
Na semana passada, anunciamos o roteiro do GreptimeDB 2024, revelando vários planos de versões principais do GreptimeDB este ano. Com a chegada do início da primavera em março, a primeira versão de código aberto do GreptimeDB adequada para o nível de produção também chegou conforme programado durante a temporada "Jingzhe", quando tudo se recupera. A v0.7 marca um passo importante em direção a uma versão pronta para produção e damos as boas-vindas a todos os membros da comunidade para participarem ativamente e fornecerem feedback valioso.
Da v0.6 à v0.7, a equipe Greptime fez um progresso significativo: um total de 184 commits foram mesclados, 705 arquivos foram modificados, incluindo 82 melhorias de recursos, 35 correções de bugs, 19 refatorações de código e um grande número de trabalho de teste. Durante este período, um total de 8 contribuidores independentes participaram da contribuição de código do GreptimeDB. Agradecimentos especiais a Eugene Tolbakov, como o primeiro committer do GreptimeDB, que continua ativo na contribuição de código do GreptimeDB e cresce conosco!
Destaques da atualização (versão de salvamento de fluxo) Metric Engine : Um novo mecanismo projetado para cenários observáveis é recomendado e pode lidar com um grande número de pequenas tabelas, adequado para cenários de monitoramento nativos da nuvem. Migração de região : Otimiza a experiência de uso e pode ser facilmente executado por meio de SQL; Migração de região; Índice invertido : Localize com eficiência os segmentos de dados envolvidos nas consultas do usuário, reduza significativamente as operações de IO necessárias para verificar arquivos de dados e acelere o processo de consulta.
v0.7 é uma das poucas atualizações de versão importantes desde que o GreptimeDB foi de código aberto. Desta vez, também iremos transmiti-lo ao vivo na