Главный контроллер ядра Kafka Контроллер
В кластере Kafka будет один или несколько брокеров, и один из них будет выбран в качестве контроллера (Kafka Controller), который отвечает за управление состоянием всех разделов и реплик во всем кластере.
- Когда ведущая копия раздела выходит из строя, контроллер отвечает за выбор новой ведущей копии для раздела.
- Когда обнаруживается изменение в наборе ISR определенного раздела, контроллер отвечает за уведомление всех брокеров об обновлении информации их метаданных.
- При использовании сценария kafka-topics.sh для увеличения количества разделов для темы контроллер также отвечает за информирование новых разделов о других узлах.
Механизм выбора контролера
Когда кластер kafka запускается, брокер будет автоматически выбран в качестве контроллера для управления всем кластером.Процесс выбора заключается в том, что каждый брокер в кластере будет пытаться создать временный узел / controller на zookeeper, а zookeeper будет гарантировать, что там - это только один брокер, который, если его удастся создать, станет главным контроллером кластера.
Когда брокер роли контроллера отключается, временный узел zookeeper в это время исчезает, а другие брокеры в кластере всегда будут отслеживать этот временный узел. Когда они обнаруживают, что временный узел исчезает, они будут соревноваться за создание временного узла. Опять же, это механизм выбора, о котором мы упоминали выше. Zookeeper гарантирует, что брокер станет новым контроллером.
Брокер с удостоверением контролера должен иметь больше обязанностей, чем другие обычные брокеры. Подробная информация заключается в следующем:
- Следите за изменениями, связанными с брокером . Добавьте BrokerChangeListener в узел / brokers / ids / в Zookeeper, чтобы обрабатывать изменения брокеров.
- Отслеживайте изменения, связанные с темой. Добавьте TopicChangeListener в узел / brokers / themes в Zookeeper для обработки изменений увеличения и уменьшения темы; добавьте TopicDeletionListener в узел / admin / delete_topics в Zookeeper для обработки действия по удалению тем.
- Прочтите всю текущую информацию, относящуюся к теме, разделу и брокеру, от Zookeeper и управляйте ею соответствующим образом. Добавьте PartitionModificationsListener в узел / brokers / themes / [topic] в Zookeeper, соответствующий всем темам, чтобы отслеживать изменения в распределении разделов в теме.
- Обновите информацию метаданных кластера и синхронизируйте ее с другими обычными узлами брокера.
Механизм выбора лидера при копировании раздела
Контроллер обнаруживает, что брокер, на котором находится лидер раздела, не работает (контроллер отслеживает множество узлов zk и может определить, что брокер жив), и контроллер выберет первого брокера из списка ISR (в соответствии с предпосылкой параметра unclean.leader.election.enable = false) В качестве лидера (первый брокер помещается в список ISR первым, это может быть копия с наиболее синхронизированными данными), если параметр unclean.leader.election.enable имеет значение true, это означает, что все копии в списке ISR могут находиться в ISR, когда все копии отключены. Лидер выбирается из реплик, которых нет в списке. Этот параметр может улучшить доступность, но у нового выбранного лидера может быть намного меньше данные.
Для того, чтобы копия попала в список ISR, есть два условия:
- Узел реплики не может создавать разделы и должен иметь возможность поддерживать сеанс с zookeeper и подключаться к сети ведущей реплики.
- Реплика может реплицировать все операции записи на лидере и не может слишком сильно отставать. (Реплики, которые отстают в синхронизации с ведущей репликой, определяются конфигурацией replica.lag.time.max.ms. Реплики, которые не синхронизировались с ведущей репликой один раз по истечении этого времени, будут удалены из списка ISR)
Механизм регистрации смещения для сообщений о потреблении потребителей
Каждый потребитель будет периодически отправлять смещение своего собственного раздела потребления во внутреннюю тему Kafka: __consumer_offsets. При отправке прошлого ключом будет consumerGroupId + topic + номер раздела, а значение - это значение текущего смещения. Kafka будет периодически очистить сообщения в теме и, наконец, сохранить последние данные
Поскольку __consumer_offsets может получать запросы с высоким уровнем параллелизма, Kafka по умолчанию выделяет ему 50 разделов (что может быть установлено с помощью offsets.topic.num.partitions), чтобы он мог противостоять большому параллелизму путем добавления машин.
