


Compartilhando convidados: Qiu Lu, Tang Chunxu, Wang Beinan
Atualmente, os campos da inteligência artificial (IA) e da aprendizagem automática (ML) estão a desenvolver-se rapidamente e torna-se cada vez mais crítico lidar eficazmente com grandes conjuntos de dados durante a formação. Ray tornou-se um participante importante neste campo, permitindo o treinamento de conjuntos de dados em grande escala por meio do processamento eficiente de fluxo de dados. Ray divide grandes conjuntos de dados em partes gerenciáveis e divide os trabalhos de treinamento em tarefas menores, sem a necessidade de armazenar todo o conjunto de dados localmente na máquina de treinamento. No entanto, esta abordagem inovadora também enfrenta certos desafios.
Embora Ray facilite o treinamento com grandes conjuntos de dados, o carregamento de dados ainda é um sério gargalo. Cada época requer o recarregamento de todo o conjunto de dados do armazenamento remoto, o que reduzirá seriamente a utilização da GPU e aumentará o custo de transmissão dos dados armazenados. Portanto, precisamos de um método mais otimizado para gerenciar os dados durante o processo de treinamento e melhorar a eficiência.
Ray usa memória principalmente para armazenar dados, e seu armazenamento de objetos na memória é projetado para dados de tarefas grandes. No entanto, essa abordagem enfrenta gargalos em tarefas com uso intensivo de dados porque os dados necessários para tarefas grandes devem ser pré-carregados no armazenamento de memória do Ray antes da execução. Como o tamanho do armazenamento de objetos geralmente não pode acomodar o conjunto de dados de treinamento, ele não é adequado para armazenar dados em cache em várias épocas de treinamento, o que também destaca a necessidade de uma solução de gerenciamento de dados mais escalável para a estrutura Ray.
Uma das vantagens importantes do Ray é que ele utiliza a GPU para treinamento enquanto utiliza a CPU para carregamento e pré-processamento de dados. Este método garante a utilização eficiente dos recursos de GPU, CPU e memória no cluster Ray, mas também resulta na subutilização dos recursos do disco e na falta de gerenciamento eficaz. Surgiu uma ideia revolucionária: construir uma camada de acesso a dados de alto desempenho para armazenar em cache e acessar conjuntos de dados de treinamento gerenciando de forma inteligente recursos de disco ineficientes em máquinas. Isso pode melhorar significativamente o desempenho geral do treinamento e reduzir o custo de acesso à frequência de armazenamento remoto.
Alluxio acelera o treinamento em conjuntos de dados em grande escala, utilizando de forma inteligente e eficiente a capacidade de disco não utilizada em GPUs e máquinas CPU adjacentes para armazenamento em cache distribuído. Esta abordagem inovadora melhora significativamente o desempenho do carregamento de dados, fundamental para o treinamento com conjuntos de dados em grande escala, ao mesmo tempo que reduz a dependência do armazenamento remoto e os custos de transferência de dados associados.
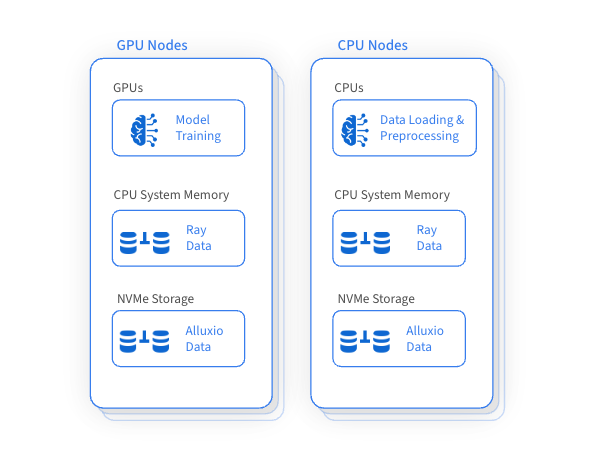
A integração do Alluxio melhora as capacidades de gerenciamento de dados do Ray e traz muitos benefícios:
√
Escalabilidade
O acesso a dados e o cache são altamente escalonáveis
√
Acelere o acesso aos dados
Utiliza discos de alto desempenho para armazenar dados em cache
Otimizado para leitura aleatória de alta simultaneidade de formatos de arquivo de armazenamento de coluna, como Parquet
cópia zero
√
confiabilidade e disponibilidade
Nenhum ponto único de falha
Acesso robusto ao armazenamento remoto durante interrupções
√
Gerenciamento flexível de recursos
Aloque e libere recursos de cache dinamicamente com base nas necessidades da carga de trabalho
Ray pode orquestrar com eficiência fluxos de trabalho de aprendizado de máquina e integrar-se perfeitamente com estruturas de carregamento, pré-processamento e treinamento de dados. Como uma camada de acesso a dados de alto desempenho, o Alluxio pode otimizar muito o treinamento de IA/ML e as tarefas de inferência, especialmente quando os dados de armazenamento remoto precisam ser acessados repetidamente.
Ray utiliza PyArrow para carregar dados e converter o formato de dados em formato Arrow, que é então usado pelo fluxo de trabalho Ray no próximo estágio. PyArrow delega problemas de conexão de armazenamento para a estrutura fsspec, e Alluxio serve como uma camada de cache intermediária entre Ray e sistemas de armazenamento subjacentes (como S3, Azure Blob Storage e Hugging Face).
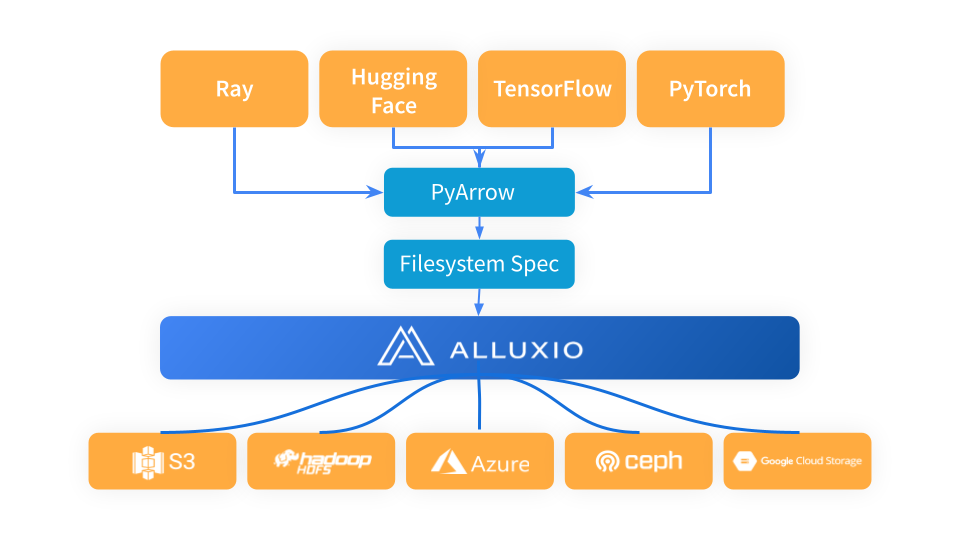
Ao usar o Alluxio como camada de cache entre Ray e S3, basta importar Alluxiofs, inicializar o sistema de arquivos Alluxio e alterar o sistema de arquivos Ray para Alluxio.
# Import fsspec & alluxio fsspec implementationimport fsspecfrom alluxiofs import AlluxioFileSystemfsspec.register_implementation("alluxio", AlluxioFileSystem)# Create Alluxio filesystem with S3 as the underlying storage systemalluxio = fsspec.filesystem("alluxio", target_protocol=”s3”, etcd_host=args.etcd_host)# Ray read data from Alluxio using S3 URLds = ray.data.read_images("s3://datasets/imagenet-full/train", filesystem=alluxio)
Usamos o teste noturno Ray Data da Ray Data para comparar o desempenho de carregamento de dados do Alluxio e S3 na mesma região em diferentes épocas de treinamento. Os resultados do benchmark mostram que os custos de armazenamento podem ser reduzidos significativamente e o rendimento melhorado com a integração do Alluxio com o Ray.

