

Construir seus aplicativos de IA em torno de modelos de código aberto pode torná-los melhores, mais baratos e mais rápidos.
Traduzido de Como vencer LLMs proprietários com modelos menores de código aberto , autor Aidan Cooper.
Introdução
Ao projetar sistemas que usam modelos de geração de texto, muitas pessoas recorrem primeiro a serviços proprietários, como o GPT-4 da OpenAI ou o Gemini do Google. Afinal, esses são os maiores e melhores modelos que existem, então por que se preocupar com mais alguma coisa? Eventualmente, os aplicativos atingem uma escala que essas APIs não suportam, ou se tornam com custos proibitivos, ou os tempos de resposta são muito lentos. Os modelos de código aberto podem resolver todos esses problemas, mas se você tentar usá-los da mesma forma que usa LLMs proprietários, não obterá desempenho suficiente.
Neste artigo, exploraremos as vantagens exclusivas dos LLMs de código aberto e como eles podem ser aproveitados para desenvolver aplicativos de IA que não são apenas mais baratos e mais rápidos que os LLMs proprietários, mas também melhores.
LLM proprietário vs. LLM de código aberto
A Tabela 1 compara as principais características dos LLMs proprietários e dos LLMs de código aberto. O LLM de código aberto é pensado para ser executado em infraestrutura gerenciada pelo usuário, seja no local ou na nuvem. Em resumo: o LLM proprietário é o serviço gerenciado e oferece o modelo de código fechado mais poderoso e a maior janela de contexto, mas o LLM de código aberto é superior em todos os outros aspectos importantes.
A seguir está a versão chinesa da tabela (formato de redução):
| Modelo proprietário de linguagem grande | Modelo de linguagem grande de código aberto | |
|---|---|---|
| Exemplo | GPT-4 (OpenAI), Gemini (Google), Claude (Anthropic) | Gemma 2B (Google), Mistral 7B (Mistral AI), Llama 3 70B (Meta) |
| acessibilidade de software | Fonte fechada | Código aberto |
| Número de parâmetros | nível de trilhão | Escala típica: 2B, 7B, 70B |
| janela de contexto | Mais longo, 100 mil-1 milhão + tokens | Tokens mais curtos e típicos de 8k a 32k |
| habilidade | Melhor desempenho em todas as tabelas de classificação e benchmarks | Historicamente atrasado em relação aos modelos proprietários de grandes linguagens |
| a infraestrutura | Plataforma como serviço (PaaS), gerenciada pelo provedor. Não configurável. Limites de taxa de API. | Normalmente autogerenciado em infraestrutura em nuvem (IaaS). Totalmente configurável. |
| Custo de raciocínio | mais alto | mais baixo |
| velocidade | Mais lento na mesma faixa de preço. Não pode ser ajustado. | Depende de infraestrutura, tecnologia e otimização, mas mais rápido. Altamente configurável. |
| Taxa de transferência | Geralmente sujeito ao limite de taxa API. | Ilimitado: escalável de acordo com sua infraestrutura. |
| Atraso | mais alto. Várias rodadas de conversas podem acumular latência de rede significativa. | Se você executar o modelo localmente, não haverá latência de rede. |
| Função | Normalmente expõe um conjunto limitado de funcionalidades por meio de sua API. | O acesso direto ao modelo desbloqueia muitas técnicas poderosas. |
| esconderijo | Não é possível acessar o lado do servidor | Políticas configuráveis do lado do servidor para aumentar o rendimento e reduzir custos. |
| afinação | Serviços de ajuste fino limitados (como OpenAI) | Controle total sobre o ajuste fino. |
| Projeto de prompt/fluxo | Muitas vezes não é possível devido ao alto custo ou devido a limites de tarifas ou atrasos | Processos de controle irrestritos e cuidadosamente projetados têm impacto negativo mínimo. |
**Tabela 1.** Comparação de recursos LLM proprietários e LLM de código aberto
O foco deste artigo é que, aproveitando os pontos fortes dos modelos de código aberto, é possível construir aplicativos de IA que executam tarefas melhor do que LLMs proprietários, ao mesmo tempo que alcançam melhores perfis de rendimento e custo.
