
Este artigo é compartilhado da comunidade Huawei Cloud " Prática de construção de sistemas altamente disponíveis com Huawei Cloud FunctionGraph " por Xiaozhi, Huawei Cloud PaaS Service.
Introdução
Todos os anos, surgem relatos na Internet de que o sistema XXX está anormalmente indisponível, causando enormes perdas económicas aos clientes. Os serviços em nuvem têm uma base de clientes maior. Quando surgirem problemas, eles terão um grande impacto nos clientes e no próprio serviço. Com base nas próprias práticas do Huawei Cloud FunctionGraph, este artigo apresentará em detalhes como construir uma plataforma de computação sem servidor altamente disponível para alcançar uma situação ganha-ganha tanto para os clientes quanto para a plataforma.
Introdução à alta disponibilidade
Alta disponibilidade [1] (inglês: alta disponibilidade, abreviado como HA), um termo de TI , refere-se à capacidade do sistema de executar suas funções sem interrupção, representando a disponibilidade do sistema . É um dos critérios ao projetar um sistema.
A indústria geralmente utiliza indicadores de SLA para medir a disponibilidade do sistema.
Acordo de nível de serviço [2] (inglês: acordo de nível de serviço, abreviatura SLA), também conhecido como acordo de nível de serviço, acordo de nível de serviço, é um compromisso formal definido entre um provedor de serviços e um cliente . O prestador de serviços e o cliente atendido atingiram especificamente os indicadores de serviço prometidos – qualidade, disponibilidade e responsabilidade. Por exemplo, se o provedor de serviços prometer um SLA de 99,99%, o tempo máximo anual de falha do serviço será de 5,26 minutos (365*24*60*0,001%).
FunctionGraph mede intuitivamente os dois indicadores dourados de disponibilidade do sistema, SLI e latência é o indicador da taxa de sucesso de solicitações do sistema, e latência é o desempenho do processamento do sistema.
Desafios de alta disponibilidade
