Мы знаем, что данные, представленные в отчетах, часто не извлекаются напрямую из базы данных (источника), но требуются некоторые вычисления. Инструменты отчетности обычно предоставляют определенные возможности вычислений (такие как фильтрация, группировка и т. Д.) Для удовлетворения этой потребности . Однако, когда ситуация усложняется, для выполнения расчетов по набору данных отчета может потребоваться несколько этапов.В настоящее время необходимо проверить степень поддержки инструмента отчета для процедурных расчетов.
Описание варианта использования
Статистические требования
Перечислите основных клиентов в указанный период времени. Так называемый крупный покупатель определяется как покупатель, продажи которого составляют первую половину, то есть после того, как продажи клиента отсортированы от крупных к мелким, общие продажи предыдущих клиентов составляют половину от общего объема продаж, и эти клиенты называются крупными покупателями.
Стиль отчета
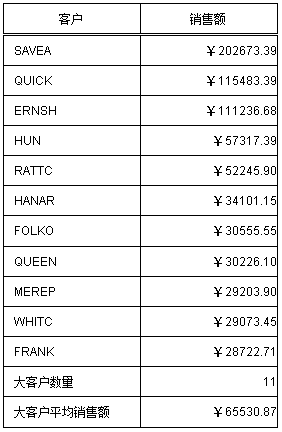
структура данных
[Журнал продаж]
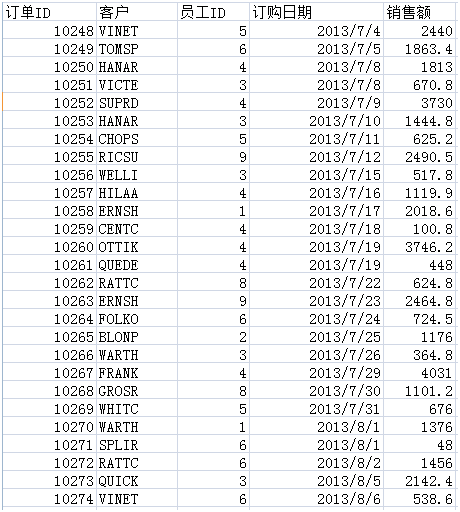
Характеристический анализ:
Формат отчета очень прост. Основная проблема заключается в том, что вам необходимо вычислить крупных клиентов из исходного набора данных перед его представлением. Этот расчет не является простым одноэтапным процессом.
Наша цель - изучить вычислительную мощность процесса инструмента отчетности, поэтому предполагается, что вычислительная мощность SQL или источников данных не используется для завершения.
Выполнить сухой отчет
Производственный процесс:
1. Настройте источник данных и подключитесь к нему.
2. Настройте набор данных.
Runqian Report предоставляет независимый механизм вычислений, который может вычислять данные с помощью встроенных сценариев и возвращать результаты в набор данных отчета. Добавьте новый набор данных в отчет. Тип набора данных использует набор данных сценария. Сценарий выглядит следующим образом:

2.1 Ячейка A1: ячейка подключается к источнику данных, а затем ячейка A6 закрывает соединение после выполнения.
2.2 A2: возьмите числа из таблицы продаж клиентов, здесь они суммированы в соответствии с именами клиентов и отсортированы в порядке убывания продаж.
2.3 A3: Выполните операцию суммирования суммы продаж и наложите 2, и вычтите половину общей суммы для оценки крупных клиентов. B3 устанавливает начальное значение 0, которое используется для накопления продаж.
2.4 A4: Суммируйте продажи и выньте серийный номер A2, накопленная сумма которого превышает A3
2.5 A5: Возьмите соответствующее значение в A2 согласно серийному номеру и верните его в отчет как набор результатов.
3. Разработка шаблона отчета.
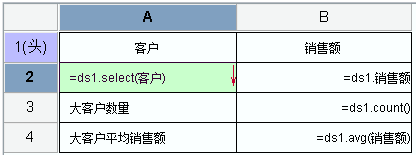
Данные, возвращаемые в наборе данных скрипта, представляют собой информацию об основных клиентах, поэтому составить отчет довольно просто. Настройки следующие:
3.1. Ячейки A2 и B2 напрямую берут данные из набора данных.
3.2 Ячейки B3 и B4 напрямую используют функцию сводки набора данных для подсчета количества крупных клиентов в наборе данных и функцию avg для получения средних продаж для продаж.
3.3 Установите границы и формат отображения суммы.
Результат операции :
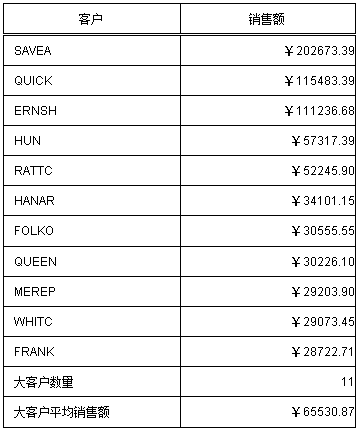
Обзор после завершения
1. За 0,5 часа, используя встроенный синтаксис в наборе данных скрипта, обработка нескольких ячеек может быстро удовлетворить требования.
2. Могут использоваться наборы данных скриптов, встроены богатые грамматические правила и могут быть быстро обработаны различные сложные требования к статистике данных.
3. Дизайн отчета прост, вспомогательные ячейки не нужны, а эффективность расчета отчета высокая.
Отчет фанатов
Производственный процесс:
1. Настройте источник данных и подключитесь к нему.
2. Настройте набор данных.
Увеличить запрос к базе данных, SQL: ВЫБРАТЬ клиента, сумма продаж (продаж) ИЗ ДЕМО. Таблица продаж клиентов группировать по заказам клиентов по продажам по убыванию.
3. Разработка шаблона отчета.

3.1 Ячейка B2 занимает половину общего объема продаж для оценки основных клиентов. Продажи суммируются в ячейке, и настраивается формула пользовательского отображения. Если FanRuan суммирует поля, а затем вычисляет, он не может Вручную добавляйте выражения прямо в ячейку, и вы можете устанавливать только настраиваемые формулы отображения.
3.2 Ячейки A3 и B3 обращаются к полям клиента и продаж в наборе данных.
3.3 C3: Найдите накопленную сумму = B3 + C3 [A3: -1], увеличьте атрибут условия и скройте данные небольших клиентов.
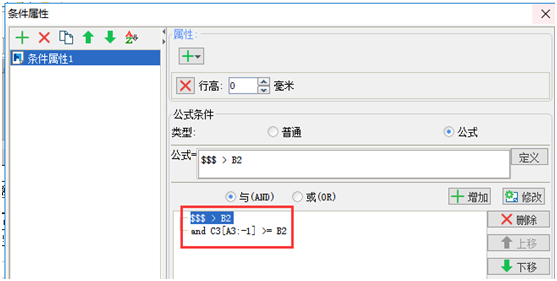
3.4 B4: Количество крупных клиентов, = count (B3 [! 0;! 0] {C3 <= B2 || (C3 [A3: -1] <B2 && C3> = B2)}), используйте функцию count для подсчета совокупных продаж. Больше, чем общий объем продаж.
3.5 Средние продажи, = сумма (B3 [! 0;! 0] {C3 <= B2 || (C3 [A3: -1] <B2 && C3> = B2)}) / B4, установить сохранение формата ячеек Два десятичных знака.
3.6. Скройте строки и столбцы, которые не нужно отображать.
Сообщить результат
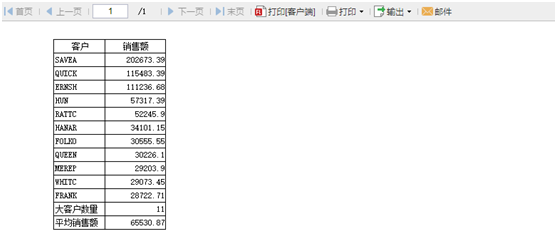
Обзор после завершения
1. Проходит 1 час.
2. Накопление может быть реализовано с помощью встроенной функции уровня LAYERTOTAL (B1, C1, D1) или через координаты уровня.В этом примере используется метод таблицы уровней, который имеет богатые встроенные функции.
3. Вы можете динамически установить динамическое скрытие строк и столбцов отчета в соответствии с условной формулой.
4. Необходимо добавить вспомогательные ячейки, что увеличит потребление дополнительных ресурсов, особенно когда количество клиентов велико, вся информация о клиентах выносится в отчет (количество мелких клиентов часто намного больше), а затем суждение скрывается. Производительность вычислений будет иметь влияние.
Смартби
Производственный процесс
1. Настройте источник данных и подключитесь к нему.
2. Настройте набор данных.
Используя собственные наборы данных SQL, просто извлекайте данные напрямую через операторы SQL:
выберите клиента, сумма (продажи) сумма из группы таблицы продаж клиентов по заказу клиента по сумме desc.
3. Разработка шаблона отчета.
Дизайн отчета выполнен в формате excel.С помощью богатого набора функций excel, smartbi не составляет особых проблем для решения такого рода межячейковых вычислений. Например, несколько ключевых расчетов:
3.1 D1: Общий объем продаж всех клиентов, выражение, записанное в D2 = D1 / 2, что составляет половину общего объема продаж.
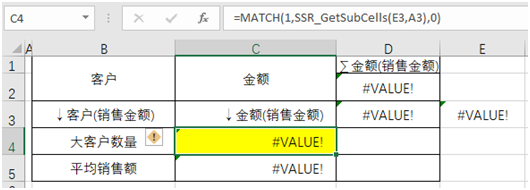
3.2 Ячейка D3: совокупная сумма, = *** _ GetCell (D3, B3, -1) + C3.
3.3 E3: = IF (*** _ GetSubCells (D3, B3)> D2,1 + *** _ GetCell (E3, B3, -1), 0), в соответствии с кумулятивной суммой, определить, когда кумулятивная сумма превышает половину общей суммы Когда метка равна 1, совокупное значение по-прежнему превышает половину общей суммы, а совокупное значение составляет 2/3/4 (используется для скрытия ненужных данных позже) и т. Д.
3.4 Ячейка C4: = MATCH (1, *** _ GetSubCells (E3, A3), 0), в соответствии с идентификатором E3 найдите порядковый номер первого появления 1, который является количеством крупных клиентов.
3.5 Сетка C5: средние продажи относительно просты, = D4 / C4, и задайте формат отображения данных в отчете.
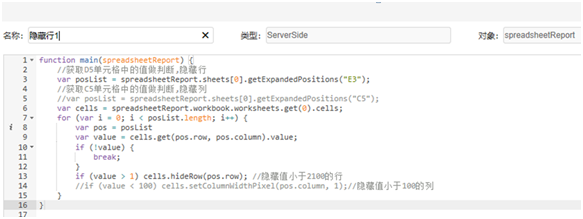
3.6 Настройки скрытых строк, вам необходимо скрыть данные небольших клиентов и не поддерживать определение скрытых выражений в таблице. Здесь скрытые выражения скрыты в соответствии со значением E3 больше 1. Вы должны использовать платформу для установки макросов для электронной таблицы (вам необходимо написать код js), чтобы достичь:
результат операции
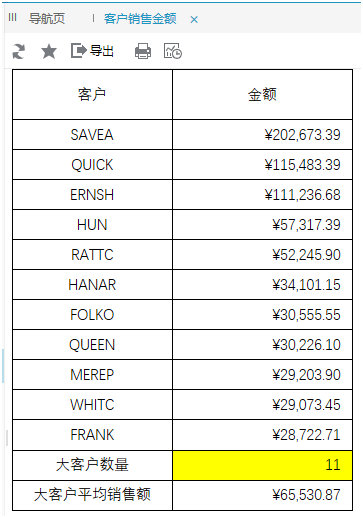
Комментарии после завершения:
1. Продолжительность: 1,5 часа.
2. Он полностью работает в Excel, прост в использовании и удобен в эксплуатации. Excel имеет богатый набор функций, и в этом отчете в основном используются функции поиска.
3. При скрытии данных о клиентах, которые не нужны (кроме крупных клиентов), он не поддерживает определение скрытых выражений в таблице, для чего требуется код js, что более сложно.
4. Необходимо добавить вспомогательные ячейки, что увеличит потребление дополнительных ресурсов, особенно когда количество клиентов велико, вся информация о клиентах выносится в отчет (количество мелких клиентов часто намного больше), а затем суждение скрывается. Производительность вычислений будет иметь влияние.
Yonghong BI
Производственный процесс:
1. Настройте источник данных и подключитесь к нему.
2. Настройте набор данных.
Используйте набор данных SQL-запроса: выберите клиента, сумму (продажи) из таблицы продаж клиентов, группу по заказу клиента по количеству по убыванию
3. Разработка шаблона отчета.

3.1 Первый столбец добавляет номер доступа по продажам. Фактически обнаружено, что, хотя набор данных отсортирован по продажам, когда поле имени клиента извлекается напрямую, даже если оно не отсортировано, оно не будет отсортировано в соответствии с исходными данными набора данных, поэтому перед Добавлено поле продаж и настроена сортировка по убыванию.
3.2 Общие продажи и соответствующие совокупные продажи выводятся в четвертом столбце, а совокупные продажи перетаскиваются напрямую, и расчет в нижней сетке не является совокупным.
3.3 Ячейка для количества крупных клиентов использует вычисление между ячейками, а выражение внутри:
var a = 0;
for (var i = 1; i <= ridx-1; i ++) {
if (cell (i, 3)> = cell (0,3) / 2) {
а = я;
перерыв;
}
}
С помощью грамматики js прокрутите строки и столбцы, чтобы определить, превышает ли совокупное значение половину общих продаж, и верните соответствующее количество строк, которое является количеством.
3.4 Такой же подход для средних продаж крупных клиентов:
var a = 0;
for (var i = 1; i <= ridx-2; i ++) {
if (cell (i, 3)> = cell (0,3) / 2) {
а = ячейка (я, 3) / я;
перерыв;
}
}
3.5 Первый и четвертый столбцы являются вспомогательными столбцами, и справа есть параметр скрытого столбца, чтобы скрыть эти два столбца.
3.6 Настройки скрытых строк, Yonghong не поддерживает выражения скрытых строк ячеек. Если вы хотите скрыть небольшие данные о клиентах, вам необходимо реализовать это с помощью операторов js. Вы можете получить атрибуты строки отчета после вычисления в js. Согласно данным, полученным в 3.3 Количество клиентов динамически устанавливает высоту строки для небольших клиентов (строки с номерами строк, превышающими количество крупных клиентов после расчета отчета) для достижения скрытого эффекта. Это похоже на Smartbi, поэтому я не буду реализовывать его здесь.
результат операции
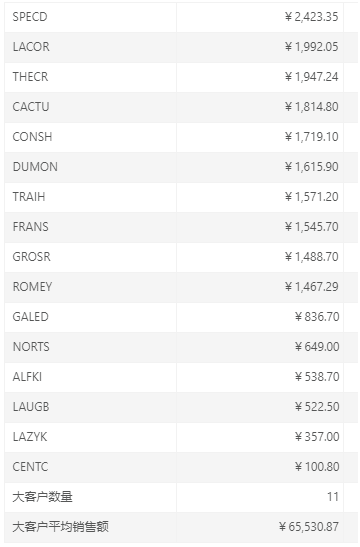
Обзор после завершения
1. Проходит 2 часа, а время обработки нескольких ячеек между сетками больше, что проверяет способность к проявлению.
2. Грамматика JS может использоваться для вычисления данных в вычислениях сетки, которая удобна для использования разработчиками и является более гибкой, но в то же время меньше встроенных функций, которые проверяют способности разработчика.
3. Настройка накопления более удобна, просто используйте встроенный синтаксис напрямую.
4. Проблема с настройкой сортировки: сортировка данных задана в наборе данных, но отчет не будет отсортирован в соответствующем порядке по умолчанию (или метод может не быть найден).
5. Необходимо добавить вспомогательные столбцы, например кумулятивные столбцы, если объем данных слишком велик, чтобы занимать дополнительное пространство памяти.
6. Скрытый столбец может быть установлен, но после настройки интерфейс дизайна не может видеть столбец и не может быть восстановлен.Если набор данных изменяется, а скрытый столбец ссылается на поле до изменения, его трудно изменить.
7. Необходимость добавления вспомогательных ячеек увеличит потребление дополнительных ресурсов, особенно когда количество клиентов велико, вся информация о клиентах выносится в отчет (количество мелких клиентов часто намного больше), а затем, как считается, скрывается, когда объем данных велик, отчет Производительность вычислений будет иметь влияние. А при сокрытии небольшой информации о клиентах нужно писать сложные js, что сложнее.
Миллиард письмо
Производственный процесс
1. Настройте и свяжите источник данных.
2. Настройте набор данных.
Просто выберите числа напрямую через оператор SQL: оператор SQL: выберите клиента, сумма (продажи) как продажи из группы продаж по заказу клиента по сумме (продажи) по убыванию
3. Разработка шаблона отчета.
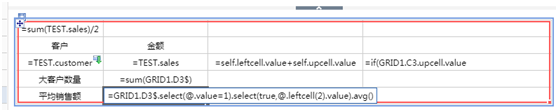
3.1 A1: = sum (TEST.sales) / 2 Вычислить половину общей суммы продаж всех клиентов и установить скрытый атрибут в правом атрибуте
3.2 A3: = ТЕСТ. Поле плавающих размеров заказчика, и установите основу сортировки справа B3.
3.3 C3: = self.leftcell.value + self.upcell.value для выполнения кумулятивного расчета суммы.
3.4 D3: = if (GRID1.C3.upcell.value <GRID1.A1,1, null) Данные, совокупная сумма которых превышает значение ячейки A1, помечаются как 1, а неквалифицированная отметка помечается как null, что удобно для последующей статистики.
3.5 B4: = сумма (GRID1.D3 $), подсчитайте количество крупных клиентов на основе логотипа D3 (возврат 1 для средних и крупных клиентов в D3, а сумма до 1 - количество крупных клиентов)
3.6 B5: = GRID1.D3 $ .select (@. Value = 1) .select (true, @. Leftcell (2) .value) .avg () Сначала используйте метод массива для фильтрации соответствующих данных, а затем выполните поиск Расчет среднего
3.7 Выберите третью строку и задайте отображаемое выражение как: <# = if (GRID1.D3 = 1,1,0) #>, ячейка D3 определяет, является ли этот фрагмент данных основным покупателем, здесь контролируется на основе значения ячейки D3 Отображается ли строка (если это 1, верните 1, чтобы указать отображение, в противном случае верните 0, чтобы не отображать)
результат операции
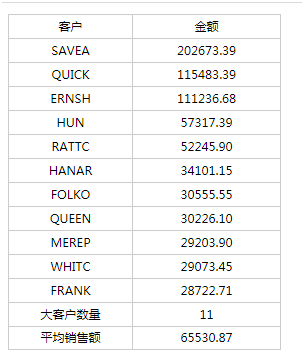
Комментарии после завершения:
1. Срок изготовления: 1,5 часа.
2. Встроенные функции относительно богаты, и общие операции в этой таблице в основном реализованы с помощью встроенных функций.
3. Удобнее динамически настроить динамическое скрытие строки и столбца отчета по условной формуле.
4. Необходимо добавить вспомогательные ячейки, что увеличит потребление дополнительных ресурсов, особенно когда количество клиентов велико, вся информация о клиентах выносится в отчет (количество мелких клиентов часто намного больше), а затем суждение скрывается. Производительность вычислений будет иметь влияние.
подводить итоги
Формат результатов отчета в этом примере относительно прост, и в принципе можно реализовать все инструменты отчета.
Для расчетов процесса, рассмотренных в этом примере, методы реализации Fanruan, Smartbi, Yonghong и Yixin в основном одинаковы. Все они используют вспомогательные ранги для извлечения общих продаж и совокупных продаж, а затем выполняют оценку данных, чтобы определить, какие клиенты Это крупный заказчик, он считает данные и, наконец, скрывает вспомогательные звания. Весь процесс имеет определенную степень сложности и громоздкости, потому что отчет может выполнять только вычисления на основе состояния, и он может использовать только этот окольный путь для обработки вычислений.
Среди этих продуктов Fanruan, Smartbi и Yixin в основном одинаковы, все они реализованы с помощью встроенных функций или методов, и ранги удобнее скрывать. Yonghong легко реализовать, и его можно настроить прямо с помощью мыши. Однако при статистике данных необходимо написать сложную грамматику javascript для статистики. Это сложнее реализовать, и скрывать строки и столбцы неудобно. Сложная функция отчетов Yonghong слабее, чем у трех других моделей, и Fanruan относительно лучше в этих четырех моделях, что также согласуется с выводами других случаев, протестированных ранее.
Сушку можно выполнить с помощью методов скрытой сетки, но здесь мы предлагаем другой подход. Runqian добавляет слой вычислений, используя наборы данных сценария, может более легко выполнять процедурные вычисления, возврат к отчету - это результаты обработанных данных, никакой специальной обработки в отчете нет, общий процесс проще и потребляет ресурсы Производительность будет намного меньше, чем при использовании вспомогательных сеток. Это по-прежнему согласуется с выводами предыдущих тестовых примеров. Runqian - это продукт с самой мощной вычислительной мощностью среди этих продуктов. Вычислительный уровень явно открыл разрыв с другими продуктами, что важно для эффективной разработки сложных отчетов.
Дальнейший пример
Давайте посмотрим на значение слоя расчета на примере и запросим самые длинные последовательные дни роста акций:

Источник данных - это текст, в котором записана дневная цена закрытия каждой акции:
Стиль этого отчета также очень прост, но процесс расчета более громоздкий: вам нужно сгруппировать набор данных, отфильтрованных по дате по коду акций, а затем рассчитать количество дней подряд, в течение которых каждая группа акций росла, а затем отфильтровать более 5 дней. акции.
Такой сложный процесс без помощи расчетного слоя с использованием скрытых решеток является очень хлопотным процессом, который можно примерно описать следующим образом:
1. Выньте набор текстовых данных и поместите его в ячейку.
2. Установите сортировку, сортировку по коду акций и дате
3. Сгруппируйте по коду акций для создания двухуровневого отчета.
4. Добавьте вспомогательную сетку в подробный ряд, чтобы рассчитать количество последовательных дней роста.
5. Рассчитайте максимальное количество последовательных дней роста в строке группировки.
6. Скройте линию детализации.
7. Скрыть неуказанные даты и группы, не соответствующие условиям.
Этот процесс просто громоздок для FanRuan, инструмента отчетности с мощными межсетевыми вычислительными возможностями; Smartbi, Yonghong и Yixin - это не просто громоздкие проблемы, и промежуточные вычисления также трудно выразить. Более того, независимо от того, какой это инструмент, это приведет к раздуванию всего отчета с большим количеством скрытых сеток (намного больше, чем представленных сеток).
Чтобы избежать этого, реальный метод часто использует пользовательский источник данных, считывает данные в Java для вычисления набора результатов или импортирует данные в базу данных для использования SQL для вычисления. В любом случае, это все еще очень громоздко и серьезно влияет на эффективность разработки.
Однако, если есть уровень вычислений, который можно интерпретировать и выполнять как отчет о пробах, он будет очень простым и не потребует нескольких строк кода для реализации этой логики:
A1: = file ("F: / Stock Information.txt"). Import @ t (). Select (left (string (Date), 7) == rq), прочитать данные в информации о запасах и в соответствии с отчетом Входящий параметр rq используется для фильтрации данных, и берутся данные за определенный месяц.
A2: = A1.sort (Date) .group (SID), сортировка по дате и группировка по полю SID
A3 :, go=A2.new(SID, ~.group@i(Closing>Closing\[-1\]).max(~.len()):ts)Closing [-1] принимает цену закрытия предыдущей записи в текущей записи. В A3 максимальное количество последовательных дней роста основано на том, что цена закрытия той же акции дня выше, чем цена закрытия предыдущего дня.
A4: вернуть A3.select (ts> = 5), извлечь данные из A3 с наибольшим количеством последовательных дней роста, превышающим 5, и вернуть их в набор данных отчета для использования.
Поскольку данные были обработаны в наборе данных скрипта, составить отчет довольно просто и нет необходимости в конкретных пояснениях.
Окончательный вывод комплексного отчета
Мы использовали три статьи, чтобы сравнить эти пять инструментов отчетности со сложными возможностями отчетности в качестве рекламного аргумента:
сравнение инструментов отчетов и выбор серий вариантов использования - фрагментированные отчеты из нескольких источников
Серии выборок для сравнения инструментов отчетов, ранжирование сценариев использования и межбанковская групповая статистика
Общий вывод таков:
Преимущества Runqian очевидны: даже без учета его уникального вычислительного уровня его комплексные возможности создания отчетов являются самыми сильными среди этих пяти продуктов. В сочетании с вычислительным уровнем можно сказать, что он далеко впереди, и он уже не соответствует требованиям по сравнению с некоторыми другими продуктами.
FanRuan занимает второе место. Если оставить в стороне уникальный расчетный слой Runqian, возможности комплексной отчетности FanRuan все равно будут слабее, чем у RunQian, но разница не слишком велика. Кроме того, дружественный интерфейс FanRuan может добавить очков. Считается, что Runqian и Fanruan являются первыми продуктами, и использование сложных отчетов в качестве рекламных пунктов достойно такого названия.
Смартби послабее, модель в основном реализована, но детали выразительности сильно отличаются от мягкости Runganfan, который можно рассматривать как продукт второго сорта. Использование сложных отчетов в качестве рекламного аргумента в области бизнес-аналитики все еще едва ли оправдано.
Строго говоря, возможности комплексной отчетности Yonghong и Yixin все еще находятся на начальном этапе, и разрыв с другими продуктами очень велик. Его можно отнести только к третьему классу или даже к недокументированным продуктам. Фактически, эти два продукта изначально представляют собой продукты бизнес-аналитики с яркими цветами. Использование сложных отчетов в качестве рекламных пунктов - это немного неправильно.