
Autor: Equipe de Big Data da Internet da vivo - Huang Guihu, Chen Shengzun
HBase é um banco de dados não relacional distribuído de código aberto com alta confiabilidade, alta escalabilidade e alto desempenho. É amplamente utilizado em processamento de big data, computação em tempo real, armazenamento e recuperação de dados e outros campos. Em um cluster distribuído, a falha de hardware é uma ocorrência comum. A falha de hardware pode levar à interrupção do serviço no nível do nó ou do cluster, danos à metatabela, RIT, falhas de região, sobreposições e outros problemas. particularmente importante. Este artigo trata principalmente de Descrever falhas comuns e soluções correspondentes em torno de metatabelas HBase.
1. Fundo
Acredito que amigos que fizeram trabalhos relacionados ao desenvolvimento, operação e manutenção do HBase têm, até certo ponto, essa sensação de que o HBase, como líder em bancos de dados não relacionais distribuídos, não é apenas estável, de alto desempenho e muito simples de instalar e expandir. , mas também carece de sistemas de monitoramento maduros que são extremamente hostis à solução de problemas. Se você não tiver um conhecimento abrangente do HBase, muitas vezes não terá como lidar com falhas diárias. Como editores, operamos e mantemos mais de 20 clusters HBase de vários tamanhos envolvendo as versões 1.x~2.x. experimentamos corrupção de metatabelas e falha ao ficar on-line normalmente, sobreposições de regiões. Temos lidado com problemas on-line, como falhas de região e perdas de permissões, e também buscamos as respostas corretas no código-fonte do HBase com vários problemas. solução comum para a metatabela que os editores resumiram de muitas falhas.
2. Tabela de meta-informações do HBase
A metatabela HBase, também conhecida como tabela de catálogo, é uma tabela HBase especial que armazena todas as regiões no cluster HBase e suas informações RegionServer correspondentes. A precisão dos dados da tabela de metainformações é crucial para a operação normal do cluster HBase. portanto, é necessário garantir que os dados corretos na tabela de metainformações sejam uma condição necessária para a operação estável do cluster. Se os dados na metatabela forem inconsistentes, isso causará RIT (Region In Transition) ou mesmo o cluster não poderá iniciar normalmente porque o HMaster não pode ser inicializado normalmente. Isso mostra a importância da metatabela no cluster HBase. a estrutura da metatabela, formato de dados, inicie o processo de análise (este artigo se concentra principalmente na versão HBase 2.4.8 e também intercalará a versão HBase 1.x).
2.1 estrutura da metatabela
A metatabela inclui principalmente três famílias de colunas: info, table e rep_barrier, que registram respectivamente informações da região e status da tabela:
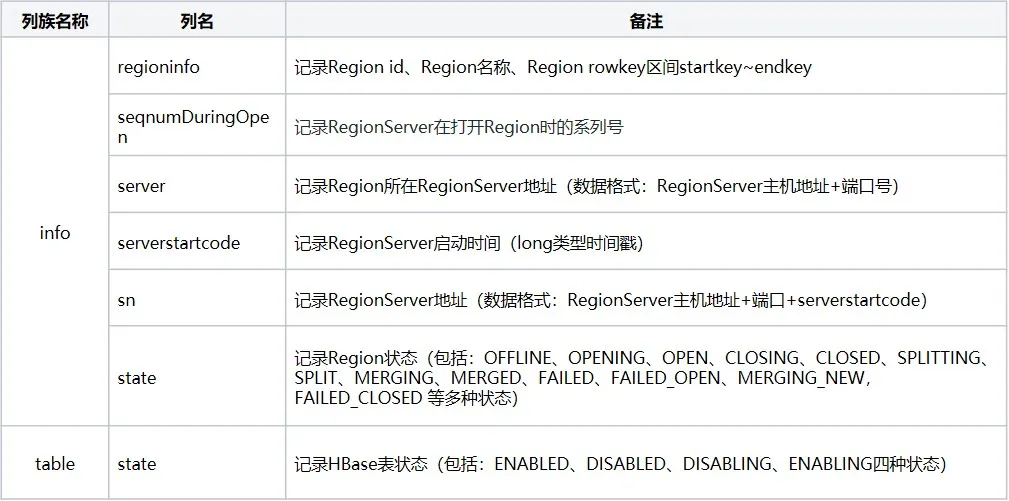
2.2 processo de carregamento de metatabela
Através da estrutura da metatabela acima, temos uma compreensão geral da tabela. Amigos que realizaram operação e manutenção do HBase acreditam que todos eles têm essa experiência. Alguns clusters iniciam mais rápido, alguns clusters iniciam mais lentamente e, às vezes, até o cluster reinicia devido a. operação inadequada. Ele ficou preso no carregamento da metatabela e não pode continuar a executar processos subsequentes. Se tivermos uma compreensão geral do processo de carregamento da metatabela, teremos uma expectativa mais ou menos psicológica para cada tempo de inicialização do cluster. A seguir está o processo relacionado ao carregamento da metatabela:
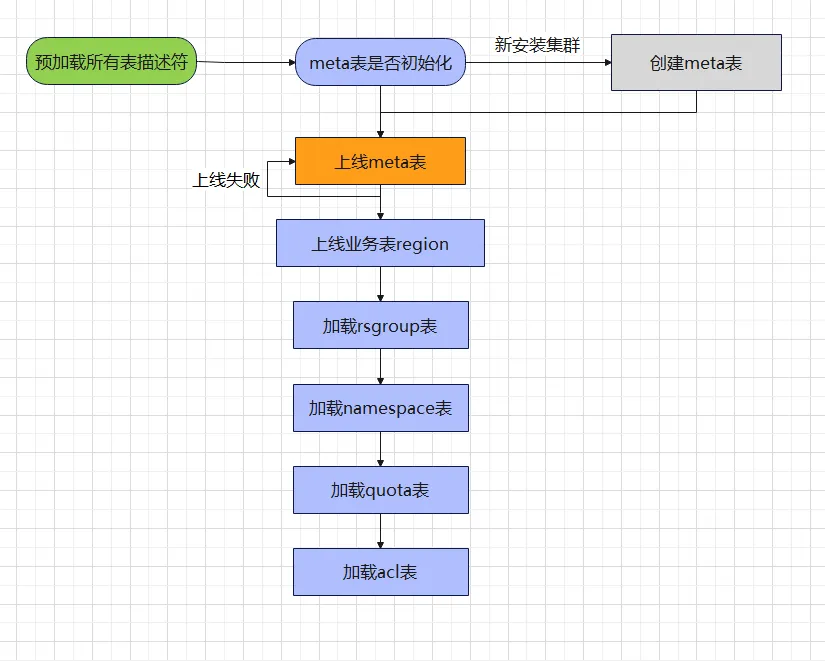
Por meio do fluxograma de carregamento da metatabela acima, podemos descobrir facilmente por que alguns clusters iniciam lentamente e outros falham ao iniciar. Abaixo, analisamos dois tipos de cenários:
- O cluster começa lentamente:
Normalmente, novos clusters ou clusters com menos tabelas tendem a iniciar mais rápido, enquanto clusters com mais tabelas tendem a iniciar muito mais lentamente. Alguns clusters levam até 15 a 30 minutos para iniciar o HMaster. há algo errado com o cluster Por que ele não consegue entrar em um estado normal por tanto tempo? Existem dois locais que demoram muito em todo o processo de carregamento.
Pré-carregar todos os descritores de tabela : você precisa verificar todo o diretório de dados do HBase e analisar os arquivos de dados no diretório .tabledesc e armazená-los na memória do HMaster. Se houver um grande número de tabelas (mais de 10.000 tabelas), esse processo será frequente. leva cerca de dez minutos. Quando vemos as palavras "descritores de tabela de pré-carregamento" aparecerem na página do HMaster, significa que o cluster está no estágio de pré-carregamento. Só precisamos esperar pacientemente, porque o estágio de carregamento da metatabela ainda não chegou. alcançado.
Região da tabela de negócios online : O tamanho dos dados da metatabela geralmente está entre dezenas de MB e centenas de MB. O tempo de abertura da região é relativamente rápido (segundos). Durante a fase de inicialização do cluster, a região offline precisa ser verificada e online. deseja acelerar a velocidade de abertura, você pode ajustar o valor hbase apropriadamente.
- Falha na inicialização do cluster:
Falha on-line da metatabela : quando o HRegionServer do grupo de recursos padrão desliga e o código inicial da máquina muda após a reinicialização, o fragmento de metadados não consegue encontrar o nó aberto, fazendo com que o cluster falhe ao iniciar.
3. Como reparar a metatabela
Como o status do cluster HBase é mantido principalmente por meio da metatabela, se a metatabela estiver danificada ou errada, o cluster HBase ficará indisponível e enfrentará o risco de perda de dados. Sabemos que a consistência dos dados da metatabela é muito importante, então em que circunstâncias ocorrerá a inconsistência dos dados? (Para comandos de reparo do HBase 2.4.8, consulte a ferramenta hbase-operator-tools).
-
RegionServer está inativo ou anormal : Quando RegionServer está inativo ou anormal, as informações de região e RegionServer armazenadas na metatabela podem estar incorretas ou perdidas.
-
Corrupção ou erros de dados : quando os dados na metatabela estão corrompidos ou incorretos, isso pode levar à indisponibilidade do cluster HBase e à perda de dados.
-
Operações ilegais : quando operações ilegais são executadas na metatabela, como excluir ou modificar dados na metatabela, isso pode causar erros ou perda da metatabela.