Como um subserviço na Huawei Cloud, o FunctionGraph deve considerar não apenas a robustez do próprio sistema, mas também a robustez dos serviços dependentes circundantes enquanto constrói suas próprias capacidades (por exemplo, o serviço de autenticação de identidade dependente está indisponível, o gateway para encaminhamento de tráfego O serviço de serviço está inativo, o acesso do serviço ao objeto de armazenamento falha, etc.). Além disso, quando os recursos de hardware dos quais o sistema depende falham ou o sistema é subitamente atacado por tráfego, etc., enfrentando esses cenários anormais incontroláveis, é um grande desafio para o sistema construir suas próprias capacidades para manter a alta disponibilidade do negócio. A Figura 1 mostra as interações periféricas do FunctionGraph.

Figura 1 Interação periférica do FunctionGraph
Para problemas comuns, foram classificadas quatro categorias principais, conforme mostrado na Tabela 1.
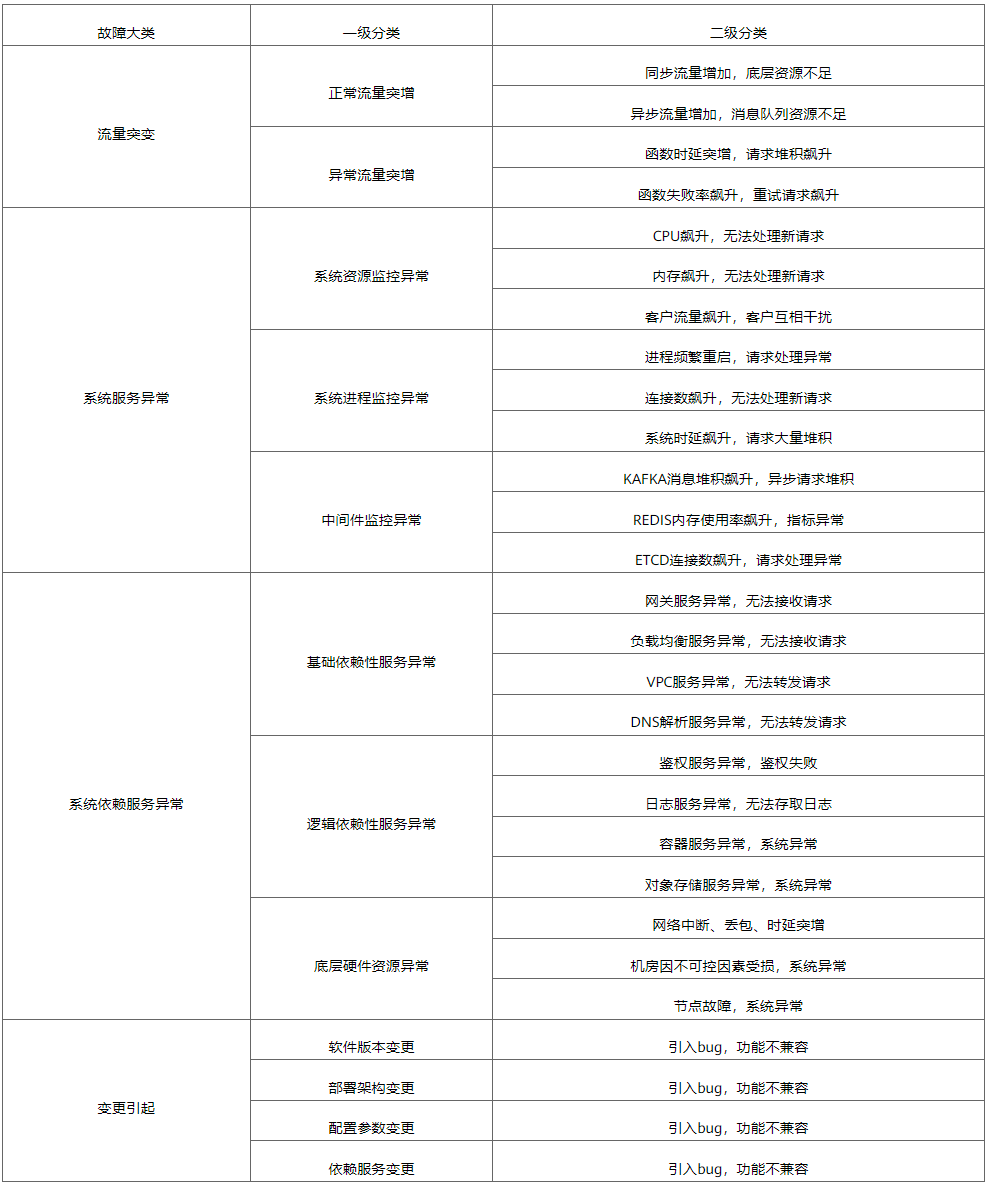
Tabela 1 Resumo das perguntas frequentes no FunctionGraph
Em resposta a estes problemas, resumimos os seguintes métodos gerais de governação:
- Gerenciamento de mutação de tráfego: proteção contra sobrecarga + expansão e contração elástica + disjuntor + corte de pico assíncrono + monitoramento e alarme Com base no conceito de design defensivo, proteção contra sobrecarga + disjuntor garante que todos os recursos do sistema estejam sob controle, e então sobre isso. base, ele fornece a capacidade de expansão máxima para atender a grandes tráfegos, cenários de clientes adequados recomendam redução de pico assíncrona para reduzir a pressão do sistema e monitoramento de alarmes para detectar problemas de sobrecarga em tempo hábil.
- Gerenciamento de exceções de serviço do sistema: arquitetura de recuperação de desastres + nova tentativa + isolamento + monitoramento e alarmes A arquitetura de recuperação de desastres evita todo o tempo de inatividade do sistema e reduz o impacto das anormalidades do sistema nos negócios do cliente. descubra rapidamente anomalias no serviço do sistema por meio de alarmes de monitoramento.
- Gerenciamento de exceções de serviço dependente do sistema: arquitetura de recuperação de desastres + downgrade de cache + monitoramento e alarmes A arquitetura de recuperação de desastres reduz pontos únicos de falha em serviços dependentes. O downgrade de cache garante que o sistema ainda possa funcionar normalmente após falhas de serviço dependentes. detectar exceções de serviço dependentes.