Vamos nos concentrar em estratégias para modelos de código aberto que não são possíveis ou são menos eficazes com LLMs proprietários. Isso significa que não discutiremos técnicas que beneficiam ambos, como dicas de poucos disparos ou geração aumentada de recuperação (RAG).
Requisitos para um sistema LLM eficaz
Ao considerar como projetar sistemas eficazes em torno do LLM, existem alguns princípios importantes a serem considerados.
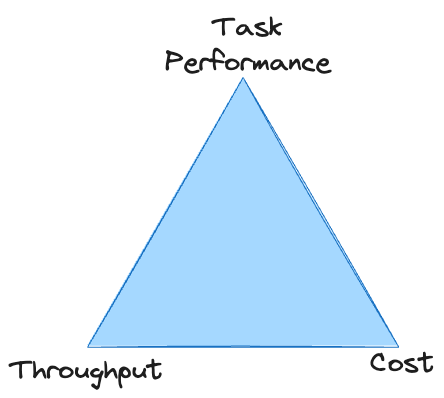
Existe uma compensação direta entre o desempenho da tarefa, o rendimento e o custo: é fácil melhorar qualquer um deles, mas geralmente às custas dos outros dois. A menos que você tenha um orçamento ilimitado, o sistema deve atender aos padrões mínimos nas três áreas para sobreviver. Com LLMs proprietários, muitas vezes você fica preso no vértice do triângulo, incapaz de atingir rendimento suficiente a um custo aceitável.
Descreveremos brevemente as características de cada um desses requisitos não funcionais antes de explorar estratégias que podem ajudar a resolver cada problema.
Taxa de transferência
Muitos sistemas LLM lutam para atingir o rendimento adequado simplesmente porque o LLM é lento.
Ao usar o LLM, o rendimento geral do sistema é quase inteiramente determinado pelo tempo necessário para gerar a saída de texto.
A menos que o seu processamento de dados seja particularmente pesado, outros fatores além da geração de texto são relativamente sem importância. O LLM pode "ler" texto muito mais rápido do que gerá-lo - isso ocorre porque os tokens de entrada são calculados em paralelo, enquanto os tokens de saída são gerados sequencialmente.
Precisamos maximizar a velocidade de geração de texto sem sacrificar a qualidade ou incorrer em custos excessivos.
Isso nos dá duas alavancas para puxar quando o objetivo é aumentar o rendimento:
- Reduza o número de tokens que precisam ser gerados
- Aumente a velocidade de geração de cada token individual
Muitas das estratégias abaixo foram concebidas para melhorar uma ou ambas as áreas.
custo
Para LLM proprietário, você será cobrado por token de entrada e saída. O preço de cada token estará relacionado à qualidade (ou seja, tamanho) do modelo que você usa. Isso oferece opções limitadas para reduzir custos: você precisa reduzir o número de tokens de entrada/saída ou usar um modelo mais barato (não haverá muitos para escolher).
Com o LLM auto-hospedado, seus custos são determinados pela sua infraestrutura. Se você usar um serviço de nuvem para hospedagem, será cobrado por unidade de tempo em que “alugar” a máquina virtual.

Modelos maiores exigem máquinas virtuais maiores e mais caras. Aumentar o rendimento sem alterar o hardware reduz os custos porque são necessárias menos horas de computação para processar uma quantidade fixa de dados. Da mesma forma, o rendimento pode ser aumentado dimensionando o hardware verticalmente ou horizontalmente, mas isso aumentará os custos.
As estratégias para minimizar custos concentram-se em permitir modelos mais pequenos para a tarefa, uma vez que estes têm o maior rendimento e são os mais baratos de executar.
desempenho da tarefa
O desempenho da missão é o mais vago dos três requisitos, mas também aquele com o escopo mais amplo para otimização e melhoria. Um dos principais desafios para alcançar o desempenho adequado da tarefa é medi-lo: é difícil obter uma avaliação quantitativa e confiável dos resultados do LLM.
Como nos concentramos em tecnologias que beneficiam exclusivamente o LLM de código aberto, nossa estratégia enfatiza fazer mais com menos recursos e aproveitar métodos que só são possíveis com acesso direto ao modelo.
