
01 Visão geral do plano de fundo
No cenário em que os dados da série temporal são gravados no banco de dados, devido a problemas como atrasos na rede, pode acontecer que o carimbo de data/hora dos dados a serem gravados seja menor que o carimbo de data/hora máximo dos dados que foram gravados. os dados são coletivamente chamados de dados fora de ordem. A geração de dados fora de ordem é quase inevitável. Ao mesmo tempo, a gravação de dados fora de ordem afetará a classificação e consulta de todos os dados. dados do pedido e também suporta bem a consulta de dados fora de ordem.
02 Visão Geral do Processo
Ao processar dados fora de ordem, os dados fora de ordem dentro de uma janela de tempo especificada (como 10 minutos ou 1 hora) serão processados de acordo com a estratégia de desduplicação e armazenados, e os dados fora de ordem fora do tempo janela será descartada. A figura a seguir é o processo básico de gravação de dados fora de ordem:

Entre eles, três pontos-chave precisam ser esclarecidos:
- A janela de tempo refere-se a um período de tempo anterior ao ponto no tempo do último carimbo de data/hora dos dados na tabela. Quando nenhum dado novo é gravado na tabela, sua janela de tempo não será alterada.
- Há um parâmetro no arquivo de configuração: ts_st_iot_disorder_interval, que é usado para suportar a janela de tempo para gravação de dados fora de ordem, unidade: segundos. O valor deste item de configuração não pode exceder o valor do intervalo de partição.
- A base para julgar se os dados estão fora de ordem é que o carimbo de data/hora dos dados gravados é menor ou igual ao carimbo de data/hora máximo de todos os dados armazenados no objeto de tabela gravado.
03 Exemplo de cenário
1. Processo normal de escrita
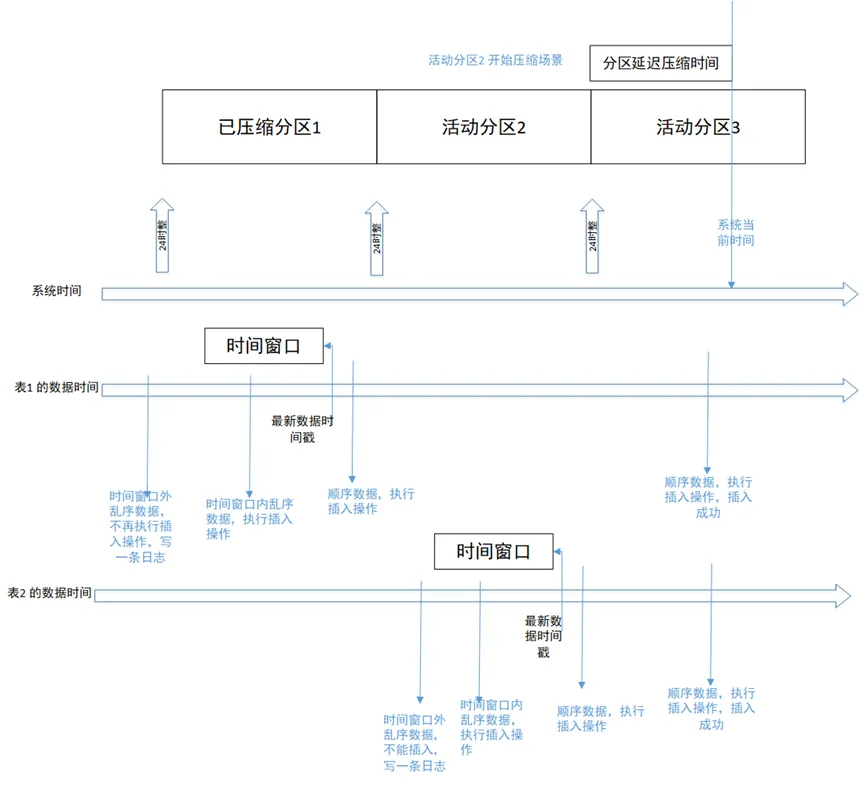
A hora é dividida em duas linhas: hora do sistema e hora dos dados. O horário dos dados é diferente para cada tabela, por isso é dividido em duas linhas: o horário dos dados da Tabela 1 e o horário dos dados da Tabela 2.