- Governança causada por mudanças: atualização em escala de cinza + controle de processo + monitoramento e alarme Por meio da atualização em escala de cinza, podemos evitar falhas globais causadas por atualizações anormais do sistema para clientes formais. Por meio do controle de processo, podemos minimizar o risco de mudanças humanas. mudanças após mudanças através de monitoramento e falha alarmante.
Prática de design do sistema FunctionGraph
Para resolver os problemas da Tabela 1, o FunctionGraph otimizou muitos aspectos, como recuperação de desastres arquitetônicos, controle de fluxo, novas tentativas, cache, atualização em escala de cinza, monitoramento e alarmes e processos de gerenciamento, e sua usabilidade foi bastante melhorada. A seguir, apresentamos principalmente algumas práticas de design orientadas a exceções do FunctionGraph e, por enquanto, não expandimos os recursos elásticos, funções do sistema, etc.
Arquitetura de recuperação de desastres
Para implementar a arquitetura Huawei Cloud Disaster Recovery 1.1 (por exemplo: domínio de falha de nível AZ de serviço, capacidade de autocura de cluster cross-AZ, isolamento de dependência de serviço de nível AZ), vários conjuntos de plano de gerenciamento FunctionGraph e clusters de plano de dados são implantados e cada conjunto dos clusters são isolados de AZ para alcançar a mesma região de recuperação de desastres. Conforme mostrado na Figura 2, o FunctionGraph implanta vários conjuntos de clusters de plano de dados (para realizar a função FunctionGraph executando negócios) e clusters de agendamento de despachantes (para realizar as tarefas de agendamento de cluster de tráfego do FunctionGraph) para aumentar a capacidade do sistema e a recuperação de desastres. Quando um dos clusters Yuanrong está anormal, o componente de agendamento do despachante pode remover imediatamente o cluster defeituoso e distribuir o tráfego para vários outros clusters.

Figura 2 Diagrama de arquitetura simples do FunctionGraph
O design de arquitetura descentralizada distribuída suporta expansão e contração horizontal flexível
Esta estratégia é a chave para a concepção de serviços lógicos de multilocação. Ela precisa resolver o problema de reequilíbrio após a descentralização e a expansão e contração de componentes.
Descentralização do gerenciamento de dados estáticos: Os metadados dos serviços lógicos multilocatários podem ser todos armazenados no mesmo conjunto de middleware devido à pequena quantidade no estágio inicial. À medida que os clientes aumentam o seu volume, é necessário conceber um plano de divisão de dados para suportar a fragmentação de dados e lidar com a subsequente leitura e escrita massiva de dados, bem como com a pressão de fiabilidade.
Descentralização da função de agendamento de tráfego: O design da função do componente suporta a descentralização (dependências centralizadas comuns: bloqueios, valores de controle de fluxo, tarefas de agendamento, etc.). Após o aumento do tráfego, o número de cópias do componente pode ser expandido. estratégia de equilíbrio. Recarga completa do tráfego.
Estratégia de controle de fluxo multidimensional
Antes que o tráfego da função cliente no FunctionGraph finalmente atinja o tempo de execução, ele passará por vários links e cada link poderá ter tráfego excedendo seu limite de transporte. Portanto, para garantir a estabilidade de cada link, o FunctionGraph adiciona defensivamente diferentes estratégias de controle de fluxo em cada link. Os princípios básicos abordam o isolamento de recursos na granularidade da função em computação (CPU), armazenamento (disco, E/S de disco) e rede (conexão HTTP, largura de banda).
O tráfego da função é acionado no lado do cliente e o controle de fluxo do link que finalmente é executado é mostrado na Figura 3.

Figura 3 Controle de fluxo do FunctionGraph
Controle de fluxo APIG do gateway
APIG é a entrada de tráfego do FunctionGraph. Ele suporta controle total de tráfego no nível da região e pode ser expandido de forma flexível de acordo com a atividade comercial da região. Ao mesmo tempo, o APIG oferece suporte ao controle de tráfego no nível do cliente. Quando o tráfego anormal do cliente é detectado, o tráfego do cliente pode ser rapidamente restringido pelo lado do APIG para reduzir o impacto de clientes individuais na estabilidade do sistema.
