
Este artigo foi compartilhado pela comunidade Huawei Cloud " Estatísticas e análises de texto Python do básico ao avançado " por Lemony Hug.
Na era digital de hoje, os dados de texto estão em toda parte e contêm uma riqueza de informações, desde postagens em mídias sociais até artigos de notícias e trabalhos acadêmicos. A análise estatística é um requisito comum para processar esses dados de texto, e Python, como uma linguagem de programação poderosa e fácil de aprender, nos fornece uma grande variedade de ferramentas e bibliotecas para implementar a análise estatística de dados de texto. Este artigo apresentará como usar Python para implementar estatísticas de texto em inglês, incluindo estatísticas de frequência de palavras, estatísticas de vocabulário e análise de sentimento de texto.
estatísticas de frequência de palavras
A contagem de frequência de palavras é uma das tarefas mais básicas na análise de texto. Existem muitas maneiras de implementar estatísticas de frequência de palavras em Python. O seguinte é um dos métodos básicos:
def contagem_palavras(texto):
# Remova a pontuação do texto e converta para minúsculas
texto = texto.inferior()
para char em '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~':
texto = texto.replace(char, ' ')
# Divida o texto em uma lista de palavras
palavras = texto.split()
# Crie um dicionário vazio para armazenar contagens de palavras
contagem_palavras = {}
# Percorra cada palavra e atualize a contagem no dicionário
por palavra em palavras:
se palavra em word_count:
contagem_palavra[palavra] += 1
outro:
contagem_palavras[palavra] = 1
retornar contagem de palavras
# Código de teste
se __nome__ == "__main__":
text = "Este é um texto de exemplo. Usaremos este texto para contar as ocorrências de cada palavra."
contagem_palavras = contagem_palavras(texto)
para palavra, conte em word_count.items():
print(f"{palavra}: {contagem}")
Este código define uma função que aceita uma string de texto como parâmetro e retorna um dicionário contendo cada palavra do texto e o número de vezes que ela ocorre. Aqui está uma análise linha por linha do código: count_words(text)
def count_words(text):: Define uma função que aceita um parâmetro , a string de texto a ser processada. count_words text
text = text.lower(): converte sequências de texto em letras minúsculas, o que torna as estatísticas de palavras independentes de maiúsculas e minúsculas.
for char in '!"#$%&\'()*+,-./:;<=>?@[\\]^_{|}~':`: Este é um loop que percorre todos os sinais de pontuação no texto.
text = text.replace(char, ' '): substitui todos os sinais de pontuação do texto por um espaço, o que remove o sinal de pontuação do texto.
words = text.split(): divida a sequência de texto processada em uma lista de palavras por espaços.
word_count = {}: Cria um dicionário vazio que armazena contagens de palavras, onde as chaves são as palavras e os valores são o número de vezes que aquela palavra aparece no texto.
for word in words:: Itere cada palavra na lista de palavras.
if word in word_count:: Verifique se a palavra atual já existe no dicionário.
word_count[word] += 1: se a palavra já existir no dicionário, adicione 1 à sua contagem de ocorrências.
else:: Se a palavra não estiver no dicionário, execute o código a seguir.
word_count[word] = 1: adiciona uma nova palavra ao dicionário e define sua contagem de ocorrências como 1.
return word_count: Retorna um dicionário contendo contagens de palavras.
if __name__ == "__main__":: verifique se o script está sendo executado como programa principal.
text = "This is a sample text. We will use this text to count the occurrences of each word.": Define um texto de teste.
word_count = count_words(text): Chame a função, passando o texto de teste como parâmetro, e salve o resultado em uma variável. count_words word_count
for word, count in word_count.items():: itere cada par de valores-chave no dicionário. word_count
print(f"{word}: {count}"):Imprime cada palavra e seu número de ocorrências.
