
Autor: Chen Xin (Shenxiu)
Olá a todos, sou Chen Xin, diretor técnico de produto da Tongyi Lingma. Nos últimos oito anos, tenho trabalhado no Grupo Alibaba em desempenho de P&D, ou seja, trabalho relacionado a ferramentas de P&D.
Começamos a construir uma plataforma DevOps completa em 2015 e, em seguida, criamos o Cloud Effect, que visa transformar a plataforma DevOps em nuvem. Em 2023, sentimos claramente que, após a chegada da era dos grandes modelos, as ferramentas de software enfrentarão inovações profundas. A combinação de grandes modelos e cadeias de ferramentas de software trará a pesquisa e o desenvolvimento de software para a próxima era.
Então, onde é sua primeira parada? Na verdade, é uma programação auxiliar, então começamos a criar o produto Tongyi Lingma , que é uma ferramenta auxiliar de IA baseada em um grande modelo de código. Hoje aproveito para compartilhar com vocês alguns detalhes sobre a implementação da tecnologia Tongyi Lingma e como vemos o desenvolvimento de grandes modelos na área de pesquisa e desenvolvimento de software.
Vou compartilhá-lo em três partes. A primeira parte introduz primeiro o impacto fundamental do AIGC na pesquisa e desenvolvimento de software e apresenta as tendências atuais de uma perspectiva macro; a segunda parte apresentará o modelo Copilot e a terceira parte é o progresso dos futuros produtos de desenvolvimento de software; Por que mencionei o Agente Copiloto, explicarei a você mais tarde.
O impacto fundamental do AIGC no desenvolvimento de software
Esta imagem é uma imagem que desenhei nos últimos anos. Acho que os principais fatores que influenciam a eficiência da P&D corporativa são esses três pontos.
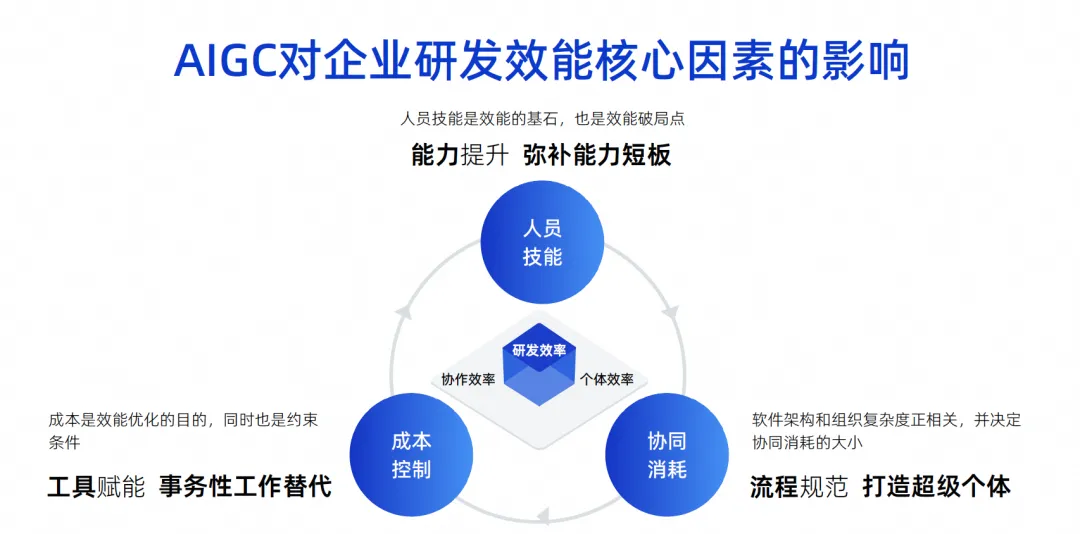
O primeiro ponto são as habilidades pessoais. As habilidades pessoais determinam um fator muito importante na eficiência de P&D de uma empresa. Por exemplo, o Google pode recrutar engenheiros cujas habilidades pessoais sejam dez vezes mais fortes do que outras. engenheiros capazes terão uma eficácia de combate muito poderosa e podem até realizar a pilha completa. Sua divisão de funções pode ser muito simples, seu trabalho é muito eficiente e sua eficácia final também é muito grande.
Mas, na verdade, poucas das nossas empresas, especialmente as chinesas, conseguem atingir o nível do Google. Este é um factor de influência objectivo. Acreditamos que as competências do pessoal são a pedra angular da eficácia e, claro, são também o ponto de ruptura da eficácia.
O segundo ponto é o consumo colaborativo. Com base no fato de que não podemos exigir que todos os engenheiros sejam altamente capazes, todos devem ter uma divisão profissional de trabalho. Por exemplo, alguns fazem design de software e outros fazem desenvolvimento, testes e gerenciamento de projetos. À medida que a complexidade da arquitetura de software da equipe composta por essas pessoas aumenta, a complexidade da organização também aumentará proporcionalmente. Isso fará com que o consumo colaborativo aumente, diminuindo, em última análise, a eficiência geral da P&D.
O terceiro ponto é o controle de custos. Descobrimos que quando se trabalha em projectos, as pessoas nem sempre são ricas, há sempre falta de mão-de-obra e é impossível ter fundos ilimitados para recrutar dez vezes mais engenheiros, pelo que isto também é um constrangimento.
Hoje, na era do AIGC, estes três factores produziram algumas mudanças fundamentais.
Em termos de competências pessoais, a assistência da IA pode melhorar rapidamente as capacidades de alguns engenheiros juniores. Na verdade, existem alguns relatórios sobre isso no exterior. O efeito dos engenheiros juniores que usam ferramentas de assistência de código é significativamente maior do que o dos engenheiros seniores. Como essas ferramentas são substitutos muito bons para o trabalho inicial ou para seu efeito auxiliar, elas podem rapidamente compensar as deficiências dos engenheiros juniores.
Em termos de consumo colaborativo, se a IA puder se tornar um superindividual hoje, será realmente útil reduzir o consumo colaborativo de processos. Por exemplo, não há necessidade de lidar com pessoas para algumas tarefas simples, a IA pode fazer isso diretamente e não há necessidade de explicar a todos como testar os requisitos. A IA pode apenas fazer testes simples, para que a eficiência do tempo seja melhorada. . Portanto, o consumo colaborativo pode ser efetivamente reduzido através de superindivíduos.
Em termos de controlo de custos, de facto, um grande número de utilizações de IA destinam-se a substituir o trabalho transacional, incluindo a utilização atual de grandes modelos de código para assistência de código, que também deverá substituir 70% do trabalho transacional diário.
Se olharmos especificamente, haverá estes quatro desafios e oportunidades para a inteligência.

O primeiro é a eficiência individual. Como acabei de apresentar a vocês, o trabalho repetitivo e a comunicação simples de um grande número de engenheiros de P&D podem ser concluídos por meio de IA.