Controle de fluxo de negócios do sistema
Controle de fluxo no nível da API
Depois que o tráfego do cliente passa pela APIG, ele vai para o lado do sistema do FunctionGraph. Com base no cenário em que o controle de fluxo APIG falha, o FunctionGraph constrói sua própria estratégia de controle de fluxo. Atualmente, há suporte para controle de fluxo em nível de nó, controle de fluxo total de API do cliente e controle de fluxo em nível de função. Quando o tráfego do cliente excede a capacidade de carga do FunctionGraph, o sistema o rejeita diretamente e retorna 429 ao cliente.
Controle de fluxo de recursos do sistema
FunctionGraph é um serviço lógico de multilocação. Os recursos do plano de controle e do plano de dados são compartilhados pelos clientes quando ataques maliciosos de clientes ilegais causam instabilidade do sistema. FunctionGraph implementa controle de fluxo de clientes com base no número de solicitações simultâneas de recursos compartilhados, limitando estritamente os recursos disponíveis aos clientes. Além disso, o agrupamento de recursos partilhados garante que a quantidade total de recursos partilhados seja controlável, garantindo assim a disponibilidade do sistema. Por exemplo: pool de conexões http, pool de memória, pool de corrotinas.
Controle de simultaneidade: Construa uma estratégia de controle de fluxo baseada na granularidade da função FunctionGraph com base no número de solicitações simultâneas. O tempo de execução da função cliente do FunctionGraph tem vários tipos, como milissegundos, segundos, minutos, horas, etc. o segundo é o processamento. Solicitações executadas por períodos de tempo extremamente longos apresentam deficiências inerentes e não podem limitar os recursos compartilhados do sistema ocupados pelos clientes ao mesmo tempo. A estratégia de controle baseada no número de simultaneidade limita estritamente o número de solicitações ao mesmo tempo. Se o número de solicitações exceder o número, ele será rejeitado diretamente para proteger os recursos compartilhados do sistema.
Conjunto de conexões http: ao construir serviços de alta simultaneidade, manter razoavelmente o número de conexões http longas pode minimizar o tempo de sobrecarga de recursos das conexões http, ao mesmo tempo que garante que o número de recursos de conexão http seja controlável, garantindo a segurança do sistema e melhorando o desempenho do sistema. A indústria pode referir-se à reutilização de conexões http2 e à implementação do pool de conexões dentro do fasthttp. Os princípios são minimizar o número de http e reutilizar os recursos existentes.
Conjunto de memória: em cenários em que as mensagens de solicitação e resposta do cliente são particularmente grandes e a simultaneidade é particularmente alta, a memória do sistema ocupada por unidade de tempo é grande. Quando o limite é excedido, pode facilmente causar estouro de memória do sistema e fazer com que o sistema seja reiniciado. . Com base neste cenário, o FunctionGraph adicionou controle unificado do pool de memória. Na entrada da solicitação e na saída da resposta, ele verifica se a mensagem de solicitação do cliente excede o limite para proteger a memória do sistema e controlá-la.
Pool de corrotinas: FunctionGraph é construído em uma plataforma nativa da nuvem e usa a linguagem go. Se cada solicitação usar uma corrotina para processar logs e indicadores, quando vierem grandes solicitações simultâneas, um grande número de corrotinas será executado simultaneamente, causando um declínio significativo no desempenho geral do sistema. FunctionGraph introduz o pool de corrotinas do go e transforma tarefas de processamento de log e indicadores em tarefas de trabalho individuais e as envia ao pool de corrotinas. Em seguida, o pool de corrotinas as trata uniformemente, o que alivia bastante o problema de explosão de corrotinas.
Controle de taxa de consumo assíncrono: quando uma função assíncrona é chamada, ela será colocada primeiro no Kafka do FunctionGraph. Ao definir razoavelmente a taxa de consumo de Kafka do cliente, ela garante que as instâncias de função sejam sempre suficientes e evita que chamadas de função excessivas causem o colapso dos recursos subjacentes. ser consumido rapidamente.