Falha na metatabela é apenas um termo geral. Podemos dividi-la aproximadamente em RIT de longo prazo, buraco de região, sobreposição de região, perda de arquivo de descrição de tabela, caminho hdfs de metatabela vazio, perda de dados de metatabela, etc. Vou discuti-los respectivamente. Esses tipos de falhas são analisados e corrigidos:
3.1 RIT
RIT (Região em Transição) refere-se à transição de estado em andamento no cluster HBase. As operações a seguir farão com que o estado da região no cluster HBase seja alterado. Por exemplo, o RegionServer está inativo, a região está dividida, mesclada e. outras operações O estado da região inclui principalmente os seguintes doze estados e diagrama de transformação:
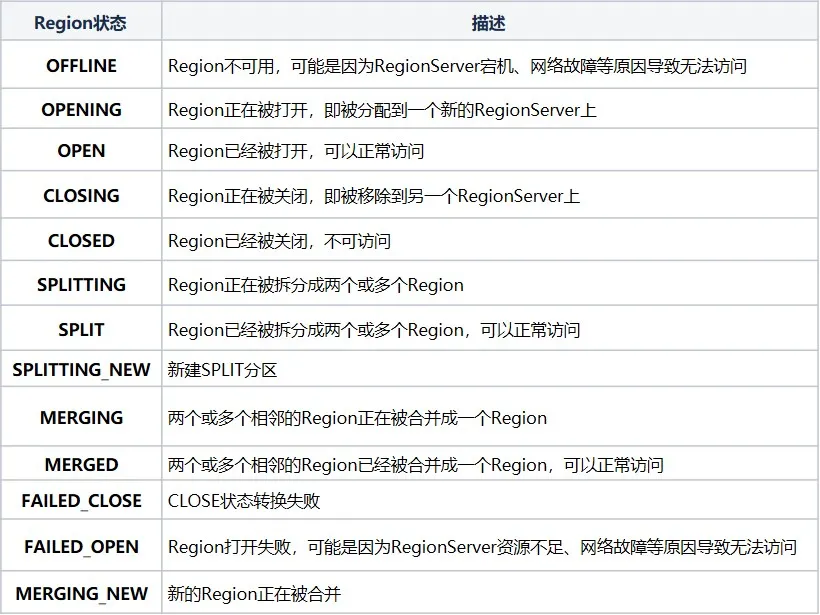
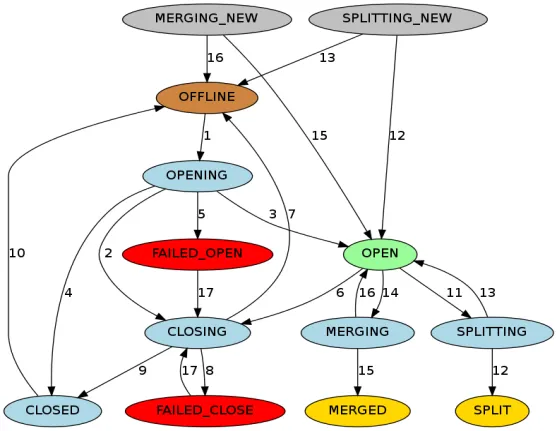
Para ser mais claro sobre o status da região, podemos dividi-lo em atribuir, cancelar atribuição, dividir e mesclar de acordo com o tipo de operação. Se o RegionServer estiver inativo ou anormal, os dados forem danificados ou ocorrerem erros durante a operação, o RIT irá. Embora o RIT seja frequentemente encontrado em problemas de operação e manutenção do HBase, se a lógica subjacente for clara, será mais fácil lidar com os problemas do cluster RIT. A maioria dos casos pode ser restaurada normalmente sem intervenção manual. a intervenção é necessária apenas quando a RIT ocorre por um longo período. Então, qual é o tempo de longo prazo para a RIT? Por que ocorre RIT de longo prazo?
Se você usou as versões HBase 1.xe HBase 2.x, obviamente sentirá que o RIT é menos comum no HBase 2.x. Na verdade, a operação da região é principalmente para transferir a região por meio da classe AssignmentManager. nos códigos das duas versões, descobrimos que hbase.assignment.maximum O valor padrão do parâmetro de tentativas (número de tentativas de atribuição) é diferente nas duas versões. O número de tentativas no HBase 2.4.8 é o número inteiro máximo. .MAX_VALUE (embora o valor padrão seja 10 no HBase 1.x). É por isso que no HBase os motivos para RIT de longo prazo são relativamente raros no 2.x.
Método de processamento RIT:
-
O RIT ocorrerá ao criar ou excluir tabelas grandes. Isso se deve principalmente ao grande número de regiões e à alta pressão no cluster, o que resulta em longos tempos de resposta para atribuição e não atribuição. Para esse tipo de problema, o HBase geralmente não requer manual. intervenção e pode curar-se.
-
Se a versão do cluster for 1.x, você poderá ajustar adequadamente o valor hbase.assignment.maximum.attempts para aumentar o número de novas tentativas. Por exemplo, FAILED_OPEN e FAILED_CLOSE geralmente podem se auto-curar ou executar manualmente o comando de atribuição para atribuir cada um. Região online (se houver muitas regiões, mude para reparo HMaster).
-
Se a alocação de região falhar e não houver RegionServer, a atribuição manual não poderá ser restaurada. Por exemplo, a região será atribuída a bogus.example.com e os nós 1 e 1 só poderão ser restaurados alternando o HMaster.
Perguntas para pensar:
Por que a região não consegue ficar online normalmente mesmo após intervenção manual e pode ser restaurada trocando o HMaster? (Consulte o processo de inicialização do HMaster TransitRegionStateProcedure, código-fonte da classe HMaster)
3.2 Buraco Regional
Quando criamos uma tabela HBase, se analisarmos cuidadosamente as regras da região, ficaremos surpresos ao descobrir que a chave inicial e a chave final da região pertencem a intervalos contínuos que são fechados à esquerda e abertos à direita. um desses intervalos está faltando (conforme mostrado abaixo)?