Outro aspecto da eficiência da colaboração é que algumas tarefas simples podem ser realizadas diretamente pela IA, o que pode reduzir o consumo de colaboração que acabei de explicar claramente.
O terceiro é a experiência em P&D. Em que se concentrava a cadeia de ferramentas DevOps no passado? Um por um, eles formam uma grande linha de montagem e toda a cadeia de ferramentas. Na verdade, cada cadeia de ferramentas pode ter hábitos de uso diferentes em empresas diferentes e pode até ter sistemas de contas diferentes, interfaces diferentes, interações diferentes e permissões diferentes. Essa complexidade traz custos muito grandes de mudança de contexto e de compreensão para os desenvolvedores, o que invisivelmente deixa os desenvolvedores muito insatisfeitos.
Mas algumas mudanças ocorreram na era da IA. Podemos usar a linguagem natural para operar muitas ferramentas por meio de uma entrada de diálogo unificada e até mesmo resolver muitos problemas na janela da linguagem natural.
Deixe-me dar um exemplo. Por exemplo, se verificarmos se há algum problema de desempenho em uma instrução SQL, o que devemos fazer? Você pode primeiro desenterrar a instrução SQL no código, transformá-la em uma instrução executável e, em seguida, colocá-la em um sistema DMS para diagnosticá-la e ver se ela usa índices e se há algum problema, e então julgar manualmente se é necessário ou não. Modifique este SQL para otimizá-lo e, finalmente, altere-o no IDE. Este processo requer a troca de vários sistemas e muitas coisas precisam ser feitas.
No futuro, se tivermos ferramentas de inteligência de código, podemos circular um código e perguntar ao modelo grande se há algum problema com este SQL. Esse modelo grande pode chamar independentemente algumas ferramentas, como o sistema DMS, para analisar, e o. os resultados obtidos podem ser diretamente, diga-me como o SQL deve ser otimizado por meio do modelo grande e diga-me os resultados diretamente. Só precisamos adotá-lo para resolver o problema. a eficiência será melhorada.
O quarto são os ativos digitais. No passado, todos escreviam códigos e os colocavam lá, e isso se transformou em uma montanha de códigos ou passivos. É claro que existem muitas minas de ouro pendentes que não foram descobertas e ainda existem muitos documentos. que eu quero encontrar. O tempo não pode ser encontrado.
Mas na era da IA, uma das coisas mais importantes que fazemos é organizar nossos ativos e documentos e capacitar grandes modelos por meio de SFT e RAG, para que os grandes modelos se tornem mais inteligentes e mais alinhados com a personalidade do Portanto, as mudanças atuais nos métodos de interação humano-computador trarão mudanças na experiência.

A inteligência artificial analisa os fatores que influenciam agora. Seu núcleo é provocar três mudanças nos métodos de interação humano-computador. A primeira é que a IA se tornará um copiloto, combinada com ferramentas, e então as pessoas poderão comandá-la para nos ajudar a completar algumas ferramentas de ponto único. No segundo estágio, todos devem realmente ter um consenso. Ele se torna um Agente, o que significa que tem a capacidade de concluir tarefas de forma independente, incluindo escrever código ou fazer testes de forma independente. Na verdade, a ferramenta atua como um especialista em vários domínios. Precisamos apenas fornecer o contexto e completar o alinhamento do conhecimento. Na terceira fase, julgamos que a IA pode tornar-se um tomador de decisões, porque na segunda fase o tomador de decisões ainda é um ser humano. Na terceira fase, é possível que o grande modelo tenha algumas capacidades de tomada de decisão, incluindo recursos mais avançados de integração e análise de informações. Neste momento, as pessoas se concentrarão mais na criatividade e na correção dos negócios, e muitas coisas podem ser deixadas para grandes modelos. Através desta mudança nos diferentes modos homem-máquina, a nossa eficiência geral de trabalho aumentará.

Outro ponto é que a forma de transferência de conhecimento de que acabamos de falar também sofreu mudanças fundamentais. No passado, o problema da transferência de conhecimento era resolvido através do boca-a-boca, da formação e do antigo trazendo o novo. É muito provável que isso não seja necessário no futuro. Precisamos apenas equipar o modelo com conhecimento de negócios e experiência de domínio e permitir que cada engenheiro de desenvolvimento use ferramentas inteligentes. Esse conhecimento pode ser transferido para o processo de pesquisa e desenvolvimento. ferramentas, e se tornará a imagem à direita mostrada acima, agora é uma cadeia de ferramentas completa para DevOps. Após acumular um grande número de ativos de código e documentos, esses ativos são classificados e reunidos com o grande modelo. Por meio de RAG e SFT, o modelo é incorporado em cada link da ferramenta DevOps, gerando assim mais dados, formando tal encaminhamento. ciclo, neste processo, os desenvolvedores da linha de frente podem aproveitar os dividendos ou capacidades trazidos pelos ativos.
O texto acima é minha introdução, de uma perspectiva macro, aos principais fatores que afetam a eficiência de P&D de grandes modelos, bem como às duas mudanças mais importantes na forma: a primeira é a mudança na forma de interação humano-computador, e a segunda é a mudança na forma como o conhecimento é transferido. Devido a diversas limitações técnicas e problemas na fase de desenvolvimento de grandes modelos, o que fazemos de melhor é o modo de interação humano-computador Copilot, então a seguir apresentaremos um pouco de nossa experiência e como criar o melhor modo de interação Copiloto humano-computador. .
Crie sua melhor pose de copiloto
Acreditamos que o modelo de interação humano-computador de desenvolvimento de código atualmente só pode resolver problemas como pequenas tarefas, problemas que requerem adoção manual e problemas de alta frequência, como a conclusão de código que a IA nos ajuda a gerar um parágrafo, nós aceitamos isso. e depois gerar outro parágrafo, vamos pegar outra seção. Esse é um problema muito frequente, e também há o problema da saída curta. Não geraremos um projeto de uma vez, ou mesmo geraremos uma classe. função ou algumas linhas de cada vez. porque nós fazemos isso? Na verdade, tem muito a ver com as limitações das capacidades do próprio modelo.
