
Autor: Ye Jidong, da equipe de big data da Internet da vivo
Este artigo apresenta principalmente todo o processo de análise e solução do problema de estouro de memória causado por vazamento de memória online causado pela classe FileSystem.
Definição de vazamento de memória : um objeto ou variável que não é mais usado pelo programa ainda ocupa espaço de armazenamento na memória e a JVM não pode recuperar adequadamente o objeto ou variável alterado. Um único vazamento de memória pode não parecer ter um grande impacto, mas a consequência do acúmulo de vazamentos de memória é o estouro de memória.
Estouro de memória (falta de memória) : refere-se a um erro em que o programa não pode continuar a ser executado devido a espaço de memória alocado insuficiente ou uso indevido durante a execução do programa. Neste momento, um erro OOM será relatado, que é o. o chamado estouro de memória.
1. Fundo
Xiaoye estava matando pessoas no Canyon of Kings no fim de semana e seu telefone de repente recebeu um grande número de alarmes de CPU da máquina. Se o uso da CPU exceder 80%, ele emitirá um alarme. para o serviço. Este serviço é um serviço muito importante para a equipe do projeto Xiaoye. Xiaoye desligou rapidamente o Honor of Kings e ligou o computador para verificar o problema.


Figura 1.1 Alarme de CPU Alarme de GC completo
2. Descoberta de problemas
2.1 Monitoramento e visualização
Como a CPU de serviço e o GC completo são alarmantes, abra o monitoramento de serviço para visualizar o monitoramento da CPU e o monitoramento do GC completo. Você pode ver que ambos os monitores apresentam uma protuberância anormal ao mesmo tempo. Full GC é particularmente frequente, especula-se que o alarme de aumento de uso da CPU pode ser causado por Full GC .
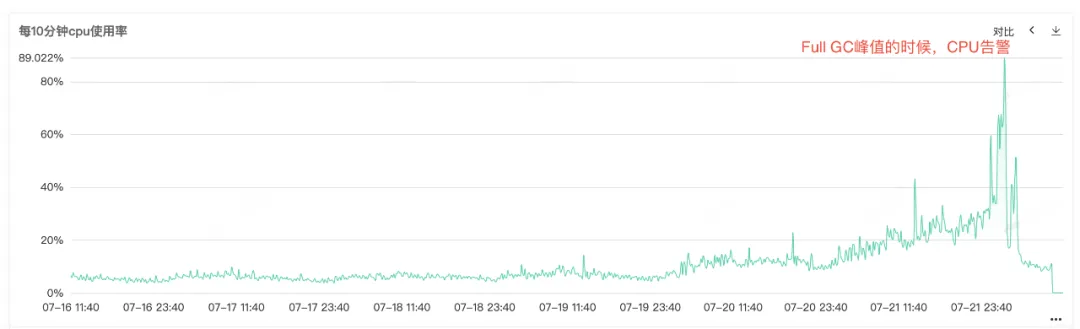
Figura 2.1 Uso da CPU
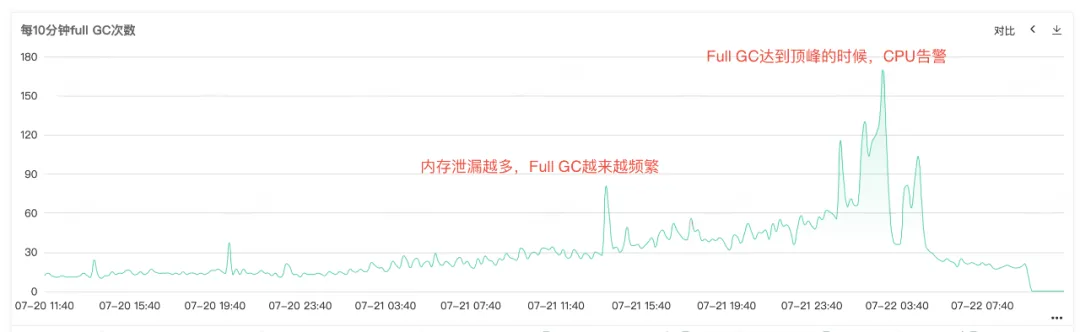
Figura 2.2 Tempos completos de GC
2.2 Vazamento de memória
A partir do Full Gc frequente, podemos saber que deve haver problemas com a reciclagem de memória do serviço. Portanto, verifique o monitoramento da memória heap, da memória da geração antiga e da memória da geração mais recente do serviço. na geração antiga, podemos ver que a memória residente da geração antiga está ficando cada vez maior. Cada vez mais objetos da geração antiga não podem ser reciclados e, finalmente, toda a memória residente está ocupada e um óbvio vazamento de memória pode ser visto. .