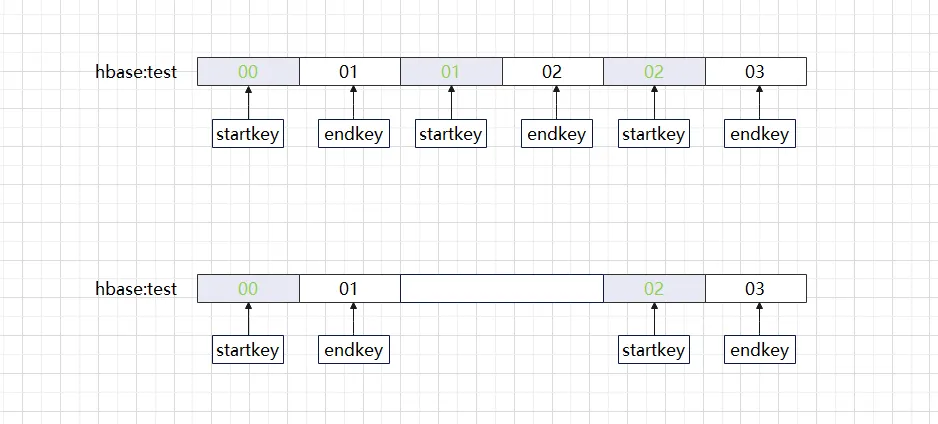
A situação acima é o que costumamos chamar de buraco na região. Se você usar a ferramenta HBase hbck para verificar, verá a mensagem de erro ERRO: Há um buraco na cadeia de regiões entre 01 e 02. Você precisa criar um buraco. novo .regioninfo e diretório de região em hdfs para tapar o buraco Quando um buraco aparece em um cluster HBase, ele geralmente não consegue se curar e requer intervenção manual para retornar ao normal. Agora que sabemos que uma região está faltando, não é? será suficiente preenchermos apenas a Região no intervalo em branco? A abordagem normal é primeiro adicionar novamente a região em branco, verificar se as informações da metatabela estão corretas e, finalmente, ficar online com a região. Se esta série de operações for feita manualmente, ela não apenas estará sujeita a erros, mas também sofrerá um erro. muito tempo. Aqui estão os diferentes métodos de reparo do HBase, na verdade, embora os métodos de processamento das diferentes versões sejam ligeiramente diferentes, o processo de processamento é o mesmo.
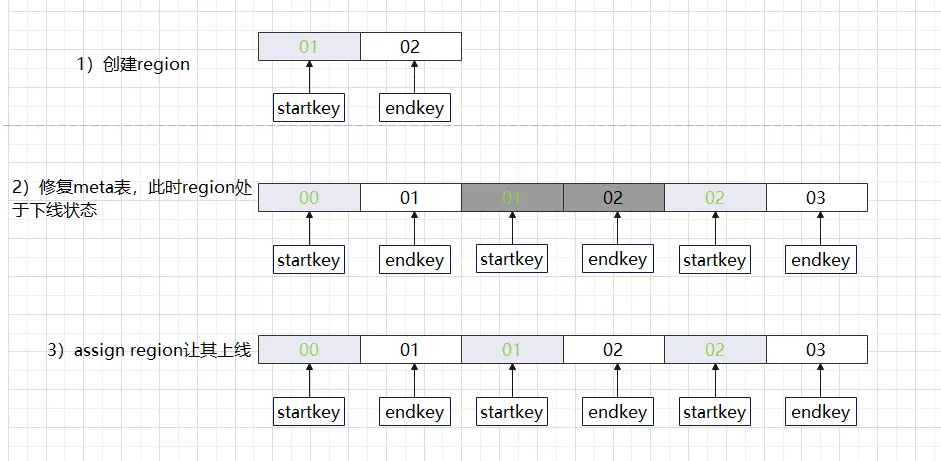
Método de processamento de buraco regional:
(1) Método de reparo HBase 1.x
-
HBase hbck –fixHdfsHoles : Crie um caminho de arquivo de região vazio em hdfs
-
HBase hbck -fixMeta : repara os dados da metatabela onde a região está localizada
-
HBase hbck –fixAssignments : Região após reparo online
-
Ou HBase hbck –repairHoles é equivalente a uma combinação de (fixHdfsHoles, fixMeta, fixAssignments)
(2) Método de reparo do HBase 2.4.8 (consulte a ferramenta hbase-operator-tools posteriormente)
Como o HBase 2.4.8 não fornece comandos relevantes para adicionar operações de diretório de região, é relativamente problemático. Na verdade, muitas classes de ferramentas no HBase 2.4.8 fornecem métodos para criar regiões e a classe HBaseTestingUtility no hbase-server-2.4. O pacote de 8 testes os fornece Para operar a entrada relacionada à região, nossa solução abaixo concentra-se principalmente na recuperação com base neste método.
-
extraRegionsInMeta -fix : primeiro exclua os registros que não existem no diretório hdfs na metatabela.
