
Com o desenvolvimento da tecnologia de modelo de linguagem grande (LLM), a tecnologia RAG (Retrieval Augmented Generation) tem sido amplamente discutida e pesquisada, e métodos cada vez mais avançados de recuperação de RAG foram descobertos. Em comparação com a recuperação de RAG comum, o RAG avançado fornece métodos mais precisos. resultados de recuperação de informações mais relevantes e ricos por meio de detalhes técnicos mais profundos e estratégias de pesquisa mais complexas. Este artigo discute primeiro essas tecnologias e apresenta um caso de implementação baseado em Milvus.
01.RAG Júnior
Definição de RAG primário
O paradigma primário de pesquisa RAG representa a metodologia mais antiga e ganhou importância logo após a adoção generalizada do ChatGPT. O RAG primário segue o processo tradicional, incluindo indexação, recuperação e geração. É frequentemente descrito como uma estrutura de "leitura de recuperação" e seu fluxo de trabalho inclui três etapas principais:
-
O corpus é dividido em partes discretas e um modelo codificador é então usado para construir índices vetoriais.
-
O RAG identifica e recupera pedaços com base na similaridade vetorial entre consultas e pedaços indexados.
-
O modelo gera respostas com base nas informações contextuais obtidas no Retrieved Chunk.
Limitações do RAG primário
O RAG primário enfrenta desafios significativos em três áreas principais: “recuperação”, “geração” e “aprimoramento”.
Existem muitos problemas com a qualidade de recuperação do RAG primário, como baixa precisão e baixa recuperação. A baixa precisão pode levar ao desalinhamento dos blocos recuperados, bem como a problemas potenciais, como alucinações. Uma baixa taxa de recuperação resultará na incapacidade de recuperar todos os blocos relevantes, resultando em uma resposta insuficientemente abrangente do LLM. Além disso, o uso de informações mais antigas agrava ainda mais o problema e pode levar a resultados de pesquisa imprecisos.
A qualidade das respostas geradas enfrenta desafios ilusórios, ou seja, as respostas geradas pelo LLM não são baseadas no contexto fornecido, não são relevantes para o contexto, ou as respostas geradas têm o risco potencial de conter conteúdo prejudicial ou discriminatório.
Durante o processo de aprimoramento, o RAG primário também enfrenta desafios consideráveis em como integrar efetivamente o contexto das passagens recuperadas com a tarefa de geração atual. A integração ineficiente pode resultar em resultados incoerentes ou fragmentados. A redundância e a duplicação também são uma questão espinhosa, especialmente quando múltiplas passagens recuperadas contêm informações semelhantes e conteúdo duplicado pode aparecer nas respostas geradas.
02. RAG Avançado
Para resolver as deficiências do RAG primário, nasceu o RAG avançado e as suas funções foram melhoradas de forma direcionada. Primeiro discutiremos essas técnicas, que podem ser categorizadas como otimização pré-recuperação, otimização intermediária e otimização pós-recuperação.
Otimização pré-pesquisa
A otimização de pré-recuperação concentra-se na otimização do índice de dados e na otimização de consulta. A tecnologia de otimização do índice de dados visa armazenar dados de uma forma que melhore a eficiência da recuperação:
-
Janela deslizante: Utiliza sobreposição entre blocos de dados, esta é uma das técnicas mais simples.
-
Melhore a granularidade dos dados: aplique técnicas de limpeza de dados, como remoção de informações irrelevantes, confirmação da precisão factual, atualização de informações desatualizadas, etc.
-
Adicione metadados: como informações de data, finalidade ou capítulo para filtragem.
-
A otimização da estrutura do índice envolve diferentes estratégias de indexação de dados: como ajustar o tamanho do bloco ou usar uma estratégia de vários índices. Uma técnica que implementaremos neste artigo é a recuperação de janela de sentença, que incorpora sentenças individuais no momento da recuperação e as substitui por janelas de texto maiores no momento da inferência.
Otimize durante a pesquisa
A fase de recuperação concentra-se na identificação do contexto mais relevante. Normalmente, a recuperação é baseada na pesquisa vetorial, que calcula a similaridade semântica entre a consulta e os dados indexados. Portanto, a maioria das técnicas de otimização de pesquisa giram em torno de modelos de incorporação:
-
Ajustar modelos de incorporação: Personalize modelos de incorporação para contextos de domínio específicos, especialmente para domínios com terminologia rara ou de desenvolvimento. Por exemplo,
BAAI/bge-small-ené um modelo de incorporação de alto desempenho que pode ser ajustado. -
Incorporação dinâmica: adapta-se ao contexto em que as palavras são usadas, ao contrário da incorporação estática que utiliza um vetor por palavra. Por exemplo, o OpenAI
embeddings-ada-02é um modelo de incorporação dinâmica complexo que captura a compreensão contextual. Além da pesquisa vetorial, existem outras técnicas de recuperação, como a pesquisa híbrida, que geralmente se refere ao conceito de combinar a pesquisa vetorial com a pesquisa baseada em palavras-chave. Essa técnica de pesquisa é benéfica se a pesquisa exigir correspondências exatas de palavras-chave.
Otimização pós-recuperação
Para o conteúdo de contexto recuperado, encontraremos ruído, como o contexto excedendo o limite da janela ou o ruído introduzido pelo contexto, que desviará a atenção das informações principais:
-
Compactação de prompts: reduza o comprimento geral dos prompts removendo conteúdo irrelevante e destacando contextos importantes.
