
Os índices de banco de dados são um componente chave na otimização do desempenho de qualquer sistema de banco de dados. Sem índices eficazes, suas consultas ao banco de dados podem se tornar lentas e ineficientes, resultando em uma experiência de usuário ruim e em produtividade reduzida. Neste artigo, exploraremos algumas práticas recomendadas para criar e usar índices de banco de dados.
Autor: A Trilha Java
Fonte deste artigo e capa: https://medium.com/, traduzido pela comunidade de código aberto Axon.
Este artigo tem cerca de 2.700 palavras e deve levar 9 minutos para ser lido.
Vários algoritmos de indexação são usados em bancos de dados para melhorar o desempenho da consulta. Aqui estão alguns dos algoritmos de indexação mais comumente usados:
Índice de árvore B
Um índice B-Tree é uma estrutura de dados em árvore com autoequilíbrio que mantém a ordenação dos dados e permite pesquisas, acesso sequencial, inserções e exclusões em tempo logarítmico. A estrutura do índice B-Tree é amplamente utilizada em bancos de dados e sistemas de arquivos. Os índices B-Tree são amplamente utilizados em bancos de dados relacionais como MySQL e PostgreSQL.
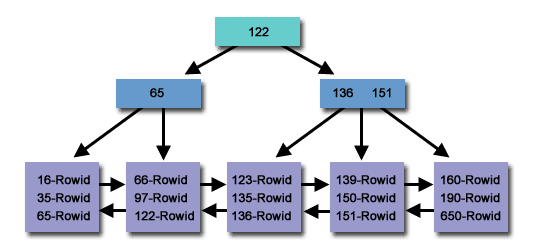
Os índices B-Tree são otimizados para consultas de intervalo porque podem localizar com eficiência todos os registros dentro de um intervalo de valores. Isso ocorre porque os registros são armazenados em ordem de classificação no índice. Aproveite o uso de comparações de colunas em expressões que usam os operadores =, >, >=, <ou .<=BETWEEN
Por exemplo, suponha que temos uma tabela de produtos com a seguinte estrutura de tabela:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
pricePodemos adicionar um índice B-Tree ao campo por meio da seguinte instrução SQL .
CREATE INDEX products_price_index ON products (price);
Índice de hash
Os índices hash são outro algoritmo de indexação popular usado para acelerar consultas. Os índices hash usam uma função hash para mapear chaves para locais de índice. Esse algoritmo de indexação é mais útil para consultas de correspondência exata, como a pesquisa de registros específicos com base em valores de chave primária . Os índices hash são comumente usados em bancos de dados na memória, como o Redis.
Os índices hash funcionam mapeando cada registro da tabela para um intervalo exclusivo com base em seu valor hash. Os valores hash são calculados usando uma função hash, uma função matemática que recebe um item de dados como entrada e retorna um valor inteiro exclusivo.
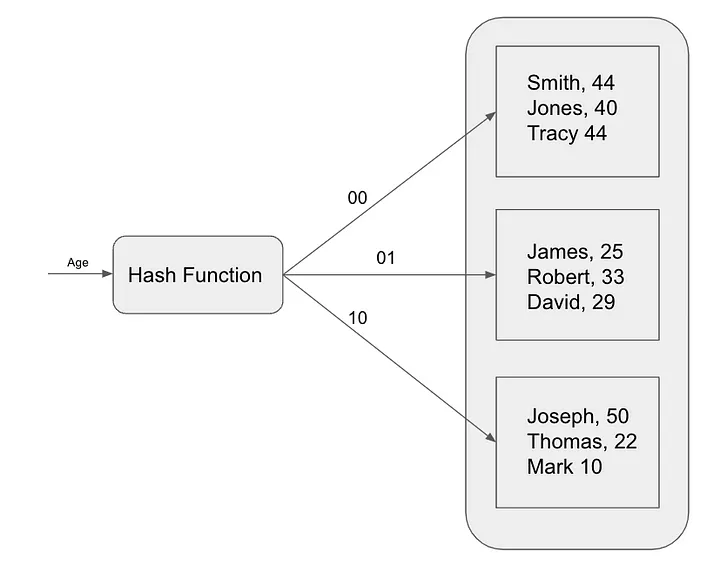
Para encontrar um registro em um índice hash, o banco de dados calcula o hash da chave de pesquisa e, em seguida, procura o intervalo correspondente. Se o registro estiver no bucket, o banco de dados retornará o registro. Caso contrário, o banco de dados realizará uma varredura completa da tabela.