-
HBaseTestingUtility.createLocalHRegion : Crie o caminho do arquivo hdfs para garantir a continuidade da região
-
addFsRegionsMissingInMeta : adiciona novas informações de região à metatabela (o ID da região será retornado após a adição ser bem-sucedida)
-
atribui : Finalmente coloque a região recém-adicionada online
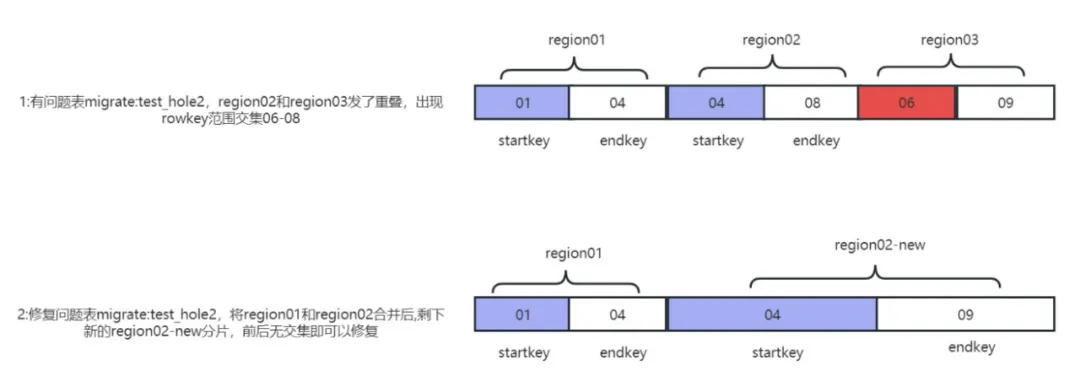
3.3 Sobreposição de regiões
Como haverá lacunas na região, isso acontecerá? Haverá várias chaves de início e de fim idênticas? A resposta é sim. Se a chave inicial e a chave final de várias regiões forem a mesma região, chamaremos essa situação de Regiões sobrepostas. A sobreposição de regiões é difícil de simular no HBase e também é um problema difícil de resolver. Se fizermos a verificação hbck e esse tipo de log aparecer ERRO: Múltiplas regiões têm a mesma tecla de início: 02

Outro tipo de região sobreposta cruza o intervalo de chaves de linha de um ou dois fragmentos adjacentes. Esse tipo de problema é chamado coletivamente de problema de sobreposição. Para esse cenário mais difícil, usamos ferramentas autodesenvolvidas para simular a recorrência do problema de sobreposição e reparar. a sobreposição com um clique (dobragem) e problemas de furo (furo).
função de simulação de problema de sobreposição
O problema de sobreposição de regiões é, na verdade, duas regiões diferentes. Os intervalos de chaves de linha, por exemplo, a chave inicial e a chave final da Região01 são (01,03), e o intervalo de outra Região02 é (01,02). as duas regiões se cruzam (01,02), a detecção de hbck reportará um problema de sobreposição.
No ambiente de produção, o problema de sobreposição só ocorrerá quando a região for dividida e a máquina desligar ao mesmo tempo. As condições são relativamente adversas e é difícil reproduzir o problema no futuro. reparos e exercícios de falha O problema de sobreposição Princípio de reprodução:
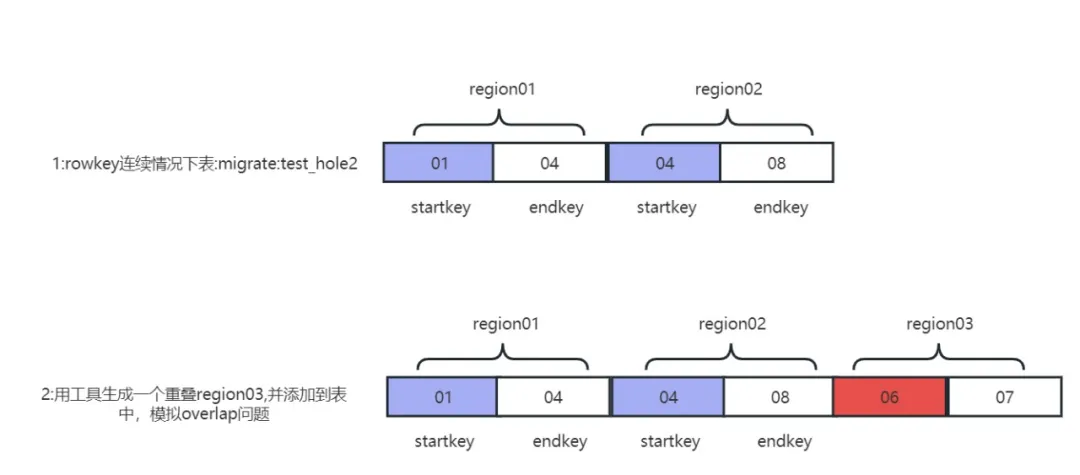
sobreposição de recorrência de problema
1) Gere um fragmento de região com intervalos de rowkey sobrepostos:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=createRegion -DRegion.startkey=06 -DRegion.endkey=07 hbase-meta-tool-0.0.1.jar
2) Mova a região do problema de sobreposição para o diretório da tabela:
sudo -uhdfs hdfs dfs -mv /tmp/.tmp/data/migrate/test_hole2/c8662e08f6ae705237e390029161f58f /hbase/data/migrate/test_hole2
3) Exclua as informações da metatabela da tabela normal Migrate:test_hole2:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
4) Reconstrua as informações de metadados da tabela de problemas de sobreposição:
java -jar -Drepair.tableName=migrate:test_hole2 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
5) Após reiniciar o cluster, hbck relatou que a região se sobrepôs a c8662e08f6ae705237e390029161f58f e o problema de sobreposição foi reproduzido com sucesso.