-
Reclassificação: Use um modelo de aprendizado de máquina para recalcular a pontuação de relevância do contexto recuperado.
As técnicas de otimização pós-pesquisa incluem:
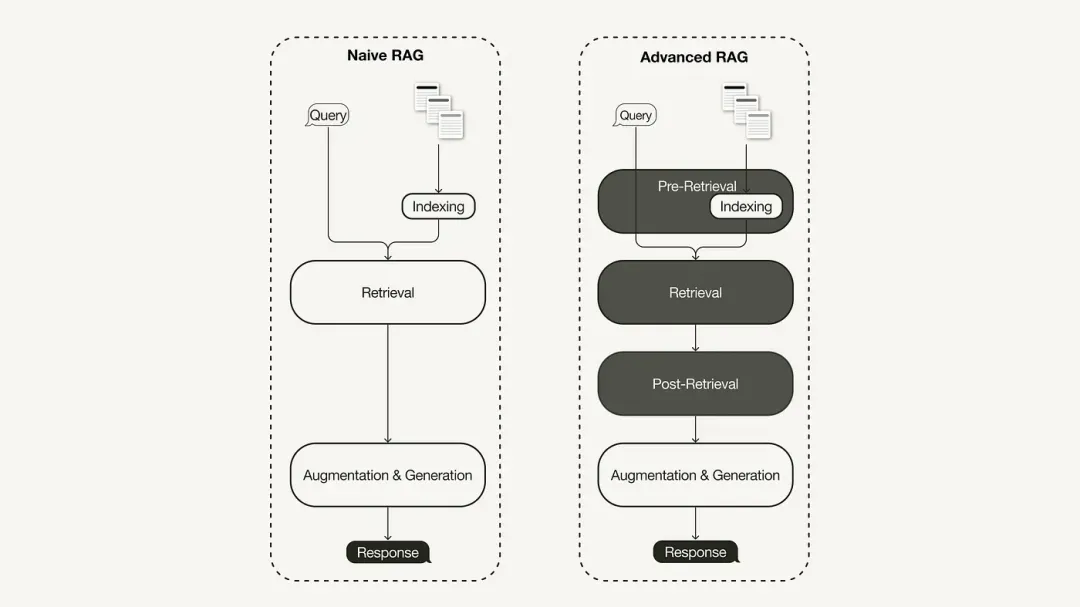
03. Implementar RAG avançado baseado em Milvus + LlamaIndex
O RAG avançado que implementamos usa o modelo de linguagem OpenAI, o modelo de rearranjo BAAI hospedado no Hugging Face e o banco de dados vetorial Milvus.
Criar índice Milvus
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)
Exemplo de otimização de índice: recuperação de janela de frase
Usamos SentenceWindowNodeParser em LlamaIndex para implementar a tecnologia de recuperação de janela de frase.
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser executa duas operações:
Ele separa o documento em frases separadas, que são incorporadas.
Para cada frase, cria uma janela de contexto. Se você especificar window_size = 3, a janela resultante conterá três sentenças, começando com a sentença anterior à sentença incorporada e estendendo-se até a sentença seguinte. Esta janela será armazenada como metadados. Durante a recuperação, a frase que melhor corresponde à consulta é retornada. Após a recuperação, você precisa substituir a frase pela janela inteira dos metadados, definindo a MetadataReplacementPostProcessore usando-a na lista.node_postprocessors
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
Exemplo de otimização de pesquisa: pesquisa híbrida
A implementação da pesquisa híbrida no LlamaIndex requer apenas duas alterações de parâmetros no mecanismo de consulta, desde que o banco de dados vetorial subjacente suporte consultas de pesquisa híbrida. A versão 2.4 do Milvus não suportava pesquisa híbrida antes, mas na versão 2.4 lançada recentemente, esse recurso já é compatível.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
Exemplo de otimização pós-recuperação: reclassificação
Adicionar uma reclassificação ao RAG avançado requer apenas três etapas simples:
Primeiro, defina um modelo de reclassificação usando Hugging Face BAAI/bge-reranker-base.
No mecanismo de consulta, adicione o modelo de reordenação à node_postprocessorslista.
Aumento do mecanismo de consulta similarity_top_kpara recuperar mais fragmentos de contexto, que podem ser reduzidos para top_n após o rearranjo.
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
Para obter o código de implementação detalhado, consulte o link do Baidu Netdisk: https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1 Código de extração: r2i1
Os recursos piratas de "Qing Yu Nian 2" foram carregados no npm, fazendo com que o npmmirror suspendesse o serviço unpkg. Zhou Hongyi: Não resta muito tempo para o Google. Sugiro que todos os produtos sejam de código aberto . time.sleep(6) aqui desempenha um papel. Linus é o mais ativo em “comer comida de cachorro”! O novo iPad Pro usa 12 GB de chips de memória, mas afirma ter 8 GB de memória. O People’s Daily Online analisa o carregamento estilo matryoshka do software de escritório: Somente resolvendo ativamente o “conjunto” poderemos ter um futuro . novo paradigma de desenvolvimento para Vue3, sem a necessidade de `ref/reactive `, sem necessidade de `ref.value` MySQL 8.4 LTS Manual chinês lançado: Ajuda você a dominar o novo domínio de gerenciamento de banco de dados Tongyi Qianwen nível GPT-4 modelo principal preço reduzido em 97%, 1 yuan e 2 milhões de tokens