Os índices hash são muito rápidos para pesquisas , mas não podem ser usados para consultar intervalos de dados de maneira eficiente . Isso ocorre porque as funções hash não preservam nenhuma ordem entre os registros da tabela.
Para executar uma consulta usando um índice hash:
- O banco de dados calcula o valor hash dos critérios de consulta.
- Encontre o bucket de hash correspondente na tabela de hash.
- O banco de dados então recupera um ponteiro para a linha da tabela com o valor hash correspondente.
- Use esses ponteiros para recuperar as linhas reais da tabela.
Suponha que temos uma tabela de produtos com a seguinte estrutura de tabela:
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(255),
price DECIMAL(10,2)
);
P: Os índices hash não são otimizados como o B-Tree?
Existem algumas situações em que um índice hash pode não ser a melhor escolha:
- Os índices hash são mais rápidos que os índices de árvore para pesquisas (para comparações de igualdade usando o operador
=ou<=>), mas não podem ser usados para consultar intervalos de dados com eficiência. - Os índices de árvore são mais lentos do que os índices hash durante a pesquisa, mas podem ser usados para consultar intervalos de dados com eficiência.
Consultas de intervalo: os índices hash não são otimizados para consultas de intervalo, onde você precisa encontrar registros dentro de um intervalo de valores (usando os operadores =, >, >=, <ou ). Neste caso, um índice B-Tree seria mais apropriado.<=BETWEEN
Classificação: os índices hash não são otimizados para classificação; você precisa classificar os registros com base em uma coluna específica. Neste caso, um índice B-Tree ou um índice clusterizado seria mais adequado.
Grandes conjuntos de dados: os índices hash podem consumir muita memória, portanto, podem não ser adequados para grandes conjuntos de dados onde o uso de memória é uma preocupação.
Podemos namecriar um índice hash na coluna usando o seguinte comando:
CREATE INDEX products_name_hash ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
CREATE INDEX products_name_tree ON products (name);
SELECT * FROM products WHERE name = 'iPhone 13 Pro';
Se usarmos um índice hash, o banco de dados calculará o valor hash da chave de pesquisa “iPhone 13 Pro” e, em seguida, procurará o intervalo correspondente. Como as funções hash são determinísticas, o banco de dados sempre encontrará registros no mesmo bucket, independentemente da ordem em que os registros são armazenados na tabela.
Se usarmos um índice de árvore, o banco de dados começará na raiz da árvore e comparará a chave de pesquisa “iPhone 13 Pro” com o valor da chave armazenada na raiz . Como a árvore está ordenada, o banco de dados encontrará rapidamente o registro que contém a chave de pesquisa.
P: Por que o B-Tree é mais otimizado para consultas de intervalo do que o índice Hash?
Agora, digamos que queremos encontrar todos os produtos com preço entre US$ 100 e US$ 200. Podemos usar a seguinte consulta:
SELECT * FROM products WHERE price BETWEEN 100 AND 200;
princípio de trabalho
Árvore B
Os índices B-Tree funcionam armazenando registros em ordem de classificação. Para encontrar registros em um índice B-Tree,
- O banco de dados começa na raiz da árvore e compara a chave de pesquisa com o valor da chave armazenada na raiz.
- Se a chave de pesquisa for igual à chave raiz, o banco de dados retornará esse registro.
- Caso contrário, o banco de dados determinará qual subárvore pesquisar em seguida com base nos resultados da comparação.
