目次
5.2 影検出モジュールとストリートビュー検出モジュールの実験設定
この記事はかなり長く、上・中・下の3部に分かれていますので、詳しくは記事インデックスをご覧ください。
影の環境でのターゲット検出における地域畳み込みネットワークの研究と応用
5.2影検出モジュールとストリートビュー検出モジュールの実験設定
5.2.1実験環境とツール
実験的な操作では、
プラットフォームとして
Ubuntu 16.04オペレーティング システムを使用し、
Python3.6言語コーディングを使用し、ソフトウェアは
Pytorch
と
Mxnet
は深層学習フレームワークとして使用され、
Opencv
、
Matplotlib
、
Numpy
およびその他のツールキットと組み合わせてデータを処理します。
処理と操作、ハードウェアの観点では、トレーニング プロセスは
Nvidia Tesla P4に基づいており
、予測と推論のプロセスは
Nvidiaに基づいています。
GTX 960M では
、この実験は影検出モジュールの実験とストリートビューターゲット検出モジュールの実装の 2 種類のサブ実験で構成されています。
この経験については、具体的なディスカッションの中で別途説明します。
5.2.2
入力層と出力層の設定
影検出モジュールの場合、入力レイヤーは固定の
512
×
512
×
3 の
画像入力を使用してトレーニングされます。
階層化する前に、各データはランダムにトリミングされます。つまり、データは512
×
512のサイズ
に拡張され
、モデルに直接入力できるようになります。出力
この層は主に、双線形補間に基づく転置畳み込み層を使用します。これは、4 つの畳み込みモジュールを通過した画像を 4 倍のサイズから縮小するために使用されます。
出力結果に合わせて画像サイズを元のサイズに戻します。
ストリート ビュー オブジェクト検出モジュールの場合、トレーニング入力レイヤーは双一次補間を一律に使用して、画像データ サイズを
512
×にスケールします。
256
、ラベル内の他の浮動小数点値を避けるために、最近傍補間を使用してラベルを同じサイズにスケールし、
Resnetを入力します。
特徴抽出操作用の
FPN 。出力層はバウンディング ボックス認識ブランチと
マスク
ブランチに分かれています。
特徴マップを全結合層に入力した後、予測されたカテゴリと境界ボックスの位置が出力され、
マスク
ブランチは
28
×
28
× 80を出力します。
 は影ピクセルの総数と影以外のピクセルの総数を表します。誤差係数が低いほど、モデルの影検出精度は高くなります。
は影ピクセルの総数と影以外のピクセルの総数を表します。誤差係数が低いほど、モデルの影検出精度は高くなります。

 実験では、影検出モデルの各モジュールの役割を調べるために、4つの参照ネットワークを構築し比較検証しました。
実験では、影検出モデルの各モジュールの役割を調べるために、4つの参照ネットワークを構築し比較検証しました。
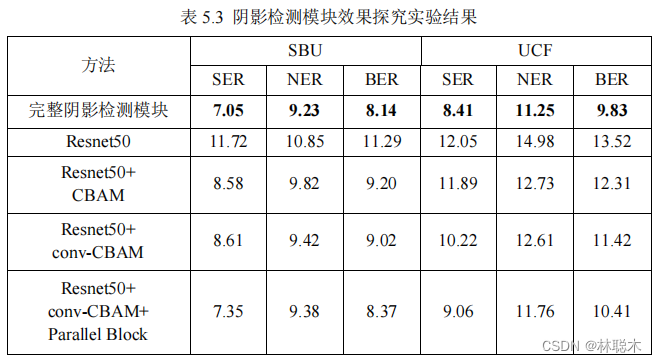 実験結果を観察すると、この記事で提案した完全な影検出モジュールの評価指標は、検証実験で構築された 4 つのカテゴリよりも優れていることがわかります。
実験結果を観察すると、この記事で提案した完全な影検出モジュールの評価指標は、検証実験で構築された 4 つのカテゴリよりも優れていることがわかります。
 観察結果から、影検出モジュールとストリートビュー検出モジュールに基づく完全な影シーンにおけるストリートビュー検出モデルは基本的に次のとおりであることがわかります。
観察結果から、影検出モジュールとストリートビュー検出モジュールに基づく完全な影シーンにおけるストリートビュー検出モデルは基本的に次のとおりであることがわかります。
 精度と再現率の曲線を分析すると、どちらのタイプのパラメータも 350 ステップから400
ステップまで徐々に収束していることがわかります。
精度と再現率の曲線を分析すると、どちらのタイプのパラメータも 350 ステップから400
ステップまで徐々に収束していることがわかります。



マスクを使用すると、最終モジュールは 3 つの結果を出力し、それらを元の画像にマッピングして、位置決め、検出、セグメンテーションの機能を実現します。
5.2.3損失関数
損失関数はモデルの検出結果と実際のラベルとの距離を表現するために使用されますが、損失関数で計算される損失はどのように計算すればよいのでしょうか?
