
Nota do editor: Quando o autor estava tentando ensinar sua mãe a usar o LLM para realizar tarefas de trabalho, ela percebeu que a otimização de palavras imediatas não era tão simples quanto se imaginava. A otimização automática de palavras de prompt é valiosa para escritores de palavras de prompt inexperientes que não têm experiência suficiente para ajustar e melhorar as palavras de prompt fornecidas ao modelo , o que desencadeou uma exploração mais aprofundada de ferramentas automatizadas de otimização de palavras de prompt.
O autor deste artigo analisa a natureza da engenharia de palavras imediatas a partir de duas perspectivas - ela pode ser considerada como parte da otimização de hiperparâmetros ou pode ser considerada como um processo de exploração, tentativa e erro e correção que requer tentativas e ajustes constantes. .
O autor acredita que para tarefas com entrada e saída de modelo relativamente claro, como resolução de problemas matemáticos, classificação de emoções e geração de instruções SQL, etc. O autor acredita que a engenharia de palavras imediatas, neste caso, é mais como otimizar um "parâmetro", assim como ajustar hiperparâmetros no aprendizado de máquina. Podemos usar métodos automatizados para tentar constantemente diferentes palavras de prompt para ver qual delas funciona melhor. Para tarefas relativamente subjetivas e vagas, como escrever e-mails, poemas, resumos de artigos, etc. Como não existe um padrão preto e branco para julgar se a saída está "correta", a otimização das palavras de prompt não pode ser realizada de forma simples e mecânica.
O link do artigo original: https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
Link do perfil do LinkedIn: https://linkedin.com/in/ianhojy
Link do perfil médio para assinaturas: https://ianhojy.medium.com/
Autor | Ian Ho
Compilado |
Nos últimos meses, tenho tentado construir vários aplicativos com tecnologia LLM. Para ser honesto, passo boa parte do meu tempo melhorando o Prompt para obter o resultado que desejo do LLM.
Houve muitas ocasiões em que fiquei preso no vazio e na confusão, me perguntando se eu era apenas um engenheiro de alerta glorificado. Dado o estado atual da interação humana com LLMs (Large Language Models), ainda tendo a concluir "ainda não" e sou capaz de superar minha síndrome do impostor na maioria das noites. (Nota do tradutor: É um fenômeno psicológico que se refere a indivíduos que são céticos em relação às suas próprias realizações e habilidades. Eles muitas vezes se sentem mentirosos, acreditam que não são dignos de ter ou alcançar as conquistas que alcançaram e são preocupado em ser exposto.) Atualmente Não discutiremos esse assunto em profundidade por enquanto.
Mas ainda me pergunto se um dia o processo de escrever o Prompt poderá ser basicamente automatizado. Como responder a essa pergunta depende de você conseguir descobrir a verdadeira natureza da engenharia imediata.
Embora existam inúmeros manuais de engenharia imediata na vasta Internet, ainda não consigo decidir se a engenharia imediata é uma arte ou uma ciência.
Por um lado, parece uma arte quando tenho que aprender e aprimorar repetidamente as instruções que escrevo com base no que observo na saída do modelo . Com o tempo, descobri que pequenos detalhes são importantes – como usar “deve” em vez de “deveria” ou adicionar diretrizes, recomendações ou especificações) no final da palavra do prompt, e não no meio. Dependendo da tarefa, há tantas maneiras de expressar uma série de instruções e orientações que às vezes parece uma tentativa e erro constante e cometer erros.
Por outro lado, pode-se pensar que as palavras-prompt são apenas hiperparâmetros. Em última análise, o LLM (Large Language Model) trata apenas as palavras de prompt que escrevemos como embeddings, assim como todos os hiperparâmetros. Se tivermos um conjunto de dados preparado e aprovado para treinar e testar modelos de aprendizado de máquina, podemos fazer ajustes nas palavras de alerta e avaliar objetivamente seu desempenho. Recentemente vi uma postagem de Moritz Laurer, engenheiro de ML da HuggingFace[1]:
Cada vez que você testa um prompt diferente em seus dados, você fica menos certo se o LLM realmente generaliza para dados invisíveis... Usar uma divisão de validação separada para ajustar o hiperparâmetro principal dos LLMs (o prompt) é tão importante quanto train-val-test divisão para ajuste fino. A única diferença é que você não tem mais um conjunto de dados de treinamento e, de alguma forma, parece diferente porque não há treinamento/sem atualizações de parâmetros. É fácil se enganar e acreditar que um LLM tem um bom desempenho em sua tarefa, mas na verdade você superajustou o prompt em seus dados. Todo bom artigo “zeroshot” deve esclarecer que eles usaram uma divisão de validação para encontrar seu prompt antes do teste final.