√
Melhor desempenho de acesso aos dados: Observamos que quando o armazenamento de objetos do Ray não é afetado pela pressão da memória, o rendimento do Alluxio é 2 vezes maior que o do S3 na mesma área.
√
A vantagem é mais óbvia sob pressão de memória: é importante notar que quando o armazenamento de objetos de Ray enfrenta pressão de memória, a vantagem de desempenho do Alluxio aumenta significativamente e seu rendimento é 5 vezes maior que o S3.
Para tarefas Ray, é de grande importância estratégica usar recursos de disco não utilizados como armazenamento para cache distribuído. Este método melhora significativamente o desempenho do carregamento de dados e é especialmente útil ao treinar ou ajustar o mesmo conjunto de dados em várias épocas. Além disso, quando Ray enfrenta pressão de memória, ele pode fornecer soluções práticas para otimizar e simplificar o processo de gerenciamento de dados nesses cenários.
✦
[Adicione assistente para obter mais informações]
✦

✦
【Popularidade recente】
✦

✦
【Mercado Baodiano】
✦






Este artigo é compartilhado na conta pública do WeChat - Alluxio (Alluxio_China).
Se houver alguma violação, entre em contato com [email protected] para exclusão.
Este artigo participa do “ Plano de Criação da Fonte OSC ”. Você que está lendo é bem-vindo para participar e compartilhar juntos.