過剰適合せずに最小化することは、モデル トレーニングの目標の 1 つです。この記事に含まれる 2 種類の実験には、異なる方法があります。
損失関数の定義。
影検出モジュールの場合、影データ セットを観察すると、以下の図5.1
に示すように、陽性サンプルと陰性サンプルの割合に不均衡があります。
このような問題が発生したトレーニング セット画像の例。

実際の検出結果では、黒いピクセルが背景情報を表し、白いピクセルが検出対象の影情報を表します。この場合は白
影付きのピクセルは全体の合計に占める割合が低くなります。完全なデータセットでは、このような陽性サンプルと陰性サンプルの分布の不均衡は一般的です。
状況に応じて包括的な分析を行った後、最終的なモデル トレーニングの損失関数として
Focal Lossが使用されます
。次の式
5.1は
Focal Loss
を表します。
損失の具体的な定義
[53]。


平均バイナリ クロス エントロピーは、通常のバイナリ クロス エントロピーに基づいており、
シグモイド
活性化関数を使用して各ピクセルを 1 つずつ計算します。
ピクセルの計算により、クラス間の競合の問題が回避され、解決されます。
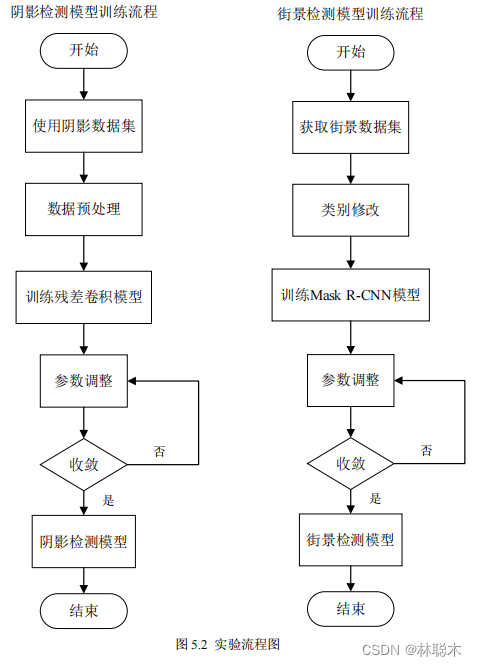
5.2.4実験の具体的な手順
図5.2
に示すように
、この実験には 2 つのサブ実験が含まれており、実験全体のトレーニング ステップには、データ セットの取得と使用、データの前処理、および
プロセスまたはクラスの変更を処理し、コア モデルをトレーニングし、収束するようにパラメーターを調整して、最終的な全体的なモデル構成を取得します。影検出モード時
このブロックは、シャドウ データ セットを前処理および拡張し、
Focal を使用して
Resnet50に基づく
並列残差畳み込みモジュールに入力します。
Loss は
損失を推定し、収束するまで約
500
ステップをトレーニングします。ストリート ビュー検出モジュールでは、まずストリート ビュー データ セット
Cityscapesについて
カテゴリを元の
34
カテゴリから
5
カテゴリに変換し、トレーニング用の
マスク R-CNN
ネットワークを入力し、バウンディング ボックスをターゲットにします
損失、分類損失、および
マスク
損失は、ネットワーク トレーニングが約
400
ステップで収束に達し、使用可能なストリート ビュー検出が得られるまで最適化されます。
モデル。
5.3実験による評価と比較
5.3.1 2種類の実験の評価基準
上記のデータをプロセスに従ってトレーニングすることで、最終的な出力結果が評価基準に従って評価され、モデルが観察されます。
実際のモデルの予測能力は、影検出モデルと街路物体検出モデルで以下のように評価基準が異なります。
具体的な定義を示します。
影検出モデルでは、モデルの影の認識率と影以外の誤検出率にさらに注目し、実験結果を評価します。
その結果を、従来の影検出モデル[14-15]と同じ評価指標「
影画素検出誤差要因」を用いて分析・比較する。
SER
、非影ピクセル検出誤差係数
NER
、平均検出誤差係数
BER は
、次のように定義されます
: 5.6
、
5.7
、および
5.8
:
は影ピクセルの総数と影以外のピクセルの総数を表します。誤差係数が低いほど、モデルの影検出精度は高くなります。
ピクセルの意味情報の分類が正確であればあるほど、最終的な評価基準は検出エラーの確率をより適切に反映し、モデルが正しいかどうかを評価できます。
より良い検出結果。
ストリート ビューのターゲット検出モデルには、特定の
IOU条件下
での平均精度率
Average Precision (mAP)
と平和率が使用されます。
評価指標として
Average Recall (mAR)