Следующая формула может использоваться для выбора раздела, который потребитель использует смещения для отправки в __consumer_offsets.
Формула: hash (consumerGroupId)% __consumer_offsets номер раздела темы
Механизм перебалансировки потребителей
Ребалансировка означает, что если количество потребителей в группе потребителей изменится или количество разделов потребления изменится, Kafka перераспределит отношения между разделами потребления потребителей. Например, если потребитель в группе потребителей повесит трубку, назначенный ему раздел будет автоматически передан другим потребителям в это время.Если он перезапустится снова, некоторые разделы будут ему снова возвращены.
Примечание: ребалансировка предназначена только для подписки, которая не указывает потребление раздела. Если раздел указан с помощью assign, Kafka не будет выполнять ребанансирование.
Следующие ситуации могут вызвать перебалансировку потребителей.
- Потребители в группе потребителей увеличиваются или уменьшаются
- Динамически добавлять разделы в тему
- Группа потребителей подписалась на другие темы
Во время процесса ребалансировки потребители не могут получать сообщения от Kafka, что повлияет на TPS Kafka. Если в кластере Kafka много узлов, например сотни, ребалансировка может занять много времени, поэтому старайтесь избегать system Происходит перебалансировка пиков.
Процесс ребалансировки выглядит следующим образом
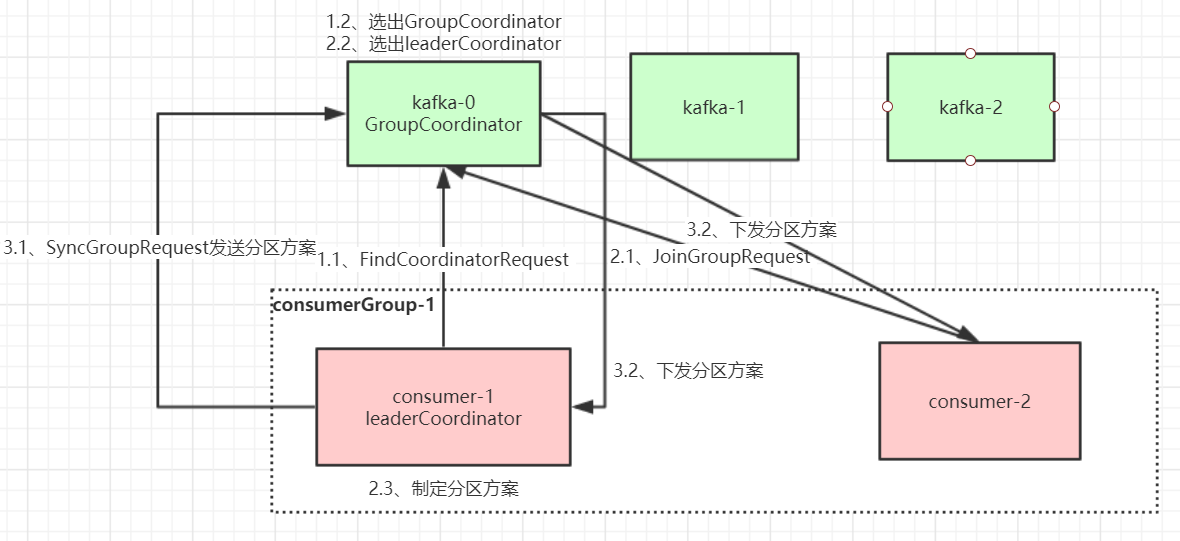
Когда потребитель присоединяется к группе потребителей, потребитель, группа потребителей и координатор группы проходят следующие этапы.