Método 1: Reparar sobreposições e furos com um clique
Adequada para casos em que o número de dobras não excede 64, a ferramenta autodesenvolvida hbase-meta-tool pode ser usada para mesclar os intervalos de regiões adjacentes com interseções de rowkey e gerar novas regiões se houver buracos ou intervalos ausentes, então que o problema pode ser reparado. Princípio da reparação do problema Como mostrado na imagem:
1) Corrija problemas de sobreposição e furos de cluster:
java -jar -Dfix.operator= fixOverlapAndHole hbase-meta-tool-0.0.1.jar
Método 2: reparo dobrável em grande escala
Adequado para dobrar em grande escala mais de milhares ou dezenas de milhares de casos para reparar anormalidades no lado do servidor, siga os seguintes métodos de reparo
1) Limpe os metadados de tabelas com problemas de dobramento com um clique:
java -jar -Drepair.tableName=migrate:test1 -Dzookeeper.address=zkAddress -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Faça backup dos dados originais da tabela:
hdfs dfs -mv /hbase/data/migrate/test/ /back
3) Exclua a tabela original e importe os dados de backup para cada fragmento de região:
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /back/test/region01-regionN migrate:test1
3.4 Reparo de dados da metatabela
Podemos encontrar os seguintes problemas difíceis em clusters online do HBase:
-
A tabela do coprocessador está configurada incorretamente, o caminho do coprocessador não pode ser localizado e o jar não pode ser encontrado durante o carregamento da região, fazendo com que o cluster trave repetidamente e o comando drop não possa excluí-lo;
-
O número de elementos na metatabela HBase está errado, o código inicial está incorreto, a tabela do servidor não pode ser encontrada durante o processo online e a tabela nunca fica online.
Precisamos reparar a tabela problemática de forma independente, sem interromper o serviço e sem afetar outros serviços de tabela no cluster.
Reparo de metadados da tabela de problemas
1) Supondo que haja um problema com a tabela Migrate:test1, você pode excluir os metadados da tabela problemática com um clique:
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=delete hbase-meta-tool-0.0.1.jar
2) Leia o conteúdo da pasta .regioninfo da tabela hdfs e reconstrua os metadados corretos com um clique:
java -jar -Drepair.tableName=migrate:test1 -Dfix.operator=fixFromHdfs hbase-meta-tool-0.0.1.jar
3.5 meta quebrado
As cinco situações acima são todas reparadas sob a premissa de que a metatabela está online normalmente. Se os dados da metatabela estiverem danificados e não puderem estar online, como devemos repará-los? Normalmente pensamos em reconstruir a metatabela e, em seguida, gravar as informações da região na metatabela. Se o cluster estiver offline, o shell do HBase ou a API do HBase geralmente não poderá executar a criação para construir a tabela.
Analisamos a classe de inicialização da metatabela InitMetaProcedure e descobrimos que o processo de criação da metatabela é dividido em duas etapas:
1) Crie o diretório Region e o arquivo .tabledesc
2) Aloque a região e fique online.
Código-fonte principal do InitMetaProcedure:
ProcedimentoInitMeta
protected Flow executeFromState(MasterProcedureEnv env, InitMetaState state) throws ProcedureSuspendedException, ProcedureYieldException, InterruptedException {
try {
switch (state) {
case INIT_META_WRITE_FS_LAYOUT:
Configuration conf = env.getMasterConfiguration();
Path rootDir = CommonFSUtils.getRootDir(conf);
TableDescriptor td = writeFsLayout(rootDir, conf);
env.getMasterServices().getTableDescriptors().update(td, true);
setNextState(InitMetaState.INIT_META_ASSIGN_META);
return Flow.HAS_MORE_STATE;
case INIT_META_ASSIGN_META:
addChildProcedure(env.getAssignmentManager().createAssignProcedures(Arrays.asList(RegionInfoBuilder.FIRST_META_RegionINFO)));
return Flow.NO_MORE_STATE;
default:
throw new UnsupportedOperationException("unhandled state=" + state);
}
} catch (IOException e) {
}
private static TableDescriptor writeFsLayout(Path rootDir, Configuration conf) throws IOException {
LOG.info("BOOTSTRAP: creating hbase:meta region");
FileSystem fs = rootDir.getFileSystem(conf);
Path tableDir = CommonFSUtils.getTableDir(rootDir, TableName.META_TABLE_NAME);
if (fs.exists(tableDir) && !fs.delete(tableDir, true)) {
LOG.warn("Can not delete partial created meta table, continue...");
}
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(conf, fs, rootDir);
HRegion.createHRegion(RegionInfoBuilder.FIRST_META_RegionINFO, rootDir, conf, metaDescriptor, null).close();
return metaDescriptor;
}
Podemos consultar a lógica do código InitMetaProcedure para escrever as ferramentas correspondentes para criar tabelas e ficar online. Depois que a meta-tabela ficar online, só precisamos escrever as informações da região de cada tabela na meta e atribuir todas as regiões para ficarem online para restaurar o normal. estado do cluster. Através do processo acima, descobrimos que o processo de reparo da metatabela não é tão complicado. No entanto, se houver um grande número de tabelas no ambiente de produção ou se houver milhares de regiões em tabelas grandes individuais, a adição manual torna-se muito demorada. consumindo. Apresentaremos o processo abaixo que sempre foi relativamente simples Solução (ferramenta HBase 1.x hbck, HBase 2.x hbase-operator-tools), vamos dar uma olhada no processo de reparo offline.
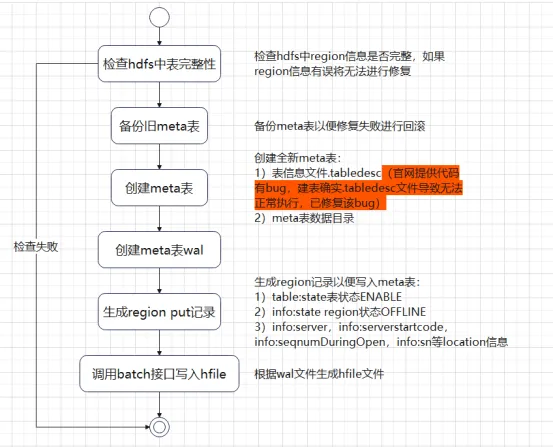
Correções do HBase 1.x
-
Pare o cluster HBase
-
sudo -u hbase hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair -fix
-
Reinicie o cluster para concluir o reparo.
Método de reparo HBase 2.4.8 (ferramenta hbase-operator-tools)
1) Gerar metatabela automaticamente com base no caminho hdfs
-
Pare o cluster HBase
-
sudo -u hbase hbase org.apache.hbase.hbck1.OfflineMetaRepair -fix
-
Reinicie o cluster para concluir o reparo.
2) Método de reparo de mesa única
-
Exclua o diretório raiz do HBase no zookeeper
-
Exclua o diretório hdfs WALs onde HMaster e RegionServer estão localizados
-
Depois de reiniciar o cluster, não há dados no meta e o cluster não pode entrar no estado normal.
-
Execute o comando add Region para adicionar as tabelas de quatro caracteres hbase:namespace, hbase:quota, hbase:rsgroup e hbase:acl ao cluster. Depois que a adição for concluída, o log imprimirá as regiões seguidas por atribuições e essas tabelas. Essas regiões precisam ser registradas para a próxima operação de atribuição.
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-tools.jar addFsRegionsMissingInMeta hbase:namespace hbase:quota hbase:rsgroup hbase:acl
- Adicione a região de impressão na etapa anterior online
sudo -u hbase hbase --config /etc/hbase/conf hbck -j hbase-hbck2.jar assigns regionid
- A mesa de negócios está online (você só precisa repetir as etapas 4 a 5 para colocar gradualmente a mesa de negócios online)
Precauções
(Se houver muitas regiões na tabela de negócios e a quinta região não for atribuída, todas as regiões não poderão ser colocadas online com sucesso. Você precisa desabilitar e habilitar o desempenho para ficar online normalmente)
Nota: A ferramenta hbase-operator-tools OfflineMetaRepair possui os seguintes bugs que precisam ser corrigidos.
1. A metatabela criada pelo método createNewMeta HBaseFsck não possui o arquivo .tabledesc.
antes de consertar:
TableDescriptor td = new FSTableDescriptors(getConf()).get(TableName.META_TABLE_NAME);
Após modificação:
FileSystem fs = rootdir.getFileSystem(conf);
TableDescriptor metaDescriptor = FSTableDescriptors.tryUpdateAndGetMetaTableDescriptor(getConf(), fs, rootdir);
2. O estado de região padrão do HBaseFsck generatePuts é CLOSED porque o HMaster só fica online no estado OFFLINE quando é reiniciado (se estiver CLOSED, a carga de trabalho de ficar online manualmente, um por um, é muito grande)
antes de consertar:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.CLOSED);
Após modificação:
addRegionStateToPut(p, org.apache.hadoop.hbase.master.RegionState.State.OFFLINE);
deficiência
1) O reparo offline requer a interrupção do serviço do cluster. O tempo de parada depende do tempo de reparo (cerca de 10 a 15 minutos).
2) Se houver problemas como sobreposição de regiões e furos, eles precisarão ser processados manualmente antes de executar o comando de reparo offline OfflineMetaRepair.