-
Cenário 1: O cenário de gravação sequencial de dados há dois dias é mostrado na figura acima. O cenário da Tabela 1 grava sequencialmente na partição histórica 1. Os dados sequenciais gravados serão armazenados na partição correspondente. partição falha e lança errado.
-
Cenário 2: Gravando dados fora de ordem dentro da janela de tempo Conforme mostrado na figura acima, a Tabela 2 grava dados fora de ordem dentro da janela de tempo. Os dados gravados serão armazenados na partição ativa 2, que está sendo processada. em outro thread, a compactação de partição, as operações de gravação também serão bem-sucedidas.
-
Cenário 3: Gravando dados fora de ordem que excedem a janela de tempo Quando o banco de dados ativa a função de compactação e configura a janela de tempo fora de ordem para 1 hora, gravando dados fora de ordem que estão 1 hora antes. do que o carimbo de data/hora do registro mais recente na tabela falhará. Os dados gravados serão filtrados e gravados no log.
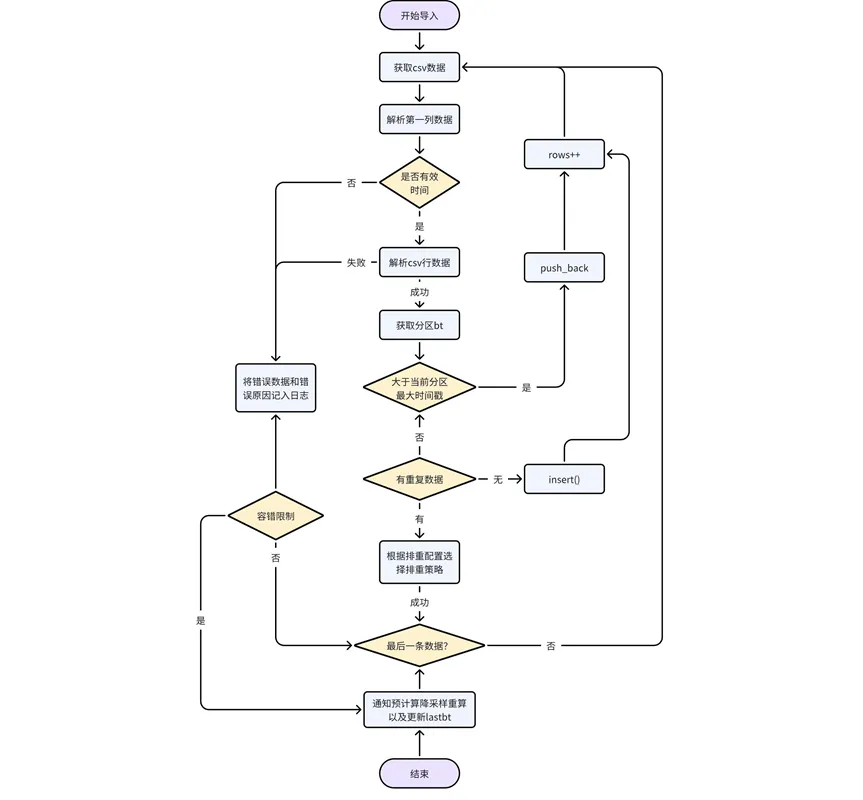
2. Processo de importação de dados
Também pode haver dados fora de ordem nos dados importados. Nesse cenário, o processamento de dados fora de ordem é consistente com o processo normal de gravação.
-
Processamento dos próprios dados: analise os dados no arquivo CSV linha por linha, determine se a primeira coluna de dados é um tipo de hora/carimbo de data e hora válido e, caso contrário, retorne um erro, se forem dados de hora válidos, determine a partição para; à qual os dados pertencem e obtenha a partição bt. Se o carimbo de data/hora dos dados for maior que o carimbo de data/hora máximo dos dados existentes na partição atual, retroceda diretamente, caso contrário, os dados fora de ordem precisarão ser processados de acordo com a lógica de configuração de desduplicação.
-
Adaptar a lógica de redução da resolução e pré-computação: Durante o processo de importação de dados, você precisa atualizar o status do registro do URL na tabela de tarefas do sistema kaiwudb_jobs para expirar após a conclusão da importação, notificar a pré-computação/redução da resolução, recalcular/processar os dados envolvidos ou; aguarde a próxima etapa. Uma tarefa de pré-cálculo é recalculada quando é agendada pelo sistema.