À medida que testamos cada vez mais diferentes palavras de prompt (Prompts) nesses conjuntos de dados, ficaremos cada vez mais incertos se o LLM pode realmente generalizar para dados invisíveis... Isolar uma parte do conjunto de dados Definir como o conjunto de validação para ajustar os principais hiperparâmetros (Prompt) do LLM e use o método de divisão train-val-test (Nota do tradutor: divida o conjunto de dados disponível em três partes: conjunto de treinamento, conjunto de validação e conjunto de teste.) O ajuste fino é igualmente importante. A única diferença é que esse processo não envolve treinar o modelo (sem treinamento) ou atualizar os parâmetros do modelo (sem atualizações de parâmetros), mas apenas avaliar o desempenho de diferentes palavras de prompt no conjunto de validação. É fácil enganar-se e acreditar que o LLM tem um bom desempenho na tarefa alvo, quando na verdade as palavras-chave sintonizadas podem ter um desempenho muito bom neste conjunto de dados atual, mas podem não ter um bom desempenho em um conjunto de dados mais amplo ou invisível, não aplicável. Todo bom artigo "zeroshot" deve indicar claramente que usa um conjunto de validação para ajudar a encontrar os melhores prompts antes do teste final.
Depois de pensar um pouco, acho que a resposta está em algum lugar no meio. Se a engenharia imediata é uma ciência ou uma arte depende do que queremos que o LLM faça. Vimos o LLM fazer muitas coisas incríveis no ano passado, mas tendo a categorizar as intenções das pessoas ao usar modelos grandes em duas categorias amplas: resolver problemas e concluir tarefas criativas (criação).
No lado da resolução de problemas , temos LLMs resolvendo problemas matemáticos, classificando sentimentos, gerando instruções SQL, traduzindo texto e assim por diante. De um modo geral, acho que todas essas tarefas podem ser agrupadas, porque podem ter pares de entrada-saída relativamente claros (Nota do tradutor: A associação entre os dados de entrada e os dados de saída do modelo correspondente) (portanto, podemos ter visto muitos casos em que usando apenas um pequeno número de prompts pode realizar muito bem a tarefa desejada). Para esse tipo de tarefa com dados de treinamento bem definidos (Nota do tradutor: a relação entre entrada e saída no conjunto de dados de treinamento é clara e clara), a engenharia imediata parece mais uma ciência para mim. Portanto, a primeira metade deste artigo discutirá o Prompt como um hiperparâmetro , explorando especificamente o progresso da pesquisa da engenharia automatizada de prompts (Nota do tradutor: Usando métodos ou tecnologias automatizadas para projetar, otimizar e ajustar palavras de prompt).
Em termos de tarefas criativas , as tarefas exigidas do LLM são mais subjetivas e ambíguas. Escreva e-mails, relatórios, poemas, resumos. É aqui que encontramos mais ambiguidade – o conteúdo da escrita do ChatGPT é impessoal? (Com base nos milhares de artigos que escrevi sobre isso, minha opinião atual é sim) E, como muitas vezes nos falta um critério mais objetivo sobre como queremos que os LLMs respondam, a natureza e as demandas das tarefas criativas muitas vezes não são apropriadas. pensar em palavras-chave como parâmetros que podem ser ajustados e otimizados como hiperparâmetros.
Neste ponto, alguns podem dizer que para tarefas criativas só precisamos usar o bom senso. Para ser sincero, eu também pensava assim, até tentar ensinar minha mãe a usar o ChatGPT para ajudá-la a gerar e-mails de trabalho. Nesses casos, como a engenharia do Prompt ainda trata principalmente de melhorias por meio de experimentação e ajuste contínuos, em vez de uma conclusão única, como você pode usar suas próprias ideias para melhorar o Prompt e ainda manter a universalidade do Prompt (conforme mencionado na citação anterior? ), nem sempre é óbvio.
De qualquer forma, procurei uma ferramenta que pudesse melhorar automaticamente os prompts com base no feedback do usuário em exemplos gerados por modelos grandes, mas não encontrei nada. Portanto, construí um protótipo de tal ferramenta para explorar se existia uma solução viável. Posteriormente neste artigo, compartilharei com vocês uma ferramenta que experimentei que melhora automaticamente as palavras de prompt com base no feedback do usuário em tempo real.
