Якорь DETR (AAAI 2022)
Улучшать:
- Предлагаемый запрос объекта на основе привязки
- Предлагаемый вариант - RCDA
В предыдущем DETR целевым запросом был набор обучаемых вложений. Однако каждое обучаемое встраивание не имеет четкого значения (поскольку оно инициализируется случайным образом), поэтому нет объяснения того, где оно в конечном итоге сосредоточится. Кроме того, поскольку каждый запрос объекта не будет фокусироваться на определенной области , оптимизация во время обучения также затруднена.

Примечания по визуализации в DETR: (слоты — один из 100 запросов)

Три шаблона прогнозирования здесь могут быть одинаковыми или разными.
простая модель
Особо больших изменений от DETR нет.
6encoder, 6decoder, нижний правый угол — точки привязки.
встраивание позиции будет добавлено к q и k декодера
запрос объекта:[100,256] добавляет точку привязки, кодирует ее во встраивание позиции, заменяет исходный oq
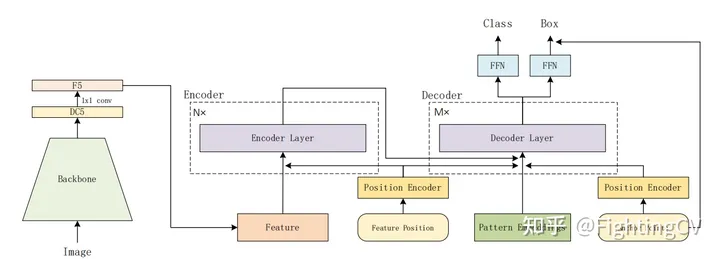
Существует два способа создания опорных точек.
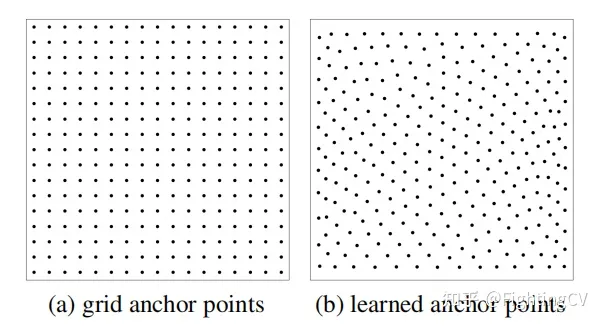
(а) Якорь фиксирован, ширина и высота распределены равномерно, а выборка однородна.
(б) Сначала случайным образом инициализируйте точки тензора с равномерным распределением 0-1 и используйте его в качестве параметра обучения (встраивание).Экспериментальный эффект хороший.

Преобразование точки привязки в запрос объекта

Сначала получите изученные опорные точки [100 (NA), 2] ;
Затем преобразуем его в высокочастотное кодирование позиции [100, 256] через sin/cos (функция в коде — pos2posemb2d);
После двух уровней обучения MLP (adapt_pos2d в коде) он преобразуется в Q_P: [Np (шаблон), 256].
Между кодексом и статьей есть некоторые различия:

Множественные прогнозы для каждой опорной точки
Предположим, что имеется 100 опорных точек, и каждая точка предсказывает цель. Реальное изображение может иметь несколько целей рядом с одной и той же точкой.
якорь detr предназначен для прогнозирования нескольких режимов (3 типа) для одной точки, причем режимы Np задаются для каждой точки (Np=3)
Исходный detr, запрос объекта — [100 256], каждый — [1 256]
Anchor detr добавляет встраивание шаблона следующим образом:
Q fi = Embedding ( N p , C ) Q_{f}^{i}=\operatorname{Embedding}\left(N_{p}, C\right)вопросжя"="Встраивание( Нп,C )
То есть каждая точка имеет шаблоны Np(3), [3, 256].В статье Np=300, шаблон=3, что составляет 900 точек.
В конце концов, вам нужно только добавить Q_p внедрения шаблона и точку привязки , чтобы получить окончательный запрос объекта.Запрос позиции шаблона можно выразить как:
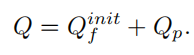
На самом деле приведенная выше формула в коде не используется.
В коде на предыдущей кодовой диаграмме контрольная точка напрямую повторяется от 300 до 900.
Напомните мне, если я что-то не так понимаю.
Шаблон кода является входом первого декодера, а tgt исходного detr все равны 0.

