


As ideias atuais de aceleração convencionais incluem otimização de operador, compilação de modelo, cache de modelo, destilação de modelo, etc. A seguir, apresentaremos brevemente várias soluções representativas de código aberto usadas em testes.
▐Otimização do operador : FlashAttention2
▐Compilação do modelo : oneflow/stable-fast
oneflow acelera a inferência do modelo compilando o modelo em um gráfico estático e combinando-o com a fusão de operadores integrada do oneflow.nn.Graph e outras estratégias de aceleração. A vantagem é que o modelo SD básico precisa apenas de uma linha de código compilado para completar a aceleração, o efeito de aceleração é óbvio, a diferença no efeito de geração é pequena, pode ser usado em combinação com outras soluções de aceleração (como deepcache) , e a frequência de atualização oficial é alta. As deficiências serão discutidas posteriormente.
Stable-fast também é uma biblioteca de aceleração baseada na compilação de modelos e combina uma série de métodos de aceleração de fusão de operadores, mas sua otimização de desempenho depende de ferramentas como xformer, triton e torch.jit.
▐Cache de modelo : deepcache
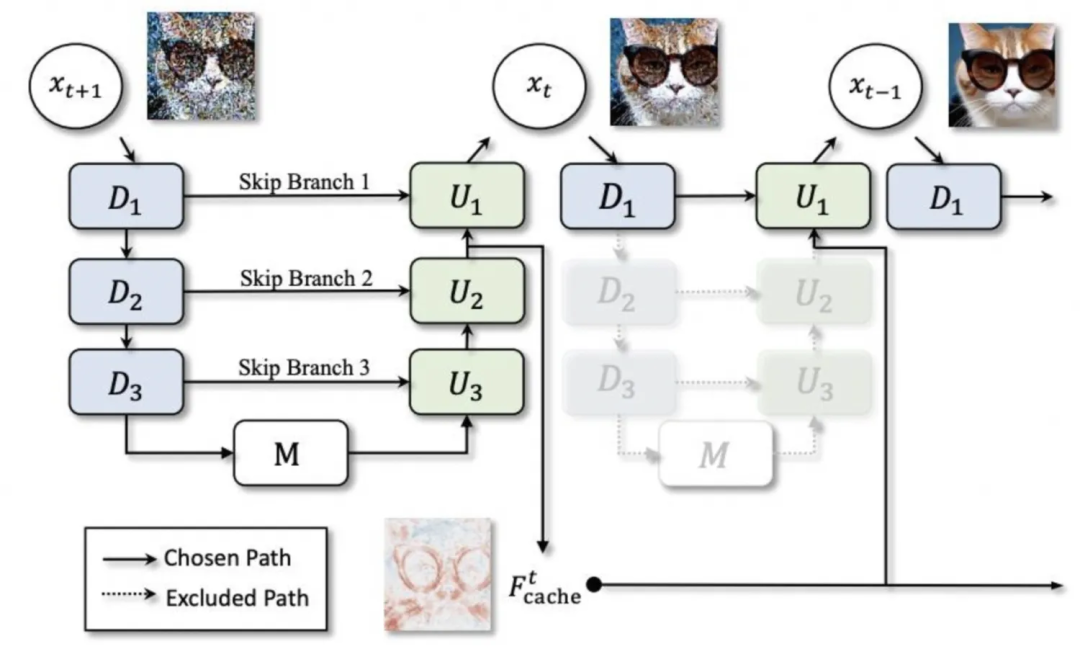
▐Modelo de destilação: lcm-lora
Combinando lcm (Modelo de Consistência Latente) e lora, o lcm destilará todo o modelo sd para obter raciocínio em poucas etapas, enquanto lcm-lora usa a forma de lora para otimizar apenas a parte lora, que também pode ser combinada diretamente. com uso regular de lora.