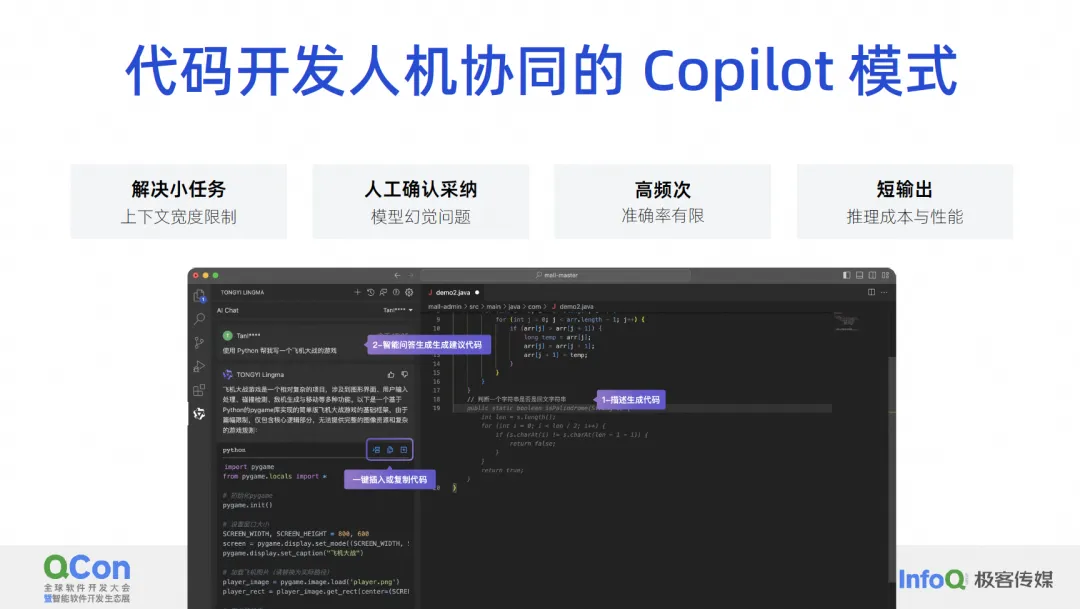
Como nossa largura de contexto atual ainda é muito limitada, se quisermos completar um requisito, não há como entregar todo o conhecimento prévio a ele de uma vez, então podemos usar o Agente para dividi-lo em um monte de pequenas tarefas e resolvê-los passo a passo. Ou deixe-o completar a tarefa mais simples no modo Copilot, como gerar um pequeno trecho de código de acordo com um comentário. Isso é o que chamamos de resolução de pequenas tarefas.
Em termos de adoção manual, os humanos agora precisam fazer julgamentos sobre os resultados gerados por grandes modelos de código. O que estamos fazendo bem atualmente pode ser uma taxa de adoção de 30% a 40%, o que significa que mais da metade de nossos códigos gerados são realmente imprecisos ou não atendem às expectativas dos desenvolvedores, por isso devemos eliminar constantemente os problemas de ilusão.
Porém, o mais importante para que modelos grandes sejam realmente utilizáveis no nível de produção é a confirmação manual. Então, não gere muitos modelos de alta frequência, mas gere um pouco de cada vez, pois o custo de confirmar manualmente se este código é. OK também afeta o desempenho. Este artigo falará sobre alguns de nossos pensamentos e o que fazemos, e resolverá o problema de precisão limitada por meio de alta frequência. Além disso, a produção curta se deve principalmente a questões de desempenho e custo.
O modelo atual de assistente de código atinge com muita precisão algumas limitações técnicas de modelos grandes, de modo que tal produto pode ser lançado rapidamente. Em nossa opinião, o modelo Copilot que os desenvolvedores mais gostam são as seguintes quatro palavras-chave: necessidades rígidas e de alta frequência, ao alcance, sabendo o que quero e exclusivas para mim.

A primeira é que precisamos resolver cenários de alta frequência e de necessidade urgente, para que os desenvolvedores possam sentir que essa coisa é realmente útil, e não apenas um brinquedo.
O segundo está ao nosso alcance, ou seja, pode ser despertado a qualquer momento e pode nos ajudar a resolver problemas a qualquer momento. Não preciso mais procurar códigos em vários buscadores como antes. É como se ele estivesse ao meu lado e pudesse acordá-lo a qualquer momento para me ajudar a resolver problemas.
A terceira é saber o que penso, ou seja, a precisão com que ele responde às minhas perguntas e o momento em que ele responde às minhas perguntas são muito importantes.
Finalmente, ele precisa pertencer a mim. Ele pode compreender parte do meu conhecimento privado, em vez de apenas compreender coisas que são completamente de código aberto. Vamos discutir esses quatro pontos em detalhes.
Alta frequência é apenas necessária
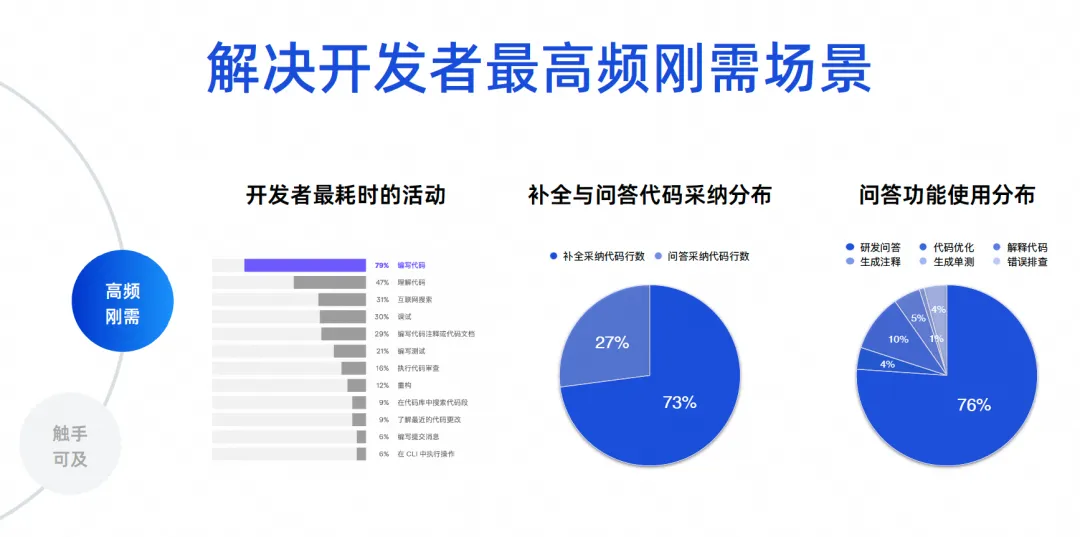
Precisamos determinar quais são os cenários mais frequentes para desenvolvimento de software. Tenho alguns dados reais aqui. Os primeiros dados vêm de um relatório ecológico de desenvolvedores feito pela JetBrains em 2023, que compilou as atividades mais demoradas dos desenvolvedores. Pode-se observar que 70% a 80% estão escrevendo código, entendendo o código. e pesquise na Internet, depure, escreva comentários e escreva testes. Esses cenários são, na verdade, funções de ferramentas de inteligência de código. Os principais problemas que produtos como o Tongyi Lingma resolvem são, na verdade, os problemas mais frequentes.
Os dois últimos dados são análises de dados de centenas de milhares de usuários do Tongyi Lingma Online. 73% do código que adotamos online atualmente vem de tarefas de conclusão e 27% vem da adoção de tarefas de perguntas e respostas. Portanto, hoje, um grande número de IAs substituem as pessoas na escrita de códigos e ainda são gerados nas entrelinhas do IDE. Este é um resultado refletido na situação real. Em seguida, vem a proporção de uso da função de perguntas e respostas, 76% da proporção vem de perguntas e respostas de P&D e os 10% restantes são uma série de tarefas de código, como otimização e interpretação de código. Portanto, a grande maioria dos desenvolvedores ainda usa nossas ferramentas para solicitar algum conhecimento comum de P&D ou usa linguagem natural para gerar alguns algoritmos a partir de grandes modelos de código para resolver alguns pequenos problemas.
