

-
A lógica de utilização do cache é muito geral. Basicamente, o cache é verificado primeiro e, se houver, é retornado diretamente sem verificar o banco de dados e depois colocado no cache. Esta lógica geral está espalhada por todo o sistema, violando o princípio de alta coesão e baixo acoplamento. -
O código de cache e o código de lógica de negócios estão profundamente acoplados, o que não apenas reduz a legibilidade do código, mas também aumenta a complexidade do sistema. -
Caso queira trocar o cache (MDB->LDB) ou atualizar a API, todos os códigos envolvidos precisam ser alterados. -
Se você deseja resolver problemas comuns, como penetração de cache, penetração de cache, cache em cascata, etc., você precisa resolvê-los por meio do framework.

Leia os dados do cache primeiro e retorne diretamente se houver dados. Se nenhum dado for lido, leia os dados do banco de dados e atualize o cache após os dados serem retornados.
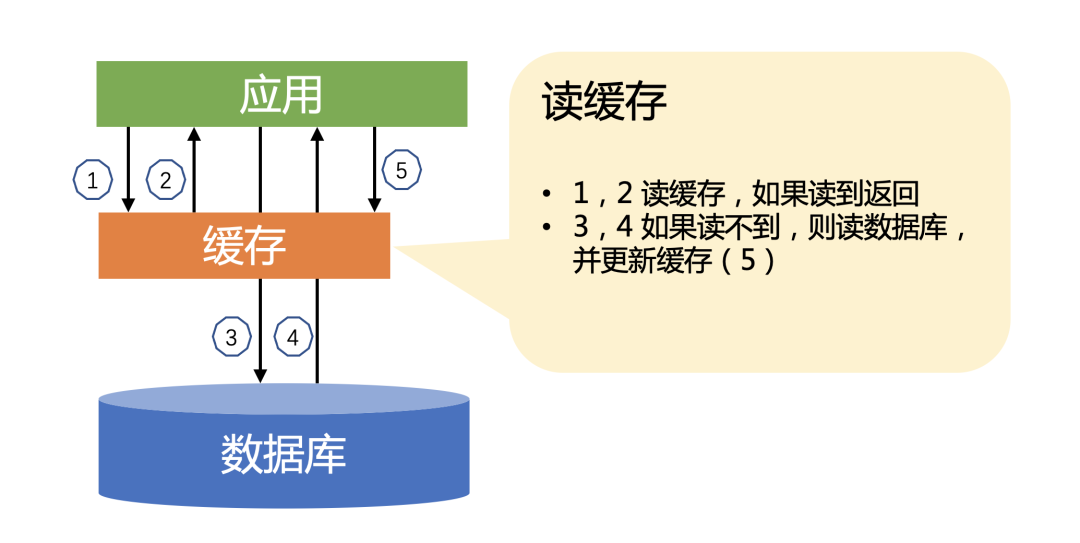
Este cenário é muito comum na codificação diária e é muito simples, mas o código real é realmente muito diferente.
▐Escrita tradicional
Qualquer que seja o cache usado, use-o diretamente e incorpore-o ao código comercial. Esse tipo de código é algo que não quero ver, seja para revisão de código ou quando as gerações futuras aprenderem código de negócios. O motivo é muito simples e não tem nada a ver com funções de negócios reais. você usa ou como você codifica o código de cache.
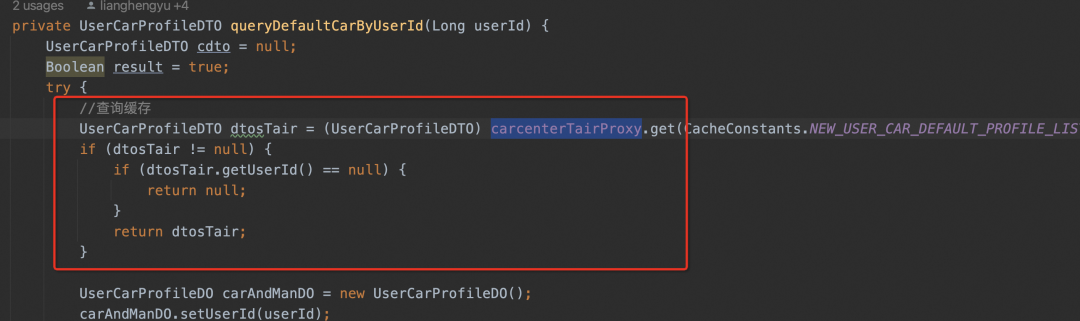