を使用し、 IOUとは予測されたエディットボックス領域とラベルのバウンディングボックスを指します。
領域間の交差比率
[54]
は、予測とラベルの間のギャップを調べるために使用されます
。IOU
参照範囲は
0.5:0.05:0.95に設定されます
。
0.5
:0.05:0.95 は、
0.5から0.95まで0.05の間隔で分割された10 個のサブ間隔
を表し、各間隔の
IOUは次のようになります。
精度を平均して最終的な評価指標を算出し、ターゲットサイズに応じて大・中・小エリアごとに異なる正解率を評価します。
制御変数の比較分析の目的を達成するための再現率と再現率 小領域
(小)は
32*32
未満のラベル位置ボックスを表し
、中
領域
(中)は
96*96
より小さい注釈配置ボックスを表し
、大きな領域(大)は96*96以上の注釈配置ボックスを表します。
5.3.2 2種類の実験結果の比較
評価基準と組み合わせた影検出ネットワークは、
ubuntu16.04
、
Python3.6
、
mxnet-cu100
の環境で構築されています。
Tesla P4グラフィックス
カードでトレーニングおよびテストされたため、画像の処理には
平均
0.031秒かかり、検出速度は毎秒に達すると予想されます。
32.2フレーム
/秒
、効率的なリアルタイム検出機能を備えています。
この記事のSBUおよびUCFテスト セット
に関する影検出モジュールの具体的なパフォーマンス
本体テスト結果と一般的な同型影検出モデルとの比較結果を表
5.1
、表
5.2に示します
。
実験では、影検出モデルの各モジュールの役割を調べるために、4つの参照ネットワークを構築し比較検証しました。
最初のネットワークは、最後の出力層のみが変更された、元の事前トレーニングされた
Resnet50
ネットワークです。2 番目のネットワークは、
オリジナルのResnet50ネットワーク
に基づく
Resnet50+CBAMネットワークは、各残差畳み込みブロック間の未改善のアテンションを接続します。
強制モジュール
CBAM
; 3 番目のネットワークは、元の
Resnet50ネットワークに基づく
Resnet50+conv-CBAM
ネットワークです。
改良されたアテンション モジュール
conv-CBAM は各残差畳み込みブロック間に接続され
、4 番目のネットワークは
Resnet50+Parallelです。
Block+conv-CBAM
ネットワークは、
前述の並列畳み込み設計を使用して、元の
Resnet50の各残差モジュールを再構成したものです。
このアイデアは、並列畳み込みモジュールを形成し、各モジュール間に改良されたアテンション メカニズム モジュールを接続することですが、各層の出力結果には、
密なつながりでつながっています。上記 4 種類のネットワーク構造はそれぞれ異なり、高密度接続の考え方とは異なり、ますます複雑化しています。
完全なネットワークを相互に比較すると、アテンション メカニズム
CBAM
、改良されたアテンション メカニズム
conv-CBAM
、および並列ボリュームをそれぞれ検証できます。
製品モジュールの役割と高密度接続の設計方法。検証実験の信頼性を確保するために、各モデルのトレーニングに同じ損失が使用されました。
損失関数、データセット、トレーニング戦略を統合し、同じ評価指標を使用して予測結果を評価します。
研究実験の結果を表
5.3に示します
。
実験結果を観察すると、この記事で提案した完全な影検出モジュールの評価指標は、検証実験で構築された 4 つのカテゴリよりも優れていることがわかります。
基準ネットワーク、およびこれら 5 種類のネットワークの複雑さが深まるにつれて、一般に評価指標値は低下します。
これにより、各モジュールの設計の合理性が確保され、この影検出モジュールの信頼性が確保されます。完全なモジュールは、
