Библиотеки алгоритмов в этой области обычно включают librosa, essentia, torchaudio, deep learning и т. Д. Текущие инженерные процедуры в этой области:
- Прежде всего, звук - это одномерный сигнал во временной области, но компьютер считает его бесполезным (вы посмотрите на точки выборки файла wav, что можно объяснить этими числами); слуховая система человека PS (из ухо к коре головного мозга).
- Поскольку одномерный сигнал во временной области бесполезен, люди начинают проводить анализ в частотной области, который является знаменитым fft; наконец, он имеет некоторую полезность, но это все еще слишком далеко;
- Как насчет добавления как частотной области, так и временной области, например stft, наиболее классического метода анализа частотно-временной области? Что ж, так лучше;
- Как насчет преобразования результатов анализа в частотно-временной области в тепловую карту и отправки ее в сеть CNN, которая хорошо подходит для анализа изображений? Ничего себе, CNN эквивалентен коре головного мозга в слуховой системе человека, и он намного более мощный;
- Но по сравнению с различными задачами звукоанализа все равно намного хуже, чем тогда восполнить? Два аспекта: один - более эффективно извлекать эффективные характеристики звука; другой - это разработка алгоритмов глубокого обучения. Что касается искусственного извлечения характеристик звука, то за последние несколько десятилетий не было большого прогресса, и мы, естественно, отказались; остальное может полагаться только на алгоритмы глубокого обучения.
Загрузка звуковых файлов
Обычно звуковые файлы могут быть либо монофоническими, либо стерео (двухканальными), и, конечно же, есть каналы 5.1 (или даже больше), но доменов в Интернете не так много из-за мобильных телефонов, компьютеров, гарнитур и другого оборудования. в основном поддерживает стерео.
Когда звуковой файл демультиплексируется из контейнеров wav и mp3, а затем считывается в данные формата pcm_s16le, концепция моно преобразуется в одномерный массив, а концепция стерео преобразуется в двумерный массив. Когда частота дискретизации звука составляет 44100, то одна секунда стереоаудиофайлов обычно читается как массив 44100x2 или 2x44100.
Здесь Гемфилд использует torchaudio в качестве примера, используя torchaudio для чтения mp3-файла фортепианной музыки Canon:
>>> import torch
>>> import torchaudio
>>> import matplotlib.pyplot as plt
>>> waveform, sample_rate = torchaudio.load("kalong.mp3")
>>> waveform
tensor([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
>>> waveform.shape
torch.Size([2, 9895643])Тогда продолжительность этого mp3-файла составляет около 9895643 / sample_rate = 224 секунды:
>>> waveform.shape
torch.Size([2, 9895643])
>>> 9895643 / sample_rate
224.3909977324263Для удобства последующего частотно-временного анализа большинство этих аудиобиблиотек предоставляют интерфейсы функций повторной дискретизации. Например, функция resample находится в модуле преобразований torchaudio:
torchaudio.transforms.Resample(sample_rate, new_sample_rate)(waveform)Голосовые характеристики
С детства мы узнали о звуке, что звук можно рассматривать как волну, и ее характеристики: звуковая частота, громкость и тембр.
- Аудио, также называемое высотой тона, частотой волн, например частотным диапазоном человеческого слуха, например свистом музыки и т. Д .;
- Громкость, амплитуда волны, размер звука;
- Тембр ... объяснение непонятное, в любом случае различие между одним типом звука и другим в основном основано на тембре. Например, когда флейта и фортепиано издают одинаковые ду-ми и свисток, мы можем четко различить, что это два разных звука; когда два певца поют одинаковую высоту, мы также можем различить, что это разные звуки;
Однако вышеупомянутое знание кажется очень бледным, потому что главный отличительный признак звука от звука лежит в необъяснимом тоне, приведенном выше. Какой тон? Никто не может все четко сказать, например соотношение составов гармоник? Форма конверта?
Вообще говоря, в задачах классификации голосов основная особенность скрыта в нечетком тоне. Как это сделать? Гемфилд сказал с самого начала.
1. Форма волны звука
Это самый простой и понятный способ, который заключается в построении значений точек дискретизации на двухмерной плоскости один за другим и естественном отображении формы волны звука. Например, нарисуйте первый 17-секундный сигнал Canon, прочитанный torchaudio:
>>> plt.plot(waveform[:,0:44100*17].t().numpy())
[<matplotlib.lines.Line2D object at 0x1321a05d0>, <matplotlib.lines.Line2D object at 0x1321a0890>]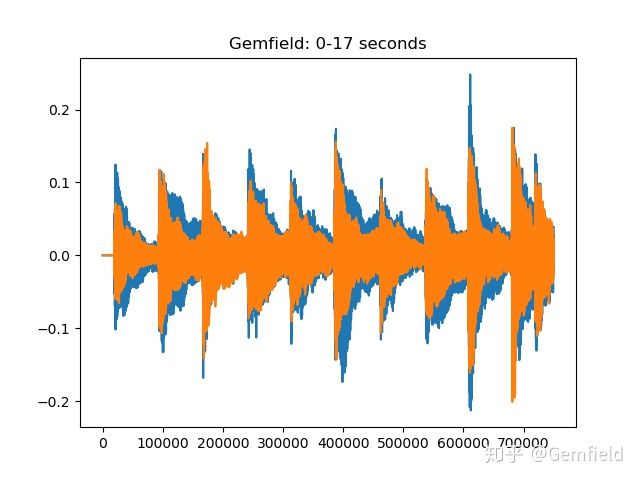
В качестве другого примера используйте библиотеку essentia, чтобы напрямую нарисовать вторую вторую форму волны второго канала фортепианной музыки Cannon:
>>> loader = essentia.standard.MonoLoader(filename='./kalong.mp3')
>>> audio = loader()
>>> from pylab import plot, show, figure, imshow
>>> import matplotlib.pyplot as plt
>>> plt.rcParams['figure.figsize'] = (15, 6)
>>> plot(audio2[0].transpose(1,0)[1][1*44100:2*44100])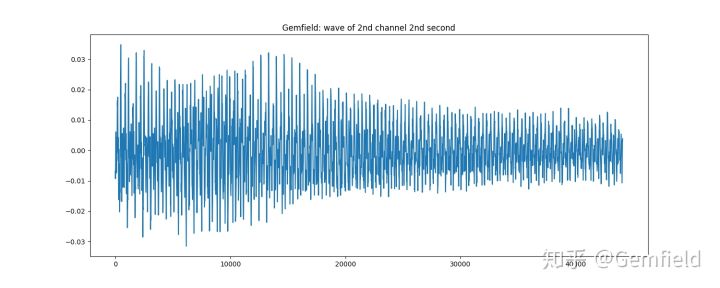
Рисование диаграммы формы звуковой волны просто преобразует одномерный сигнал во временной области непосредственно в форму, которую люди любят слышать, но это бесполезно.
2. Спектрограмма
Преобразование звука в спектрограмму также является методом изучения звуковых характеристик. Проще говоря, это кратковременное преобразование Фурье звука для получения тепловой карты, содержащей трехмерные данные. Следующее:
>>> specgram = torchaudio.transforms.Spectrogram(n_fft=1024)(waveform)
>>> plt.imshow(specgram.log2()[0,:,:1000].numpy(), cmap='plasma')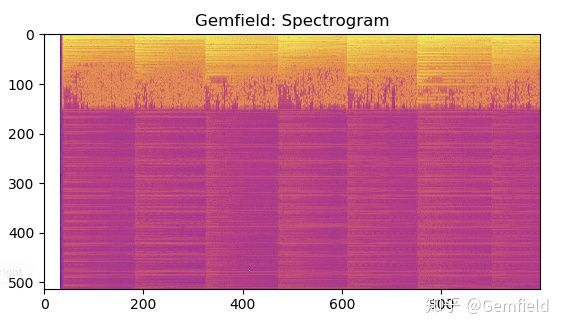
На рисунке горизонтальная ось представляет время, вертикальная ось представляет частоту, а цвет представляет энергию.
В процессе преобразования звуковых данных в спектрограмму с помощью STFT (кратковременное преобразование Фурье) каждая библиотека алгоритмов предоставляет аналогичные интерфейсы и параметры, которые определяются природой алгоритма stft. Вот эти параметры:
- n_fft, длина кадра, которая представляет собой количество точек выборки в кадре;
- win_length, связанная с оконной функцией, обычно такая же длина, как длина кадра;
- hop_length, длина шага для перехода вперед, обычно половина длины кадра;
- window_fn, оконная функция, по умолчанию torch.hann_window (окно Ханнинга).
Цветовая палитра, используемая тепловой картой, обычно имеет следующие форматы:
Accent, Accent_r, Blues, Blues_r, BrBG, BrBG_r, BuGn, BuGn_r, BuPu, BuPu_r, CMRmap, CMRmap_r, Dark2, Dark2_r, GnBu, GnBu_r, Greens, Greens_r, Grays, Greys_Rd, ORRD, ORGAN, ORD, ORD PRGn_r, Парный, Парный_r, Pastel1, Pastel1_r, Pastel2, Pastel2_r, PiYG, PiYG_r, PuBu, PuBuGn, PuBuGn_r, PuBu_r, PuOr, PuOr_r, PuRd, RdGu_r, Purples, Purples_r, RdGu_r, RdBu_r, RdBu_r, RdGu_r, RdGu_r RdYlBu, RdYlBu_r, RdYlGn, RdYlGn_r, Reds, Reds_r, Set1, Set1_r, Set2, Set2_r, Set3, Set3_r, Spectral, Spectral_r, Wistia, Wistia_r, YlGn, YlGnBurOr, YlGnBur_r, YlGnBur_r, YlGnBur_r, YlGnBur_r, YlGnBur, YlGnBur, YlGnBur afmhot_r, осень, autumn_r, двоичный, binary_r, bone, bone_r, brg, brg_r, bwr, bwr_r, cividis, cividis_r, cool, cool_r, coolwarm, coolwarm_r, медь, медь_r, cubehelix, cubehelix_r, flag, flag_earth_r, gist_r, gist_r, gist_r, gist_r, gist_r, gist_r, gist_r, gist_r, gist_r, gist_r, gist_r, gist_r gist_gray, gist_gray_r,gist_heat, gist_heat_r, gist_ncar, gist_ncar_r, gist_rainbow, gist_rainbow_r, gist_stern, gist_stern_r, gist_yarg, gist_yarg_r, gnuplot, gnuplot2, gnuplot2_r, gnuplot2, gnuplot2_r, gnuplot_r_r, грейврма_р_р_р_р magma_r, nipy_spectral, nipy_spectral_r, океан, ocean_r, розовый, pink_r, плазма, Plasma_r, призма, prism_r, радуга, rainbow_r, сейсмический, seismic_r, весна, spring_r, лето, лето_r, tab10, tab10_r, tab20, tabb20_r, tab20, tabb20_r, tab20, tabb20_r, tab20, tabb20_r tab20c, tab20c_r, terrain, terrain_r, сумерки, twilight_r, twilight_shifted, twilight_shifted_r, viridis, viridis_r, winter, winter_r。magma_r, nipy_spectral, nipy_spectral_r, океан, ocean_r, розовый, pink_r, плазма, Plasma_r, призма, prism_r, радуга, rainbow_r, сейсмический, seismic_r, весна, spring_r, лето, лето_r, tab10, tab10_r, tab20, tabb20_r, tab20, tabb20_r, tab20, tabb20_r, tab20, tabb20_r tab20c, tab20c_r, terrain, terrain_r, сумерки, twilight_r, twilight_shifted, twilight_shifted_r, viridis, viridis_r, winter, winter_r。magma_r, nipy_spectral, nipy_spectral_r, океан, ocean_r, розовый, pink_r, плазма, Plasma_r, призма, prism_r, радуга, rainbow_r, сейсмический, seismic_r, весна, spring_r, лето, лето_r, tab10, tab10_r, tab20, tabb20_r, tab20, tabb20_r, tab20, tabb20_r, tab20, tabb20_r tab20c, tab20c_r, terrain, terrain_r, сумерки, twilight_r, twilight_shifted, twilight_shifted_r, viridis, viridis_r, winter, winter_r。
3. Спектрограмма Мела MelSpectrogram
Спектрограмма сохраняет исходный диапазон звуковых частот для данного частотного диапазона, но это не очень хорошо для человеческого уха: у людей есть свои особенности в отношении чувствительной области и чувствительности звука. Это мел-спектр - мы часто пропускаем его через банки фильтров мел-накипи и преобразуем его в мел-спектр. Что такое банк фильтров Mel? Начнем с мелкой шкалы. Единица измерения частоты - герц (Гц), и человеческое ухо может слышать диапазон частот 20-20000 Гц, но человеческое ухо не имеет линейного отношения восприятия с единицей шкалы Гц, поэтому мы преобразовали частоту в Шкала mel Восприятие является линейной зависимостью по шкале mel.
Спектрограмма mel - это преобразование спектрограммы по шкале mel, которая представляет собой комбинацию шкалы mel + спектрограмма.
>>> specgram = torchaudio.transforms.MelSpectrogram(sample_rate=44100, n_fft=1024)(waveform)
>>> plt.imshow(specgram.log2()[0,:,:500].detach().numpy(), cmap='hot')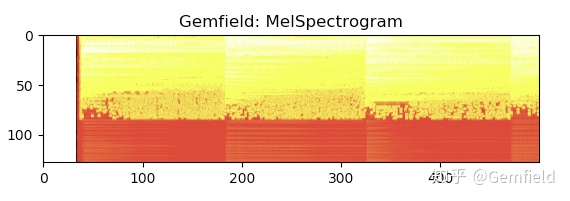
Помимо тех, которые изначально требуются алгоритмом спектрограммы, есть еще параметры:
- sample_rate, частота дискретизации звука;
- n_mels, количество банков фильтров от накипи.
Стоит упомянуть, что SoundAnalysisPreprocessing, используемый в обучении классификации тупых звуков (с использованием createML, новой функции в Core ML 3), которую Apple показала на wwdc, заключается в преобразовании аудиосэмплов в спектрограммы mel . Gemfield извлек следующие шаги из официальной реализации ( https://github.com/apple/coremltools/blob/master/mlmodel/format/SoundAnalysisPreprocessing.proto ):
message SoundAnalysisPreprocessing {
/* Vggish preprocesses input audio samples and makes them ready to
be fed to Vggish feature extractor.
c.f. https://arxiv.org/pdf/1609.09430.pdf
The preprocessing takes input a single channel (monophonic) audio samples
975 miliseconds long, sampled at 16KHz, i.e., 15600 samples 1D multiarray
and produces preprocessed samples in multiarray of shape [1, 96, 64]
(1) Splits the input audio samples into overlapping frames, where each
frame is 25 milliseconds long and hops forward by 10 milliseconds.
Any partial frames at the end are dropped.
(2) Hann window: apply a periodic Hann with a window_length of
25 milliseconds, which translates to 400 samples in 16KHz sampling rate
w(n) = 0.5 - 0.5 * cos(2*pi*n/window_length_sample),
where 0 <= n <= window_lenth_samples - 1 and window_lenth_samples = 400
Then, the Hann window is applied to each frame as below
windowed_frame(n) = frame(n) * w(n)
where 0 <= n <= window_lenth_samples - 1 and window_lenth_samples = 400
(3) Power spectrum: calculate short-time Fourier transfor magnitude, with
an FFT length of 512
(4) Log Mel filter bank: calculates a log magnitude mel-frequency
spectrogram minimum frequency of 125Hz and maximum frequency of 7500Hz,
number of mel bins is 64, log_offset is 0.01, number of spectrum bins
is 64.
*/
}Видно, что идея использования проекта vggish, в проекте Vggish ( https://github.com/tensorflow/models/tree/master/research/audioset/vggish ), характеристики звука рассчитываются согласно следующие шаги:
- Все аудио передискретизируются до моно 16 кГц.
- Спектрограмма вычисляется с использованием величин кратковременного преобразования Фурье с размером окна 25 мс, шагом окна 10 мс и периодическим окном Ханна.
- Спектрограмма mel вычисляется путем сопоставления спектрограммы с 64 ячейками mel, охватывающими диапазон 125-7500 Гц.
- Стабилизированная спектрограмма log mel вычисляется путем применения log (mel-спектр + 0,01), где используется смещение, чтобы избежать логарифма нуля.
- Затем эти функции объединяются в неперекрывающиеся примеры продолжительностью 0,96 секунды, где каждый пример охватывает 64 диапазона mel и 96 кадров по 10 мс каждый.
Видно, что у всех одна и та же идея, от torchaudio до CoreML3 и tenorflow.
4. Другие алгоритмы
Например, сжатие звука (алгоритм Mu-law, используемый в G.711), дельта-коэффициенты спектрограммы (приблизительная производная, такая как compute_deltas torchaudio, которая вычисляется с точки зрения спектрограммы), фильтрует класс (например, highpass_biquad в функционале torchaudio). , фильтр верхних частот), класс пространственных объектов (например, mfcc, mfcc Essentia рассчитывается следующим образом: frame -> window -> Spectrum -> mfcc, а затем вы можете получить mfcc_bands и mfcc_coeffs, последний является первым 13 Коэффициенты Mel кадра аудио).
И множество других, таких как библиотека essentia, содержит следующие очень многие известные и неизвестные алгоритмы:
AfterMaxToBeforeMaxEnergyRatio
AllPass
AutoCorrelation
BFCC
BPF
BandPass
BandReject
BarkBands
BeatTrackerDegara
BeatTrackerMultiFeature
Beatogram
BeatsLoudness
BinaryOperator
BinaryOperatorStream
BpmHistogram
BpmHistogramDescriptors
BpmRubato
CartesianToPolar
CentralMoments
Centroid
ChordsDescriptors
ChordsDetection
ChordsDetectionBeats
Chromagram
Clipper
ConstantQ
Crest
CrossCorrelation
CubicSpline
DCRemoval
DCT
Danceability
Decrease
Derivative
DerivativeSFX
Dissonance
DistributionShape
Duration
DynamicComplexity
ERBBands
EasyLoader
EffectiveDuration
Energy
EnergyBand
EnergyBandRatio
Entropy
Envelope
EqloudLoader
EqualLoudness
Extractor
FFT
FFTC
FadeDetection
Flatness
FlatnessDB
FlatnessSFX
Flux
FrameCutter
FrameGenerator
FrameToReal
FreesoundExtractor
FrequencyBands
GFCC
GeometricMean
HFC
HPCP
HarmonicBpm
HarmonicMask
HarmonicModelAnal
HarmonicPeaks
HighPass
HighResolutionFeatures
HprModelAnal
HpsModelAnal
IDCT
IFFT
IIR
Inharmonicity
InstantPower
Intensity
Key
KeyExtractor
LPC
Larm
Leq
LevelExtractor
LogAttackTime
LoopBpmConfidence
LoopBpmEstimator
Loudness
LoudnessEBUR128
LoudnessVickers
LowLevelSpectralEqloudExtractor
LowLevelSpectralExtractor
LowPass
MFCC
Magnitude
MaxFilter
MaxMagFreq
MaxToTotal
Mean
Median
MelBands
MetadataReader
Meter
MinToTotal
MonoLoader
MonoMixer
MonoWriter
MovingAverage
MultiPitchKlapuri
MultiPitchMelodia
Multiplexer
MusicExtractor
NoiseAdder
NoveltyCurve
NoveltyCurveFixedBpmEstimator
OddToEvenHarmonicEnergyRatio
OnsetDetection
OnsetDetectionGlobal
OnsetRate
Onsets
OverlapAdd
PCA
Panning
PeakDetection
PercivalBpmEstimator
PercivalEnhanceHarmonics
PercivalEvaluatePulseTrains
PitchContourSegmentation
PitchContours
PitchContoursMelody
PitchContoursMonoMelody
PitchContoursMultiMelody
PitchFilter
PitchMelodia
PitchSalience
PitchSalienceFunction
PitchSalienceFunctionPeaks
PitchYin
PitchYinFFT
PolarToCartesian
PoolAggregator
PowerMean
PowerSpectrum
PredominantPitchMelodia
RMS
RawMoments
ReplayGain
Resample
ResampleFFT
RhythmDescriptors
RhythmExtractor
RhythmExtractor2013
RhythmTransform
RollOff
SBic
Scale
SilenceRate
SineModelAnal
SineModelSynth
SineSubtraction
SingleBeatLoudness
SingleGaussian
Slicer
SpectralCentroidTime
SpectralComplexity
SpectralContrast
SpectralPeaks
SpectralWhitening
Spectrum
SpectrumCQ
SpectrumToCent
Spline
SprModelAnal
SprModelSynth
SpsModelAnal
SpsModelSynth
StartStopSilence
StereoDemuxer
StereoMuxer
StereoTrimmer
StochasticModelAnal
StochasticModelSynth
StrongDecay
StrongPeak
SuperFluxExtractor
SuperFluxNovelty
SuperFluxPeaks
TCToTotal
TempoScaleBands
TempoTap
TempoTapDegara
TempoTapMaxAgreement
TempoTapTicks
TonalExtractor
TonicIndianArtMusic
TriangularBands
TriangularBarkBands
Trimmer
Tristimulus
TuningFrequency
TuningFrequencyExtractor
UnaryOperator
UnaryOperatorStream
Variance
Vibrato
WarpedAutoCorrelation
Windowing
ZeroCrossingRateПоиск музыкальной информации МИР
Музыка занимает большую часть исследований звука. Когда звук - это музыка, общая тема исследования в этой области связана с музыкой.Например, в библиотеке Essentia обычно используется класс MusicExtractor. Это поле называется поиском музыкальной информации (MIR). Ниже Гемфилд перечисляет некоторые общие области исследований в области музыки.
1. Музыкальная точка ритма
Алгоритм для получения точек биений в музыке является относительно зрелым, однако, если вы хотите в дальнейшем получить точку сверхбита или точку сильной доли (то есть сильную или оптимистичную), текущий алгоритм все равно не сможет этого сделать. В сущности, вы можете использовать
from essentia.standard import *
# Loading audio file
audio = MonoLoader(filename='gemfield_dubstep.flac')()
# Compute beat positions and BPM
rhythm_extractor = RhythmExtractor2013(method="multifeature")
bpm, beats, beats_confidence, _, beats_intervals = rhythm_extractor(audio)
print("BPM:", bpm)
print("Beat positions (sec.):", beats)
print("Beat estimation confidence:", beats_confidence)Вы можете получить количество ударов в минуту, положение ударов и так далее. BPM также может продолжать получать гистограмму BPM через BpmHistogramDescriptors.Этот индикатор очень важен, если темп музыки колеблется быстро и медленно.
2. Обнаружение начала
OnsetDetection of essentia предоставляет множество алгоритмов, таких как hfc, complex и т. Д.
# Loading audio file
audio = MonoLoader(filename='gemfield_hiphop.mp3')()
# Phase 1: compute the onset detection function
# The OnsetDetection algorithm provides various onset detection functions. Let's use two of them.
od1 = OnsetDetection(method='hfc')
od2 = OnsetDetection(method='complex')
# Let's also get the other algorithms we will need, and a pool to store the results
w = Windowing(type = 'hann')
fft = FFT() # this gives us a complex FFT
c2p = CartesianToPolar() # and this turns it into a pair (magnitude, phase)
pool = essentia.Pool()
# Computing onset detection functions.
for frame in FrameGenerator(audio, frameSize = 1024, hopSize = 512):
mag, phase, = c2p(fft(w(frame)))
pool.add('features.hfc', od1(mag, phase))
pool.add('features.complex', od2(mag, phase))
# Phase 2: compute the actual onsets locations
onsets = Onsets()
onsets_hfc = onsets(# this algo expects a matrix, not a vector
essentia.array([ pool['features.hfc'] ]),
# you need to specify weights, but as there is only a single
# function, it doesn't actually matter which weight you give it
[ 1 ])
onsets_complex = onsets(essentia.array([ pool['features.complex'] ]), [ 1 ])3. Обнаружение мелодии
Определение высоты звука основной мелодии в аудиофайле. По сути, мы можем использовать алгоритм PredominantPitchMelodia. Этот алгоритм определяет мелодию входящего звука, а затем дает мгновенную высоту звука основной мелодии в каждый период времени (единицы Гц). :
import numpy
# Load audio file; it is recommended to apply equal-loudness filter for PredominantPitchMelodia
loader = EqloudLoader(filename='gemfield.wav', sampleRate=44100)
audio = loader()
print("Duration of the audio sample [sec]:")
print(len(audio)/44100.0)
# Extract the pitch curve
# PitchMelodia takes the entire audio signal as input (no frame-wise processing is required)
pitch_extractor = PredominantPitchMelodia(frameSize=2048, hopSize=128)
pitch_values, pitch_confidence = pitch_extractor(audio)
# Pitch is estimated on frames. Compute frame time positions
pitch_times = numpy.linspace(0.0,len(audio)/44100.0,len(pitch_values) 4. Анализ тональности
Он предназначен для анализа тональности музыки, такой как до мажор, ре минор и т. Д. Что это значит? Джемфилд нашел объяснение, которое все еще очень легко понять, на https://www.zhihu.com/question/28481469/answer/79850430 на Zhihu :
大家都知道12345671(do re mi)是一个八度,八个音,七个音差。但每两个音之间的差距不是平均的。
两个do之间,不包括高音do,可以分成12份,每份是半音,两个半音是一个全音,这叫12平均律(等比平均)。
调式是7个主音之间一种结构关系,就是怎样在八度区间内分配12个半音,定义12345671。
大调是这样,全全半全全全半,加起来12个半音,对应12345671,do Re 之间差一个全音,
re mi全音,mi fa半音,以此类推后面都是全音直到xi do又是一个半音。我们一般从小唱的do Re mi就是这样。
那么什么是C大调,D大调等。C D E F G A B C是五线谱上代表音高的音符。每一个可以对应一个声音频率,即音高。
以中音C为例,调琴标准频率260赫兹左右(非准确值),即琴弦或簧片每秒震动260次发出的声波。
高八度的C就翻倍到520赫兹,八度就是频率加倍,在中间分12份就得到其他音阶。C大调就是以C,260赫兹,
为do的12345671,全全半全全全半,对应CDEFGABC。这样就可以算出DEF等的频率。D大调就是从D,
即C大调的2,开始的大调,音阶结构一样。比如同一首歌,男中音可以唱C大调,女高音可以用D大调,听起来调子一样,音高不同。
小调就是另外一种结构,全半全全半全全,同样以C开头的就是C小调。在键盘上就是CDd#FGg#a#C。
仍然是C到C,八度。如果还唱1234567,调子听起来却像大调的6712345(音高不同)。
“#”,读sharp,计算机语言C#也来源于此。Используя алгоритмы HPCP, тональности и гаммы библиотеки essentia (чтобы определить, является ли тональность мажорной или минорной), вы можете получить результат, аналогичный «ля минор», основанный на входящей музыке.
5. Алгоритм отпечатка пальца
Распространенным применением в музыкальной сфере является ввод отрывка музыкальной мелодии, затем извлечение характеристик отпечатка пальца, а затем отправка характеристик отпечатка пальца в базу данных для поиска другой соответствующей информации о музыке.
В библиотеке essentia интерфейс Chromaprint инкапсулирует алгоритм Chromaprint (извлечение функций цветности), и вы можете использовать этот интерфейс для извлечения отпечатков пальцев:
# the specified file is not provided with this notebook, try using your own music instead
audio = es.MonoLoader(filename='Desakato-Tiempo de cobardes.mp3', sampleRate=44100)()
fingerprint = es.Chromaprinter()(audio)
client = 'hGU_Gmo7vAY' # This is not a valid key. Use your key.
duration = len(audio) / 44100.
# Composing a query asking for the fields: recordings, releasegroups and compress.
query = 'http://api.acoustid.org/v2/lookup?client=%s&meta=recordings+releasegroups+compress&duration=%i&fingerprint=%s' \
%(client, duration, fingerprint)
from six.moves import urllib
page = urllib.request.urlopen(query)
print(page.read())6. Сравнение схожести песен.
Идентификация кавер-версии (CSI) используется, чтобы узнать, является ли песня плагиатом или кавер-версией другой песни. Здесь используются алгоритмы HPCP, ChromaCrossSimilarity и CoverSongSimilarity из библиотеки essentia. Библиотека Essentia по-прежнему очень сильна в этом отношении.
подводить итоги
Что касается разработки функций в области аудио, наиболее часто используемыми библиотеками Gemfield являются torchaudio, librosa и essentia. Все алгоритмы, предоставляемые этими библиотеками, связаны со звуком и имеют много общего. Среди них torchaudio ничего не знает о музыке MIR, а librosa и essentia включают MIR. Еще одна особенность библиотеки Essentia заключается в том, что она поддерживает кроссплатформенность (и даже включает мобильные устройства).