conta de vídeo. Para saber mais sobre detalhes funcionais, assistir demonstrações de demonstração ou ter discussões aprofundadas com nossa equipe principal de desenvolvimento, seja bem-vindo para participar da transmissão ao vivo às 19h30 da próxima quinta-feira (14 de março).
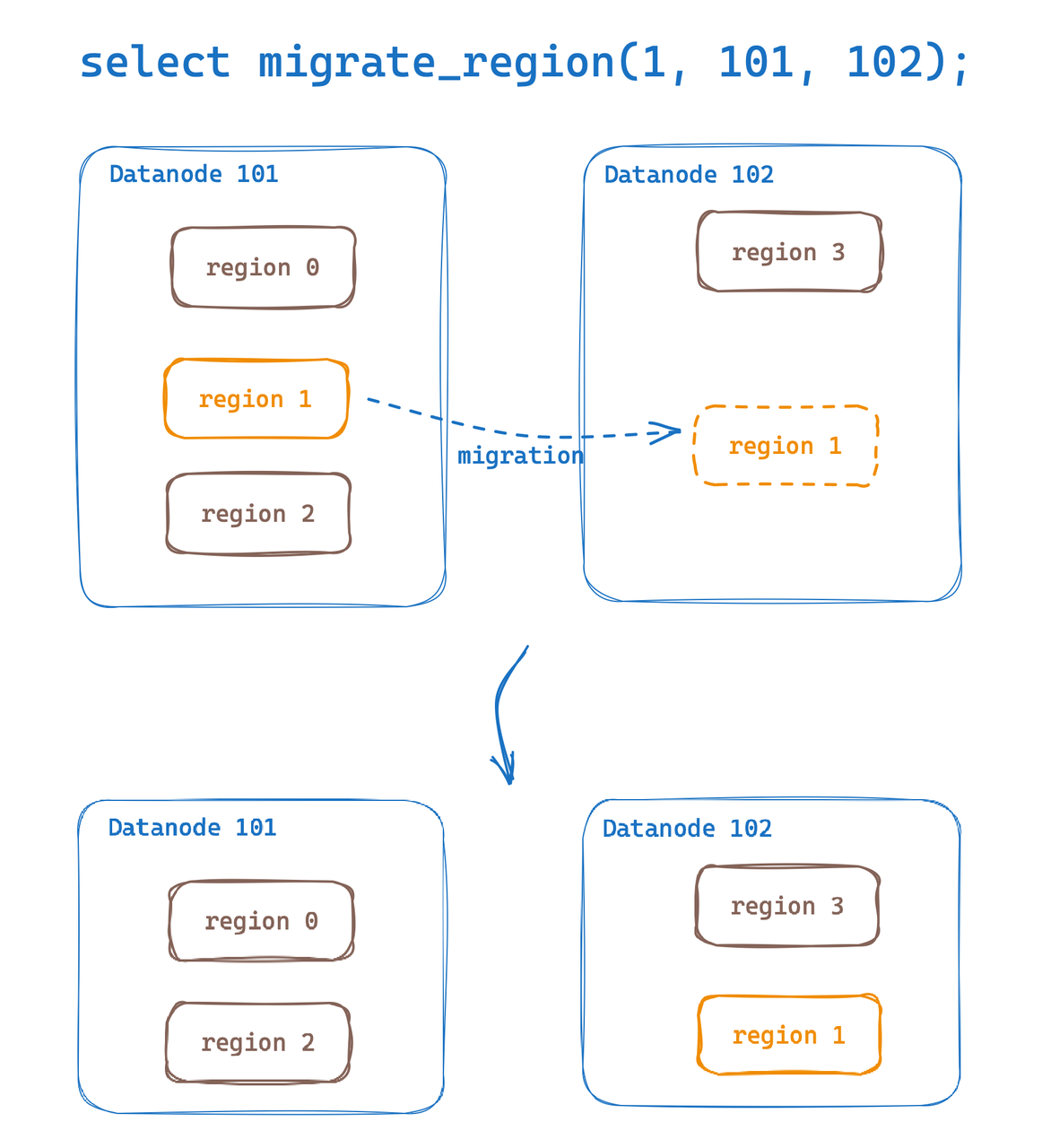
Migração de região
A migração de região fornece a capacidade de migrar regiões de tabelas de dados entre Datanodes. Com esse recurso, podemos implementar facilmente a migração de dados de hotspot e a expansão horizontal do balanceamento de carga. GreptimeDB mencionou que a migração de região foi implementada inicialmente quando a v0.6 foi lançada. Esta atualização de versão melhora e otimiza a experiência do usuário.
Agora, podemos realizar facilmente a migração de regiões via SQL:
select migrate_region(
region_id,
from_dn_id,
to_dn_id,
[replay_timeout(s)]);
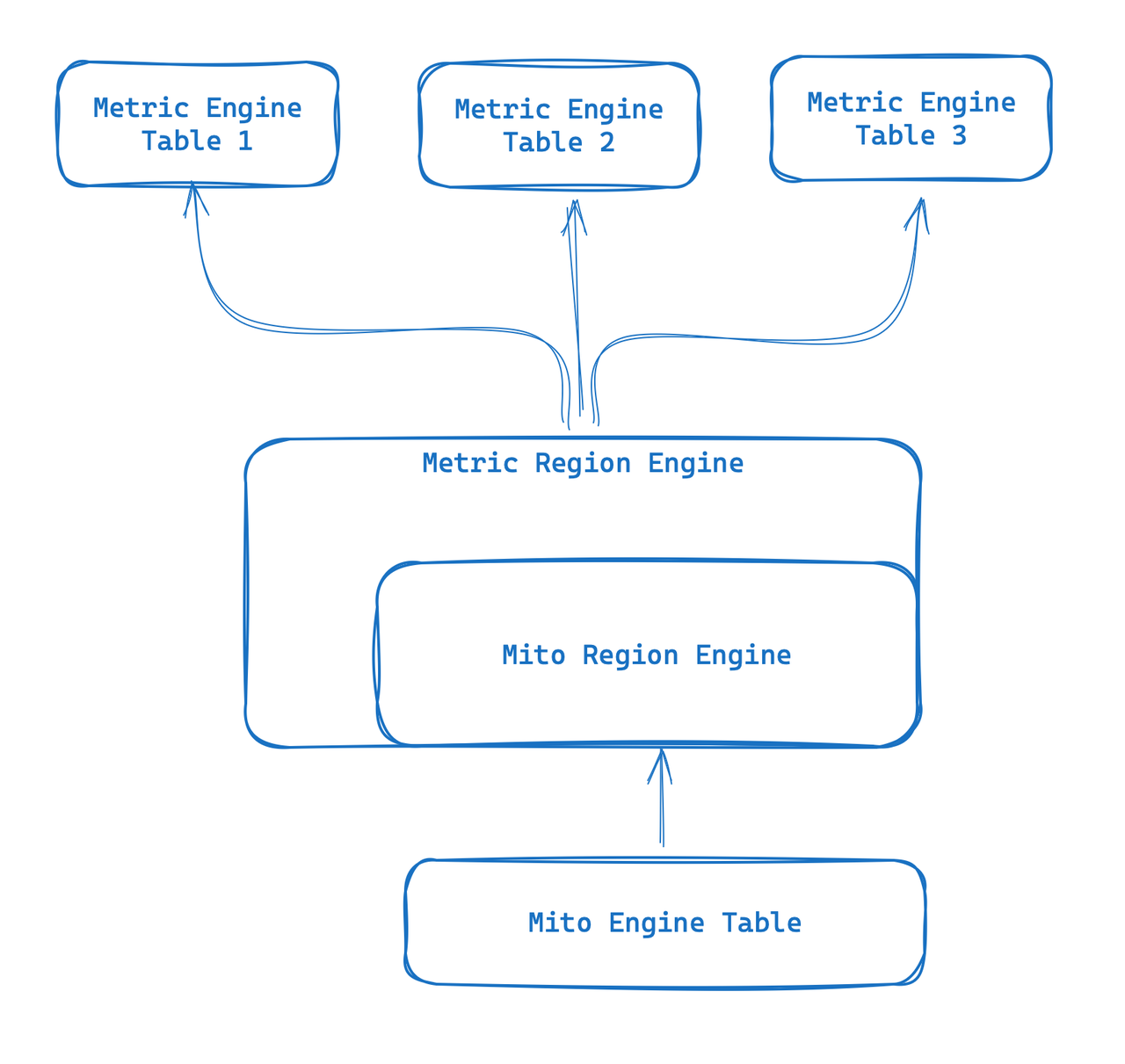