Os resultados em execução são os seguintes
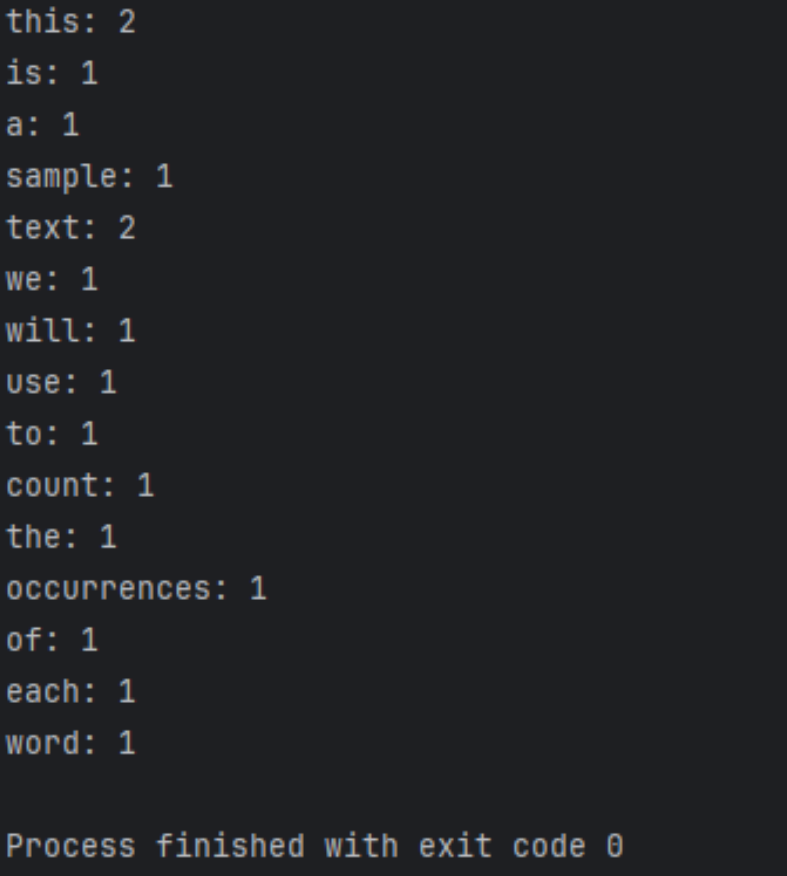
Otimização e expansão adicionais
importar re
de coleções importar contador
def contagem_palavras(texto):
# Divida o texto em uma lista de palavras (incluindo palavras hifenizadas) usando expressões regulares
palavras = re.findall(r'\b\w+(?:-\w+)*\b', text.lower())
# Use o contador para contar rapidamente o número de ocorrências de palavras
word_count = Contador(palavras)
retornar contagem de palavras
# Código de teste
se __nome__ == "__main__":
text = "Este é um texto de exemplo. Usaremos este texto para contar as ocorrências de cada palavra."
contagem_palavras = contagem_palavras(texto)
para palavra, conte em word_count.items():
print(f"{palavra}: {contagem}")
Este código difere do exemplo anterior das seguintes maneiras:
- Expressões regulares são usadas para dividir o texto em listas de palavras. Esta expressão regular corresponde a palavras, incluindo palavras hifenizadas (como "alta tecnologia").
re.findall()\b\w+(?:-\w+)*\b - As classes da biblioteca padrão do Python são usadas para contagem de palavras, o que é mais eficiente e o código é mais limpo.
Counter
Esta implementação é mais avançada, mais robusta e lida com casos mais especiais, como palavras hifenizadas.
Os resultados em execução são os seguintes
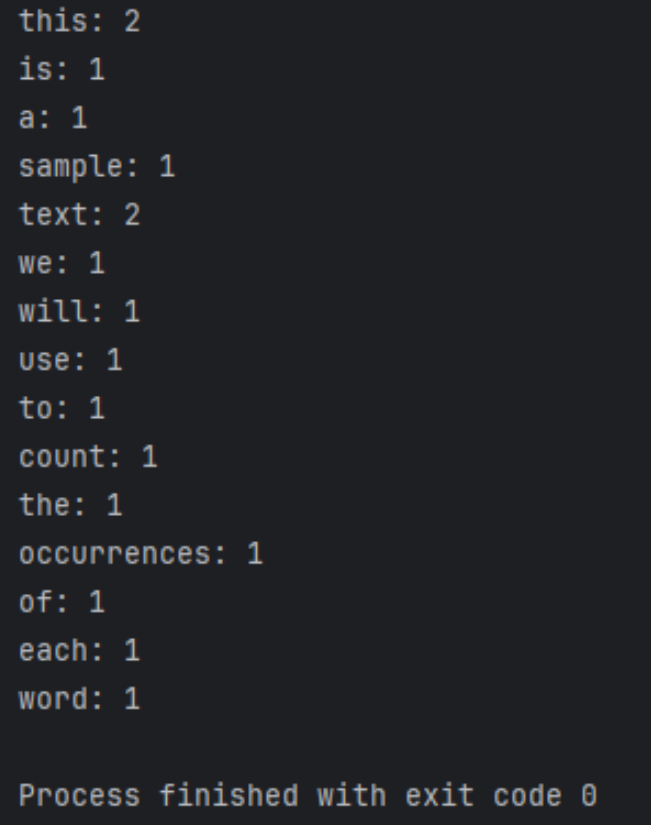
Pré-processamento de texto
Antes da análise do texto, geralmente é necessário o pré-processamento do texto, incluindo remoção de pontuação, processamento de maiúsculas e minúsculas, lematização e lematização. Isso pode tornar os dados de texto mais padronizados e precisos.