01 Parte 1 - LLMs como solucionadores: trate a Prompt Engineering como parte da otimização de hiperparâmetros
Muitas pessoas na indústria estão familiarizadas com a famosa terminologia "Zero-Shot-COT" no artigo "Large Language Models are Zero-Shot Reasoners" [2] (Nota do tradutor: O modelo não aprendeu dados de treinamento explícitos para uma tarefa específica . Em seguida, resolva novos problemas combinando o conhecimento existente). Zhou et al. (2022) decidiram explorar mais no artigo "Grandes modelos de linguagem são engenheiros de prompt de nível humano" [3] Qual é sua versão melhorada? —— "Vamos resolver isso passo a passo para ter certeza de que temos a resposta certa". A seguir está uma visão geral do método do Automatic Prompt Engineer que eles propuseram:
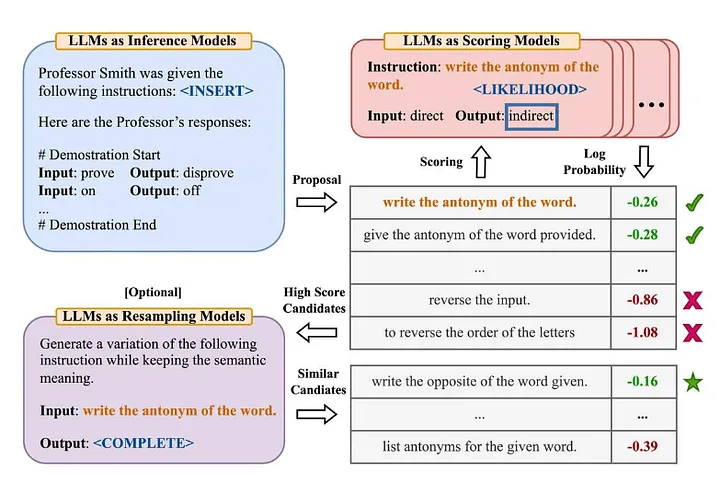
Fonte: Grandes modelos de linguagem são engenheiros de alerta de nível humano[3]
Para resumir este artigo:
- Use o LLM para gerar prompts de orientação de candidatos com base em determinados pares de entrada-saída (Nota do tradutor: a associação entre os dados de entrada e os dados de saída do modelo correspondentes).
- Use o LLM para pontuar cada prompt instrucional, seja com base em quão bem a resposta gerada usando a instrução corresponde à resposta esperada, ou com base na resposta do modelo obtida com a instrução para avaliar a probabilidade logarítmica.
- Novas palavras de prompt de orientação de candidato são geradas iterativamente com base em palavras de prompt de orientação de candidato de alta pontuação (instruções).
Algumas conclusões interessantes foram descobertas:
- Além de demonstrar o desempenho superior de (engenheiros de prompt humano) e algoritmos propostos anteriormente, os autores observam: “Contraintuitivamente, adicionar exemplos no contexto prejudica o desempenho do modelo… porque todas as palavras de instrução selecionadas se ajustam demais ao cenário de aprendizagem zero-shot e, portanto, têm desempenho ruim no caso de amostras pequenas (poucas fotos) .
- O efeito do algoritmo iterativo de Pesquisa de Monte Carlo (Pesquisa de Monte Carlo) enfraquecerá gradualmente na maioria dos casos, mas quando o espaço da proposta original (Nota do tradutor: pode referir-se ao algoritmo de Pesquisa de Monte Carlo, inicialmente usado para gerar candidatos. Ele funciona bem quando o o escopo inicial ou a solução do problema não é adequada ou suficientemente eficaz.
Então, em 2023, alguns pesquisadores do Google DeepMind lançaram um método chamado “Otimização por prompt (OPRO)”. Semelhante ao exemplo anterior, o meta-prompt contém uma série de pares de entrada/saída (Nota do tradutor: a entrada e as expectativas que descrevem uma tarefa específica ou combinação de saída de problema). A principal diferença aqui é que o meta-prompt também contém amostras de palavras de prompt previamente treinadas e suas respostas ou soluções corretas e a precisão com que o modelo respondeu a essas palavras de prompt, além de detalhar as diferenças entre as diferentes partes do meta-prompt. para relacionamentos.