Mecanismo Métrico
Metric Engine é um mecanismo totalmente novo projetado para cenários observáveis. Seu principal objetivo é ser capaz de lidar com um grande número de tabelas pequenas e é especialmente adequado para cenários de monitoramento nativos da nuvem, como o uso do Prometheus. Ao utilizar tabelas largas sintéticas, este novo mecanismo fornece a capacidade de armazenar dados de indicadores e reutilizar metadados. A "tabela" torna-se mais leve e pode superar algumas das tabelas existentes do mecanismo Mito que são muito pesadas.
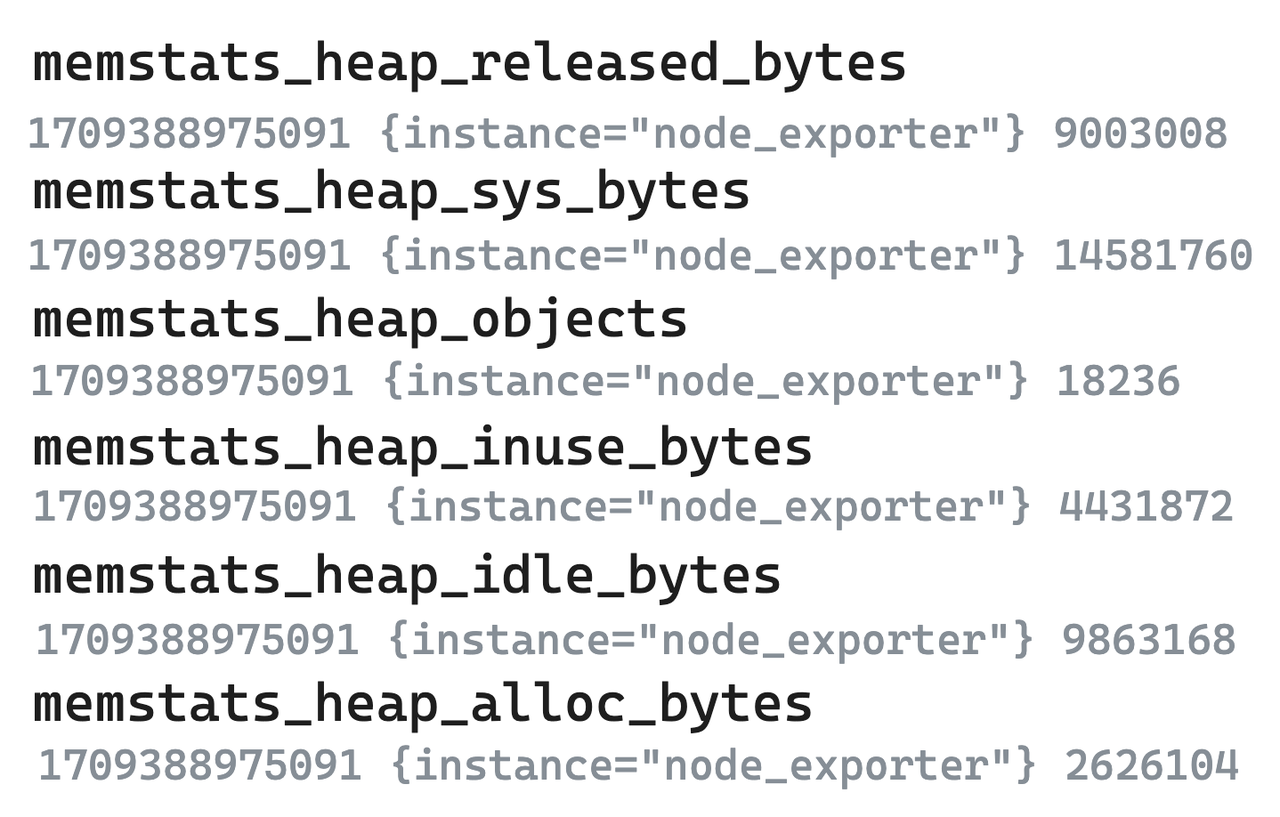
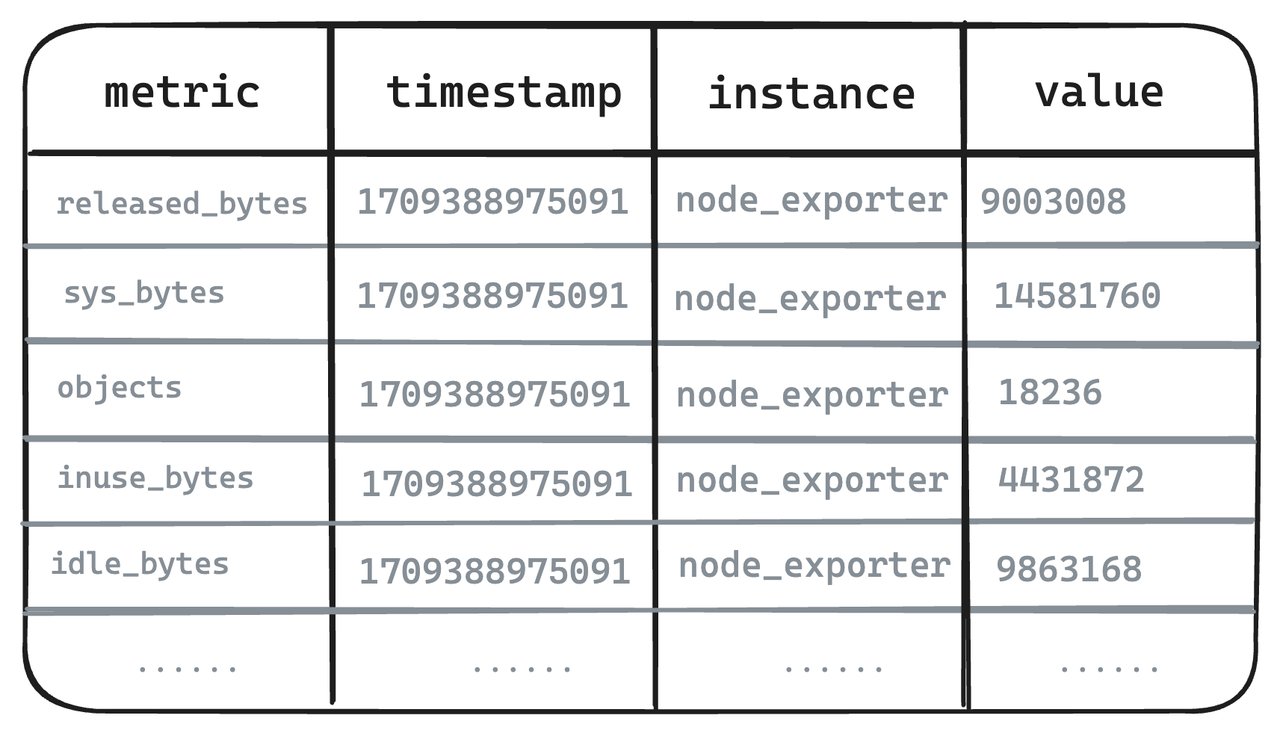
-
Legenda - Dados brutos de métricas
- As seguintes métricas dos seis exportadores de nós são tomadas como exemplos. Nos sistemas de modelo de valor único representados pelo Prometheus, mesmo indicadores altamente correlacionados precisam ser divididos em vários e armazenados separadamente.
