A, приобретение заголовков
Возьмите блог Home Park, например: HTTP: //www.cnblogs.com/
Откройте страницу, нажмите клавишу F12, как показано ниже:
Перейдите на вкладку ниже сетей, следующим образом:
После щелчка, показанного на фиг:
Найдите ярлык, показанный в красном положении подчеркивания и нажмите в правой части экрана вы можете просмотреть содержимое заголовков, необходимых информацию.
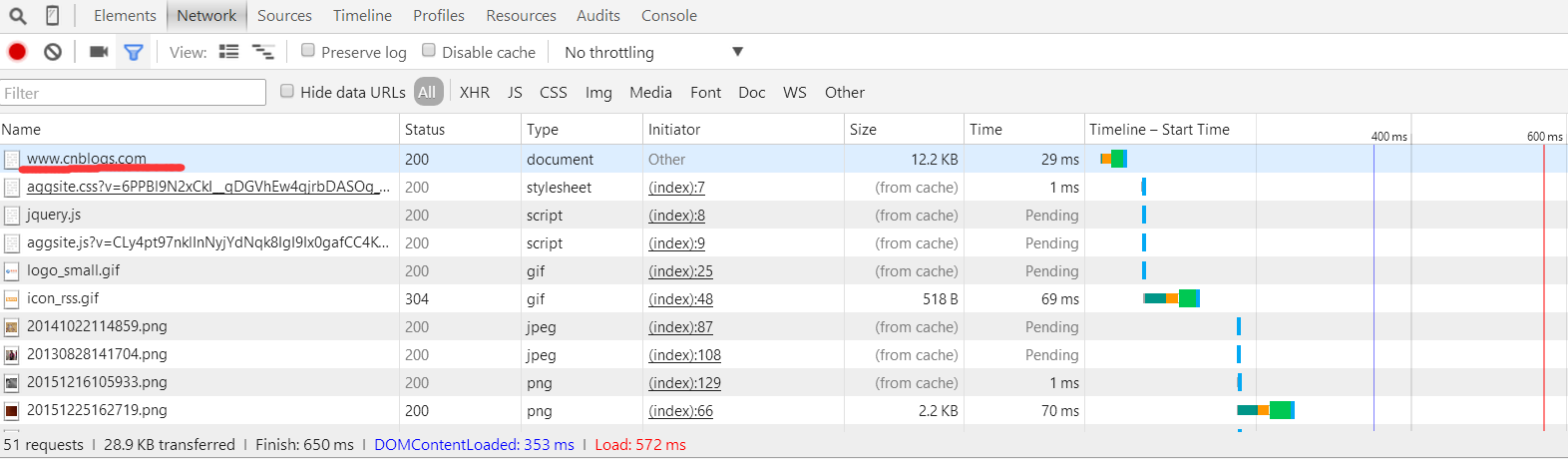
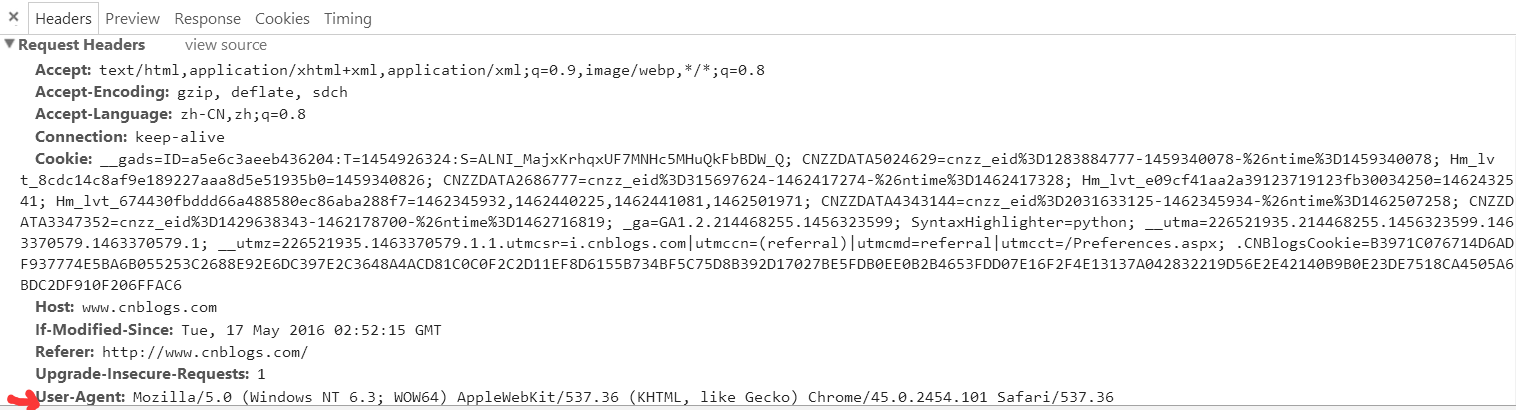
Как правило, нужно только добавить User-Agent Этой информации достаточно, заголовки также словарь;
user_agent = ' Mozilla / 5.0 (Windows NT 6.3; WOW64) AppleWebKit / 537,36 (KHTML, как Gecko) Chrome / 45.0.2454.101 Safari / 537.36 ' заголовки = { ' User-Agent ': user_agent}
