
A magia do código eBPF, propagando endereços de pares diretamente no fluxo TCP para reconstruir a topologia de comunicação
Sobre Construindo uma topologia de rede de um aplicativo Kubernetes de maneira não intrusiva , por exemplo, Ilya Shakhat.
introduzir
Um aplicativo Kubernetes é logicamente dividido em duas partes: uma parte são os recursos de computação (representados por pods) e a outra parte fornece acesso ao aplicativo (representado por serviços). Os clientes do aplicativo podem acessá-lo usando o nome abstrato sem se preocupar com qual pod realmente trata a solicitação. E, como um único serviço pode ter vários pods como back-ends, ele também atua como balanceador de carga. Em uma implantação padrão do Kubernetes, essa função de balanceamento de carga é implementada usando iptables muito simples ou Linux IPVS - ambos funcionam na camada L4 (como TCP) e implementam um mecanismo round-robin ingênuo e aleatório. É claro que os provedores de nuvem também podem oferecer soluções de balanceamento de carga mais tradicionais para expor aplicativos, mas vamos começar de forma simples.
Quando pensamos nos diversos problemas que podem ocorrer em aplicações implantadas no Kubernetes, existe uma classe de problemas que requer a compreensão da instância específica de tratamento das solicitações do cliente. Por exemplo: (1) um pod de aplicativo é implantado em um host com uma conexão de rede ruim e leva mais tempo para estabelecer uma nova conexão do que outros pods ou (2) o desempenho de um pod diminui com o tempo, enquanto o desempenho de outros pods permanece estável ou (3) a solicitação de um cliente específico afeta o desempenho do aplicativo. O rastreamento distribuído costuma ser uma das maneiras de obter insights sobre problemas como esse e, obviamente, é usado para rastrear o caminho de uma solicitação do cliente até o aplicativo de back-end. Tradicionalmente, o rastreamento distribuído requer alguma forma de instrumentação, que pode passar da adição manual de código até a injeção totalmente automatizada no tempo de execução. Mas será que o mesmo efeito pode ser alcançado sem modificar o código do cliente?
Para depurar o problema acima, precisamos basicamente de dois recursos de rastreamento distribuído: (1) coletar métricas relacionadas à latência da solicitação e (2) saber exatamente para onde cada solicitação está indo. O primeiro recurso pode ser facilmente implementado de forma não intrusiva usando uma das inúmeras ferramentas suportadas pelo eBPF (uma tecnologia que permite anexar dinamicamente testes às funções do kernel), por exemplo, registrar qual processo estabeleceu uma nova conexão, obter métricas relacionadas ao soquete/conexão. e até mesmo verificar se há retransmissões ou redefinições de conexão maliciosas. No ecossistema openEuler, tal ferramenta é o gala-gopher, que fornece um grande número de testes diferentes, incluindo testes de soquete, TCP e L7/HTTP(s). No entanto, a segunda característica (saber para onde vai uma solicitação individual) é muito mais difícil de alcançar. Em uma estrutura de rastreamento distribuído, isso é conseguido injetando um ID de span/rastreamento na carga útil do aplicativo e, em seguida, correlacionando as observações do cliente e do back-end usando o mesmo ID de span. Ser não intrusivo ao código da aplicação significa que as mesmas informações precisam ser injetadas de maneira genérica, mas fazer isso no protocolo da aplicação simplesmente não é viável, pois exigiria interceptar o tráfego de saída, analisá-lo, injetar o ID e é serializado e encaminhado. Parece que acabamos de reinventar uma malha de serviço!
Antes de continuarmos, vamos dar uma olhada nos dados disponíveis no monitoramento de rede. Aqui assumimos que o monitor obterá informações de todos os nós que hospedam o Pod do aplicativo e, em seguida, esses dados serão processados, por exemplo, pelo Prometheus. Colete-os. Para conseguir isso, precisamos de algum ambiente experimental.
ambiente de teste
Primeiro, precisamos de um cluster Kubernetes de vários nós implantado. Na Huawei Cloud, o serviço correspondente é denominado Cloud Container Engine (CCE).