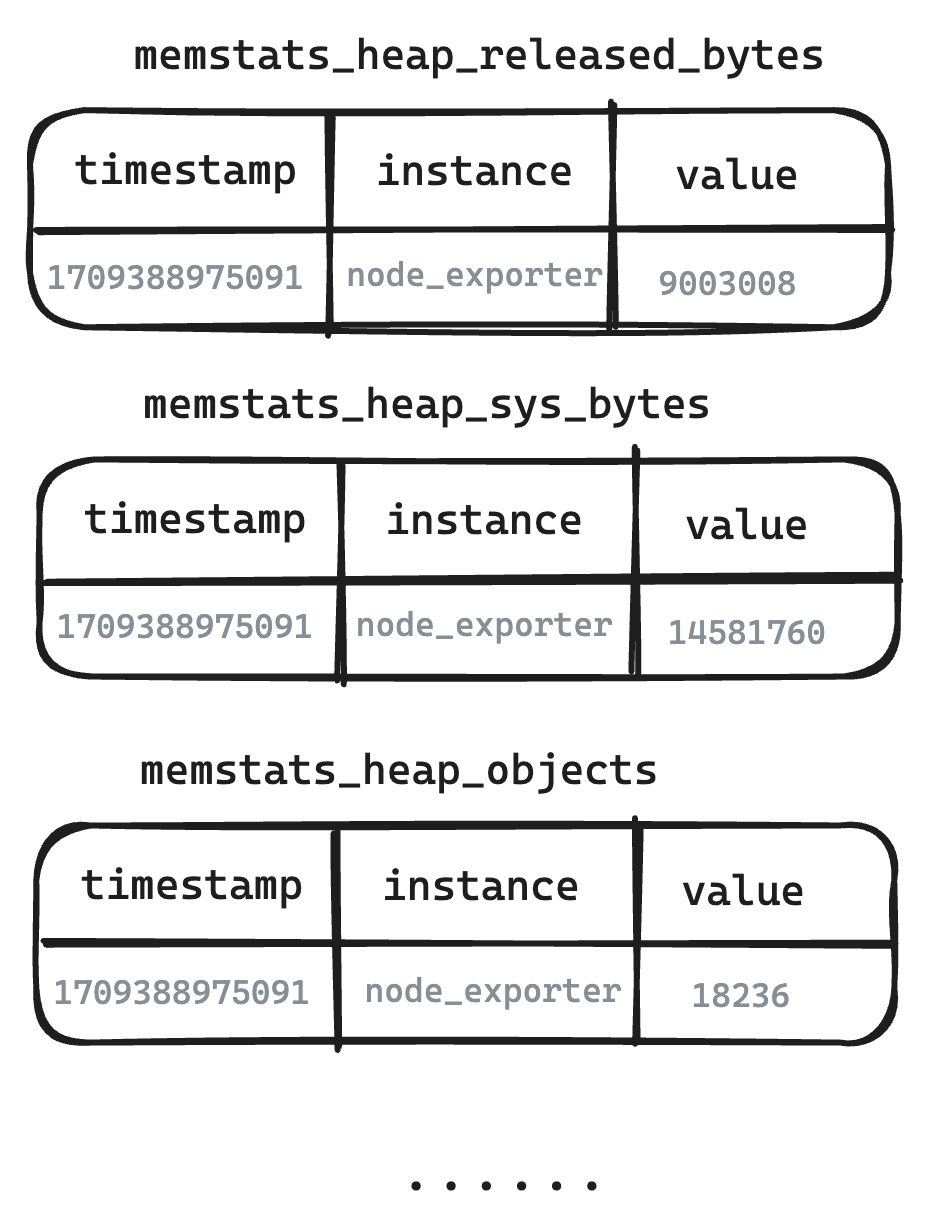
-
Legenda - Tabela lógica na perspectiva do usuário
- O Metric Engine restaura autenticamente a estrutura das métricas, e o que os usuários veem é a estrutura escrita das métricas.