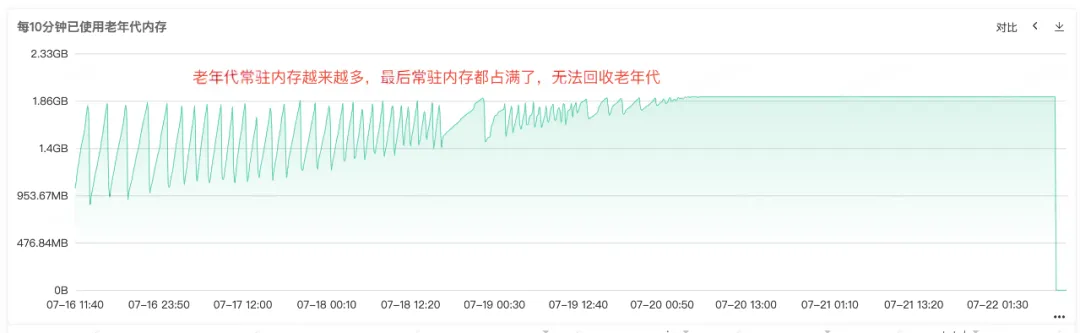
Figura 2.3 Memória da geração antiga
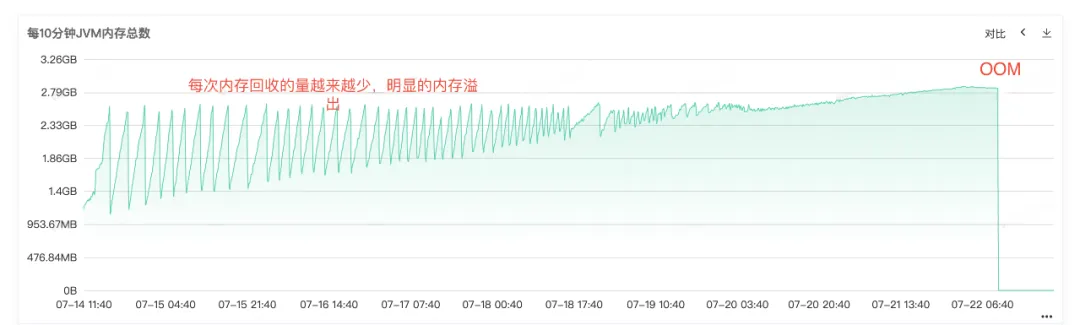
Figura 2.4 Memória JVM
2.3 Estouro de memória
A partir do log de erros online, também podemos saber claramente que o serviço acabou em OOM, então a causa raiz do problema é que o vazamento de memória fez com que a memória transbordasse OOM e, finalmente, o serviço ficou indisponível .

Figura 2.5 Registro OOM
3. Solução de problemas
3.1 Análise de memória heap
Depois que ficou claro que a causa do problema era um vazamento de memória, descartamos imediatamente o instantâneo da memória de serviço e importamos o arquivo de despejo para o MAT (Eclipse Memory Analyzer) para análise. Suspeitos de Vazamento Insira a visualização do ponto de vazamento suspeito.
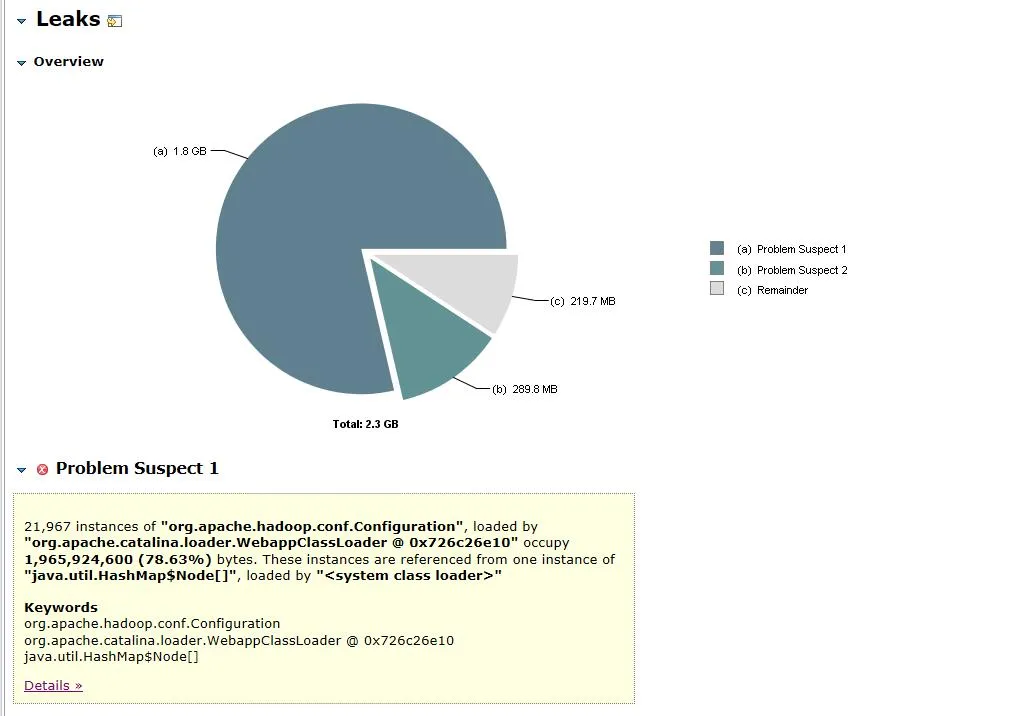
Figura 3.1 Análise de objetos de memória
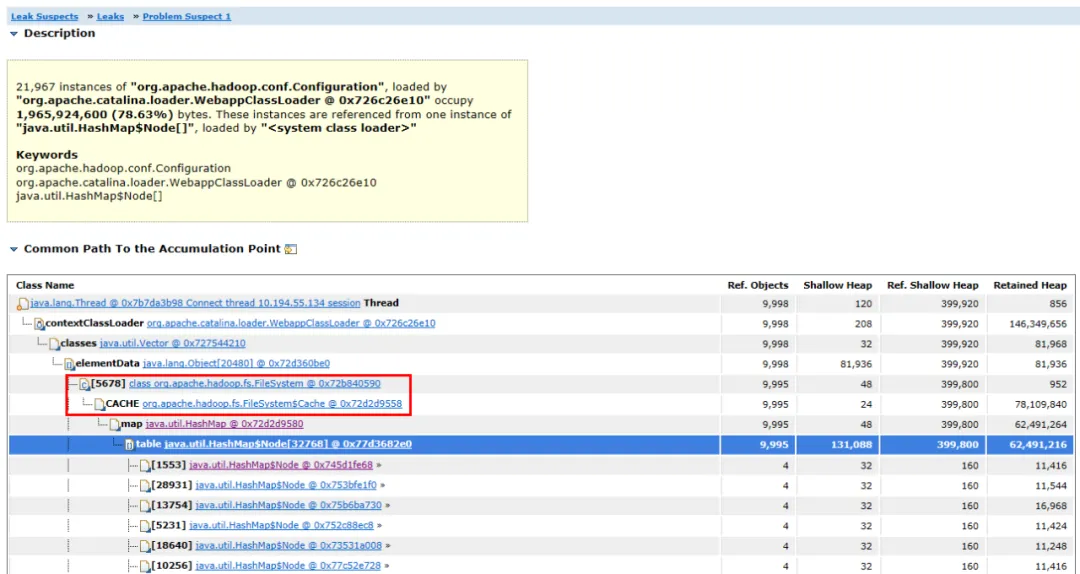
Figura 3.2 Diagrama de ligação de objetos
O arquivo de despejo aberto é mostrado na Figura 3.1. O objeto org.apache.hadoop.conf.Configuration é responsável por 1,8 G da memória heap de 2,3 G, representando 78,63% de toda a memória heap .