Como explicam os autores, cada etapa de otimização de palavras-chave no trabalho de pesquisa gera novas palavras-chave, com o objetivo de referenciar trajetórias de aprendizagem anteriores para que o modelo possa compreender melhor a tarefa atual e produzir resultados de saída mais precisos.
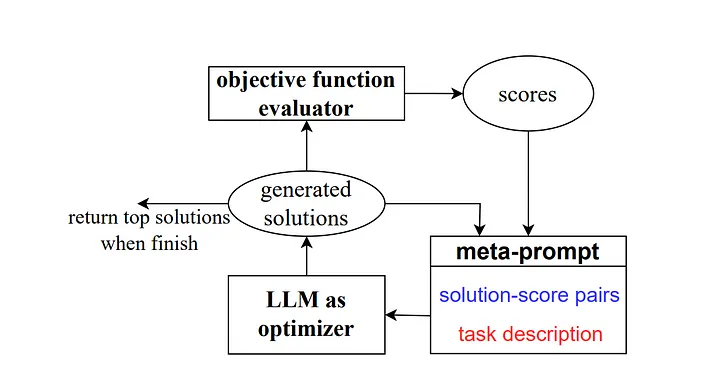
Fonte: Grandes modelos de linguagem como otimizadores[4]
Para o cenário Zero-Shot-COT, eles propuseram o método de otimização de palavras imediatas "Respire fundo e trabalhe neste problema passo a passo" e obtiveram bons resultados.
Eu tenho algumas idéias sobre isso:
- “Os estilos de instruções instrucionais geradas por diferentes tipos de modelos de linguagem variam muito. Alguns modelos, como PaLM 2-L-IT e text-bison, geram instruções instrucionais muito concisas e claras, enquanto outros, como as instruções do GPT, são longas e claras. bastante detalhado. "Isso merece nossa atenção. Atualmente, muitos métodos de engenharia de prompt no mercado são escritos usando o modelo de linguagem OpenAI como objeto de referência. No entanto, à medida que mais e mais modelos de diferentes fontes começam a ser usados, devemos prestar atenção a essas palavras comuns de engenharia que podem não funcionar. isso bem. Um exemplo é dado na Seção 5.2.3 do artigo, que demonstra a alta sensibilidade do desempenho do modelo a pequenas mudanças nas instruções. Precisamos prestar mais atenção a isso.
Por exemplo, ao usar o PaLM 2-L para avaliar o modelo no conjunto de testes GSM8K, a precisão de "Vamos pensar passo a passo" atingiu 71,8% e a precisão de "Vamos resolver o problema juntos" foi de 60,5%. enquanto as duas primeiras A combinação semântica de palavras de instrução, “Vamos trabalhar juntos para resolver este problema passo a passo, tem uma precisão de apenas 49,4%.
Esse comportamento aumenta tanto a variação entre as instruções de etapa única quanto as flutuações que ocorrem durante o processo de otimização, levando-nos a gerar múltiplas instruções de etapa única em cada etapa para melhorar a estabilidade do processo de otimização.
Outro ponto importante é mencionado na conclusão do artigo: "Uma limitação de nossa aplicação atual de algoritmos para problemas do mundo real é que os grandes modelos de linguagem usados para otimizar palavras-chave não exploram efetivamente os casos errôneos no conjunto de treinamento para inferir promissor No experimento, tentamos adicionar casos de erro que ocorreram quando o modelo foi treinado ou testado no meta-prompt, em vez de amostragem aleatória do conjunto de treinamento em cada etapa de otimização, mas os resultados foram semelhantes, o que mostrou que apenas O A quantidade de informações nesses casos de erro não é suficiente para que o otimizador LLM (um grande modelo de linguagem usado para otimizar palavras de prompt) entenda as razões para as previsões incorretas "Isso realmente vale a pena enfatizar, porque embora esses métodos forneçam fortes evidências do erro. processo de otimização de palavras de prompt. Semelhante ao processo de otimização de hiperparâmetros em ML/AI tradicional, mas tendemos a preferir usar exemplos positivos, seja que tipo de entrada de conteúdo queremos fornecer ao LLM ou como orientamos o LLM para. melhorar as palavras imediatas. No entanto, em ML/IA tradicional, esta preferência geralmente não é tão óbvia, e nos concentramos mais em como usar as informações de erro para otimizar o modelo, em vez de prestar muita atenção à direção ou tipo do erro em si (ou seja, nos concentramos em erros -5 e +5 são geralmente tratados igualmente).
Se você estiver interessado em APE (Automated Prompt Engineering), você pode acessar https://github.com/keirp/automatic_prompt_engineer para fazer o download e usá-lo.