Первый этап: выбор координатора группы
Координатор группы: каждая группа потребителей выберет брокера в качестве координатора своей группы, ответственного за мониторинг пульса всех потребителей в этой группе потребителей и определение того, не работает ли она, а затем включит ребалансировку потребителей.
Когда каждый потребитель в группе потребителей запускается, он отправляет запрос FindCoordinatorRequest узлу в кластере Kafka, чтобы найти соответствующего координатора группы GroupCoordinator и установить с ним сетевое соединение.
Методика выбора координатора группы:
Какому разделу __consumer_offsets потребитель потребляет смещения, следует передать, и брокер, соответствующий лидеру этого раздела, является координатором группы потребителей
Второй этап: присоединиться к группе потребителей JOIN GROUP
После успешного нахождения GroupCoordinator, соответствующего группе потребителей, он переходит на этап присоединения к группе потребителей.На этом этапе потребитель отправляет запрос JoinGroupRequest в GroupCoordinator и обрабатывает ответ. Затем GroupCoordinator выбирает первого потребителя для присоединения к группе из группы потребителей в качестве лидера (координатора группы потребителей), отправляет информацию о группе потребителей этому лидеру, и затем этот лидер будет отвечать за формулирование плана разделения.
Третий этап (SYNC GROUP)
Лидер потребителя отправляет SyncGroupRequest в GroupCoordinator, а затем GroupCoordinator распространяет план раздела каждому потребителю, и они будут выполнять сетевое соединение и потребление сообщений в соответствии с лидером брокера назначенного раздела.
Анализ механизма публикации сообщений производителя
Стратегия распределения раздела Consumer Rebalance:
Существует три основных стратегии ребалансировки: диапазон, циклический и липкий.
Kafka предоставляет клиентский параметр partition.assignment.strategy для установки стратегии распределения разделов между потребителями и темами подписки. По умолчанию используется стратегия распределения диапазона.
Если предположить, что в теме 10 разделов (0-9), теперь существует три потребительских потребления:
Стратегия диапазона состоит в сортировке по номеру раздела. Предполагая, что n = количество разделов / количество потребителей = 3, m = количество разделов% количество потребителей = 1, тогда каждому из первых m потребителей выделяется n + 1 разделов, а следующим потребителям (количество потребляемых лиц-m) выделяется n разделов каждому.
Например, раздел 0 ~ 3 предоставляется одному потребителю, зона 4 ~ 6 - одному потребителю, а зона 7 ~ 9 - одному потребителю.
Стратегия циклического перебора - это циклическое распределение. Например, разделы 0, 3, 6 и 9 назначаются потребителю, разделы 1, 4 и 7 назначаются потребителю, а разделы 2, 5 и 8. закреплены за потребителем.
Первоначальная стратегия распределения липкой стратегии аналогична циклической, но во время перебалансировки необходимо гарантировать соблюдение следующих двух принципов.
1) Распределение разделов должно быть максимально равномерным.
2) Насколько это возможно, распределение разделов остается таким же, как и при последнем выделении.
Когда эти две цели противоречат друг другу, первая цель имеет приоритет над второй. Таким образом можно максимально сохранить исходную стратегию распределения разделов.
Например, для случая выделения первого диапазона, если третий потребитель терпит неудачу, результат перераспределения с использованием липкой стратегии будет следующим:
В дополнение к исходным 0 ~ 3 потребителю 1 будут назначены еще 7
Consumer2 выделит 8 и 9 в дополнение к исходным 4 ~ 6
Анализ механизма публикации сообщений производителя
1. Метод письма
Производитель использует режим push для публикации сообщений брокеру, и каждое сообщение добавляется к паттиону, который представляет собой последовательную запись на диск (эффективность последовательной записи на диск выше, чем в памяти произвольной записи, и пропускная способность Kafka гарантирована).
2. Маршрутизация сообщений
Когда производитель отправляет сообщение брокеру, он выбирает, в каком разделе его сохранить, в соответствии с алгоритмом разделения. Механизм маршрутизации:
1. Если патиция указана, используйте ее напрямую; 2. Если патиция не указана, но указан ключ, патция выбирается путем хеширования значения ключа 3. Если патиция и ключ не указаны, используйте опрос для выбора патиция.