Estratégias de LLM de código aberto para derrotar o LLM proprietário
Todas as estratégias a seguir são eficazes isoladamente, mas também são complementares. Eles podem ser aplicados em vários graus para atingir o equilíbrio certo entre os requisitos não funcionais do sistema e maximizar o desempenho geral.
Diálogo multivoltas e fluxo de controle
- Melhore o desempenho das tarefas
- Reduza a produtividade
- Adicione custo por entrada
Embora uma ampla gama de estratégias de diálogo multiturno possa ser usada com LLMs proprietários, essas estratégias muitas vezes não são viáveis porque:
- Pode ser caro quando cobrado por token
- Pode esgotar os limites de taxa de API porque exigem várias chamadas de API por entrada
- Pode ser muito lento se a troca de ida e volta envolver a geração de muitos tokens ou o acúmulo de muita latência de rede
É provável que esta situação melhore com o tempo, à medida que os LLMs proprietários se tornam mais rápidos, mais escaláveis e mais acessíveis. Mas, por enquanto, os LLMs proprietários são frequentemente limitados a uma estratégia única e de prompt único que pode ser aplicada em escala a casos de uso do mundo real. Isso é consistente com a janela de contexto maior fornecida pelos LLMs proprietários: a estratégia preferida geralmente é apenas amontoar muitas informações e instruções em um único prompt (o que, aliás, tem impactos negativos em custos e velocidade).
Com um modelo auto-hospedado, estas desvantagens das conversas multi-round são menos preocupantes: o custo por token é menos relevante, não há limites de taxa de API e a latência da rede pode ser minimizada; A janela de contexto menor e os recursos de inferência mais fracos dos modelos de código aberto também devem impedir o uso de uma única dica. Isso nos leva à estratégia central para derrotar LLMs proprietários:
A chave para superar o LLM proprietário é usar modelos menores de código aberto para realizar mais trabalho em uma série de subtarefas mais refinadas.
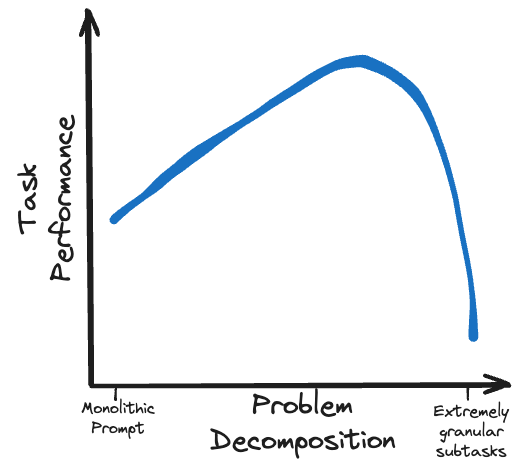
Estratégias de estímulo multi-round cuidadosamente formuladas são viáveis para modelos locais. Técnicas como Chain of Thoughts (CoT), Trees of Thought (ToT) e ReAct permitem que modelos menos capazes tenham desempenho equivalente a modelos maiores.
Outro nível de complexidade é o uso de fluxo de controle e ramificação para guiar dinamicamente o modelo ao longo do caminho de inferência correto e transferir algumas tarefas de processamento para funções externas. Eles também podem ser usados como um mecanismo para preservar o orçamento do token da janela de contexto, bifurcando subtarefas em ramificações fora do fluxo de prompt principal e, em seguida, reunindo novamente os resultados agregados dessas bifurcações.
Em vez de sobrecarregar um pequeno modelo de código aberto com uma tarefa excessivamente complexa, divida o problema em um fluxo lógico de subtarefas viáveis.
decodificação restrita
- Melhore o rendimento
- cortar custos
- Melhore o desempenho das tarefas
Para aplicativos que envolvem a geração de saída estruturada (como objetos JSON), a decodificação restrita é uma técnica poderosa que pode:
- Saída garantida que está em conformidade com a estrutura exigida
- Melhore drasticamente o rendimento acelerando a geração de tokens e reduzindo o número de tokens que precisam ser gerados
- Melhore o desempenho das tarefas guiando modelos
Escrevi um artigo separado explicando este tópico em detalhes: Um guia para geração estruturada com decodificação restrita Os comos, porquês, capacidades e armadilhas da geração de resultados de modelos de linguagem
Crucialmente, a decodificação de restrições funciona apenas com modelos de geração de texto que fornecem acesso direto à distribuição completa de probabilidade do próximo token, que não está disponível em nenhum grande provedor proprietário de LLM no momento da redação deste artigo.
