Группа обмена | Введите «группа датчиков/группа шасси скейтборда», добавьте идентификатор WeChat: xsh041388
Группа обмена | Войдите в «Группу автомобильного базового программного обеспечения», добавьте учетную запись WeChat: Faye_chloe
Примечания: название группы + настоящее имя, компания, должность
Автор интересовался многими знаниями в области моделирования автономного вождения (номер один — «моделирование с реальными дорожными данными») более двух лет, но у меня никогда не было возможности изучить его раньше. Во время эпидемии в апреле прошлого года мне иногда выпадала возможность пообщаться с основателем компании по разработке симуляторов, и автор воспользовался случаем, чтобы задать ему множество вопросов.
С тех пор для перекрестной проверки автор последовательно проконсультировался почти с 20 экспертами, работающими на переднем крае бизнеса по моделированию автономного вождения.
В число экспертов, оказывающих поддержку этой серии исследовательских заметок, входят, помимо прочего, Ань Хунвэй, генеральный директор Zhixing Zhongwei, Ян Цзыцзян, основатель Shenxin Kechuang, Ли Юэ, технический директор Zhixing Zhongwei, Бао Шицян, технический директор 51 World, и специалисты по моделированию. экспертов Momo Zhixing, Qingzhou Zhihang, Cheyou Intelligent и т. д. Спасибо за это.
Вопрос 1: Источник сцены — от синтетических данных к реальным дорожным данным
По словам Ли Манмана, автора публичного аккаунта «Che Lu Slowly», и Ли Юэ, технического директора Zhixing Zhongwei, обычно существует два взгляда на источник симуляционной тестовой сцены:
Первая идея представляет собой трехуровневую систему функциональных сценариев-логических сценариев-специфических сценариев, предложенную немецким проектом PEGASUS: 1) получить различные типы сценариев (то есть функциональные сценарии) путем сбора и теоретического анализа реальных дорожных данных; 2) , а затем проанализировать ключевые параметры в этих различных типах сцен и получить диапазон распределения этих ключевых параметров (то есть логических сцен) с помощью таких методов, как статистика реальных данных и теоретический анализ; 3) и, наконец, выбрать значение группа параметров в виде тестовых сценариев (т.е. конкретных сценариев).
Как показано ниже:
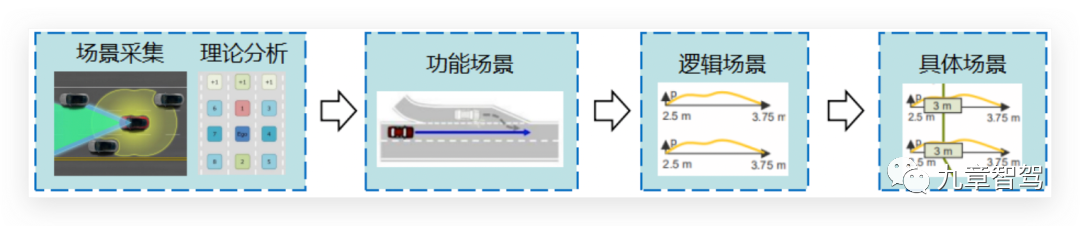
Например, функциональный сценарий можно описать так: «самостоятельное транспортное средство (испытываемое транспортное средство) движется по текущей полосе движения, перед самоходным транспортным средством ускоряется автомобиль, и самоходное транспортное средство следует за движущимся впереди транспортным средством. ." Логическая сцена извлекает ключевые параметры сцены, И присваивает параметрам сцены определенный диапазон значений. Например, в описанной выше сцене такие параметры, как скорость автомобиля впереди, скорость и ускорение автомобиля впереди , а также расстояние между впереди идущим транспортным средством и впереди идущим транспортным средством может быть извлечено.Каждый параметр имеет определенный диапазон значений и характеристики распределения.Также могут быть зависимости между параметрами. Для конкретной сцены необходимо выбрать конкретные значения параметров сцены, чтобы сформировать вектор параметров сцены и выразить их на конкретном языке сцены.
На самом деле это так называемая "виртуальная конструкция/сгенерированная алгоритмом сцена". Хотя понимание сцены все же исходит из реальной дорожной сцены, на практике больше основано на этом понимании "искусственное начертание" сцены в Программное обеспечение Траектория движения, набор сцен, поэтому данные за этой сценой также называют «синтетическими данными».
На практике основная проблема с этим подходом заключается в том, достаточно ли глубоко понимает инженер-симулятор обычные сценарии вождения автомобиля. Если инженер не разбирается в сцене и умышленно "рисует" сцену, конечно, ее нельзя использовать.
Второй способ мышления: собрать данные о транспортном потоке в заранее определенной рабочей зоне автономного транспортного средства и ввести эти данные в инструмент моделирования дорожного движения для создания транспортного потока и использовать этот транспортный поток в качестве «окружающего транспортного средства». автономного вождения автомобиля для реализации теста Автоматическая генерация сцен.
По словам Яна Цзыцзяна, основателя Shenxin Kechuang, чтобы обеспечить более точное «истинное значение», обычно конфигурация датчиков на инженерном транспортном средстве намного выше, чем у обычных беспилотных автомобилей. система будет использовать оборудование мощностью более 20 Вт, а лидар дальнего света будет давать более точные данные.
Говорят, что Waabi, компания по моделированию, основанная Ракель Уртасун, бывшим главным научным сотрудником UberACT, использует данные, собранные камерой, для моделирования без необходимости использования высокоточных датчиков, таких как лидар.
Самым большим преимуществом использования реальных дорожных данных для моделирования является то, что разнообразие сценариев не будет ограничено непониманием инженерами сценариев, поэтому легче «спасти» те неизвестные сценарии, о которых «никто не может подумать». ".
Кроме того, человек, отвечающий за симуляцию компании с автономным вождением, сказал: «Чтобы повысить реалистичность симуляции, мы будем использовать как можно меньше синтетических данных и использовать больше реальных дорожных данных». На самом деле текущая симуляция уже развивается в этом направлении — реальных данных и модулей становится все больше.
Однако инженеры, занимающиеся передовым моделированием, обычно считают эту идею слишком идеалистичной. В частности, использование реальных дорожных данных для моделирования имеет следующие ограничения:
1. Данные нужно проверять вручную
На самом деле, данные, собираемые датчиком, нельзя напрямую использовать для симуляции — тип и формат данных нужно преобразовывать, есть много недействительных данных, которые нужно очистить, и из них нужно выделить валидные сцены, а некоторые необходимо пометить определенные элементы Различные датчики Данные между ними должны быть синхронизированы и объединены в режиме реального времени и т. д.
В нормальных условиях данные о восприятии автономных транспортных средств не нужно проверять вручную, а они напрямую передаются алгоритму принятия решений.Однако, если это симуляция, ручная проверка данных о восприятии является важным шагом.
2. Обратный процесс реализовать труднее, чем прямой.
Инженер-симулятор компании по производству беспилотных грузовиков сказал: Моделирование с использованием синтетических данных — это положительный процесс, то есть вы сначала знаете, какие тесты вам нужно провести, а затем берете на себя инициативу по разработке такой сцены; моделирование с использованием реальных данных — это положительный процесс. Обратный процесс, то есть вы сначала сталкиваетесь с проблемой, а потом решаете ее. Сравнивая два, последнее намного сложнее.
3. Не удалось решить проблему взаимодействия
Джейми Чжан, глава Furui Microelectronics, упомянул в публичном сообщении, что WorldSim (с использованием виртуальных данных для моделирования) похож на игру, а LogoSim (с использованием реальных дорожных данных для моделирования) больше похож на фильм, который можно только смотреть. участвовать, поэтому LogoSim, естественно, не может решить проблему интерактивности.
4. Невозможно сделать замкнутый цикл
Джейми Чжан, глава Furui Microelectronics, также упомянул еще одно различие между двумя методами моделирования: при использовании реальных дорожных данных для воспроизведения фрагменты, которые можно собрать, всегда ограничены, и часто, когда начинается сбор, опасность уже может возникнуть. какое-то время, и получить предыдущие данные сложно, но если вы используете виртуальные данные (синтетические данные), вам не придется сталкиваться с этой проблемой.
Ответственный за моделирование OEM сказал: «Вышеупомянутые эксперты описали процесс сбора данных. Действительно, учитывая мощность оборудования для сбора данных и определение эффективных сцен, сцены сбора и управления имеют продолжительность, как правило, до и после срабатывания функции.Время,особенно кеш перед срабатыванием, будет не особо долгим.С другой стороны,когда данные собираются и используются для перезаполнения,действительна только сцена до срабатывания функции,а реальная сцена после срабатывания триггер функции недействителен из."
Эксперт OEM сказал: «Можно использовать реальные дорожные данные для обучения алгоритма восприятия, но для тестирования всей связи алгоритма ему все равно придется полагаться на синтетические данные сцены».