Controle de instância de função
- Cota de instância do cliente: Ao limitar a cota total do cliente, evitamos que clientes mal-intencionados consumam todos os recursos subjacentes para garantir a estabilidade do sistema. Quando o negócio do cliente realmente precisa, a cota do cliente pode ser rapidamente expandida solicitando uma ordem de serviço.
- Cota de instância de função: Ao limitar a cota de função, a função de um único cliente pode ser impedida de consumir todas as instâncias do cliente. Também pode evitar que a cota do cliente se torne inválida e cause um grande consumo de recursos em um curto período de tempo. Além disso, se o negócio do cliente envolver o uso de middleware, como bancos de dados e redis, o número de conexões de middleware do cliente poderá ser protegido dentro de um intervalo controlável por meio de restrições de cota de instância de função.
Capacidades eficientes de elasticidade de recursos
O controle de fluxo é um conceito de projeto defensivo que reduz o risco de sobrecarga do sistema por meio de bloqueio antecipado. Quando o negócio normal de um cliente aumenta repentinamente e requer uma grande quantidade de recursos, a primeira coisa a resolver é o problema de elasticidade de recursos. Com a premissa de garantir o sucesso do negócio do cliente, estratégias de controle de fluxo podem ser usadas para cobrir anormalidades do sistema e prevenir. a propagação de explosões. FunctionGraph oferece suporte a vários recursos elásticos, como elasticidade rápida de nós de cluster, elasticidade rápida de instâncias de função do cliente e elasticidade de previsão inteligente de instâncias de função do cliente, garantindo que o FunctionGraph ainda possa ser usado normalmente quando os negócios do cliente aumentarem repentinamente.
Estratégia de nova tentativa
Ao projetar uma estratégia de repetição com benefícios apropriados, o FunctionGraph pode garantir que a solicitação do cliente seja executada com êxito quando ocorrer uma exceção. Conforme mostrado na Figura 4, a estratégia de nova tentativa deve ter condições de terminação, caso contrário causará uma tempestade de novas tentativas e romperá mais facilmente o limite de carga do sistema.

Figura 4 Estratégia de nova tentativa
A solicitação de função falhou na nova tentativa
- Solicitação síncrona: quando um cliente solicita a execução e encontra um erro de sistema, o FunctionGraph encaminhará a solicitação para outros clusters e tentará novamente até 3 vezes para garantir que a solicitação do cliente possa ser executada em outros clusters, mesmo que encontre exceções ocasionais de cluster.
- Solicitações assíncronas: como as funções assíncronas não possuem altos requisitos em tempo real, após a falha na execução da função do cliente, o sistema pode implementar uma estratégia de repetição mais refinada para solicitações com falha. Atualmente, o FunctionGraph suporta novas tentativas de espera exponencial binária. Quando uma função termina de forma anormal devido a um erro do sistema, a função recua exponencialmente de acordo com o método de 2, 4, 8 e 16. Quando o intervalo diminui para 20 minutos, as tentativas subsequentes. será baseado em 20 minutos. O tempo de repetição da solicitação de função é realizado em intervalos. O tempo de repetição da solicitação de função suporta no máximo 6 horas, será processado como uma solicitação com falha e retornado ao cliente. Através da retirada exponencial binária, a estabilidade dos negócios do cliente pode ser garantida ao máximo.
Novas tentativas entre serviços dependentes
- Mecanismo de nova tentativa de middleware: Tomando o redis como exemplo, quando o sistema falha ao ler e escrever redis ocasionalmente, ele irá dormir por um período de tempo e, em seguida, repetirá as operações de leitura e gravação do redis, com um número máximo de novas tentativas de 3 vezes.
