Каталог статей
Рамки
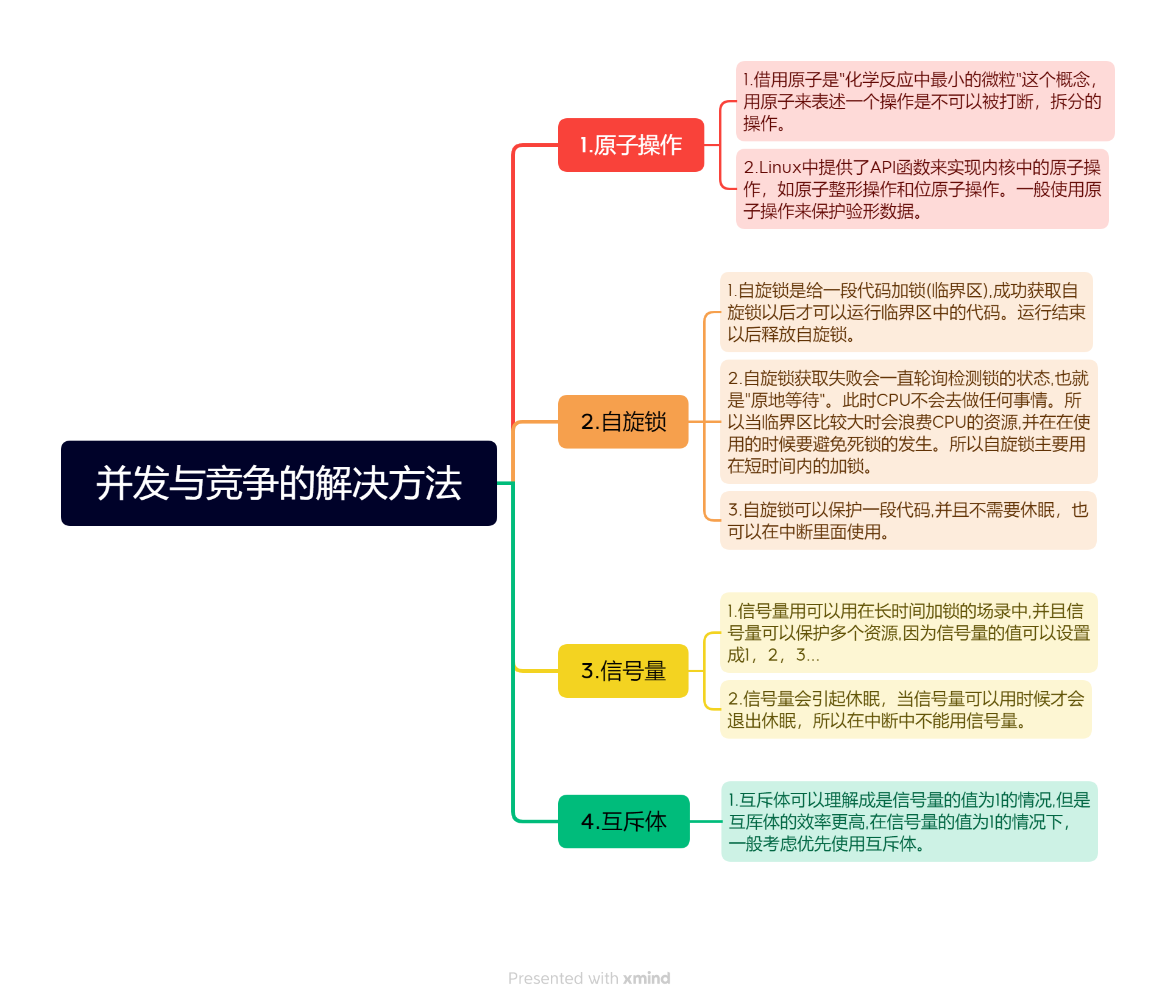
Что такое параллелизм и конкуренция?
Параллелизм приведет к одновременному доступу нескольких программ к общему ресурсу.В настоящее время проблемой, вызванной одновременным доступом к общему ресурсу, является конкуренция. Например, A и B хотят позвонить по телефону, но есть только один общественный телефон. Если A и B хотят позвонить, это параллелизм, и кто бы ни позвонил первым, это конкуренция. Но телефоном может пользоваться любой, поэтому телефон является общим ресурсом.
LinuxЭто многозадачная операционная система, где параллелизм и конкуренция Linuxочень распространены. Поэтому в процессе написания Linuxдрайверов необходимо учитывать параллелизм и конкуренцию. В противном случае могут возникнуть проблемы при доступе к общим ресурсам, и эти проблемы часто нелегко устранить и найти.
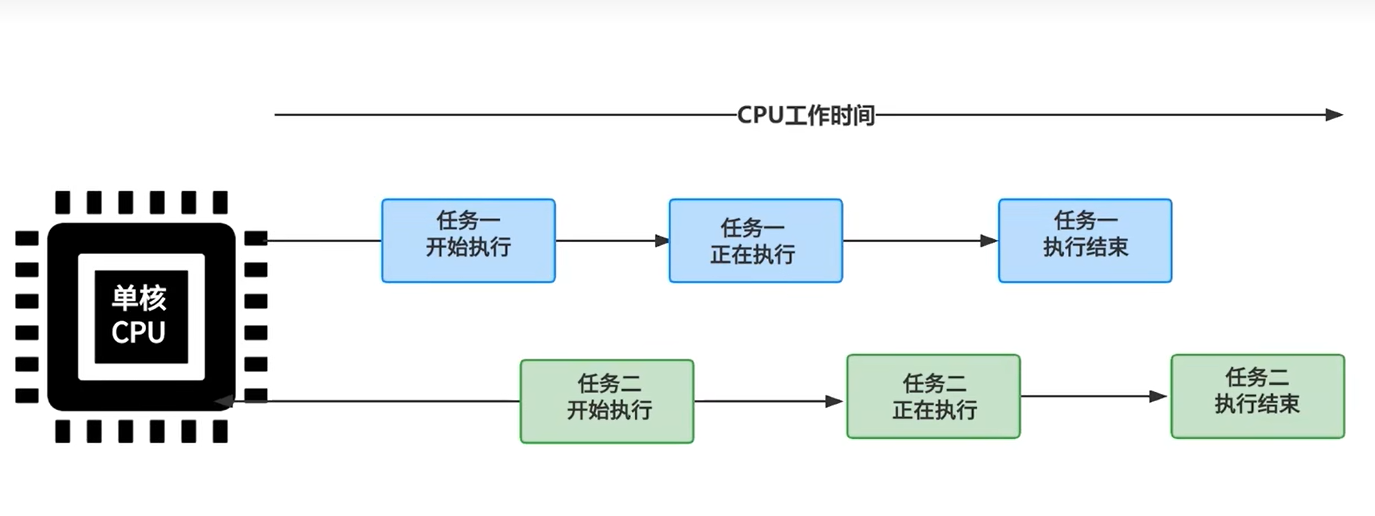
Параллелизм : назначайте задачи процессорам в разные моменты времени для обработки. В один и тот же момент времени задачи не выполняются одновременно.
Параллелизм : назначьте каждую задачу каждому процессору для независимого выполнения. В один и тот же момент времени задачи должны выполняться одновременно.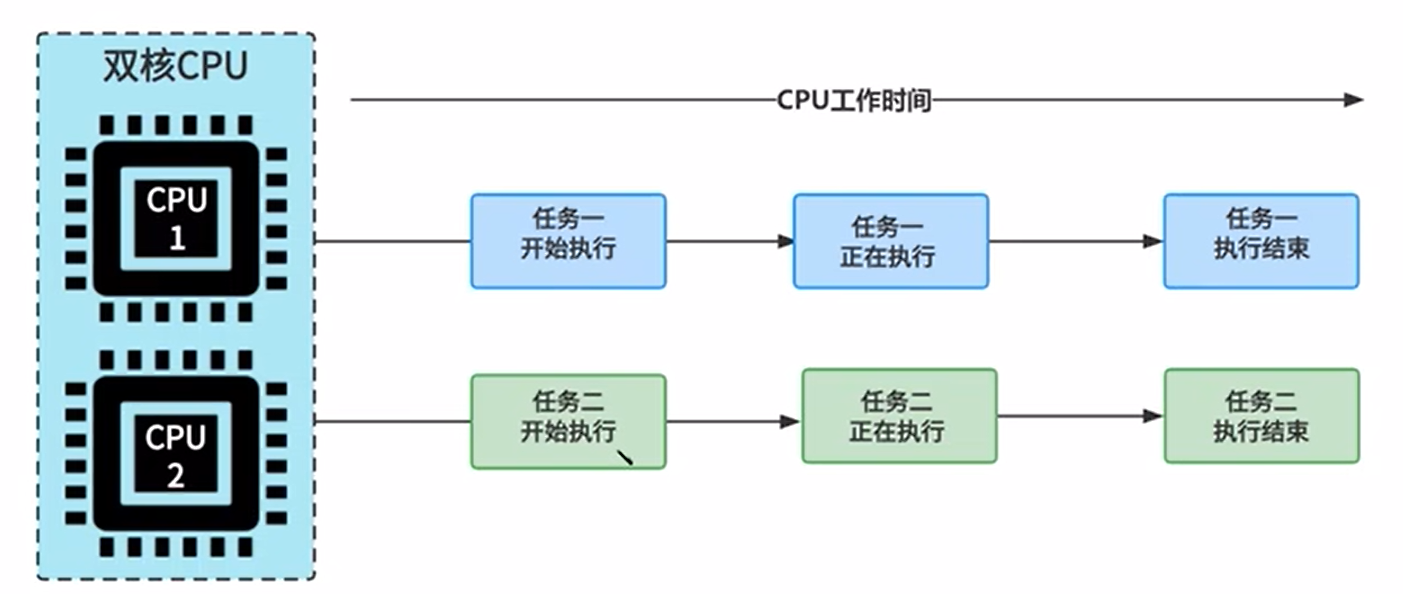
Что произойдет, если вы не справитесь с параллелизмом?
Здесь мы обсуждаем параллелизм в пространстве ядра, а не параллелизм в пространстве пользователя.Теперь есть два идентичных драйвера A и B, эти два драйвера выполняются одновременно, и они оба модифицируют переменную c.
Дело 1:
Сначала запускается программа A, заканчивает выполнение программа A, а затем запускается программа B, что является идеальной ситуацией. Программа А и программа Б работают без ошибок.
Случай 2:
Программа A выполняется наполовину, и ядро планирует выполнение программы B. После завершения выполнения программы B оно возвращается к выполнению программы A. Но эквивалентна ли программа B бездействию после выполнения программы A? Значение переменной c равно значению программы A.
Ситуация 1 — идеальная ситуация, но мы не можем предсказать, как вообще будут работать программа А и программа Б. Если вы не защитите свои коворкинг-ресурсы. Как минимум, программа запускается один раз зря, а в худшем случае происходит сбой системы.
При каких обстоятельствах Linux вызывает параллелизм?
В основном это следующие ситуации:
- Прервите одновременный доступ к программе. Прерывание может быть сгенерировано в любое время.После прерывания оно отложит работу и выполнит прерванную задачу.Если общий ресурс будет изменен во время выполнения прерванной задачи, возникнут непредвиденные проблемы.
- Упреждающий одновременный доступ. После версии
Linuxядра ядро поддерживает вытеснение.Когда вытеснение поддерживается, исполняемый процесс может быть вытеснен в любое время.2.6Linux - Многопроцессорный
(SMP)одновременный доступ. Межъядерный одновременный доступ существует между многоядерными процессорами.
Что защитить от параллелизма?
Небезопасно, чтобы процессы (запущенная программа — это процесс) одновременно обращались к общим ресурсам.Если два процесса обращаются к пространственным ресурсам одновременно, возникнет конкуренция. Итак, мы должны защищать общие ресурсы.Что такое общие ресурсы? В реальной жизни общими ресурсами могут быть общественные телефоны, общие велосипеды, общие зарядные устройства и т. д. в нашей повседневной жизни. Это общие ресурсы.
В коде общий ресурс — это целочисленная глобальная переменная или структура устройства в драйвере. Конечно, другие данные также могут быть общими данными, которые необходимо анализировать в соответствии с реальной программой драйвера.
Как бороться с параллелизмом и конкуренцией
При написании драйвера мы должны стараться избегать параллелизма и конкуренции в драйвере.Ядро Linuxпредоставляет нам несколько методов для борьбы с параллелизмом и конкуренцией, а именно: атомарные операции, спин-блокировки, семафоры и мьютексы .
атомарная операция
Что такое атомарные операции?
«Атом» в атомных операциях относится к мельчайшей частице в химической реакции. Использование Linuxатомов для описания операции или функции является наименьшей единицей выполнения и не может быть прервано. Таким образом, атомарная операция означает, что операция не будет прервана ничем до ее выполнения.
Применение атомарных операций
Атомарные операции обычно используются для защиты целочисленных переменных или битов. По сравнению со мной мы определяем переменную а. Если программа А присваивает значение переменной а, программа Б также будет оперировать переменной а в это время, и в это время будет происходить параллелизм и конкуренция. Работа программы А может быть прервана программой В. Если мы используем атомарные операции для защиты переменной a, мы можем избежать этой проблемы.
Описание атомарной целочисленной переменной
Linuxопределяет структуру , называемую atomic_tи для описания атомарных переменных, которые используются в 32-битных системах, а atomic64_t используется в 64-битных системах. Код выглядит следующим образом:atomic64_tatomic_t
typedef struct {
int counter;
} atomic_t;
#ifdef CONFIG_64BIT
typedef struct {
long counter;
} atomic64_t;
#endif
API-функция атомарного формирования (32-разрядная версия)
64Бит состоит в том, чтобы заменить все следующие атомарные слова наatomic64
головной файлlinux/atomic.h,asm/atomic.h
| атомарные целочисленные операции | описывать |
|---|---|
| ATOMIC_INIT (целое число) | При объявлении переменной atomic_t инициализируйте ее значением i |
| int atomic_read (atomic_t * v) | Атомарно читает целочисленную переменную v |
| пустота atomic_set (atomic_t * v, int i) | Атомарно устанавливает v в i |
| пустота atomic_add (int i, atomic_t * v) | добавить i к v атомарно |
| пустота atomic_sub (int i,atomic_t * v) | Атомарно вычесть i из v |
| пустота atomic_inc (atomic_t * v) | Атомарно увеличить v на 1 |
| пустота atomic_dec (atomic_t * v) | Атомарно вычесть 1 из v |
| int atomic_sub_and_test (int i, atomic_t * v) | Атомарно вычитает i из v и возвращает true, если результат равен o; в противном случае false |
| int atomic_add_negative (int i, atomic_t * v) | Атомарно добавляет i к v, возвращает true, если результат отрицательный, иначе возвращает false |
| int atomic_add_return (int i, atomic_t * v) | Атомарно добавляет i к v и возвращает результат |
| int atomic_sub_return (int i, atomic_t * v) | Атомарно вычитает i из v и возвращает результат |
| int atomic_inc_return (int i, atomic_t * v) | атомарно увеличить v и вернуть результат |
| int atomic_dec_return (int i, atomic_t * v) | Атомарно вычитает 1 из v. и возвращает результат |
| int atomic_dec_and_test (atomic_t * v) | Атомарно вычитает 1 из v и возвращает true, если результат равен 0; иначе false |
| int atomic_inc_and_test (atomic_t * v) | Атомарно добавляет 1 к v, возвращает true, если результат равен 0; в противном случае возвращает false |
Примеры атомарных операций
atomic64_t v=ATOMIC64_INIT(O);//定义并初始化原子变量v=o
atomic64_set(&v,1);//设置v=1
atomic64_read(&v);//读取v的值,此时v的值是1
atomic64_inc(&v);//v的值加1,此时v的值是2
API-функции для работы с атомарными битами
API-функции атомарных операций с битами
В дополнение к операциям с атомарными целыми числами ядро также предоставляет набор функций операций с битами, которые работают с обычными адресами памяти, а параметрами являются указатель и номер бита.
| атомарные битовые операции | описывать |
|---|---|
| недействительным set_bit (int nrvoid * адрес) | Атомарно устанавливает номер бита объекта, на который указывает addr |
| недействительным clear_bit (интервал номер, недействительным * адрес) | Атомарно очищает номер бита объекта, на который указывает адрес |
| недействительное изменение bti (int nrvoid * адрес) | Атомарно переворачивает n-ые биты объекта, на который указывает addr |
| int test_and _set бит (int nrvoid *addr) | Атомарно устанавливает n-й бит объекта, на который указывает addr, и возвращает исходное значение |
| int проверить и очистить _bit (int nr, void *addr) | Атомарно очищает n-ые биты объекта, на который указывает addr, и возвращает исходное значение |
| int проверить и изменить бит (int nr, void *addr) | Атомарно переворачивает n-ые биты объекта, на который указывает addr, и возвращает исходное значение |
| бит проверки int (int nrvoid * адрес) | Атомарно возвращает n-й бит объекта, на который указывает адрес |
пример
usr.c
#include <linux/module.h>
#include <linux/init.h>
#include <linux/moduleparam.h>
#include <linux/fs.h>
#include <linux/kdev_t.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/uaccess.h>
#include <linux/errno.h>
#include <asm/atomic.h>
struct device_test
{
dev_t dev_num;
struct cdev cdev_test;
int major;
int minor;
struct class *class;
struct device *device;
char kbuf[32];
};
struct device_test dev1;
static atomic64_t v = ATOMIC64_INIT(1);
static int cdev_test_open(struct inode *inode, struct file *file)
{
if(!atomic64_dec_and_test(&v)){
atomic64_add(1, &v);
return -EBUSY;
}
file->private_data = &dev1;
printk("This is a cdev_test_open\n");
return 0;
}
static ssize_t cdev_test_read(struct file *file, char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_to_user(buf, dev->kbuf, strlen(dev->kbuf)) != 0)
{
printk("copy_to_user is error");
return -EFAULT;
}
return 0;
}
static ssize_t cdev_test_write(struct file *file, const char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_from_user(dev->kbuf, buf, size) != 0)
{
printk("copy_from_user is error");
return -EFAULT;
}
printk("kbuf is %s\n", dev->kbuf);
return 0;
}
static int cdev_test_release(struct inode *inode, struct file *file)
{
atomic64_inc(&v);
return 0;
}
struct file_operations cdev_test_ops = {
.owner = THIS_MODULE,
.open = cdev_test_open,
.read = cdev_test_read,
.write = cdev_test_write,
.release = cdev_test_release,
};
static int usr_init(void)
{
int ret;
ret = alloc_chrdev_region(&dev1.dev_num, 0, 1, "alloc_name");
if (ret < 0)
{
goto err_chrdev;
printk("alloc_chrdev_region failed\n");
}
printk("alloc_chrdev_region succeed\n");
dev1.major = MAJOR(dev1.dev_num);
dev1.minor = MINOR(dev1.dev_num);
printk("major is %d\n", dev1.major);
printk("minor is %d\n", dev1.minor);
dev1.cdev_test.owner = THIS_MODULE;
cdev_init(&dev1.cdev_test, &cdev_test_ops);
ret = cdev_add(&dev1.cdev_test, dev1.dev_num, 1);
if (ret < 0)
{
goto err_chr_add;
}
dev1.class = class_create(THIS_MODULE, "test");
if (IS_ERR(dev1.class))
{
goto err_class_create;
}
device_create(dev1.class, NULL, dev1.dev_num, NULL, "test");
if (IS_ERR(dev1.device))
{
goto err_class_device;
}
return 0;
err_class_device:
class_destroy(dev1.class);
err_class_create:
cdev_del(&dev1.cdev_test);
err_chr_add:
unregister_chrdev_region(dev1.dev_num, 1);
err_chrdev:
return ret;
}
static void usr_exit(void)
{
unregister_chrdev_region(dev1.dev_num, 1);
cdev_del(&dev1.cdev_test);
device_destroy(dev1.class, dev1.dev_num);
class_destroy(dev1.class);
printk("bye bye\n");
}
module_init(usr_init);
module_exit(usr_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("fengzc");
MODULE_VERSION("v1.0");
app.c(gcc app.c -o a.out)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int fd;
char buf1[32] = {};
char buf2[32] = {"nihao"};
fd = open("/dev/test", O_RDWR); // 打开设备节点
if (fd < 0)
{
perror("open error \n");
return fd;
}
sleep(5);
close(fd);
return 0;
}
выход:
fengzc@ubuntu:~/study/drivers_test/11_atomic$ sudo insmod usr.ko
fengzc@ubuntu:~/study/drivers_test/11_atomic$ cp ./a.out ./b.out
fengzc@ubuntu:~/study/drivers_test/11_atomic$ sudo ./a.out &
[1] 16630
fengzc@ubuntu:~/study/drivers_test/11_atomic$ sudo ./b.out
ошибка открытия
: устройство или ресурс занят
блокировка спина
Что такое спин-блокировка?
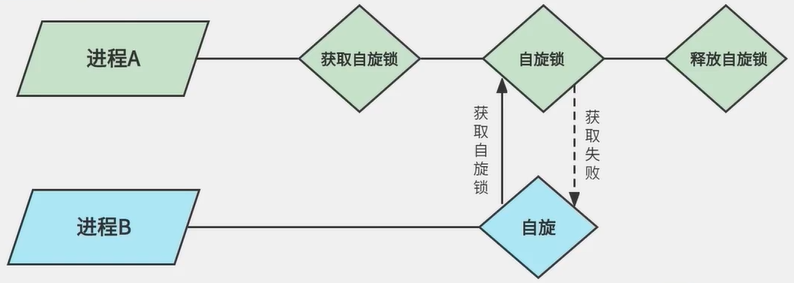
Спин-блокировка — это механизм блокировки, предложенный для защиты общих ресурсов, а также распространенный механизм блокировки в ядре. Спин-блокировки разрешают конфликты ресурсов, «ожидая на месте». То есть после того, как поток A получит спин-блокировку, поток B также захочет получить спин-блокировку. Но поток B не может его получить, поэтому он может только «вращаться на месте» (все еще занят CPU, не будет спать), продолжать попытки получить блокировку вращения до тех пор, пока не добьется успеха, а затем выйти из цикла.
LinuxЯдро использует структуру spinlock_tдля описания спин-блокировки, и эта структура определяется следующим образом:
typedef struct spinlock {
union {
struct raw_spinlock rlock;
#ifdef CONFIG_DEBUG_LOCK_ALLOC
#define LOCK_PADSIZE (offsetof(struct raw spinlock, dep_map)
struct {
u8 __padding[LOCK_PADSIZE];
struct lockdep_map dep_map;
}
#endif
};
}spinlock_t;
API-функция спин-блокировки
| функция | описывать |
|---|---|
| DEFINE_SPINLOCK (блокировка spinlock_t) | определить и инициализировать переменную |
| int spin_lock_init (блокировка spinlock_t *) | Инициализировать спин-блокировку |
| пустота spin_lock (spinlock_t * блокировка) | Получение спин-блокировки, также известной как блокировка |
| пустота spin_unlock (spinlock_t * блокировка) | Снимите блокировку вращения, также называемую разблокировкой. |
| int spin_trylock(spinlock_t * блокировка) | Попробуйте получить спин-блокировку, если нет, верните 0 |
| int spin_is_locked(spinlock_t * блокировка) | Проверьте, получена ли спин-блокировка, если нет, верните ненулевое значение, иначе верните 0 |
| пустота spin_lock_irq (spinlock_t * блокировка) | Отключить прерывания и получить спин-блокировки |
| пустота spin_unlock_irq (spinlock_t * блокировка) | Включите прерывания и снимите спин-блокировку |
| void spin_lock_irqsave(spinlock_t * lock, unsigned long flags) | 保存中断状态,关闭中断并获取自旋锁 |
| void spin_unlock_irqrestore(spinlock_t * lock, unsigned long flags) | 恢复之前保存的中断状态,打开中断并释放自旋锁 |
| void spin_lock_bh(spinlock_t * lock) | 关闭下半部,获取自旋锁 |
| void spin_unlock_bh(spinlock_t * lock) | 打开下半部,获取自旋锁 |
注意:其中,spin_lock_irq与spin_lock_irqsave是防止临界区被系统中断使用的
自旋锁的使用步骤
-
在访问临界资源的时候先申请自旋锁
-
获取到自旋锁以后就进入临界区,获取不到自旋锁就“原地等待“
-
退出临界区的时候要释放自旋锁
自旋锁的注意事项
-
由于自旋锁会“原地等待”,因为“原地等待”会继续占用
CPU,会消耗CPU资源。所以锁的时间不能太长。也就是临界区的代码不能太多。 -
在自旋锁保护的临界区里面不能调用可能会导致线程休眠的函数,否则可能会发生死锁。
-
自旋锁一般是用在多核的
SOC上。
自旋锁的死锁
在多核CPU或者支持抢占的单核CPU中。被自旋锁保护的临界区不能调用任何能够引起睡眠或者阻塞的函数,否则可能会发生死锁。
使用自旋锁会禁止抢占。比如在单核CPU下,A进程获取到自旋锁以后暂时关闭内核抢占,如果A进程此时进入了休眠状态(放弃了CPU的使用权),B进程此时也想获取到自旋锁,但是此时白旋锁被进程A持有,而且此时CPU的抢占被禁止了。因为是单核,进程B就无法被调度出去,只能在”原地旋转”等在锁被A释放。但是进程A无法运行,锁也就无法释放。死锁就发生了。
多核CPU不会发生上面的情况。因为其他的核会调度其他进程。
当进程A获取到自旋锁以后,如果产生了中断,并且在中断里面也要访问共享资源(中断里面可以用自旋锁),此时中断里面无法获取到自旋锁,只能“原地旋转”,产生死锁。为了避免这种情况发生,可以使用spin_lock_irqsave等API来禁止中断并获取自旋锁
自旋锁死锁图解
如何避免死锁
- 如果中断服务函数里面要使用自旋锁,需要在驱动程序中使用
spin_lock_irqsave和spin_unlock_irqrestore函数来申请自旋锁,防止在执行临界区里面的代码时被中断打断。 - 避免在一个函数里面多次获取自旋锁
- 临界区的代码不能太久
例子
usr.c
#include <linux/module.h>
#include <linux/init.h>
#include <linux/moduleparam.h>
#include <linux/fs.h>
#include <linux/kdev_t.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/uaccess.h>
#include <linux/errno.h>
#include <asm/atomic.h>
struct device_test
{
dev_t dev_num;
struct cdev cdev_test;
int major;
int minor;
struct class *class;
struct device *device;
char kbuf[32];
};
struct device_test dev1;
static spinlock_t spinlock;
static int flag = 1;
static int cdev_test_open(struct inode *inode, struct file *file)
{
spin_lock(&spinlock);
if(flag != 1){
spin_unlock(&spinlock);
return -EBUSY;
}
flag = 0;
spin_unlock(&spinlock);
file->private_data = &dev1;
printk("This is a cdev_test_open\n");
return 0;
}
static ssize_t cdev_test_read(struct file *file, char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_to_user(buf, dev->kbuf, strlen(dev->kbuf)) != 0)
{
printk("copy_to_user is error");
return -EFAULT;
}
return 0;
}
static ssize_t cdev_test_write(struct file *file, const char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_from_user(dev->kbuf, buf, size) != 0)
{
printk("copy_from_user is error");
return -EFAULT;
}
printk("kbuf is %s\n", dev->kbuf);
return 0;
}
static int cdev_test_release(struct inode *inode, struct file *file)
{
spin_lock(&spinlock);
flag = 1;
spin_unlock(&spinlock);
return 0;
}
struct file_operations cdev_test_ops = {
.owner = THIS_MODULE,
.open = cdev_test_open,
.read = cdev_test_read,
.write = cdev_test_write,
.release = cdev_test_release,
};
static int usr_init(void)
{
int ret;
ret = alloc_chrdev_region(&dev1.dev_num, 0, 1, "alloc_name");
if (ret < 0)
{
goto err_chrdev;
printk("alloc_chrdev_region failed\n");
}
printk("alloc_chrdev_region succeed\n");
dev1.major = MAJOR(dev1.dev_num);
dev1.minor = MINOR(dev1.dev_num);
printk("major is %d\n", dev1.major);
printk("minor is %d\n", dev1.minor);
dev1.cdev_test.owner = THIS_MODULE;
cdev_init(&dev1.cdev_test, &cdev_test_ops);
ret = cdev_add(&dev1.cdev_test, dev1.dev_num, 1);
if (ret < 0)
{
goto err_chr_add;
}
dev1.class = class_create(THIS_MODULE, "test");
if (IS_ERR(dev1.class))
{
goto err_class_create;
}
device_create(dev1.class, NULL, dev1.dev_num, NULL, "test");
if (IS_ERR(dev1.device))
{
goto err_class_device;
}
return 0;
err_class_device:
class_destroy(dev1.class);
err_class_create:
cdev_del(&dev1.cdev_test);
err_chr_add:
unregister_chrdev_region(dev1.dev_num, 1);
err_chrdev:
return ret;
}
static void usr_exit(void)
{
unregister_chrdev_region(dev1.dev_num, 1);
cdev_del(&dev1.cdev_test);
device_destroy(dev1.class, dev1.dev_num);
class_destroy(dev1.class);
printk("bye bye\n");
}
module_init(usr_init);
module_exit(usr_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("fengzc");
MODULE_VERSION("v1.0");
app.c(gcc app.c -o a.out)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int fd;
char buf1[32] = {};
char buf2[32] = {"nihao"};
fd = open("/dev/test", O_RDWR); // 打开设备节点
if (fd < 0)
{
perror("open error \n");
return fd;
}
sleep(5);
close(fd);
return 0;
}
输出:
fengzc@ubuntu:~/study/drivers_test/12_spinlock$ sudo insmod usr.ko
fengzc@ubuntu:~/study/drivers_test/12_spinlock$ sudo ./a.out &
[1] 19119
fengzc@ubuntu:~/study/drivers_test/12_spinlock$ sudo ./b.out
open error
: Device or resource busy
信号量
信号量的引入
自旋锁是通过“原地等待”的方式来处理并发与竞争的,所以被保护的临界区不能太长,以免造成对CPU资源的浪费。但是有些情况我们必不可免要长时间对一些资源进行保护。这时候就可以使用信号量。
什么是信号量呢?
举个例子,现在有一个电话亭,里面只有一个公共电话。某天A去打电话,恰好过了一会B也来了要打电话。但是此时A在打电话,所以B就只能等A打完电话才可以打。如果是自旋锁的,B就要一直等着A打完。但是A的事情很重要,需要打很长时间电话。这时候自旋锁就不合适了。那A是不是也可以告诉B,你先去休息一会,等我打完告诉你,你再来打电话。这个就是信号量。信号量会引起调用者睡眠,所以信号量也叫睡眠锁。
信号量的工作方式
信号量的本质是一个全局变量。信号量的值可以根据实际情况来自行设置(取值范围大于等于0,当有线程来访问资源时,信号量执行“减一”操作,访问完以后,在执行“加一”操作。比如一个屋子有5把钥匙,这5把钥匙就是信号量的值,也就是说有5个人可以进到这个屋子(允许多个线程同时访问共享资源)。当某个人想进屋子的时候,就要先拿一把钥匙,此时信号量的值“减一”。直到这5把钥匙全部拿走以后,这个屋子别人就进不去了。如果有人从屋子里面出来,还回去一把钥匙,此时信号量的值“加一”,那就又可以进去一个人。
信号量的描述
Linux内核使用结构体semaphore来表示信号量,定义在semaphore.h文件当中,如下所示:
struct semaphore {
raw_spinlock_t lock;
unsigned int count;
struct list_head wait list;
}
信号量API
| 函数 | 描述 |
|---|---|
| DEFINE_SEAMPHORE(name) | 定义信号量,并设置信号量的值为 1 |
| void sema_init(struct semaphore *sem, int val) | 初始化信号量 sem 并设置信号的值为 val |
| void down(struct semaphore *sem) | 获取信号量。不能被信号打断,如 ctrl+c |
| int down_interruptible(struct semaphore *sem) | 获取信号量。能被信号打断,如 ctrl+c |
| void up(struct semaphore *sem) | 释放信号量 |
| int down_trylock(struct semaphore *sem | 尝试获取信号量,如果获取到信号量就返回0,获取不到就返回非 0 |
信号量的注意事项
-
信号量的值不能小于0
-
访问共享资源时,信号量执行“减一”操作,访问完成后在执行“加一”操作
-
当信号量的值为0时,想访问共享资源的线程必须等待,直到信号量大于0时,等待的线程才可以访
问 -
因为信号量会引起休眠,所以中断里面不能用信号量
-
共享资源持有时间比较长,一般用信号量而不用自旋锁
-
在同时使用信号量和自旋锁的时候,要先获取信号量,在使用自旋锁。因为信号量会导致睡眠
例子
usr.c
#include <linux/module.h>
#include <linux/init.h>
#include <linux/moduleparam.h>
#include <linux/fs.h>
#include <linux/kdev_t.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/uaccess.h>
#include <linux/errno.h>
#include <asm/atomic.h>
#include <linux/semaphore.h>
struct device_test
{
dev_t dev_num;
struct cdev cdev_test;
int major;
int minor;
struct class *class;
struct device *device;
char kbuf[32];
};
struct device_test dev1;
static struct semaphore semlock;
static int cdev_test_open(struct inode *inode, struct file *file)
{
#if 0
down(&semlock);
#else
if (down_interruptible(&semlock))
{
return -EBUSY;
}
#endif
file->private_data = &dev1;
printk("This is a cdev_test_open\n");
return 0;
}
static ssize_t cdev_test_read(struct file *file, char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_to_user(buf, dev->kbuf, strlen(dev->kbuf)) != 0)
{
printk("copy_to_user is error");
return -EFAULT;
}
return 0;
}
static ssize_t cdev_test_write(struct file *file, const char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_from_user(dev->kbuf, buf, size) != 0)
{
printk("copy_from_user is error");
return -EFAULT;
}
printk("kbuf is %s\n", dev->kbuf);
return 0;
}
static int cdev_test_release(struct inode *inode, struct file *file)
{
up(&semlock);
return 0;
}
struct file_operations cdev_test_ops = {
.owner = THIS_MODULE,
.open = cdev_test_open,
.read = cdev_test_read,
.write = cdev_test_write,
.release = cdev_test_release,
};
static int usr_init(void)
{
int ret;
sema_init(&semlock, 1);
ret = alloc_chrdev_region(&dev1.dev_num, 0, 1, "alloc_name");
if (ret < 0)
{
goto err_chrdev;
printk("alloc_chrdev_region failed\n");
}
printk("alloc_chrdev_region succeed\n");
dev1.major = MAJOR(dev1.dev_num);
dev1.minor = MINOR(dev1.dev_num);
printk("major is %d\n", dev1.major);
printk("minor is %d\n", dev1.minor);
dev1.cdev_test.owner = THIS_MODULE;
cdev_init(&dev1.cdev_test, &cdev_test_ops);
ret = cdev_add(&dev1.cdev_test, dev1.dev_num, 1);
if (ret < 0)
{
goto err_chr_add;
}
dev1.class = class_create(THIS_MODULE, "test");
if (IS_ERR(dev1.class))
{
goto err_class_create;
}
device_create(dev1.class, NULL, dev1.dev_num, NULL, "test");
if (IS_ERR(dev1.device))
{
goto err_class_device;
}
return 0;
err_class_device:
class_destroy(dev1.class);
err_class_create:
cdev_del(&dev1.cdev_test);
err_chr_add:
unregister_chrdev_region(dev1.dev_num, 1);
err_chrdev:
return ret;
}
static void usr_exit(void)
{
unregister_chrdev_region(dev1.dev_num, 1);
cdev_del(&dev1.cdev_test);
device_destroy(dev1.class, dev1.dev_num);
class_destroy(dev1.class);
printk("bye bye\n");
}
module_init(usr_init);
module_exit(usr_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("fengzc");
MODULE_VERSION("v1.0");
app.c(gcc app.c -o a.out)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int fd;
char buf1[32] = {
};
char buf2[32] = {
"nihao"};
fd = open("/dev/test", O_RDWR); // 打开设备节点
if (fd < 0)
{
perror("open error \n");
return fd;
}
printf("open ok!\n");
sleep(10);
close(fd);
printf("close ok!\n");
return 0;
}
输出:
fengzc@ubuntu:~/study/drivers_test/13_sem$ sudo insmod usr.ko
fengzc@ubuntu:~/study/drivers_test/13_sem$ sudo ./a.out &
[1] 21355
fengzc@ubuntu:~/study/drivers_test/13_sem$ open ok!
fengzc@ubuntu:~/study/drivers_test/13_sem$ sudo ./b.out
close ok!
open ok!
close ok!
互斥锁
什么是互斥锁?
同一个资源同一个时间只有一个访问者在进行访问,其他的访问者访问结束以后才可以访问这个资源。这就是互斥。
互斥锁和信号量值为1的情况很类似,但是互斥锁更简洁,更高效,互斥锁会引起休。不过在使用中需要注意的事项也就更多。
Linux内核使用结构体mutex来描述互斥锁,结构体定义如下:
struct mutex{
atomic_long_t owner;
spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map ;
#endif
};
互斥锁的API函数
| 函数 | 描述 |
|---|---|
| DEFINE_MUTEX(name) | 定义并初始化一个互斥锁 |
| void mutex_init(mutex *lock) | 初始化互斥锁 |
| void mutex_lock(struct mutex *lock) | 上锁,如果不可以用则睡眠 |
| void mutex_unlock(struct mutex *lock) | 解锁 |
| int mutex_is_locked(struct mutex *lock) | 如果锁已经被使用则返回1,否则返回0 |
互斥锁的注意事项
- 互斥锁会导致休眠,所以在中断里面不能用互斥锁。
- 同一时刻只能有一个线程持有互斥锁,并且只有持有者可以解锁。
- 不允许递归上锁和解锁。
- 一般情况下我们优先考虑互斥锁,不考虑信号量,因为互斥锁更简洁,更高效
例子
usr.c
#include <linux/module.h>
#include <linux/init.h>
#include <linux/moduleparam.h>
#include <linux/fs.h>
#include <linux/kdev_t.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/uaccess.h>
#include <linux/errno.h>
#include <asm/atomic.h>
struct device_test
{
dev_t dev_num;
struct cdev cdev_test;
int major;
int minor;
struct class *class;
struct device *device;
char kbuf[32];
};
struct device_test dev1;
static struct mutex mutex;
static int flag = 1;
static int cdev_test_open(struct inode *inode, struct file *file)
{
mutex_lock(&mutex);
if(flag != 1){
mutex_unlock(&mutex);
return -EBUSY;
}
flag = 0;
mutex_unlock(&mutex);
file->private_data = &dev1;
printk("This is a cdev_test_open\n");
return 0;
}
static ssize_t cdev_test_read(struct file *file, char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_to_user(buf, dev->kbuf, strlen(dev->kbuf)) != 0)
{
printk("copy_to_user is error");
return -EFAULT;
}
return 0;
}
static ssize_t cdev_test_write(struct file *file, const char __user *buf, size_t size, loff_t *off)
{
struct device_test *dev = (struct device_test *)file->private_data;
if (copy_from_user(dev->kbuf, buf, size) != 0)
{
printk("copy_from_user is error");
return -EFAULT;
}
printk("kbuf is %s\n", dev->kbuf);
return 0;
}
static int cdev_test_release(struct inode *inode, struct file *file)
{
flag = 1;
return 0;
}
struct file_operations cdev_test_ops = {
.owner = THIS_MODULE,
.open = cdev_test_open,
.read = cdev_test_read,
.write = cdev_test_write,
.release = cdev_test_release,
};
static int usr_init(void)
{
int ret;
mutex_init(&mutex);
ret = alloc_chrdev_region(&dev1.dev_num, 0, 1, "alloc_name");
if (ret < 0)
{
goto err_chrdev;
printk("alloc_chrdev_region failed\n");
}
printk("alloc_chrdev_region succeed\n");
dev1.major = MAJOR(dev1.dev_num);
dev1.minor = MINOR(dev1.dev_num);
printk("major is %d\n", dev1.major);
printk("minor is %d\n", dev1.minor);
dev1.cdev_test.owner = THIS_MODULE;
cdev_init(&dev1.cdev_test, &cdev_test_ops);
ret = cdev_add(&dev1.cdev_test, dev1.dev_num, 1);
if (ret < 0)
{
goto err_chr_add;
}
dev1.class = class_create(THIS_MODULE, "test");
if (IS_ERR(dev1.class))
{
goto err_class_create;
}
device_create(dev1.class, NULL, dev1.dev_num, NULL, "test");
if (IS_ERR(dev1.device))
{
goto err_class_device;
}
return 0;
err_class_device:
class_destroy(dev1.class);
err_class_create:
cdev_del(&dev1.cdev_test);
err_chr_add:
unregister_chrdev_region(dev1.dev_num, 1);
err_chrdev:
return ret;
}
static void usr_exit(void)
{
unregister_chrdev_region(dev1.dev_num, 1);
cdev_del(&dev1.cdev_test);
device_destroy(dev1.class, dev1.dev_num);
class_destroy(dev1.class);
printk("bye bye\n");
}
module_init(usr_init);
module_exit(usr_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("fengzc");
MODULE_VERSION("v1.0");
app.c(gcc app.c -o a.out)
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
int fd;
char buf1[32] = {
};
char buf2[32] = {
"nihao"};
fd = open("/dev/test", O_RDWR); // 打开设备节点
if (fd < 0)
{
perror("open error \n");
return fd;
}
sleep(5);
close(fd);
return 0;
}
输出:
fengzc@ubuntu:~/study/drivers_test/15_mutex$ sudo insmod usr.ko
fengzc@ubuntu:~/study/drivers_test/15_mutex$ cp ./a.out ./b.out
fengzc@ubuntu:~/study/drivers_test/15_mutex$ (sudo ./a.out &);sudo ./b.out
open error
: Device or resource busy