OpenAI fornece um esquema JSON , mas essa decodificação estritamente restrita não garante vantagens estruturais ou de rendimento da saída JSON.
A decodificação de restrições anda de mãos dadas com estratégias de fluxo de controle, pois permite direcionar de forma confiável um grande modelo de linguagem para um caminho pré-especificado, restringindo sua resposta a diferentes opções de ramificação. Pedir a um modelo que produza respostas curtas e restritas a uma série de longas perguntas de diálogo com várias voltas é muito rápido e barato (lembre-se: a velocidade de transferência é determinada pelo número de tokens gerados).
A decodificação de restrições não tem nenhuma desvantagem digna de nota; portanto, se sua tarefa exigir saída estruturada, você deverá usá-la.
Cache, quantização de modelo e outras otimizações de back-end
- Melhore o rendimento
- cortar custos
- Não afeta o desempenho da tarefa
O cache é uma técnica que acelera as operações de recuperação de dados, armazenando pares de entrada:saída de uma computação e reutilizando os resultados se a mesma entrada for encontrada novamente.
Em sistemas não LLM, o cache é normalmente aplicado a solicitações que correspondem exatamente às solicitações vistas anteriormente. Alguns sistemas LLM também podem se beneficiar dessa forma estrita de cache, mas geralmente, ao construir com LLM, não queremos encontrar exatamente a mesma entrada com muita frequência.
Felizmente, existem técnicas sofisticadas de cache de valores-chave específicas para LLM que são muito mais flexíveis. Essas técnicas podem acelerar bastante a geração de texto para solicitações que correspondem parcialmente, mas não exatamente, à entrada vista anteriormente. Isto melhora o rendimento do sistema, reduzindo a quantidade de tokens que precisam ser gerados (ou pelo menos acelerando-os, dependendo da tecnologia e do cenário de cache específico).
Com um LLM proprietário, você não tem controle sobre como o cache é ou não executado em suas solicitações. Mas para LLM de código aberto, existem várias estruturas de back-end para serviços LLM que podem melhorar significativamente o rendimento de inferência e podem ser configuradas de acordo com os requisitos personalizados do seu sistema.
Além do cache, existem outras otimizações LLM que podem ser usadas para melhorar o rendimento da inferência, como a quantização do modelo . Ao reduzir a precisão usada para pesos de modelo, o tamanho do modelo (e, portanto, seus requisitos de memória) pode ser reduzido sem comprometer significativamente a qualidade de sua saída. Os modelos populares geralmente têm um grande número de variantes quantizadas disponíveis no Hugging Face, contribuídas pela comunidade de código aberto, o que evita que você tenha que realizar o processo de quantização sozinho.
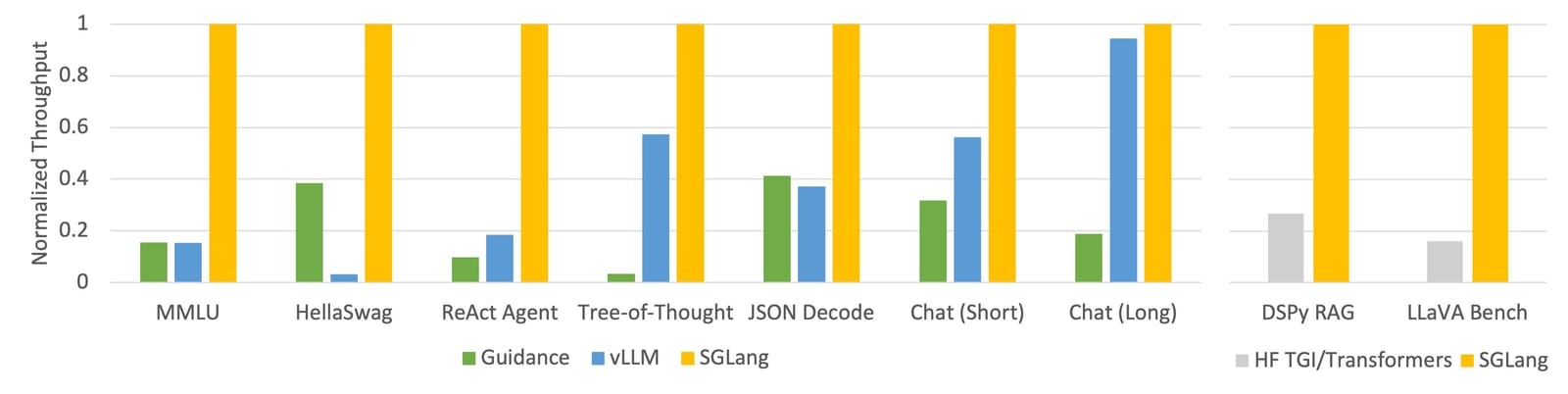
Anúncio de rendimento incrível do SGLang (veja a postagem do blog de lançamento do SGLang)
vLLM é provavelmente a estrutura de serviço mais madura, com vários mecanismos de cache, paralelização, otimização de kernel e métodos de quantização de modelo. SGLang é um player mais recente com funcionalidade semelhante ao vLLM, bem como um método inovador de cache RadixAttention que apresenta desempenho particularmente impressionante.