приобретение двух, данных
В блог экран входа в сад, к примеру: HTTP: //passport.cnblogs.com/user/signin ReturnUrl = HTTP% 3A% 2F% 2F% 2Fwww.cnblogs.com?
Нажмите клавишу F12, как показано ниже:
Нажмите Network, то не стесняйтесь, чтобы ввести имя пользователя и пароль, нажмите на входе можно увидеть ниже:

Сад Войти Информация Блог данные:
data={
input1:"*******",
input2:"*******", remember:"false" }
以电驴下载网站为例:http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/
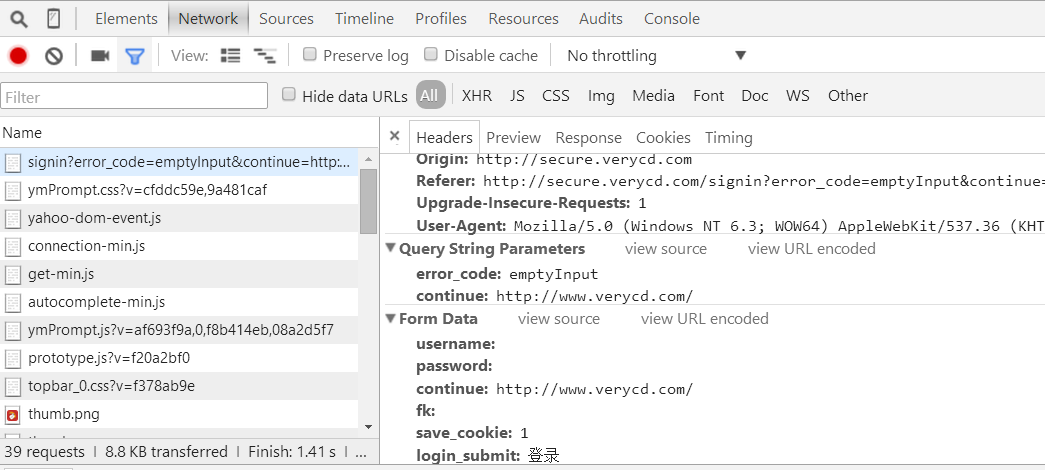
data信息在From Data标签中:

data={
username:"****",
password:"****", continue:"http://www.verycd.com/" fk:" ", save_cookie:1, login_submit:"登录" }
每一个登录网站的data信息不一定一样,都需要进入网页确定。
好啦,今天就到这了~明天介绍一个实例:如何爬取糗百的段子。
转载时注明原作者出处:Maple2cat|Python爬虫学习:四、headers和data的获取