
В расширенной серии «X» «Встраивание в НЛП» мы представили базовые знания об обработке естественного языка — языковых моделях токенов, N-грамм и пакетов слов на естественном языке. Сегодня мы продолжим с вами «практиковаться», углубимся в нейросетевые языковые модели, особенно рекуррентные нейронные сети, и кратко разберемся, как генерировать векторы встраивания.
01. Глубокое понимание нейронных сетей
Сначала давайте кратко рассмотрим компоненты нейронных сетей, а именно нейроны, многослойные сети и алгоритм обратного распространения ошибки. Если вы хотите подробнее узнать об этих базовых понятиях, вы можете обратиться к другим ресурсам, например к примечаниям к курсу CS231n .
В машинном обучении нейроны являются основными единицами, из которых состоят все нейронные сети. По сути, нейрон — это единица нейронной сети, которая принимает взвешенную сумму всех своих входных данных плюс необязательный член смещения. Представление уравнения следующее:
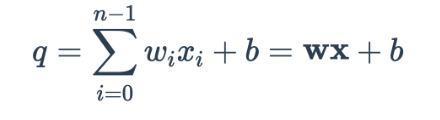
Здесь 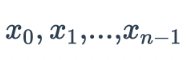 представляет выходной сигнал нейрона на предыдущем слое и
представляет выходной сигнал нейрона на предыдущем слое и 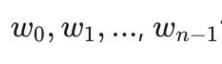 представляет вес, используемый этим нейроном для синтеза выходного значения.
представляет вес, используемый этим нейроном для синтеза выходного значения.
Если бы многослойная нейронная сеть состояла только из взвешенных сумм в приведенном выше уравнении, мы могли бы объединить все термины в один линейный слой, что не очень идеально для моделирования отношений между токенами или кодирования сложного текста. Вот почему все нейроны содержат нелинейную функцию активации после взвешенной суммы, наиболее известным примером которой является функция выпрямленной линейной единицы (ReLU):
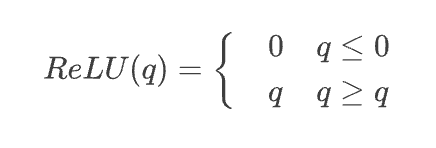
Для большинства современных языковых моделей нейронных сетей более распространена функция активации Gaussian Error Linear Unit (GELU):
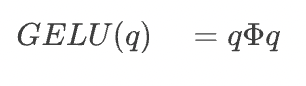
Здесь 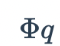 представляет собой кумулятивную функцию распределения Гаусса, которую можно
представляет собой кумулятивную функцию распределения Гаусса, которую можно  использовать для выражения. Эта функция активации применяется после взвешенного суммирования, описанного выше. В целом один нейрон выглядит так:
использовать для выражения. Эта функция активации применяется после взвешенного суммирования, описанного выше. В целом один нейрон выглядит так:
Чтобы изучить более сложные функции, мы можем складывать нейроны друг над другом, образуя слой. Все нейроны в одном слое получают одинаковые входные данные; единственная разница между ними — это вес W и смещение b. Мы можем выразить приведенное выше уравнение в матричной записи для одного слоя:
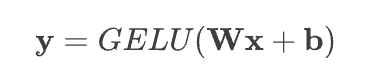
Здесь w — двумерная матрица, содержащая все веса, приложенные к входу x ; каждая строка матрицы соответствует весу нейрона. Этот тип слоя часто называют плотным слоем или полностью связным слоем, поскольку все входы x подключены ко всем выходам y .
Мы можем объединить эти два слоя, чтобы создать базовую сеть прямой связи:
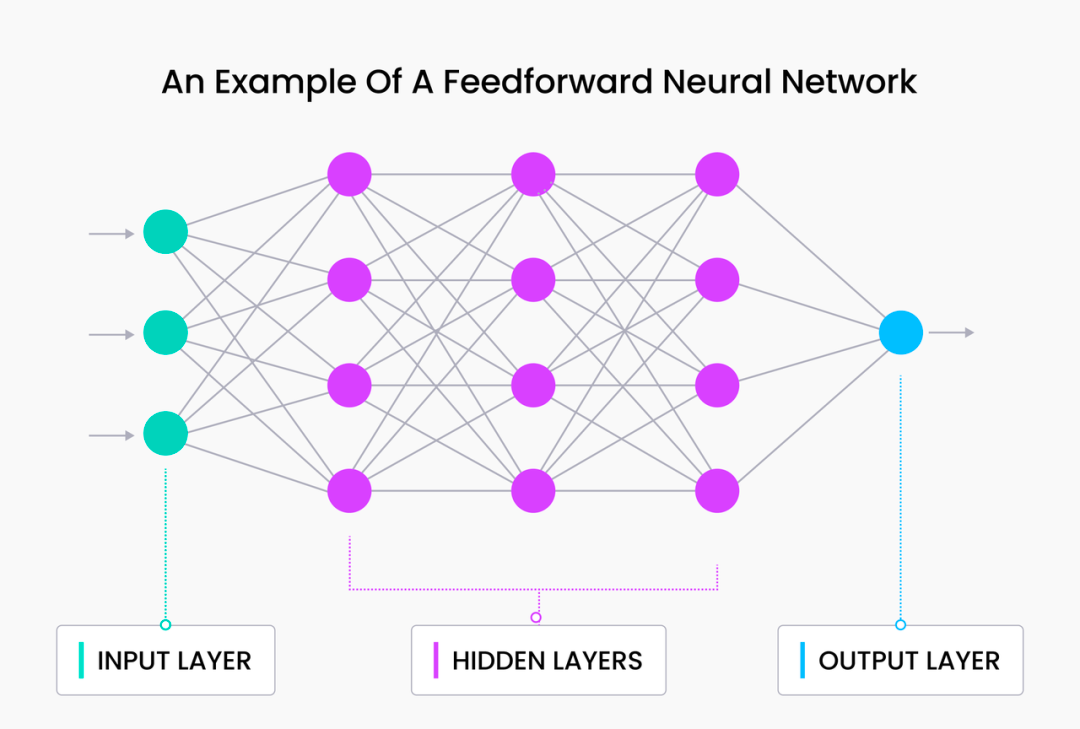
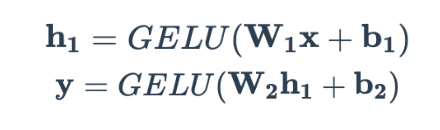
Здесь мы вводим новый скрытый слой h1 , который не связан напрямую ни со входом x , ни с выходом y . Этот слой эффективно увеличивает глубину сети, увеличивая общее количество параметров (множественные весовые матрицы w ). При этом важно отметить, что по мере добавления большего количества скрытых слоев скрытые значения (значения активации), близкие к входному слою, становятся более «похожими» на x , в то время как значения активации, близкие к выходному, становятся больше похоже на y .
Мы обсудим встраивание векторов на основе этого принципа в последующих статьях. Концепция скрытых слоев имеет решающее значение для понимания векторного поиска.
Параметры отдельных нейронов в сети прямого распространения можно обновить с помощью процесса, называемого обратным распространением ошибки, который, по сути, представляет собой повторное применение правила цепочки в исчислении. Вы можете поискать курсы, которые конкретно объясняют обратное распространение ошибки. Эти курсы расскажут, почему обратное распространение ошибки настолько эффективно для обучения нейронных сетей. Мы не будем здесь вдаваться в подробности, основной процесс заключается в следующем:
-
Пропустите пакет данных через нейронную сеть.
-
Посчитайте потери. Обычно это потеря L2 (квадратная разность) для регрессии и потеря перекрестной энтропии для классификации.
-
Используйте эту потерю для расчета градиента потерь с весами последнего скрытого слоя
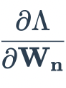 .
. -
Рассчитайте потери через последний скрытый слой,
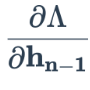 т.е.
т.е. -
Обратно распространите эту потерю на веса предпоследнего скрытого слоя
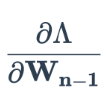 .
. -
Повторяйте шаги 4 и 5, пока не будут рассчитаны частные производные всех весов.
После расчета частных производных потерь, связанных со всеми весами в сети, можно выполнить массовое обновление весов на основе оптимизатора и скорости обучения. Этот процесс повторяется до тех пор, пока модель не достигнет сходимости или пока не будут завершены все эпохи.
02. Рекуррентная нейронная сеть
Все формы текста и естественного языка по своей природе являются последовательными, то есть слова/токены обрабатываются одно за другим. Простые, казалось бы, изменения, такие как добавление слова, перестановка двух последовательных токенов или добавление знаков препинания, могут привести к огромным различиям в интерпретации. Например, фразы «давай поедим, Чарльз» и «давай поедим Чарльза» — это совершенно разные вещи. Из-за последовательной природы естественного языка рекуррентные нейронные сети (RNN), естественно, стали лучшим выбором для языкового моделирования.
Рекурсия — это уникальная форма рекурсии, в которой функцией является нейронная сеть, а не код. RNN также имеет биологическое происхождение: человеческий мозг можно сравнить с (искусственной) нейронной сетью, а слова, которые мы вводим или произносим, являются результатами биологической обработки.
RNN состоит из двух компонентов: 1) стандартной сети прямого распространения и 2) рекурсивного компонента. Сети прямой связи — это те же сети, которые мы обсуждали в предыдущем разделе. Для рекурсивного компонента последнее скрытое состояние возвращается на вход, чтобы сеть могла сохранить предыдущий контекст. Таким образом, предыдущие знания (в виде скрытых слоев предыдущего временного шага) вводятся в сеть на каждом новом временном шаге.
Основываясь на приведенном выше макроопределении и объяснении RNN, мы можем примерно понять, как он реализуется и почему RNN хорошо работает в семантическом моделировании.
Во-первых, рекуррентная структура RNN позволяет им последовательно собирать и обрабатывать данные, подобно тому, как люди говорят, читают и пишут. Кроме того, RNN могут эффективно получать доступ к «информации» из более ранних времен и понимать естественный язык лучше, чем модели n-грамм и чистые сети прямой связи.