▐Uma forma mais avançada de escrever
Comparado com o método de escrita tradicional, a fim de resolver o problema de armazenamento em cache de vários formatos de dados (lista, mapa, etc.) e serialização de vários objetos (java, json), a equipe pode encapsular o armazenamento em cache em uma API simples para todos usarem . É mais fácil de usar, mas o código ainda está incorporado no código comercial e não foi eliminado.
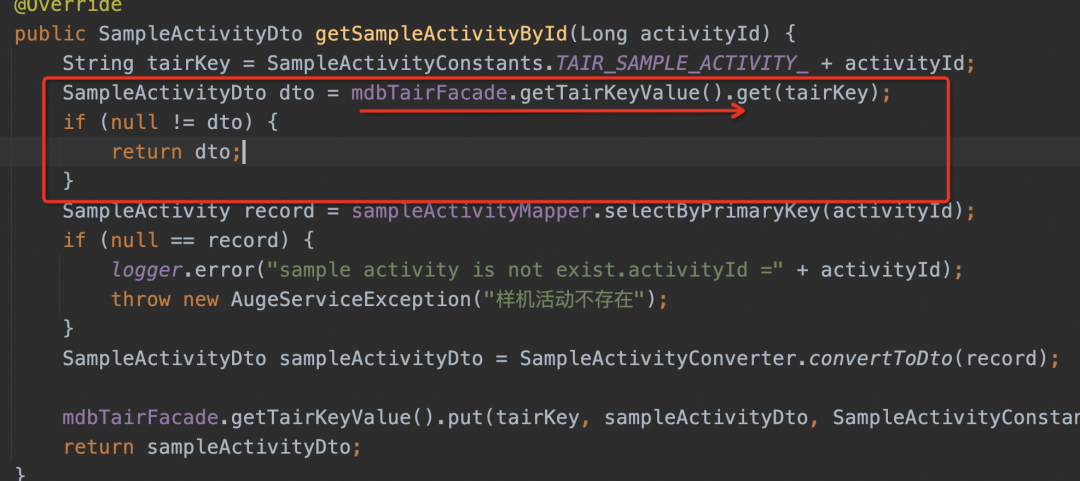
▐Como escrever anotações