Внимание, разделенное между строками и столбцами
Что уменьшено, так это накладные расходы на память! ! ! !
Механизм внимания разложения строк и столбцов ускоряет сходимость.Длина q равна 900, что снижает нагрузку на память и накладные расходы на память.

Исходный входной токен трансформатора (H*W) будет преобразован в одномерный входной сигнал.
Ax (W), рассчитывается первым в измерении строки
Ay (H), выполнение операции Ay
Ay и Z выполняют взвешенную сумму в измерении высоты.
QK all выполняет разложение по строкам и столбцам, V не разлагает [Nq, H*W]
Исходное внимание: Nq*H*W*M (голова)
RCDA:
Акс:Nq*W*M
Есть: Nq*H*M
Вам нужно только сравнить размеры двух матриц.Правая часть рисунка - это формула пропорции.После сравнения двух измерений слева остается W*M/C.W предполагается равным 32 (DC5), M=8 , C=256. То же самое, посмотрите на C и W*M
DC5 означает, что к последнему этапу магистральной сети добавляется свертка дыр (по умолчанию resnet50), а уровень пула уменьшается для удвоения разрешения.
эксперимент
1. Сравнение памяти и ПД разного линейного внимания.
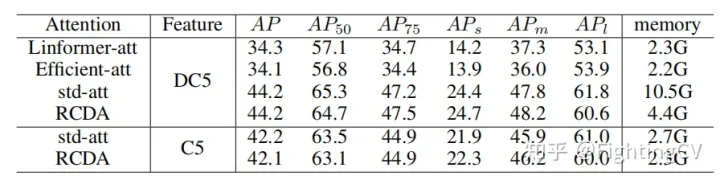
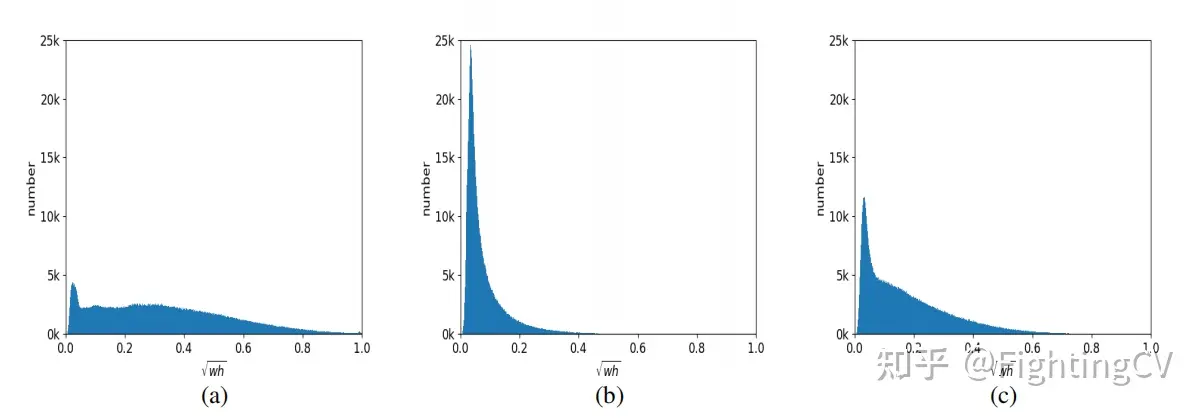
2. Режим a обычно предназначен для крупных объектов, режим b — для мелких объектов, а режим c более сбалансирован.
ссылка
https://www.bilibili.com/video/BV148411M7ev/?spm_id_from=333.788&vd_source=4e2df178682eb78a7ad1cc398e6e154d