Teste de aceleração SD1.5
▐ Ambiente de teste
▐Resultados do teste
-
Ao comparar as imagens geradas com uma semente fixa, podemos descobrir que a compilação oneflow pode reduzir o rt em mais de 40% quase sem perda de precisão. No entanto, ao usar um novo pipeline para gerar imagens pela primeira vez, são necessárias dezenas de vezes. segundos de tempo de compilação como aquecimento. -
Deepcache pode reduzir o rt em mais 15% a 25% nesta base, mas ao mesmo tempo, à medida que o intervalo de cache aumenta, a diferença no efeito de geração torna-se cada vez mais óbvia. -
oneflow também é eficaz para o modelo SD1.5 usando controlnet -
Stable-fast depende muito de pacotes externos e está sujeito a vários problemas de versão e erros de ferramentas externas. Semelhante ao oneflow, leva um certo tempo de compilação para gerar imagens pela primeira vez e o efeito de aceleração final é ligeiramente inferior ao. fluxo único.
▐Dados de comparação detalhados
Otimização |
Tempo médio de geração (segundos) 512*512,50 passos |
efeito de aceleração |
Gerar efeito 1 |
Gerar efeito 2 |
Gerar efeito 3 |
difusores |
3.3701 |
0 |
|
|
|
difusores+bf16 |
3.3669 |
≈0 |
|
|
|
difusores+controlnet |
4.7452 |
|
|||
difusores + compilação oneflow |
1.9857 |
41,08% |
|
|
|
difusores + compilação oneflow + controlnet |
2.8017 |
|
|||
difusores + compilação oneflow + deepcache |
intervalo=2:1,4581 |
56,73%(15,65%) |
|
|
|
intervalo=3:1,3027 |
61,35%(20,27%) |
|
|
||
intervalo=5:1,1583 |
65,63%(24,55%) |
|
|
||
difusores+rápido |
2.3799 |
29,38% |















▐ Ambiente de teste
▐Resultados do teste
Modelo sdxl básico:
Sob a condição de semente fixa, o modelo sdxl parece ter maior probabilidade de afetar o efeito de geração de imagens usando diferentes esquemas de aceleração.
O Oneflow só pode reduzir o rt em 24%, mas ainda pode garantir a precisão das imagens geradas.
Deepcache pode fornecer aceleração extremamente significativa Quando o intervalo é 2 (ou seja, o cache é usado apenas uma vez), o rt é reduzido em 42%. Quando o intervalo é 5, o rt é reduzido em 69%. imagens também é óbvio.
lcm-lora reduz significativamente o número de etapas necessárias para gerar gráficos e pode atingir grande aceleração de inferência. No entanto, ao usar pesos pré-treinados, a estabilidade é extremamente baixa e é muito sensível ao número de etapas. garantir uma saída estável consistente com a imagem solicitada
oneflow e deepcache/lcm-lora podem ser usados bem juntos
lora:
Após o carregamento da lora, a velocidade de inferência dos difusores é significativamente reduzida, e o grau de redução está relacionado ao tipo e quantidade de lora utilizada.
deepcache ainda funciona e ainda há problemas de precisão, mas a diferença não é grande em intervalos de cache mais baixos
Ao usar lora, a compilação oneflow não pode corrigir a semente para permanecer consistente com a versão original.
A compilação Oneflow otimiza a velocidade de inferência após o carregamento de lora. Quando vários loras são carregados, o rt de inferência é quase o mesmo de quando nenhum lora é carregado, e o efeito de aceleração é extremamente significativo. Por exemplo, usando fio + aquarela duas loras ao mesmo tempo, o rt pode ser reduzido em cerca de 65%
oneflow otimizou ligeiramente o tempo de carregamento do lora, mas o tempo de operação de configuração após o carregamento do lora aumentou.
▐Dados de comparação detalhados
Otimização |
Lora |
Tempo médio de geração (segundos) 512*512, 50 passos |
Tempo de carregamento de Lora (segundos) |
tempo de modificação de lora (segundos) |
Efeito 1 |
Efeito 2 |
Efeito 3 |
difusores |
nenhum |
4.5713 |
|
||||
fio |
7.6641 |
13.9235 11.0447 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0263 |
||||||
yarn+watercolor |
10.1402 |
|
|||||
diffusers+bf16 |
无 |
4.6610 |
|
||||
yarn |
7.6367 |
12.6095 11.1033 |
0.06~0.09 根据配置的lora数量 |
||||
watercolor |
7.0192 |
||||||
yarn+ watercolor |
10.0729 |
||||||
diffusers+deepcache |
无 |
interval=2:2.6402 |
|
||||
yarn |
interval=2:4.6076 |
||||||
watercolor |
interval=2:4.3953 |
||||||
yarn+ watercolor |
interval=2:5.9759 |
|
|||||
无 |
interval=5: 1.4068 |
|
|||||
yarn |
interval=5:2.7706 |
||||||
watercolor |
interval=5:2.8226 |
||||||
yarn+watercolor |
interval=5:3.4852 |
|
|||||
diffusers+oneflow编译 |
无 |
3.4745 |
|
||||
yarn |
3.5109 |
11.7784 10.3166 |
0.5左右 移除lora 0.17 |
||||
watercolor |
3.5483 |
||||||
yarn+watercolor |
3.5559 |
|
|||||
diffusers+oneflow编译+deepcache |
无 |
interval=2:1.8972 |
|
||||
yarn |
interval=2:1.9149 |
||||||
watercolor |
interval=2:1.9474 |
||||||
yarn+watercolor |
interval=2:1.9647 |
|
|||||
无 |
interval=5:0.9817 |
|
|||||
yarn |
interval=5:0.9915 |
||||||
watercolor |
interval=5:1.0108 |
||||||
yarn+watercolor |
interval=5:1.0107 |
|
|||||
diffusers+lcm-lora |
4step:0.6113 |
||||||
diffusers+oneflow编译+lcm-lora |
4step:0.4488 |