Então precisamos de um aplicativo de teste, e para isso usaremos um programa Python muito simples que aceita uma solicitação HTTP e é capaz de fazer solicitações HTTP de saída para o endereço especificado na solicitação original. Dessa forma, podemos vincular aplicativos facilmente.
Esses aplicativos serão nomeados com as letras latinas A, B, etc. O Aplicativo A é implantado como Implantação A e Serviço A e assim por diante. A primeira aplicação também ficará exposta ao mundo exterior para que possa ser chamada de fora.
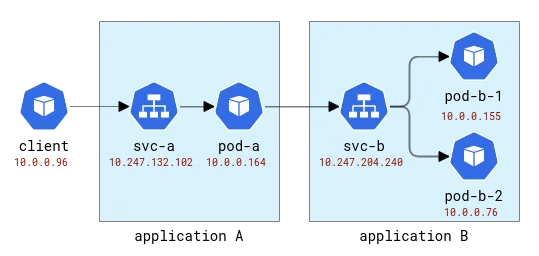
Topologia de aplicação A e B
No Kubernetes, o Gala-gopher é implantado como um conjunto de daemons e é executado em cada nó do Kubernetes. Ele fornece métricas que são consumidas pelo Prometheus e, por fim, visualizadas pelo Grafana. A topologia de serviço é construída com base em métricas e visualizada pelo plugin NodeGraph.
Observabilidade
Vamos enviar algumas solicitações para a Aplicação A e encaminhar para a Aplicação B assim:
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-698tr ip 10.0.0.76 at node 192.168.3.218
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
[root@debug-7d8bdd568c-5jrmf /]# curl http://a.app:8000/b.app:8000
..Hello from pod b-67b75c8557-mzn6p ip 10.0.0.149 at node 192.168.3.14
Hello from pod a-7954c595f7-tmnx8 ip 10.0.0.148 at node 192.168.3.14
Na saída, vemos que uma das solicitações do Aplicativo B foi enviada para um pod e a outra solicitação foi enviada para outro pod. É assim que a topologia aparece no Grafana:
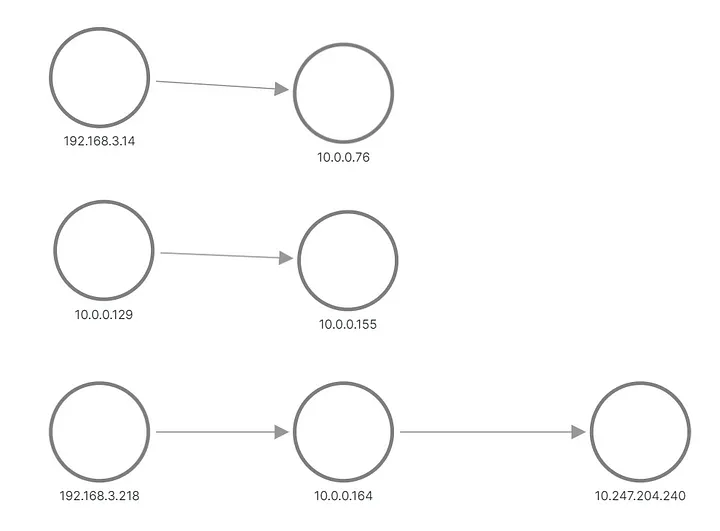
A e B aplicam topologia, reconstruída a partir de métricas
As linhas superior e intermediária mostram algo enviando uma solicitação ao pod do Aplicativo B, enquanto a parte inferior mostra um dos pods de A enviando uma solicitação ao IP virtual do Serviço B. Mas isso não parece nada com o que esperávamos, certo? Vemos apenas três conjuntos de nós sem links entre eles. Os endereços IP da sub-rede 192.168.3.0/24 são os endereços dos nós da rede privada do cluster (VPC) e 10.0.0.1/24 é o endereço do pod, exceto 10.0.0.129, que é o endereço do nó usado para intranet. comunicação do nó.
Agora, essas métricas são coletadas no nível do soquete, o que significa que são exatamente o que o processo do aplicativo pode ver. A coleta é feita via testes eBPF, então a primeira ideia é verificar se o kernel do sistema operacional sabe mais sobre a conexão da aplicação do que as informações disponíveis no soquete. O cluster é configurado com um CNI padrão e o serviço Kubernetes é implementado como uma regra iptables. A saída de iptables-save mostra a configuração. As mais interessantes são estas regras que realmente configuram o balanceamento de carga:
-A KUBE-SERVICES -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-SVC-CELO6J2CXNI7KVVA
-A KUBE-SVC-CELO6J2CXNI7KVVA -d 10.247.204.240/32 -p tcp -m comment
--comment "app/b:http-port cluster IP" -m tcp --dport 8000 -j KUBE-MARK-MASQ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.155:8000"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-VFBYZLZKPEFJ3QIZ
-A KUBE-SVC-CELO6J2CXNI7KVVA -m comment --comment "app/b:http-port -> 10.0.0.76:8000"
-j KUBE-SEP-SXF6FD423VYX6VFB
O balanceamento de carga é feito no mesmo nó do cliente. Então, se mapearmos pods para nós, ficará assim:
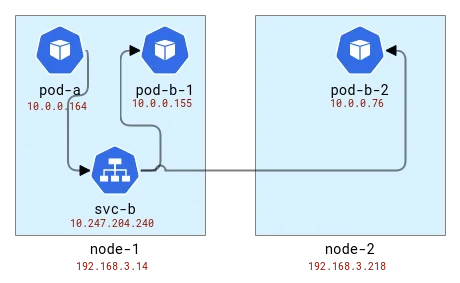
Mapeie a topologia do aplicativo A e B para nós do Kubernetes
Internamente o iptables (na verdade nftables ) usa o módulo conntrack para entender que os pacotes pertencem à mesma conexão e devem ser tratados de maneira semelhante. Conntrack também é responsável pela tradução de endereços, portanto, os nós com aplicações clientes devem saber para onde enviar pacotes. Vamos verificar usando a ferramenta CLI conntrack.
# node-1
# conntrack -L | grep 8000
tcp 6 82 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51030 dport=8000 src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [ASSURED] use=1
tcp 6 79 TIME_WAIT src=10.0.0.164 dst=10.247.204.240 sport=51014 dport=8000 src=10.0.0.155 dst=10.0.0.129 sport=8000 dport=56734 [ASSURED] use=1
# node-2
# conntrack -L | grep 8000
tcp 6 249 CLOSE_WAIT src=10.0.0.76 dst=192.168.3.14 sport=8000 dport=19554 [UNREPLIED] src=192.168.3.14 dst=10.0.0.76 sport=19554 dport=8000 use=1
Ok, vemos que no primeiro nó o endereço foi traduzido do pod do Aplicativo A e obtivemos um endereço de nó com alguma porta aleatória. No segundo nó, as informações de conexão são invertidas, pois seu próprio pacote é na verdade uma resposta, mas com isso em mente vemos que a solicitação vem do primeiro nó e da mesma porta aleatória. Observe que há duas solicitações no Nó-1 porque enviamos 2 solicitações e elas foram tratadas por pods diferentes: pod-b-1 no mesmo nó e pod-b-2 em outro nó.
A boa notícia aqui é que é possível saber o real destinatário da solicitação no nó cliente, mas para o lado do servidor ele precisa estar correlacionado com as informações coletadas no nó cliente . assim:
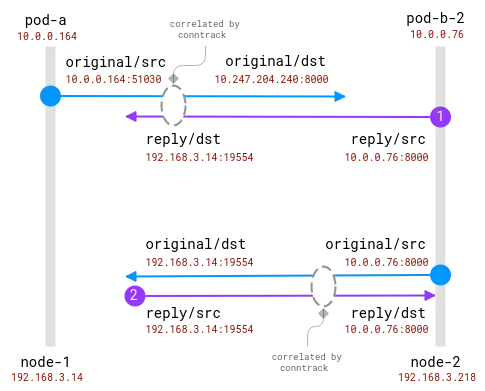
As conexões são rastreadas pelo módulo conntrack. O círculo azul é o endereço local observado no soquete e o roxo é o endereço remoto. O desafio é relacionar o roxo e o azul.
Quando os pods de cliente e servidor estão no mesmo nó, a correlação se torna mais simples, mas ainda existem algumas suposições sobre quais endereços são reais e quais devem ser ignorados:
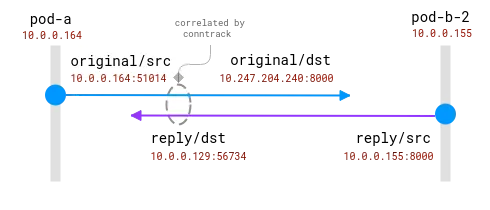
Uma conexão entre dois pods no mesmo nó. O endereço de origem é real, mas o endereço de destino precisa ser mapeado
Aqui, o sistema operacional tem total visibilidade do NAT e pode fornecer um mapeamento entre a origem real e o destino real. É _possível_ reconstruir o fluxo completo de 10.0.0.164 a 10.0.0.155.
Para concluir esta seção, deve ser possível estender as sondas eBPF existentes para incluir informações sobre tradução de endereços do módulo conntrack. O cliente pode saber para onde está indo a solicitação. Mas nem sempre o servidor consegue saber quem é o cliente, não existe um algoritmo de correlação centralizado diretamente. Em contraste, os métodos de rastreamento distribuído fornecem aos clientes e servidores informações sobre seus pares, direta e imediatamente a partir dos dados de comunicação. Então, aí vem o FlowTracer!
FlowTracer
A ideia é simples: transferir dados entre pares diretamente na conexão. Esta não é a primeira vez que tal recurso é necessário, por exemplo, o balanceador de carga HTTP inserirá o cabeçalho HTTP X-Forwarded-For para informar o servidor back-end sobre o cliente. A limitação aqui é que queremos permanecer em L4, suportando assim qualquer protocolo de nível de aplicação. Tal funcionalidade também existe, e alguns balanceadores de carga L4 (como este ) podem injetar o endereço de origem como uma opção de cabeçalho TCP e disponibilizá-lo ao servidor.
Resumo dos requisitos:
- Endereço de peer de transporte da camada L4.
- Capacidade de ativar dinamicamente a injeção de endereço (como implantar facilmente aplicativos em K8s).
- Não invasivo e rápido.
A abordagem mais direta parece ser usar opções de cabeçalho TCP (também conhecidas como TOA). A carga útil é o endereço IP e o número da porta (porque eles mudam durante a tradução do endereço). Como a implantação do Huawei Kubernetes oferece suporte apenas a IPv4, podemos limitar o suporte apenas a IPv4. Os endereços IPv4 têm 32 bits, enquanto os números de porta requerem 16 bits, exigindo um total de 6 bytes, mais 1 byte para o tipo de opção e 1 byte para o comprimento da opção. Esta é a aparência das especificações do cabeçalho TCP:
O cabeçalho pode conter várias opções de até 40 bytes. Cada opção pode ter comprimento e tipo/tipo variáveis.
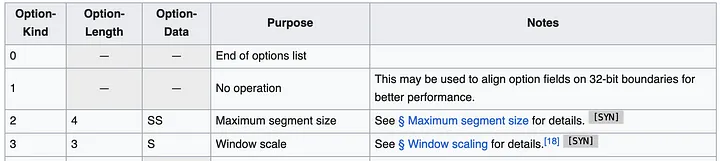
Em geral, os pacotes TCP do Linux já possuem algumas opções, como MSS ou timestamp. Mas ainda existem cerca de 20 bytes de espaço disponíveis para nós.
Agora, quando sabemos onde colocar os dados, a próxima pergunta é onde devemos adicionar o código? Queremos que a solução seja o mais geral possível e possa ser usada para todas as conexões TCP. O local ideal é em algum lugar do kernel na pilha de rede, no que é chamado de buffer de soquete (uma estrutura que representa informações de conexão de rede), desde o nível superior até os pacotes prontos para serem transmitidos pela rede. Do ponto de vista da implementação, o código deve ser eBPF (é claro!) e a funcionalidade de injeção de endereço pode então ser habilitada dinamicamente.