SBU
テスト セットで比較的良好なパフォーマンスを示します。
パフォーマンスが大幅に向上し、
UCF
データセットの
NER
および
BER指標は
、他の同様の影検出モデルよりも大幅に低くなりました。
落とす。クロスデータセット検証の成功は、このモデルの信頼できる一般化能力を証明しています。そして
ST-CGANを通じて
。
モデルの実験結果を比較すると、このモデルは陽性サンプルと陰性サンプルに対してバランスの取れた検出能力を備えており、分類器は陽性サンプルと陰性サンプルの影響を受けないことがわかります。
量的比率の不均衡は、分類結果の不均衡につながります。
ストリートビュー対象物検出モジュールの実験結果には、ストリートビュー対象物検出モジュール単体モジュールと複合影検出モジュールを使用しました。
完全な影環境状態のストリートビューターゲット検出モデルは、影を反映するブロックで構成されるストリートビュー検出モジュールと比較されます。
この記事で説明する複雑なシーンにおけるターゲット検出トピックにおける検出モジュールの重要性と、このストリート ビュー ターゲット検出モデルの利点
全体的な使いやすさと堅牢性、具体的な比較結果は以下の表5.4
のとおりです
。
観察結果から、影検出モジュールとストリートビュー検出モジュールに基づく完全な影シーンにおけるストリートビュー検出モデルは基本的に次のとおりであることがわかります。
この本の精度と再現率はより高く、これはデータセット内の影のシーンに対する追加の影検出処理によるものです。
これにより、モデルはさまざまなシーンや照明条件においてより優れた検出能力を持つことができるようになり、最終的にこの記事で提案するストリートビュー検出方法が完成します。
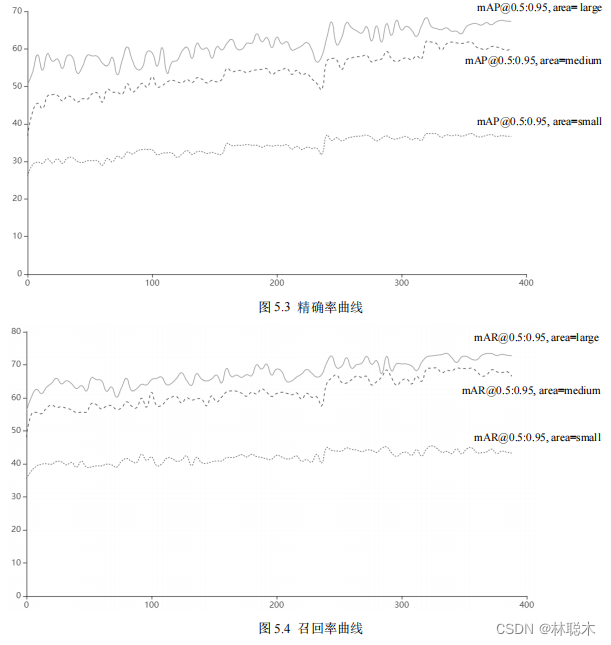
図5.3
および
5.4に示す
ように、このモデルとパラメータ ベンチマークに基づいて測定システムを構築し、より豊富なインターフェイス機能を実現します
。
は特定のパラメータ曲線であり、横軸はトレーニング反復ステップ数を表し、縦軸は特定のパーセント指数値を表します。
精度と再現率の曲線を分析すると、どちらのタイプのパラメータも 350 ステップから400
ステップまで徐々に収束していることがわかります。
クラスラベル境界ボックス領域の下の再現率と適合率、境界ボックス領域が増加するにつれて、モデル認識の適合率と再現率が増加します
値が増加するほど、モデルの検出能力が強化されます。これは、モデルが大きなオブジェクトとそれよりも小さなオブジェクトの認識能力が優れていることを意味します。
32*32スケール
のオブジェクト認識能力はわずかに弱くなります。認識精度と再現率を比較 どの位置決め枠領域でも再現率は
全体として、これは正解率よりも高く、モデルがさまざまなカテゴリをよく認識し、偽陰性が少なく、ほとんどのカテゴリを特定して見つけることができることを証明しています。
予測対象は 2 つのカテゴリに分類されており、精度も良好なレベルにあり、認識精度も保証されています。
全体的な形状は街路シーン検出のニーズを満たしており、検出と位置決めのタスクを完了できます。
影環境における街路物標検出システムの実装
6.1システム概要
ストリート ビューの物体検出タスクの場合、ドライバー、交通管制部門、保険会社などのユーザーは、多くの場合、実際の実行可能なツールを必要とします。
ほとんどの機能はシステムで完結しますが、学習済みモデルだけでは事実や予測結果をうまく表示できません。
また、技術者以外の開発者に信頼性の高い対話機能を提供することも困難です。この需要に基づいて、この影の環境でストリートシーンを構築します