Вы можете попробовать использовать PyTorch для реализации RNN. Обратите внимание, что для этого необходимо глубокое понимание основ PyTorch; если вы не знакомы с PyTorch, рекомендуется сначала прочитать эту ссылку .
Сначала определите простую сеть прямого распространения, затем расширите ее до простой RNN, сначала определив слои:
from torch import Tensor
import torch.nn as nn
class BasicNN(nn.Module):
def __init__(self, in_dims: int, hidden_dims: int, out_dims: int):
super(BasicNN, self).__init__()
self.w0 = nn.Linear(in_dims, hidden_dims)
self.w1 = nn.Linear(hidden_dims, out_dims)
Обратите внимание: поскольку мы выводим только необработанные логические значения, мы не определили стиль потери. Во время обучения могут быть добавлены некоторые стандарты в зависимости от реальной ситуации, например nn.CrossEntropyLoss: .
Теперь мы можем реализовать прямой проход:
def forward(self, x: Tensor):
h = self.w0(x)
y = self.w1(h)
return y
Эти два фрагмента кода вместе образуют очень простую нейронную сеть прямого распространения. Чтобы превратить это в RNN, нам нужно добавить цикл обратной связи из последнего скрытого состояния обратно на вход:
def forward(self, x: Tensor, h_p: Tensor):
h = self.w0(torch.cat(x, h_p))
y = self.w1(h)
return (y, h)
Вышеупомянутые, по сути, все шаги. Поскольку теперь мы увеличиваем w0количество входных данных для слоя нейронов, определяемого , нам необходимо __init__обновить его определение в . Теперь давайте сделаем это и объединим все в фрагмент кода:
import torch.nn as nn
from torch import Tensor
class SimpleRNN(nn.Module):
def __init__(self, in_dims: int, hidden_dims: int, out_dims: int):
super(RNN, self).__init__()
self.w0 = nn.Linear(in_dims + hidden_dims, hidden_dims)
self.w1 = nn.Linear(hidden_dims, out_dims)
def forward(self, x: Tensor, h_p: Tensor):
h = self.w0(torch.cat(x, h_p))
y = self.w1(h)
return (y, h)
При каждом прямом проходе hзначения активации скрытого слоя возвращаются вместе с выходными данными. Эти значения активации затем можно снова передать обратно в модель с каждым новым токеном в последовательности. Такой процесс выглядит следующим образом (следующий код приведен только для иллюстрации):
model = SimpleRNN(n_in, n_hidden, n_out)
...
h = torch.zeros(1, n_hidden)
for token in range(seq):
(out, h) = model(token, )
На этом этапе мы успешно определили простую сеть прямого распространения и расширили ее до простой RNN.
03. Встраивание языковой модели
Скрытый слой, который мы видели в приведенном выше примере, эффективно кодирует все, что было введено в RNN (все токены). Точнее, вся информация, необходимая для анализа текста, который увидел RNN, должна содержаться в значении активации h. Другими словами, h кодирует семантику входной последовательности, а упорядоченный набор значений с плавающей запятой, определенный h, является вектором внедрения, называемым вектором внедрения.
Эти векторные представления широко составляют основу векторного поиска и векторных баз данных. Хотя сегодняшние встраивания естественного языка создаются с помощью другого класса моделей машинного обучения, называемых трансформерами, а не RNN, основная концепция в основном та же: кодирование текстового контента в понятные компьютеру векторы внедрения. Мы подробно обсудим использование векторов внедрения в нашем следующем сообщении в блоге.
04. Резюме
Мы реализовали простую рекуррентную нейронную сеть в PyTorch и кратко представили языковую модель Embedding. Хотя рекуррентные нейронные сети являются мощными инструментами для понимания языка и могут использоваться в самых разных приложениях (машинный перевод, классификация, ответы на вопросы и т. д.), они по-прежнему не относятся к типу модели МО, используемой для генерации векторов внедрения.
В следующем уроке мы будем использовать модель Transformer с открытым исходным кодом для создания векторов внедрения и продемонстрируем возможности векторов, выполняя векторный поиск и операции над ними. Кроме того, мы также вернемся к концепции моделей «мешков слов» и посмотрим, как их можно использовать вместе для кодирования словарного запаса и семантики. Следите за обновлениями!
Тан Сяоу, основатель SenseTime, скончался в возрасте 55 лет. В 2023 году PHP находился в застое . Система Hongmeng вот-вот станет независимой, и многие университеты создали «классы Hongmeng». Версия Quark Browser для ПК начала внутреннее тестирование. ByteDance был «запрещен» OpenAI. Стартап-компания Чжихуэйцзюня была рефинансирована на сумму более 600 миллионов юаней, а предварительная оценка составила 3,5 миллиарда юаней. Помощники по написанию кода на основе искусственного интеллекта настолько популярны, что они даже не могут конкурировать в программировании. языковые рейтинги Mate 60 Pro модем 5G и радиочастотная технология далеко впереди No Star, No Fix MariaDB отделяется от SkySQL и становится независимой компанией