Os próximos 23% são nossas tarefas de codificação realmente detalhadas. Isso é para dar a todos uma visão dos dados. Portanto, temos nossos objetivos principais. Primeiro, precisamos resolver o problema de geração de código, principalmente entre linhas. Em segundo lugar, é necessário resolver os problemas de precisão e profissionalismo das questões de P&D.
Dentro do alcance

Em última análise, queremos falar sobre a criação de uma experiência de programação envolvente. Esperamos que a maioria dos problemas enfrentados pelos desenvolvedores hoje possam ser resolvidos dentro do IDE, em vez de ter que saltar para fora.
Qual foi a nossa experiência no passado? Quando você encontrar um problema, você deve pesquisar na Internet ou perguntar a outras pessoas e, em seguida, fazer seu próprio julgamento depois de perguntar. Finalmente, escreva o código, copie-o, coloque-o no IDE para depuração e compilação e verifique novamente se existe. falhar. Isso consumirá muito tempo. Esperamos poder perguntar diretamente ao modelo grande no IDE e deixar que o modelo grande gere código para mim, para que a experiência seja muito agradável. Através dessa escolha técnica, resolvemos o problema da experiência de programação imersiva.
A tarefa de conclusão é uma tarefa sensível ao desempenho, e sua saída precisa estar em 300 a 500 milissegundos, de preferência não mais que um segundo, então temos um modelo de parâmetro pequeno, que é usado principalmente para gerar código, e a maior parte de seu treinamento O corpus também vem do código. Embora os parâmetros do modelo sejam pequenos, a precisão da geração do código é muito alta.
A segunda é realizar tarefas especiais. Ainda temos 20% a 30% das tarefas reais provenientes delas, incluindo sete tarefas como geração de anotações, testes unitários, otimização de código e solução de problemas de erros operacionais.
Atualmente usamos um modelo de parâmetros moderados. As principais considerações aqui são, em primeiro lugar, a eficiência da geração e, em segundo lugar, o ajuste. Para um modelo de parâmetros muito grandes, nosso custo de ajuste é muito alto, mas neste modelo de parâmetros médios, seu entendimento de código e efeitos de geração de código já são bons, então escolhemos o modelo de parâmetros médios.
Então, em modelos grandes, especialmente ao responder a mais de 70% das nossas questões de P&D, buscamos alta precisão e conhecimento em tempo real. Portanto, sobrepomos nossa tecnologia RAG por meio de um modelo de parâmetro máximo, permitindo que ela se conecte a uma base de conhecimento baseada na Internet quase em tempo real, de modo que a qualidade e o efeito de suas respostas sejam muito altos e possam eliminar bastante as ilusões do modelo e melhorar a resposta. qualidade. Apoiamos toda a experiência de programação imersiva através de três desses modelos.

O segundo ponto é que precisamos implementar vários terminais, porque somente cobrindo mais terminais poderemos cobrir mais desenvolvedores. Atualmente, Tongyi Lingma suporta código VS e JetBrains. Ele resolve principalmente problemas de disparo, problemas de exibição e alguns problemas de interatividade.
No nível central, nosso serviço de agente local é um processo independente. Haverá comunicação entre este processo e o plug-in acima. Este processo aborda principalmente alguns recursos principais do código, incluindo conclusão inteligente de código, gerenciamento de sessão e agentes.
Além disso, os serviços de análise de sintaxe também são muito importantes. Precisamos de análise de sintaxe para resolver problemas de referência entre arquivos. Se quisermos melhorar a recuperação local, também precisaremos de um mecanismo leve de recuperação de vetores locais. Portanto, todo o serviço de back-end pode ser expandido rapidamente dessa forma.
Também temos um recurso: temos um pequeno modelo offline local de alguns décimos de B para implementar o preenchimento de linha única em idiomas individuais. Isso pode ser feito offline, incluindo JetBrains. Recentemente, a JetBrains também lançou um pequeno modelo que é executado localmente. . Dessa forma, alguns dos nossos problemas de segurança e privacidade de dados, como gerenciamento de sessão local e armazenamento local, são todos colocados no computador local.

sabe o que eu penso
Eu sei o que penso em relação à ferramenta de plug-in IDE, acho que há vários pontos. O primeiro é o tempo de acionamento. Quando acionado, também tem um grande impacto na experiência do desenvolvedor. Por exemplo, devo acioná-lo ao entrar em um espaço? Deve ser acionado quando o IDE gerar um prompt? Deve ser acionado ao excluir este código? Provavelmente temos mais de 30 a 50 cenários para resolver. Se o acionamento do código neste cenário pode ser resolvido por meio de regras, desde que o exploremos cuidadosamente e investiguemos a experiência do desenvolvedor, podemos resolvê-lo. .
Mas em termos de duração da geração de código, achamos que é mais difícil. Porque em diferentes locais e diferentes áreas de edição, o comprimento do código que ele gera afeta diretamente nossa experiência. Se os desenvolvedores tendem a gerar apenas uma única linha de código, o problema é que o desenvolvedor não consegue entender todo o conteúdo gerado. Por exemplo, ao gerar uma função, ele não sabe o que a função vai fazer, ou ao gerar um if. declaração, ele não sabe o que está dentro da declaração if. Qual é a lógica de negócios? Não há como julgar completamente as unidades funcionais, o que afeta sua experiência.
Se usarmos algumas regras fixas para fazer isso, também causará um problema, ou seja, será relativamente rígido. Portanto, nossa abordagem é na verdade baseada nas informações semânticas do código. Por meio de treinamento e um grande número de amostras, o modelo entende por quanto tempo deve ser gerado em qual cenário hoje. Implementamos o modelo para determinar automaticamente o nível de classe, função. nível, A intensidade de geração no nível do bloco lógico e no nível da linha é chamada de tomada de decisão de intensidade de geração adaptativa. Ao fazer muito pré-treinamento, permitimos a percepção do modelo, melhorando assim a precisão da geração. Achamos que este também é um item técnico fundamental.