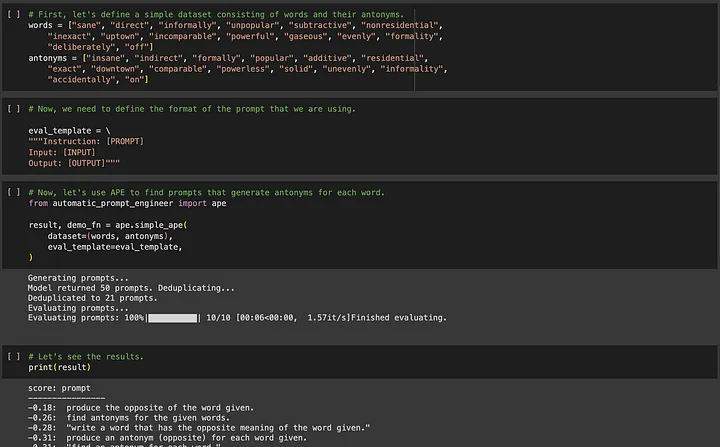
Fonte: Captura de tela do exemplo de notebook para APE[5]
Um requisito fundamental em ambos os métodos, APE e OPRO, é que é necessário que haja dados de treinamento para ajudar na otimização, e o conjunto de dados precisa ser grande o suficiente para garantir a universalidade das palavras-chave otimizadas.
Agora, quero falar sobre outro tipo de tarefa de LLM onde podemos não ter dados prontamente disponíveis.
02 Parte 2 - LLMs como Criadores: Pense na Prompt Engineering como um processo de melhoria incremental por meio de tentativas e ajustes constantes
Suponhamos que agora inventássemos alguns contos.
Simplesmente não temos exemplos de textos novos para treinar o modelo e demoraria muito para escrever alguns exemplos de textos novos qualificados. Além disso, não está claro para mim se faz sentido que um modelo grande produza uma resposta "chamada correta", uma vez que pode haver muitos tipos de resultados de modelo que são aceitáveis. Portanto, para este tipo de tarefa, é quase impraticável utilizar métodos como o APE para automatizar a engenharia de palavras imediatas.
No entanto, alguns leitores podem se perguntar: por que precisamos automatizar o processo de escrita de palavras imediatas? Você pode começar com qualquer palavra simples, como "forneça-me três ideias de contos sobre {{issue}} em {{country}}", preencha {{problema}} com "desigualdade", substitua {{país}} por "Singapura" e observe o modelo Responda aos resultados, descubra problemas, ajuste as palavras de alerta e, em seguida, observe se o ajuste é eficaz e repita esse processo.
Mas, neste caso, quem se beneficiará mais com a engenharia de palavras-chave? São precisamente aqueles iniciantes que não têm experiência em escrever palavras de alerta. Eles não têm experiência suficiente para ajustar e melhorar as palavras de alerta fornecidas ao modelo . Experimentei isso em primeira mão quando ensinei minha mãe a usar o ChatGPT para realizar tarefas de trabalho.
Minha mãe pode não ser muito boa em canalizar sua insatisfação com o resultado do ChatGPT para melhorias adicionais nas palavras imediatas, mas percebi que não importa quão boas sejam nossas habilidades de engenharia de palavras rápidas, somos realmente bons em articular os problemas que veja (ou seja, a capacidade de reclamar). Portanto, tentei construir uma ferramenta para ajudar os usuários a expressar suas reclamações e deixar que o LLM melhorasse as palavras imediatas para nós. Para mim, esta parece ser uma forma mais natural de interagir e parece tornar mais fácil para aqueles de nós que tentam usar o LLM para tarefas criativas.
Deve ser dito antecipadamente que esta é apenas uma prova de conceito, portanto, se os leitores tiverem boas ideias, sinta-se à vontade para compartilhá-las com o autor!
Primeiro, escreva a palavra do prompt com variáveis {{}}. A ferramenta detectará esses espaços reservados para preenchermos mais tarde, novamente usando o exemplo acima, pedindo ao modelo grande que produza algumas histórias criativas sobre a desigualdade em Singapura.