Se você auto-hospedar seu modelo, vale a pena usar essas estruturas e técnicas de otimização, pois você pode razoavelmente esperar melhorar o rendimento em pelo menos uma ordem de magnitude.
Ajuste fino de modelo e destilação de conhecimento
- Melhore a eficiência da execução de tarefas
- Não afeta os custos de raciocínio
- Não afeta o rendimento
O ajuste fino abrange uma variedade de técnicas para ajustar um modelo existente para um melhor desempenho em uma tarefa específica. Eu recomendo verificar a postagem do blog de Sebastian Raschka sobre métodos de ajuste fino como uma introdução ao assunto. A destilação de conhecimento é um conceito relacionado no qual um modelo menor de “aluno” é treinado para simular o resultado de um modelo maior de “professor” na tarefa de interesse.
Alguns provedores proprietários de LLM, incluindo OpenAI , oferecem recursos mínimos de ajuste fino. Mas apenas os modelos de código aberto proporcionam controlo total sobre o processo de ajuste fino e acesso a tecnologias abrangentes de ajuste fino.
Os modelos de ajuste fino podem melhorar significativamente o desempenho das tarefas sem afetar o custo de inferência ou o rendimento. Mas o ajuste fino requer tempo, habilidade e bons dados para ser implementado, e há um custo envolvido no processo de treinamento. Técnicas de ajuste fino com eficiência de parâmetros (PEFT), como LoRA, são particularmente atraentes porque oferecem os mais altos retornos de desempenho em relação à quantidade de recursos necessários.
O ajuste fino e a destilação do conhecimento estão entre as técnicas mais poderosas para maximizar o desempenho do modelo. Desde que sejam implementados corretamente, não apresentam desvantagens, exceto o investimento inicial necessário para executá-los. No entanto, você deve ter cuidado para garantir que o ajuste fino seja feito de maneira consistente com outros aspectos do sistema, como fluxo de sinalização e estruturas de saída de decodificação restritas. Se houver diferenças entre essas tecnologias, poderá ocorrer um comportamento inesperado.
Otimizar o tamanho do modelo
Modelo pequeno:
- Melhore o rendimento
- cortar custos
- Reduza o desempenho de execução de tarefas
Isto pode igualmente ser considerado um “modelo maior”, com vantagens e desvantagens opostas. Os pontos principais são:
Faça seu modelo o menor possível, mas ainda mantenha capacidade suficiente para compreender e concluir a tarefa de maneira confiável.
A maioria dos provedores proprietários de LLM oferece algum nível de tamanho/capacidade de modelo. E quando se trata de código aberto, existem opções estonteantes de modelos em todos os tamanhos que você desejar, com parâmetros de até 100B+.
Conforme mencionado na seção de conversação multiturno, podemos simplificar tarefas complexas dividindo-as em uma série de subtarefas mais gerenciáveis. Mas sempre haverá um problema que não pode ser mais detalhado, ou que isso comprometeria aspectos da missão que precisam ser abordados de forma mais completa. Isso depende muito do caso de uso, mas a granularidade e a complexidade da tarefa terão um ponto ideal que ditará o tamanho correto do modelo, conforme demonstrado pela obtenção de desempenho adequado da tarefa no menor tamanho de modelo.