Expanda os objetos associados e os caminhos do objeto, você pode ver que o principal objeto ocupado é HashMap . O HashMap é mantido pelo objeto FileSystem.Cache e a camada superior é FileSystem . Pode-se adivinhar que o vazamento de memória provavelmente está relacionado ao FileSystem.
3.2 Análise do código-fonte
Depois de encontrar o objeto com vazamento de memória, a próxima etapa é encontrar o código com vazamento de memória.
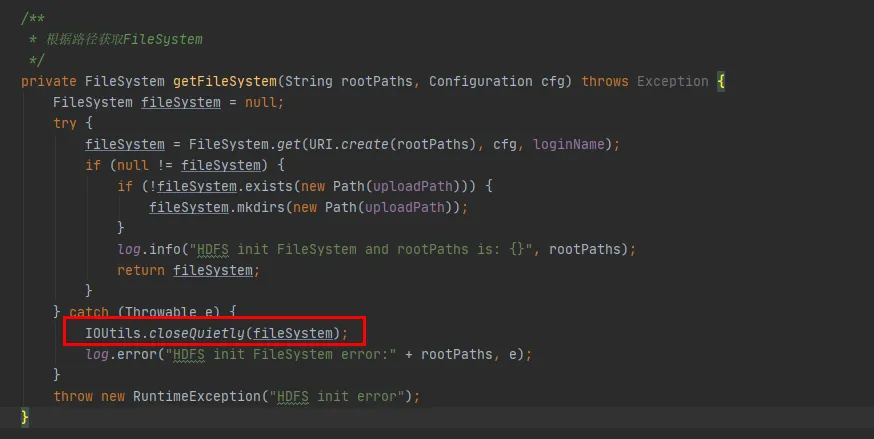
Na Figura 3.3, podemos encontrar esse trecho de código em nosso código. Cada vez que ele interagir com hdfs, ele estabelecerá uma conexão com hdfs e criará um objeto FileSystem. Mas depois de usar o objeto FileSystem, o método close() não foi chamado para liberar a conexão.
No entanto, a instância de configuração e a instância de FileSystem aqui são variáveis locais. Após a execução do método, esses dois objetos devem ser recicláveis pela JVM.
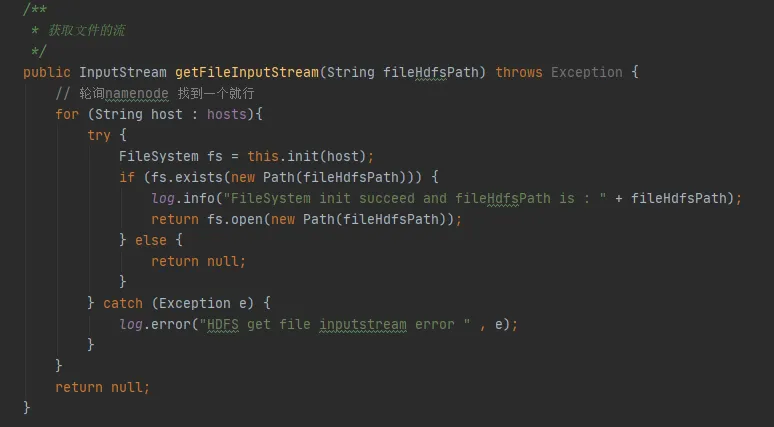
Figura 3.3
(1) Conjectura 1: FileSystem possui objetos constantes?
