「自動運転ハート」公開アカウントに注目するには下のカードをクリックしてください
ADASの巨大なボリュームの乾物が手に入る
本日、Heart of Autopilot は、BEV 統合事前トレーニング アルゴリズム Occ-BEV の最新開発を共有するよう Garfield 氏を招待できることを光栄に思います。Garfield 氏は、弊社の契約著者でもあります。共有する関連作品がある場合は、この記事の最後にご連絡ください。記事!
>>クリックしてエントリー→自動運転の核心【BEV Perception】技術交流グループ
『オートパイロットの中心』 著者 | ガーフィールド
エディター | オートパイロットの中心部
1. 用紙情報
論文のタイトル: Occ-BEV: 3D シーン再構成によるマルチカメラ統合事前トレーニング
著者: チェン・ミン
リンク: https://arxiv.org/pdf/2305.18829.pdf
コード: https://github.com/chaytonmin/Occ-BEV
2. はじめに

自動運転におけるマルチカメラ 3D 認識システムは、車両周囲の環境情報を収集するための費用対効果の高いソリューションを提供するため、近年研究のホットスポットとなっています。ただし、現在のマルチカメラ 3D 認識モデルは通常、単眼画像で事前トレーニングされた ImageNet モデルまたは深度推定モデルに依存しています。これらのモデルは、マルチカメラ システムに存在する固有の空間的および時間的相関を考慮できません。さらに、単眼事前トレーニングは画像特徴抽出の能力を強化しますが、後続のタスクの事前トレーニング要件に完全に対処することはできません。自動運転車は、貴重な 3D 空間情報と構造情報を含む画像と LiDAR のペアを多数収集します。したがって、これらのラベルのない画像と LiDAR のペアを効果的に利用すると、自動運転システムのパフォーマンスを向上させることができます。
BEVDepth や DD3D などの最近の研究では、視覚ベースの知覚アルゴリズムにおける奥行き推定の重要性が強調されています。単眼の奥行き推定は、オブジェクトの空間位置情報を取得する際に重要な役割を果たします。ただし、深度推定方法は通常、オブジェクト表面の深度を推定することに重点を置き、オブジェクトの全体的な 3D 構造とオクルージョン要素を無視します。マルチカメラ認識システムの場合、3D 幾何学的占有グリッドを使用して 3D シーンを記述することができます。マルチカメラ認識システムにおける全体的な 3D 認識の精度を向上させるには、正確な幾何学的占有予測が重要です。したがって、自動運転知覚の分野では、深度予測のみを重視する場合と比較して、3D シーン全体の占有グリッドの再構築を優先することでモデルの事前トレーニングがより大きなメリットをもたらします。
人間は、遮られたシーンの完全な 3D ジオメトリを頭の中で再構築する驚くべき能力を持っており、これは認識と理解にとって重要です。自動運転車の知覚システムに同様の機能を持たせるために、Occ-BEV と呼ばれるマルチカメラ統合事前トレーニング方法を提案します。私たちの方法では、マルチカメラ システムを使用して 3D シーンをベース ステージとして再構成し、その後下流のタスクで微調整するという直観的な概念を活用しています。マルチカメラ BEV 知覚の場合、LSS や Transformer などの高度な技術を使用して入力マルチカメラ画像を BEV 空間に変換し、幾何学的占有予測ヘッドを追加して 3D 占有分布を学習します。これにより、モデルの理解が強化されます。 3D 周囲のシーン。単一フレームの点群はまばらであるため、占有ラベル生成のベンチマークとしてマルチフレームの点群融合を採用します。デコーダは事前トレーニングにのみ使用され、適切にトレーニングされたモデルはマルチカメラ知覚モデルの初期化に使用されます。効率的なマルチカメラ統合事前トレーニング方法を設計することで、ラベルなしデータに固有の豊富な空間的および時間的情報を事前トレーニングされたモデルで活用できるようになります。これにより、複雑な 3D シーンを理解するモデルの能力が向上するだけでなく、高価で時間のかかる手動の 3D 注釈への依存も軽減されます。
私たちの手法の有効性を評価するために、広く使用されている自動運転データセット nuScenes を使用して広範な実験を実施します。実験結果は、私たちの方法が障害物検出、セマンティックセグメンテーション、オブジェクト追跡などのいくつかの重要なタスクで最先端のパフォーマンスを達成することを示しています。特に、半教師あり設定では、私たちの方法は自動運転システムのパフォーマンスを大幅に向上させ、教師あり学習のレベルに近づく、またはそれを超えることができます。さらに、私たちの方法の一般化能力と拡張性も実験的に検証し、その可能性と実用性を実証します。要約すると、マルチカメラ統合事前トレーニング方法は効果的な自動運転認識アルゴリズムであり、ラベルなしデータの活用において重要な役割を果たします。この方法は、3D シーン全体の占有分布を学習することで自動運転車の 3D 認識を強化し、それによって複雑な環境でのパフォーマンスを向上させます。これは、安全、信頼性、効率的な自動運転システムの実現に重要な意味を持ちます。
3. 方法
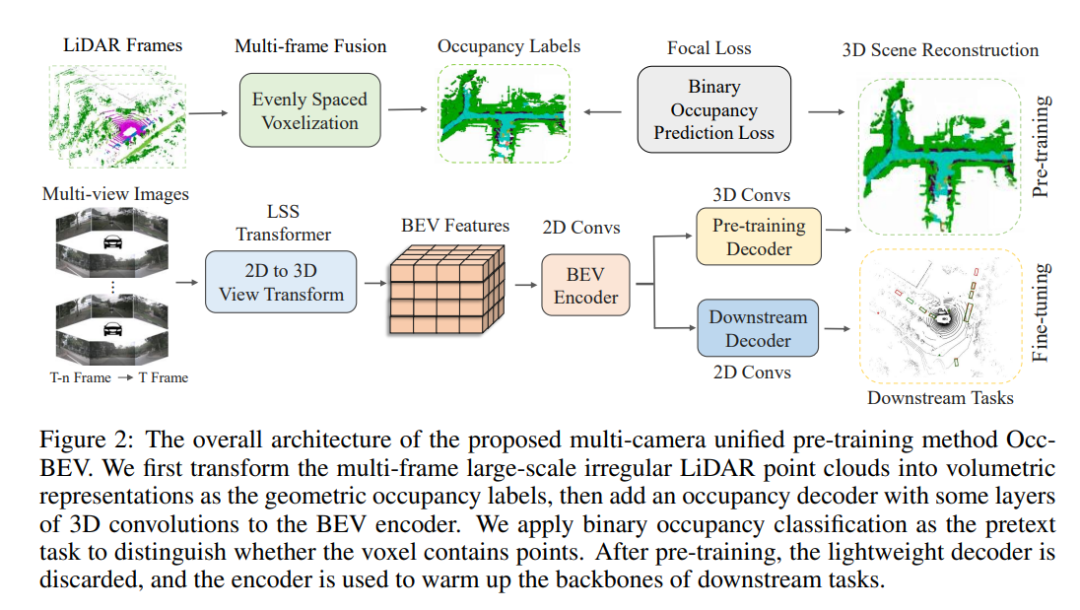
この論文で提案される方法は、自動運転における鳥瞰図 (BEV) 認識タスク用のマルチカメラ統合事前トレーニング モデルである Occ-BEV です。以下では、BEV知覚のレビュー、幾何学的占有デコーダ、事前トレーニングターゲット、および周囲の意味論的占有予測の事前トレーニングの側面からこの方法を紹介します。
3.1 BEV の認識のレビュー
このペーパーでは、BEV 知覚のための既存の視覚ベースの方法をレビューし、マルチカメラの統合された事前トレーニング済みモデルのワークフローを紹介します。このワークフローには、画像バックボーン ネットワークを使用して複数のカメラからの入力画像を処理し、各カメラ ビューの特徴マップを生成することが含まれます。これらの特徴マップは統一されたBEV表現に変換され、特定のヘッド処理を通じて、3Dオブジェクト検出、マップセグメンテーション、オブジェクト追跡などのさまざまな自動運転認識タスクが実現されます。現在の BEV 認識アルゴリズムは通常、単眼画像でトレーニングされた特徴抽出モデル (ImageNet など) または深度推定モデル (V2-99 など) に依存しています。ただし、これらの方法では、異なるカメラやフレームからのビュー間の空間的および時間的関係が無視されるため、マルチカメラの統合された事前トレーニング済みモデルが不足します。異なるカメラビュー間の空間的および時間的関係を最大限に活用するために、この論文では、マルチカメラの統合された事前トレーニング済みモデルを提案します。
3.2 マルチカメラの統合事前トレーニング
マルチカメラ統合事前トレーニングは、自動運転における鳥瞰図 (BEV) 認識タスクの事前トレーニング方法です。複数のカメラからの入力画像を使用して各カメラビューの特徴マップを生成し、これらの特徴マップを統一された BEV 表現に変換することで、3D 物体検出、地図セグメンテーション、物体追跡待機などのさまざまな自動運転認識タスクが可能になります。この事前トレーニング方法の核心は、幾何学的占有デコーダと事前トレーニングされたターゲットを使用して、マルチビュー画像から 3D シーンを予測することです。具体的には、事前トレーニングのターゲットはバイナリ幾何占有分類タスクであり、ネットワークは多視点画像に基づいて 3D シーンの幾何占有分布を正確に予測するようにトレーニングされます。幾何学的占有デコーダは軽量の 3D 畳み込み層で構成され、最終層を通じて各ボクセルに点が含まれる確率を提供します。事前トレーニング中のデコーダーの主な目的は、占有されたボクセルを再構築することです。
3.2.1 幾何学的占有デコーダ
それでは、数式を組み合わせて、幾何学的占有デコーダー、事前トレーニング ターゲット、および周囲のセマンティック占有予測の事前トレーニングの 3 つの側面を紹介します。
まず、Geometric Occupancy Decoder は、3D 幾何学的占有を予測するためのデコーダーです。軽量の 3D 畳み込みレイヤーを通じて特徴マップを処理し、最終レイヤーを通じて各ボクセルに点が含まれる確率を提供します。このデコーダの出力は次の式で表すことができます。
その中には、各ボクセルに点が含まれる確率、 はシグモイド関数、 は 3D 畳み込み演算、および BEV 特徴マップがあります。Geometric Occupancy Decoder の価値は、多視点画像を処理することによって 3D シーンの各ボクセルに点が含まれる確率を予測できることにあります。自動運転車は安全に運転するために周囲の環境を正確に認識する必要があるため、これは自動運転の認識タスクにとって非常に重要です。3D シーンの各ボクセルに点が含まれる確率を予測すると、自動運転車が周囲の形状と占有状況をよりよく理解できるようになります。
3.2.2 トレーニング前の目標
2 番目に、Pre-training Target は、事前トレーニング ターゲットを生成する方法です。LiDAR 点群を使用して占有ラベルを生成し、LiDAR 点群を等間隔のボクセルに分割し、各ボクセルはポイントが含まれているかどうかを示します。これらのボクセルの占有率、つまり各ボクセルが占有されているかどうかは、グラウンド トゥルースとして機能します。事前トレーニングは、バイナリの幾何学的占有分類タスクをターゲットとし、マルチビュー画像に基づいて 3D シーンの幾何学的占有分布を正確に予測するようにネットワークをトレーニングします。事前トレーニング ターゲットの損失関数は次の式で表すことができます。
ここで、 はボクセルの数、 は真の値、 は予測値です。事前トレーニング ターゲットの価値は、マルチビュー画像に基づいて 3D シーンの幾何学的占有分布を正確に予測するためにネットワークをトレーニングするための正確な事前トレーニング ターゲットを提供することです。事前トレーニングのターゲットはバイナリの幾何学的占有分類タスクであり、不均衡なバイナリ分類問題を解決するために焦点損失が使用されるため、これにより事前トレーニングされたモデルの精度と安定性が大幅に向上します。さらに、LiDAR 点群を使用して占有ラベルを生成し、実際のシーンとより一致させることで、事前トレーニングされたモデルの汎化能力が向上します。
3.2.3 周囲の意味的占有予測のための事前トレーニング
最後に、周囲のセマンティック占有予測の事前トレーニングでは、事前トレーニング アルゴリズムを周囲のセマンティック シーンに拡張してタスクを完了します。幾何学的占有予測に基づいて、事前トレーニングされたモデルが微調整され、マルチビュー画像の 3D セマンティクスが予測されます。具体的には、事前トレーニングされたモデルの微調整損失関数は次の式で表すことができます。
ここで、 は周囲の意味ラベルの真の値、 は予測された周囲の意味ラベル、 は周囲の意味ラベルの数、 は微調整損失関数の重み係数です。周囲のセマンティック占有予測のための事前トレーニングの価値は、タスクを完了するために事前トレーニング アルゴリズムを周囲のセマンティック シーンに拡張することにあります。この利点は、モデルをトレーニングするために大量の 3D セマンティック アノテーションを収集するオーバーヘッドと時間コストを回避できることです。事前トレーニングされたモデルを微調整してマルチビュー画像から 3D セマンティクスを予測することで、環境内の物体やシーンをより深く理解できるようになり、自動運転車の認識と安全性が向上します。
4. 実験
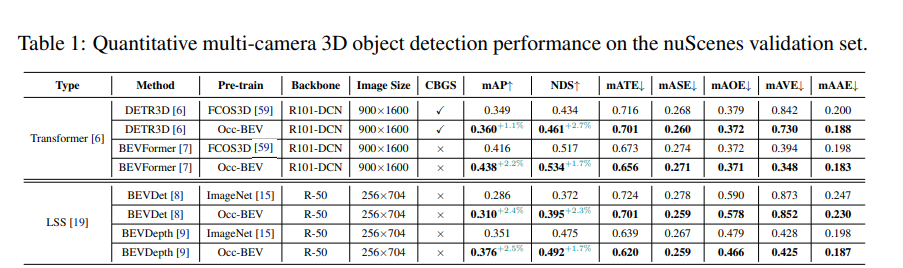
実験結果は、nuScenes 検証セットに対する occbev メソッドと以前のメソッドのパフォーマンスを示しています。この実験では、DETR3D、BEVFormer、BEVDet、BEVDepth という 4 つの異なるモデルを使用し、ImageNet または Occ-BEV 事前トレーニングを使用した場合のパフォーマンスを比較します。同時に、実験では、さまざまなバックボーン、画像サイズ、CBGS (つまり、カテゴリバランスのとれたサンプリングを使用するかどうか) などの要因がモデルのパフォーマンスに与える影響も調査しました。結果は、Occ-BEV で事前トレーニングされたモデルが、マルチビュー 3D オブジェクト検出のタスクにおいてより優れたパフォーマンスを発揮することを示しています。DETR3D モデルを例にとると、Occ-BEV で事前トレーニングされたモデルは、ImageNet で事前トレーニングされたモデルと比較して、mAP と NDS (それぞれ 1.1% と 2.7%) が大幅に向上しました。さらに、他のモデルでも同様の結果が観察されました。これは、Occ-BEV 事前トレーニング方法がマルチビュー 3D オブジェクト検出のパフォーマンスを効果的に向上できることを示しています。さらに、実験では、Occ-BEV 事前トレーニング方法を使用すると、CBGS がなくてもモデルのパフォーマンスを向上できることも示されました。これは、Occ-BEV がマルチビュー情報を効果的に利用し、モデルの堅牢性を向上できることを示しています。

実験結果は、nuScenes テスト セットを使用して評価された、マルチビュー 3D オブジェクト検出タスクにおける 2 つの異なる方法 (DD3D と Occ-BEV) のパフォーマンスを示しています。結果は、Occ-BEV で事前トレーニングされた DETR3D モデルは、DD3D で事前トレーニングされたモデルよりも mAP と NDS が 1.9% および 1.7% 高いことを示しています。これは、Occ-BEV 事前トレーニング方法が、特に複雑なシーンにおけるマルチビュー 3D オブジェクト検出のパフォーマンスを効果的に向上できることを示しています。同時に、Occ-BEVで事前トレーニングされたモデルのmATE、mASE、mAOE、mAVE、mAAEなどの誤差指標も減少し、この方法が3Dオブジェクトの位置と姿勢をより正確に推定できることを示しています。

実験結果は、3D 占有予測チャレンジにおけるさまざまな方法 (BEVFormer、BEVDet4D、BEVStereo+Occ-BEV) を使用したセグメンテーションのパフォーマンスを示しています。結果は、バックボーン ネットワークとして Swin-B を使用する場合、Occ-BEV 事前トレーニングを使用する BEVStereo 手法は、BEVFormer および BEVDet4D 手法と比較して mIoU インデックスを 3.14% 改善することを示しています。一方、BEVStereo+Occ-BEV 手法は、ほとんどのカテゴリ、特に「バリア」、「自転車」、「運転可能」カテゴリで改善され、それぞれ 26.21%、33.41%、4.69% 増加しました。これは、Occ-BEV 事前トレーニング方法が、特に複雑なシーンにおいて、マルチカメラのセマンティック シーン予測のパフォーマンスを効果的に向上できることを示しています。
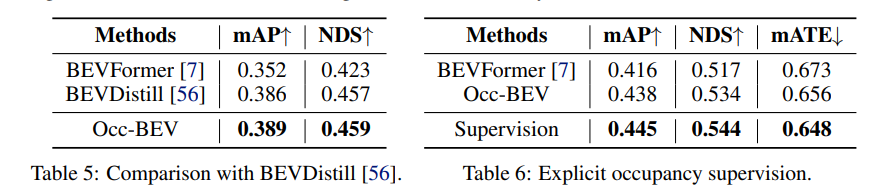
下流タスクでは、この方法は、マルチビュー 3D オブジェクト検出とマルチカメラ セマンティック シーン予測のタスクで良好なパフォーマンスを達成しました。マルチビュー 3D オブジェクト検出タスクでは、Occ-BEV で事前トレーニングされたモデルは、nuScenes 検証セットの他の方法と比較して大幅に向上しました。たとえば、ImageNet で事前トレーニングされた BEVFormer モデルと比較すると、次の 2 つの指標が向上しました。 NDS と mAP はそれぞれ 1.7% と 2.2%。マルチカメラのセマンティック シーン予測タスクでは、Occ-BEV で事前トレーニングされたモデルは、BEVStereo 手法と比較して 3D 占有予測チャレンジの mIoU インデックスを 3% 改善します。これは、この方法がマルチビュー 3D オブジェクト検出とマルチカメラ セマンティック シーン予測のパフォーマンスを効果的に向上できることを示しています。
5. ディスカッション

前の方法と比較すると、occbev 方法には次の違いがあります。
occbev 手法は、マルチカメラ入力画像を採用し、多視点画像からの情報を使用することで動的環境のより良い理解とより正確な予測を実現します。以前の単眼画像事前トレーニング方法と比較して、occbev 方法はより優れた時空間融合能力を備えています。
occbev メソッドは統一された BEV 表現を採用しており、これによりモデルは異なるカメラ ビュー間の共有表現を学習できるため、知識の伝達が容易になり、タスク固有の事前トレーニングの必要性が減ります。以前の深度推定事前トレーニング方法と比較して、occbev 方法は、より優れた多視点情報融合能力を備えています。
occbev 法には、遮蔽されたオブジェクトを認識する機能もあり、各ボクセルの占有率を予測することで、遮蔽されたオブジェクトのより包括的な 3D 再構成を実現できます。以前の知識蒸留法と比較して、occbev 法は大量の 3D アノテーション データと事前トレーニングされた LiDAR 検出モデルを必要としないため、3D アノテーションの要件とコストが削減されます。さらに、occbev 手法では、Nerf などのテクノロジーによって生成された 3D シーンをラベルとして使用することもできるため、LiDAR データへの依存が排除されます。
自動運転シナリオにおける Occ-BEV 手法のパフォーマンスには大きな可能性が示されていますが、まだ改善の余地があります。考えられる改善の方向性は次のとおりです。
3D シーン再構成法の改善: Occ-BEV 法のパフォーマンスは 3D シーン再構成法の品質に大きく依存するため、3D シーン再構成法の改善は Occ-BEV 法のパフォーマンス向上に役立つ可能性があります。
より良い事前トレーニング データセット: 現在の Occ-BEV 手法では、大規模なラベルなしの画像 LiDAR データを使用してモデルを事前トレーニングします。ただし、これらのデータセットにはノイズや不正確さが含まれる可能性があるため、より正確で豊富な事前トレーニング データセットを収集すると、Occ-BEV 法のパフォーマンスの向上に役立つ可能性があります。
より優れたマルチカメラ フュージョン戦略: Occ-BEV 手法は、各カメラの BEV 特徴を平均化する単純なマルチカメラ フュージョン戦略を使用します。ただし、より優れた融合戦略により、たとえば、異なるカメラ間の距離と角度、カメラの解像度と視野を考慮して、モデルのパフォーマンスがさらに向上する可能性があります。
より良い後処理方法: Occ-BEV 方法では、非最大抑制や穴埋めなどのいくつかの単純な後処理方法を使用して、モデルのパフォーマンスをさらに向上させます。ただし、より優れた後処理方法により、たとえば事前の知識を組み込んで誤った予測を除去するなど、モデルのパフォーマンスがさらに向上する可能性があります。
6 結論
私たちは、マルチカメラの統合事前トレーニング タスクを定義し、マルチビュー 3D 物体検出や周囲のセマンティック シーンの完成など、複数の自動運転タスクで優れたパフォーマンスを発揮する初の統合事前トレーニング アルゴリズムを提案します。ラベルなしの画像 LiDAR データを使用して 3D シーンを事前トレーニングすると、ラベル付き 3D データへの依存を効果的に軽減でき、自動運転の基本モデルを構築する有望な機会を提供できます。今後の作業は、前述の制限に対処し、実際の自動運転シナリオにおける私たちの方法のパフォーマンスと適用性をさらに向上させることに重点を置く必要があります。
(1)動画講座はこちら!
自動運転の心臓部は、ミリ波レーダービジョンフュージョン、高精度地図、BEV知覚、センサーキャリブレーション、センサー展開、自動運転協調知覚、セマンティックセグメンテーション、自動運転シミュレーション、L4知覚、意思決定計画、軌道予測などを統合します。 . 方向学習ビデオ、ご自身で受講してください (コードをスキャンして学習を入力してください)

(コードをスキャンして最新のビデオをご覧ください)
動画公式サイト:www.zdjszx.com
(2) 中国初の自動運転学習コミュニティ
1,000 人近くのコミュニケーション コミュニティと 20 以上の自動運転技術スタックの学習ルートが、自動運転の認識 (分類、検出、セグメンテーション、キー ポイント、車線境界線、3D 物体検出、占有、マルチセンサー フュージョン、物体追跡、オプティカル フロー推定、軌道予測)、自動運転位置決めとマッピング(SLAM、高精度マップ)、自動運転計画と制御、フィールド技術ソリューション、AI モデル展開の実装、業界トレンド、求人リリース、スキャンへようこそ以下の QR コード、自動運転の中心となるナレッジ プラネットに参加してください。ここは本物の乾物がある場所です。この分野の大手の人々と、仕事の開始、勉強、仕事、転職に関するさまざまな問題を交換し、論文 + コードを共有します。毎日+ビデオ、交換を楽しみにしています!

(3) 【自動運転の心臓部】フルスタック技術交流会
The Heart of Autonomous Driving は、物体検出、セマンティック セグメンテーション、パノラマ セグメンテーション、インスタンス セグメンテーション、キー ポイント検出、車線境界線、物体追跡、3D 物体検出、BEV 認識、マルチセンサー フュージョン、 SLAM、光流推定、深さ推定、軌道予測、高精度地図、NeRF、計画制御、モデル展開、自動運転シミュレーションテスト、プロダクトマネージャー、ハードウェア構成、AI求人検索とコミュニケーションなど。

Autobot Assistant Wechat への招待を追加してグループに参加します
備考:学校/会社+方向+ニックネーム