общий
Эта статья представляет собой модель дистилляции, иммунная к большинству состязательных атак, имеет хорошую устойчивость и легко поезд.
Основное содержание
| символ | объяснение |
|---|---|
| \ (F (\ CDOT) \) | Нейронная сеть, и \ (F (Х) = \ mathrm {*} ^ SoftMax (г (Х)) \) . |
| \ (Х \ в \ mathcal {X} \) | образец |
| \ (Y \) | В соответствии с образцом тега |
| \ (Р ^ д \) | дистиллированная сеть |
| \ (Т \) | температура |
Примечание: Здесь \ (\ mathrm {SoftMax} ^ * (г) - i: = \ гидроразрыва {E ^ {z_i / T}} {\ sum_j е ^ {e_j / T}}, i = 0, \ ldots, N -1 \) ;
Примечание: \ (D ^ Ф. \) и \ (Ф. \) в качестве сетевой структуры;
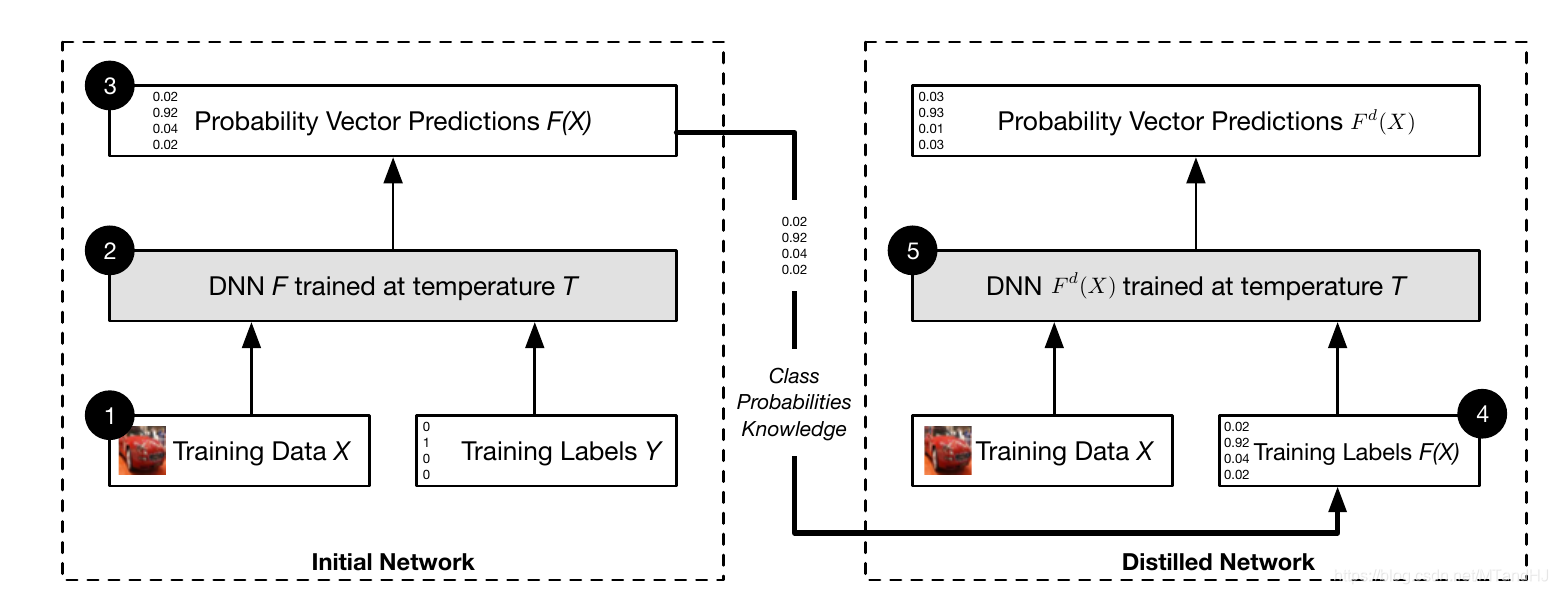
алгоритм
INPUT: \ (T \) , обучающие данные \ ((Х-, у-) \) .
- Подготовка данных \ ((X, Y) \ ) на тренированный \ (F. \) ;
- Получить новые учебные данные \ ((Х-, F (Х-)) \) ;
- Используя \ ((X, F (X )) \) Обучение \ (^ D F. \) ;
- Изменить \ (Р ^ д \) конечного слоя \ (Т = 1 . \) .
Выход: \ (F ^ d \) .
Почему этот алгоритм эффективен он?
- Обучение \ (F ^ d \) с меткой вероятность вектор \ (F (Х-) \) , возьмите цифровой Например, если вы напишете траву один час \ (7 \) и \ (1 \) очень похожи, но если обучение тег \ ((0,0,0,0,0,0,1,0,0,0) \) , то , но не реалистичны, это приведет к нестабильности;
- Когда \ (T \) является относительно большим , когда (обучение):
Будет относительно небольшой, где \ (G (Х) = \ sum_ {L} = 0. 1} ^ {N-E ^ {z_l (Х) / T} \) .
3. Во время теста мы пусть \ (T 1 = \) , предполагая , что \ (Х \) в случае , когда оригинал \ (z_1 / Т \) максимум, \ (Z_2 / T \) раз большие,
тогда
В котором \ (\ mathcal {G} \ ) из \ (z_2-z_1 \) в \ (Х \) отрицательный градиент в.
Некоторые интересные показатели
Надёжность определяется
Где \ (\ му \) для распределения образцов
Он может быть использован, чтобы фактически оценить по формуле
Квалифицированный механизм иммунитета
- Имеют меньшее влияние на первоначальную структуру;
- Чистая сеть передачи данных в связи с большой точностью;
- Лучше скорость обучения;
- К \ (\ | \ дельта Х \ | \) меньше невосприимчив к помеховой обстановке.
Существует также теоретический анализ оригинала, но я думаю, что это не важно, пропустить.
import torch.nn as nn
class Tsoftmax(nn.Module):
def __init__(self, T=100):
super(Tsoftmax, self).__init__()
self.T = T
def forward(self, x):
if self.train():
return nn.functional.softmax(x / self.T)
else:
return nn.functional.softmax(x)