3. Процесс написания

1. Производитель сначала находит лидера раздела из узла «/brokers/.../state» в zookeeper
2. Производитель отправляет сообщение лидеру
3. Лидер записывает сообщение в локальный журнал
4. Последователи извлекают сообщение от лидера и записывают. После входа в локальный журнал отправьте ACK лидеру.5.
После того, как лидер получит ACK всех реплик в ISR, он добавляет HW (высокий водяной знак, смещение конечного commit) и
отправляет ACK производителю
Подробное объяснение HW и LEO
HW широко известен как high water mark, сокращение от HighWatermark. Наименьшее LEO (log-end-offset) в ISR, соответствующем разделу, принимается как HW, и потребитель может потреблять только до места, где находится HW. . Кроме того, каждая реплика имеет HW, а лидер и ведомый несут ответственность за обновление своего собственного статуса HW. Для сообщения, недавно написанного лидером, потребитель не может использовать его немедленно.Лидер будет ждать, пока сообщение будет синхронизировано всеми репликами в ISR, и обновит HW, после чего сообщение может быть использовано потребителем. Это гарантирует, что в случае отказа брокера, у которого находится лидер, сообщение все еще может быть получено от вновь избранного лидера. Для запросов на чтение от внутренних брокеров нет никаких ограничений HW.
На следующем рисунке подробно показан поток ISR, HW и LEO после того, как производитель отправляет сообщения брокеру:

Можно видеть, что механизм репликации Kafka не является ни полной синхронной репликацией, ни чистой асинхронной репликацией. Фактически, синхронная репликация требует, чтобы все рабочие последователи были реплицированы до того, как это сообщение будет зафиксировано.Этот метод репликации сильно влияет на пропускную способность. В режиме асинхронной репликации ведомый реплицирует данные от ведущего асинхронно. Пока данные записываются в журнал ведущим, они считаются зафиксированными. В этом случае, если ведомый еще не реплицировал, и когда лидер отстает, лидер внезапно падает, данные будут потеряны. Kafka использует ISR - это хороший баланс, гарантирующий, что данные не будут потеряны, и пропускная способность. Давайте рассмотрим настройку параметра отправителя сообщения acks для механизма сохранения сообщения. Давайте объединим HW и LEO, чтобы увидеть случай acks = 1.
Объедините HW и LEO, чтобы увидеть случай acks = 1

Сегментация журнала
Данные сообщений раздела Kafka соответственно хранятся в папке, названной в честь названия темы + номера раздела. Сообщения хранятся в сегментах в разделе, а сообщения каждого сегмента хранятся в отдельном файле журнала. Эта удобная функция для быстрого удаления старого файла сегмента. Kafka оговаривает, что максимальный размер файла журнала для сегмента составляет 1 ГБ. Цель этого ограничения - облегчить загрузку файла журнала в память для работы:
# 部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件,
# 如果要定位消息的offset会先在这个文件里快速定位,再去log文件里找具体消息
00000000000000000000.index
# 消息存储文件,主要存offset和消息体
00000000000000000000.log
# 消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,
# 如果需要按照时间来定位消息的offset,会先在这个文件里查找
00000000000000000000.timeindex
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindexЭто число, например 9936472, представляет начальное смещение, содержащееся в файле сегмента журнала, что означает, что в этот раздел записано не менее 10 миллионов фрагментов данных.
У Kafka Broker есть параметр log.segment.bytes, который ограничивает размер каждого файла сегмента журнала, максимальный - 1 ГБ.
Когда файл сегмента журнала заполнен, новый файл сегмента журнала автоматически открывается для записи, чтобы не допустить, чтобы отдельный файл был слишком большим и не влиял на производительность чтения и записи файла. Этот процесс называется прокруткой журнала, а файл сегмента журнала запись называется активным сегментом журнала.