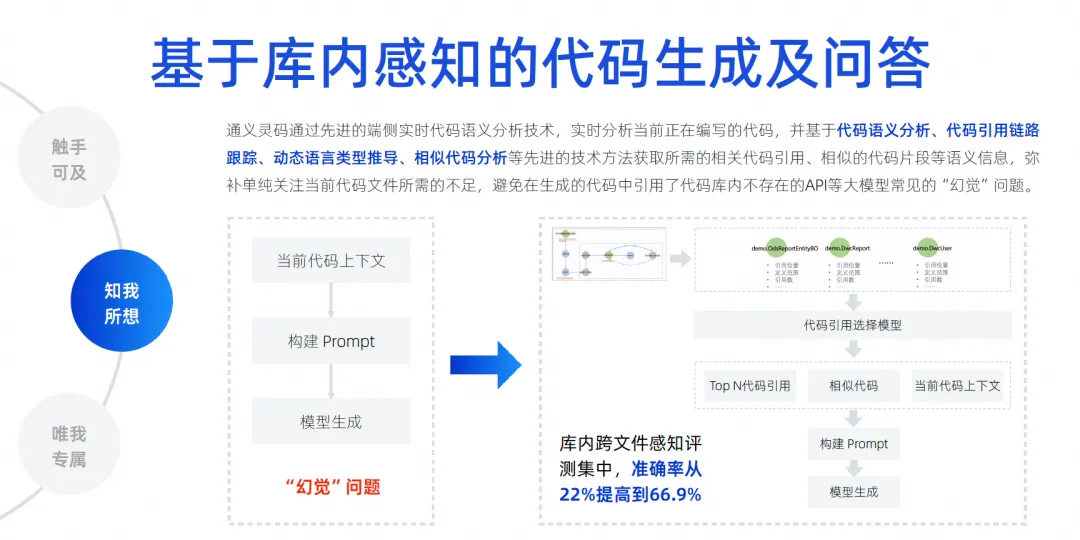
A coisa mais crítica daqui para frente é como eliminar a ilusão do modelo, porque somente quando a ilusão for suficientemente eliminada é que a nossa taxa de adoção poderá ser melhorada. Portanto, devemos implementar o reconhecimento de contexto entre arquivos na biblioteca. Aqui, fazemos muitas análises semânticas baseadas em código, rastreamento de cadeia de referência, código semelhante e derivação dinâmica de tipo de linguagem.
O mais importante é tentar todos os meios para adivinhar que tipo de conhecimento prévio o desenvolvedor pode precisar para preencher esta posição. Essas coisas também podem envolver algumas linguagens, frameworks, hábitos de usuário, etc. contexto, priorize-as, coloque as informações mais críticas no contexto e, em seguida, entregue-as ao modelo grande para derivação, permitindo que o modelo grande elimine ilusões. Através desta tecnologia, podemos obter um conjunto de testes de reconhecimento de contexto entre arquivos. Nossa precisão aumentou de 22% para 66,9% . Ainda estamos melhorando constantemente o efeito de conclusão.
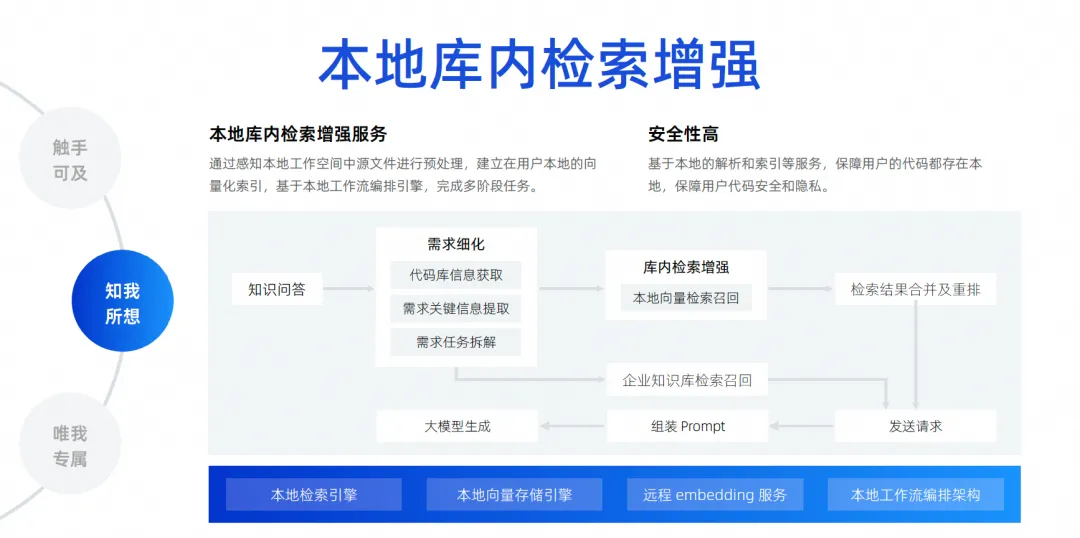
O último é o nosso aprimoramento de pesquisa local na biblioteca. Como acabei de dizer, o reconhecimento de contexto apenas adivinha o contexto do desenvolvedor no local do gatilho. Um cenário mais comum é que hoje os desenvolvedores querem fazer uma pergunta e deixar o modelo grande me ajudar a resolver um problema com base em todos os arquivos da biblioteca local, como me ajudar a corrigir um bug, me ajudar a adicionar um requisito, me ajudar preencher um arquivo e implementar automaticamente adições, exclusões, modificações e pesquisas, e até mesmo adicionar uma nova versão do pacote ao meu arquivo Pompt. Na verdade, existem muitas necessidades como essa, na verdade precisamos conectar um mecanismo de pesquisa. para o modelo grande. Como é impossível colocar todos os arquivos de todo o projeto no modelo grande, devido ao impacto da largura do contexto, devemos usar uma tecnologia chamada aprimoramento de pesquisa local na biblioteca .
Esta função visa realizar nossas perguntas e respostas gratuitas com base na biblioteca e estabelecer um serviço de aprimoramento de pesquisa local na biblioteca. Julgamos que este método é o melhor para a experiência dos desenvolvedores e tem a mais alta segurança.
O código não precisa ser carregado na nuvem para completar todo o link. Da perspectiva de todo o link, depois que um desenvolvedor fizer uma pergunta, iremos para a base de código para extrair as principais informações necessárias para desmontar a tarefa. Após a conclusão da desmontagem, realizaremos a pesquisa e recuperação do vetor local e, em seguida, realizaremos a pesquisa e recuperação do vetor local. mesclar e reorganizar os resultados da pesquisa e pesquisar a base de conhecimento de dados interna da empresa, porque a empresa possui gerenciamento unificado da base de conhecimento, que é de nível empresarial. Por fim, todas as informações são resumidas e enviadas ao grande modelo, para que o grande modelo possa gerar e resolver problemas.

Só para mim
Acho que se as empresas quiserem obter um efeito muito bom com grandes modelos de código, não poderão escapar desse nível. Por exemplo, como realizar cenários personalizados para dados corporativos, por exemplo, na fase de gerenciamento de projetos, como gerar grandes modelos de acordo com alguns formatos e especificações inerentes de requisitos/tarefas/conteúdos de defeitos, ajudando-nos a realizar a desmontagem automática e a renovação automática de alguns requisitos. Escrita, resumo automático, etc.
O estágio de desenvolvimento pode ser o que todos prestam mais atenção. As empresas costumam dizer que devem ter especificações de código que estejam em conformidade com as da própria empresa, fazer referência às bibliotecas de terceiros da própria empresa, chamar APIs para gerar SQL, inclusive usando algum front-end. frameworks, bibliotecas de componentes, etc. autodesenvolvidos pela empresa, todos pertencem a cenários de desenvolvimento. Os cenários de teste também devem gerar casos de teste que atendam às especificações da empresa e até mesmo compreendam o negócio. Em cenários de operação e manutenção, você deve sempre buscar o conhecimento de operação e manutenção da empresa e, em seguida, responder perguntas para obter algumas APIs de operação e manutenção da empresa para gerar código rapidamente. Esses são os cenários para personalização de dados empresariais que acreditamos que precisamos realizar. A abordagem específica é conseguir isso através do aprimoramento da recuperação ou do treinamento de ajuste fino.
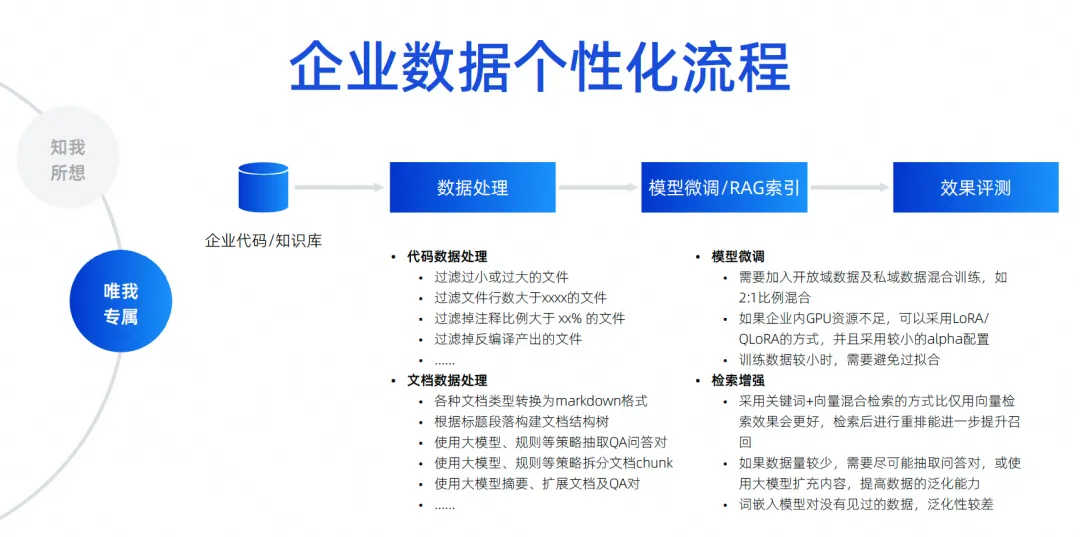
Listei aqui alguns cenários simples e itens aos quais prestar atenção, incluindo como o código deve ser processado, como os documentos devem ser processados e o código deve ser filtrado, limpo e estruturado antes de poder ser usado.
Durante nosso processo de treinamento, devemos considerar a mistura de dados de domínio aberto e dados de domínio privado. Por exemplo, precisamos fazer alguns ajustes de parâmetros diferentes em termos de aprimoramento de recuperação, temos que considerar diferentes estratégias de aprimoramento de recuperação que estamos constantemente explorando, incluindo como atingir as informações contextuais de que precisamos em cenários de geração de código. atingir as informações contextuais das respostas que precisamos no cenário de perguntas e respostas é o aprimoramento da recuperação.
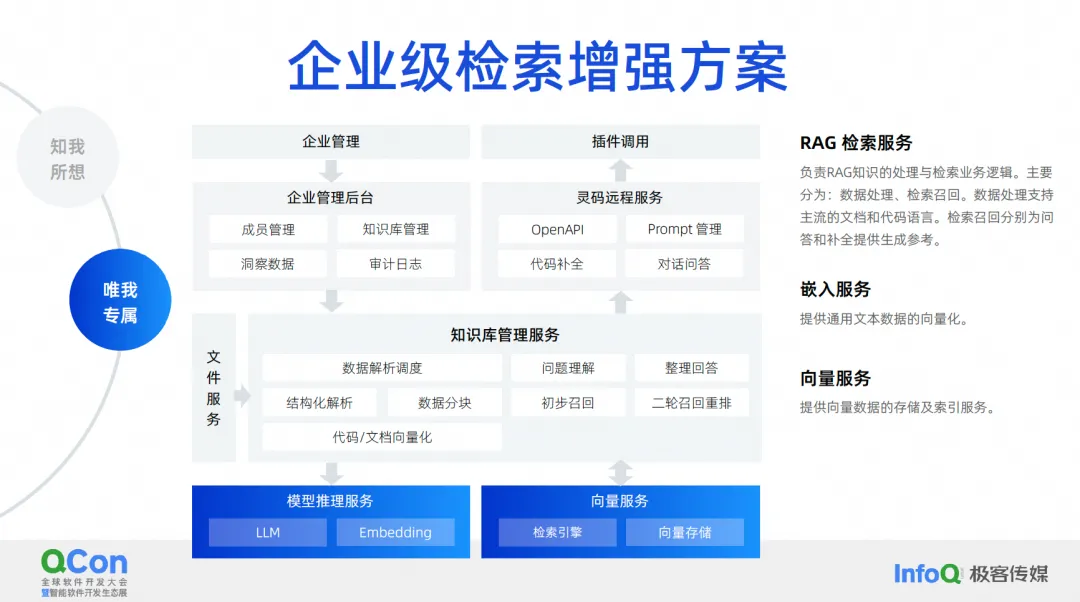
O que queremos fazer é uma solução de aprimoramento de recuperação de nível empresarial . O diagrama de arquitetura atual da solução de aprimoramento de recuperação de nível empresarial é mais ou menos assim. No meio está o serviço de gerenciamento da base de conhecimento, incluindo agendamento de análise de dados, compreensão de perguntas, organização de respostas, análise estruturada, segmentação de dados, etc. Os recursos principais estão no meio, e abaixo estão nossos serviços de incorporação mais comumente usados ., incluindo serviços para grandes modelos, armazenamento e recuperação de vetores.
Acima estão alguns back-ends que gerenciamos. Nesse cenário, eles suportam nosso aprimoramento de recuperação de documentos e aprimoramento de recuperação de geração de código. A geração de código visa completar a recuperação e aprimoramento deste cenário. Os métodos e tecnologias de processamento necessários são, na verdade, ligeiramente diferentes daqueles dos documentos.
No passado, realizamos pesquisas acadêmicas com a Universidade Fudan por vários anos e estamos muito gratos por seus esforços. Também publicamos alguns artigos. Naquela época, os resultados do nosso conjunto de testes também foram baseados em um modelo de 1.1. para 1B, juntamente com o aprimoramento de pesquisa, na verdade, a precisão e o efeito podem atingir o mesmo efeito de um modelo 7B ou superior.
Evolução futura do produto do agente de desenvolvimento de software
Acreditamos que o futuro desenvolvimento de software entrará definitivamente na era do Agente, o que significa que ele terá alguma autonomia e poderá usar nossas ferramentas com muita facilidade, entender as intenções humanas, concluir o trabalho e, eventualmente, formar um software multifuncional, conforme mostrado em a figura. Modelo colaborativo de agentes.

Ainda em março deste ano, o nascimento de Devin realmente nos fez sentir que esse assunto estava realmente acelerado. Nunca imaginamos que esse assunto pudesse concluir um projeto empresarial real. Nunca tínhamos imaginado isso no passado, e até sentimos que esse assunto. ainda pode demorar um ano, mas seu surgimento nos faz sentir que hoje podemos realmente desmontar centenas ou milhares de etapas em grandes modelos e executá-las passo a passo. Se surgirem problemas, também podemos refletir sobre nós mesmos e iterar sobre nós mesmos. forte capacidade de desmantelamento e capacidade de raciocínio nos surpreendeu muito.
Com o nascimento do Devin, vários especialistas e estudiosos começaram a investir, incluindo o nosso Laboratório Tongyi, que lançou imediatamente um projeto chamado OpenDevin. Este projeto ultrapassou 20.000 estrelas em apenas algumas semanas. Percebe-se que todos estão muito entusiasmados com esta área. Então, imediatamente abrimos o código-fonte do projeto Agent do SWE, elevando a taxa de solução do SWE-bench para mais de 10%. Os modelos grandes no passado estavam todos na faixa de alguns por cento, e aumentá-lo para 10% já está próximo do desempenho de Devin, então julgamos que a pesquisa acadêmica neste campo pode ser muito rápida,
Vamos fazer um palpite ousado. É muito provável que de junho a setembro, em meados de 2024, a taxa de solução do banco SWE exceda 30%. Vamos fazer um palpite ousado: se ele conseguir atingir uma taxa de resolução de 50 a 60 por cento, seu conjunto de testes será, na verdade, alguns problemas reais do Github. Deixe a IA resolver os problemas no Github, corrigir bugs e resolver essas necessidades. Se este conjunto de testes puder fazer com que a taxa de conclusão autônoma da IA atinja 50 ou 60%, acreditamos que ele poderá realmente ser implementado no nível de produção. Pelo menos alguns defeitos simples podem ser corrigidos por ele, que são alguns dos desenvolvimentos mais recentes que vimos na indústria.
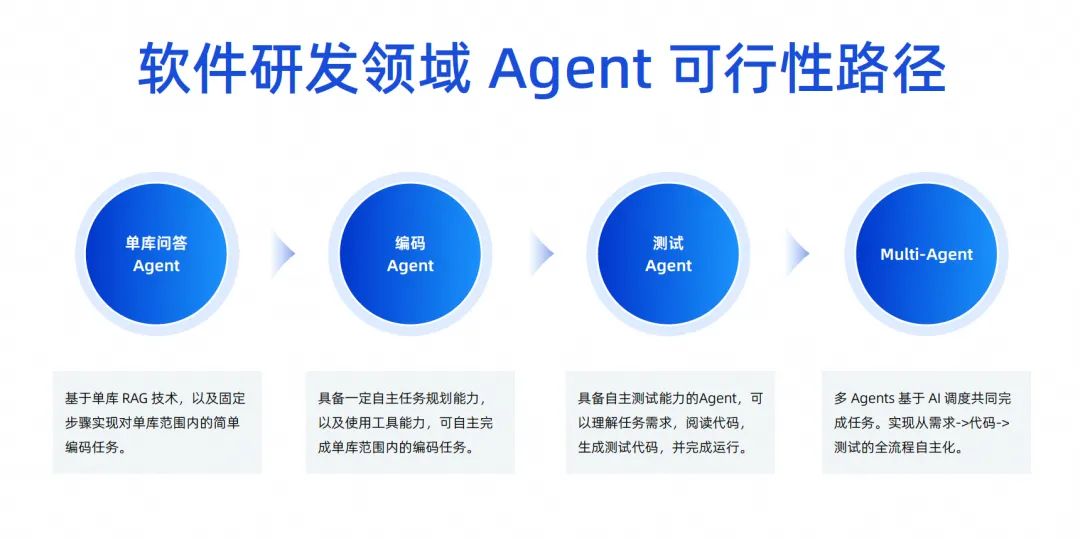
No entanto, esta imagem não pode ser concretizada imediatamente. Do ponto de vista técnico, iremos implementá-la gradualmente nestas quatro etapas.
Na primeira etapa, ainda estamos trabalhando em um agente de perguntas e respostas para banco de dados único. Este campo é muito avançado. Atualmente, estamos trabalhando em um agente de perguntas e respostas para banco de dados único, que estará online em um futuro próximo.
Na próxima etapa, esperamos lançar um agente que possa concluir tarefas de codificação de forma independente. Sua principal função é ter um certo grau de capacidade de planejamento independente. Ele pode usar algumas ferramentas para compreender o conhecimento prévio e concluir tarefas de codificação de forma independente em uma única. biblioteca, não entre bibliotecas, você pode imaginar que um requisito tem várias bases de código, e então o front-end também é alterado, e o back-end também é modificado e, finalmente, um requisito é formado. .
Portanto, primeiro implementamos o agente de codificação de uma única biblioteca e, em seguida, faremos o agente de teste. O agente de teste pode concluir automaticamente algumas tarefas de teste com base nos resultados gerados pelo agente de codificação, incluindo a compreensão dos requisitos da tarefa, lendo o. código, gerando casos de teste e executando de forma autônoma.
Se a taxa de sucesso destas duas etapas for relativamente alta, passaremos para a terceira etapa. Permita que vários agentes trabalhem juntos para concluir tarefas com base no agendamento de IA, obtendo assim a autonomia de todo o processo, desde os requisitos até o código e os testes.
Do ponto de vista da engenharia, procederemos passo a passo para garantir que cada etapa atinja uma melhor implementação no nível de produção e, em última análise, produza produtos. Mas do ponto de vista acadêmico, a velocidade de pesquisa deles será mais rápida que a nossa. Agora estamos discutindo do ponto de vista acadêmico e de engenharia, e temos um terceiro ramo que é a evolução do modelo. Esses três caminhos são algumas das pesquisas que estamos realizando atualmente em conjunto com o Alibaba Cloud e o Tongyi Lab.
Eventualmente, formaremos uma arquitetura conceitual multiagente. Os usuários podem se comunicar com o modelo grande, e o modelo grande pode dividir tarefas, e então haverá um sistema de colaboração multiagente. Este Agente pode conectar algumas ferramentas e ter seu próprio ambiente de execução. Então, vários Agentes podem colaborar entre si e também compartilharão alguns mecanismos de contexto.