Após a conclusão da importação, o pré-cálculo e a redução da resolução são notificados para recalcular ou atualizar os resultados e atualizar o lastbt.
3. Processo de redução da resolução
Depois que os dados fora de ordem são gravados, os resultados da redução da resolução precisam ser atualizados com base nos dados mais recentes.

-
Processamento de dados fora de ordem importados para partições históricas: Ao importar dados fora de ordem pertencentes a partições históricas, atualize o status do registro de url=[database/partition/table_name] na tabela de tarefas do sistema kaiwudb_jobs para expirado e então a tabela de partição será baixada novamente de acordo.
-
Processar inserção e gravação de dados históricos da partição: Ao descompactar a partição histórica da tabela de dados de inserção, atualize o status do registro de url=[banco de dados/partição/nome_tabela] na tabela de tarefas do sistema kaiwudb_jobs para expirado e a tabela de partição será re- correspondente no futuro. Processamento de regras de redução da resolução.
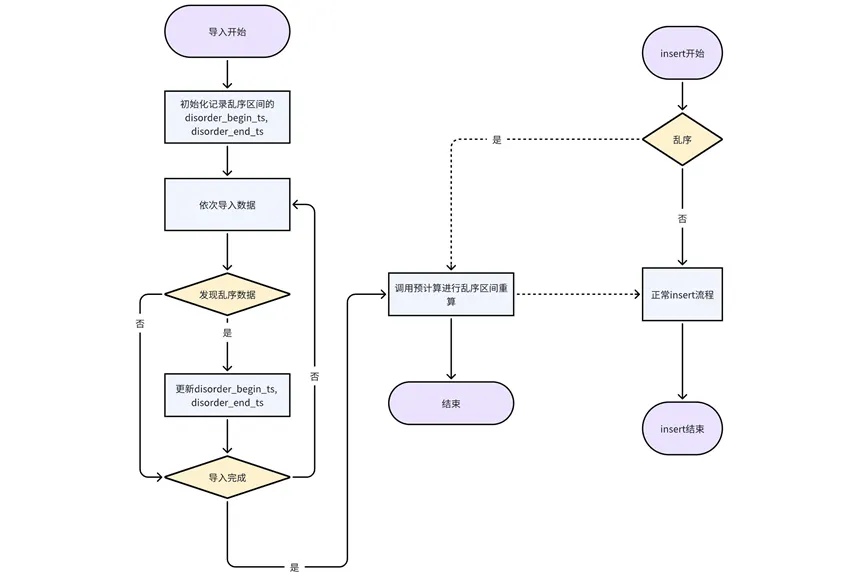
4. Após a gravação dos dados fora de ordem no processo de pré-computação, os resultados da pré-computação precisam ser atualizados com base nos dados mais recentes.
-
Processar inserção e gravação de dados fora de ordem: insira sempre que um dado fora de ordem aparecer na inserção. Essa abordagem pode garantir maior precisão dos resultados de pré-cálculo.
-
Processamento de dados fora de ordem importados: A importação é atualmente processada em unidades de tabelas de partição Durante o processo de importação de cada tabela de partição, o carimbo de data/hora de início e de término fora de ordem são registrados após a importação do atual. tabela de partição é concluída, a interface de pré-cálculo é chamada para recálculo.
04 Resumo
No cenário de processamento de dados fora de ordem, há muitas funções e módulos de ligação envolvidos, que precisam ser sincronizados e atualizados. Quando o banco de dados possui processamento completo de dados fora de ordem, ele pode se adaptar melhor aos cenários de negócios do usuário e melhorar significativamente a aplicabilidade do banco de dados em vários cenários.
Decidi desistir do software industrial de código aberto . Grandes eventos - OGG 1.0 foi lançado, a Huawei contribuiu com todo o código-fonte do Ubuntu 24.04 LTS foi oficialmente demitido . ". O Fedora Linux 40 foi lançado oficialmente. Uma conhecida empresa de jogos lançou novos regulamentos: os presentes de casamento dos funcionários não devem exceder 100.000 yuans. A China Unicom lança a primeira versão chinesa Llama3 8B do mundo do modelo de código aberto. Pinduoduo é condenado a compensar 5 milhões de yuans por concorrência desleal Método de entrada na nuvem doméstica - apenas a Huawei não tem problemas de segurança de upload de dados na nuvem.