Para algumas tarefas, isso significa usar o modelo maior e mais capaz que você puder encontrar; para outras tarefas, você poderá usar um modelo muito pequeno (mesmo um não LLM).
Em qualquer caso, opte por usar o melhor modelo da categoria em qualquer tamanho de parâmetro. Isto pode ser identificado por referência a benchmarks e classificações públicas , que mudam regularmente com base no rápido ritmo de desenvolvimento no campo. Alguns benchmarks são mais adequados para o seu caso de uso do que outros, por isso vale a pena descobrir quais funcionam melhor.
Mas não pense que você pode simplesmente substituir o novo melhor modelo e obter uma melhoria imediata no desempenho. Diferentes modelos têm diferentes modos de falha e características, portanto um sistema otimizado para um modelo não funcionará necessariamente para outro – mesmo que seja melhor.
roteiro de tecnologia
Como mencionado anteriormente, todas estas estratégias são complementares e quando combinadas, combinam-se para produzir um sistema robusto e abrangente. Mas existem dependências entre estas tecnologias e é importante garantir que sejam consistentes para evitar disfunções.
A figura a seguir é um diagrama de dependências que mostra a sequência lógica para implementação dessas tecnologias. Isso pressupõe que o caso de uso requer a geração de resultados estruturados.
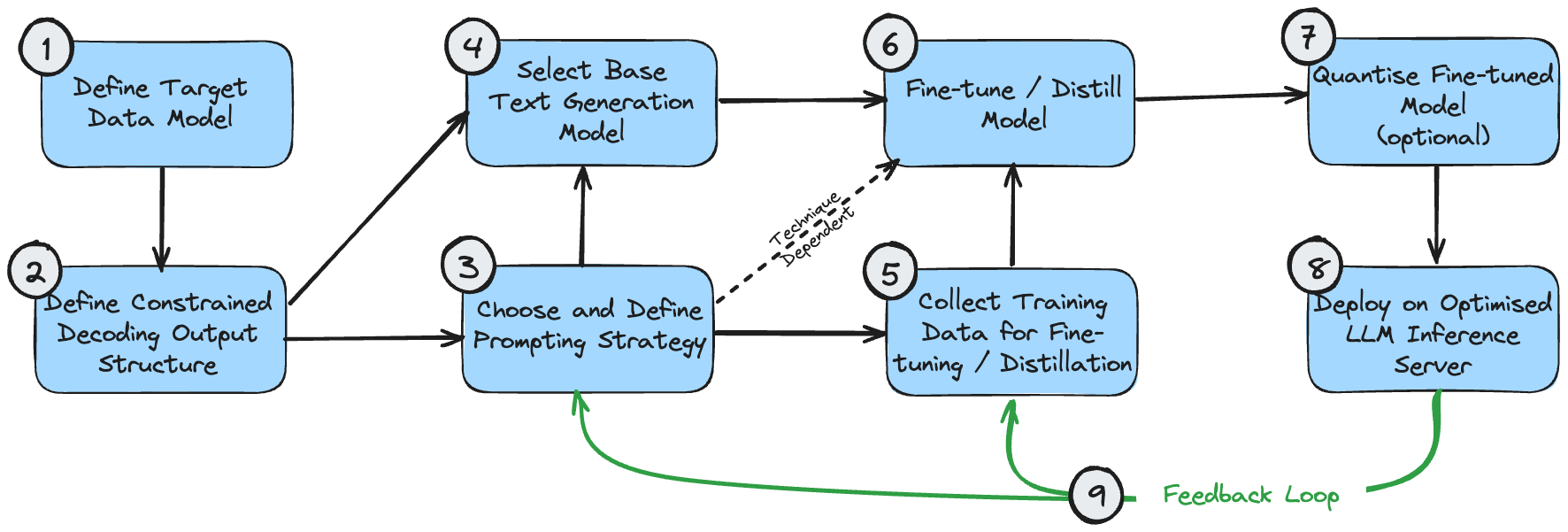
Essas etapas podem ser entendidas da seguinte forma:
- O modelo de dados de destino é o resultado final que você deseja criar. Isso é determinado pelo seu caso de uso e pelos requisitos mais amplos do sistema geral, além da geração de processamento de texto.