- Mecanismo de nova tentativa de solicitação http: Quando erros como eof e io timeout ocorrem em uma solicitação http devido a flutuações na rede, ele irá dormir por um período de tempo e repetir a operação de envio http, com um número máximo de tentativas de 3 vezes.
esconderijo
O cache pode não apenas acelerar o acesso aos dados, mas também usar dados armazenados em cache para garantir a disponibilidade do sistema quando os serviços dependentes falharem. Divididos em categorias funcionais, existem dois tipos de componentes que o FunctionGraph precisa armazenar em cache. O primeiro é o middleware e o segundo são os serviços de nuvem dependentes. O sistema dá prioridade ao acesso aos dados armazenados em cache e, ao mesmo tempo, atualiza regularmente os dados armazenados em cache locais. middleware e serviços de nuvem dependentes. O método é mostrado na Figura 5.
- Dados de middleware de cache: FunctionGraph monitora alterações nos dados de middleware e os atualiza no cache local em tempo hábil por meio de publicação e assinatura. Quando o middleware está anormal, o cache local pode continuar a ser usado para manter a estabilidade do sistema.
- Dados de serviço dependentes de chave de cache: Tomemos como exemplo o serviço de autenticação de identidade da Huawei Cloud, o FunctionGraph dependerá fortemente do IAM. Quando o cliente iniciar a primeira solicitação, o sistema armazenará o token em cache localmente com um tempo de expiração de 24 horas. ativado, ele não será afetado. Utilização do sistema FunctionGraph. Outros serviços importantes em nuvem dependem da prática de armazenar temporariamente dados importantes em cache na memória local.

Figura 5 Medidas de cache do FunctionGraph
fusível
As medidas acima podem garantir o bom funcionamento dos negócios do cliente. No entanto, quando os negócios do cliente são anormais e não podem ser recuperados ou clientes mal-intencionados continuam a atacar a plataforma FunctionGraph, os recursos do sistema serão desperdiçados em tráfego anormal, ocupando os recursos dos clientes normais. , e o sistema também pode falhar após operação contínua de alta carga com tráfego anormal. Para este cenário, o FunctionGraph construiu sua própria estratégia de disjuntor com base no modelo de volume de chamada de função. Conforme mostrado na Figura 6, os disjuntores multinível são implementados com base na taxa de falha do volume de chamadas para garantir a tranquilidade dos negócios do cliente e a estabilidade do sistema.

Figura 6 Modelo de estratégia de disjuntor
isolamento
- Isolamento de negócios de função assíncrona: De acordo com a categoria de solicitações assíncronas, o FunctionGraph divide os grupos de consumidores do Kafka em grupos de consumidores de gatilho cronometrado, grupos de consumidores exclusivos, grupos de consumidores gerais e grupos de consumidores de repetição de mensagens assíncronas. Os tópicos também são divididos em categorias de pares da mesma maneira. . Ao subdividir grupos e tópicos de consumidores, isolar serviços de acionamento programados de serviços de alto tráfego e isolar serviços normais de serviços de solicitação de nova tentativa, as solicitações de atendimento ao cliente são garantidas com a mais alta prioridade.
- Isolamento seguro de contêineres: os contêineres CCE tradicionais são isolados com base em cgroups. Quando o número de clientes aumenta e o número de chamadas de clientes aumenta, ocasionalmente ocorrerá interferência mútua entre os clientes. Através de contêineres seguros, o isolamento no nível da máquina virtual pode ser alcançado para que os serviços ao cliente não interfiram uns com os outros.
Serviço lógico de multilocação, uma vez que haja um problema com a atualização, o impacto será incontrolável. FunctionGraph suporta atualizações de anel (divididas de acordo com o risco do negócio na região), lançamento azul-verde e estratégias de lançamento canário. A ação de atualização é brevemente descrita em três etapas:
- Isolamento de tráfego do cluster antes da atualização: Quando o FunctionGraph atual é atualizado, é dada prioridade ao isolamento do tráfego do cluster atualizado para garantir que novo tráfego não entre no cluster atualizado;
- Migração de tráfego e saída normal do cluster antes da atualização: migre o tráfego para outros clusters e execute a operação de atualização após a solicitação para atualizar o cluster sair normalmente.