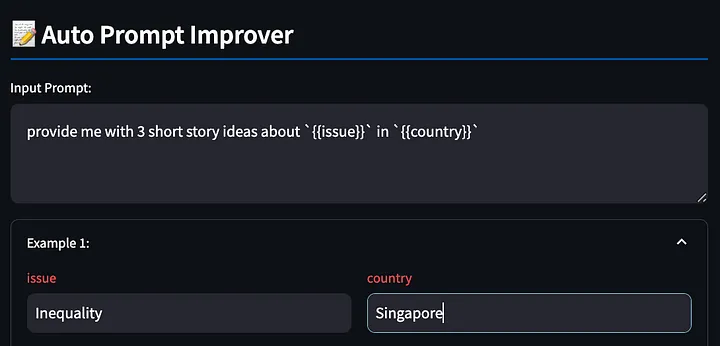
Em seguida, a ferramenta gera uma resposta modelo com base nas palavras do prompt preenchidas.

Em seguida, dê nosso feedback (reclamações sobre o resultado do modelo):
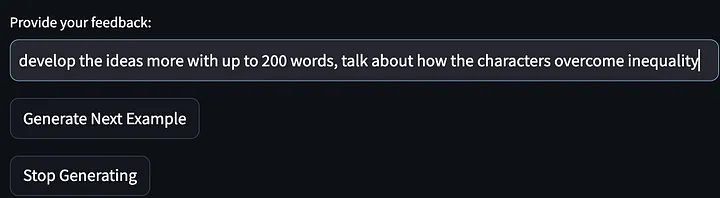
O modelo foi então solicitado a parar de gerar mais exemplos de ideias para histórias e produzir palavras-chave que melhoraram desde a primeira iteração. Observe que as instruções fornecidas abaixo foram refinadas e generalizadas para exigir "descrever as estratégias...para superar ou se envolver com esses desafios". E meu feedback sobre o primeiro resultado do modelo foi “falar sobre como o protagonista da história resolve a desigualdade”.

Pedimos então ao modelo grande que concebesse o conto novamente, usando as palavras-chave modificadas.
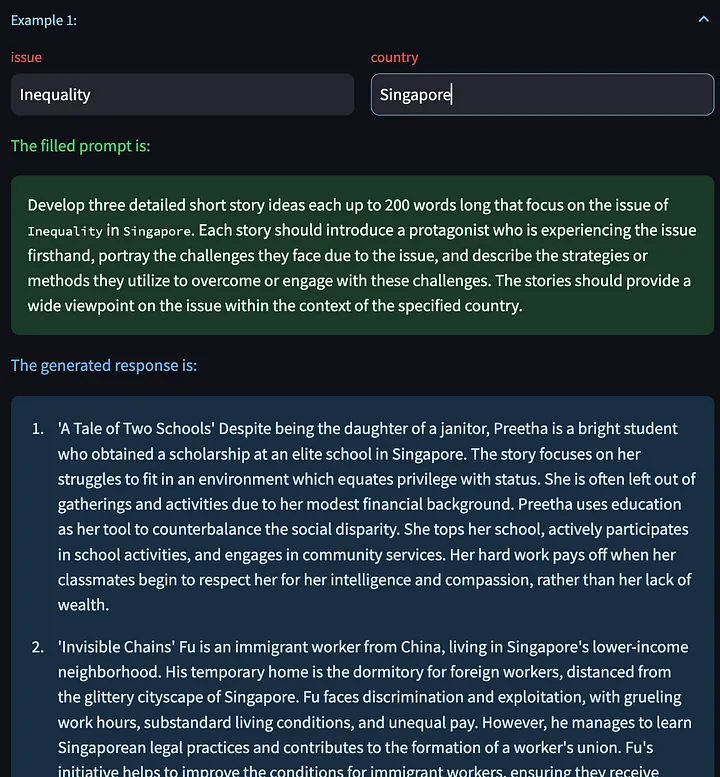
Também temos a opção de clicar em “Gerar próximo exemplo”, o que nos permite gerar uma nova resposta de modelo com base em outras variáveis de entrada. Aqui estão algumas histórias criativas geradas sobre o problema das demissões na China:
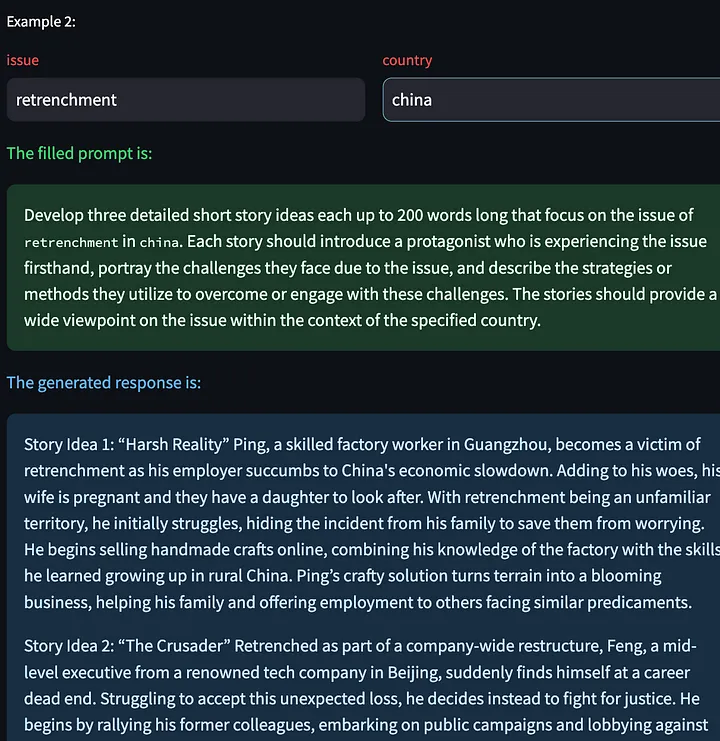
Em seguida, dê feedback sobre o resultado do modelo acima:
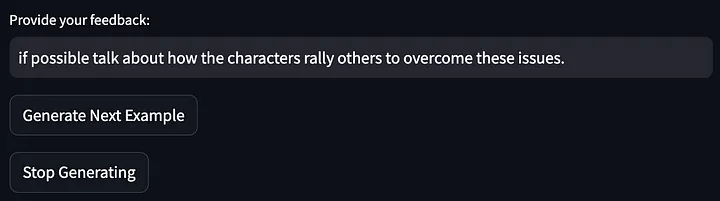
Em seguida, as palavras de alerta foram otimizadas ainda mais:

Os resultados da otimização desta vez parecem muito bons. Afinal, no início era apenas uma palavra de prompt simples. Depois de menos de dois minutos de feedback (embora um tanto casual), a palavra de prompt otimizada foi obtida após três iterações. Agora, podemos continuar a otimizar as palavras de alerta simplesmente sentando e expressando insatisfação com o resultado do LLM.
A implementação interna desta função é começar a partir do meta-prompt e otimizar e gerar continuamente novas palavras de prompt com base no feedback dinâmico do usuário. Não é nada sofisticado e definitivamente há espaço para melhorias adicionais, mas é um bom começo.
prompt_improvement_prompt = """
# Context #
You are given an original prompt.
The original prompt was used to generate some example responses. For each response, feedback was provided on how to improve the desired response.
Your task is to review all the feedback and then return an improved prompt that addresses the feedback, making it better at generating responses when prompted against the GPT language model.
# Guidelines #
- The original prompt will contain placeholders within double curly brackets. These are values for input that you will see in the examples.
- The improved prompt should not exceed 200 words
- Just return the improved prompt and nothing else before and after. Remember to include the same placeholders with double curly brackets.
- When generating the improved prompt, refrain from writing the entire prompt as one paragraph. Instead, you should use a combination of task descriptions, guidelines (in point form), and other sections to the prompt as appropriate.
- The guidelines should be in point form, and should not be a repetition of the task. The guidelines should also be distinct from one another.
- The improved prompt should be written in normal English that is best understood by the language model.
- Based on the feedback provided, you must rephrase the desired behavior of the response into `must`, imperative statements, instead of `should` suggestive statements.
- Improvements made to the prompt should not be overly specific to one single example.
# Details #
The original prompt is:
```
{original_prompt}
```
These are the examples that were provided and the feedback for each:
```
{examples}
```
The improved prompt is:
```
"""
Algumas observações ao usar esta ferramenta:
- GPT4 tende a usar um grande número de palavras ao gerar texto (o recurso “poliglota”). Por esta razão, pode haver dois efeitos. Primeiro, esta propriedade "detalhada" pode encorajar o ajuste excessivo a exemplos específicos . ** Se o LLM receber muitas palavras, ele as usará para corrigir feedback específico fornecido pelo usuário. Em segundo lugar, esta característica “verbal” pode prejudicar a eficácia das palavras de estímulo, especialmente em palavras de estímulo longas, algumas informações orientadoras importantes podem ser obscurecidas. Acho que o primeiro problema pode ser resolvido escrevendo bons meta-prompts para encorajar o modelo a generalizar com base no feedback do usuário. Mas o segundo problema é mais difícil. Em outros casos de uso, os prompts instrutivos são frequentemente ignorados quando a palavra do prompt é muito longa. Podemos adicionar algumas restrições ao meta-prompt (como limitar o número de palavras no exemplo do prompt fornecido acima) , mas isso é realmente arbitrário e algumas restrições ou regras nas palavras do prompt podem ser afetadas pelo grande modelo subjacente. O impacto de um atributo ou comportamento específico.