Spring cache usa proxy dinâmico para processar operações relacionadas ao cache na classe proxy e, ao mesmo tempo, chama métodos na classe proxy, para que o código que opera o cache e o código de negócios possam ser separados e quando a capacidade do cache precisar para ser fortalecido posteriormente, basta modificar o método na classe proxy.
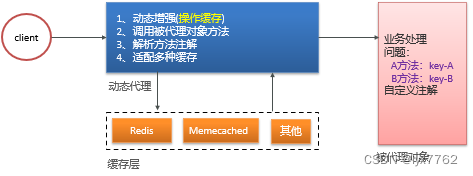
▐Diretório de códigos
▐Mapa de anotação
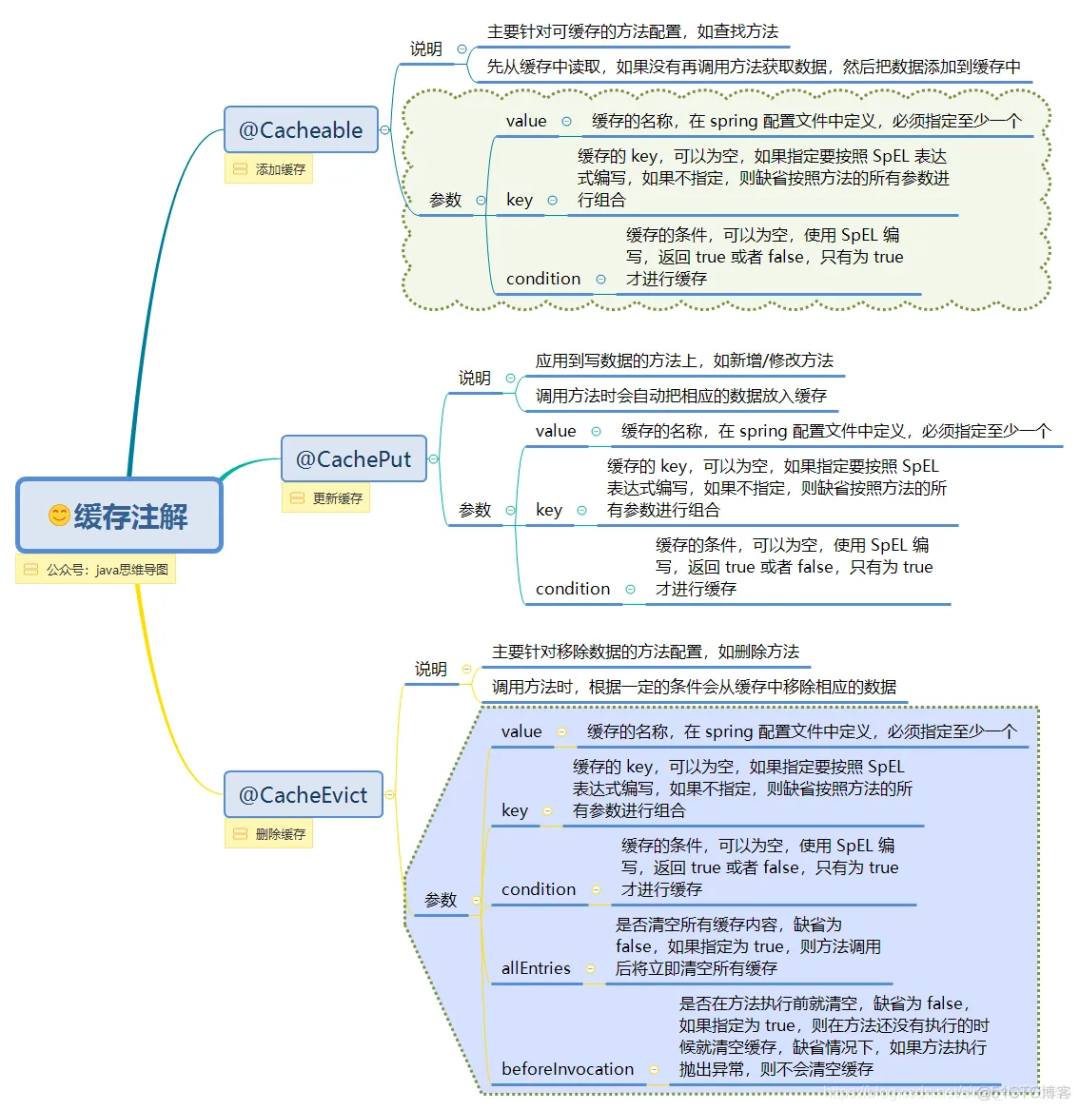
▐Exemplo de uso de anotação
@Cacheable(value = "user_cache", unless = "#result == null")public User getUserById(Long id) {return userMapper.getUserById(id);}@CachePut(value = "user_cache", key = "#user.id", unless = "#result == null")public User updateUser(User user) {userMapper.updateUser(user);return user;}@CacheEvict(value = "user_cache", key = "#id")public void deleteUserById(Long id) {userMapper.deleteUserById(id);}
▐Análise do programa
-
Cache multinível; -
O cache é atualizado regularmente; -
cache de lista; -
Mecanismo de proteção de cache cpp; -
Contagem de cache.
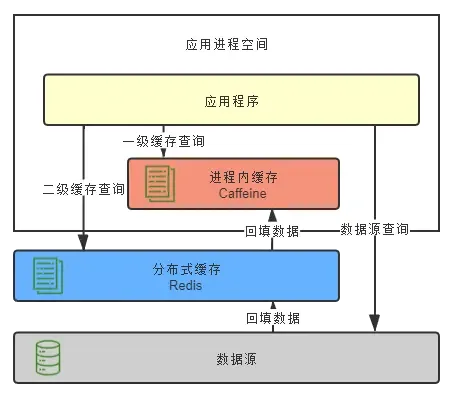

Aprenda a solução da estrutura Spring Cache e implemente uma estrutura de cache personalizada, que não apenas retém as vantagens da estrutura Spring Cache, mas também realiza muitos recursos ausentes do Spring Cache, como quebra de cache, proteção contra penetração de cache, cache multinível, etc. .
▐Exemplo de código de anotação