A seguir, veremos o código-fonte da classe FileSystem. Os métodos init e get de FileSystem são os seguintes:
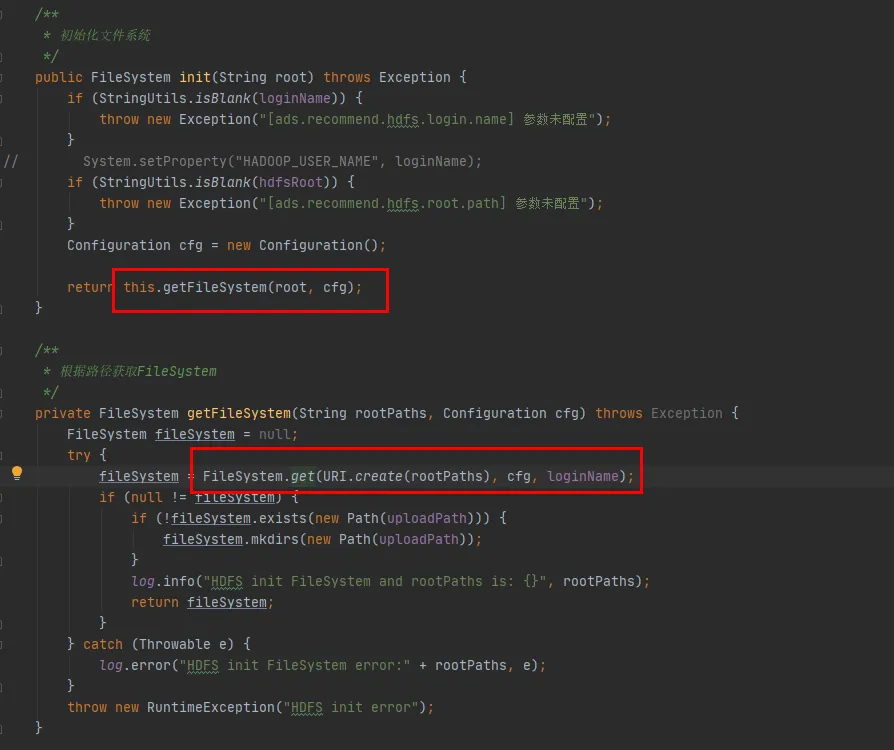

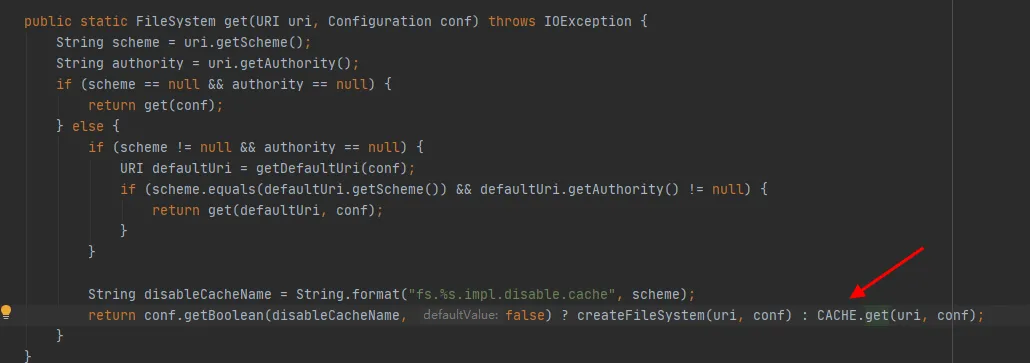
Figura 3.4
Como pode ser visto na última linha de código da Figura 3.4, há um CACHE na classe FileSystem e disableCacheName é usado para controlar se é necessário obter objetos do cache . O valor padrão deste parâmetro é falso. Ou seja, FileSystem será retornado por padrão através do objeto CACHE .

Figura 3.5
Na Figura 3.5 podemos ver que CACHE é um objeto estático da classe FileSystem. Em outras palavras, o objeto CACHE sempre existirá e não será reciclado. O objeto constante CACHE existe e a conjectura foi verificada.