AI试衣业务场景使用了算法在diffusers框架基础上改造的专用pipeline,功能为根据待替换服饰图对原模特图进行换衣,基础模型为SD2.1。
根据调研的结果,deepcache与oneflow是优先考虑的加速方案,同时,由于pytorch版本较低,也可以尝试使用较新版本的pytorch进行加速。
▐ 测试环境
A10 + cu118 + py310 + torch2.0.1 + diffusers0.21.4
图生图(示意图,仅供参考):
待替换服饰 |
原模特图 |
|
|


▐ 测试结果
pytorch2.2版本集成了FlashAttention2,更新版本后,推理加速效果明显
deepcache仍然有效,为了尽量不损失精度,可设置interval为2或3
对于被“魔改”的pipeline和子模型,oneflow的图转换功能无法处理部分操作,如使用闭包函数替换forward、使用布尔索引等,而且很多错误原因较难通过报错信息来定位。在进行详细的排查之后,我们尝试了改造原模型代码,对其中不被支持的操作进行替换,虽然成功地在没有影响常规生成效果的前提下完成了改造,通过了oneflow编译,但编译后的生成效果很差,可以看出oneflow对pytorch的支持仍然不够完善
最终采取pytorch2.2.1+deepcache的结合作为加速方案,能够实现rt降低40%~50%、生成效果基本一致且不需要过多改动原服务代码
▐ 详细对比数据
优化方法 |
平均生成耗时(秒) 576*768,25step |
生成效果 |
diffusers |
22.7289 |
|
diffusers+torch2.2.1 |
15.5341 |
|
diffusers+torch2.2.1+deepcache |
11.7734 |
|
diffusers+oneflow编译 |
17.5857 |
|
diffusers+deepcache |
interval=2:18.0031 |
|
interval=3:16.5286 |
|
|
interval=5:15.0359 |
|








目前市面上有很多非常好用的开源模型加速工具,pytorch官方也不断将各种广泛采纳的优化技术整合到最新的版本中。
我们在初期的调研与测试环节尝试了很多加速方案,在排除了部分优化效果不明显、限制较大或效果不稳定的加速方法之后,初步认为deepcache和oneflow是多数情况下的较优解。
但在解决实际线上服务的加速问题时,oneflow表现不太令人满意,虽然oneflow团队针对SD系列模型开发了专用的加速工具包onediff,且一直保持高更新频率,但当前版本的onediff仍存在不小的限制。
如果使用的SD pipeline没有对unet的各种子模块进行复杂修改,oneflow仍然值得尝试;否则,确保pytorch版本为最新的稳定版本以及适度使用deepcache可能是更省心且有效的选择。

相关资料
FlashAttention:
https://github.com/Dao-AILab/flash-attention
https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
oneflow
https://github.com/Oneflow-Inc/oneflow
https://github.com/siliconflow/onediff
stable-fast
https://github.com/chengzeyi/stable-fast
deepcache
https://github.com/horseee/DeepCache
lcm-lora
https://latent-consistency-models.github.io/
pytorch 2.2
https://pytorch.org/blog/pytorch2-2/

我们是淘天集团内容技术AI工程团队,通过搭建完善的算法工程化一站式平台,辅助上千个淘宝图文、视频、直播等泛内容领域算法的工程落地、部署和优化,承接每日上亿级别的数字内容数据,支撑并推动AI技术在淘宝内容社交生态中的广泛应用。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。