- O cluster atualizado oferece suporte à migração de tráfego por cliente: Após a conclusão da atualização, o tráfego dos clientes de teste dial-up será encaminhado para o cluster atualizado. Depois que todos os casos de uso de teste dial-up forem executados com sucesso, o tráfego dos clientes oficiais será. mudou-se.
Quando ocorre um erro no FunctionGraph que não pode ser evitado pelo sistema, nossa solução é criar recursos de monitoramento e alarme para descobrir rapidamente pontos anormais, recuperar-se de falhas no nível minuto e minimizar o tempo de interrupção do sistema. Como última linha de defesa para a alta disponibilidade do sistema, a capacidade de detectar problemas rapidamente é crucial. O FunctionGraph construiu vários pontos de alarme em torno dos caminhos críticos do negócio. Conforme mostrado na tabela 2.
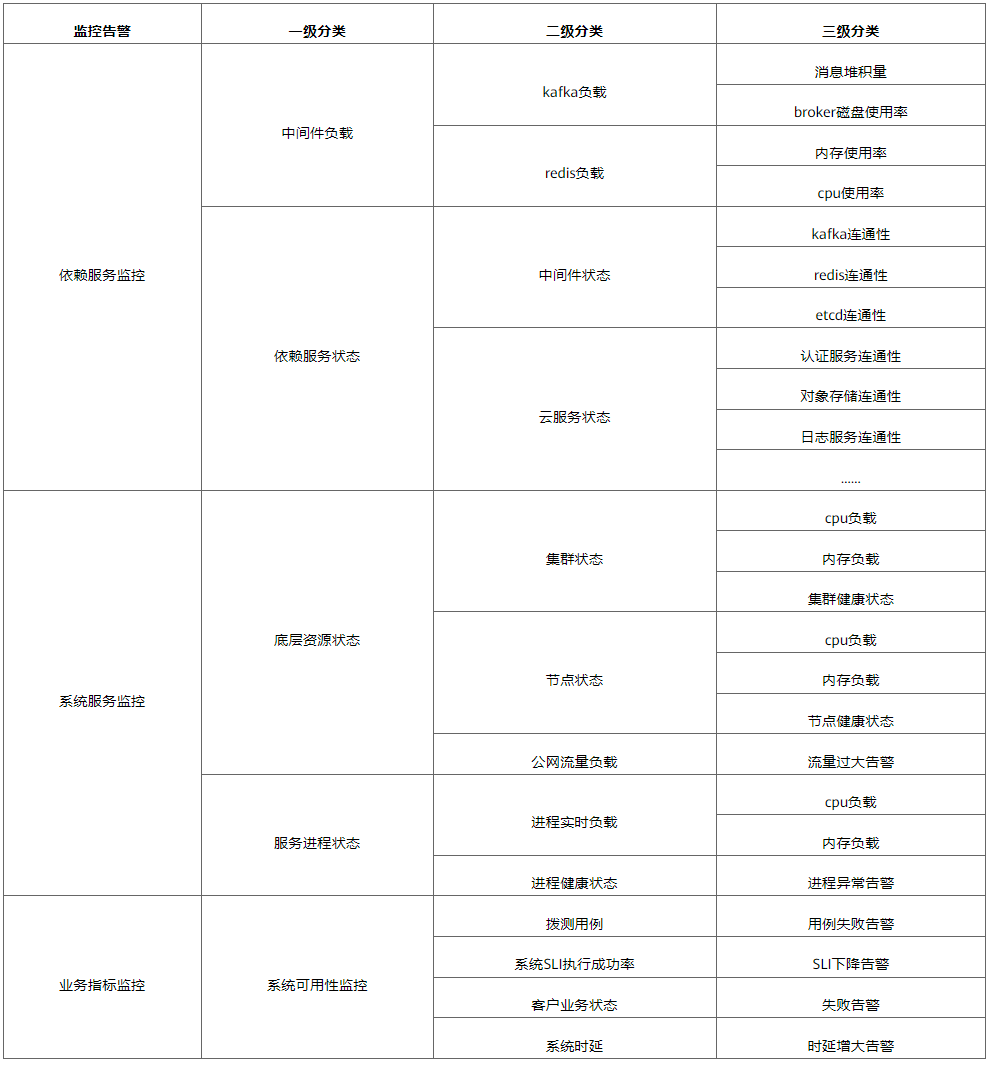
Tabela 2: Monitoramento de alarmes construídos pelo FunctionGraph
Especificações do processoAlgumas das medidas acima resolvem o problema de disponibilidade do sistema no nível do projeto técnico. O FunctionGraph também formou um conjunto de regras e regulamentos do processo. Quando a tecnologia não consegue resolver o problema no curto prazo, o risco pode ser rapidamente eliminado por meio de humanos. intervenção. Especificamente, existem as seguintes especificações de operação da equipe:
- Processo de sala de guerra interna: Ao encontrar um problema de emergência na rede ativa, a equipe organiza rapidamente funções-chave dentro da equipe para restaurar a falha da rede ativa o mais rápido possível;
- Processo interno de revisão de alterações: Depois que a versão do sistema é imersa no ambiente de teste e verificada sem problemas, antes da mudança oficial para a rede ativa, uma diretriz de mudança precisa ser escrita para identificar os pontos de função e pontos de risco alterados. a avaliação dos principais papéis da equipe pode ser colocada na rede ao vivo. Reduzir anormalidades causadas por mudanças humanas por meio de gerenciamento de processos padrão;
- Análise e revisão regular de problemas de rede em tempo real: avaliação semanal de risco de rede em tempo real, análise e revisão de alarmes, identificação de deficiências no projeto do sistema por meio de problemas, elaboração de inferências a partir de uma instância e otimização do sistema.
Recuperação de desastres do cliente