Однако директор по моделированию завода главных двигателей также подчеркнул в конце: «Так называемая «замкнутая петля не может быть достигнута» также относительна. Уже есть поставщики, которые могут завершить параметризацию элементов в собранных сценах, поэтому что замкнутый цикл может быть достигнут. Но цена такого оборудования очень высока».
5. Подлинность данных по-прежнему сложно гарантировать
Моделирование с использованием реальных данных о транспортном потоке, также известное как «подзарядка».
По словам Ян Цзыцзяна, основателя Shenxin Kechuang, есть две основные технологии, которые необходимо использовать для «подзарядки»: одна заключается в восстановлении структуры дорожной сети данных горных работ в среде моделирования, а другая — в интеграции. динамические участники дорожного движения (пешеходы, транспортные средства и т. д.). Информация о положении в различных системах координат сопоставляется с глобальной системой координат в моделируемой мировой дорожной сети.
Инструменты, которые необходимо использовать в этом процессе, — SUMO или openScenario — используются для считывания информации о местонахождении участников дорожного движения.
Эксперт по моделированию OEM-производителя сказал: «Повторное заполнение исходных данных не может гарантировать 100% подлинность, потому что после того, как исходные данные вводятся в платформу моделирования, необходимо добавить моделирование динамики автомобиля. такая же, как и на настоящей дороге. Сцены такие же, поэтому трудно сказать».
Причина в том, что существующее программное обеспечение для моделирования транспортных потоков часто имеет следующие серьезные недостатки:
Сгенерированный транспортный поток недостаточно точен, часто поддерживает только импорт траекторий транспортных средств, а двустороннее взаимодействие между транспортными средствами недостаточно реалистично;
Интерфейс передачи данных между модулем имитации (собственное транспортное средство) и модулем транспортного потока (другие участники дорожного движения) ограничен (например, формат дорожной сети другой, требуется согласование дорожной сети), а сторонняя работоспособность ограничена. ограниченное;
Модель транспортного потока на основе правил ориентирована на оценку эффективности трафика, и могут быть проблемы чрезмерного упрощения (часто используются одномерные модели, предполагающие, что заведение движется по центральной линии, а боковое воздействие меньше учитывается) ), и трудно выполнить требования интерактивной оценки безопасности.
Инженер по моделированию уровня 1 сказал, что довольно сложно использовать данные о реальном транспортном потоке для создания сценариев моделирования, как выбрать модель транспортного потока (например, как определить модель следования за автомобилем и модель смены полосы движения) и как определить интерфейс модуля имитации транспортного потока. При этом, как синхронизировать данные собственного автомобиля с данными других участников дорожного движения, тоже будет большой проблемой.
6. Универсальность данных низкая, а обобщение затруднено
И Ан Хунвэй, генеральный директор Zhixing Zhongwei, и Ли Юэ, технический директор, особо отметили «универсальность» данных моделирования. Так называемая универсальность данных означает возможность настройки параметров автомобиля и сцены. Например, когда данные собираются автомобилем, угол обзора камеры очень низкий, но после того, как он становится сценой моделирования, угол обзора камеры можно отрегулировать выше, и этот набор данных может быть используется для испытания модели грузовика.
Если сцена сгенерирована виртуальной конструкцией/алгоритмом, каждый параметр можно настроить произвольно в соответствии с потребностями, тогда что, если сцена основана на реальных дорожных данных?
Ответственный за моделирование компании, занимающейся цепочкой инструментов, сказал, что в случае использования реальных дорожных данных для моделирования после изменения положения или модели датчика значение этого набора данных будет уменьшено или даже « устаревший".
Эксперты по моделированию Цинчжоу Чжихан сказали, что нейронная сеть также может использоваться для настройки параметров реальных дорожных данных.Такая настройка параметров будет более интеллектуальной, но управляемость будет слабее.
Использование реальных данных о транспортном потоке для моделирования, также известного как «подзарядка», и подзарядка может быть разделена на два типа: прямая подзарядка и подзарядка модели ——
Так называемая "прямая перезарядка" относится к прямой подаче данных датчика в алгоритм без обработки. В этом режиме параметры автомобиля и сцены не могут быть скорректированы. Данные, собранные определенной моделью, могут использоваться только для тот же автомобиль Имитационный тест модели;
«Заполнение модели» относится к абстрагированию и моделированию данных сцены в первую очередь и выражению их с помощью набора математических формул.В этой математической формуле параметры транспортного средства и сцены настраиваются.
По словам Ли Юэ, прямая подзарядка не требует использования математических моделей: "Это относительно просто. По сути, пока есть возможность работы с большими данными, это можно сделать". математические формулы.
Технический порог перезарядки модели очень высок, а стоимость невысока. Инженер-симулятор сказал: «Очень сложно преобразовать данные, записанные датчиком, в данные моделирования. Поэтому в настоящее время эта технология в основном остается в PR. На практике симуляционные тесты каждой компании основаны на сценариях, сгенерированных алгоритмами, дополненных сценариями из реальных дорожных наборов».
Ответственный за моделирование компании по автономному вождению сказал: "Использование реальных данных о транспортном потоке для моделирования все еще является очень передовой технологией. Очень сложно настроить параметры этих данных (параметры можно настроить только в небольшой ассортимент). Поскольку добыча дорог представляет собой набор журналов и записей один за другим, он записывает, как машина работает в первую и вторую секунду, в отличие от некоторых сцен, отредактированных людьми, которые состоят из ряда формул.
Эксперт по моделированию сказал, что самая большая проблема перезаполнения модели заключается в том, что в случае сложных сценариев чрезвычайно сложно сформулировать сценарии.Этот процесс может быть реализован в автоматическом режиме, но в конечном итоге это может быть ли сцена б/у тоже вопрос.
В 2020 году Waymo объявила, что, «непосредственно генерируя реалистичную информацию об изображении из данных, собранных датчиком для моделирования», ChauffeurNet фактически использует нейронную сеть в облаке для преобразования исходных дорожных данных в математическую модель, а затем пополняет модель. Но эксперт по моделированию, много лет работающий в Силиконовой долине, сказал, что это все еще находится в стадии эксперимента, и до того, как это станет реальным продуктом, еще есть время.
По словам эксперта по моделированию, более значимым, чем повторное кормление, является внедрение машинного обучения или обучения с подкреплением. В частности, система моделирования обучает некоторую собственную логику на основе полного изучения привычек поведения различных участников дорожного движения, формулирует эту логику, а затем корректирует параметры в этих формулах.
Однако, по словам Ли Юэ, технического директора Zhixing Zhongwei, и Фэн Цзунлей, заместителя генерального директора, они уже смогли реализовать подзарядку модели.
Фэн Цзунлей считает, что способность компании, занимающейся моделированием, пополнить модель, в основном зависит от используемых ими инструментов и их возможностей управления сценой.
«В управлении сценами нарезка является очень важной частью — не все данные действительны. Например, за 1 час данных реальные эффективные данные могут быть менее 5 минут. быть вырезаны, и этот процесс называется «нарезкой».
«После того, как нарезка завершена, компании, занимающейся моделированием, необходимо создать соответствующую среду управления с семантической информацией (например, кто пешеход, а кто перекресток), чтобы облегчить следующую проверку. В частности, необходимо сначала классифицировать срезы данных. , а затем Затем уточните список динамических целей, а затем импортируйте его в модель среды моделирования. Таким образом, модель имеет соответствующую семантическую информацию. С помощью семантической информации вы можете настроить параметры, а затем данные. можно использовать повторно.
«Причина, по которой большинство компаний не могут настроить параметры на основе реальных данных о транспортном потоке, заключается в том, что они плохо справились с управлением сценой».
Ян Цзыцзян, основатель Shenxin Kechuang, сказал: «Если вы хотите обобщить данные о горных работах на дорогах и сохранить их достоверность, вы можете воспроизвести данные о горных работах на этапе инициализации сцены и на начальном этапе, а также на определенном этапе. указать, что модель smart-npc возьмет на себя управление дорогой Фоновые транспортные средства в системе будут препятствовать движению фоновых транспортных средств в соответствии с данными выборки дорог После того, как smart-npc вступит во владение, он записывает обобщенные сцены, чтобы обобщенные ключевые сцены можно воспроизвести».
Инженер-симулятор OEM-производителя считает, что, хотя перезарядка модели звучит «неясно», на самом деле в этом нет необходимости. Причина в том, что моделирование данных не соответствует первоначальному намерению пополнения — первоначальное намерение пополнения состоит в том, чтобы захотеть получить реальные данные, но, поскольку модель смоделирована и параметры настраиваются, это не самое реальное; отнимающее много времени и кропотливое преобразование формата данных Очень хлопотно и неблагодарно.
Инженер сказал: «Поскольку вам нужно больше сценариев, вы можете напрямую использовать симулятор для создания обобщенных сценариев в больших масштабах. Вам не нужно идти по пути моделирования реальных данных».
В ответ Фэн Цзунлей ответил:
«Использование алгоритмов для прямого создания сцен, конечно, не проблема на ранних стадиях разработки, но ограничения также очевидны — как насчет тех сцен, которые инженеры «неожиданно» придумали? Реальные условия дорожного движения постоянно меняются, и ваше воображение не может ограничено Дайте все.
«Что еще более важно, в сцене, придуманной инженером, отношения взаимодействия между объектами часто неестественны. Например, если перед вами находится транспортное средство, под каким углом оно вставляется? Когда оно находится в 10 метрах от вас. ,это еще метров 5.Врезка времени?В практике использования алгоритмов генерации сцен формулировка параметров сцены часто очень субъективна и условна.Инженеры взяли мозги и придумали набор моделей ввода параметров,но это этот набор параметров репрезентативен?»
Фэн Цзунлей считает, что когда беспилотное вождение все еще находится на стадии демонстрации, виртуальные сцены, генерируемые алгоритмами, могут удовлетворить потребности, но в эпоху предустановленного массового производства обобщение сцен основано на крупномасштабных данных о естественном вождении (реальный транспортный поток). данные) Еще очень нужно.
По словам человека, имевшего контакт с Momenta: «Momenta уже имеет возможность использовать данные реальных дорог для обобщения сцены (настройки параметров), но их технология предназначена только для их собственного использования, а не для внешнего мира».
Бао Шицян, руководитель отдела моделирования транспортных средств в 51 World, считает, что обобщение данных о естественном вождении все еще относительно перспективно, но оно определенно станет очень важным направлением в будущем, поэтому они также изучают.
Краткое содержание: Два маршрута пересекаются друг с другом, и границы становятся все более размытыми.
Джеймс Чжан, ответственный за микросимуляцию Furui, некоторое время назад упомянул, что существует два метода моделирования Теслы: полностью виртуальная сцена (генерируемая алгоритмом) называется WorldSim, а воспроизведение реальных данных называется LogSim. чтобы алгоритм увидел. "Однако дорожная сеть в WorldSim также генерируется на основе автоматической стандартизации данных реальных дорог. Поэтому границы между WorldSim и LogSim становятся все более размытыми".
Эксперт по моделированию из Qingzhou Zhihang сказал: «После того, как данные реальной сцены преобразуются в стандартные отформатированные данные, их можно дегенерализировать с помощью правил, тем самым создавая более ценные сценарии моделирования».
Бао Шицян, глава отдела автомобильного моделирования 51 World, также считает, что будущая тенденция заключается в том, что два пути моделирования с использованием реальных дорожных данных и моделирования с использованием данных, сгенерированных алгоритмом, будут взаимопроникать.
Бао Шицян сказал: «С одной стороны, использование алгоритмов для создания сцен также зависит от понимания инженером реальных дорожных сцен. Чем полнее понимание реальных сцен, тем ближе моделирование может быть к реальности. С другой стороны, использование реальные дорожные данные в виде сцен. Также необходимо нарезать и извлечь данные (отсеять эффективную часть), затем установить параметры, запустить правила, а затем выполнить уточненную классификацию, после чего их можно логизировать и сформулировать».
Вопрос 2: Обобщение сцен и извлечение сцен
«Настройка параметров» данных сцены, неоднократно упоминавшаяся в предыдущих абзацах, также называется «генерализацией сцены» — обычно в основном относится к генерализации виртуальных сцен. По словам системного инженера OEM-производителя, преимущество обобщения сцен заключается в том, что мы можем «создать» некоторые сцены, которые никогда не видели в реальном мире.
Чем сильнее способность компании-симулятора к обобщению сцен, тем больше доступных сцен можно получить после настройки параметров определенной сцены.Поэтому способность к обобщению сцен также является ключевым фактором конкурентоспособности компании-симулятора.
Тем не менее, эксперты по алгоритмам Qingzhou Zhihang заявили, что обобщение сцены может быть достигнуто с помощью математических моделей, машинного обучения и других методов, но ключевой вопрос заключается в том, как обеспечить, чтобы обобщенная сцена была реальной и более ценной.
Каковы ключевые факторы, определяющие, насколько сильна или слаба способность компании к обобщению сцены?
Ян Цзыцзян, основатель Shenxin Kechuang, считает, что большая трудность в обобщении сцены заключается в том, как абстрагировать траекторию в семантику более высокого уровня и выразить ее на языке формального описания.
Инженер по моделированию уровня 1 сказал: «В основном это зависит от того, какой язык (например, openscenario) используется инструментом моделирования, используемым компанией для описания различных сценариев трафика.
Существуют соответствующие языки сценариев для функциональных сценариев, логических сценариев и конкретных сценариев: для первых двух существуют расширенные языки сценариев, такие как M-SDL, для последних — OpenSCENARIO, GeoScenario и т. д.
Другим уровнем может быть имитация интерференционного поведения, степень обобщения различных видов поведения при вождении и «личность» вождения.
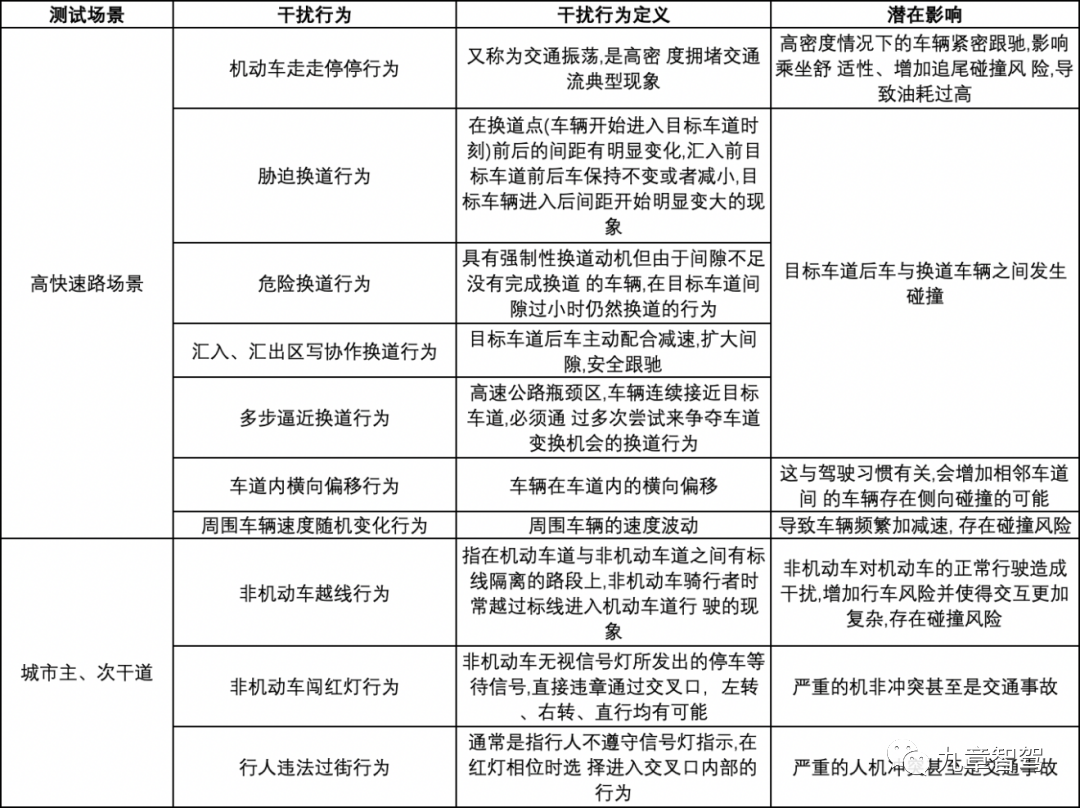
△Диаграмма взята из книги «Теория и метод оценки теста виртуального моделирования автономного вождения» Сунь Цзяня, Тянь Е и Ю Жунцзе.
Ян Цзыцзян, основатель Shenxin Technology, сказал: «Основываясь на обобщении транспортного потока и интеллекте водителей, если модель достаточно хороша, из-за наличия случайных факторов 10-кратный запуск сцены эквивалентен 10-кратному обобщению. раз».
Однако Ли Юэ, технический директор Zhixing Zhongwei, считает, что нельзя делать обобщение ради обобщения. «Мы должны иметь глубокое понимание тестируемой функции, а затем разработать план обобщения, а не обобщение ради обобщения, не говоря уже об обобщении без границ. Хотя обобщение сцены виртуально, мы также должны уважать Реальность».
Другой эксперт по моделированию также сказал: «В конце концов, моделирование должно служить тестированию. Мы уже столкнулись с проблемой на дороге, и тогда мы посмотрим, как решить ее с помощью моделирования, вместо того, чтобы говорить, что у меня есть технология моделирования. сначала, а потом посмотрим, для чего он используется?»
Упомянутый выше специалист по моделированию сказал, что, насколько ему известно, не так много компаний, которые действительно могут добиться обобщения сценариев, в большинстве случаев настройка параметров выполняется вручную. «Способность обобщать сцену очень важна, но на данном этапе ни одна компания не может сделать это хорошо».
Бао Шицян, глава отдела моделирования транспортных средств в 51 World, считает, что самое важное для обобщения сцен — это глубокое понимание того, какие сценарии необходимы для тестов моделирования автономного вождения. На самом деле проблема сейчас не в том, что сгенерированных сценариев слишком мало, а в том, что их слишком много, и многие из них на самом деле не сбудутся, поэтому они не считаются эффективными тестовыми сценариями, это вызвано непониманием требований.
По мнению некоторых экспертов, самая большая проблема, с которой сталкиваются сторонние компании, занимающиеся моделированием, заключается в том, что они недостаточно понимают, какое моделирование требуется для автономного вождения, поскольку они лично не участвовали в автономном вождении.
И те компании, занимающиеся автономным вождением L4, которые способны и имеют глубокое понимание требований к моделированию, не имеют достаточной мотивации для очень глубокого обобщения сцены. Поскольку роботакси обычно работает только в небольшом районе определенного города, им нужно только собрать данные сцены этой области для обучения и тестирования, нет особой необходимости обобщать многие из них на долгое время. один коснется.
Бао Шицян считает, что такие OEM-производители, как Вэй Сяоли, располагают большим количеством данных о реальных дорогах, и нет большой потребности в обобщении сцен. Напротив, для этих компаний важнее, чем обобщение сцен, отладить классификацию сцен и управление ими, а также отсеять действительно эффективные сцены.
Эксперты по моделированию из Qingzhou Zhihang также считают, что с увеличением размера автопарка и быстрым распространением данных с реальных дорог для компаний, занимающихся моделированием, как полностью разработать эффективные сценарии в этих данных действительно гораздо важнее, чем обобщение сцены. «Мы можем изучить более интеллектуальный метод обобщения, который может быстрее выполнять крупномасштабную проверку алгоритма».
Ян Цзыцзян сказал: «Стремясь к обобщению на уровне параметров, таких как количество полос движения, количество типов участников дорожного движения, погода и ключевые параметры, такие как скорость и TTC, способность каждой компании генерировать обобщенные сценарии аналогична, но суть способности сцены к обобщению заключается в том, как идентифицировать действительные сцены и фильтровать недопустимые сцены (включая повторяющиеся и необоснованные); а сложность распознавания сцен заключается в том, что сложные сцены должны идентифицировать отношения между несколькими объектами. "
Упомянутое выше «определение допустимых сцен и фильтрация недопустимых сцен» также называется «извлечением сцен».
Предпосылка извлечения сцены состоит в том, чтобы сначала выяснить, что является «действительной сценой». По мнению нескольких экспертов по моделированию, в дополнение к сценариям, которые должны быть проверены в соответствии с законом, эффективные сценарии также включают следующие два типа: при предварительном проектировании системы сценарии, определенные инженерами в соответствии с требованиями разработки алгоритма; сценарий «Не могу понять правильно».
Конечно, эффективность и неэффективность относительны, что связано со стадией развития компании и стадией зрелости алгоритма — в принципе, по мере зрелости алгоритма и решения задачи многие исходные эффективные сценарии станут недействительными сценариями.
Так как же эффективно отсеивать эффективные сценарии?
В академическом сообществе есть идея: задать некоторые значения энтропии в алгоритме восприятия, и когда сложность сцены превысит эти значения, алгоритм восприятия пометит измененную сцену как действительную сцену. Но как установить это значение энтропии — большая проблема.
Компания, занимающаяся моделированием, использует «метод исключения», то есть, если алгоритм, который изначально работал очень хорошо, имеет «частые проблемы» в некоторых сценариях обобщения, то этот сценарий с высокой вероятностью является «недопустимым сценарием» и может быть исключен. .
Системный инженер из OEM сказал: «В настоящее время нет хорошего метода для скрининга сцены. Если вы не уверены, то поместите его в облачное моделирование для расчета. В конце концов, вы можете просчитать эти экстремальные сценарии, а затем использовать эти экстремальные условия в ваших собственных. Если проверка выполняется на стенде HIL или стенде VIL, эффективность будет намного выше».
Вопрос 3: В чем сложность моделирования?
В процессе общения с экспертами из многих компаний по моделированию и их последующими пользователями мы узнали, что одним из самых сложных аспектов моделирования автономного вождения является сенсорное моделирование.
По словам Ли Юэ, технического директора Zhixing Zhongwei, сенсорное моделирование можно разделить на моделирование на функциональном информационном уровне, моделирование на уровне информации о явлениях/уровень статистической информации и полное моделирование на физическом уровне. Разница между этими понятиями заключается в следующем –
Функциональное моделирование на информационном уровне просто описывает конкретные функции выходного изображения камеры и радара миллиметрового диапазона, обнаруживающие цели в определенном диапазоне.Основная цель состоит в тестировании и проверке алгоритма восприятия, но не обращает внимания на производительность сам датчик;
Моделирование на уровне информации о явлениях и статистической информации представляет собой гибридное моделирование на промежуточном уровне, которое включает частичное моделирование на функциональном информационном уровне и частичное моделирование на физическом уровне;
Моделирование на уровне полной физики относится к моделированию всего физического звена работы датчика с целью проверки физических характеристик самого датчика, таких как фильтрующая способность радара миллиметрового диапазона.
Сенсорное моделирование в узком смысле относится к моделированию на полном физическом уровне. Этот вид моделирования мало кто может преуспеть, конкретные причины заключаются в следующем:
1. Недостаточно высокая эффективность рендеринга изображения
С точки зрения принципов визуализации компьютерной графики моделирование датчика включает свет (моделирование ввода и вывода), геометрию, моделирование материалов, рендеринг изображений и другие моделирования, и разница в возможностях и эффективности рендеринга будет влиять на подлинность моделирования.
2. Слишком много типов датчиков и «невозможный треугольник» точности, эффективности и универсальности модели.
Недостаточно иметь один датчик с высокой точностью, также необходимо, чтобы все датчики достигали идеального состояния одновременно, что требует широкого охвата моделирования, но под давлением стоимости это, очевидно, невозможно для команда моделирования Radar делает 10 или 20 версий моделирования, верно? С другой стороны, сложно использовать общую модель для выражения различных сенсоров разных стилей.
Точность, эффективность и универсальность модели представляют собой отношения «невозможного треугольника». Вы можете улучшить одну сторону или два угла, но вам сложно постоянно улучшать три измерения одновременно. Когда эффективность достаточно высока, точность модели должна снижаться.
Эксперт по моделированию Cheyou Intelligence сказал: «Независимо от того, насколько сложна математическая модель, она может имитировать реальный датчик только с 99% сходства, а оставшийся 1% может быть фактором, который вызовет фатальные проблемы».
3. Моделирование датчика зависит от параметров цели
Моделирование датчика требует внешних данных, то есть данные внешней среды сильно связаны с датчиком, однако моделирование внешней среды на самом деле довольно сложно и стоит не мало.
В городских сценах слишком много зданий, которые будут серьезно потреблять вычислительные ресурсы для рендеринга изображения. Некоторые здания будут блокировать транспортный поток, пешеходов и другие целевые объекты на дороге, но заблокированы они или нет, сумма расчета совсем другая.
Кроме того, с помощью моделирования датчика трудно определить отражательную способность и материал цели. Например, можно сказать, что мишень имеет форму бочки, но через моделирование трудно четко выразить, железная ли это бочка или пластиковая бочка, даже если это можно выразить ясно, это уже другая проблема. настроить эти параметры в имитационную модель Супер большой проект.
Если физическая информация, такая как материал целевого объекта, неясна, трудно выбрать симулятор для моделирования.
4. Трудно определить, сколько шума добавляет датчик
Инженер-симулятор уровня 1 сказал: «Распознавание объектов с помощью алгоритмов глубокого обучения — это процесс от сбора реальных данных датчика до шумоподавления сигнала. В отличие от этого, моделирование датчика основано на идеальной физической модели. Добавьте шум, и сложность заключается в том, как добавить шум, чтобы он был достаточно близок к реальному миру, чтобы его можно было распознать с помощью модели глубокого обучения и эффективно улучшить обобщение распознавания модели».
Подразумевается, что сигнал датчика, генерируемый симуляцией, должен быть «достаточно похож» на сигнал датчика в реальном мире (может идентифицировать соответствующий объект), но не «слишком похож» (моделирование углового случая позволяет модели восприятия достичь узнавание в большем количестве ситуаций — — обобщение). Однако проблема заключается в том, что в реальном мире шум датчика во многих случаях является случайным, а это означает, что моделирование этих шумов в системе моделирования является большой проблемой.
С точки зрения принципа сенсора, процесс моделирования камеры также должен выполнять размытие камеры (сначала создать идеальную модель, а затем добавить шум), моделирование искажения, моделирование виньетирования, преобразование цвета, обработку эффекта «рыбий глаз» и т. д. Модель может также можно разделить на идеальную модель облака точек (этапы включают отсечение сцены, оценку видимости, оценку окклюзии и расчет положения), модель затухания мощности (включая мощность приемного лазера, мощность отраженного лазера, коэффициент усиления отражающей антенны, поперечное сечение целевого рассеяния, апертуру интерфейса , расстояние до цели, коэффициент атмосферного пропускания, коэффициент оптического пропускания и т. д.) и физические модели с учетом погодного шума и т. д.
5. Ограничения ресурсов
Хунвэй, генеральный директор Zhixing Zhongwei, упомянул об ограниченности ресурсов для виртуального моделирования восприятия: «Нам необходимо провести полное моделирование физического уровня датчика, например, оптических и физических параметров камеры и т. д., а также нам необходимо знать цель (объект зондирования) Материалы, отражательную способность и другие данные, объем этого проекта огромен - при достаточной рабочей силе срок строительства одного километра сцены занимает около одного месяца.Даже если его можно построить, сложность модели чрезвычайно высока, и ее трудно запустить на физической машине (слишком большая вычислительная мощность)».
«В будущем все симуляции перейдут в облако. Кажется, что вычислительная мощность облака «бесконечна», но когда она распределяется на одну модель одного узла, вычислительная мощность облака может не быть так же хорошо, как и у физической машины — и, при моделировании на физической машине, если вычислительных ресурсов одной машины недостаточно, можно установить три машины, одна отвечает за модель датчика, одна отвечает за динамику , и один отвечает за регулирование и контроль, но запуск симуляции в облаке можно использовать в одной сцене. Вычислительная мощность одной модели не безгранична, поэтому это ограничивает сложность нашей модели».
6. Компаниям, занимающимся моделированием, сложно получить исходные данные датчиков.
Полное моделирование на физическом уровне требует построения различных характеристик датчиков с помощью математических моделей. Например, конкретная производительность приемника сигнала, пути распространения (влияние воздуха в середине, всей связи отражения и преломления) выражается в математических формулах. Однако на этапе, когда программное и аппаратное обеспечение еще не развязаны по-настоящему, алгоритм восприятия внутри сенсора представляет собой черный ящик, и компания-симулятор не может понять, как выглядит алгоритм.
Полное физическое моделирование необходимо для получения основных параметров компонентов датчиков (таких как микросхемы CMOS, ISP) и моделирования этих параметров.Более того, также необходимо знать основные физические принципы датчиков и анализировать лазерные волны лидара и Радары миллиметрового диапазона Моделирование электромагнитных волн.
В связи с этим эксперт по моделированию сказал: «Чтобы хорошо справляться с моделированием датчиков, вы должны иметь глубокое понимание базовых знаний об аппаратном обеспечении датчика, что в основном эквивалентно знанию того, как спроектировать датчик».
Однако поставщики сенсоров, как правило, неохотно раскрывают базовые данные.
Ли Юэ, технический директор Zhixing Zhongwei, сказал: «Если вы получите эти базовые параметры и используете их для моделирования, то вы сможете создать этот датчик».
Ань Хунвэй, генеральный директор Zhixing Zhongwei, сказал: «Обычно, когда OEM-производители имеют дело с поставщиками датчиков, непросто получить протокол интерфейса, не говоря уже о деталях физических параметров материала. Если OEM-производитель достаточно силен, поставщики датчиков тоже активно сотрудничают, и они могут получить протоколы интерфейсов, но не все из них.ОЕМ-производителям еще сложнее получить то, что сложно для компаний-симуляторов».
Фактически моделирование датчиков на физическом уровне может выполняться только самими производителями датчиков. Многие отечественные производители датчиков используют внешние микросхемы и другие компоненты для интеграции, поэтому фактически апстрим-поставщики, такие как TI и NXP, могут имитировать физический уровень датчиков.
Инженер по моделированию компании, занимающейся беспилотным вождением коммерческого транспорта, сказал: «Моделирование датчиков затруднено, что делает процесс выбора датчика очень сложным. Когда мы хотим выбрать датчики, в основном компания, производящая датчики, сначала отправляет мне образцы, а затем мы устанавливаем их. различные типы на автомобиле для тестирования. Если производители датчиков могут сотрудничать с компаниями, занимающимися моделированием, они могут подключить все интерфейсы и обеспечить точное моделирование датчика. Знание информации датчика значительно уменьшит рабочую нагрузку при выборе датчика».
Тем не менее, Бао Шицян, технический директор 51 World, сказал: «Моделирование восприятия все еще находится в зачаточном состоянии, и оно далеко не достигло той стадии, когда моделирование внутри датчика должно быть выполнено так тонко. Я разбираю внутреннюю часть датчика и моделировать эти вещи. Это кажется бессмысленным».
Кроме того, по словам лица, отвечающего за моделирование беспилотного вождения компании, невозможность моделирования датчиков не означает, что моделирование восприятия вообще невозможно.
Например, аппаратное обеспечение в контуре (HIL) может быть подключено к реальным датчикам (датчики и контроллеры домена, оба являются реальными) для тестирования. Подключение к реальному датчику позволяет не только проверить алгоритм восприятия, но и проверить работу и работоспособность самого датчика. В этом режиме датчик является реальным, а точность моделирования выше, чем у моделирования датчика.
Однако, поскольку он включает вспомогательное оборудование, его сложно интегрировать, и этот метод по-прежнему требует модели датчика для управления генерацией сигналов окружающей среды, а стоимость выше, поэтому этот метод редко используется на практике.
Приложение: Два этапа симуляции автономного вождения

(Отрывок из статьи «Введение в виртуальный симуляционный тест автономного вождения», опубликованной официальным аккаунтом «Car Road Slowly» 26 марта 2021 г.)
Учитывая актуальную ситуацию последнего времени, моделирование автономного вождения можно условно разделить на два этапа развития (конечно, эти два этапа могут не иметь четкого временного ограничения).
(1) Этап 1:
Модуль восприятия и идентификации датчика тестируется в лаборатории и на закрытом испытательном полигоне, а модуль управления принятием решений тестируется в среде виртуального моделирования.Среда моделирования непосредственно предоставляет целевой список модулю управления принятием решений.
В основном это связано с тем, что текущее моделирование датчиков имеет много ограничений, которые препятствуют эффективному (или даже правильному) моделированию. Например, изображения, выдаваемые камерой, легче смоделировать, но смоделировать такие характеристики, как пятна и сильный свет, сложнее; а для радара миллиметрового диапазона, если установлена модель с высокой точностью, скорость расчета низкая. , что не может удовлетворить потребности имитационного тестирования.
Полный контроль и регистрация данных об испытательной среде могут осуществляться в лаборатории и на закрытом испытательном полигоне. Например, расположите пешеходов и транспортные средства разных категорий, позиций и скоростей и даже смоделируйте элементы окружающей среды, такие как дождь, снег, туман и яркий свет, и сравните список целей, выводимый обработкой датчика, с реальной средой, чтобы получить результаты оценки модуля распознавания восприятия и рекомендации по улучшению.
Преимущество этого заключается в том, что в случае многих ограничений в моделировании датчиков модуль управления принятием решений все же можно протестировать в среде моделирования и заранее воспользоваться преимуществами тестирования с помощью моделирования.
(2) Второй этап:
Выполните высокоточное моделирование датчиков в среде виртуального моделирования, чтобы протестировать полные алгоритмы автономного вождения.
Таким образом, тестирование может выполняться не только в той же среде, тем самым повышая эффективность тестирования, охват и сложность тестового сценария, но также можно выполнять сквозное тестирование на некоторых алгоритмах на основе ИИ.
Сложность на данном этапе заключается, с одной стороны, в моделировании датчика, отвечающем указанным выше требованиям к испытаниям, а с другой стороны, интерфейсы для прямого взаимодействия между разными производителями датчиков и OEM-производителями могут быть несогласованными (в ряде случаев они может не существовать).
Вопрос 4: Каковы различия между более низким и более высоким уровнями моделирования автономного вождения?
Для этапа автономного вождения низкого уровня симуляция является лишь вспомогательным средством, но когда дело доходит до автономного вождения высокого уровня, симуляция становится барьером для входа — L3 необходимо выполнить достаточное количество симуляций пробега, чтобы выйти на дорогу.
Эксперт по моделированию из OEM-производителя сказал: «Обычно компании, занимающиеся беспилотным вождением, больше способны к моделированию L4, в то время как сторонние компании-симуляторы в основном сосредоточены на моделировании L2. Итак, каковы конкретные различия между двумя фазами моделирования?
1. Функциональные границы
Эксперт по моделированию Цинчжоу Чжихан: «Определение продукта L2 является зрелым, а функциональные границы ясны. Поэтому услуги, предоставляемые поставщиками услуг моделирования для различных OEM-производителей, очень универсальны; и где функциональные границы L4 находятся, все еще исследуют, таким образом, клиенты имеют высокую степень настройки для нужд моделирования».
2. Масштаб библиотеки сцен
Ян Цзыцзян, основатель Kechuang: «С точки зрения тестовых сценариев, из-за более высокой сложности ODD в L4, порядок библиотеки сцен намного выше, чем у L2».
3. Требования к воспроизведению сцены
Эксперт по моделированию OEM-производителя сказал: «Моделирование L4 предъявляет более высокие требования к воспроизводимости сцены, то есть может ли проблема, обнаруженная в дороге, быть воспроизведена в среде моделирования; но многие компании, занимающиеся моделированием L2, не задумывались об этом». ."
4. Внимание к возможностям интеллектуального анализа данных
Для низкоуровневой симуляции автономного вождения все в основном борются за аутентичность сцены, в то время как автономное вождение высокого уровня уделяет больше внимания интеллектуальному анализу данных.
5. Состав данных
Бао Шицян, ответственный за моделирование транспортных средств в 51 WORLD: «L2 имеет относительно четкое определение функций, и моделирование может быть в основном основано на синтетических данных, дополненных реальными дорожными данными; а на этапе L4 важность data-driven будет выше. Поэтому необходимо в основном основываться на реальных дорожных данных, дополненных данными, сгенерированными алгоритмами».
6. Восприятие
Автономные транспортные средства высокого уровня имеют большое количество камер и высокие пиксели, что выдвигает более высокие требования к способности рендеринга изображений, возможности синхронизации данных и стабильности механизма моделирования системы моделирования.
7. HD-карта
Ли Юэ, технический директор Zhixing Zhongwei: «По сути, автономное вождение низкого уровня не требует высокоточных карт, но автономное вождение высокого уровня на текущем этапе сильно зависит от высокоточных карт, что является одной из причин, почему при построении сцены необходимо построить цифрового двойника, по сравнению с реальным миром».
8. Принятие решений
Ли Юэ, технический директор Zhixing Zhongwei: «План L2 уделяет больше внимания стратегической логике принятия решений и тестированию исполнительного органа, но не фокусируется на алгоритме планирования. Однако в плане L4, как избежать препятствия и способы их обхода. В алгоритмах планирования пути есть и другие факторы, такие как дороги».
9. Требуется ли модель водителя?
Для низкоуровневого автоматического вождения система не будет полностью контролировать поведение транспортного средства, а будет играть только вспомогательную роль.Поэтому компаниям-симуляторам необходимо проектировать множество моделей водителей при проектировании сцены;сказал, что управление транспортным средством реализуется посредством автоматического вождения , следовательно, нет необходимости проектировать модель водителя в дизайне сцены моделирования.
10. Настраивать ли процесс тестирования заранее
По поводу этой логики паблик-аккаунт «Car Road Slowly» более подробно объяснил в статье:
Сложность и диапазон рабочих условий, с которыми сталкивается автоматическое вождение более низкого уровня, относительно невелики, или, поскольку поведение вождения в основном зависит от водителей-людей, системе автоматического вождения необходимо иметь дело только с ограниченным числом определенных рабочих условий. Автоматическое вождение высокого уровня в основном отвечает за систему автоматического вождения, а сложность и диапазон рабочих условий, с которыми она справляется, очень велики, и ее даже нельзя предсказать заранее.
Основываясь на этой разнице между ними, автономное вождение более низкого уровня может быть лучше протестировано с использованием методов тестирования, основанных на сценариях использования, в то время как автономное вождение более высокого уровня требует методов тестирования, основанных на сценариях.
Метод тестирования, основанный на сценарии использования, заключается в предварительном задании входных данных теста и процесса тестирования, а также оценке того, пройден ли тест, путем проверки того, достигает ли тестируемый алгоритм ожидаемой функции. Например, при испытании ACC задается начальная скорость испытуемого автомобиля и впереди идущего автомобиля, а также время замедления и замедления впереди идущего автомобиля и проверяется, может ли тестируемый автомобиль следовать за замедлением. остановиться.
Метод тестирования, основанный на сценариях, заключается в предварительном задании тестового входа , но не предварительно устанавливает процесс тестирования, а только устанавливает поведение транспортных средств, дает тестируемому алгоритму большую степень свободы и проверяет, достигает ли тестируемый алгоритм ожидаемых результатов. Цель Оценить, пройти ли тест . Например, при испытании на прямолинейное движение заранее задаются начальная скорость испытуемого автомобиля и впереди идущего автомобиля, а также время замедления и замедления впереди идущего автомобиля, но не ограничивается тем, находится ли автомобиль под Тест позволяет избежать столкновения с впереди идущим автомобилем путем замедления или смены полосы движения.
Одной из причин использования разных методов тестирования для разных уровней функций автоматического вождения является то, что низкоуровневое автоматическое вождение, как правило, можно разложить на простые и независимые функции, а в качестве объекта тестирования можно использовать одну функцию, в то время как автоматическое вождение высокого уровня вождение сложнее, трудно разложить на простые и независимые функции, поэтому в качестве объекта тестирования приходится брать всю систему автоматического вождения или относительно большую ее часть.
11. Промышленная экология
Ян Цзыцзян, основатель Kechuang: «С точки зрения промышленной экологии, для L2 автомобильные компании в основном не будут проводить собственные исследования, а будут напрямую внедрять аутсорсинговые решения, а тест будет основан на HIL или даже на дорожных испытаниях; для моделирование L4. Многие автомобильные компании склонны начинать свои собственные исследования с SIL».
Вопрос 5: Как понимать «тысячи километров в день» в симуляции?
Подобно реальным дорожным испытаниям, некоторые компании-симуляторы также подчеркивают «пробег», например, «сотни тысяч километров в день», так что же на самом деле означает это число? Как это соотносится с пробегом на реальных дорогах?
Виртуальный пробег относится к сумме пробегов массивной платформы моделирования в параллельных узлах моделирования в единицу времени. Пробег симуляции в единицу времени зависит от количества узлов, поддерживаемых вычислительной мощностью всей платформы, и индекса сверхреального времени при различной сложности сцен симуляции.
Проще говоря, узел моделирования — это транспортное средство, то есть, сколько «тестовых транспортных средств» платформа моделирования может поддерживать при параллельной работе в одно и то же время.
По словам Ан Хунвэя, генерального директора Zhixing Zhongwei, он пояснил: «Проще говоря, если платформа моделирования имеет вычислительную мощность 100 серверов GPU, и каждый из них развертывает 8 экземпляров моделирования, то платформа моделирования имеет возможность распараллелить 800 моделирования одновременно. в то же время. Пробег симуляции зависит от ежедневного пробега каждого экземпляра.
Сколько экземпляров может работать на сервере GPU , зависит от производительности GPU и от того, можно ли параллельно моделировать решатель моделирования на сервере .
Ан Хунвэй сказал: «В узлах моделирования нашей платформы облачного моделирования реализовано множество методов развертывания, которые могут гибко соответствовать условиям различных облачных ресурсов клиентов и могут обеспечить крупномасштабное и гибкое развертывание узлов. В настоящее время мы строим в Сянчэн, Сучжоу. Его платформа облачного моделирования позволила развернуть более 400 узлов».
В сочетании с ежедневным пробегом каждого экземпляра можно приблизительно рассчитать общий ежедневный пробег моделирования на платформе моделирования. Если один экземпляр (виртуальный автомобиль) проходит в среднем 120 километров в час и работает 24 часа в сутки, то это почти 3000 километров в сутки, если 33 экземпляра, то на этом сервере почти 100 000 километров в сутки.
Однако, по словам Ань Хунвэя, моделирование «тысячи тысяч километров в день», на которое обычно ссылается отрасль, не очень строгое. « Это должно поддерживаться разумным планом испытаний моделирования и большим количеством сценариев, а охват и эффективность сценариев должны постоянно расширяться. Наконец, эффективные сценарии, которые могут быть исчерпаны, имеют основополагающее значение» .
Вопрос 6: Моделирование в суперреальном времени
Во время интервью автор неоднократно задавал вопрос: автомобили, работающие на симуляционной платформе, находятся в том же временном измерении, что и автомобили в реальном мире? Иными словами: равен ли 1 час на симуляционной платформе 1 часу в реальном мире? Будет ли ситуация «один год на земле, десять лет на небе»?
Ответ таков: он может быть равен (симуляция в реальном времени) или не равен (симуляция в суперреальном времени). Моделирование в сверхреальном времени можно разделить на два случая: «ускорение времени» и «замедление времени» — ускорение времени означает, что время на платформе моделирования быстрее, чем время в реальном мире, а замедление времени означает, что время на платформе моделирования медленнее, чем в реальном мире.
Моделирование быстрее, чем реальное время для эффективности, так почему же оно медленнее , чем реальное время ?
Объяснение Хунвэя: «Например, некоторые симуляционные тесты требуют очень высокой точности рендеринга изображения. Чтобы добиться точности, рендеринг одного кадра изображения может не выполняться в реальном времени. Такой вид симуляции медленнее реального время, вместо тестирования в реальном времени с обратной связью, оно проводит тестирование в автономном режиме».
В частности, при моделировании в реальном времени после создания изображения оно напрямую отправляется алгоритму для распознавания.Этот процесс может быть завершен в течение 100 миллисекунд, но при моделировании в автономном режиме изображение сначала сохраняется после генерации и отправляется в алгоритм в оффлайн условиях.
Согласно объяснению Ан Хунвэя, для моделирования в сверхреальном времени на платформе моделирования необходимо выполнить следующие два условия: вычислительные ресурсы сервера достаточно мощные, тестируемый алгоритм может получать виртуальное время.
Алгоритмы могут принимать виртуальное время, как вы это понимаете? Объяснение Хунвэя заключается в том, что некоторым алгоритмам может потребоваться считывание службы времени на оборудовании или службы времени в сети при условии объединения аппаратной платформы, но они не могут считывать виртуальное время, предоставленное системой моделирования.
Эксперт по моделированию уровня 1 сказал: Точное выравнивание и синхронизация времени могут быть достигнуты в инженерной структуре системы моделирования PoseidonOS, а затем алгоритм может быть развернут на кластерных серверах, чтобы время в пространстве моделирования можно было отделить от времени. в реальном физическом мире.Как только вы развяжете его, вы сможете «ускоряться по желанию».
Итак, делая ускорение времени, можно ли его ускорить в 2 раза или в 3 раза, от чего зависит этот коэффициент ускорения?
Ответ Хунвэя: вычислительные ресурсы сервера, сложность тестового сценария, сложность алгоритма и эффективность работы алгоритма. То есть, теоретически, в условиях одинаковой сложности сцены и одного и того же алгоритма, чем мощнее вычислительные ресурсы сервера, тем большее возможное время ускорения может быть достигнуто.
Каков верхний предел кратного ускорения времени? Мы должны объединить принцип ускорения времени, чтобы ответить на этот вопрос.
По словам лица, ответственного за моделирование компании автономного вождения, из-за несоответствия сложности алгоритма и других причин скорость расчета модуля обучения, модуля управления транспортным средством и других модулей отличается, и наиболее традиционный метод супер реального времени заключается в использовании расчета каждого модуля, участвующего в расчете.У единого планирования. Так называемое ускорение означает, что модуль с более высокой скоростью расчета "отменяет время ожидания" - неважно, если вы еще не закончили расчет другого модуля, я синхронизирую, когда время истечет.
Если разница в периоде расчета между модулями слишком мала, время ожидания отмены очень мало, поэтому коэффициент ускорения будет очень низким; с другой стороны, если разница в периоде расчета каждого модуля особенно велика, например , это занимает 1 секунду, а другой занимает 100 секунд, поэтому нет возможности «отменить ожидание».
Поэтому кратность ускорения времени часто ограничивается - 2-3 раза считается очень высоким.
Даже многие эксперты говорили, что на практике действительно ускорить время сложно.
Ян Цзыцзян, основатель Shenxin Kechuang, сказал, что если алгоритм системы автоматического вождения был скомпилирован и развернут на контроллере домена или промышленном компьютере (это имеет место на этапе HIL), он может работать в режиме реального времени только в система моделирования—— В настоящее время моделирование в суперреальном времени невозможно.
Хунвэй также сказал: «Аппаратное обеспечение в цикле (HIL, моделирование аппаратного обеспечения в цикле) само по себе должно быть моделированием в реальном времени. параллельное моделирование» или «ускорение времени» неприменимы».
Бао Шицян сказал: «Предпосылкой ускорения времени является точный контроль времени и синхронизация времени. Ускорить восприятие сложно, потому что частоты разных датчиков разные. Камера может работать на частоте 30 Гц, а лидар — на 10 Гц, подобно это, как вы гарантируете, что сигналы от разных датчиков могут быть строго синхронизированы?»
Кроме того, эксперт по моделированию, много лет проработавший в Силиконовой долине, считает, что ни одна компания не может по-настоящему добиться моделирования в сверхреальном времени. По мнению этого эксперта, для повышения эффективности моделирования более желательным решением является массово-параллельное моделирование.
Хунвэй считает, что возможность ускорения времени зависит от уровня сверхреального времени каждого экземпляра, общего количества экземпляров и качества сцены. «На самом деле, для моделирования мощности облачных вычислений уровень ультра-реального времени на одном экземпляре не очень важен. Главное — сосредоточиться на качестве моделирования на этом экземпляре».
Эксперты по моделированию Цинчжоу Чжихан даже считают, что термин «множественное ускорение» на самом деле не соответствует действительности. Потому что между временем в симуляции и временем в реальном мире нет простой множественной связи, у них даже нет связи. На практике используется больше технических средств для уменьшения занимаемой вычислительной мощности и повышения эффективности планирования времени для достижения улучшения времени вычислений.
В реальных дорожных испытаниях транспортное средство движется постоянно. Вы бы не сказали, что это угловой случай. Я прогоню его. Это не угловой случай. угловой случай; на платформе моделирования инженеры обычно фиксируют только те фрагменты, которые связаны с угловой случай (то есть «эффективные сцены»).После обработки этого вопроса часы перейдут к следующему периоду времени без необходимости тратить время на сцену.
Поэтому при моделировании более важно, как эффективно отсеивать эффективные сценарии, чем фактор ускорения времени.
Говоря об этом, мы можем обнаружить, что хотя ускорение времени не кажется очевидным, но для увеличения виртуального пробега на платформе моделирования на самом деле мы не можем в основном полагаться на ускорение времени.Ключ должен полагаться на «многоэкземплярный параллелизм», который фактически предназначен для моделирования вычислительной мощности облачных вычислений и увеличения количества серверов и экземпляров моделирования .
Вопрос 7: Крупномасштабное параллельное тестирование
Может ли он поддерживать высокую степень параллелизма в облаке и насколько масштабен параллелизм? Достаточно ли просто полагаться на серверы кучи?
Звучит правильно, но проблема в том, что каждый порядок увеличения размера сервера приносит новые проблемы -
(1) Стоимость серверов довольно высока.Каждый сервер-сотни тысяч.Если есть 100 серверов-прямая стоимость-десятки миллионов.Идеальное решение-уйти в общедоступное облако,но отечественным OEM-производителям все же нужно принять общедоступное облако период времени;
(2) В случае крупномасштабного параллелизма необработанные данные датчика чрезвычайно велики.Стоимость хранения этих данных очень высока, а передача также затруднена - синхронизация данных на разных серверах вызовет задержки, что повлияет на эффективность Zhixing;
(3) На каждой дороге проходит не непрерывная сцена транспортного потока, а очень короткий сегмент, может быть, всего 30 секунд, но обычно тысячи дорог проходят параллельно, если 1000 дорог имеют 1000 алгоритмов, работающих на 1000 сцен, что создает серьезный вызов архитектуре платформы моделирования. (генеральный директор симуляционной компании)
Однако, что касается последнего пункта выше, Ань Хунвэй сказал: "Это основное требование для моделирования мощности облачных вычислений, и это не проблема для нас. Платформа облачного моделирования в районе Сянчэн, Сучжоу, решила эту проблему еще в 2019 году". Кроме того, сцены, запущенные на платформе облачного моделирования, также будут иметь несколько километров непрерывных сложных/комбинированных сцен.Система оценки моделирования Robo-X компании Xiangcheng включает такие (групповые) сцены. На основе таких сценариев можно провести тест «поглощения» в условиях виртуального моделирования.
Вопрос 8: Какой показатель является наиболее важным для измерения возможностей моделирования в компании?
На текущем этапе симуляции разных компаний сильно отличаются от цепочки инструментов до используемых данных сцены, от методологии до источника данных. Все говорят о «симуляции», но они не обязательно говорят об одном и том же понятии. Итак, каковы наиболее важные показатели для измерения возможностей компании в области моделирования? После этого раунда интервью мы получили следующие ответы:
1. Воспроизводимость
То есть, могут ли проблемы, обнаруженные в реальных дорожных испытаниях, быть воспроизведены в среде моделирования. (Умное плавание на легких лодках, умное путешествие в конце дня)
Подробнее этот вопрос будет рассмотрен во второй половине статьи.
2. Возможность определения сцены
То есть, действительно ли сценарий моделирования, определенный компанией, может помочь улучшить фактическую пропускную способность автономного вождения.
3. Возможность сбора данных сцены
Сбор данных сцены, производственная мощность, универсальность данных и возможность повторного использования.
4. Качество и количество данных сцены
То есть, насколько сцена моделирования близка к реальной сцене, точность, достоверность и свежесть данных сцены, а также количество действительных сцен, а также достаточно ли массивных данных сцены моделирования для поддержки параллельного моделирования с несколькими экземплярами.
5. Эффективность моделирования
То есть, как автоматизировать и эффективно проводить интеллектуальный анализ данных для создания модели среды, необходимой для моделирования, чтобы быстро найти реальные проблемы.
6. Техническая архитектура
То есть имеется ли полная техническая замкнутая система, подходящая для нужд испытуемого объекта. (ИАЭ Чжисин Чжунвэй Ли Юэ)
7. Есть ли у него возможность крупномасштабного параллельного тестирования
Только в крупномасштабном тесте (количество экземпляров и сценариев достаточно велико) компания может построить систему оценки точности модели, стабильности системы и т. д., которая проверяет управление данными компании, интеллектуальный анализ данных, планирование ресурсов и другие. возможности. (Цинчжоу Чжихан)
8. Точность моделирования
Моделирование, ориентированное на регулирование, и моделирование, ориентированное на восприятие, имеют разные требования к точности: первое может зависеть от модели динамики транспортного средства, существующих уровней абстракции и детализации поведения помех в транспортном потоке; последнее может зависеть от разных датчиков на основе шума. добавленные различными принципами изображения и т.д.
Обычно из соображений стоимости пользователи надеются, что техническую архитектуру можно будет использовать повсеместно. Однако чрезмерно общее решение приведет к потере точности в некоторых аспектах — точность модели, эффективность модели и универсальность модели представляют собой треугольные отношения.
Что касается достоверности данных симуляции, то нужно добавить еще один вопрос: MANA ввела в систему симуляции сценарии реальных транспортных потоков, реальный транспортный поток в каждый момент времени записывается, а затем через log2world импортируется в движок симуляции. После добавления модели водителя ее можно использовать для отладки и проверки сцены перекрестка. Итак, как гарантировать точность такого рода данных?
В связи с этим эксперт по моделированию в Momo сказал: «В настоящее время такого рода данные в основном используются для разработки и тестирования когнитивных модулей, поэтому нам нужно максимально реалистичное динамическое поведение трафика. Сами данные дискретизированы для непрерывный мир. , пока частота сбора соответствует потребностям вычислений когнитивного алгоритма, нам не нужно сравнивать эти данные с истинным значением (и нет никакого способа получить значение абсолютной истины). Проще говоря, что мы преследуем рациональность действия и разнообразие, а не точность».
9. Согласованность между имитационным испытанием и испытанием на реальном транспортном средстве.
Инженер-симулятор из компании, занимающейся беспилотным вождением коммерческих транспортных средств, сказал, что они часто обнаруживали, что результаты теста SIL были противоположны результатам реального дорожного теста: в реальных дорожных испытаниях не было проблем, но были проблемы в SIL. ; и были проблемы в реальных дорожных испытаниях.Проблемный сценарий, но нет проблем в SIL.
Человек, отвечающий за моделирование автономного вождения OEM-производителя, сказал, что, когда они проводили тесты HIL, они обнаружили, что характеристики автомобиля в сцене моделирования более или менее отличались от его характеристик на реальной дороге. Причинами такой разницы могут быть: (1) виртуальный датчик, EPS и т. д. не полностью соответствуют реальному транспортному средству, (2) виртуальная сцена не полностью соответствует реальной, (3) стандарт динамики автомобиля Не могу сделать это правильно.
10. Роль имитационного моделирования в системе НИОКР компании.
Степень проникновения моделирования в реальный бизнес, то есть доля данных моделирования во всех данных об использовании бизнеса в процессе НИОКР, а также используется ли моделирование в качестве основного инструмента для НИОКР и тестирования. (Эксперт по миллиметровому моделированию)
1 1. Создавать ли коммерческий замкнутый цикл
Эксперт по моделированию из компании, занимающейся беспилотным вождением, сказал: «Для компании, занимающейся моделированием, важнее взять на себя инициативу в создании коммерческого замкнутого цикла, чем преимущества самой технологии».
Бао Шицян, руководитель отдела моделирования транспортных средств в 51 World, сказал, что основные моменты, на которые клиенты обращают внимание при выборе поставщика моделирования: A. Достаточно ли совершенен модуль моделирования? B. Какой набор инструментов вы можете ему предоставить. C. Открытость платформы моделирования.
Говоря об открытости, Бао Шицян сказал: «Общая тенденция такова, что пользователи не хотят напрямую покупать программное обеспечение для решения конкретной проблемы, а хотят создавать свою собственную платформу. Поэтому они предпочитают имитировать технические модули поставщика. дать им возможность создавать свои собственные платформы моделирования.Поэтому поставщики моделирования должны подумать о том, как проектировать API-интерфейсы, как интегрироваться с существующими модулями клиентов и даже открывать часть кода для клиентов».
Приложение: Как улучшить воспроизводимость сцены
«Может ли проблема, обнаруженная на дороге, быть воспроизведена в среде моделирования», рассматривается такими компаниями, как Qingzhou Zhihang, как один из наиболее важных показателей для измерения силы возможностей моделирования компании. Итак, какие факторы будут влиять на воспроизводимость сцены?
Имея в виду этот вопрос, автор неоднократно опрашивал многих экспертов и получил следующие ответы:
1. Модель автомобиля, модель датчика, модель дороги и модель погоды могут отличаться от реальной ситуации.
2. Критерии оценки облака и автомобиля могут не совпадать.
3. Время связи и время планирования в моделирующей системе не соответствуют времени на реальном транспортном средстве. Например, при получении сообщения, если вы случайно получите кадр раньше или кадр позже, и, наконец, под эффектом бабочки, разница будет очень большой.
4. Параметры управления транспортным средством в системе моделирования не соответствуют реальному транспортному средству. В реальных испытаниях автомобиля акселератор, тормоз, рулевое колесо и шины существуют в физической форме, но в системе моделирования таких физических компонентов нет, поэтому можно использовать только методы моделирования. обработаны хорошо, реализм симуляции будет скомпрометирован.
5. Данные сцены в системе моделирования неполные. При моделировании мы можем захватить только определенный сегмент сцены, например, данные за несколько секунд до и после светофора недоступны.
6. Проблема может быть покрыта логическим языком, описывающим среду, а уровень и охват языкового определения могут быть несовершенными.
7. Адаптивность самого программного обеспечения для моделирования к различным сценариям недостаточно хороша, переключение между языками не является плавным, и трудно поддерживать крупномасштабную многоузловую работу.
8. Данные на реальной дороге имеют много переменных.При моделировании, чтобы найти проблемы как можно скорее, инженеры должны «предполагать», что определенные параметры остаются неизменными, чтобы уменьшить влияние на ключевую переменную.
9. Последовательность вычислений между модулями восприятия, предсказания, позиционирования и другими модулями автономного вождения может быть разной в облаке и на стороне автомобиля, или сторона автомобиля может не строго записывать определенную информацию — пока есть один кадр. привести к проблемам с одним результатом.
10. Если это проблема на уровне восприятия, при воспроизведении сцены необходимо добиться лучшего обратного создания 3D-сцены, а затем дополнить данные путем обобщения и преобразования перспективы.Каждый шаг здесь немного сложен. Если это проблема на нормативном уровне, для точного воспроизведения сцены необходимо определить поведение взаимодействия и ключевые параметры сцены, чтобы точно сгенерировать и запустить сцену. (Я твердо верю в Ян Цзыцзяна, основателя Кэчуана)
Сценарий запуска относится к тому, реализовано ли содержимое, которое этот сценарий хочет протестировать. Например, если пешеход вдруг перейдёт дорогу перед основным автомобилем, если перед выездом основной автомобиль проедет мимо пешехода, то тестовый эффект не будет достигнут, то есть сцена не сработает. Например, если пешеход переходит дорогу, а затем поворачивает назад, критичными являются скорость ходьбы, время поворота и скорость основного транспортного средства — это один человек на велосипеде. Участники мультитрафика намного сложнее, и отношения между ними связаны, и даже при незначительном отклонении параметра эффект от моделирования будет сильно снижен.
При написании этой статьи было процитировано много информации о галантерейных товарах из общедоступного аккаунта WeChat «Car Road Slowly». Автор официальной учетной записи, Li Slowly, инженер-симулятор, Эта учетная запись посвящена изучению опыта моделирования и рекомендует друзьям, которые заинтересованы в этом направлении, следовать им.

Использованная литература:
Супер-всеобъемлющий обзор моделирования автономного вождения: от сценариев моделирования, систем к оценке
https://zhuanlan.zhihu.com/p/321771761
Рекомендуемое чтение:
напиши в конце
О вкладе
Если вы заинтересованы в том, чтобы внести свой вклад в «Девять глав умного вождения» (статьи типа «накопление и сортировка знаний»), отсканируйте QR-код справа и добавьте сотрудников WeChat.

Примечание. Не забудьте указать свое настоящее имя, компанию и текущую должность при добавлении WeChat.
И информация о позиции интереса, спасибо!
Требования к качеству рукописей «накопления знаний»:
О: Плотность информации выше, чем в большинстве отчетов большинства брокерских контор, и не ниже среднего уровня «Умного вождения девяти глав»;
B: Информация должна быть очень скудной, и более 80% информации должно быть невидимо для других средств массовой информации.Если она основана на общедоступной информации, она должна иметь особенно мощную и исключительную точку зрения. Спасибо за ваше понимание и поддержку.
Рекомендуемое чтение:
◆ Девять глав - сборник статей 2022 года
◆Посвящается «первому городу автономного вождения» — «движущейся столице».
◆ Радар миллиметрового диапазона 4D четко объясняется в подробном тексте 4D
◆ Применение алгоритма глубокого обучения в автоматическом регулировании и управлении вождением
◆ «Будь жадным, когда другие боятся», этот фонд увеличит инвестиции в «Автоматическое вождение зимой».