Cerquilha
Os índices hash funcionam mapeando cada registro em uma tabela para um intervalo exclusivo com base em seu valor hash. O valor hash é calculado usando uma função hash. Os índices hash distribuem dados aleatoriamente entre buckets, tornando as consultas de intervalo ineficientes. A recuperação de um intervalo de valores, como preços entre US$ 100 e US$ 200, exige a verificação de todos os intervalos nesse intervalo, o que resulta efetivamente em uma verificação completa da tabela. Os índices hash são bons para pesquisas rápidas de correspondência exata, mas não possuem a ordenação de dados necessária para consultas de intervalo eficientes.
Pergunta, por que o índice B-Tree é mais otimizado do que o índice Hash na classificação?
Os índices de árvore B-Tree classificam os dados com mais eficiência do que os índices hash porque armazenam registros em ordem de classificação. Isso permite que o banco de dados itere rapidamente pelos registros em ordem de classificação.
Os índices hash funcionam mapeando cada registro em uma tabela para um intervalo exclusivo com base em seu valor hash. Isso significa que a ordem dos registros no intervalo é aleatória. Para classificar os registros, o banco de dados precisa percorrer todos os depósitos e, em seguida, classificar os registros em cada depósito. Isso é mais lento do que usar um índice B-Tree, que armazena registros em ordem de classificação.
Podemos pricecriar um índice B-Tree na coluna usando o seguinte comando:
CREATE INDEX products_price_index ON products (price);
Agora, digamos que queremos classificar os produtos por preço em ordem crescente. Podemos usar a seguinte consulta:
SELECT * FROM products ORDER BY price ASC;
O banco de dados usará um índice de árvore B para iterar rapidamente os produtos em ordem de classificação.
Desvantagens do índice hash:
- Os índices hash não suportam consultas de intervalo ou classificação
- Os índices hash consomem muita memória
- Os índices hash não são adequados para bancos de dados atualizados com frequência
Índice de bitmap
Os índices de bitmap são usados para colunas com um pequeno número de valores distintos, como colunas booleanas ou de gênero. Os índices de bitmap são muito compactos e eficientes para colunas de cardinalidade mais baixa.
SELECT * FROM employees WHERE gender = 'Female';
Os índices de bitmap são muito eficientes em colunas de cardinalidade mais baixa, permitindo operações de configuração rápida, como uniões e interseções. Ideal para relatórios ad hoc e armazenamento de dados.
Índice de texto completo
A indexação de texto completo é usada para indexar grandes quantidades de dados de texto, como documentos ou páginas da web. Este algoritmo de indexação divide o texto em palavras ou tokens e os indexa de uma forma que permite operações de pesquisa eficientes. Os índices de texto completo são mais úteis para consultas que envolvem a pesquisa de palavras ou frases específicas no texto. A indexação de texto completo é comumente usada em mecanismos de pesquisa como o Elasticsearch.
Casos de uso para indexação de texto completo de comércio eletrônico:
A indexação de texto completo permite que aplicativos de comércio eletrônico pesquisem rapidamente grandes catálogos de produtos com base em consultas de pesquisa inseridas pelo usuário. A indexação de texto completo permite pesquisas com base em múltiplas palavras e frases, incluindo erros ortográficos, sinônimos e até mesmo conceitos relacionados. Isso torna mais fácil para os usuários encontrarem o que procuram, mesmo que não saibam o nome ou a descrição exata do produto.
Por exemplo, imagine que um cliente esteja procurando um novo par de tênis de corrida. Eles digitam “tênis de corrida” na barra de pesquisa. Com a indexação de texto completo, os aplicativos de comércio eletrônico podem pesquisar rapidamente todas as descrições, nomes e rótulos de produtos para encontrar todos os produtos relacionados a tênis de corrida. Os resultados da pesquisa são classificados por relevância, que é determinada pela frequência com que os termos de pesquisa aparecem nas informações do produto.
Sem indexação de texto completo, uma pesquisa pode considerar apenas o nome do produto, sem levar em conta outros fatores que possam ser relevantes para os clientes, como descrições ou rótulos dos produtos. Além disso, a pesquisa não pode tratar erros ortográficos ou conceitos relacionados, como "tênis de corrida" ou "tênis".