ターゲット検出システムを使用すると、ユーザーはストリートビューの写真をアップロードしたり、ストリートビューのビデオをアップロードしたり、カメラを使用して写真を撮ったり、ストリートビューのターゲット検出を実行したりできます。
計測と予測の基本機能。
このストリートビュー検出システムは、上記の実験で 2 つのモジュール モデルを使用し、相互に接続することでユーザーに効率的で便利な情報を提供します。
Jie のワンストップ多機能ストリートビュー検出プラットフォームこのシステムは
C/Sアーキテクチャに基づいて
開発されており、主に
Windows
オペレーティング システムに適しています。
PyQt5フレームワーク
を使用して
グラフィカル インターフェイス ウィンドウを開発し、
Pytorch
および
Opencv
ツールキットを使用してイメージ操作を完了します。
などの具体的な詳細機能は、実験学習モデル層とビジネス層の接続インターフェース、そして、実験学習モデル層とビジネス層の接続インターフェースの大きく3つの開発タスクに分かれています。
これは、データベース永続層とビジネス層の間の接続を推進するものであり、3 番目は、コア ビジネス層の構築、ビジネス ロジックの開発、およびその相互作用です。
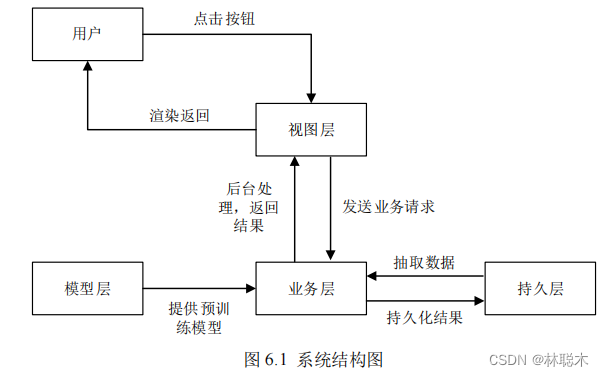
レイヤ接続を表示します。モデル層は、各モジュールの構成やネットワークの定義など、コア アルゴリズム モデル プロセスをカプセル化します。また、次の役割も果たします。
トレーニング パラメーターをモデル テンプレートにインポートし、最後に使用するために直接利用可能なモジュール モデルをエクスポートします。ビュー レイヤーは
PyQt5に基づいて開発されています
。
機能的なインターフェイスとコントロールを配置し、利用可能なマンマシン インターフェイスとボタンを提供し、ユーザーにバックグラウンド データを提示する責任を負います。
ユーザーに予測結果などの情報を公開すると同時に、ビジネス層はビュー層からのフィードバックを処理し、ユーザーが処理する必要があるプロセスを処理する責任があります。
モデル層と永続化層を組み合わせて、システム全体のバックエンドである画像処理やデータストレージなどのデータ操作を行うことができます。
プラットフォームの最も重要なコアであるデータ永続層は、
MySQL
データベースに基づいており、主にデータベースのカプセル化とデータベース操作の実装に使用されます。
関連する重要な情報を操作および処理するために、図
6.1
は日陰環境における街路検出システムのシステム構成図です。
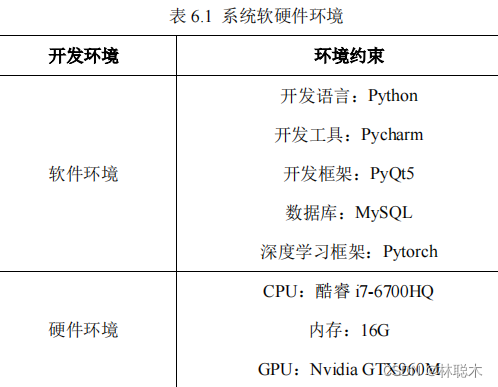
6.2システムソフトウェアおよびハードウェア環境
PyQt5フレーム
ワークと
Pytorch
深層学習を使用した地域畳み込みネットワークに基づく、シャドウ環境における街路ターゲット検出システム
学習フレームワーク等によりシステムの様々な機能が実現されます。
システム環境の制約を表6.1
に示します
。
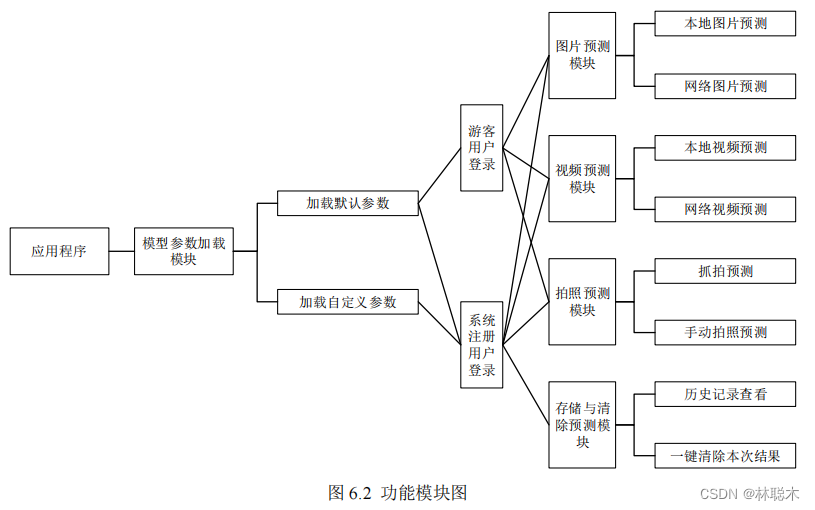
6.3機能モジュールの設計
地域畳み込みネットワークに基づく影環境におけるストリートビューターゲット検出システムは、以下の機能モジュールで構成されます。
(
1
) モデルパラメータロードモジュール: このモジュールは主にモデル層を呼び出し、システムユーザーは誰でもデフォルトの保存ディレクトリを取得できます。
記録された既存のモデルパラメータリストには、最終評価パラメータ、トレーニングステップ数、トレーニングステップ数などの特定のトレーニングパラメータが含まれます。
また、システムの登録ユーザーが追加のカスタマイズされたモデル パラメーター ファイルを使用するためのインターフェイスも提供します。