- A estrutura de saída de decodificação restrita pode ser a mesma do seu modelo de dados de destino ou pode ser ligeiramente modificada para obter desempenho ideal durante a decodificação restrita. Veja meu artigo sobre decodificação restrita para entender por que isso acontece. Se for diferente, é necessária uma etapa de pós-processamento para transformá-lo no modelo de dados de destino final.
- Você deve fazer uma estimativa inicial da estratégia de solicitação correta para seu caso de uso. Se o problema for simples ou não puder ser resolvido intuitivamente, escolha uma estratégia de prompt único. Se o problema for muito complexo, com muitos subcomponentes refinados, escolha uma estratégia multi-prompt.
- A seleção inicial do modelo é principalmente uma questão de otimizar o tamanho e garantir que as propriedades do modelo atendam aos requisitos funcionais do problema. Os tamanhos ideais dos modelos são discutidos acima. Propriedades do modelo, como o comprimento necessário da janela de contexto, podem ser calculadas com base na estrutura de saída esperada ((1) e (2)) e na estratégia de prompt (3).
- Os dados de treinamento usados para o ajuste fino do modelo devem ser consistentes com a estrutura de saída (2). Se for usada uma estratégia multi-sugestão que construa o resultado passo a passo, os dados de treinamento também deverão refletir cada estágio desse processo.
- O ajuste fino/destilação do modelo depende naturalmente da seleção do modelo, da curadoria de dados de treinamento e do fluxo imediato.
- A quantização de modelos ajustados é opcional. Suas opções de quantificação dependerão do modelo básico escolhido.
- O servidor de inferência LLM oferece suporte apenas a arquiteturas de modelos e métodos de quantização específicos, portanto, certifique-se de que sua seleção anterior seja compatível com a configuração de back-end desejada.
- Depois de implementar um sistema ponta a ponta, você pode criar um ciclo de feedback para melhoria contínua. Você deve ajustar periodicamente os prompts e os exemplos de poucas tentativas (se os estiver usando) para levar em conta exemplos em que o sistema não consegue produzir resultados aceitáveis. Depois de acumular uma amostra razoável de casos de falha, você também deve considerar o uso dessas amostras para realizar ajustes adicionais no modelo.
Na realidade, o processo de desenvolvimento nunca é completamente linear e, dependendo do caso de uso, pode ser necessário priorizar a otimização de alguns desses componentes em detrimento de outros. Mas é uma base razoável para projetar um roteiro baseado em seus requisitos específicos.
para concluir
Os modelos de código aberto podem ser mais rápidos, mais baratos e melhores que os LLMs proprietários. Isso pode ser conseguido projetando sistemas mais complexos que aproveitem os pontos fortes exclusivos dos modelos de código aberto e façam compensações apropriadas entre rendimento, custo e desempenho da missão.
Esta escolha de design troca a complexidade do sistema pelo desempenho geral. Uma alternativa válida é ter um sistema mais simples e igualmente poderoso, alimentado por um LLM proprietário, mas com um custo mais elevado e menor rendimento. A decisão certa depende da sua aplicação, do seu orçamento e da disponibilidade de recursos de engenharia.
Mas não abandone os modelos de código aberto muito rapidamente sem adaptar sua estratégia tecnológica para acomodá-los – você poderá se surpreender com o que eles podem fazer.
Decidi desistir do software industrial de código aberto . Grandes eventos - OGG 1.0 foi lançado, a Huawei contribuiu com todo o código-fonte do Ubuntu 24.04 LTS foi oficialmente demitido . ". O Fedora Linux 40 foi lançado oficialmente. Uma conhecida empresa de jogos lançou novos regulamentos: os presentes de casamento dos funcionários não devem exceder 100.000 yuans. A China Unicom lança a primeira versão chinesa Llama3 8B do mundo do modelo de código aberto. Pinduoduo é condenado a compensar 5 milhões de yuans por concorrência desleal Método de entrada na nuvem doméstica - apenas a Huawei não tem problemas de segurança de upload de dados na nuvem.Este artigo foi publicado pela primeira vez em Yunyunzhongsheng ( https://yylives.cc/ ), todos são bem-vindos para visitar.