-
Legenda – a tabela física que armazena a perspectiva
- Na camada de armazenamento, o Metric Engine realiza o mapeamento e usa uma tabela física para armazenar dados relacionados, o que pode reduzir os custos de armazenamento e oferecer suporte ao armazenamento de métricas em maior escala.
-
Legenda - Próximo plano de P&D: Agrupamento automático de campos
- A maioria das métricas geradas em cenários reais são relevantes. GreptimeDB pode derivar automaticamente indicadores relacionados e mesclá-los, o que não apenas reduz o número de cronogramas nas métricas, mas também é amigável para consultas relacionadas.

-
Otimização de custos de armazenamento
O teste de custo foi realizado com base no back-end de armazenamento AWS S3. Cada dado foi gravado por cerca de 30 minutos e o volume total de gravação foi de cerca de 30 W linhas/s. Conte o número de vezes que cada operação ocorre no processo e estime o custo com base na cotação da AWS. A função de índice foi habilitada durante o teste.
Para cotações, consulte o nível Padrão em https://aws.amazon.com/s3/pricing/
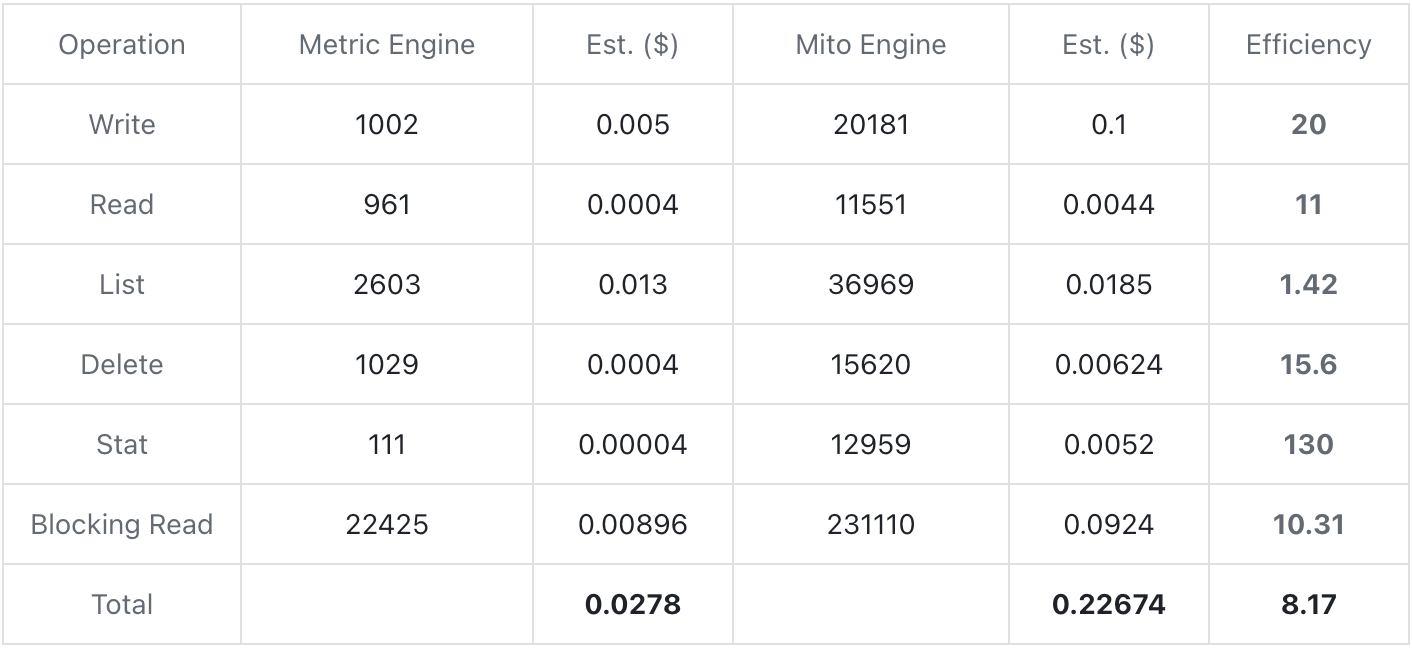
Como pode ser visto na tabela de teste acima, o Metric Engine pode reduzir significativamente os custos de armazenamento, reduzindo o número de tabelas físicas. O número de operações em cada estágio é reduzido em ordens de magnitude. O custo abrangente convertido pode ser reduzido em mais de oito. vezes em comparação com o Mito Engine.
Índice invertido
Como um módulo de índice recém-introduzido, o Índice Invertido foi projetado para localizar com eficiência os segmentos de dados envolvidos nas consultas do usuário, reduzir significativamente as operações de E/S necessárias para verificar arquivos de dados e acelerar o processo de consulta. No cenário de teste TSBS, o desempenho da cena melhorou em média 50% e, em alguns cenários, o desempenho melhorou quase 200%. As principais vantagens do Índice Invertido incluem:
- Pronto para uso: o sistema gera automaticamente índices apropriados e os usuários não precisam especificar índices adicionais;
- Funções práticas: suporta igualdade, intervalo e correspondência regular de valores de múltiplas colunas, garantindo que os dados possam ser rapidamente localizados e filtrados na maioria dos cenários;
- Adaptação flexível: ajuste automaticamente os parâmetros internos para equilibrar os custos de construção e a eficiência da consulta, respondendo efetivamente às necessidades de indexação de diferentes cenários
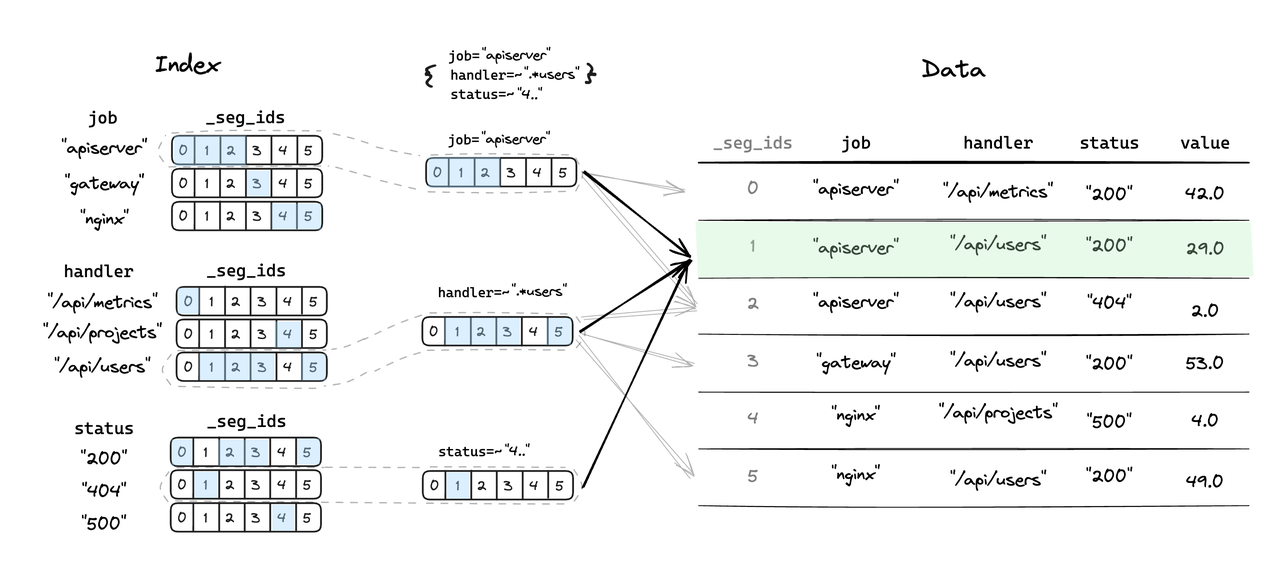
- Legenda - Representação lógica do Índice Invertido e processo de posicionamento dos dados
- Os usuários especificam as condições de filtragem em múltiplas colunas e, por meio do posicionamento rápido do Índice Invertido, a maioria dos segmentos de dados incomparáveis pode ser eliminada, resultando em menos segmentos de dados a serem verificados e na aceleração da consulta.