Mesmo os serviços de nuvem mais avançados do setor não podem prometer SLA de 100% para o mundo exterior. Portanto, quando o próprio sistema ou mesmo a intervenção humana não conseguem restaurar rapidamente o estado do sistema num curto período de tempo, o plano de recuperação de desastres concebido em conjunto com o cliente torna-se crucial. Geralmente, FunctionGraph trabalhará com os clientes para projetar um plano de recuperação de desastres para o cliente. Quando o sistema continua a enfrentar exceções, o cliente precisa tentar novamente para obter retornos. Quando o número de falhas atinge um determinado nível, é necessário considerar o acionamento de um. disjuntor no lado do cliente para limitar o impacto nos sistemas downstream enquanto alterna prontamente para opções de escape.
Resumir
Quando o FunctionGraph está fazendo um design de alta disponibilidade, ele geralmente segue os seguintes princípios de "redundância + failover. Ao mesmo tempo que atende às necessidades básicas do negócio, ele garante que o sistema seja estável e, em seguida, melhora gradualmente a arquitetura".
" Redundância + Failover " inclui os seguintes recursos:
Arquitetura de recuperação de desastres : modo multicluster, modo de espera ativa
Proteção contra sobrecarga : controle de fluxo, redução de pico assíncrona, pooling de recursos
Gerenciamento de falhas : nova tentativa, cache, isolamento, downgrade, disjuntor
Liberação em escala de cinza : streaming em escala de cinza e saída elegante
Recuperação de desastres do cliente : nova tentativa, disjuntor, fuga
No futuro, o FunctionGraph continuará a construir mais serviços disponíveis nas dimensões de design, monitoramento e processo do sistema. Conforme mostrado na Figura 7, podemos descobrir problemas rapidamente criando recursos de monitoramento, resolver problemas rapidamente por meio de design de confiabilidade, reduzir problemas por meio de especificações de processo, melhorar continuamente os recursos de disponibilidade do sistema e fornecer aos clientes serviços de SLA mais elevados.

Figura 7: Prática de iteração de alta disponibilidade do FunctionGraph
referências
[1] Definição de alta disponibilidade: https://zh.wikipedia.org/zh-hans/%E9%AB%98%E5%8F%AF%E7%94%A8%E6%80%A7
[2]Definição de SLA: https://zh.wikipedia.org/zh-hans/%E6%9C%8D%E5%8A%A1%E7%BA%A7%E5%88%AB%E5%8D%8F %E8%AE%AE
Autor: Um revisor: Jiulang, Wenruo