Índice
2. Teste as estatísticas de milhões de dados
1. HiperLogLog
Primeiro entendemos dois conceitos:
UV: O nome completo é Visitante Único, também chamado de visitantes únicos, que se refere às pessoas físicas que acessam e navegam nesta página pela Internet.
Se o mesmo usuário visitar o site várias vezes em um dia, isso será registrado apenas uma vez.
PV: O nome completo é Page View, também chamado de page views ou cliques. Cada vez que um usuário visita uma página do site, um PV é registrado e o usuário abre a página várias vezes.
superfície, vários PVs são registrados.
Freqüentemente usado para medir o tráfego do site.
De modo geral, o UV é muito maior que o PV, portanto, ao medir o número de visitas ao mesmo site, precisamos considerar muitos fatores.
Então, apenas usamos esses dois valores como valor de referência
Será mais problemático fazer estatísticas UV no lado do servidor, porque para determinar se o usuário foi contado, as informações do usuário contadas precisam ser salvas.
Mas se cada usuário visitante for salvo no Redis, a quantidade de dados será muito assustadora, então como lidar com isso?
Hyperloglog (HLL) é um algoritmo probabilístico derivado do algoritmo Loglog e é usado para determinar a cardinalidade de conjuntos muito grandes sem a necessidade de armazenar todos eles
valor.
Você pode consultar os princípios do algoritmo relevantes: https://juejin.cn/post/6844903785744056333#heading-0
O HLL no Redis é implementado com base na estrutura de string. A memória de um único HLL é sempre menor que 16kb e o uso de memória é terrivelmente baixo!
Como compensação, suas medições são probabilísticas, com erro inferior a 0,81%.
Mas para as estatísticas UV, isso é completamente insignificante.

2. Teste as estatísticas de milhões de dados
Idéia de teste: usamos testes de unidade diretamente para adicionar 1 milhão de dados ao HyperLogLog para ver como está o uso de memória e os efeitos estatísticos.
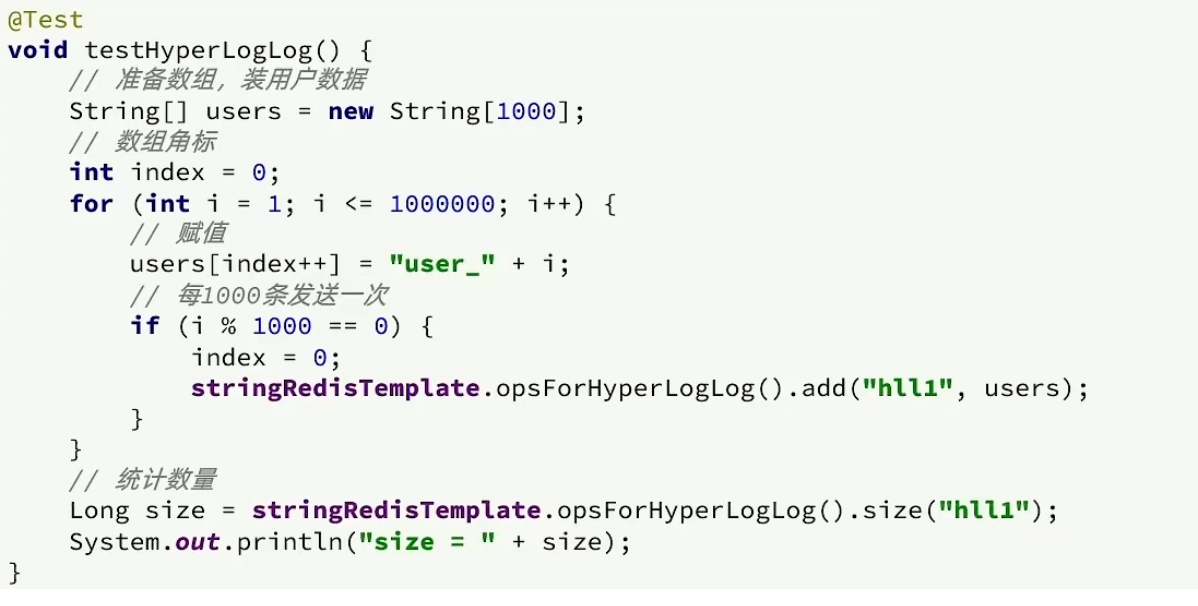
Após o teste: nosso erro está dentro da faixa permitida e o uso de memória é mínimo