Outras atualizações
1. As funções de gerenciamento do banco de dados foram significativamente aprimoradas
Complementamos significativamente a tabela information_schema, adicionando novas informações como SCHEMATA e PARTITIONS. Além disso, a nova versão introduz muitas novas funções SQL para implementar operações de gerenciamento de banco de dados. Por exemplo, agora você pode acionar Region Flush, realizar migração de região e consultar o status de execução de procedimentos por meio de SQL.
2. Melhoria de desempenho
Na versão v0.7, o Memtable foi reconstruído para melhorar a velocidade de digitalização de dados e reduzir o uso de memória. Ao mesmo tempo, também fizemos muitas melhorias e otimizações no desempenho de leitura e gravação do armazenamento de objetos.
Guia de atualização
Devido a algumas mudanças importantes na nova versão, esta versão v0.7 requer tempo de inatividade para atualização. Recomenda-se usar a ferramenta de atualização oficial. O processo geral de atualização é o seguinte:
- Crie um novo cluster v0.7
- Feche a antiga entrada de tráfego do cluster (pare de escrever)
- Exporte a estrutura da tabela e os dados por meio da ferramenta de atualização CLI GreptimeDB
- Importe dados para o novo cluster por meio da ferramenta de atualização CLI do GreptimeDB
- O tráfego de entrada muda para o novo cluster
Para obter um guia de atualização detalhado, consulte:
- Chinês: https://docs.greptime.cn/user-guide/upgrade
- Inglês: https://docs.greptime.com/user-guide/upgrade
perspectiva futura
Nosso próximo grande marco será em abril, quando a versão 0.8 será lançada. Esta versão apresentará o GreptimeFlow, uma solução otimizada de computação de fluxo projetada especificamente para realizar operações de agregação contínua em fluxos de dados do GreptimeDB. Considerando a necessidade de flexibilidade, o GreptimeFlow pode ser integrado à camada de computação do GreptimeDB e implantado em conjunto, ou pode ser implantado como um serviço independente.
Além das atualizações contínuas no nível funcional, também continuamos a otimizar o desempenho da versão. Embora o desempenho da v0.7 tenha sido bastante melhorado em comparação com antes, ainda há alguma lacuna entre ela e algumas soluções convencionais em cenários observáveis. Esta também será nossa próxima direção principal de otimização.
Bem-vindo a ler o GreptimeDB Roadmap 2024 para obter uma compreensão abrangente de nosso plano de atualização de versão durante todo o ano. Você também está convidado a participar de contribuições de código ou comentários e discussões sobre funções e desempenho. Vamos dar as mãos para testemunhar o crescimento e melhoria contínuos do GreptimeDB.
Sobre o Greptime:
Greptime A Greptime Technology está comprometida em fornecer serviços de análise e armazenamento de dados eficientes e em tempo real para campos que geram grandes quantidades de dados de séries temporais, como carros inteligentes, Internet das Coisas e observabilidade, ajudando os clientes a explorar o valor profundo dos dados. Atualmente existem três produtos principais:
-
GreptimeDB é um banco de dados de série temporal escrito em linguagem Rust. É distribuído, de código aberto, nativo da nuvem e altamente compatível. Ele ajuda as empresas a ler, escrever, processar e analisar dados de série temporal em tempo real, reduzindo os custos de armazenamento de longo prazo.
-
GreptimeCloud pode fornecer aos usuários serviços DBaaS totalmente gerenciados, que podem ser altamente integrados com observabilidade, Internet das Coisas e outros campos.
-
GreptimeAI é uma solução de observabilidade adaptada para aplicações LLM.
-
A solução integrada veículo-nuvem é uma solução de banco de dados de série temporal que se aprofunda nos cenários reais de negócios das montadoras e resolve os reais pontos problemáticos dos negócios depois que os dados dos veículos da empresa crescem exponencialmente.
GreptimeCloud e GreptimeAI foram oficialmente testados. Bem-vindo a seguir a conta oficial ou o site oficial para os últimos desenvolvimentos! Se você estiver interessado na versão empresarial do GreptimDB, entre em contato com o assistente (pesquise greptime no WeChat para adicionar o assistente).
Site oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentação: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Folga: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes para plataformas Windows no futuro