Então dê uma olhada no método CACHE.get:
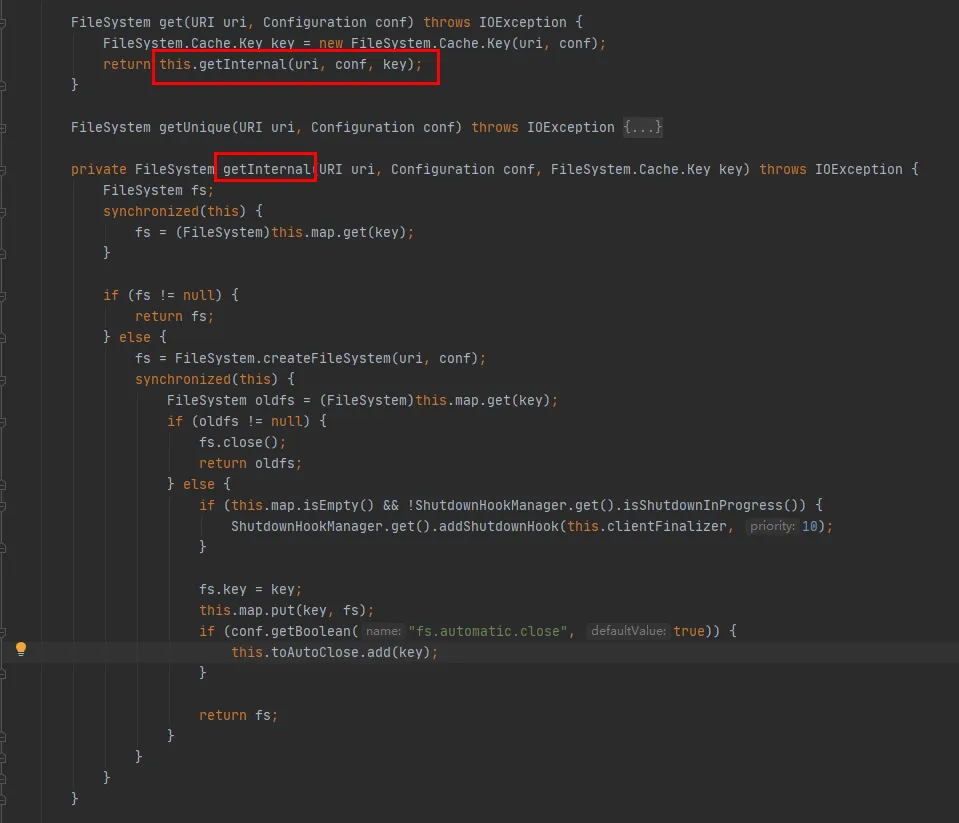
Como pode ser visto neste código:
-
Um Mapa é mantido dentro da classe Cache, que é usada para armazenar em cache objetos FileSystem conectados. A chave do Mapa é o objeto Cache.Key. FileSystem será obtido sempre por meio de Cache.Key. Caso não seja obtido, o processo de criação continuará.
-
Um Set (toAutoClose) é mantido dentro da classe Cache, que é usada para armazenar conexões que precisam ser fechadas automaticamente. As conexões nesta coleção são fechadas automaticamente quando o cliente é fechado.
-
Cada FileSystem criado será armazenado no Mapa na classe Cache com Cache.Key como chave e FileSystem como Valor. Quanto a saber se haverá vários caches para o mesmo URI hdfs durante o armazenamento em cache, você precisa verificar o método hashCode de Cache.Key.
O método hashCode de Cache.Key é o seguinte:

As variáveis de esquema e autoridade são do tipo String. Se estiverem no mesmo URI, seu hashCode é consistente. O valor do parâmetro exclusivo é 0 sempre. Então o hashCode de Cache.Key é determinado por ugi.hashCode() .
A partir da análise de código acima, podemos resolver:
-
Durante a interação entre o código comercial e o HDFS, uma conexão FileSystem será criada para cada interação e a conexão FileSystem não será fechada no final.
-
FileSystem possui um Cache estático integrado e há um Map dentro do Cache para armazenar em cache o FileSystem que criou uma conexão.
-
O parâmetro fs.hdfs.impl.disable.cache é usado para controlar se o FileSystem precisa ser armazenado em cache. Por padrão, é falso, o que significa armazenamento em cache.
-
Map in Cache, Key é a classe Cache.Key, que determina uma Key por meio de quatro parâmetros: esquema, autoridade, ugi e unique , conforme mostrado acima no método hashCode de Cache.Key.
(2) Conjectura 2: O FileSystem armazena em cache o mesmo URI hdfs várias vezes?
O construtor FileSystem.Cache.Key é o seguinte: ugi é determinado por getCurrentUser() de UserGroupInformation.

Continue examinando o método getCurrentUser() de UserGroupInformation, como segue:

O principal é se o objeto Subject pode ser obtido por meio de AccessControlContext. Neste exemplo, quando obtido por meio de get(final URI uri, final Configuration conf, final String user), durante a depuração, verifica-se que um novo objeto Subject pode ser obtido aqui todas as vezes. Em outras palavras, o mesmo caminho hdfs armazenará em cache um objeto FileSystem todas as vezes .
A conjectura 2 foi verificada: o mesmo URI do HDFS será armazenado em cache várias vezes, fazendo com que o cache se expanda rapidamente, e o cache não defina um tempo de expiração e uma política de eliminação, eventualmente levando ao estouro de memória.
(3) Por que o FileSystem armazena em cache repetidamente?
Então, por que obtemos um novo objeto Subject sempre? Vamos dar uma olhada no código para obter o AccessControlContext, como segue:
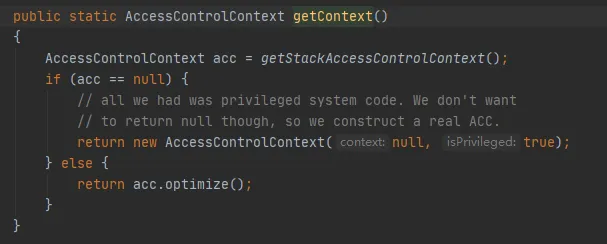
O principal é o método getStackAccessControlContext, que chama o método Native, como segue:

Este método retorna o objeto AccessControlContext das permissões do domínio de proteção da pilha atual.
Podemos ver isso através do método get(final URI uri, final Configuration conf, final String user) na Figura 3.6 , como segue:
-
Primeiro, um objeto UserGroupInformation é obtido através do método UserGroupInformation.getBestUGI .
-
Em seguida , o método get(URI uri, Configuration conf) é chamado por meio do método doAs de UserGroupInformation.
-
Figura 3.7 Implementação do método UserGroupInformation.getBestUGI Aqui, concentre-se nos dois parâmetros passados, ticketCachePath e user . ticketCachePath é o valor obtido configurando hadoop.security.kerberos.ticket.cache.path Neste exemplo, esse parâmetro não está configurado, portanto ticketCachePath está vazio. O parâmetro user é o nome de usuário passado neste exemplo.
-
ticketCachePath está vazio e user não está vazio, então o método createRemoteUser na Figura 3.7 será eventualmente executado.

Figura 3.6

Figura 3.7
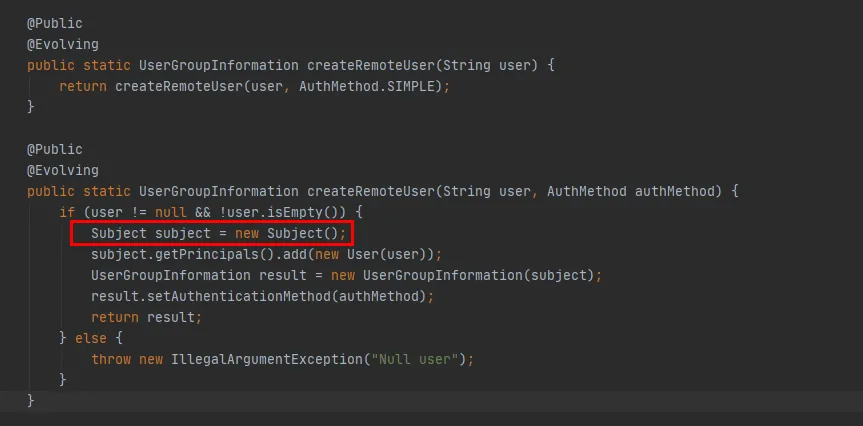
Figura 3.8
A partir do código vermelho na Figura 3.8, você pode ver que no método createRemoteUser um novo objeto Subject é criado e o objeto UserGroupInformation é criado por meio deste objeto . Neste ponto, a execução do método UserGroupInformation.getBestUGI é concluída.
A seguir, dê uma olhada no método UserGroupInformation.doAs (o último método executado por FileSystem.get(final URI uri, final Configuration conf, final String user)), como segue:
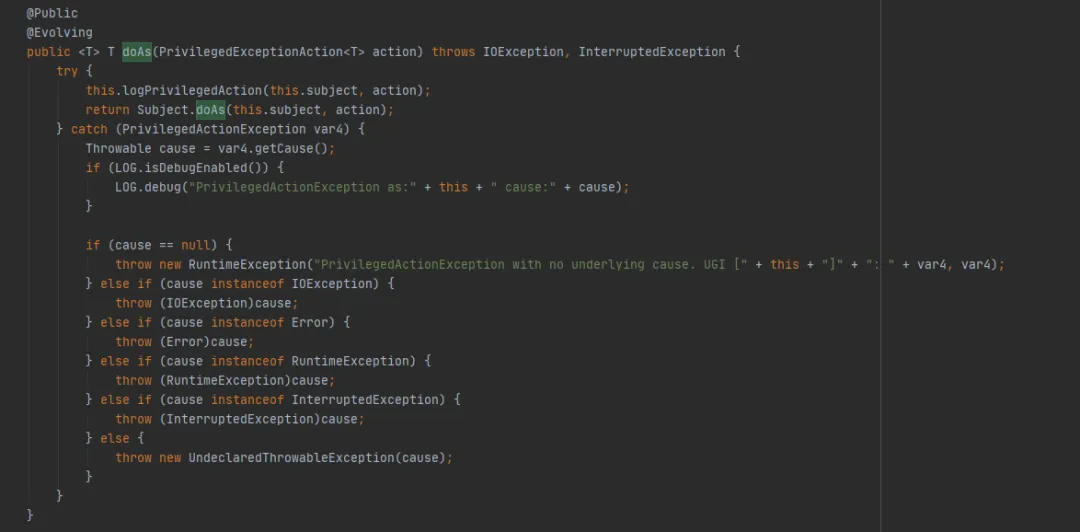
Em seguida, chame o método Subject.doAs, da seguinte forma:
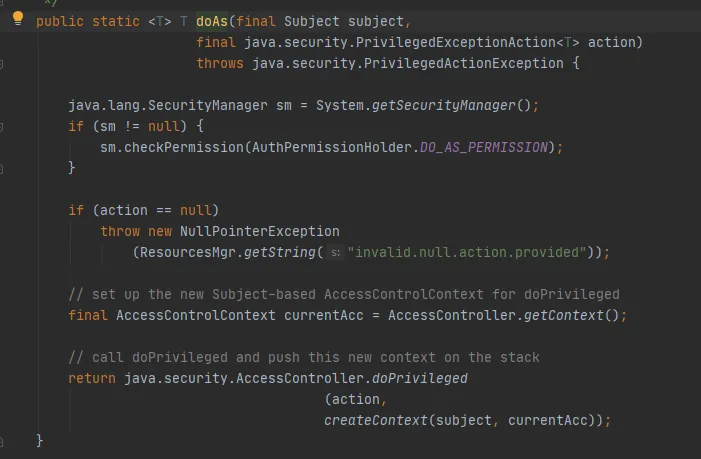
Por fim, chame o método AccessController.doPrivileged, da seguinte maneira:
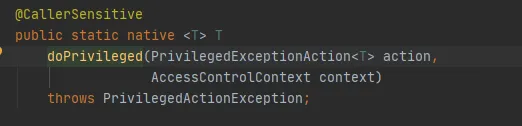
Este método é um método Native, que utilizará o AccessControlContext especificado para executar PrivilegedExceptionAction, ou seja, chamará o método run da implementação. Esse é o método FileSystem.get(uri, conf).
Neste ponto, pode-se explicar que neste exemplo, ao criar FileSystem através do método get(final URI uri, final Configuration conf, final String user), o hashCode de Cache.key armazenado no Cache de FileSystem é sempre inconsistente .
Para resumir:
-
Ao criar FileSystem por meio do método get(final URI uri, final Configuration conf, final String user) , novos objetos UserGroupInformation e Subject serão criados sempre.
-
Quando o objeto Cache.Key calcula hashCode , o que afeta o resultado do cálculo é a chamada ao método UserGroupInformation.hashCode .
-
Método UserGroupInformation.hashCode, calculado como: System.identityHashCode(subject) . Ou seja, se o Assunto for o mesmo objeto, o mesmo hashCode será retornado. Como é diferente a cada vez neste exemplo, o hashCode calculado é inconsistente.
-
Em resumo, o hashCode de Cache.key calculado a cada vez é inconsistente e o Cache do FileSystem será gravado repetidamente.
(4) Uso correto do FileSystem
Pela análise acima, como FileSystem.Cache não desempenha seu papel, por que esse Cache deveria ser projetado? Na verdade, acontece que nosso uso não está correto.
No FileSystem, existem dois métodos get sobrecarregados:
public static FileSystem get(final URI uri, final Configuration conf, final String user)
public static FileSystem get(URI uri, Configuration conf)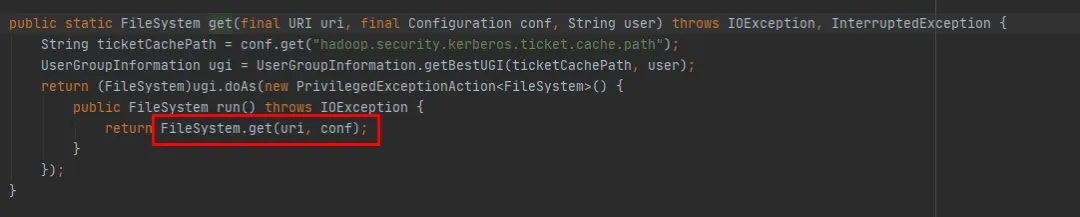
Podemos ver que o método FileSystem get(final URI uri, final Configuration conf, final String user) finalmente chama o método FileSystem get(URI uri, Configuration conf) . está faltando. Só falta a operação de criar um novo Assunto a cada vez.

Figura 3.9
Se não houver operação para criar um novo Assunto, então o Assunto da Figura 3.9 será nulo e o último método getLoginUser será usado para obter o loginUser. LoginUser é uma variável estática, portanto, assim que o objeto loginUser for inicializado com sucesso, o objeto será usado no futuro. O método UserGroupInformation.hashCode retornará o mesmo valor hashCode. Ou seja, o cache armazenado em cache no FileSystem pode ser usado com sucesso.

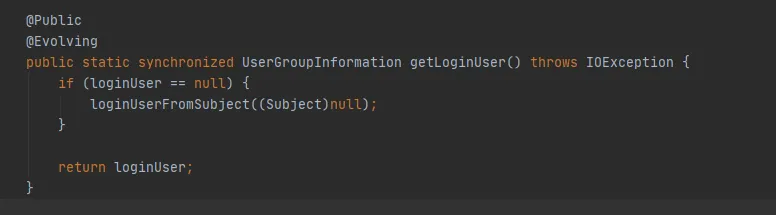
Figura 3.10
4. Solução
Após a introdução anterior, se quisermos resolver o problema de vazamento de memória do FileSystem, temos os dois métodos a seguir:
(1) Use public static FileSystem get(URI uri, Configuração conf):
-
Este método pode usar o cache do sistema de arquivos, o que significa que haverá apenas um objeto de conexão do sistema de arquivos para o mesmo URI hdfs.
-
Defina o usuário de acesso através de System.setProperty("HADOOP_USER_NAME", "hive").
-
Por padrão, fs.automatic.close=true, ou seja, todas as conexões serão fechadas através do ShutdownHook.