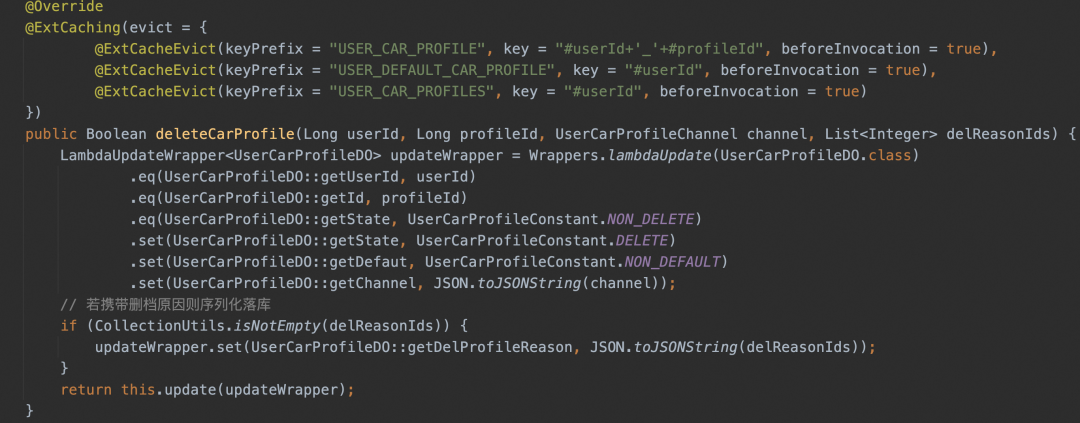
▐Estrutura do projeto
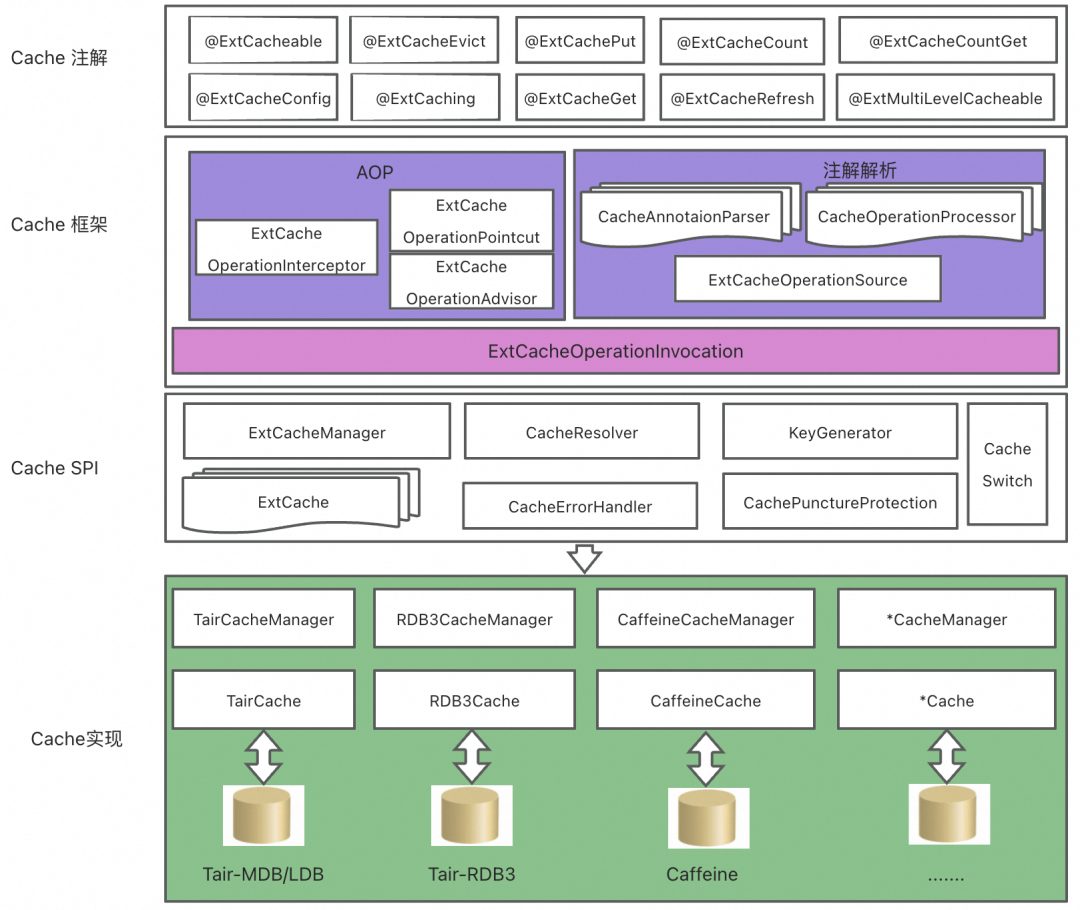

Com a ajuda da implementação do Spring Cache, construímos uma estrutura de cache personalizada e estendemos muitas anotações, como contagem, atualização de cache, cache de lista, bloqueio distribuído, cache multinível, etc., que não apenas realiza a separação do código do cache e código de negócios, mas também expande a primavera. A capacidade de cache melhora muito a legibilidade do código e reduz a eficiência da manutenção do código em cache.

A missão da Tmall Automotive Technology Team é experimentar a vida definitiva das pessoas e dos carros, remodelar a indústria automotiva e ser um administrador de automóveis atencioso ao seu redor. Todos eles estão construindo as mentes dos consumidores para visualização, compra e manutenção de carros online, digitalização. e integrar verticalmente a indústria automotiva e, por meio de inovações do Modelo, alavancar a integração de produto e efeito, melhorar a eficiência da indústria e criar dividendos para a indústria.
Tecnologia do lado do servidor | Qualidade técnica Algoritmo de dados |
Este artigo foi compartilhado na conta pública do WeChat - Big Taobao Technology (AlibabaMTT).
Se houver alguma violação, entre em contato com [email protected] para exclusão.
Este artigo participa do “ Plano de Criação da Fonte OSC ”. Você que está lendo é bem-vindo para participar e compartilhar juntos.