Несколько вещей, которые мы часто упускаем из виду при развертывании приложений в Kubernetes
Беседа с новичком Scofield по эксплуатации и техническому обслуживанию
По моему опыту, большинство людей (используя Helm или ручной yaml) развертывают приложения в Kubernetes, а затем думают, что они всегда могут работать стабильно.
Однако это не так. Фактический процесс использования все еще сталкивался с некоторыми «ловушками». Я надеюсь перечислить эти «ловушки» здесь, чтобы помочь вам разобраться в некоторых проблемах, на которые необходимо обратить внимание перед запуском приложения на Kubernetes.
Введение в планирование Kubernetes
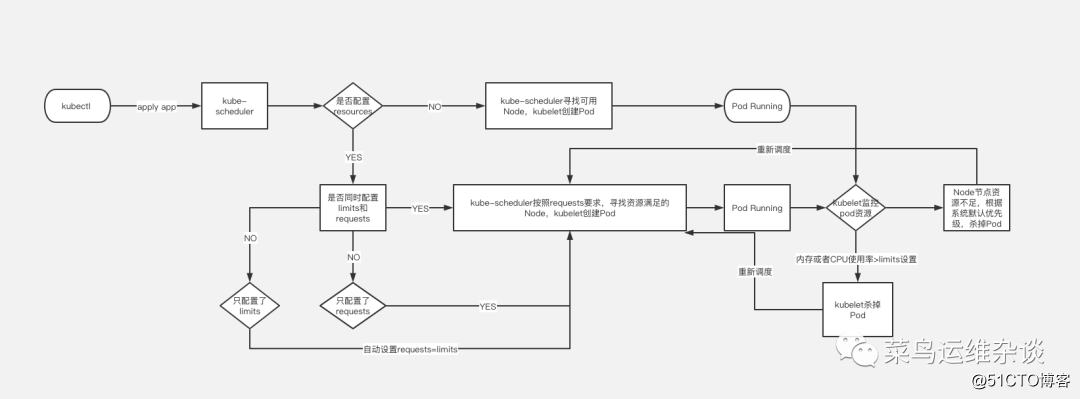
Планировщик использует механизм наблюдения кубернетов для обнаружения вновь созданных модулей в кластере, которые еще не были запланированы для узла. Планировщик назначит запуск каждого незапланированного модуля Pod на соответствующем узле. В качестве планировщика кластера по умолчанию kube-scheduler выберет оптимальный узел для запуска модуля для каждого вновь созданного модуля или незапланированного модуля. Однако у каждого контейнера в Pod разные требования к ресурсам, и у самого Pod также разные требования к ресурсам. Следовательно, перед тем, как Pod будет запланирован для узла, необходимо отфильтровать узлы в кластере в соответствии с этими конкретными требованиями планирования ресурсов.
В кластере все узлы, которые удовлетворяют запрос планирования Pod, называются планируемыми узлами. Если ни один узел не может удовлетворить запрос ресурса Pod, Pod останется в незапланированном состоянии до тех пор, пока планировщик не найдет подходящий узел.
Факторы, которые необходимо учитывать при принятии решений о планировании, включают: индивидуальные и общие запросы ресурсов, аппаратные / программные / ограничения политик, требования схожести и анти-сродства, локальность данных, взаимное влияние нагрузок и т. Д. Пожалуйста, обратитесь на официальный сайт для получения дополнительной информации о расписании.
Запросы Pod и ограничения
Давайте посмотрим на простой пример, здесь перехватывается только часть информации yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
resources:
limits:
memory: "100Mi"
cpu: 100m
requests:
memory: "1000Mi"
cpu: 100mПо умолчанию мы создаем файл развертывания службы. Если вы не укажете поле ресурсов, кластер Kubernetes будет использовать политику по умолчанию и не будет налагать какие-либо ограничения на ресурсы для Pod, что означает, что Pod может использовать ресурсы памяти и ЦП. узла узла по желанию. Но это вызовет проблему: конкуренцию за ресурсы.
Например: узел Node имеет 8 ГБ памяти, и на нем работают два модуля.
В начале работы обоим модулям для работы требуется только 2 ГБ памяти. В настоящее время проблем нет, но если один из модулей внезапно увеличивается до 7 ГБ из-за утечки памяти или процесс внезапно увеличивается, 8 ГБ памяти узла явно недостаточно на данный момент. Это приведет к очень медленным или недоступным службам.
Следовательно, при нормальных обстоятельствах, когда мы развертываем службы, нам необходимо ограничить ресурсы модуля, чтобы избежать подобных проблем.
Как показано в примере файла, необходимо добавить ресурсы;
requests: 表示运行服务所需要的最少资源,本例为需要内存100Mi,CPU 100m
limits: 表示服务能使用的最大资源,本例最大资源限制在内存1000Mi,CPU 100mЧто это обозначает? Одна картинка стоит тысячи слов.
PS: @@@ 画图 Я очень старался @@@
Зонды живучести и готовности
Еще одна горячая тема, часто обсуждаемая в сообществе Kubernetes. Освоение зондов живучести и готовности очень важно, потому что они предоставляют механизм для запуска отказоустойчивого программного обеспечения и минимизируют время простоя. Однако, если конфигурация неправильная, они могут серьезно повлиять на производительность вашего приложения. Вот краткое описание этих двух зондов и их рассуждений:
Зонд живучести: определяет, запущен ли контейнер. Если зонд активности завершится неудачно, кубелет убьет Контейнер, и Контейнер примет свою стратегию перезапуска. Если «контейнер» не предоставляет зонд активности, статус по умолчанию - «успешно».
Поскольку зонд живучести запускается чаще, настройки максимально просты. Например, если вы установите его на запуск один раз в секунду, то дополнительный запрос будет добавляться в секунду, поэтому вам необходимо учитывать дополнительные ресурсы, необходимые для этого. запрос. Обычно мы предоставляем интерфейс проверки работоспособности для Liveness, который возвращает код ответа 200, чтобы указать, что ваш процесс запущен и может обрабатывать запросы.
Зонд готовности: определяет, готов ли контейнер обработать запрос. Если проверка готовности завершится неудачно, конечная точка удалит IP-адрес модуля из конечных точек всех служб, соответствующих этому модулю.
Требования проверки готовности к проверке относительно высоки, поскольку она указывает на то, что все приложение работает и готово к приему запросов. Для некоторых приложений запрос будет принят только после того, как запись будет возвращена из базы данных. Используя хорошо продуманные датчики готовности, мы можем достичь более высокого уровня доступности и нулевого простоя при развертывании.
Методы обнаружения Зондов живучести и готовности одинаковы, их три.
- Определите команду выживания:
если команда выполнена успешно и возвращаемое значение равно нулю, Kubernetes считает это обнаружение успешным; если возвращаемое значение команды не равно нулю, это определение живучести завершается ошибкой. - Определите живой интерфейс HTTP-запроса;
отправьте HTTP-запрос и верните любой код возврата больше или равный 200 и меньше 400, чтобы указать на успех, а другие коды возврата указывают на сбой. - Определите обнаружение выживания TCP
для отправки запроса tcpSocket в порт выполнения, если он может быть подключен, это означает успех, в противном случае - сбой.
Давайте посмотрим на пример, вот обычное обнаружение выживания TCP в качестве примера
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx-demo
image: nginx
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 10
periodSeconds: 10livenessProbe 部分定义如何执行 Liveness 探测:
1. 探测的方法是:通过tcpSocket连接nginx的80端口。如果执行成功,返回值为零,Kubernetes 则认为本次 Liveness 探测成功;如果命令返回值非零,本次 Liveness 探测失败。
2. initialDelaySeconds: 10 指定容器启动 10 之后开始执行 Liveness 探测,一般会根据应用启动的准备时间来设置。比如应用正常启动要花 30 秒,那么 initialDelaySeconds 的值就应该大于 30。
3. periodSeconds: 10 指定每 10 秒执行一次 Liveness 探测。Kubernetes 如果连续执行 3 次 Liveness 探测均失败,则会杀掉并重启容器。
readinessProbe 探测一样,但是 readiness 的 READY 状态会经历了如下变化:
1. 刚被创建时,READY 状态为不可用。
2. 20 秒后(initialDelaySeconds + periodSeconds),第一次进行 Readiness 探测并成功返回,设置 READY 为可用。
3. 如果Kubernetes连续 3 次 Readiness 探测均失败后,READY 被设置为不可用。Установите сетевую политику по умолчанию для Pod
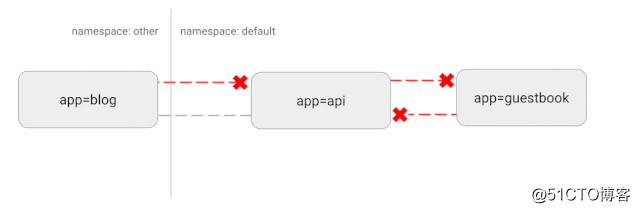
Kubernetes использует «плоскую» топологию сети. По умолчанию все поды могут напрямую взаимодействовать друг с другом. Но в некоторых случаях мы этого не хотим или даже не хотим. Могут возникнуть некоторые потенциальные риски безопасности. Например, если используется уязвимое приложение, оно может предоставить хакеру полный доступ для отправки трафика на все модули в сети. Как и во многих других областях безопасности, здесь также применяется политика минимального доступа.В идеале должна быть создана сетевая политика, четко определяющая, какие соединения между контейнерами разрешены.
Например, следующая простая стратегия будет запрещать весь входящий трафик в определенном пространстве имен.
---
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-ingress-flow
spec:
podSelector: {}
policyTypes:
- IngressПринципиальная схема этой конфигурации
Настраиваемое поведение через хуки и контейнеры инициализации
Одна из наших основных целей при использовании системы Kubernetes - попытаться предоставить стандартным разработчикам развертывание с минимальным временем простоя. Это сложно из-за различных способов, которыми приложение завершает работу и очищает использованные ресурсы. Одно из приложений, с которым мы столкнулись особенно трудным, было Nginx. Мы заметили, что когда мы начали последовательное развертывание этих модулей, активные подключения были прерваны до того, как они были успешно завершены. После обширного онлайн-исследования выяснилось, что Kubernetes не ждет, пока Nginx истощит свои соединения, прежде чем завершить работу Pod. Используя ловушку pre-stop, мы смогли внедрить эту функцию и добиться нулевого времени простоя с этим изменением.
Обычно, например, мы хотим выполнить последовательное обновление до Nginx, но Kubernetes не ждет, пока Nginx завершит соединение, прежде чем остановить Pod. Это приведет к тому, что остановленный nginx не сможет должным образом закрыть все соединения, что неразумно. Поэтому нам нужно использовать хуки, прежде чем останавливаться, чтобы решить такие проблемы.
Мы можем добавить жизненный цикл в файл развертывания
lifecycle:
preStop:
exec:
command: ["/usr/local/bin/nginx-killer.sh"]
nginx-killer.sh
#!/bin/bash
sleep 3
PID=$(cat /run/nginx.pid)
nginx -s quit
while [ -d /proc/$PID ]; do
echo "Waiting while shutting down nginx..."
sleep 10
doneТаким образом, Kubernetes выполнит сценарий nginx-killer.sh перед закрытием Pod, чтобы закрыть nginx так, как мы определили.
Другая ситуация заключается в использовании контейнера инициализации.
Контейнер инициализации - это контейнер, используемый для инициализации. Его может быть один или несколько. Если их несколько, эти контейнеры будут выполняться в определенном порядке. Только после того, как будут выполнены все контейнеры инициализации. , Главный контейнер будет запущен.
Например:
initContainers:
- name: init
image: busybox
command: ["chmod","777","-R","/var/www/html"]
imagePullPolicy: Always
volumeMounts:
- name: volume
mountPath: /var/www/html
containers:
- name: nginx-demo
image: nginx
ports:
- containerPort: 80
name: port
volumeMounts:
- name: volume
mountPath: /var/www/htmlМы смонтировали диск с данными в / var / www / html nginx.Перед запуском основного контейнера мы изменили разрешение / var / www / html на 777, чтобы не возникало проблем с разрешениями при использовании основного контейнера.
Конечно, это всего лишь каштанчик, у Init Container есть более мощные функции, например, начальная настройка. . .
Настройка ядра (оптимизация параметров ядра)
Наконец, оставив более продвинутые технологии
напоследок , ха-ха Kubernetes - очень гибкая платформа, позволяющая запускать сервисы так, как вы считаете нужным. Обычно, если у нас есть высокопроизводительные службы и строгие требования к ресурсам, такие как обычный Redis, после запуска будут отображаться следующие запросы.
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.Это требует от нас изменения параметров ядра системы. К счастью, Kubernetes позволяет нам запускать привилегированный контейнер, который может изменять параметры ядра, применимые только к определенным запущенным модулям. Ниже приведен пример, который мы использовали для изменения параметра / proc / sys / net / core / somaxconn.
initContainers:
- name: sysctl
image: alpine:3.10
securityContext:
privileged: true
command: ['sh', '-c', "echo 511 > /proc/sys/net/core/somaxconn"]подводить итоги
Хотя Kubernetes предоставляет готовое решение, оно также требует, чтобы вы предприняли некоторые ключевые шаги для обеспечения стабильной работы программы. Перед запуском программы обязательно проведите несколько тестов, изучите ключевые индикаторы и внесите корректировки в режиме реального времени.
Прежде чем развернуть сервис в кластере Kubernetes, мы можем задать себе несколько вопросов:
- Сколько ресурсов требуется нашей программе, таких как память, процессор и т. Д.?
- Каков средний трафик сервиса и какой пиковый?
- Как долго мы хотим, чтобы услуга расширялась, и сколько времени потребуется новым модулям для приема трафика?
- Наш Pod нормально останавливается? Как это сделать, не затрагивая онлайн-сервисы?
- Как мы можем гарантировать, что проблемы с нашими сервисами не повлияют на другие сервисы и не вызовут крупномасштабные простои сервиса?
- Наш авторитет слишком велик? это безопасно?
Наконец-то закончил, ву-у-у~ Это так сложно~
Изображение
PS: Последующие статьи будут синхронизированы с dev.kubeops.net
Примечание: изображения в статье взяты из Интернета. Если есть какие-либо нарушения, пожалуйста, свяжитесь со мной, чтобы удалить их вовремя.