(2)使用public static FileSystem get(final URI uri, final Configuration conf, final String user):
-
Conforme analisado acima, este método fará com que o Cache do Sistema de Arquivos se torne inválido, e será sempre adicionado ao Mapa do Cache, fazendo com que não seja reciclado.
-
Ao usá-lo, uma solução é garantir que haja apenas um objeto de conexão FileSystem para o mesmo URI hdfs.
-
Outra solução é chamar o método close após cada uso do FileSystem, o que excluirá o FileSystem do Cache.
Com base na premissa de alterações mínimas em nosso código histórico existente, escolhemos o segundo método de modificação. Feche o objeto FileSystem após cada uso do FileSystem.
5. Resultados de otimização
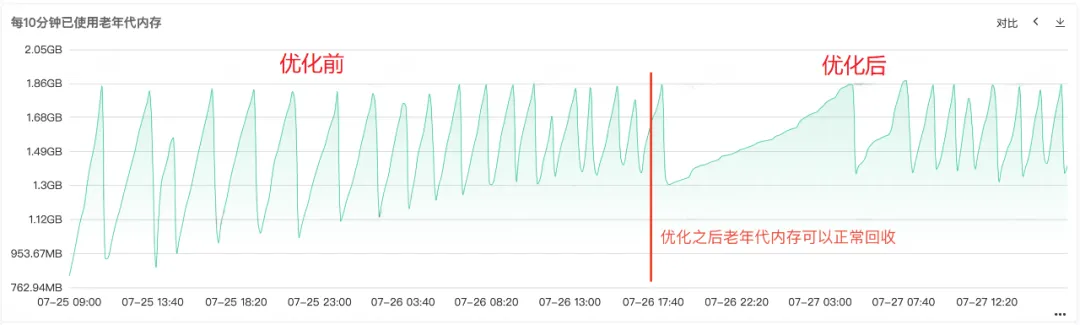
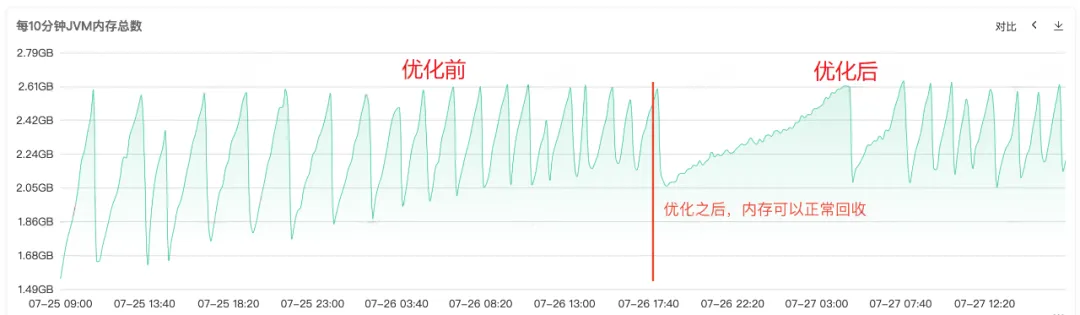
Após o código ser reparado e lançado online, conforme mostrado na Figura 1 abaixo, você pode ver que a memória da geração antiga pode ser reciclada normalmente após o reparo. Neste ponto, o problema está finalmente resolvido.
6. Resumo
O estouro de memória é um dos problemas mais comuns no desenvolvimento Java. O motivo geralmente é causado por vazamentos de memória que impedem a reciclagem normal da memória. Em nosso artigo, apresentaremos em detalhes um processo completo de processamento de estouro de memória online.
Resuma nossas soluções comuns ao encontrar estouro de memória:
(1) Gerar arquivo de memória heap :
Adicione o comando de inicialização do serviço
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/baseDeixe o serviço descarregar arquivos de memória automaticamente quando ocorrer OOM ou use o comando jam para descarregar arquivos de memória.
(2) Análise de memória heap : Use ferramentas de análise de memória para nos ajudar a analisar o problema de estouro de memória mais profundamente e encontrar a causa do estouro de memória. A seguir estão várias ferramentas de análise de memória comumente usadas:
-
Eclipse Memory Analyzer : uma ferramenta de análise de memória Java de código aberto que pode nos ajudar a localizar rapidamente vazamentos de memória.
-
VisualVM Memory Analyzer : Uma ferramenta baseada em uma interface gráfica que pode nos ajudar a analisar o uso de memória de aplicativos Java.
(3) Localize o código de vazamento de memória específico com base na análise da memória heap.
(4) Modifique o código de vazamento de memória e libere novamente para verificação.
Vazamentos de memória são uma causa comum de estouro de memória, mas não são a única causa. As causas comuns de problemas de estouro de memória incluem: objetos superdimensionados, alocação de memória heap muito pequena, chamadas de loop infinito , etc., que podem levar a problemas de estouro de memória.
Ao encontrar problemas de estouro de memória, precisamos pensar em muitos aspectos e analisar o problema de diferentes ângulos. Através dos métodos e ferramentas que mencionamos acima e de diversos monitoramentos, podemos nos ajudar a localizar e resolver problemas rapidamente e melhorar a estabilidade e disponibilidade do nosso sistema.
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes na plataforma Windows no futuro