(2) ログイン モジュール: このモジュールはユーザーにプログラムへのメインの入り口を提供する役割を果たし、ユーザーは新規ユーザーとして登録できます。
既存のアカウントを使用してシステムにログインすることも、訪問者としてエクスペリエンス システムに参加することもできます。
データ永続層は、後のレビューを容易にするために、過去のシステム予測結果を保存するためのスペースをユーザーに割り当てます。
訪問者がプログラムを閉じるかシステムを終了すると、システムは予測結果を保持しません。
(3) 画像予測モジュール: このモジュールはビュー層とユーザーの間のコアアクセスモジュールの 1 つであり、このモジュールを独自にアップロードするかどうかはユーザーに任されています。
地図の画像は予測に使用されますが、同時にコンピューターがインターネットに接続されている場合、ユーザーは
URL
接続を提供してネットワーク マップをアップロードすることもできます。
予測用のスライス。
(4) ビデオ予測モジュール: ユーザーはローカル ビデオをアップロードするか、オンライン ビデオ
URLを提供
できます。
ビデオが分析され、フレームごとに検出され、最終的に検出結果のビデオが返されます。
(5) 写真予測モジュール: ユーザーは、外部カメラまたはその他のホットスワップ可能な写真機器を使用して写真を撮ることができ、システムは
これらのデバイスを直接呼び出してイメージングを行うと、ユーザーはキーボードの指定されたキーを押して写真を撮影し、予測を行うことができます。
自動写真予測を備えたリアルタイム キャプチャ モードを有効にできるため、ユーザーは写真を撮るために手動でボタンを押す必要がありません。
(6) ストレージおよびクリアリングモジュール: このモジュールはデータ永続層に接続されており、ユーザーがログインしている条件下で予測結果を分析する役割を果たします。
自動的に保存され、ユーザーが結果を保存する必要がないことに気付いた場合は、キャッシュのクリア機能を使用して、ワンクリックで結果をクリアできます。
予測によって生成された結果ファイル。
6.4システムプロセス
図6.3に示す
ように
、地域畳み込みネットワークに基づく影環境におけるストリートビューターゲット検出システム全体はユーザーレベルにあります。
プロセスは大きく
3 つの
部分に分けることができます。
まず、システムのホームページを開いてモデル パラメーターを選択します。訪問者は、デフォルトでシステムによって提供されるパラメーター エクスペリエンスのみを使用できます。システム ノート
登録ユーザーは、他の場所にアップロードされたパラメーター ファイルをカスタマイズし、ログイン ロールを選択して予測結果に基づいてデータを保存することもできます。
システム ユーザーとしてログインするかゲストとしてログインするかを選択する必要があります。あるいは、システム ユーザーとして登録することもできます。
第二に、正式にシステムに入った後、ユーザーは異なるボタンをクリックすることで画像予測機能とビデオ予測機能を使用できるようになります。
メディア予測方法は大きく分けて「関数」と「写真予測機能」の3つがあります。画像予測機能では、ユーザーはローカル画像を直接選択したり、
システムで使用するネットワーク画像
URLを提供します
。ビデオ予測機能では、ユーザーはローカル ビデオまたはインターネット ビデオ
URLをアップロードする必要があります
。
システム ビデオ ソース ファイルは予測用に提供されており、結果のビデオは直接再生、一時停止などが可能です。写真予測モジュール
、システムはユーザーのカメラ機器を直接呼び出して写真を撮影し、ユーザーは写真を撮るタイミングを決定することもできます。
第三に、予測が完了した後、ユーザーは予測結果を操作できます。すべての予測結果はデフォルトで保存されます。
ワンクリックでこの予測結果ファイルをクリアし、過去の予測結果を確認するための履歴結果表示インターフェイスを提供することを選択できます。
ログイン ユーザーの役割がゲストの場合、履歴情報は保存されず、履歴情報を照会したり、結果をクリアしたりする権限はありません。
フルーツドキュメントの必要性。
6.5システムの設計と実装
このセクションでは、地域畳み込みネットワークに基づく日陰環境における街路ターゲット検出システムのモジュール表示と説明を行います。
具体的には、コア機能モジュールとその他の補助モジュールに細分化されており、コアモジュールについては、システム インターフェイスのスクリーンショットと具体的な機能の紹介が示されています。
他の補助モジュールについては、簡単な分析と部分的な説明が示されています。
6.5.1システムコアモジュールの設計と実装
(
1
) システムメインインターフェースモジュール
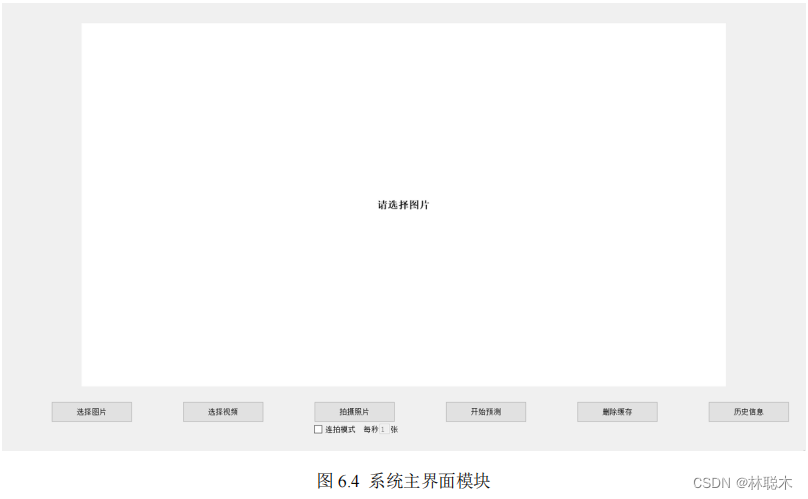
このシステムのメイン インターフェイスでは、サービス センターと同様に、さまざまな機能ボタンをクリックして、いくつかのコア機能にアクセスできます。
下の図6.4
に示すように、対応するコア機能を実現します
。システムのメイン インターフェイスは、いくつかのボタンと中央の表示領域で構成されます。各ボタン
関数の方向を示すテキストの説明があります。結果を表示する必要がある関数は、結果を処理して中央の表示フィールドに渡します。ユーザーは次のことができます。
予測結果または中間結果をリアルタイムで直接観察します。
システムのメインインターフェイスには、主に写真の選択、ビデオの選択、写真の撮影、予測の開始、キャッシュの削除などの機能入口が含まれています。
ストレージと履歴情報のうち、写真の選択、ビデオの選択、写真の撮影の 3 つの機能モジュールが中央の機能を呼び出します。
画像や動画のオリジナルプレビューファイルを表示する表示ドメイン 予測結果機能ボタンをクリックすると、画像や動画が処理されます。
分析と予測、最終的な予測結果も中央の表示ドメインに送信され、ユーザーに最も直接的な情報フィードバックが提供され、人間とコンピューターの対話が容易になります。
良い。
(2) 画像予測・映像予測モジュール
ユーザーが [画像の選択] または [ビデオの選択] ボタンをクリックすると、ローカルの画像またはビデオを選択するように求めるプロンプト サブインターフェイスがポップアップ表示されます。
ネットワーク画像またはビデオを使用します。ローカル画像またはビデオの場合は、図
6.5に示すように
、ユーザーがローカル画像またはビデオを選択するための選択ボックスがポップアップ表示されます。
ビデオ、オンラインの写真やビデオの場合、バックグラウンドは
URL
リンクを確認し、ダウンロードできるかどうかを判断し、ユーザーにプロンプトを表示します。
システムが操作を完了すると、ユーザーが写真やビデオをアップロードするためにどの方法を選択したとしても、中央の表示領域にソース ファイルが表示されます。
ユーザーが間違ったソース ファイルを選択していないことを確認するために、ステータス バーには現在のソース ファイルのパスも表示されます。ユーザーがソース ファイル情報を確認した後、
[予測の開始] ボタンをクリックすると、システムによって待機するよう求められます。データがバックグラウンドで処理され、事前トレーニングされたモデルの予測が完了した後、
予測結果は中央の表示フィールドのソース ファイルに直接上書きされ、中央の表示フィールドが更新されて予測結果が表示されるため、表示にも便利です。
ユーザーは予測結果をすぐに観察して必要な作業を完了できると同時に、観光客以外のユーザーのためにシステムが予測結果を自動的に保存します。