Suponha que temos uma productstabela nomeada com as seguintes colunas: id, name, descriptione tags.
CREATE FULLTEXT INDEX products_ft_index ON products(name, description, tags);
Agora, imagine que um cliente pesquise “tênis de corrida”. Podemos usar a seguinte consulta para pesquisar produtos relacionados ao termo de pesquisa:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('running shoes') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('running shoes' IN BOOLEAN MODE)
ORDER BY relevance DESC
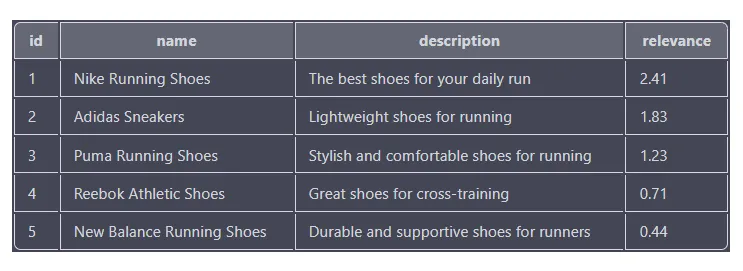
As pontuações de relevância baseiam-se na correspondência de cada produto com os termos de pesquisa, com pontuações mais altas indicando uma correspondência mais próxima. Os resultados são classificados em ordem decrescente com base na pontuação de relevância, de forma que o produto com a pontuação de relevância mais alta (tênis de corrida Nike) apareça no topo da lista.
Aqui está outro exemplo de consulta que pesquisa produtos que contêm as palavras “orgânico” e “café”:
SELECT id, name, description, MATCH(name, description, tags) AGAINST('+"organic" +"coffee"') as relevance
FROM products
WHERE MATCH(name, description, tags) AGAINST('+"organic" +"coffee"' IN BOOLEAN MODE)
ORDER BY relevance DESC;
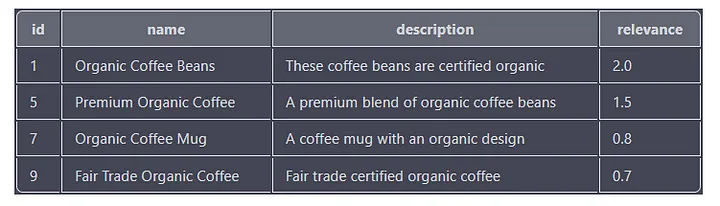
Esta consulta pesquisa todos os produtos que possuem as palavras-chave "orgânico" e "café" nas colunas de nome, descrição ou rótulo. A pontuação de relevância de cada resultado também é calculada com base no número de vezes e na posição da palavra-chave na coluna.
A saída conterá as colunas “id”, “nome”, “descrição” e “relevância”, com os resultados classificados pela coluna “relevância” em ordem decrescente.
vantagem
- Índices de texto completo funcionam muito bem para colunas baseadas em texto
- Ótimo para mecanismos de pesquisa e sistemas de gerenciamento de conteúdo
- Suporta classificação de relevância dos resultados de pesquisa
deficiência
- A indexação de texto completo ocupa muito espaço de armazenamento
- Para conjuntos de dados muito grandes, o desempenho pode degradar
- A indexação de texto completo não é adequada para dados numéricos ou categóricos
Para mais artigos técnicos, visite: https://opensource.actionsky.com/
Sobre SQLE
SQLE é uma plataforma abrangente de gerenciamento de qualidade de SQL que cobre auditoria e gerenciamento de SQL desde o desenvolvimento até ambientes de produção. Ele oferece suporte aos principais bancos de dados de código aberto, comerciais e domésticos, fornece recursos de automação de processos para desenvolvimento, operação e manutenção, melhora a eficiência on-line e melhora a qualidade dos dados.
Obter SQLE
| tipo | endereço |
|---|---|
| Repositório | https://github.com/actiontech/sqle |
| documento | https://actiontech.github.io/sqle-docs/ |
| lançar notícias | https://github.com/actiontech/sqle/releases |
| Documentação de desenvolvimento de plug-in de auditoria de dados | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |