Автор недавно провел серию экспериментов с Vocoder, нейронной сетью, основанной на Гане. Сделайте краткое резюме и задайте ряд вопросов, а также обсудите проблемы, возникшие с лидерами отрасли.
Давайте сначала посмотрим на структуру модели Melgan, которая состоит из двух частей: генератора и дискриминатора.
Генератор
Входной сигнал - это мел-спектрограмма, а на выходе - необработанная форма волны.Процесс от мел-спектрограммы к аудио, очевидно, является процессом передискретизации.
Повышение частоты дискретизации здесь реализовано посредством одномерной деконволюции (transpose1d). Как определить кратность повышения частоты дискретизации?
Следует отметить, что кратность апсемплинга определяется hop_size.Почему?
Необходимо понимать, количество кадров mel * сдвиг кадра = длина звука (количество точек дискретизации можно преобразовать в продолжительность звука, не будем говорить, как это сделать)
Следовательно, для частоты дискретизации 22050 размер скачка установлен на 256, тогда соответствующая мел-спектрограмма должна быть увеличена 256 раз.
Что делать, если частота дискретизации 16000? Длина кадра использования составляет 50 мс, а сдвиг кадра - 12,5 мс, затем размер скачка составляет 200, поэтому кратность повышения дискретизации составляет 200 раз.
После пояснения можно легко понять кратность повышения дискретизации в слое повышения дискретизации генератора. Кратность дискретизации 22050 составляет 8 X 8 X 2 X 2 = 256.
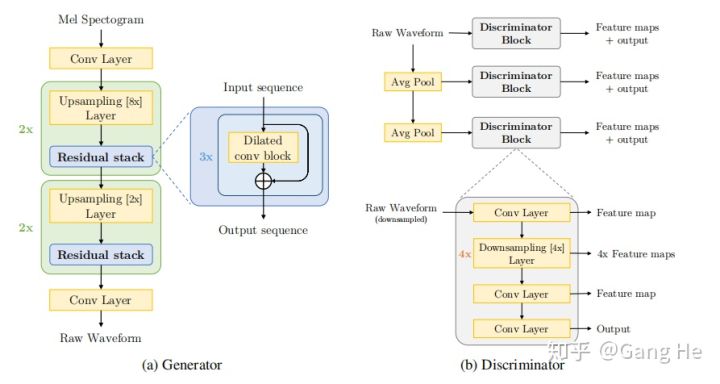
Рисунок 1 структура модели мелгана
Еще один момент, который необходимо прояснить, - как деконволюция выполняет повышающую дискретизацию?
Если кто-то не понимает, как работает деконволюция (повышающая дискретизация), то взгляните на эту статью «Понимание транспонированных сверток» , в которой объясняется операция свертки и процесс операции деконволюции через матрицу свертки.
Существует множество методов апсемплинга: помимо деконволюции, есть ближайшие соседи, билинейная интерполяция и т. Д. Эти методы также используются в реализации сети Wave. Осознайте конкретный алгоритм и исследуйте сами.
За каждым слоем Upsampling Layer будет следовать слой RedidualStack (состоящий из трехслойной расширенной одномерной свертки). Слой ResidualStack получает размер 27 за счет трех слоев свертки отверстий с разными коэффициентами расширения (1, 3, 9 Восприимчивое поле расширяет способность восприятия во временной области и может лучше моделировать зависимость на большом расстоянии во временной области.
Последний уровень сети генератора - это одномерный сверточный слой + функция tanh, а диапазон вывода - [1,1], что удовлетворяет диапазону значений точек значений звука. Количество выходных каналов этого уровня равно 1, количество каналов здесь соответствует выходу полнодиапазонного звука (полнополосного), вот отличие от многодиапазонного генератора модели Melgan, который будет обсуждаться позже.
Последний пункт, артефакты шахматной доски. Что такое эффект шахматной доски и как уменьшить проблему высокочастотного зеркалирования звука, вызванную эффектом шахматной доски (не может быть полностью решено), пожалуйста, проверьте это сообщение в блоге . Если выбранное ядро свертки и шаг не соответствуют тот же размер Соответствующий, он будет производить серьезный эффект шахматной доски, который отражается в спектре звуковых частот с более высокочастотными горизонтальными полосами и в качестве звука текущего звука (если что-то не так, добро пожаловать к обсуждению).
После разговора о Генераторе, давайте поговорим о Дискриминаторе.
Дискриминатор
В документе предлагается многомасштабный дискриминатор, основанный на предположении, что каждый масштабный дискриминатор может изучать характеристики звука в разных частотных диапазонах.
Сетевая структура каждого дискриминатора состоит из уровня понижающей дискретизации, состоящего из одномерной свертки и четырехуровневой свертки пакетов. Вход дискриминатора состоит из наземного истинного звука и фальшивого звука, генерируемого генератором. Входное измерение - [B, T, 1], а выходное измерение также [B, T, 1]. Единственное преобразование в середине - это изменение количества каналов. Выход последнего слоя и выход предпоследнего слоя сверточной сети используются отдельно Calculate featuremap и feature_score, эти две части используются для вычисления feature_matching_loss (L1_loss) генератора и mse_loss дискриминатора
. Выше мы знаем, что генератор вводит мел-спектрограмму для генерации аудио-звука, это аудио может быть выражено как G (s), s - это мел-спектрограмма. Дискриминатор должен определить, генерирует ли генератор звук из истинного или ложного, и вот модель Гана Принцип,
Генератор вводит мел-спектрограмму для генерации звука (поддельный), Дискриминатор вводит реальный (настоящий) звук и поддельный (поддельный) звук, выучивает двоичный классификатор (можно понять таким образом), вот потери mse, чтобы минимизировать разницу между реальным и поддельным звуком. 1, разница между подделкой и 0.
Благодаря состязательному обучению звук, генерируемый генератором, достигает эффекта, при котором дискриминатор не может оценить подлинность (потеря близка к 0,5).
Так Мелган учится и тренируется.
Некоторое резюме
1 При генерации звука (вывод) используйте только Генератор. Дискриминатор помогает обучению только во время обучения.
2 Для обучения модели Гана поочередно обучаются генератор и дискриминатор.Сначала зафиксируйте дискриминатор и обучите генератор на один шаг, затем исправьте генератор и обучите дискриминатор на один шаг.
3 Процесс обучения будет относительно долгим. Одна видеокарта V100 GPU может работать в течение полумесяца. Если вы замените featurematching_loss на stft loss с несколькими разрешениями, это сократит время конвергенции.
4 Звук, генерируемый в процессе обучения, изначально будет иметь очень серьезный эффект шахматной доски.По мере увеличения количества итераций этот эффект будет постепенно уменьшаться.
5 Детали высокочастотной части звука мелгана неочевидны, также будет дрожание произношения и шорох фонового шума.Эта проблема более серьезная.
Приведите пример с частотой дискретизации 16 кГц. Этот пример представляет собой звуковой спектр, сгенерированный во время наземной тренировки Melgan.