres, reconciliação de consistência e estratégias básicas de resposta a exceções do sistema. Neste momento, o ES pode suportar solicitações de leitura e gravação para dezenas de milhões de índices de produtos. O tráfego de uma única sala de computadores varia entre 500 e 100 QPS, e o tráfego de gravação é basicamente mantido em torno de 500 QPS.
No entanto, com o desenvolvimento dos negócios, o cluster ES sofreu picos de CPU muitas vezes, uma ou mais salas de computadores estão cheias ao mesmo tempo e os atrasos nas consultas aumentam repentinamente. No entanto, o tráfego de leitura e gravação não flutua muito ou é. muito menor que o pico do sistema. Este risco É atribuído aos problemas de desempenho que ocorrem no cluster ES e à postura de uso do negócio. Continuaremos apresentando esta parte no próximo artigo sobre o gerenciamento de estabilidade do mecanismo de busca ES.
Fonte do artigo | Plataforma de negócios ByteDance Wang Dan