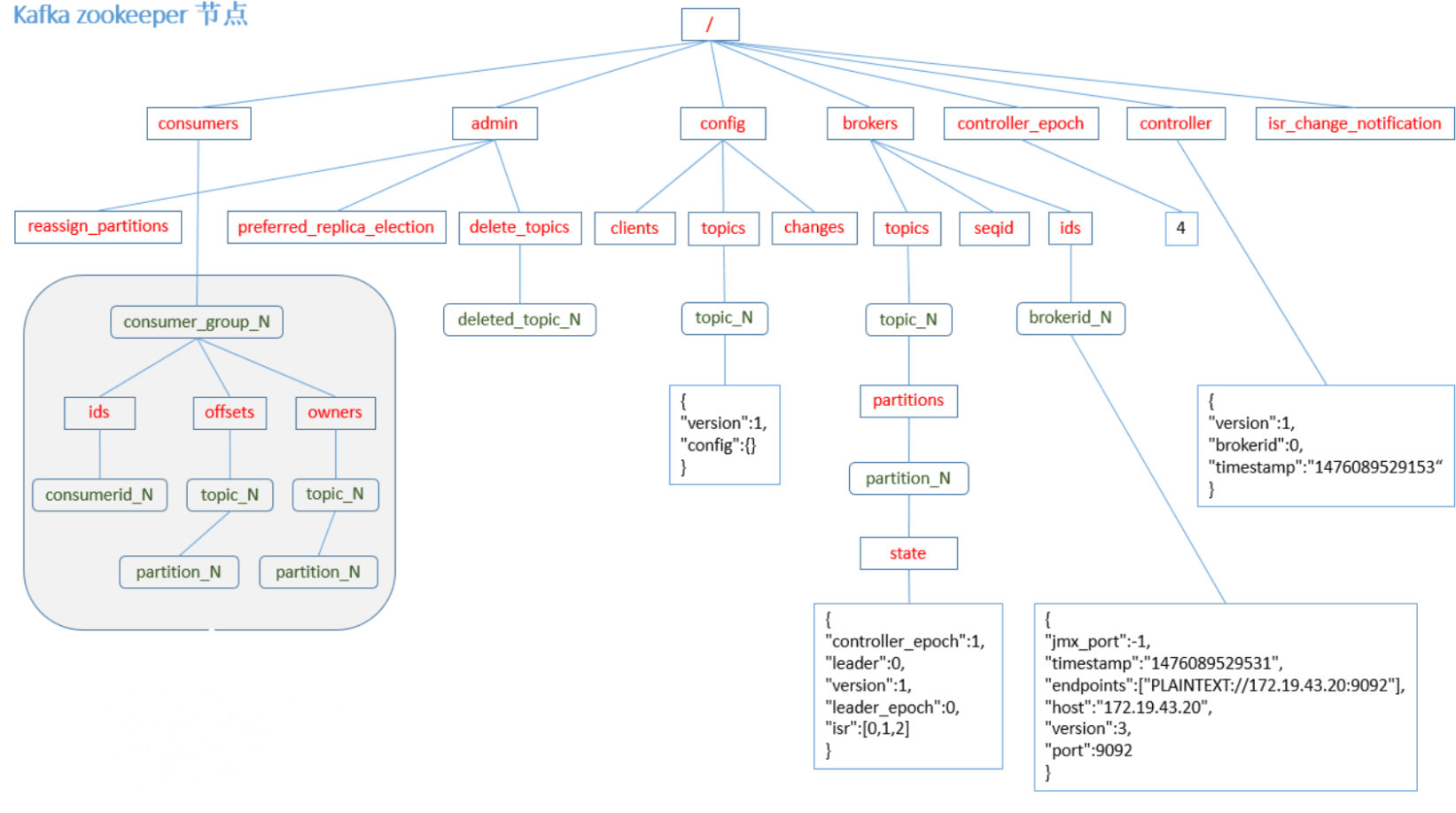
Наконец, прилагается диаграмма данных узла zookeeper: