1. Что такое среднее время восстановления?
Когда в системе происходит сбой, нам необходимо использовать некоторые индикаторы для измерения серьезности и масштаба сбоя. Среди них MTTR (среднее время восстановления ) — очень важный показатель, который может помочь нам понять среднее время, необходимое для ремонта системы. Не рекомендуется тратить слишком много времени на ремонт системы, особенно для такой компании, как JD.com. Если MTTR слишком длинный, это может привести к серьезным последствиям, таким как оплата счетов по карте пользователями и потеря дохода для компании. Поэтому, чтобы обеспечить стабильность и надежность системы, нам необходимо максимально сократить MTTR.
Чтобы рассчитать MTTR, разделите общее время обслуживания на общее количество операций по техническому обслуживанию за определенный период времени. Формула расчета MTTR:

2. Как сократить MTTR
Понимание MTTR — очень важный инструмент для любой организации, поскольку оно помогает нам лучше реагировать и устранять проблемы в производстве. В большинстве случаев организации надеются сократить MTTR за счет собственных групп технического обслуживания, для чего требуются необходимые ресурсы, инструменты и поддержка программного обеспечения.
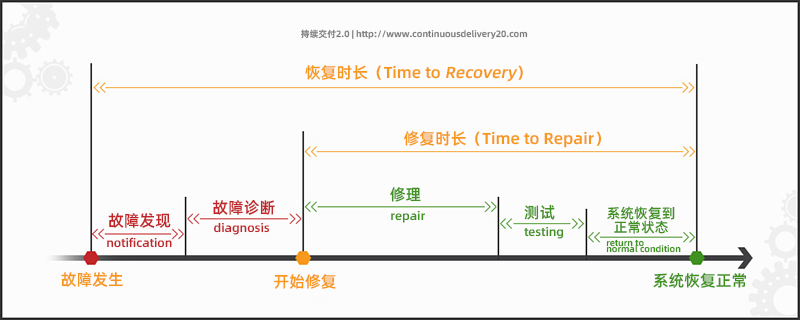
Итак, какие шаги вы можете предпринять, чтобы сократить MTTR вашей организации? Лучше всего начать с понимания каждого этапа MTTR и принятия мер по сокращению времени, затрачиваемого на каждом этапе. В частности, мы можем рассмотреть следующие аспекты:
1. Время обнаружения проблемы: мониторинг и подача сигналов тревоги для выявления неисправностей.
Чтобы технические специалисты могли выявить проблему после возникновения сбоя, мы можем сократить время идентификации MTTR, установив систему сигнализации. Контролируя работу системы в режиме реального времени и оперативно обнаруживая и срабатывая механизм сигнализации, мы можем помочь нам в кратчайшие сроки обнаружить проблему и принять соответствующие меры по ее устранению.
Мы можем отфильтровать ненужную информацию о тревогах, установив разумные пороговые значения и правила, тем самым избегая помех от шума тревог команде разработчиков и эксплуатации и позволяя им больше сосредоточиться на реальных проблемах.
1.1. Мониторинг УМЗ
- Реализуйте 3 золотых индикатора мониторинга (уровень доступности, объем звонков, TP99) через UMP.
При настройке механизма сигнализации мы можем всесторонне учитывать для оценки такие факторы, как доступность, TP99 и громкость звонков. Комплексная оценка этих показателей может помочь нам получить более полное представление о работе системы, чтобы можно было своевременно обнаружить потенциальные проблемы и принять соответствующие меры.
Рекомендуется при настройке сигналов тревоги сначала принять более строгую стратегию, то есть сначала затянуть, а затем ослабить и постепенно адаптироваться к наилучшему состоянию . Это гарантирует обнаружение проблем на самых ранних стадиях и предотвращение крупных сбоев. Но по мере постепенной стабилизации системы мы также можем ослабить порог срабатывания сигнализации в соответствии с фактической ситуацией, чтобы повысить доступность и эффективность системы.
Следует отметить, что при настройке сигнализации нам необходимо вносить коррективы и оптимизации с учетом конкретных бизнес-сценариев и характеристик системы. Разные системы могут иметь разные точки риска и узкие места, поэтому нам необходимо сформулировать соответствующие стратегии оповещения, основанные на реальной ситуации, чтобы обеспечить стабильность и надежность системы.
critical告警方式:咚咚、邮件、即时消息(京ME)、语音
可用率:(分钟级)可用率 < 99.9% 连续 3 次超过阈值则报警,且在 3 分钟内报一次警。
性能:(分钟级)TP99 >= 200.0ms 连续 3 次超过阈值则报警,且在 3 分钟内只报一次警。
调用次数:当方法调用次数在 1 分钟的总和,连续 3 次大于 5000000 则报警,且在 3分钟内只报一次警
warning告警方式:咚咚、邮件、即时消息
可用率:(分钟级)可用率 < 99.95% 连续 3 次超过阈值则报警,且在 30 分钟内报一次警。
性能:(分钟级)TP99 >= 100.ms 连续 3 次超过阈值则报警,且在 30 分钟内只报一次警。
调用次数:当方法调用次数在 1 分钟的总和,连续 3 次大于 2000000 则报警,且在 3 分钟内只报一次警- Если UMP является запланированной задачей, наиболее важным моментом является определение периода мониторинга . Только правильно настроив период мониторинга, мы можем гарантировать, что UMP будет нормально выполняться в течение ожидаемого периода времени. Таким образом, если UMP не может быть выполнен в течение ожидаемого периода времени, автоматически сработает механизм сигнализации для обнаружения и решения проблемы. во время.
1.2. Тревожные вызовы должны совершаться быстро, точно и нечасто.
При обработке тревожной информации нашим ключом является не количество, а точность и полнота информации . Наша команда ежедневно получает сотни тревожных сообщений. Хватит ли у вас сил и времени проверить каждое из них? Можете ли вы убедиться, что каждый из них привлекает внимание?
Поэтому нам необходимо оценить влияние на бизнес и установить соответствующую частоту сигналов тревоги в зависимости от ситуации. Особенно в отношении тех тревожных сообщений, которые считаются «ключевыми голосами», нам следует как можно скорее их обнаружить и устранить . Только таким образом мы сможем гарантировать, что сможем быстро и точно реагировать на чрезвычайные ситуации и минимизировать возможные последствия.
1.3. Детали определяют успех или неудачу.
2. Время для устранения системных проблем: механизм реагирования на сбой, быстрый гемостаз
Почему нам нужно устранять системные проблемы, а не просто выявлять их? Это связано с тем, что при решении системных проблем простое обнаружение проблемы является лишь частью решения. Что еще более важно, нам необходимо как можно быстрее устранить системные проблемы, чтобы избежать дальнейшего воздействия на бизнес.
Чтобы повысить эффективность решения проблем, нам необходимо начать со следующих трех аспектов:
Короче говоря, чтобы повысить эффективность решения проблем, нам необходимо принять ряд мер, чтобы сократить время возникновения проблем в системе, а не просто определить местонахождение проблемы. Только таким образом можно действительно гарантировать стабильность и надежность системы.
2.1. Внедрить механизм реагирования на чрезвычайные ситуации.
Независимо от размера организации, одной из ее важнейших характеристик является способность реагировать на чрезвычайные ситуации. При возникновении чрезвычайных ситуаций необходимо иметь полный план действий в чрезвычайных ситуациях и механизм практического обучения, чтобы обеспечить быстрое и эффективное реагирование на различные чрезвычайные ситуации. Для достижения этой цели нам необходимо начать со следующих аспектов:
Короче говоря, чтобы улучшить способность организации реагировать на чрезвычайные ситуации, нам необходимо организовать полный процесс обучения и тренировок, полностью задействовать силу команды и разумно определить серьезность проблемы . Только так можно по-настоящему гарантировать стабильность и надежность организации.
Распределение ключевых ролей
Механизм процесса
механизм обратной связи
Обратная связь о текущем ходе обработки и следующих действиях. Если есть какие-либо операции, которые необходимо выполнить немедленно, сообщите о них заранее. Содержимое, которое необходимо сообщить, включает влияние на бизнес и систему. Наконец, командующий по неисправностям выполнит принять решение перед его выполнением, чтобы не быть занятым. Что-то пошло не так. Отсутствие прогресса остается прогрессом, и необходима своевременная обратная связь. Обратная связь от нетехнического персонала, например, из службы поддержки клиентов и т. д. Его следует описывать не техническими терминами, а как можно более деловым языком, а другой стороне необходимо дать примерное представление о том, что мы делаем, сколько времени потребуется на восстановление и не сможет ли она это сделать. быть восстановлен, сколько времени потребуется, чтобы позвонить кому-нибудь? Обратная связь и многое другое.
2.2. План экстренной помощи при быстром гемостазе
Основные принципы: Во всех средствах и действиях, предпринимаемых в процессе устранения неисправностей, восстановление бизнеса является наивысшим приоритетом, а восстановление решений по гемостазу на месте важнее, чем поиск причины неисправности.
2.3. В полной мере использовать существующие инструменты для интеллектуального анализа проблем позиционирования.
2.2.1. Для TP99, который расположен высоко и его трудно установить:
Взаимоотношения вызовов сложны, что затрудняет быстрое обнаружение узких мест в производительности. Инструменты можно использовать для предварительной сортировки сложных зависимостей между сервисами и сосредоточения внимания на основных проблемах узких мест в сервисах, а не на сортировке ссылок только при возникновении проблем.
2.2.2. В ответ на внезапный высокий уровень громкости разговора
Вы можете использовать JSF>Защита трафика>Приложения и интерфейсы>Псевдоним и имя метода, чтобы определить объем вызовов восходящих приложений, а затем принять соответствующие меры, такие как восходящая связь, текущие стратегии ограничения и т. д.
2.2.3. Анализ потоков, JVM, выборка процессора Flame Graph и т. д.
Платформа Тайшань》Диагностика неисправностей》Онлайн-диагностика
2.2.4. Деловые вопросы
Судя по поиску в бортжурнале, по этому поводу сказать нечего.
Предоставляя рекомендации и обучение техническим специалистам с помощью стандартизированных процедур, вы можете сократить время, необходимое для решения проблем. В случае того же сбоя наличие соответствующей документации и планов реагирования на чрезвычайные ситуации (СОП) позволяет быстро изучить все причинные факторы, которые могли привести к сбою.
3. Резюме
После устранения онлайн-проблемы очень важным шагом является написание отчета о проверке COE (Центра передового опыта). В этом отчете мы можем рассмотреть весь процесс решения проблем и подумать о том, что можно было бы сделать, чтобы быстрее сократить MTTR (среднее время ремонта).
В частности, мы можем начать со следующих аспектов:
Короче говоря, путем углубленного анализа проблем, выявления коренных причин, обобщения опыта и уроков, а также выводов из одного примера мы можем эффективно сократить MTTR и обеспечить стабильность и надежность системы .
ссылка:
Расшифровка работы и обслуживания SRE Google
Непрерывная доставка 2.0
Оштрафован на 200 юаней и конфисковано более 1 миллиона юаней Ю Юйси: важность высококачественных китайских документов Жесткий сервер миграции Маска Solon для JDK 21, виртуальные потоки невероятны! ! ! Контроль перегрузки TCP спасает Интернет Flutter для OpenHarmony уже здесь Срок LTS ядра Linux будет восстановлен с 6 до 2 лет Go 1.22 исправит ошибку переменной цикла for Svelte построила «новое колесо» — руны Google отмечает свое 25-летиеАвтор: JD Logistics Фэн Чживэнь
Источник: Сообщество разработчиков JD Cloud Ziyuanqishuo Tech. При перепечатке указывайте источник.