フルーツ。
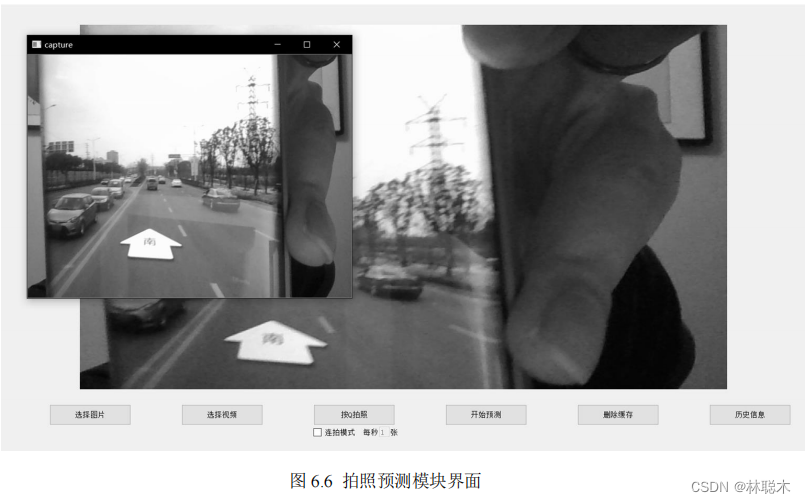
(3) 写真予測モジュール
ユーザーは、[写真を撮る] ボタンをクリックすると、デバイスのカメラまたは外部カメラが自動的に呼び出される手動写真予測機能を使用できます。
ヘッダーと、現在カメラで撮影されている画像がポップアップ表示され、ユーザーは画像を観察し、システムのプロンプトに従って手動でタイミングを決定し、ボタンを押すことができます。
写真を撮ります。下の図
6.6
は写真インターフェイスを示しています。写真が完了すると、写真の結果も中央の表示領域に転送されます。
注意深く分析または観察した後、「予測の開始」ボタンをクリックしてシステムがバックグラウンドで予測を開始することもでき、予測結果は同じになります。
中央の表示フィールドに表示されます。写真予測機能には、ユーザーが選択できる連写モードもあり、撮影した写真の下に連写モードを確認できます。
撮影モードのチェックボックスをクリックし、右側のテキストボックスを有効にすると、連続撮影の頻度をユーザーが決定できます。連続撮影モードはユーザーが指定した設定になります。
自動的にカメラが呼び出され、
指定された周波数で連続
9枚の写真が撮影され、撮影終了後、
9枚の写真が9マスのグリッド画像に合成されてパソコンに転送されます。
中央の表示欄が表示され、正しいことを確認した後、予測開始ボタンをクリックすると、システムは背景で
これら 9 枚の画像に対して予測を実行します。
予測、最終的な予測結果も中央の表示領域に 9 マスの形で表示されますので、観光客以外のユーザーは予測結果の写真を撮ってください。
また、自動的に保存されます。
6.5.2システムの他のモジュールの表示
(
1
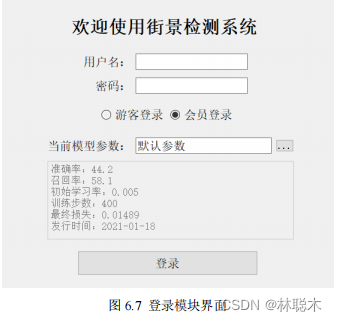
) ログインモジュール
システム ログイン インターフェイスは主に、システム バックエンド モデル パラメーターの指定とユーザーの ID と役割の確認を担当し、システム全体の鍵となります。
図6.7
に示すように、最初の入り口では
、まずデフォルトのバックエンド パラメーターと、システムの現在のバージョンの対応する評価値がユーザーに表示されます。
適合率、再現率、トレーニングステップ数、損失値、パラメータリリース時間などが含まれます。このとき、ログインロールは観光客と登録済みのどちらかを選択できます。
登録ユーザー。訪問者はログインしてメイン インターフェイスに直接入り、現在のパラメータをロックします。登録ユーザーはアカウントのパスワードを入力してシステムに入り、次の操作を行うことができます。
現在のユーザーの過去の予測情報を呼び出します。このインターフェイスでは、ユーザーはパラメーター ファイルをアップロードして、より豊富な予測効果を実現することもできます。
ただし、この機能は登録ユーザーのみをサポートしており、ゲスト ユーザーはパラメータ ファイルをカスタマイズできません。
(2) 履歴情報モジュール
ゲスト ユーザーの場合、このインターフェイスは直接非表示になりますが、登録ユーザーの場合は、図6.8
に示すように、
このインターフェイスは現在のユーザーを呼び出します。
データベース内のデータはファイル名と予測時刻ごとにリストされ、詳細なレコードをクリックすると表示されます。
中央の表示領域には、そのレコードの予測結果が表示されます。拡大ボタンをクリックすると、結果が全画面表示されます。同時に、次の予測結果についても表示されます。
端末モデルのパラメータには、ユーザーが履歴記録内の利用可能な情報をマイニングしやすくするための関連説明も含まれており、同じファイルとの比較にも使用されます。
異なるモデルパラメータの予測結果が比較および分析されます。