4. ferramenta hbase-operator-tools
hbase-operator-tools é um conjunto de ferramentas no HBase usado para auxiliar os administradores do HBase no gerenciamento e manutenção de clusters HBase. hbase-operator-tools fornece uma série de ferramentas, incluindo ferramentas de backup e recuperação, ferramentas de gerenciamento de região, compactação de dados e ferramentas de movimentação, etc., que podem ajudar os administradores a gerenciar melhor os clusters HBase e melhorar a estabilidade e confiabilidade do cluster. Você precisa compilar o código- fonte antes de poder usá-lo . Os comandos comuns são os seguintes:
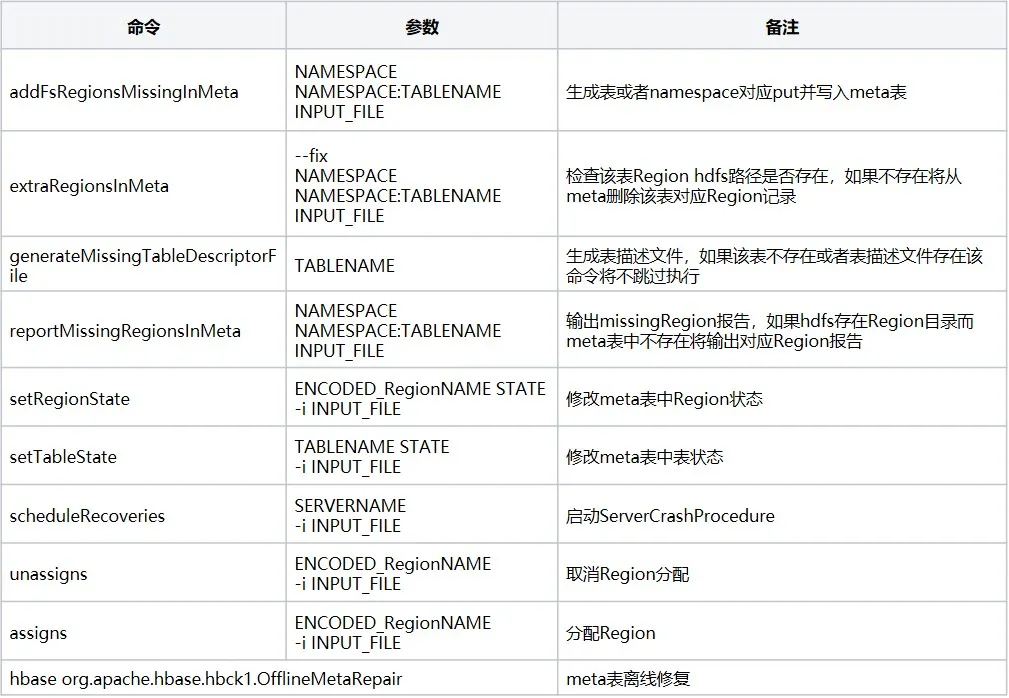
5. Resumo
A precisão dos dados da metatabela HBase é crucial para a operação normal do cluster HBase. Como garantir que os dados da metatabela estejam corretos e como reparar rapidamente os dados após serem danificados é extremamente importante. compreensão abrangente do meta, você ficará perdido sempre que o cluster falhar. Este artigo concentra-se principalmente na análise do processo de carregamento da estrutura da metatabela, problemas comuns e métodos de reparo relacionados. Podemos dividir aproximadamente os métodos de reparo acima nas duas categorias a seguir:
-
Reparo online : A metatabela pode ser reparada normalmente por meio de hbck e ferramentas autodesenvolvidas para garantir a integridade dos dados.
-
Reparo offline : a metatabela não pode ficar online normalmente. A metatabela é reconstruída com base nas informações da região no HDFS para restaurar o serviço HBase.
Se a escala do cluster for relativamente grande e o tempo de reparo offline for relativamente longo, o cluster precisará interromper os serviços por um longo período. Na maioria dos casos, o negócio não pode tolerar isso, com base na situação real. a menos que o arquivo da metatabela esteja danificado e não possa ser colocado on-line normalmente). Recomenda-se realizar verificações hbck no cluster regularmente. Quando ocorrer inconsistência de metainformações, repare-o o mais rápido possível para evitar a propagação do problema (por exemplo,). se as metainformações foram alteradas e o cluster for reiniciado e a região desordenada não puder ser atribuída, outras regiões não poderão ficar on-line normalmente. Se a inspeção regular descobrir que há confusão de metainformações na tabela de negócios, reinicie-o diretamente. A metatabela exclui as informações da tabela e adiciona a região de volta à metatabela com base nas informações do caminho hdfs (o comando addFsRegions-MissingInMeta pode adicionar corretamente a região à metatabela com base no caminho hdfs).
Artigo de referência:
Estudantes do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com a defesa, a Apple lançou o chip M4 RustDesk Os serviços domésticos foram suspensos devido a fraude desenfreada. No futuro, ele planeja produzir um jogo independente na plataforma Windows Taobao (taobao.com) Reiniciar o trabalho de otimização da versão web, destino dos programadores, Visual Studio Code 1.89 lança Java 17, a versão Java LTS mais comumente usada, Windows 10 tem um participação de mercado de 70%, o Windows 11 continua diminuindo Open Source Daily | Google apoia Hongmeng para assumir o controle do Rabbit R1 de código aberto; a ansiedade e as ambições da Microsoft encerraram a plataforma aberta;