O local mais óbvio para esse tipo de código é o TC, um módulo de controle de fluxo. No TC, o programa eBPF tem acesso ao pacote criado, podendo ler e escrever dados do pacote. Uma desvantagem é que o pacote precisa ser analisado desde o início, ou seja, mesmo que a função bpf_skb_load_bytes_relative forneça um ponteiro para o início do cabeçalho L3, a posição L4 ainda precisa ser calculada manualmente. O mais problemático é a operação de inserção. Existem 2 funções com nomes promissores, bpf_skb_adjust_room e bpf_skb_change_tail , mas elas permitem redimensionamento de pacotes até L3, não L4. Uma solução alternativa é verificar se o cabeçalho TCP existente contém certas opções e substituí-las, mas vamos primeiro verificar o que um pacote típico contém.
1514772378.301862 IP (tos 0x0, ttl 64, id 20960, offset 0, flags [DF], proto TCP (6), length 60)
192.168.3.14.28301 > 10.0.0.76.8000: Flags [S], cksum 0xbc03 (correct), seq 1849406961, win 64240, options [mss 1460,sackOK,TS val 142477455 ecr 0,nop,wscale 9], length 0
0x0000: 0000 0001 0006 fa16 3e22 3096 0000 0800 ........>"0.....
0x0010: 4500 003c 51e0 4000 4006 1ada c0a8 030e E..<Q.@.@.......
0x0020: 0a00 004c 6e8d 1f40 6e3b b5f1 0000 0000 ...Ln..@n;......
0x0030: a002 faf0 bc03 0000 0204 05b4 0402 080a ................
0x0040: 087e 088f 0000 0000 0103 0309 .~..........
Este é o pacote TCP SYN enviado quando o cliente estabelece uma conexão com o aplicativo backend. O cabeçalho contém várias opções: MSS para especificar o tamanho máximo do segmento, depois uma confirmação opcional, um carimbo de data / hora específico para garantir a ordem dos pacotes, um opcode NOP possivelmente para alinhamento de palavras e, finalmente, para alinhamento Escala de janela para tamanho de janela. Dessa lista, a opção timestamp é a melhor candidata a ser contemplada (de acordo com a Wikipedia, a adoção ainda gira em torno de 40%), enquanto o DeepFlow – um dos líderes em rastreamento não intrusivo de eBPF – tem essa operação realizada em .
Embora esta abordagem pareça viável, não é fácil de implementar. O programa TC tem acesso aos endereços traduzidos, o que significa que o mapa de tradução deve de alguma forma ser recuperado do módulo conntrack e armazenado. O programa TC é anexado à placa de rede, portanto, se um nó tiver diversas placas de rede, a implantação precisará identificar corretamente o local do anexo. O módulo leitor precisa analisar todos os pacotes para encontrar o TCP e então percorrer os cabeçalhos para descobrir onde está nosso cabeçalho. Existe alguma outra maneira?
Ao pesquisar esta pergunta no Google em agosto de 2023, é comum ver No More Results na parte inferior da página de resultados de pesquisa (espero que esta postagem do blog mude isso!). A referência mais útil é um link para um patch do Kernel Linux produzido pelos engenheiros do Facebook em 2020. Este patch mostra o que procuramos:
Os primeiros trabalhos no BPF-TCP-CC permitiram que algoritmos de controle de congestionamento TCP fossem escritos em BPF. Ele oferece a oportunidade de melhorar o tempo de resposta em ambientes de produção ao testar/liberar novas ideias de controle de congestionamento. A mesma flexibilidade pode ser estendida para escrever opções de cabeçalho TCP.
Não é incomum que as pessoas queiram testar novas opções de cabeçalho TCP para melhorar o desempenho do TCP. Outro caso de uso é para data centers que possuem um ambiente mais controlado e podem colocar opções de cabeçalho apenas no tráfego interno, o que dá mais flexibilidade.
O Santo Graal são estas funções: bpf_store_hdr_opt e bpf_load_hdr_opt ! Ambos pertencem a um tipo especial de programa sock ops , disponível desde o kernel 5.10, o que significa que podem ser usados em quase qualquer versão após 2022. O programa Sock ops é uma função única anexada ao cgroup v2 que permite que ele seja habilitado apenas para determinados soquetes (por exemplo, pertencentes a um contêiner específico). O programa recebe uma única operação indicando o estado atual do soquete. Quando queremos escrever uma nova opção de cabeçalho, primeiro precisamos habilitar a escrita para uma conexão ativa ou passiva e, em seguida, precisamos informar o novo comprimento do cabeçalho antes que a carga útil do cabeçalho possa ser escrita. A operação de leitura é mais simples, no entanto, também precisamos habilitar a leitura primeiro antes de podermos ler as opções de cabeçalho. Quando um pacote TCP é criado, o retorno de chamada do cabeçalho TCP é chamado. Isso acontece antes da tradução do endereço, para que possamos copiar o endereço de origem do soquete nas opções do cabeçalho. O leitor pode facilmente extrair o valor da opção de cabeçalho e armazená-lo em um mapa BPF para que posteriormente o consumidor possa ler e mapear do endereço remoto observado para o endereço real. A parte BPF do primeiro código de execução tem muito menos de 100 linhas. Muito bom!
Prepare o código para produção
No entanto, o diabo está nos detalhes. Primeiro, precisamos de uma forma de excluir registros antigos do mapa BPF. O melhor momento para fazer isso é quando o módulo conntrack exclui a conexão de sua tabela. Este artigo de Arthur Chiao fornece uma boa descrição do módulo conntrack e da estrutura interna do ciclo de vida da conexão, por isso é fácil encontrar a função correta nas fontes do kernel - nf_conntrack_destroy . Esta função recebe a entrada conntrack antes de excluí-la da tabela interna. Como é quando a conexão termina oficialmente, também podemos adicionar uma sonda que também removerá a conexão da nossa tabela de mapeamento.
No programa sock ops, não especificamos em quais pacotes a nova opção de cabeçalho é injetada, assumindo que ela se aplica a todos os pacotes. Na verdade, isso é verdade, mas a leitura só é eficaz quando a conexão está no estado estabelecido/reconhecido, o que significa que o lado do servidor não pode ler as opções de cabeçalho do pacote SYN recebido. SYN-ACK também é processado antes da pilha TCP normal e as opções de cabeçalho não podem ser injetadas nem lidas. Na verdade, esse recurso só funciona nas duas pontas se a conexão for executada inteiramente com o primeiro PSH (pacote). Isso é perfeitamente adequado para uma conexão funcional, mas se a tentativa de conexão falhar, o cliente não saberá para onde estava tentando se conectar. Este é um erro crítico; esta informação é útil para depurar problemas de rede. Como sabemos, o balanceamento de carga do Kubernetes é implementado no nó cliente, para que possamos extrair as informações do conntrack e armazená-las no mesmo formato dos dados recebidos pelo stream. A função Conntrack ___nf_conntrack_confirm_ ajuda aqui - ela é chamada quando uma nova conexão está prestes a ser confirmada, o que para conexões TCP de cliente ativo (de saída) ocorre quando o primeiro pacote SYN é enviado.
Com todas essas adições, o código fica um pouco inchado, mas ainda assim tem bem menos de 1.000 linhas no total. O patch completo está disponível neste MR . É hora de habilitá-lo em nossa configuração experimental e verificar as métricas e a topologia novamente!
Olhar:
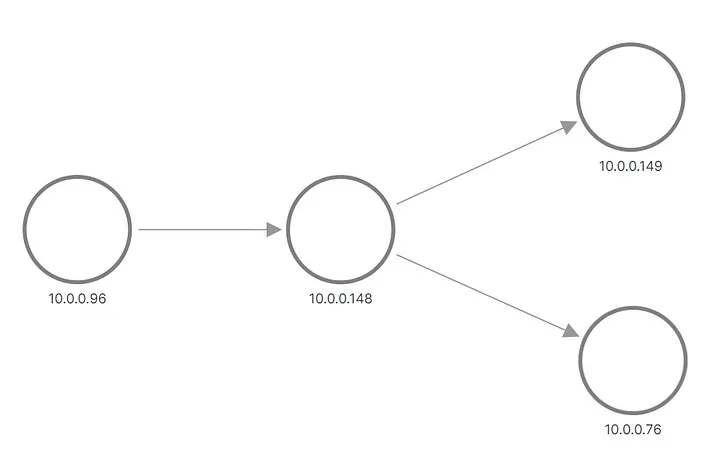
Topologia correta do aplicativo A/B
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes para plataformas Windows no futuroEste artigo foi publicado pela primeira vez em Yunyunzhongsheng ( https://yylives.cc/ ), todos são bem-vindos para visitar.