Use modelos mais avançados
Além dos métodos estatísticos básicos, também podemos usar modelos de aprendizado de máquina e aprendizado profundo para análise de texto, como classificação de texto, reconhecimento de entidade nomeada e análise de sentimento. Existem muitas bibliotecas poderosas de aprendizado de máquina em Python, como Scikit-learn e TensorFlow, que podem nos ajudar a construir e treinar esses modelos.
Lidar com dados em grande escala
Quando confrontados com dados de texto em grande escala, poderemos ter de considerar tecnologias como o processamento paralelo e a computação distribuída para melhorar a eficiência do processamento e reduzir os custos de computação. Existem algumas bibliotecas e frameworks em Python que podem nos ajudar a realizar essas funções, como Dask e Apache Spark.
Combine com outras fontes de dados
Além dos dados de texto, também podemos combinar outras fontes de dados, como dados de imagem, dados de séries temporais e dados geoespaciais, para realizar análises mais abrangentes e multidimensionais. Existem muitas ferramentas de processamento e visualização de dados em Python que podem nos ajudar a processar e analisar esses dados.
Resumir
Este artigo fornece uma introdução detalhada sobre como usar Python para implementar estatísticas de texto em inglês, incluindo estatísticas de frequência de palavras, estatísticas de vocabulário e análise de sentimento de texto. Aqui está um resumo:
Estatísticas de frequência de palavras :
- Através de funções Python
count_words(text), o texto é processado e a frequência de ocorrências de palavras é contada. - O pré-processamento de texto inclui a conversão do texto em letras minúsculas, remoção de pontuação, etc.
- Use um loop para iterar as palavras do texto e use um dicionário para armazenar as palavras e suas ocorrências.
Otimização e expansão adicionais :
- Introduza expressões regulares e
Counterclasses para tornar seu código mais eficiente e robusto. - Use expressões regulares para dividir o texto em listas de palavras, incluindo o tratamento de palavras hifenizadas.
- O uso de
Counterclasses para contagem de palavras simplifica o código.
Pré-processamento de texto :
O pré-processamento de texto é uma etapa importante na análise de texto, incluindo remoção de pontuação, processamento de maiúsculas e minúsculas, lematização e lematização, etc., para normalizar os dados do texto.
Use modelos mais avançados :
São apresentadas as possibilidades de uso de modelos de aprendizado de máquina e aprendizado profundo para análise de texto, como classificação de texto, reconhecimento de entidade nomeada e análise de sentimento.
Lidar com dados em grande escala :
São mencionadas considerações técnicas ao processar dados de texto em grande escala, incluindo processamento paralelo e computação distribuída para melhorar a eficiência e reduzir custos.
Combinado com outras fontes de dados :
É explorada a possibilidade de combinar outras fontes de dados para análises mais abrangentes e multidimensionais, como dados de imagens, dados de séries temporais e dados geoespaciais.
Resumir :
O conteúdo apresentado neste artigo é enfatizado, bem como as perspectivas para trabalhos futuros, incentivando novas pesquisas e explorações para se adaptar a tarefas de análise de dados de texto mais complexas e diversas.
Ao estudar este artigo, os leitores podem dominar os métodos básicos de uso do Python para estatísticas de texto em inglês e entender como otimizar e expandir ainda mais esses métodos para lidar com tarefas de análise de texto mais complexas.
Clique para seguir e conhecer as novas tecnologias da Huawei Cloud o mais rápido possível~