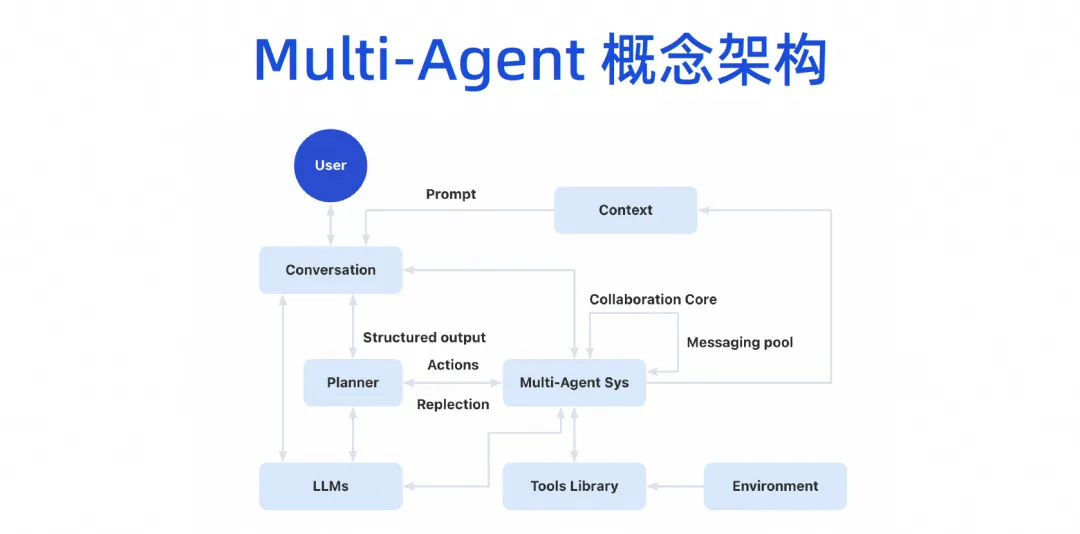
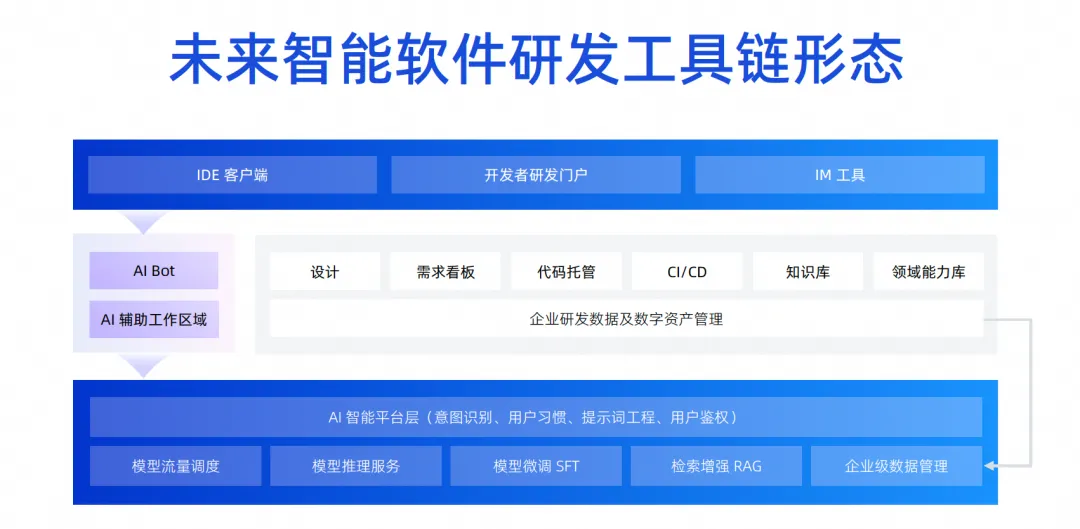
Esta imagem do produto será dividida em três camadas. A parte inferior é a camada básica. Para empresas, a camada básica pode ser concluída primeiro. Por exemplo, um grande modelo de código agora pode ser introduzido. Embora não tenhamos implementado o AI Bot imediatamente, agora temos os recursos do plug-in de geração de código IDE e já podemos fazer algum trabalho, que é o modelo Copilot.
O modo copiloto evolui a camada de Agente acima da camada de infraestrutura. Na verdade, a infraestrutura pode ser reutilizada. O aprimoramento da recuperação, o treinamento de ajuste fino e a base de conhecimento que deveriam ser feitos podem ser feitos agora. A classificação desse conhecimento e o acúmulo de ativos vêm do acúmulo da plataforma DevOps original. Agora você pode combinar a camada de capacidade básica atual com toda a cadeia de ferramentas DevOps por meio de alguns projetos de prompt word.
Fizemos alguns experimentos no estágio de requisitos, se quisermos que este modelo grande realize a desmontagem automática de um requisito, talvez precisemos apenas combinar alguns dados de desmontagem anteriores e requisitos atuais em um prompt para o modelo grande. e pessoal atribuído melhor. No experimento, constatou-se que a precisão dos resultados é bastante elevada.
Na verdade, toda a cadeia de ferramentas DevOps não requer Agente ou Copiloto para tudo. Agora usamos alguns projetos de prompt word e há muitos cenários que podem ser habilitados imediatamente, incluindo depuração automática em nosso processo CICD, perguntas e respostas inteligentes no campo da base de conhecimento, etc.
Após implementar vários agentes, o agente pode ser exposto no IDE, no portal do desenvolvedor, na plataforma DevOps ou até mesmo em nossa ferramenta de IM. Na verdade, é uma inteligência antropomórfica. O próprio agente terá seu próprio espaço de trabalho. Neste espaço de trabalho, nossos desenvolvedores ou gerentes podem monitorar como ele nos ajuda a concluir a escrita do código, como nos ajuda a concluir os testes e como é usado na Internet. completar o trabalho, terá seu próprio espaço de trabalho e, finalmente, realizará o processo completo de toda a tarefa.
Clique aqui para experimentar o Tongyi Lingma.
A equipe da Google Python Foundation foi demitida. O Google confirmou as demissões, e as equipes envolvidas em Flutter, Dart e Python correram para a lista de favoritos do GitHub - Como as linguagens e estruturas de programação de código aberto podem ser tão fofas? Xshell 8 abre teste beta: suporta protocolo RDP e pode se conectar remotamente ao Windows 10/11 Quando os passageiros se conectam ao WiFi ferroviário de alta velocidade , a "maldição de 35 anos" dos codificadores chineses surge quando eles se conectam à alta velocidade. rail WiFi. A primeira ferramenta de pesquisa de IA do MySQL com suporte de longo prazo versão 8.4 GA Perplexica : Completamente de código aberto e gratuito, uma alternativa de código aberto ao Perplexity Os executivos da Huawei avaliam o valor do código aberto Hongmeng: Ele ainda tem seu próprio sistema operacional, apesar da supressão contínua. por países estrangeiros. A empresa alemã de software automotivo Elektrobit abriu o código-fonte de uma solução de sistema operacional automotivo baseada no Ubuntu.