- Palavras de prompt aprimoradas às vezes esquecem as otimizações anteriores da palavra de prompt. Uma maneira de resolver esse problema é fornecer ao sistema um histórico de melhorias mais longo, mas isso faz com que as palavras dos prompts de melhoria se tornem muito longas.
- Uma vantagem desta abordagem na primeira iteração é que o LLM pode fornecer orientação para melhorias que não fazem parte do feedback do utilizador. Por exemplo, na otimização da primeira palavra acima, a ferramenta adicionou “Fornecer uma perspectiva mais ampla sobre o assunto discutido…” embora eu tenha fornecido Feedback é simplesmente uma solicitação de estatísticas relevantes de fontes confiáveis.
Ainda não implantei essa ferramenta porque ainda estou trabalhando no meta-prompt para ver o que funciona melhor e contornar alguns dos problemas da estrutura streamlit e, em seguida, lidar com outros erros ou exceções que possam surgir no programa. Mas a ferramenta deve estar disponível em breve!
03 Em conclusão
Todo o campo da engenharia de alertas se concentra em fornecer as melhores palavras de alerta para a resolução de tarefas. APE e OPRO são os exemplos mais importantes e notáveis neste campo, mas não representam todos. Estamos entusiasmados e ansiosos pelo progresso que poderemos fazer neste campo no futuro. Avaliar os efeitos dessas técnicas em diferentes modelos pode revelar as tendências ou características de funcionamento desses modelos e também pode nos ajudar a entender quais técnicas de meta-prompt são eficazes. Portanto, acho que essas são tarefas muito importantes que nos ajudarão a usar o LLM. em nossa prática diária de produção.
No entanto, estes métodos podem não ser adequados para outras pessoas que desejam usar o LLM para tarefas criativas. Por enquanto, existem muitos manuais de aprendizagem que podem nos ajudar a começar, mas nada se compara à tentativa e erro. Portanto, no curto prazo, acho que o mais valioso é como podemos concluir com eficiência esse processo experimental que está alinhado com nossos pontos fortes humanos (dar feedback) e deixar o LLM fazer o resto (melhorar as palavras de alerta).
Também irei trabalhar mais no meu POC (Prova de Conceito). Se você estiver interessado nisso, entre em contato comigo ( https://www.linkedin.com/in/ianhojy/) !
Obrigado por ler!
FIM
Referências
[1] https://www.linkedin.com/in/moritz-laurer/?originalSubdomain=de
[2] https://arxiv.org/pdf/2205.11916.pdf
[3] https://arxiv.org/pdf/2211.01910.pdf
[4] https://arxiv.org/pdf/2309.03409.pdf
[5] https://github.com/keirp/automatic_prompt_engineer
[6] https://arxiv.org/abs/2104.08691
[7] https://medium.com/mantisnlp/automatic-prompt-engineering-part-i-main-concepts-73f94846cacb
[8] https://www.promptingguide.ai/techniques/ape
Este artigo foi compilado por Baihai IDP com a autorização do autor original. Caso necessite reimprimir a tradução, entre em contato conosco para autorização.
Links originais:
https://towardsdatascience.com/automated-prompt-engineering-78678c6371b9
Decidi desistir do código aberto Hongmeng Wang Chenglu, o pai do código aberto Hongmeng: Hongmeng de código aberto é o único evento de software industrial de inovação arquitetônica na área de software básico na China - o OGG 1.0 é lançado, a Huawei contribui com todo o código-fonte. Google Reader é morto pela "montanha de merda de código" Fedora Linux 40 é lançado oficialmente Ex-desenvolvedor da Microsoft: o desempenho do Windows 11 é "ridiculamente ruim" Ma Huateng e Zhou Hongyi apertam as mãos para "eliminar rancores" Empresas de jogos conhecidas emitiram novos regulamentos : os presentes de casamento dos funcionários não devem exceder 100.000 yuans Ubuntu 24.04 LTS lançado oficialmente Pinduoduo foi condenado por concorrência desleal Compensação de 5 milhões de yuans